 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Practical End-to-End Optical Music Recognition for Pianoform Music
Mar 20, 2024

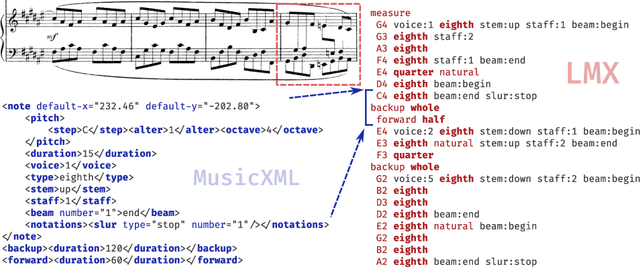

The majority of recent progress in Optical Music Recognition (OMR) has been achieved with Deep Learning methods, especially models following the end-to-end paradigm, reading input images and producing a linear sequence of tokens. Unfortunately, many music scores, especially piano music, cannot be easily converted to a linear sequence. This has led OMR researchers to use custom linearized encodings, instead of broadly accepted structured formats for music notation. Their diversity makes it difficult to compare the performance of OMR systems directly. To bring recent OMR model progress closer to useful results: (a) We define a sequential format called Linearized MusicXML, allowing to train an end-to-end model directly and maintaining close cohesion and compatibility with the industry-standard MusicXML format. (b) We create a dev and test set for benchmarking typeset OMR with MusicXML ground truth based on the OpenScore Lieder corpus. They contain 1,438 and 1,493 pianoform systems, each with an image from IMSLP. (c) We train and fine-tune an end-to-end model to serve as a baseline on the dataset and employ the TEDn metric to evaluate the model. We also test our model against the recently published synthetic pianoform dataset GrandStaff and surpass the state-of-the-art results.
Be-Your-Outpainter: Mastering Video Outpainting through Input-Specific Adaptation
Mar 20, 2024


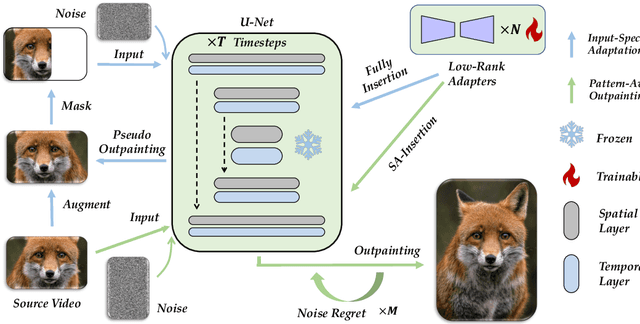
Video outpainting is a challenging task, aiming at generating video content outside the viewport of the input video while maintaining inter-frame and intra-frame consistency. Existing methods fall short in either generation quality or flexibility. We introduce MOTIA Mastering Video Outpainting Through Input-Specific Adaptation, a diffusion-based pipeline that leverages both the intrinsic data-specific patterns of the source video and the image/video generative prior for effective outpainting. MOTIA comprises two main phases: input-specific adaptation and pattern-aware outpainting. The input-specific adaptation phase involves conducting efficient and effective pseudo outpainting learning on the single-shot source video. This process encourages the model to identify and learn patterns within the source video, as well as bridging the gap between standard generative processes and outpainting. The subsequent phase, pattern-aware outpainting, is dedicated to the generalization of these learned patterns to generate outpainting outcomes. Additional strategies including spatial-aware insertion and noise travel are proposed to better leverage the diffusion model's generative prior and the acquired video patterns from source videos. Extensive evaluations underscore MOTIA's superiority, outperforming existing state-of-the-art methods in widely recognized benchmarks. Notably, these advancements are achieved without necessitating extensive, task-specific tuning.
Grounding Spatial Relations in Text-Only Language Models
Mar 20, 2024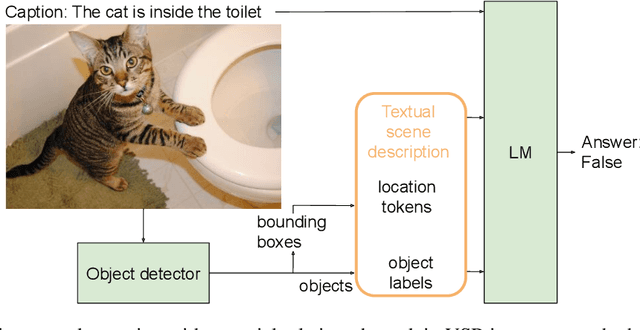
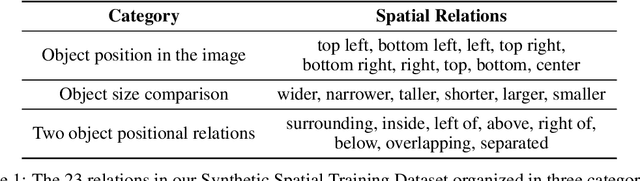


This paper shows that text-only Language Models (LM) can learn to ground spatial relations like "left of" or "below" if they are provided with explicit location information of objects and they are properly trained to leverage those locations. We perform experiments on a verbalized version of the Visual Spatial Reasoning (VSR) dataset, where images are coupled with textual statements which contain real or fake spatial relations between two objects of the image. We verbalize the images using an off-the-shelf object detector, adding location tokens to every object label to represent their bounding boxes in textual form. Given the small size of VSR, we do not observe any improvement when using locations, but pretraining the LM over a synthetic dataset automatically derived by us improves results significantly when using location tokens. We thus show that locations allow LMs to ground spatial relations, with our text-only LMs outperforming Vision-and-Language Models and setting the new state-of-the-art for the VSR dataset. Our analysis show that our text-only LMs can generalize beyond the relations seen in the synthetic dataset to some extent, learning also more useful information than that encoded in the spatial rules we used to create the synthetic dataset itself.
ProMamba: Prompt-Mamba for polyp segmentation
Mar 20, 2024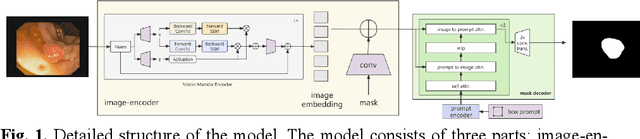
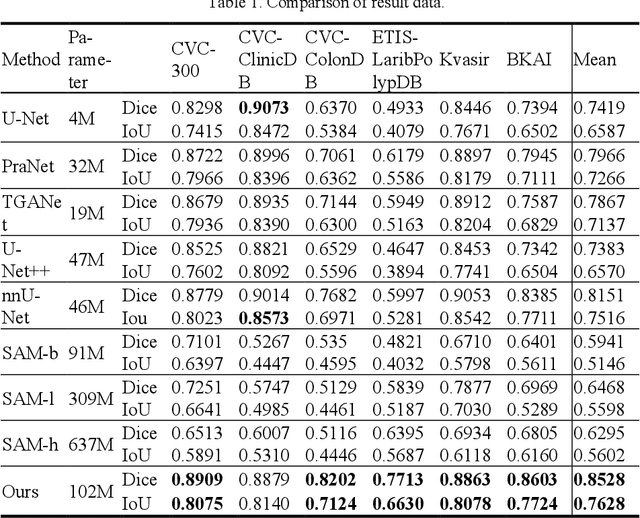
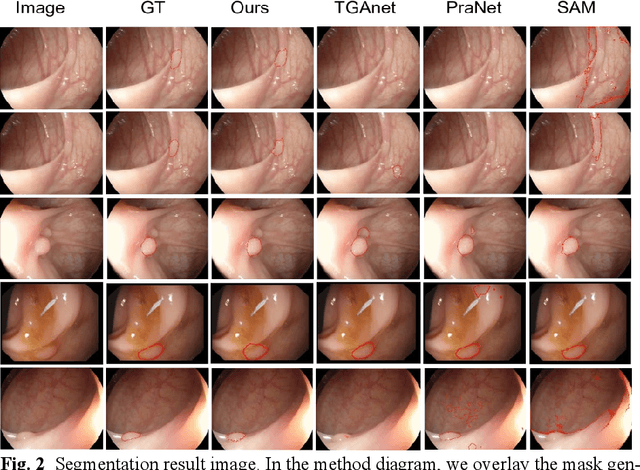
Detecting polyps through colonoscopy is an important task in medical image segmentation, which provides significant assistance and reference value for clinical surgery. However, accurate segmentation of polyps is a challenging task due to two main reasons. Firstly, polyps exhibit various shapes and colors. Secondly, the boundaries between polyps and their normal surroundings are often unclear. Additionally, significant differences between different datasets lead to limited generalization capabilities of existing methods. To address these issues, we propose a segmentation model based on Prompt-Mamba, which incorporates the latest Vision-Mamba and prompt technologies. Compared to previous models trained on the same dataset, our model not only maintains high segmentation accuracy on the validation part of the same dataset but also demonstrates superior accuracy on unseen datasets, exhibiting excellent generalization capabilities. Notably, we are the first to apply the Vision-Mamba architecture to polyp segmentation and the first to utilize prompt technology in a polyp segmentation model. Our model efficiently accomplishes segmentation tasks, surpassing previous state-of-the-art methods by an average of 5% across six datasets. Furthermore, we have developed multiple versions of our model with scaled parameter counts, achieving better performance than previous models even with fewer parameters. Our code and trained weights will be released soon.
HyperFusion: A Hypernetwork Approach to Multimodal Integration of Tabular and Medical Imaging Data for Predictive Modeling
Mar 20, 2024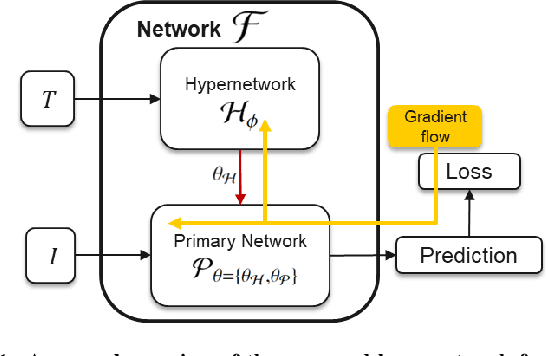
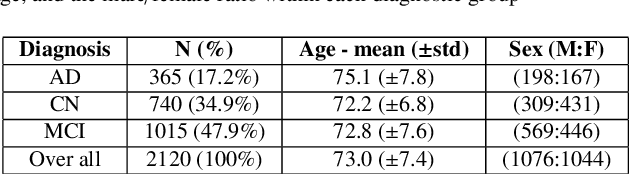
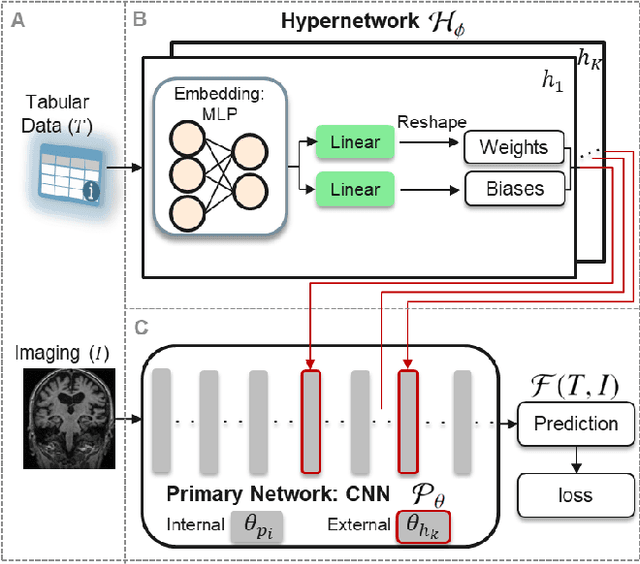
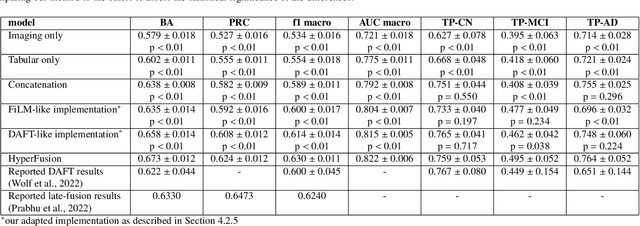
The integration of diverse clinical modalities such as medical imaging and the tabular data obtained by the patients' Electronic Health Records (EHRs) is a crucial aspect of modern healthcare. The integrative analysis of multiple sources can provide a comprehensive understanding of a patient's condition and can enhance diagnoses and treatment decisions. Deep Neural Networks (DNNs) consistently showcase outstanding performance in a wide range of multimodal tasks in the medical domain. However, the complex endeavor of effectively merging medical imaging with clinical, demographic and genetic information represented as numerical tabular data remains a highly active and ongoing research pursuit. We present a novel framework based on hypernetworks to fuse clinical imaging and tabular data by conditioning the image processing on the EHR's values and measurements. This approach aims to leverage the complementary information present in these modalities to enhance the accuracy of various medical applications. We demonstrate the strength and the generality of our method on two different brain Magnetic Resonance Imaging (MRI) analysis tasks, namely, brain age prediction conditioned by subject's sex, and multiclass Alzheimer's Disease (AD) classification conditioned by tabular data. We show that our framework outperforms both single-modality models and state-of-the-art MRI-tabular data fusion methods. The code, enclosed to this manuscript will be made publicly available.
Leveraging Neural Radiance Field in Descriptor Synthesis for Keypoints Scene Coordinate Regression
Mar 20, 2024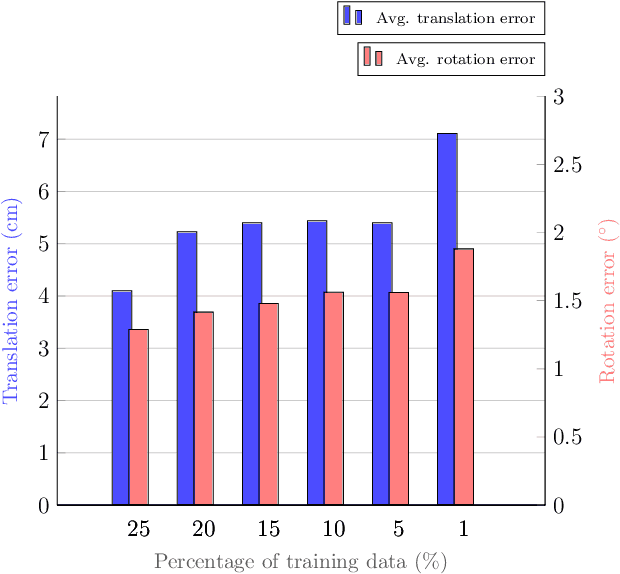
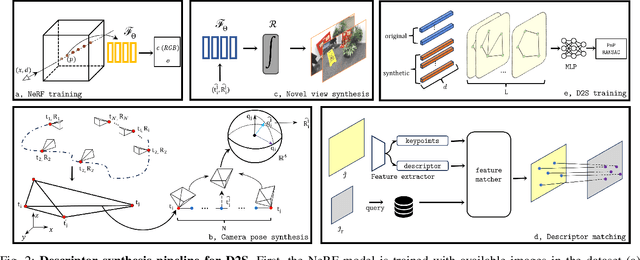
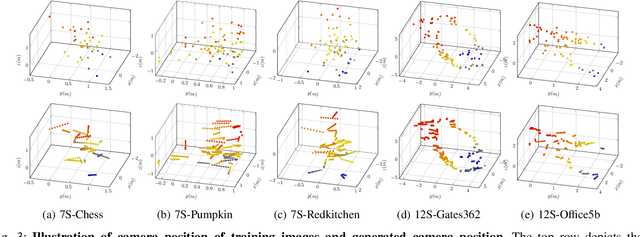

Classical structural-based visual localization methods offer high accuracy but face trade-offs in terms of storage, speed, and privacy. A recent innovation, keypoint scene coordinate regression (KSCR) named D2S addresses these issues by leveraging graph attention networks to enhance keypoint relationships and predict their 3D coordinates using a simple multilayer perceptron (MLP). Camera pose is then determined via PnP+RANSAC, using established 2D-3D correspondences. While KSCR achieves competitive results, rivaling state-of-the-art image-retrieval methods like HLoc across multiple benchmarks, its performance is hindered when data samples are limited due to the deep learning model's reliance on extensive data. This paper proposes a solution to this challenge by introducing a pipeline for keypoint descriptor synthesis using Neural Radiance Field (NeRF). By generating novel poses and feeding them into a trained NeRF model to create new views, our approach enhances the KSCR's generalization capabilities in data-scarce environments. The proposed system could significantly improve localization accuracy by up to 50% and cost only a fraction of time for data synthesis. Furthermore, its modular design allows for the integration of multiple NeRFs, offering a versatile and efficient solution for visual localization. The implementation is publicly available at: https://github.com/ais-lab/DescriptorSynthesis4Feat2Map.
A survey of synthetic data augmentation methods in computer vision
Mar 18, 2024The standard approach to tackling computer vision problems is to train deep convolutional neural network (CNN) models using large-scale image datasets which are representative of the target task. However, in many scenarios, it is often challenging to obtain sufficient image data for the target task. Data augmentation is a way to mitigate this challenge. A common practice is to explicitly transform existing images in desired ways so as to create the required volume and variability of training data necessary to achieve good generalization performance. In situations where data for the target domain is not accessible, a viable workaround is to synthesize training data from scratch--i.e., synthetic data augmentation. This paper presents an extensive review of synthetic data augmentation techniques. It covers data synthesis approaches based on realistic 3D graphics modeling, neural style transfer (NST), differential neural rendering, and generative artificial intelligence (AI) techniques such as generative adversarial networks (GANs) and variational autoencoders (VAEs). For each of these classes of methods, we focus on the important data generation and augmentation techniques, general scope of application and specific use-cases, as well as existing limitations and possible workarounds. Additionally, we provide a summary of common synthetic datasets for training computer vision models, highlighting the main features, application domains and supported tasks. Finally, we discuss the effectiveness of synthetic data augmentation methods. Since this is the first paper to explore synthetic data augmentation methods in great detail, we are hoping to equip readers with the necessary background information and in-depth knowledge of existing methods and their attendant issues.
AI-Assisted Cervical Cancer Screening
Mar 18, 2024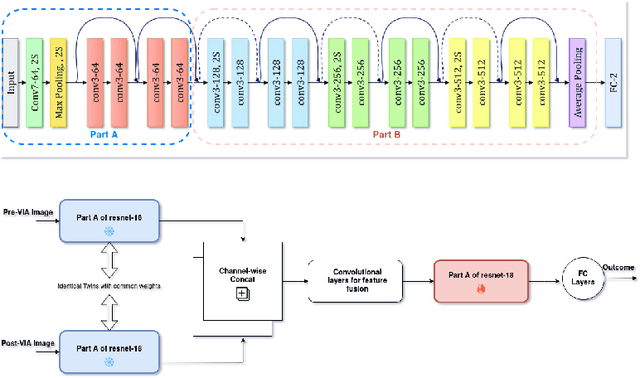

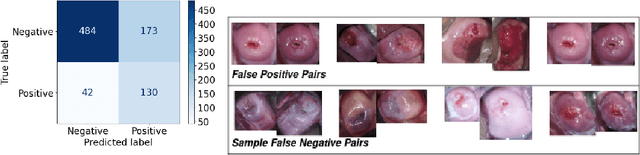
Visual Inspection with Acetic Acid (VIA) remains the most feasible cervical cancer screening test in resource-constrained settings of low- and middle-income countries (LMICs), which are often performed screening camps or primary/community health centers by nurses instead of the preferred but unavailable expert Gynecologist. To address the highly subjective nature of the test, various handheld devices integrating cameras or smartphones have been recently explored to capture cervical images during VIA and aid decision-making via telemedicine or AI models. Most studies proposing AI models retrospectively use a relatively small number of already collected images from specific devices, digital cameras, or smartphones; the challenges and protocol for quality image acquisition during VIA in resource-constrained camp settings, challenges in getting gold standard, data imbalance, etc. are often overlooked. We present a novel approach and describe the end-to-end design process to build a robust smartphone-based AI-assisted system that does not require buying a separate integrated device: the proposed protocol for quality image acquisition in resource-constrained settings, dataset collected from 1,430 women during VIA performed by nurses in screening camps, preprocessing pipeline, and training and evaluation of a deep-learning-based classification model aimed to identify (pre)cancerous lesions. Our work shows that the readily available smartphones and a suitable protocol can capture the cervix images with the required details for the VIA test well; the deep-learning-based classification model provides promising results to assist nurses in VIA screening; and provides a direction for large-scale data collection and validation in resource-constrained settings.
IDF-CR: Iterative Diffusion Process for Divide-and-Conquer Cloud Removal in Remote-sensing Images
Mar 18, 2024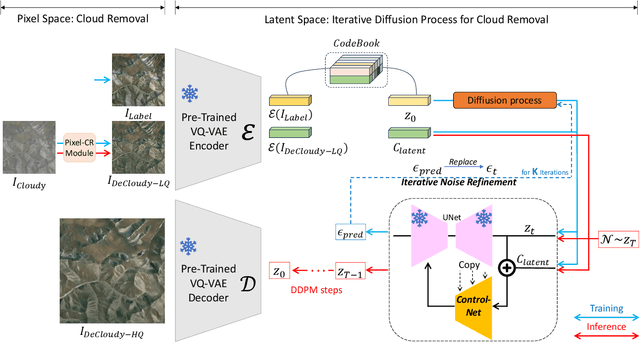
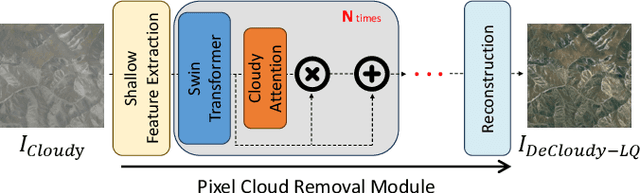
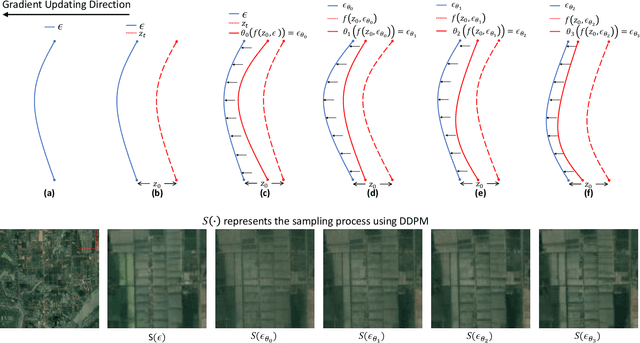

Deep learning technologies have demonstrated their effectiveness in removing cloud cover from optical remote-sensing images. Convolutional Neural Networks (CNNs) exert dominance in the cloud removal tasks. However, constrained by the inherent limitations of convolutional operations, CNNs can address only a modest fraction of cloud occlusion. In recent years, diffusion models have achieved state-of-the-art (SOTA) proficiency in image generation and reconstruction due to their formidable generative capabilities. Inspired by the rapid development of diffusion models, we first present an iterative diffusion process for cloud removal (IDF-CR), which exhibits a strong generative capabilities to achieve component divide-and-conquer cloud removal. IDF-CR consists of a pixel space cloud removal module (Pixel-CR) and a latent space iterative noise diffusion network (IND). Specifically, IDF-CR is divided into two-stage models that address pixel space and latent space. The two-stage model facilitates a strategic transition from preliminary cloud reduction to meticulous detail refinement. In the pixel space stage, Pixel-CR initiates the processing of cloudy images, yielding a suboptimal cloud removal prior to providing the diffusion model with prior cloud removal knowledge. In the latent space stage, the diffusion model transforms low-quality cloud removal into high-quality clean output. We refine the Stable Diffusion by implementing ControlNet. In addition, an unsupervised iterative noise refinement (INR) module is introduced for diffusion model to optimize the distribution of the predicted noise, thereby enhancing advanced detail recovery. Our model performs best with other SOTA methods, including image reconstruction and optical remote-sensing cloud removal on the optical remote-sensing datasets.
ObjectCompose: Evaluating Resilience of Vision-Based Models on Object-to-Background Compositional Changes
Mar 15, 2024
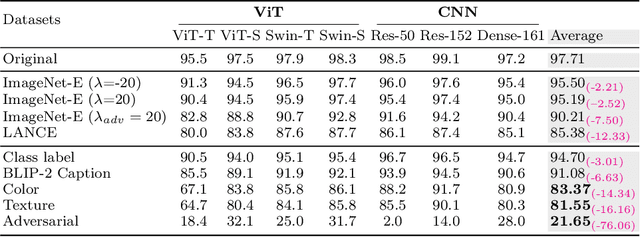
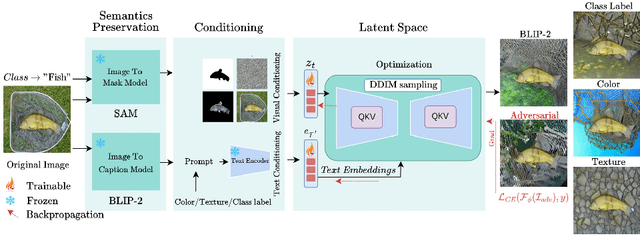
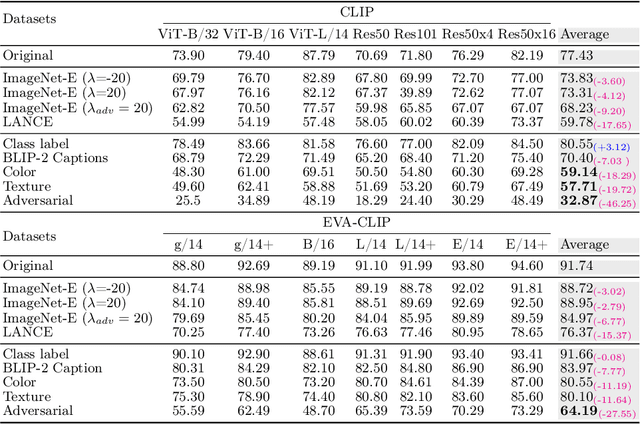
Given the large-scale multi-modal training of recent vision-based models and their generalization capabilities, understanding the extent of their robustness is critical for their real-world deployment. In this work, we evaluate the resilience of current vision-based models against diverse object-to-background context variations. The majority of robustness evaluation methods have introduced synthetic datasets to induce changes to object characteristics (viewpoints, scale, color) or utilized image transformation techniques (adversarial changes, common corruptions) on real images to simulate shifts in distributions. Recent works have explored leveraging large language models and diffusion models to generate changes in the background. However, these methods either lack in offering control over the changes to be made or distort the object semantics, making them unsuitable for the task. Our method, on the other hand, can induce diverse object-to-background changes while preserving the original semantics and appearance of the object. To achieve this goal, we harness the generative capabilities of text-to-image, image-to-text, and image-to-segment models to automatically generate a broad spectrum of object-to-background changes. We induce both natural and adversarial background changes by either modifying the textual prompts or optimizing the latents and textual embedding of text-to-image models. This allows us to quantify the role of background context in understanding the robustness and generalization of deep neural networks. We produce various versions of standard vision datasets (ImageNet, COCO), incorporating either diverse and realistic backgrounds into the images or introducing color, texture, and adversarial changes in the background. We conduct extensive experiment to analyze the robustness of vision-based models against object-to-background context variations across diverse tasks.