 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LMFLOSS: A Hybrid Loss For Imbalanced Medical Image Classification
Dec 24, 2022
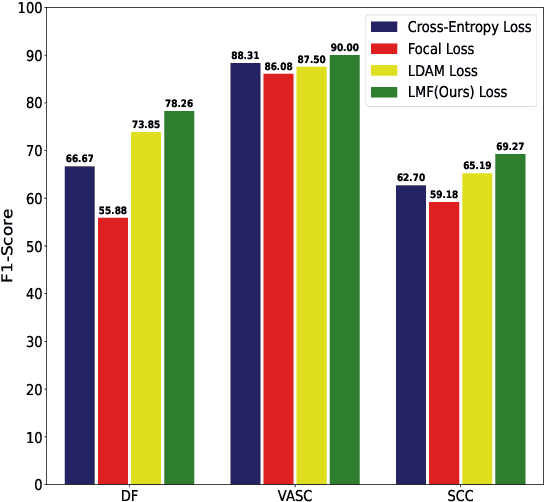


Automatic medical image classification is a very important field where the use of AI has the potential to have a real social impact. However, there are still many challenges that act as obstacles to making practically effective solutions. One of those is the fact that most of the medical imaging datasets have a class imbalance problem. This leads to the fact that existing AI techniques, particularly neural network-based deep-learning methodologies, often perform poorly in such scenarios. Thus this makes this area an interesting and active research focus for researchers. In this study, we propose a novel loss function to train neural network models to mitigate this critical issue in this important field. Through rigorous experiments on three independently collected datasets of three different medical imaging domains, we empirically show that our proposed loss function consistently performs well with an improvement between 2%-10% macro f1 when compared to the baseline models. We hope that our work will precipitate new research toward a more generalized approach to medical image classification.
Ensuring Trustworthy Medical Artificial Intelligence through Ethical and Philosophical Principles
Apr 29, 2023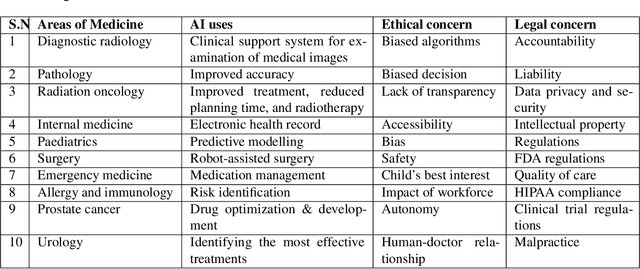
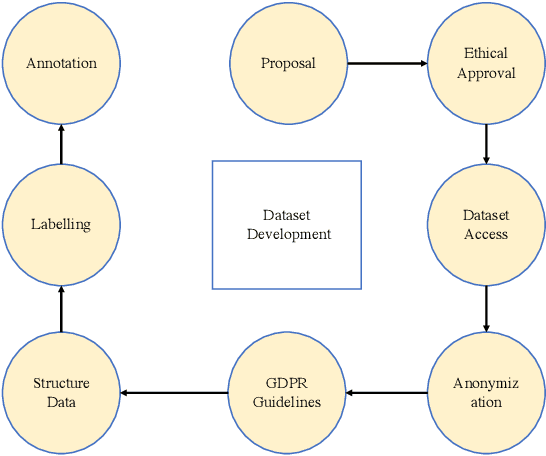

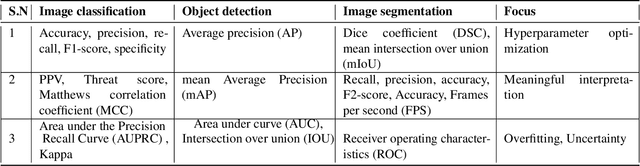
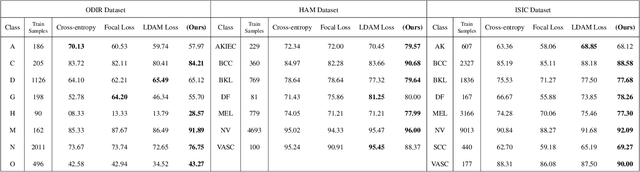
Artificial intelligence (AI) methods have great potential to revolutionize numerous medical care by enhancing the experience of medical experts and patients. AI based computer-assisted diagnosis tools can have a tremendous benefit if they can outperform or perform similarly to the level of a clinical expert. As a result, advanced healthcare services can be affordable in developing nations, and the problem of a lack of expert medical practitioners can be addressed. AI based tools can save time, resources, and overall cost for patient treatment. Furthermore, in contrast to humans, AI can uncover complex relations in the data from a large set of inputs and even lead to new evidence-based knowledge in medicine. However, integrating AI in healthcare raises several ethical and philosophical concerns, such as bias, transparency, autonomy, responsibility and accountability, which must be addressed before integrating such tools into clinical settings. In this article, we emphasize recent advances in AI-assisted medical image analysis, existing standards, and the significance of comprehending ethical issues and best practices for the applications of AI in clinical settings. We cover the technical and ethical challenges of AI and the implications of deploying AI in hospitals and public organizations. We also discuss promising key measures and techniques to address the ethical challenges, data scarcity, racial bias, lack of transparency, and algorithmic bias. Finally, we provide our recommendation and future directions for addressing the ethical challenges associated with AI in healthcare applications, with the goal of deploying AI into the clinical settings to make the workflow more efficient, accurate, accessible, transparent, and reliable for the patient worldwide.
Real-Time Superficial Vein Imaging System for Observing Abnormalities on Vascular Structures
Apr 29, 2023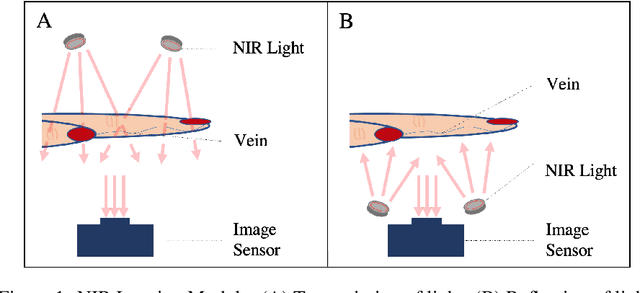
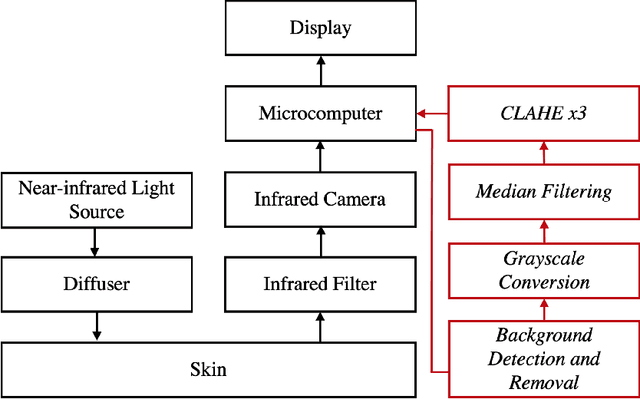

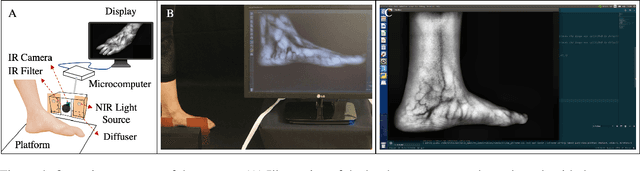
Circulatory system abnormalities might be an indicator of diseases or tissue damage. Early detection of vascular abnormalities might have an important role during treatment and also raise the patient's awarenes. Current detection methods for vascular imaging are high-cost, invasive, and mostly radiation-based. In this study, a low-cost and portable microcomputer-based tool has been developed as a near-infrared (NIR) superficial vascular imaging device. The device uses NIR light-emitting diode (LED) light at 850 nm along with other electronic and optical components. It operates as a non-contact and safe infrared (IR) imaging method in real-time. Image and video analysis are carried out using OpenCV (Open-Source Computer Vision), a library of programming functions mainly used in computer vision. Various tests were carried out to optimize the imaging system and set up a suitable external environment. To test the performance of the device, the images taken from three diabetic volunteers, who are expected to have abnormalities in the vascular structure due to the possibility of deformation caused by high glucose levels in the blood, were compared with the images taken from two non-diabetic volunteers. As a result, tortuosity was observed successfully in the superficial vascular structures, where the results need to be interpreted by the medical experts in the field to understand the underlying reasons. Although this study is an engineering study and does not have an intention to diagnose any diseases, the developed system here might assist healthcare personnel in early diagnosis and treatment follow-up for vascular structures and may enable further opportunities.
Explore the Power of Synthetic Data on Few-shot Object Detection
Mar 23, 2023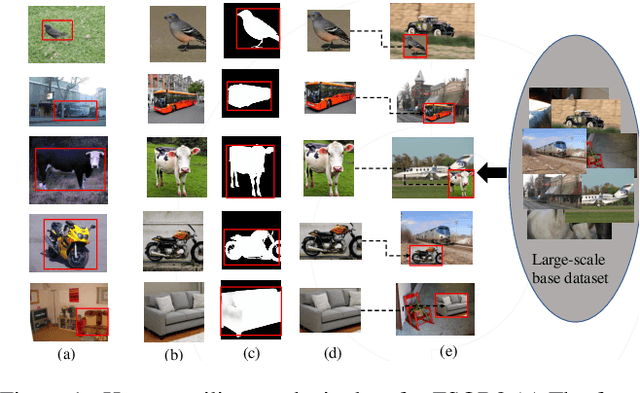
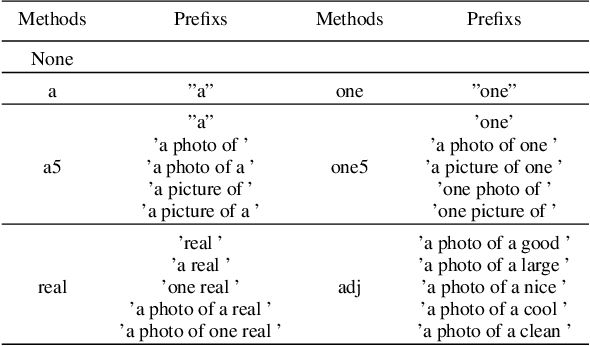
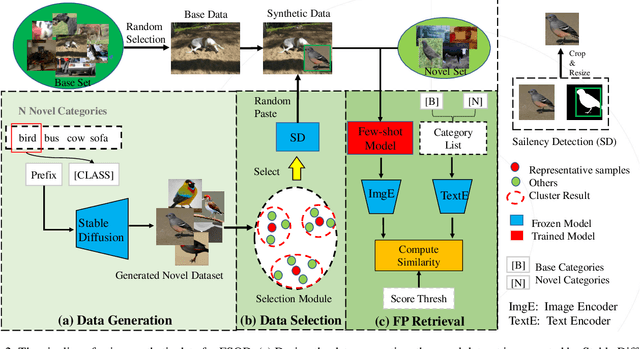
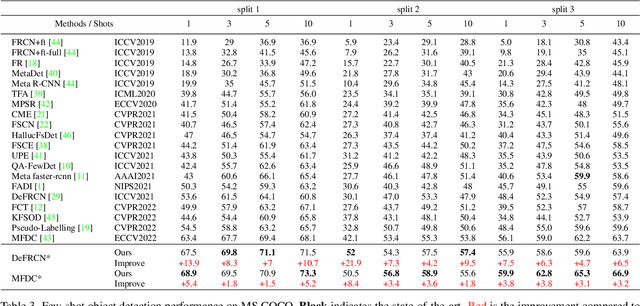
Few-shot object detection (FSOD) aims to expand an object detector for novel categories given only a few instances for training. The few training samples restrict the performance of FSOD model. Recent text-to-image generation models have shown promising results in generating high-quality images. How applicable these synthetic images are for FSOD tasks remains under-explored. This work extensively studies how synthetic images generated from state-of-the-art text-to-image generators benefit FSOD tasks. We focus on two perspectives: (1) How to use synthetic data for FSOD? (2) How to find representative samples from the large-scale synthetic dataset? We design a copy-paste-based pipeline for using synthetic data. Specifically, saliency object detection is applied to the original generated image, and the minimum enclosing box is used for cropping the main object based on the saliency map. After that, the cropped object is randomly pasted on the image, which comes from the base dataset. We also study the influence of the input text of text-to-image generator and the number of synthetic images used. To construct a representative synthetic training dataset, we maximize the diversity of the selected images via a sample-based and cluster-based method. However, the severe problem of high false positives (FP) ratio of novel categories in FSOD can not be solved by using synthetic data. We propose integrating CLIP, a zero-shot recognition model, into the FSOD pipeline, which can filter 90% of FP by defining a threshold for the similarity score between the detected object and the text of the predicted category. Extensive experiments on PASCAL VOC and MS COCO validate the effectiveness of our method, in which performance gain is up to 21.9% compared to the few-shot baseline.
MaLP: Manipulation Localization Using a Proactive Scheme
Apr 04, 2023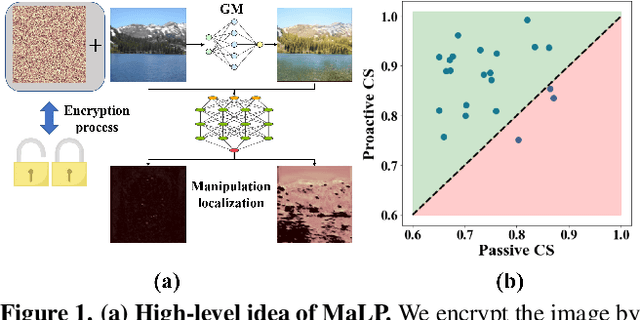
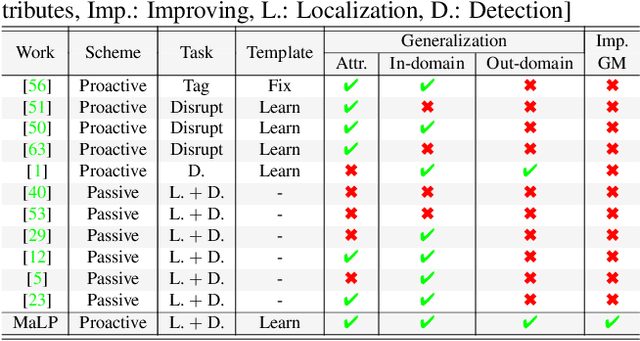
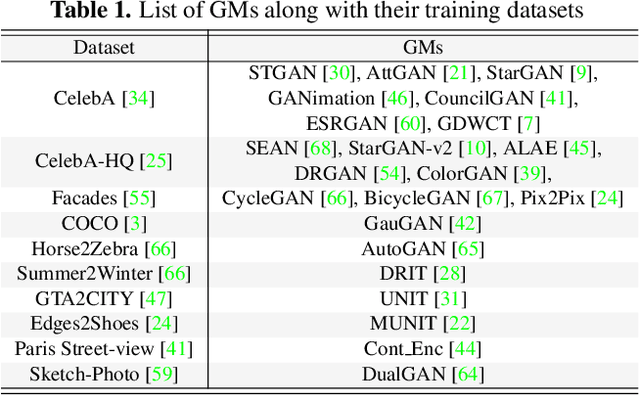
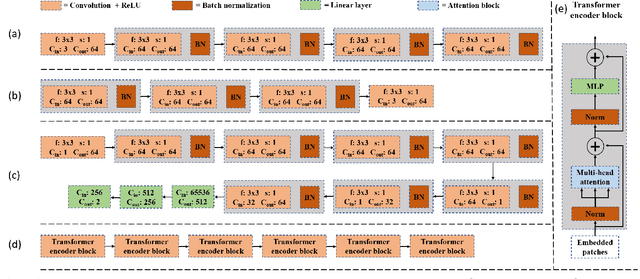
Advancements in the generation quality of various Generative Models (GMs) has made it necessary to not only perform binary manipulation detection but also localize the modified pixels in an image. However, prior works termed as passive for manipulation localization exhibit poor generalization performance over unseen GMs and attribute modifications. To combat this issue, we propose a proactive scheme for manipulation localization, termed MaLP. We encrypt the real images by adding a learned template. If the image is manipulated by any GM, this added protection from the template not only aids binary detection but also helps in identifying the pixels modified by the GM. The template is learned by leveraging local and global-level features estimated by a two-branch architecture. We show that MaLP performs better than prior passive works. We also show the generalizability of MaLP by testing on 22 different GMs, providing a benchmark for future research on manipulation localization. Finally, we show that MaLP can be used as a discriminator for improving the generation quality of GMs. Our models/codes are available at www.github.com/vishal3477/pro_loc.
OrienterNet: Visual Localization in 2D Public Maps with Neural Matching
Apr 04, 2023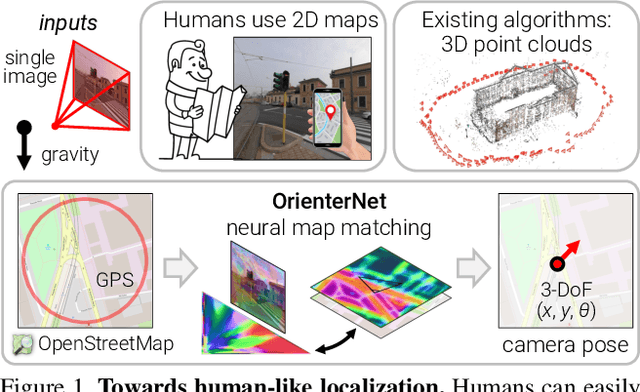
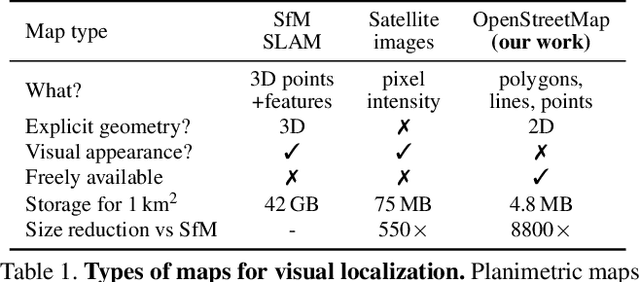
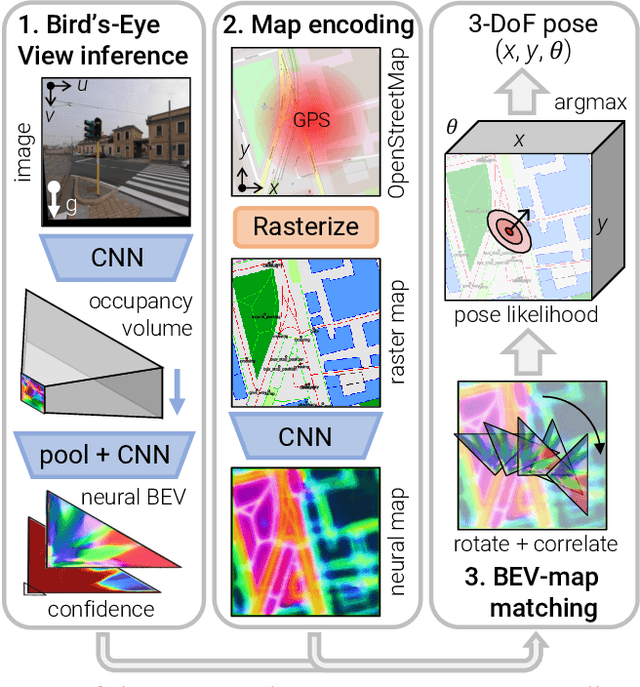
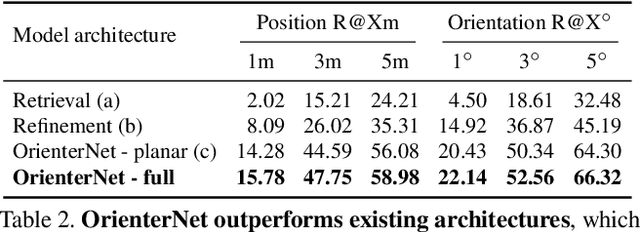
Humans can orient themselves in their 3D environments using simple 2D maps. Differently, algorithms for visual localization mostly rely on complex 3D point clouds that are expensive to build, store, and maintain over time. We bridge this gap by introducing OrienterNet, the first deep neural network that can localize an image with sub-meter accuracy using the same 2D semantic maps that humans use. OrienterNet estimates the location and orientation of a query image by matching a neural Bird's-Eye View with open and globally available maps from OpenStreetMap, enabling anyone to localize anywhere such maps are available. OrienterNet is supervised only by camera poses but learns to perform semantic matching with a wide range of map elements in an end-to-end manner. To enable this, we introduce a large crowd-sourced dataset of images captured across 12 cities from the diverse viewpoints of cars, bikes, and pedestrians. OrienterNet generalizes to new datasets and pushes the state of the art in both robotics and AR scenarios. The code and trained model will be released publicly.
Towards Nonlinear-Motion-Aware and Occlusion-Robust Rolling Shutter Correction
Apr 04, 2023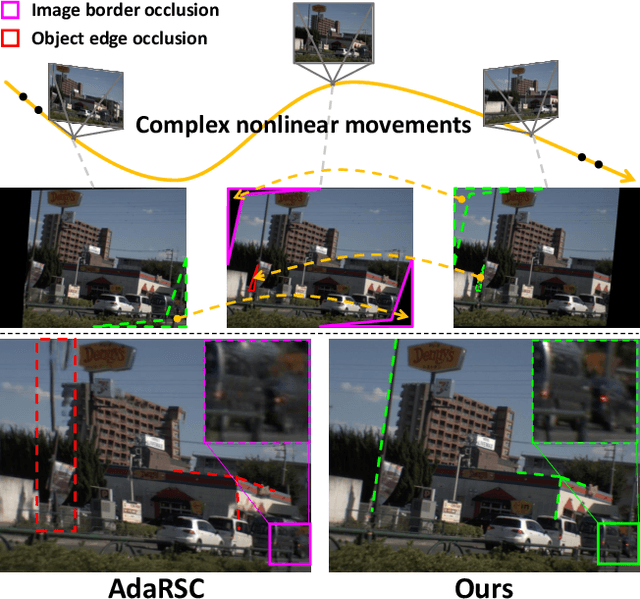
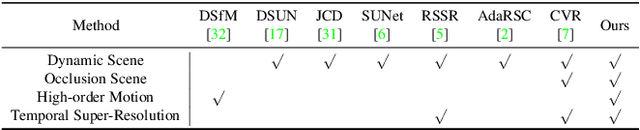
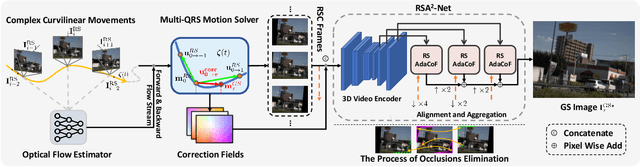
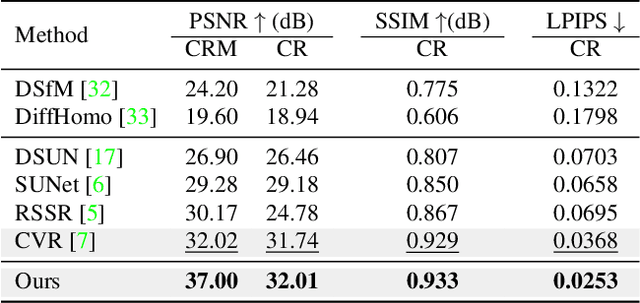
This paper addresses the problem of rolling shutter correction in complex nonlinear and dynamic scenes with extreme occlusion. Existing methods suffer from two main drawbacks. Firstly, they face challenges in estimating the accurate correction field due to the uniform velocity assumption, leading to significant image correction errors under complex motion. Secondly, the drastic occlusion in dynamic scenes prevents current solutions from achieving better image quality because of the inherent difficulties in aligning and aggregating multiple frames. To tackle these challenges, we model the curvilinear trajectory of pixels analytically and propose a geometry-based Quadratic Rolling Shutter (QRS) motion solver, which precisely estimates the high-order correction field of individual pixel. Besides, to reconstruct high-quality occlusion frames in dynamic scenes, we present a 3D video architecture that effectively Aligns and Aggregates multi-frame context, namely, RSA^2-Net. We evaluate our method across a broad range of cameras and video sequences, demonstrating its significant superiority. Specifically, our method surpasses the state-of-the-arts by +4.98, +0.77, and +4.33 of PSNR on Carla-RS, Fastec-RS, and BS-RSC datasets, respectively.
On the Opportunities and Challenges of Foundation Models for Geospatial Artificial Intelligence
Apr 13, 2023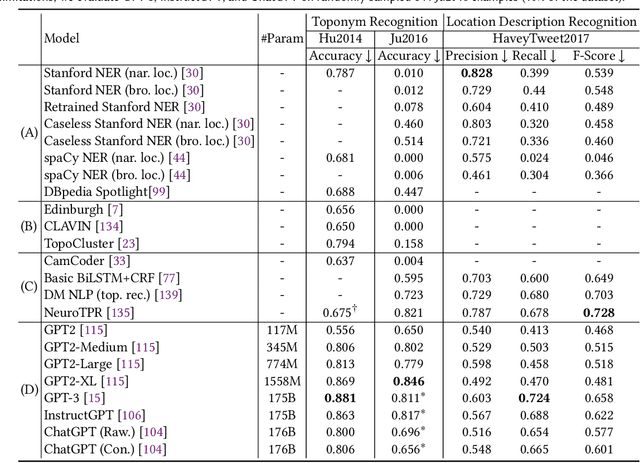
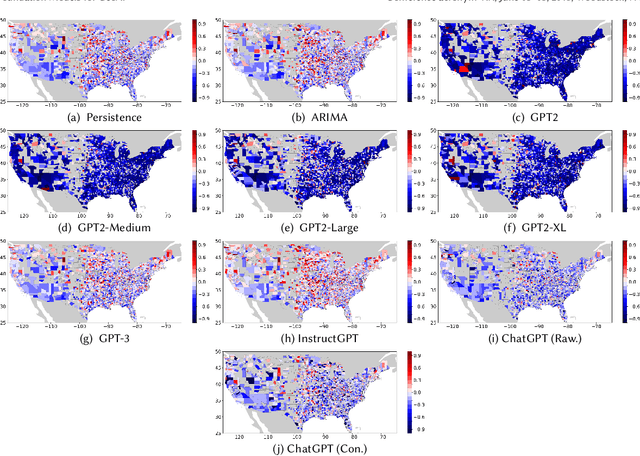
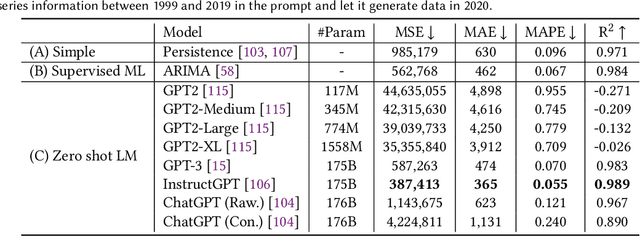
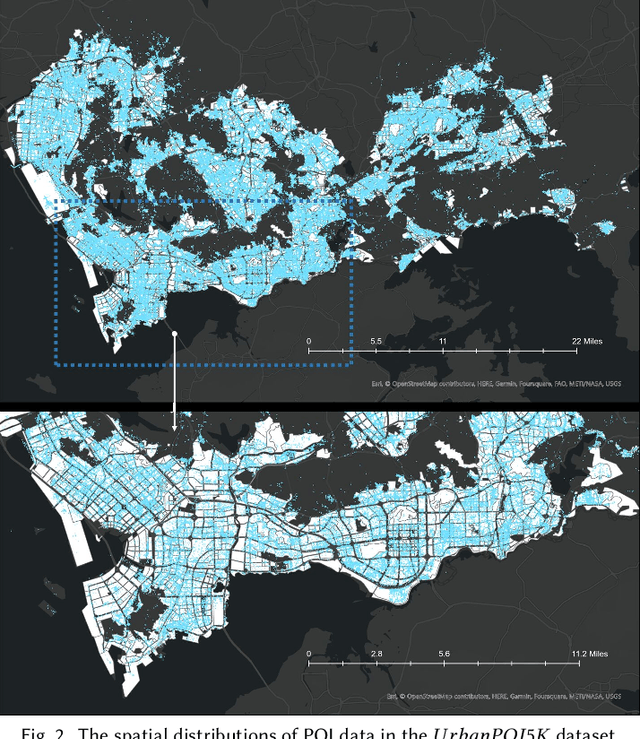
Large pre-trained models, also known as foundation models (FMs), are trained in a task-agnostic manner on large-scale data and can be adapted to a wide range of downstream tasks by fine-tuning, few-shot, or even zero-shot learning. Despite their successes in language and vision tasks, we have yet seen an attempt to develop foundation models for geospatial artificial intelligence (GeoAI). In this work, we explore the promises and challenges of developing multimodal foundation models for GeoAI. We first investigate the potential of many existing FMs by testing their performances on seven tasks across multiple geospatial subdomains including Geospatial Semantics, Health Geography, Urban Geography, and Remote Sensing. Our results indicate that on several geospatial tasks that only involve text modality such as toponym recognition, location description recognition, and US state-level/county-level dementia time series forecasting, these task-agnostic LLMs can outperform task-specific fully-supervised models in a zero-shot or few-shot learning setting. However, on other geospatial tasks, especially tasks that involve multiple data modalities (e.g., POI-based urban function classification, street view image-based urban noise intensity classification, and remote sensing image scene classification), existing foundation models still underperform task-specific models. Based on these observations, we propose that one of the major challenges of developing a FM for GeoAI is to address the multimodality nature of geospatial tasks. After discussing the distinct challenges of each geospatial data modality, we suggest the possibility of a multimodal foundation model which can reason over various types of geospatial data through geospatial alignments. We conclude this paper by discussing the unique risks and challenges to develop such a model for GeoAI.
Identity-driven Three-Player Generative Adversarial Network for Synthetic-based Face Recognition
Apr 30, 2023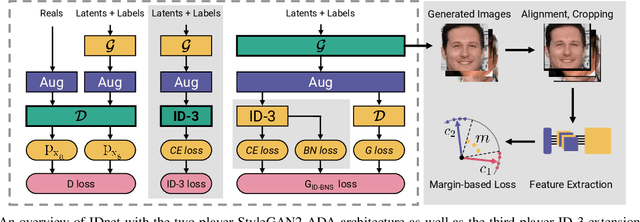
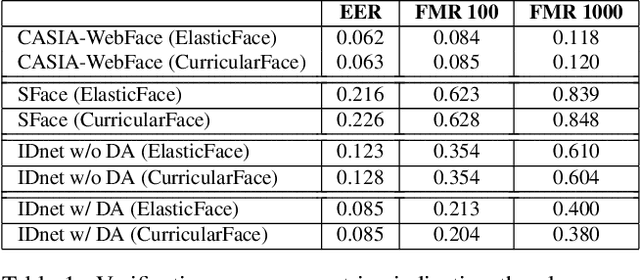

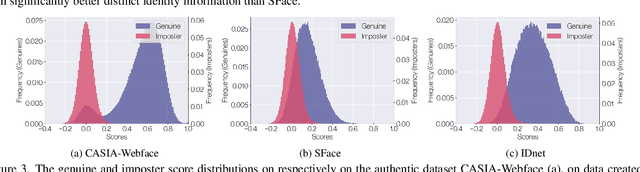
Many of the commonly used datasets for face recognition development are collected from the internet without proper user consent. Due to the increasing focus on privacy in the social and legal frameworks, the use and distribution of these datasets are being restricted and strongly questioned. These databases, which have a realistically high variability of data per identity, have enabled the success of face recognition models. To build on this success and to align with privacy concerns, synthetic databases, consisting purely of synthetic persons, are increasingly being created and used in the development of face recognition solutions. In this work, we present a three-player generative adversarial network (GAN) framework, namely IDnet, that enables the integration of identity information into the generation process. The third player in our IDnet aims at forcing the generator to learn to generate identity-separable face images. We empirically proved that our IDnet synthetic images are of higher identity discrimination in comparison to the conventional two-player GAN, while maintaining a realistic intra-identity variation. We further studied the identity link between the authentic identities used to train the generator and the generated synthetic identities, showing very low similarities between these identities. We demonstrated the applicability of our IDnet data in training face recognition models by evaluating these models on a wide set of face recognition benchmarks. In comparison to the state-of-the-art works in synthetic-based face recognition, our solution achieved comparable results to a recent rendering-based approach and outperformed all existing GAN-based approaches. The training code and the synthetic face image dataset are publicly available ( https://github.com/fdbtrs/Synthetic-Face-Recognition ).
Deep Learning based Multi-Label Image Classification of Protest Activities
Jan 10, 2023


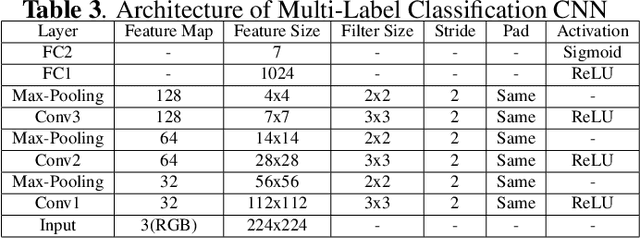
With the rise of internet technology amidst increasing rates of urbanization, sharing information has never been easier thanks to globally-adopted platforms for digital communication. The resulting output of massive amounts of user-generated data can be used to enhance our understanding of significant societal issues particularly for urbanizing areas. In order to better analyze protest behavior, we enhanced the GSR dataset and manually labeled all the images. We used deep learning techniques to analyze social media data to detect social unrest through image classification, which performed good in predict multi-attributes, then also used map visualization to display protest behaviors across the country.