 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NASDM: Nuclei-Aware Semantic Histopathology Image Generation Using Diffusion Models
Mar 20, 2023
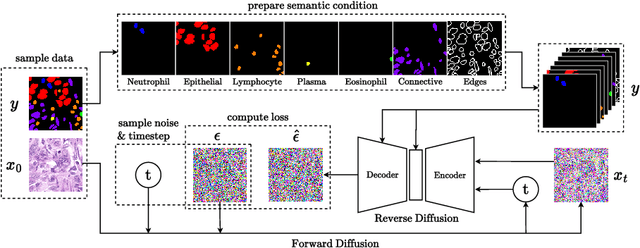

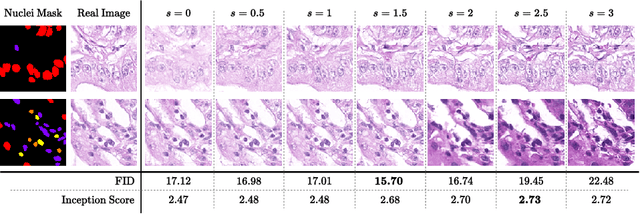
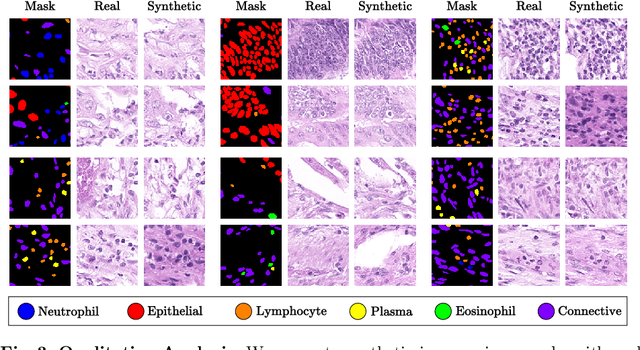
In recent years, computational pathology has seen tremendous progress driven by deep learning methods in segmentation and classification tasks aiding prognostic and diagnostic settings. Nuclei segmentation, for instance, is an important task for diagnosing different cancers. However, training deep learning models for nuclei segmentation requires large amounts of annotated data, which is expensive to collect and label. This necessitates explorations into generative modeling of histopathological images. In this work, we use recent advances in conditional diffusion modeling to formulate a first-of-its-kind nuclei-aware semantic tissue generation framework (NASDM) which can synthesize realistic tissue samples given a semantic instance mask of up to six different nuclei types, enabling pixel-perfect nuclei localization in generated samples. These synthetic images are useful in applications in pathology pedagogy, validation of models, and supplementation of existing nuclei segmentation datasets. We demonstrate that NASDM is able to synthesize high-quality histopathology images of the colon with superior quality and semantic controllability over existing generative methods.
Few Shot Semantic Segmentation: a review of methodologies and open challenges
Apr 12, 2023
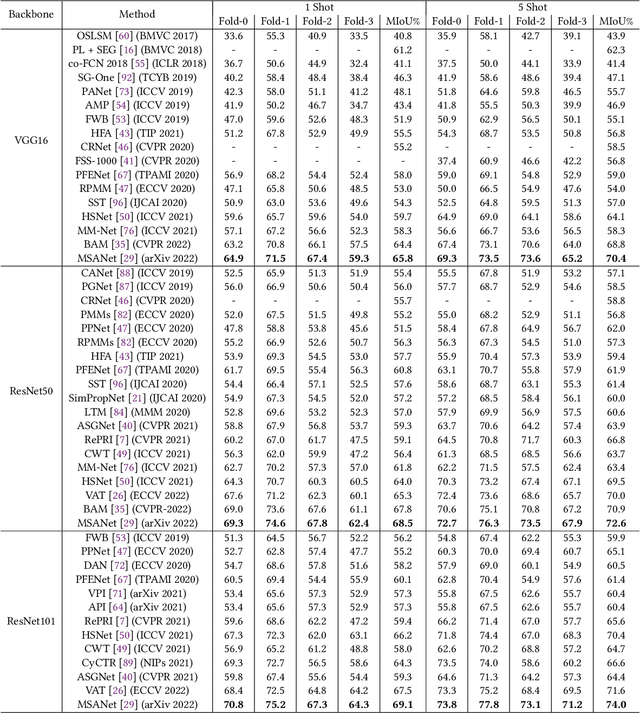
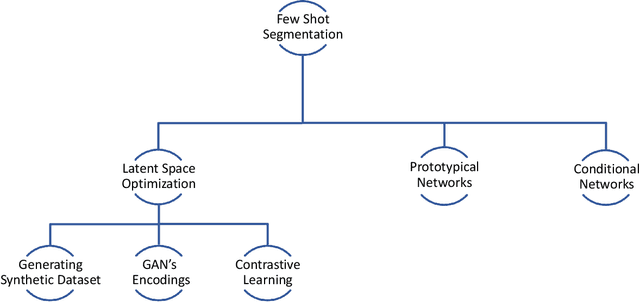
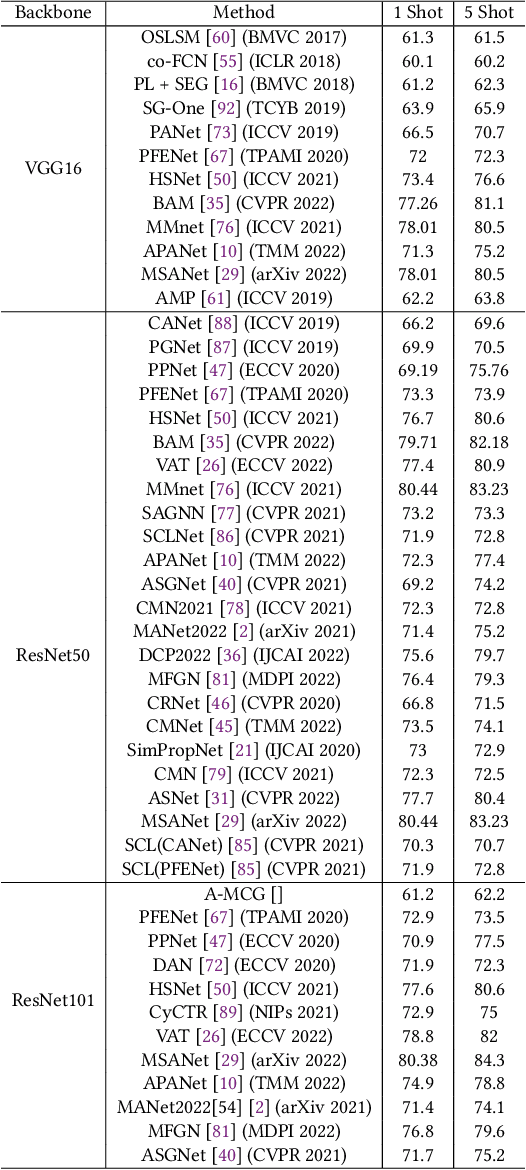
Semantic segmentation assigns category labels to each pixel in an image, enabling breakthroughs in fields such as autonomous driving and robotics. Deep Neural Networks have achieved high accuracies in semantic segmentation but require large training datasets. Some domains have difficulties building such datasets due to rarity, privacy concerns, and the need for skilled annotators. Few-Shot Learning (FSL) has emerged as a new research stream that allows models to learn new tasks from a few samples. This contribution provides an overview of FSL in semantic segmentation (FSS), proposes a new taxonomy, and describes current limitations and outlooks.
Assessing Bias in Face Image Quality Assessment
Nov 28, 2022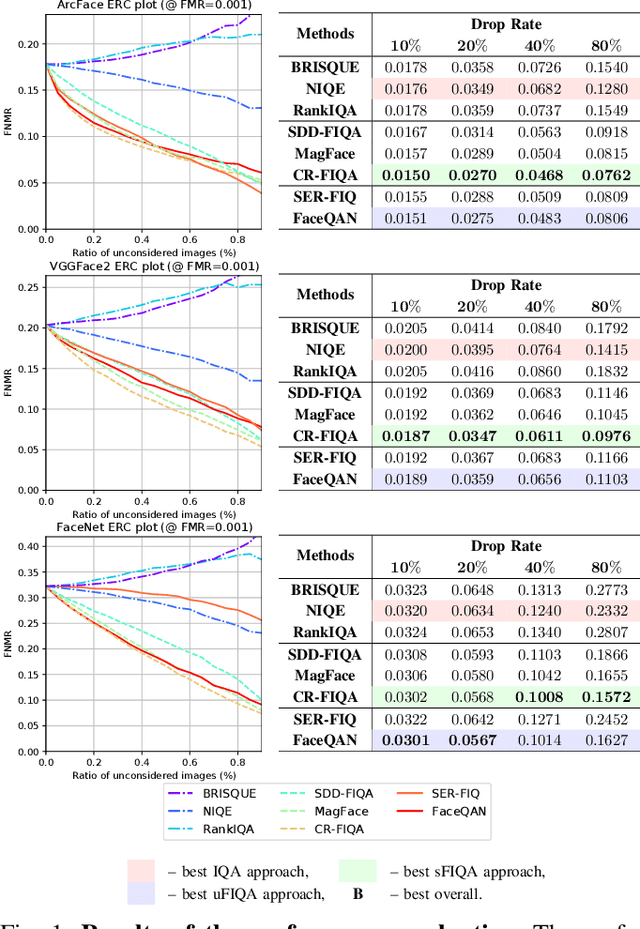

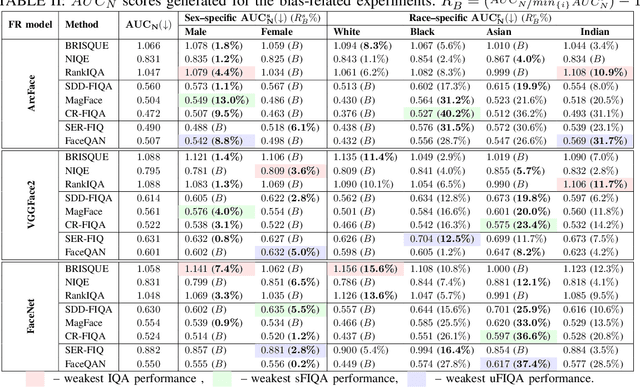
Face image quality assessment (FIQA) attempts to improve face recognition (FR) performance by providing additional information about sample quality. Because FIQA methods attempt to estimate the utility of a sample for face recognition, it is reasonable to assume that these methods are heavily influenced by the underlying face recognition system. Although modern face recognition systems are known to perform well, several studies have found that such systems often exhibit problems with demographic bias. It is therefore likely that such problems are also present with FIQA techniques. To investigate the demographic biases associated with FIQA approaches, this paper presents a comprehensive study involving a variety of quality assessment methods (general-purpose image quality assessment, supervised face quality assessment, and unsupervised face quality assessment methods) and three diverse state-of-theart FR models. Our analysis on the Balanced Faces in the Wild (BFW) dataset shows that all techniques considered are affected more by variations in race than sex. While the general-purpose image quality assessment methods appear to be less biased with respect to the two demographic factors considered, the supervised and unsupervised face image quality assessment methods both show strong bias with a tendency to favor white individuals (of either sex). In addition, we found that methods that are less racially biased perform worse overall. This suggests that the observed bias in FIQA methods is to a significant extent related to the underlying face recognition system.
Application of Segment Anything Model for Civil Infrastructure Defect Assessment
Apr 25, 2023
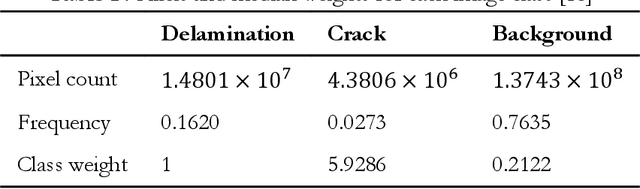

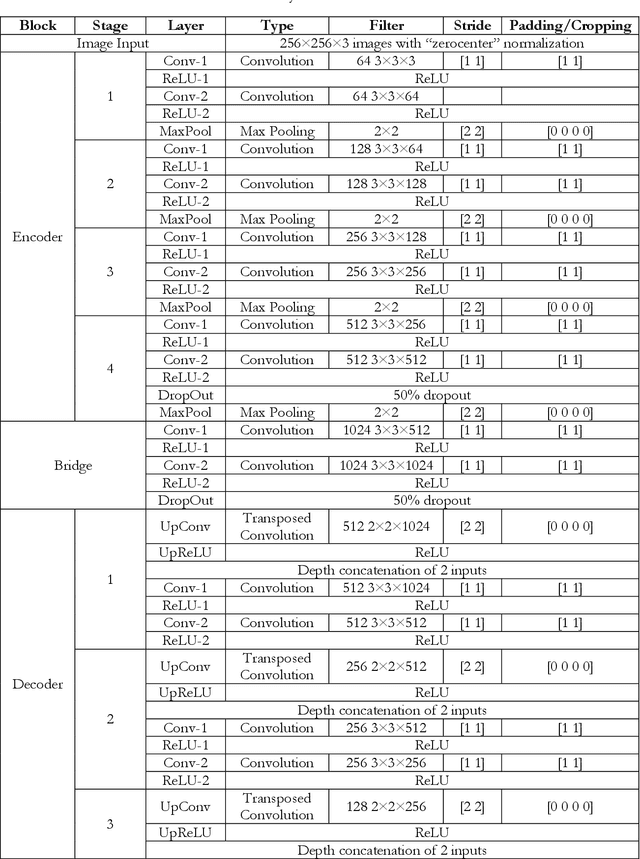
This research assesses the performance of two deep learning models, SAM and U-Net, for detecting cracks in concrete structures. The results indicate that each model has its own strengths and limitations for detecting different types of cracks. Using the SAM's unique crack detection approach, the image is divided into various parts that identify the location of the crack, making it more effective at detecting longitudinal cracks. On the other hand, the U-Net model can identify positive label pixels to accurately detect the size and location of spalling cracks. By combining both models, more accurate and comprehensive crack detection results can be achieved. The importance of using advanced technologies for crack detection in ensuring the safety and longevity of concrete structures cannot be overstated. This research can have significant implications for civil engineering, as the SAM and U-Net model can be used for a variety of concrete structures, including bridges, buildings, and roads, improving the accuracy and efficiency of crack detection and saving time and resources in maintenance and repair. In conclusion, the SAM and U-Net model presented in this study offer promising solutions for detecting cracks in concrete structures and leveraging the strengths of both models that can lead to more accurate and comprehensive results.
CompletionFormer: Depth Completion with Convolutions and Vision Transformers
Apr 25, 2023

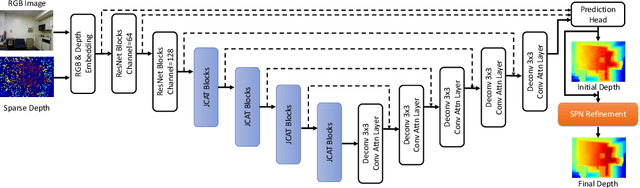
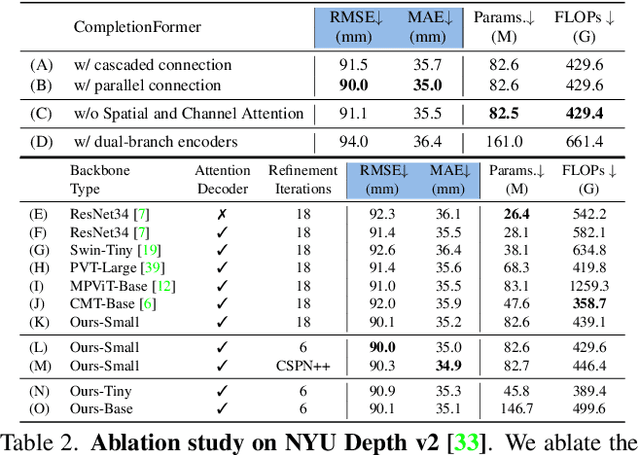
Given sparse depths and the corresponding RGB images, depth completion aims at spatially propagating the sparse measurements throughout the whole image to get a dense depth prediction. Despite the tremendous progress of deep-learning-based depth completion methods, the locality of the convolutional layer or graph model makes it hard for the network to model the long-range relationship between pixels. While recent fully Transformer-based architecture has reported encouraging results with the global receptive field, the performance and efficiency gaps to the well-developed CNN models still exist because of its deteriorative local feature details. This paper proposes a Joint Convolutional Attention and Transformer block (JCAT), which deeply couples the convolutional attention layer and Vision Transformer into one block, as the basic unit to construct our depth completion model in a pyramidal structure. This hybrid architecture naturally benefits both the local connectivity of convolutions and the global context of the Transformer in one single model. As a result, our CompletionFormer outperforms state-of-the-art CNNs-based methods on the outdoor KITTI Depth Completion benchmark and indoor NYUv2 dataset, achieving significantly higher efficiency (nearly 1/3 FLOPs) compared to pure Transformer-based methods. Code is available at \url{https://github.com/youmi-zym/CompletionFormer}.
Learning imaging mechanism directly from optical microscopy observations
Apr 25, 2023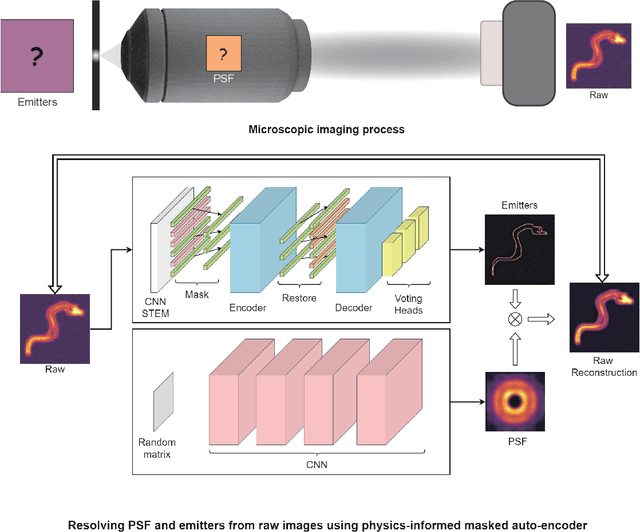
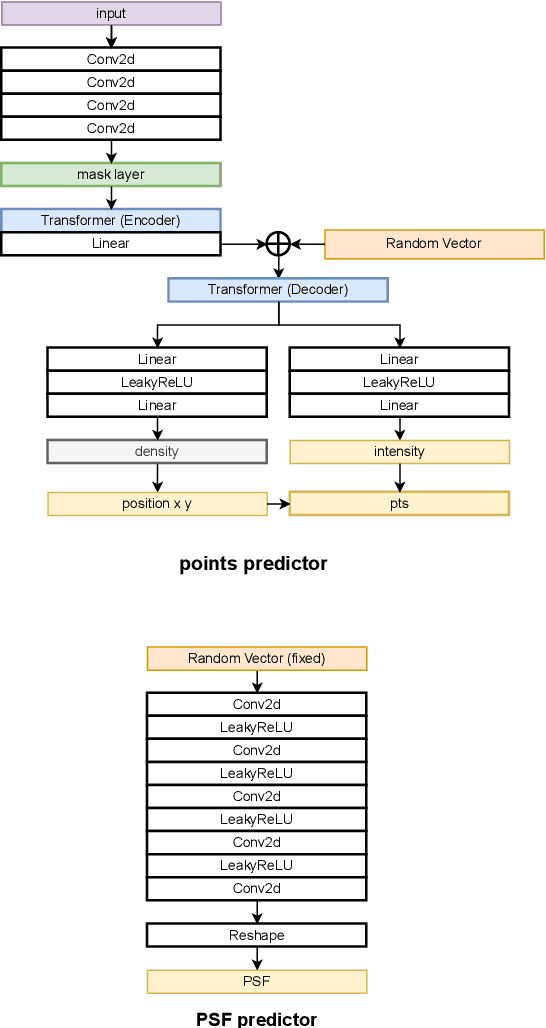
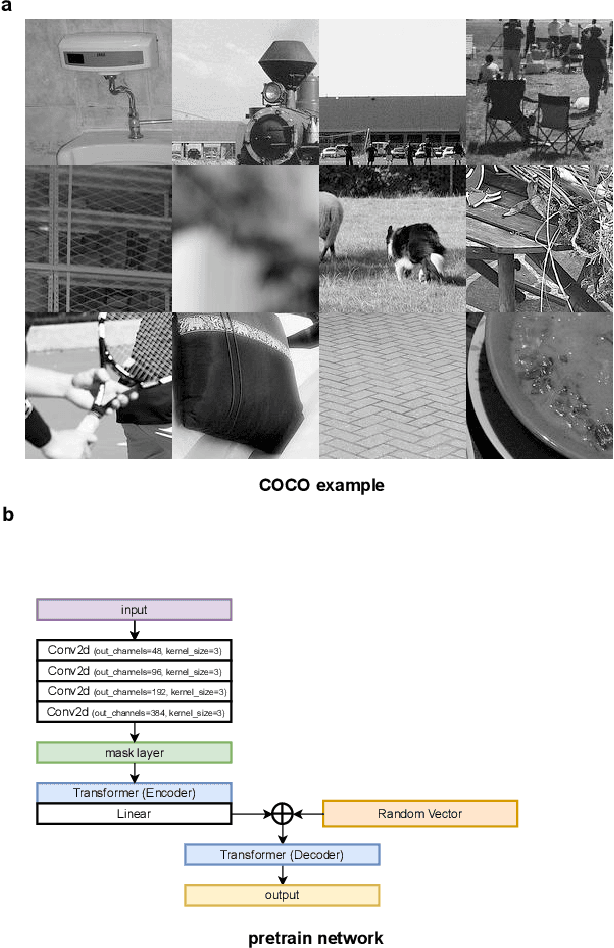

Optical microscopy image plays an important role in scientific research through the direct visualization of the nanoworld, where the imaging mechanism is described as the convolution of the point spread function (PSF) and emitters. Based on a priori knowledge of the PSF or equivalent PSF, it is possible to achieve more precise exploration of the nanoworld. However, it is an outstanding challenge to directly extract the PSF from microscopy images. Here, with the help of self-supervised learning, we propose a physics-informed masked autoencoder (PiMAE) that enables a learnable estimation of the PSF and emitters directly from the raw microscopy images. We demonstrate our method in synthetic data and real-world experiments with significant accuracy and noise robustness. PiMAE outperforms DeepSTORM and the Richardson-Lucy algorithm in synthetic data tasks with an average improvement of 19.6\% and 50.7\% (35 tasks), respectively, as measured by the normalized root mean square error (NRMSE) metric. This is achieved without prior knowledge of the PSF, in contrast to the supervised approach used by DeepSTORM and the known PSF assumption in the Richardson-Lucy algorithm. Our method, PiMAE, provides a feasible scheme for achieving the hidden imaging mechanism in optical microscopy and has the potential to learn hidden mechanisms in many more systems.
Generalist Vision Foundation Models for Medical Imaging: A Case Study of Segment Anything Model on Zero-Shot Medical Segmentation
Apr 25, 2023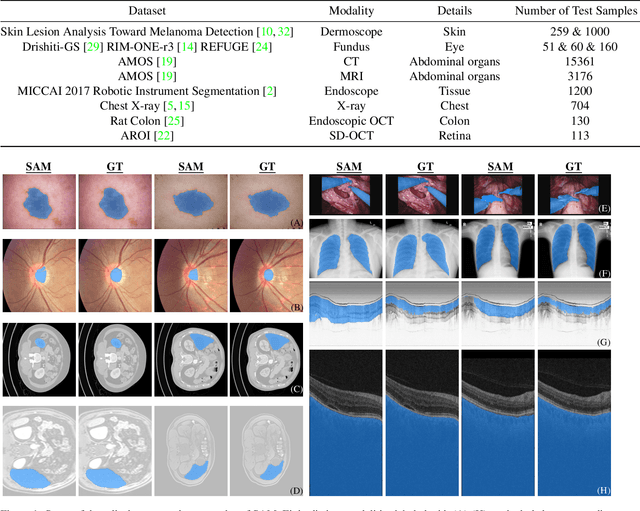
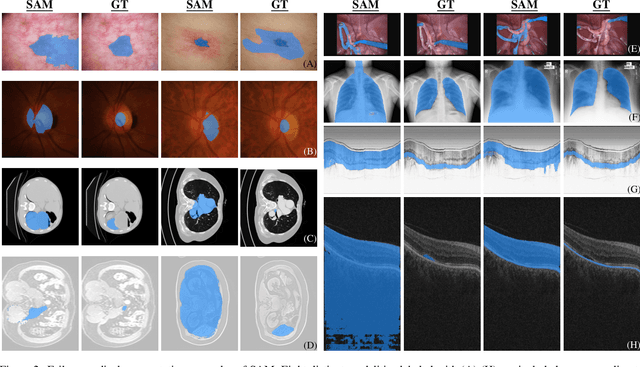
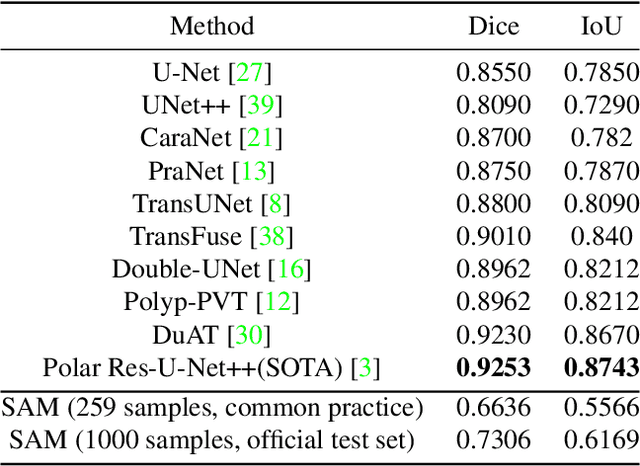
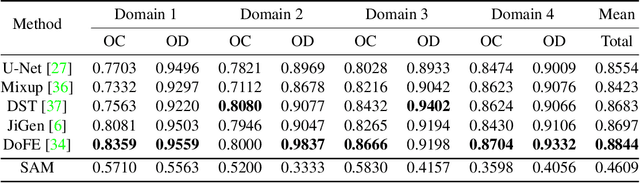
We examine the recent Segment Anything Model (SAM) on medical images, and report both quantitative and qualitative zero-shot segmentation results on nine medical image segmentation benchmarks, covering various imaging modalities, such as optical coherence tomography (OCT), magnetic resonance imaging (MRI), and computed tomography (CT), as well as different applications including dermatology, ophthalmology, and radiology. Our experiments reveal that while SAM demonstrates stunning segmentation performance on images from the general domain, for those out-of-distribution images, e.g., medical images, its zero-shot segmentation performance is still limited. Furthermore, SAM demonstrated varying zero-shot segmentation performance across different unseen medical domains. For example, it had a 0.8704 mean Dice score on segmenting under-bruch's membrane layer of retinal OCT, whereas the segmentation accuracy drops to 0.0688 when segmenting retinal pigment epithelium. For certain structured targets, e.g., blood vessels, the zero-shot segmentation of SAM completely failed, whereas a simple fine-tuning of it with small amount of data could lead to remarkable improvements of the segmentation quality. Our study indicates the versatility of generalist vision foundation models on solving specific tasks in medical imaging, and their great potential to achieve desired performance through fine-turning and eventually tackle the challenges of accessing large diverse medical datasets and the complexity of medical domains.
Segment anything, from space?
Apr 25, 2023
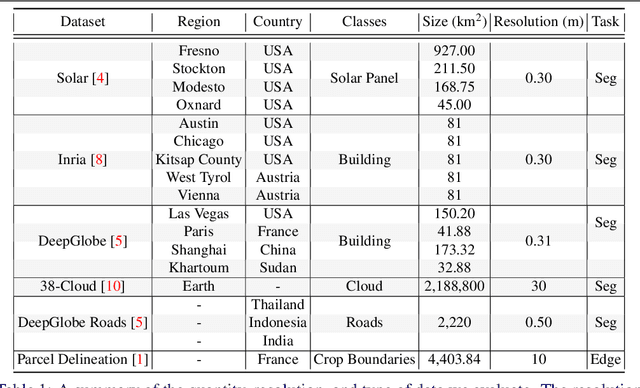
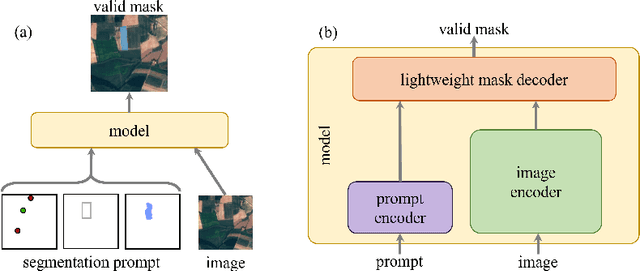
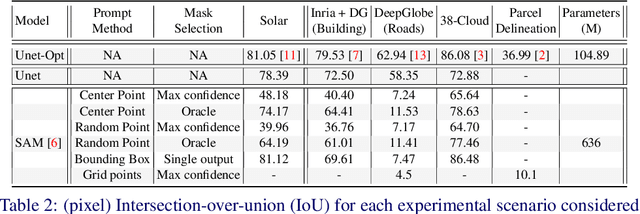
Recently, the first foundation model developed specifically for vision tasks was developed, termed the "Segment Anything Model" (SAM). SAM can segment objects in input imagery based upon cheap input prompts, such as one (or more) points, a bounding box, or a mask. The authors examined the zero-shot image segmentation accuracy of SAM on a large number of vision benchmark tasks and found that SAM usually achieved recognition accuracy similar to, or sometimes exceeding, vision models that had been trained on the target tasks. The impressive generalization of SAM for segmentation has major implications for vision researchers working on natural imagery. In this work, we examine whether SAM's impressive performance extends to overhead imagery problems, and help guide the community's response to its development. We examine SAM's performance on a set of diverse and widely-studied benchmark tasks. We find that SAM does often generalize well to overhead imagery, although it fails in some cases due to the unique characteristics of overhead imagery and the target objects. We report on these unique systematic failure cases for remote sensing imagery that may comprise useful future research for the community. Note that this is a working paper, and it will be updated as additional analysis and results are completed.
Dream3D: Zero-Shot Text-to-3D Synthesis Using 3D Shape Prior and Text-to-Image Diffusion Models
Dec 28, 2022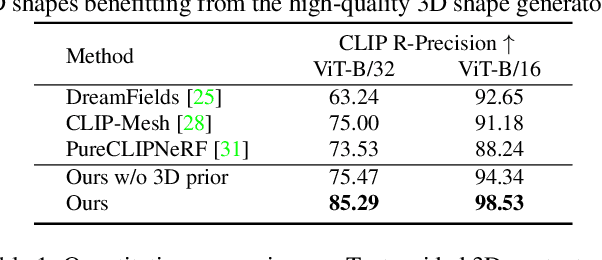
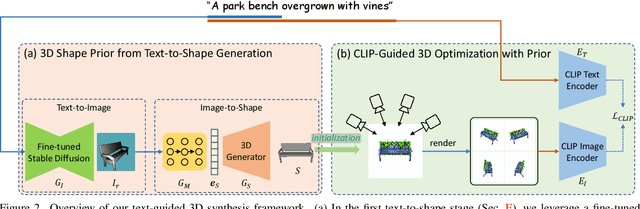

Recent CLIP-guided 3D optimization methods, e.g., DreamFields and PureCLIPNeRF achieve great success in zero-shot text-guided 3D synthesis. However, due to the scratch training and random initialization without any prior knowledge, these methods usually fail to generate accurate and faithful 3D structures that conform to the corresponding text. In this paper, we make the first attempt to introduce the explicit 3D shape prior to CLIP-guided 3D optimization methods. Specifically, we first generate a high-quality 3D shape from input texts in the text-to-shape stage as the 3D shape prior. We then utilize it as the initialization of a neural radiance field and then optimize it with the full prompt. For the text-to-shape generation, we present a simple yet effective approach that directly bridges the text and image modalities with a powerful text-to-image diffusion model. To narrow the style domain gap between images synthesized by the text-to-image model and shape renderings used to train the image-to-shape generator, we further propose to jointly optimize a learnable text prompt and fine-tune the text-to-image diffusion model for rendering-style image generation. Our method, namely, Dream3D, is capable of generating imaginative 3D content with better visual quality and shape accuracy than state-of-the-art methods.
Blind Inpainting with Object-aware Discrimination for Artificial Marker Removal
Mar 27, 2023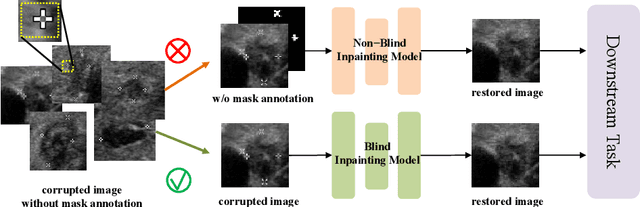
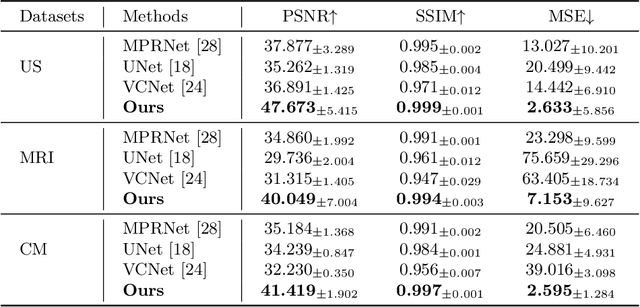
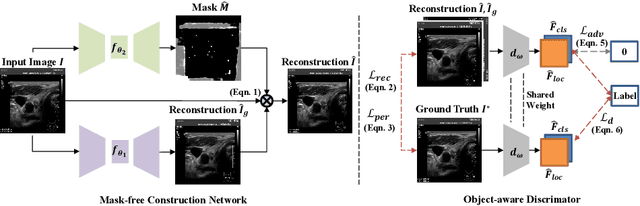
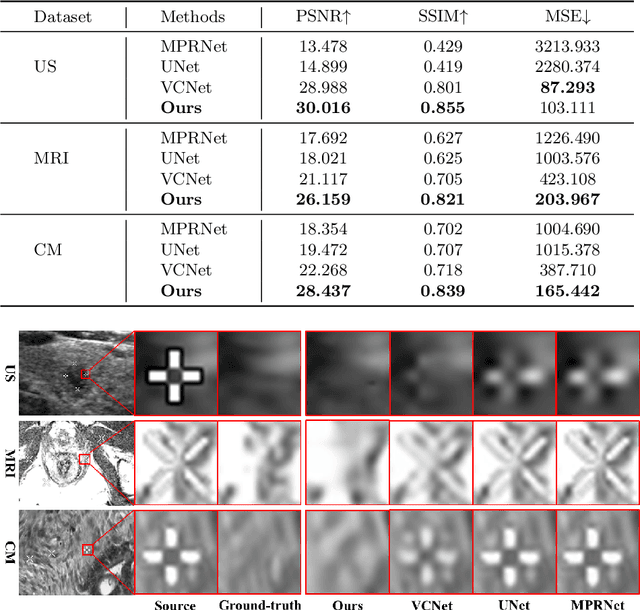
Medical images often contain artificial markers added by doctors, which can negatively affect the accuracy of AI-based diagnosis. To address this issue and recover the missing visual contents, inpainting techniques are highly needed. However, existing inpainting methods require manual mask input, limiting their application scenarios. In this paper, we introduce a novel blind inpainting method that automatically completes visual contents without specifying masks for target areas in an image. Our proposed model includes a mask-free reconstruction network and an object-aware discriminator. The reconstruction network consists of two branches that predict the corrupted regions with artificial markers and simultaneously recover the missing visual contents. The object-aware discriminator relies on the powerful recognition capabilities of the dense object detector to ensure that the markers of reconstructed images cannot be detected in any local regions. As a result, the reconstructed image can be close to the clean one as much as possible. Our proposed method is evaluated on different medical image datasets, covering multiple imaging modalities such as ultrasound (US), magnetic resonance imaging (MRI), and electron microscopy (EM), demonstrating that our method is effective and robust against various unknown missing region patterns.