 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
STNet: Spatial and Temporal feature fusion network for change detection in remote sensing images
Apr 22, 2023

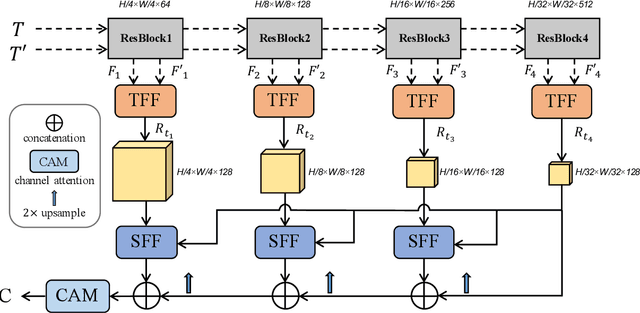
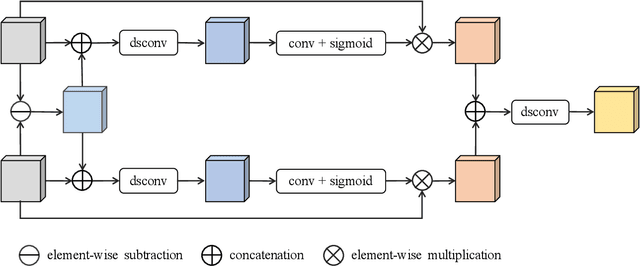
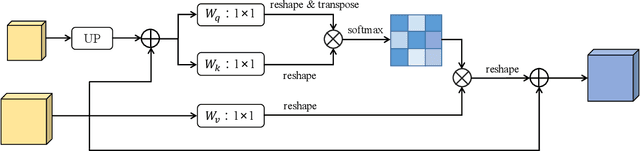
As an important task in remote sensing image analysis, remote sensing change detection (RSCD) aims to identify changes of interest in a region from spatially co-registered multi-temporal remote sensing images, so as to monitor the local development. Existing RSCD methods usually formulate RSCD as a binary classification task, representing changes of interest by merely feature concatenation or feature subtraction and recovering the spatial details via densely connected change representations, whose performances need further improvement. In this paper, we propose STNet, a RSCD network based on spatial and temporal feature fusions. Specifically, we design a temporal feature fusion (TFF) module to combine bi-temporal features using a cross-temporal gating mechanism for emphasizing changes of interest; a spatial feature fusion module is deployed to capture fine-grained information using a cross-scale attention mechanism for recovering the spatial details of change representations. Experimental results on three benchmark datasets for RSCD demonstrate that the proposed method achieves the state-of-the-art performance. Code is available at https://github.com/xwmaxwma/rschange.
CornerFormer: Boosting Corner Representation for Fine-Grained Structured Reconstruction
Apr 22, 2023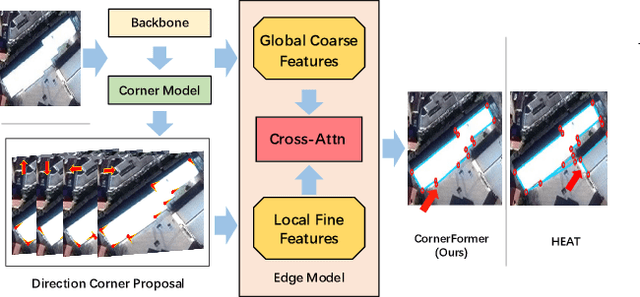
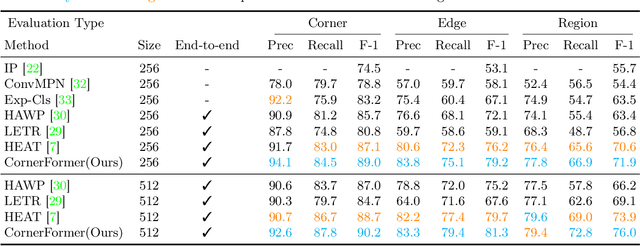
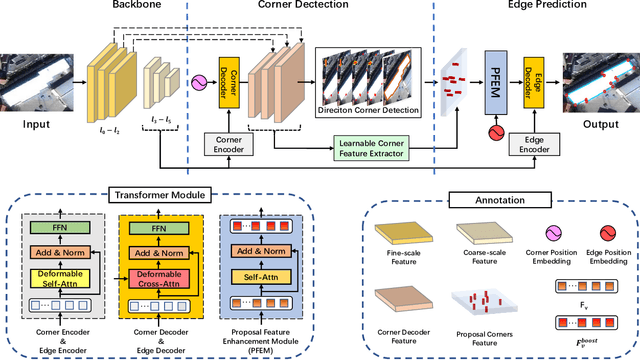
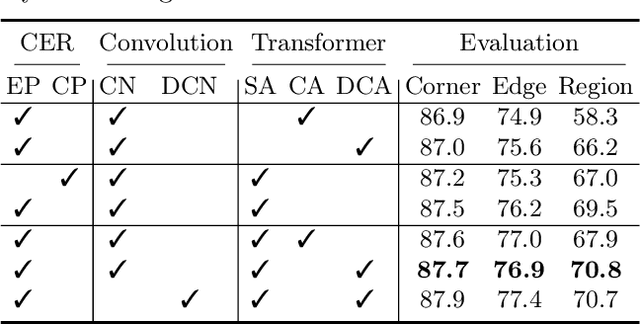
Structured reconstruction is a non-trivial dense prediction problem, which extracts structural information (\eg, building corners and edges) from a raster image, then reconstructs it to a 2D planar graph accordingly. Compared with common segmentation or detection problems, it significantly relays on the capability that leveraging holistic geometric information for structural reasoning. Current transformer-based approaches tackle this challenging problem in a two-stage manner, which detect corners in the first model and classify the proposed edges (corner-pairs) in the second model. However, they separate two-stage into different models and only share the backbone encoder. Unlike the existing modeling strategies, we present an enhanced corner representation method: 1) It fuses knowledge between the corner detection and edge prediction by sharing feature in different granularity; 2) Corner candidates are proposed in four heatmap channels w.r.t its direction. Both qualitative and quantitative evaluations demonstrate that our proposed method can better reconstruct fine-grained structures, such as adjacent corners and tiny edges. Consequently, it outperforms the state-of-the-art model by +1.9\%@F-1 on Corner and +3.0\%@F-1 on Edge.
A Specific Task-oriented Semantic Image Communication System for substation patrol inspection
Jan 09, 2023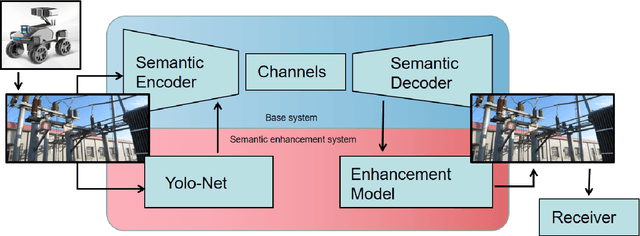
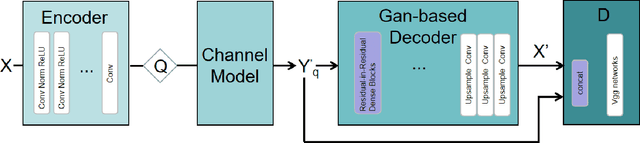
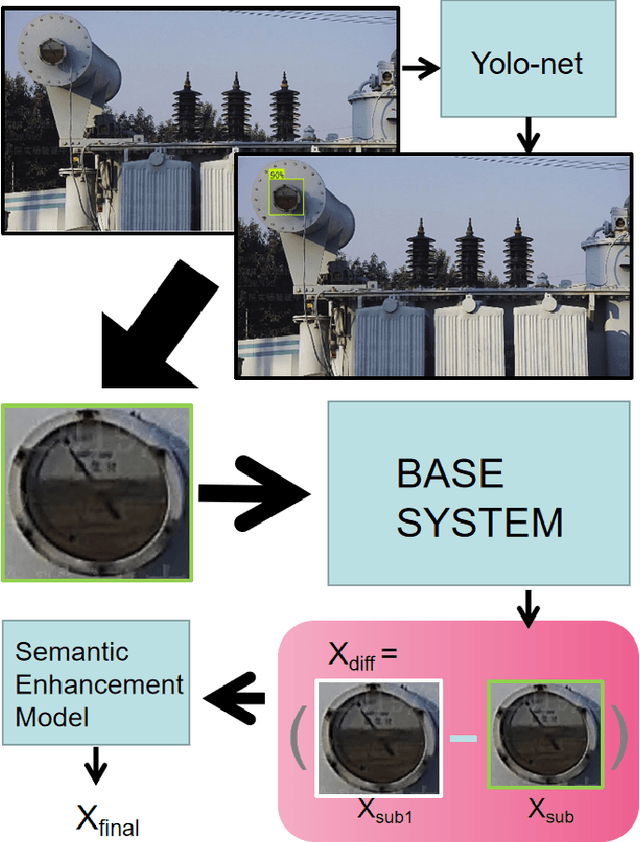
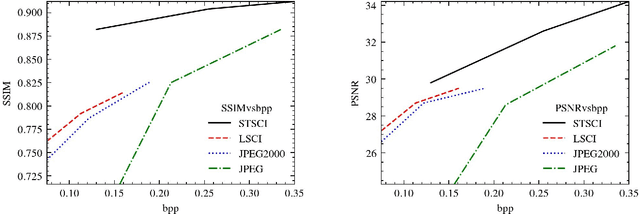
Intelligent inspection robots are widely used in substation patrol inspection, which can help check potential safety hazards by patrolling the substation and sending back scene images. However, when patrolling some marginal areas with weak signal, the scene images cannot be sucessfully transmissted to be used for hidden danger elimination, which greatly reduces the quality of robots'daily work. To solve such problem, a Specific Task-oriented Semantic Communication System for Imag-STSCI is designed, which involves the semantic features extraction, transmission, restoration and enhancement to get clearer images sent by intelligent robots under weak signals. Inspired by that only some specific details of the image are needed in such substation patrol inspection task, we proposed a new paradigm of semantic enhancement in such specific task to ensure the clarity of key semantic information when facing a lower bit rate or a low signal-to-noise ratio situation. Across the reality-based simulation, experiments show our STSCI can generally surpass traditional image-compression-based and channel-codingbased or other semantic communication system in the substation patrol inspection task with a lower bit rate even under a low signal-to-noise ratio situation.
Fusion is Not Enough: Single-Modal Attacks to Compromise Fusion Models in Autonomous Driving
Apr 28, 2023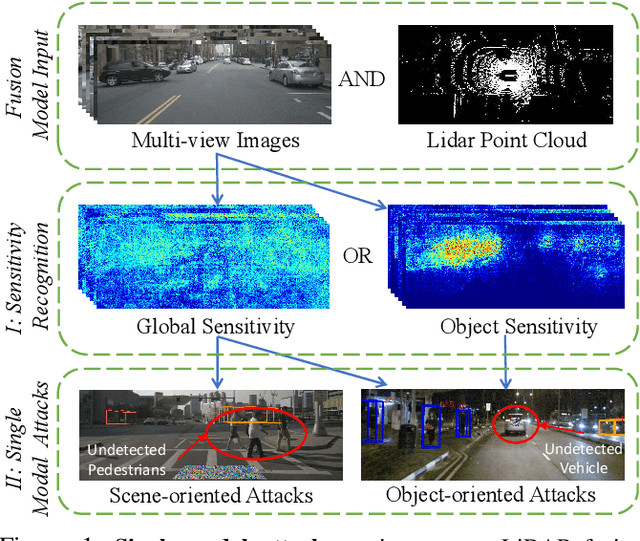
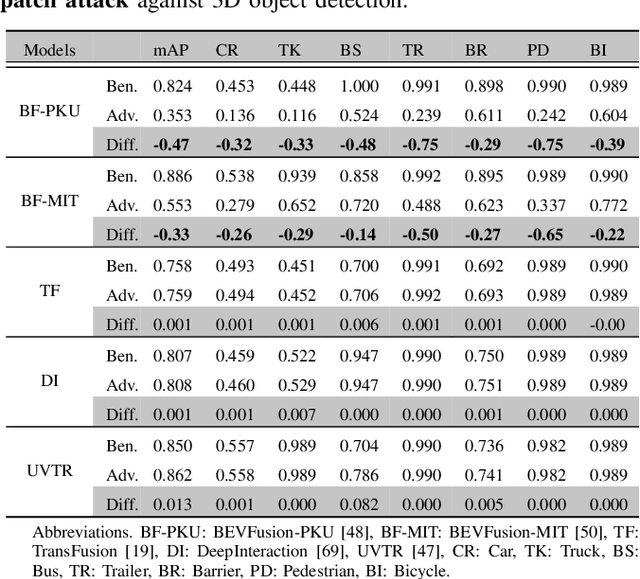
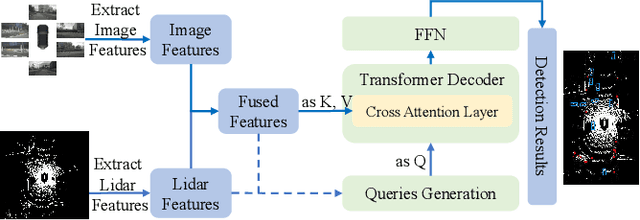
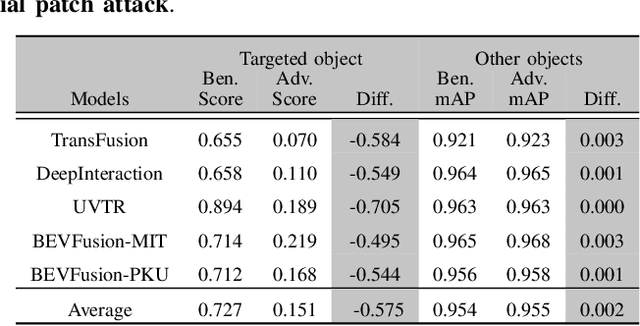
Multi-sensor fusion (MSF) is widely adopted for perception in autonomous vehicles (AVs), particularly for the task of 3D object detection with camera and LiDAR sensors. The rationale behind fusion is to capitalize on the strengths of each modality while mitigating their limitations. The exceptional and leading performance of fusion models has been demonstrated by advanced deep neural network (DNN)-based fusion techniques. Fusion models are also perceived as more robust to attacks compared to single-modal ones due to the redundant information in multiple modalities. In this work, we challenge this perspective with single-modal attacks that targets the camera modality, which is considered less significant in fusion but more affordable for attackers. We argue that the weakest link of fusion models depends on their most vulnerable modality, and propose an attack framework that targets advanced camera-LiDAR fusion models with adversarial patches. Our approach employs a two-stage optimization-based strategy that first comprehensively assesses vulnerable image areas under adversarial attacks, and then applies customized attack strategies to different fusion models, generating deployable patches. Evaluations with five state-of-the-art camera-LiDAR fusion models on a real-world dataset show that our attacks successfully compromise all models. Our approach can either reduce the mean average precision (mAP) of detection performance from 0.824 to 0.353 or degrade the detection score of the target object from 0.727 to 0.151 on average, demonstrating the effectiveness and practicality of our proposed attack framework.
Exploiting the Distortion-Semantic Interaction in Fisheye Data
Apr 28, 2023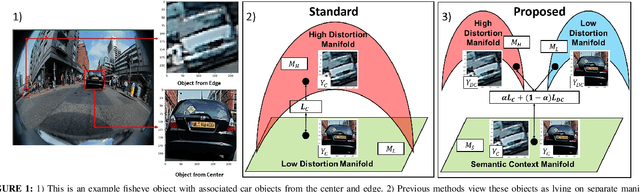
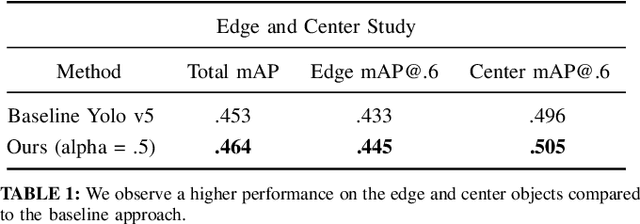
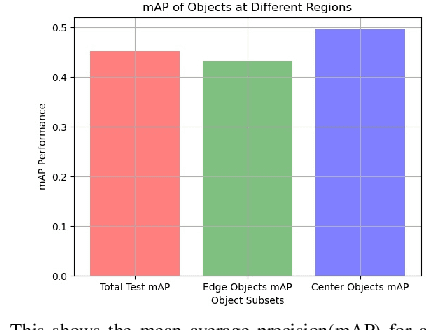

In this work, we present a methodology to shape a fisheye-specific representation space that reflects the interaction between distortion and semantic context present in this data modality. Fisheye data has the wider field of view advantage over other types of cameras, but this comes at the expense of high radial distortion. As a result, objects further from the center exhibit deformations that make it difficult for a model to identify their semantic context. While previous work has attempted architectural and training augmentation changes to alleviate this effect, no work has attempted to guide the model towards learning a representation space that reflects this interaction between distortion and semantic context inherent to fisheye data. We introduce an approach to exploit this relationship by first extracting distortion class labels based on an object's distance from the center of the image. We then shape a backbone's representation space with a weighted contrastive loss that constrains objects of the same semantic class and distortion class to be close to each other within a lower dimensional embedding space. This backbone trained with both semantic and distortion information is then fine-tuned within an object detection setting to empirically evaluate the quality of the learnt representation. We show this method leads to performance improvements by as much as 1.1% mean average precision over standard object detection strategies and .6% improvement over other state of the art representation learning approaches.
Feature Tracks are not Zero-Mean Gaussian
Mar 25, 2023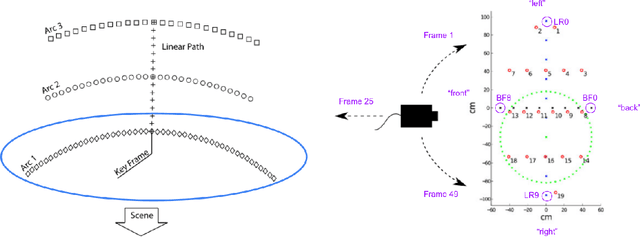

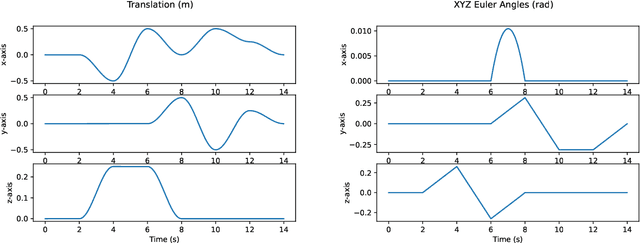

In state estimation algorithms that use feature tracks as input, it is customary to assume that the errors in feature track positions are zero-mean Gaussian. Using a combination of calibrated camera intrinsics, ground-truth camera pose, and depth images, it is possible to compute ground-truth positions for feature tracks extracted using an image processing algorithm. We find that feature track errors are not zero-mean Gaussian and that the distribution of errors is conditional on the type of motion, the speed of motion, and the image processing algorithm used to extract the tracks.
Affordance Diffusion: Synthesizing Hand-Object Interactions
Mar 21, 2023
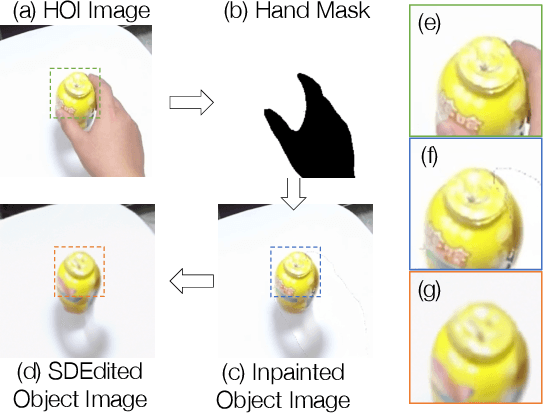

Recent successes in image synthesis are powered by large-scale diffusion models. However, most methods are currently limited to either text- or image-conditioned generation for synthesizing an entire image, texture transfer or inserting objects into a user-specified region. In contrast, in this work we focus on synthesizing complex interactions (ie, an articulated hand) with a given object. Given an RGB image of an object, we aim to hallucinate plausible images of a human hand interacting with it. We propose a two-step generative approach: a LayoutNet that samples an articulation-agnostic hand-object-interaction layout, and a ContentNet that synthesizes images of a hand grasping the object given the predicted layout. Both are built on top of a large-scale pretrained diffusion model to make use of its latent representation. Compared to baselines, the proposed method is shown to generalize better to novel objects and perform surprisingly well on out-of-distribution in-the-wild scenes of portable-sized objects. The resulting system allows us to predict descriptive affordance information, such as hand articulation and approaching orientation. Project page: https://judyye.github.io/affordiffusion-www
SMMix: Self-Motivated Image Mixing for Vision Transformers
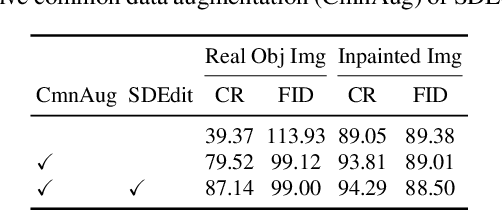
Dec 26, 2022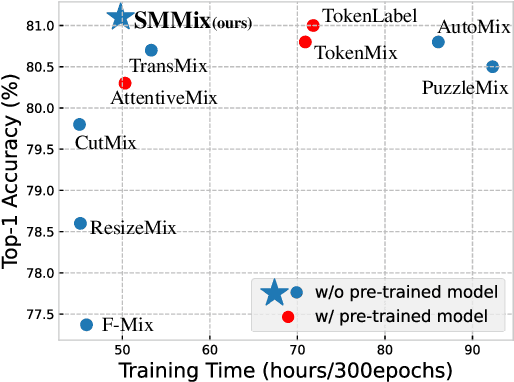
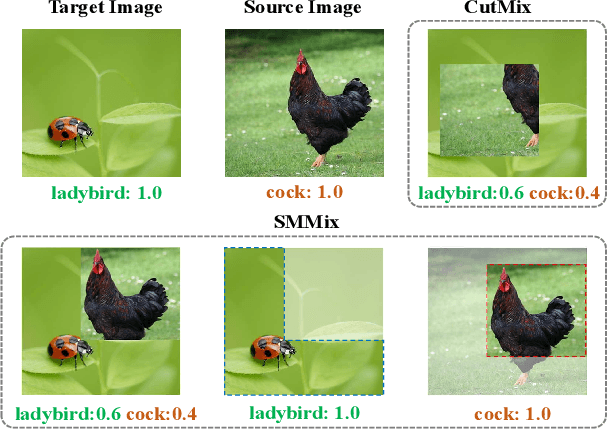
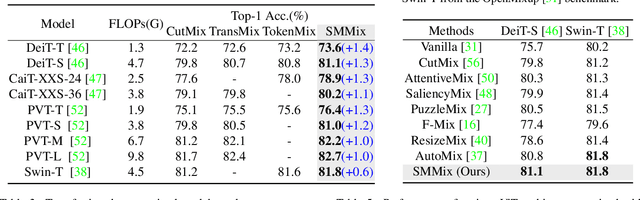
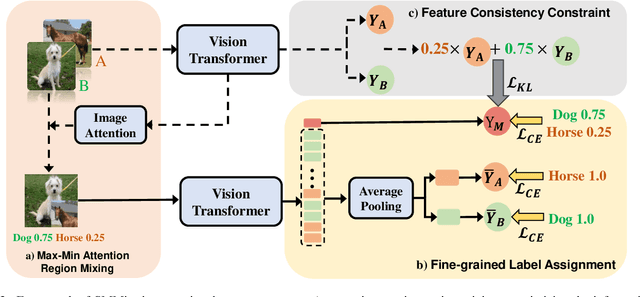
CutMix is a vital augmentation strategy that determines the performance and generalization ability of vision transformers (ViTs). However, the inconsistency between the mixed images and the corresponding labels harms its efficacy. Existing CutMix variants tackle this problem by generating more consistent mixed images or more precise mixed labels, but inevitably introduce heavy training overhead or require extra information, undermining ease of use. To this end, we propose an efficient and effective Self-Motivated image Mixing method (SMMix), which motivates both image and label enhancement by the model under training itself. Specifically, we propose a max-min attention region mixing approach that enriches the attention-focused objects in the mixed images. Then, we introduce a fine-grained label assignment technique that co-trains the output tokens of mixed images with fine-grained supervision. Moreover, we devise a novel feature consistency constraint to align features from mixed and unmixed images. Due to the subtle designs of the self-motivated paradigm, our SMMix is significant in its smaller training overhead and better performance than other CutMix variants. In particular, SMMix improves the accuracy of DeiT-T/S, CaiT-XXS-24/36, and PVT-T/S/M/L by more than +1% on ImageNet-1k. The generalization capability of our method is also demonstrated on downstream tasks and out-of-distribution datasets. Code of this project is available at https://github.com/ChenMnZ/SMMix.
On The Application Of Log Compression and Enhanced Denoising In Contrast Enhancement Of Digital Radiography Images
Apr 18, 2023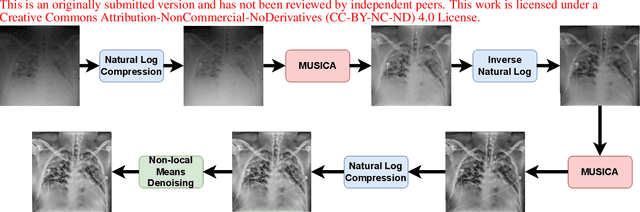

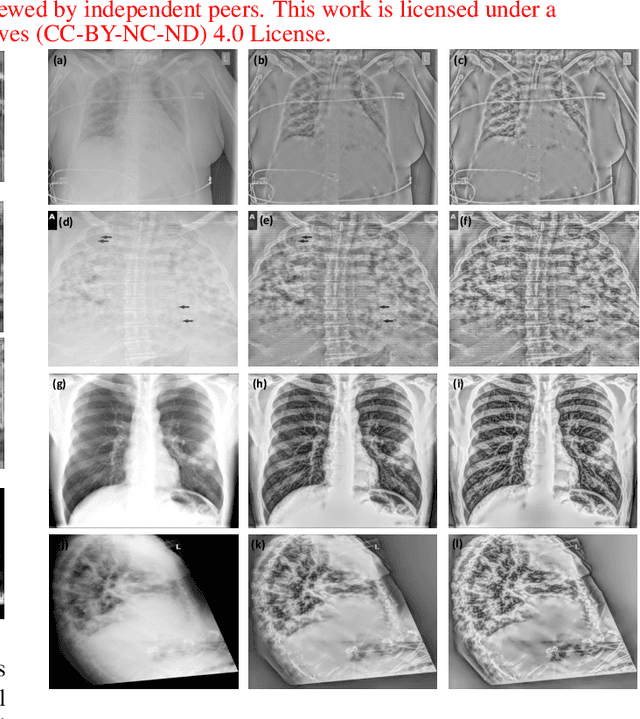
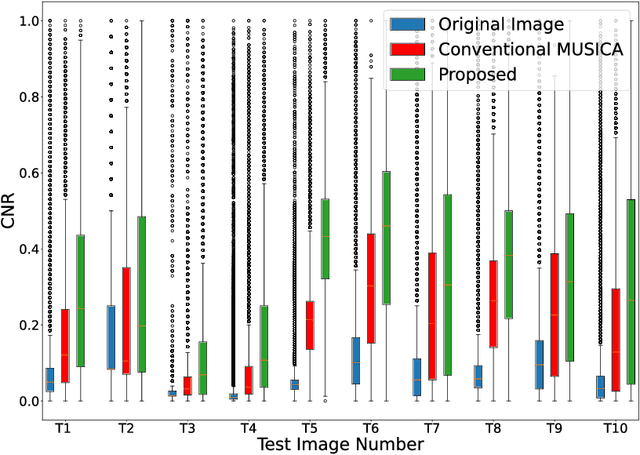
Digital radiography (DR) is becoming popular for the point of care imaging in the recent past. To reduce the radiation exposure, controlled radiation based on as low as reasonably achievable (ALARA) principle is employed and this results in low contrast images. To address this issue, post-processing algorithms such as the Multiscale Image Contrast Amplification (MUSICA) algorithm can be used to enhance the contrast of DR images even with a low radiation dose. In this study, a modification of the MUSICA algorithm is investigated to determine the potential for further contrast improvement specifically for DR images. The conclusion is that combining log compression and its inverse at the appropriate stage with a multi-stage MUSICA and denoising is very promising. The proposed method resulted in an average of 66.5 % increase in the mean contrast-to-noise ratio (CNR) for the test images considered.
Adaptive Consensus Optimization Method for GANs
Apr 20, 2023


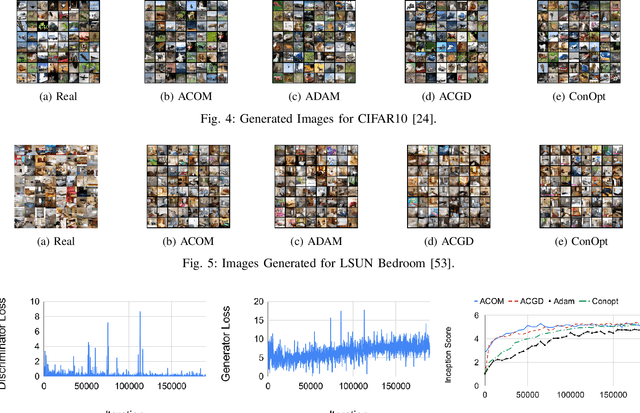
We propose a second order gradient based method with ADAM and RMSprop for the training of generative adversarial networks. The proposed method is fastest to obtain similar accuracy when compared to prominent second order methods. Unlike state-of-the-art recent methods, it does not require solving a linear system, or it does not require additional mixed second derivative terms. We derive the fixed point iteration corresponding to proposed method, and show that the proposed method is convergent. The proposed method produces better or comparable inception scores, and comparable quality of images compared to other recently proposed state-of-the-art second order methods. Compared to first order methods such as ADAM, it produces significantly better inception scores. The proposed method is compared and validated on popular datasets such as FFHQ, LSUN, CIFAR10, MNIST, and Fashion MNIST for image generation tasks\footnote{Accepted in IJCNN 2023}. Codes: \url{https://github.com/misterpawan/acom}