 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
μSplit: efficient image decomposition for microscopy data
Nov 23, 2022

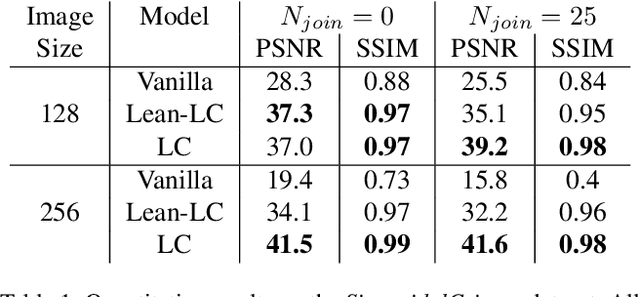
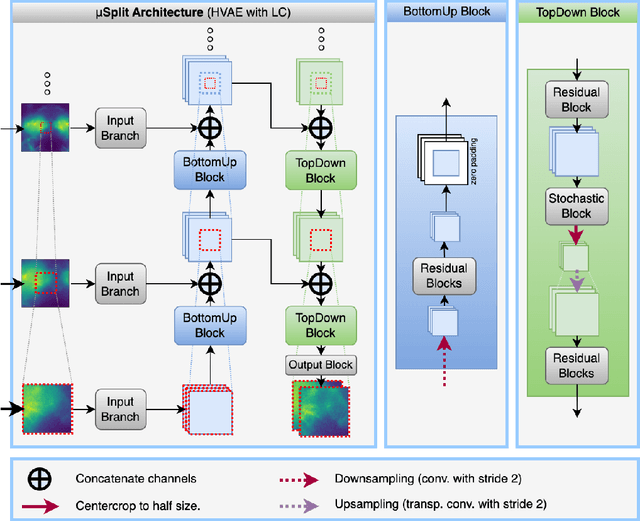
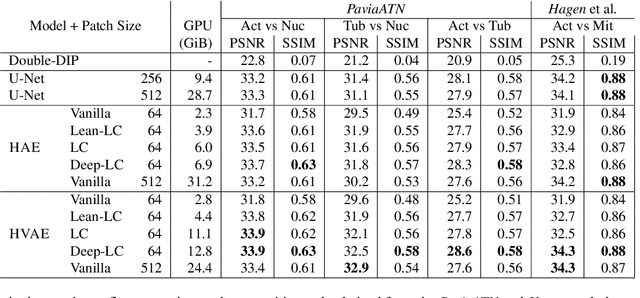
Light microscopy is routinely used to look at living cells and biological tissues at sub-cellular resolution. Components of the imaged cells can be highlighted using fluorescent labels, allowing biologists to investigate individual structures of interest. Given the complexity of biological processes, it is typically necessary to look at multiple structures simultaneously, typically via a temporal multiplexing scheme. Still, imaging more than 3 or 4 structures in this way is difficult for technical reasons and limits the rate of scientific progress in the life sciences. Hence, a computational method to split apart (decompose) superimposed biological structures acquired in a single image channel, i.e. without temporal multiplexing, would have tremendous impact. Here we present {\mu}Split, a dedicated approach for trained image decomposition. We find that best results using regular deep architectures is achieved when large image patches are used during training, making memory consumption the limiting factor to further improving performance. We therefore introduce lateral contextualization (LC), a memory efficient way to train deep networks that operate well on small input patches. In later layers, additional image context is fed at adequately lowered resolution. We integrate LC with Hierarchical Autoencoders and Hierarchical VAEs.For the latter, we also present a modified ELBO loss and show that it enables sound VAE training. We apply {\mu}Split to five decomposition tasks, one on a synthetic dataset, four others derived from two real microscopy datasets. LC consistently achieves SOTA results, while simultaneously requiring considerably less GPU memory than competing architectures not using LC. When introducing LC, results obtained with the above-mentioned vanilla architectures do on average improve by 2.36 dB (PSNR decibel), with individual improvements ranging from 0.9 to 3.4 dB.
Semi-Supervised Relational Contrastive Learning
Apr 11, 2023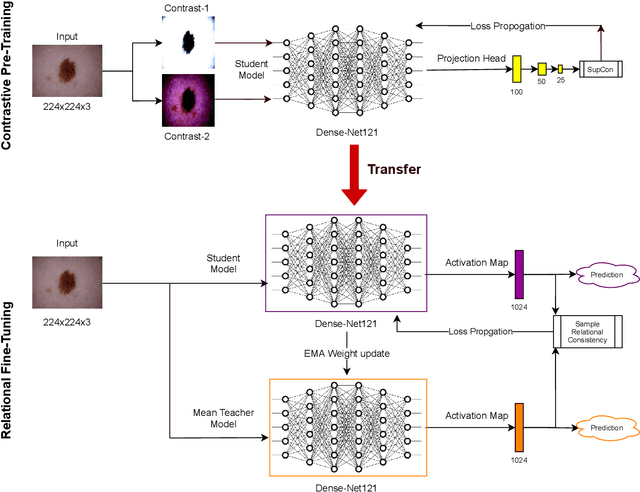
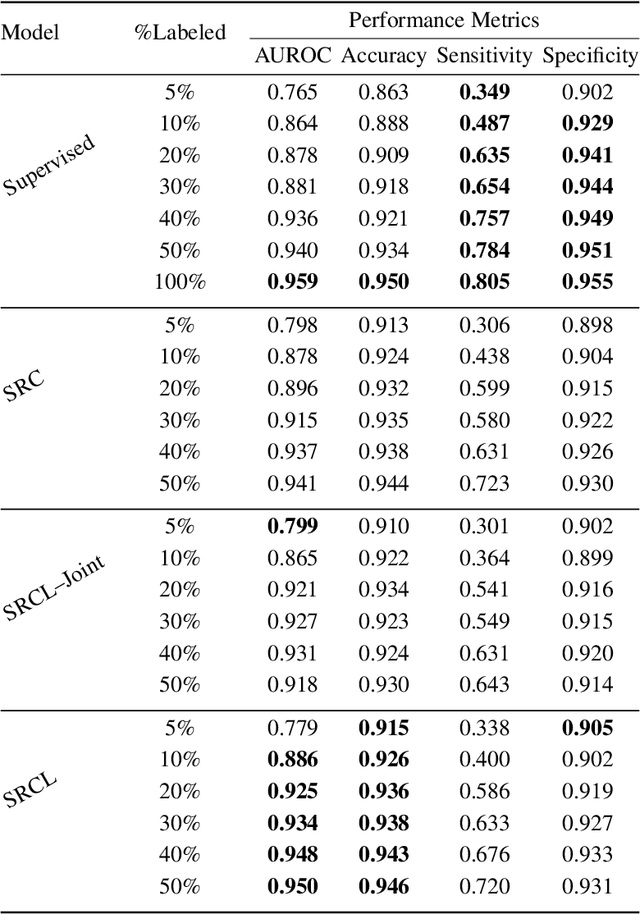
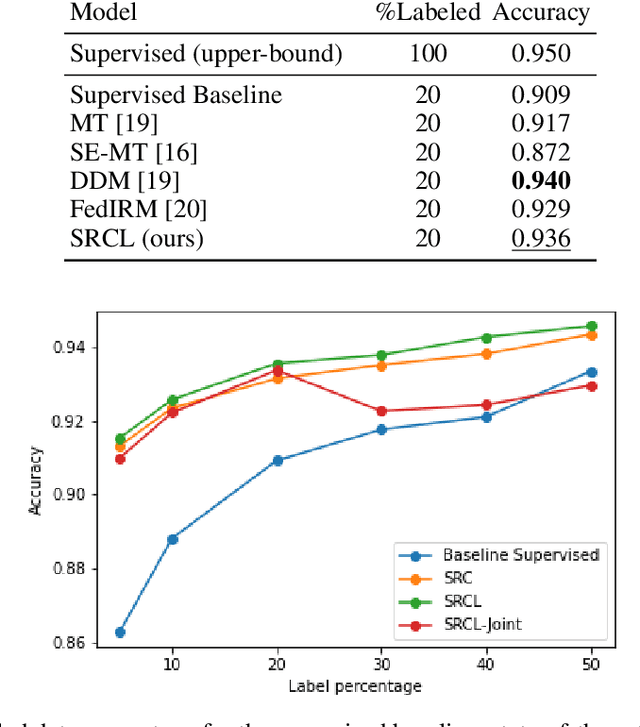
Disease diagnosis from medical images via supervised learning is usually dependent on tedious, error-prone, and costly image labeling by medical experts. Alternatively, semi-supervised learning and self-supervised learning offer effectiveness through the acquisition of valuable insights from readily available unlabeled images. We present Semi-Supervised Relational Contrastive Learning (SRCL), a novel semi-supervised learning model that leverages self-supervised contrastive loss and sample relation consistency for the more meaningful and effective exploitation of unlabeled data. Our experimentation with the SRCL model explores both pre-train/fine-tune and joint learning of the pretext (contrastive learning) and downstream (diagnostic classification) tasks. We validate against the ISIC 2018 Challenge benchmark skin lesion classification dataset and demonstrate the effectiveness of our semi-supervised method on varying amounts of labeled data.
SeaThru-NeRF: Neural Radiance Fields in Scattering Media
Apr 16, 2023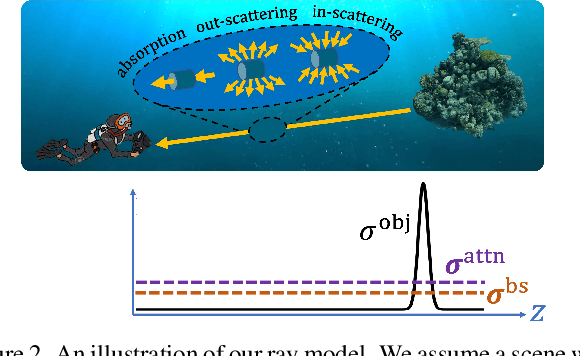

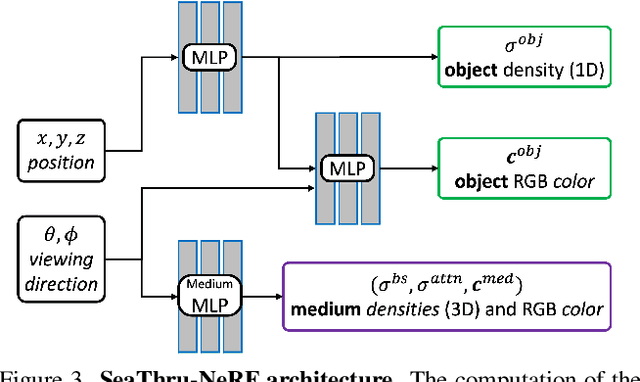

Research on neural radiance fields (NeRFs) for novel view generation is exploding with new models and extensions. However, a question that remains unanswered is what happens in underwater or foggy scenes where the medium strongly influences the appearance of objects. Thus far, NeRF and its variants have ignored these cases. However, since the NeRF framework is based on volumetric rendering, it has inherent capability to account for the medium's effects, once modeled appropriately. We develop a new rendering model for NeRFs in scattering media, which is based on the SeaThru image formation model, and suggest a suitable architecture for learning both scene information and medium parameters. We demonstrate the strength of our method using simulated and real-world scenes, correctly rendering novel photorealistic views underwater. Even more excitingly, we can render clear views of these scenes, removing the medium between the camera and the scene and reconstructing the appearance and depth of far objects, which are severely occluded by the medium. Our code and unique datasets are available on the project's website.
Optimal Goal-Reaching Reinforcement Learning via Quasimetric Learning
Apr 06, 2023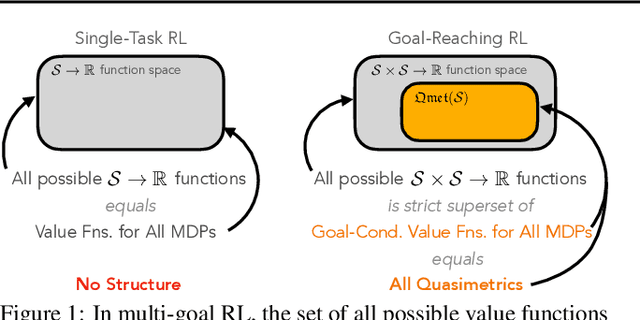
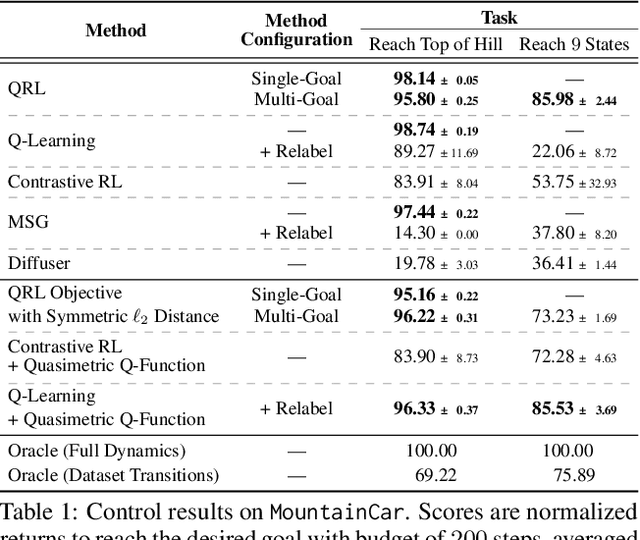
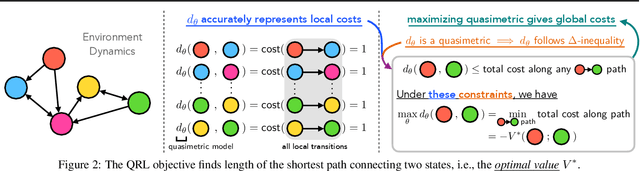
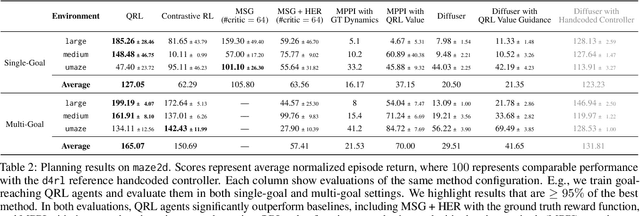
In goal-reaching reinforcement learning (RL), the optimal value function has a particular geometry, called quasimetric structure. This paper introduces Quasimetric Reinforcement Learning (QRL), a new RL method that utilizes quasimetric models to learn optimal value functions. Distinct from prior approaches, the QRL objective is specifically designed for quasimetrics, and provides strong theoretical recovery guarantees. Empirically, we conduct thorough analyses on a discretized MountainCar environment, identifying properties of QRL and its advantages over alternatives. On offline and online goal-reaching benchmarks, QRL also demonstrates improved sample efficiency and performance, across both state-based and image-based observations.
MaLP: Manipulation Localization Using a Proactive Scheme
Mar 29, 2023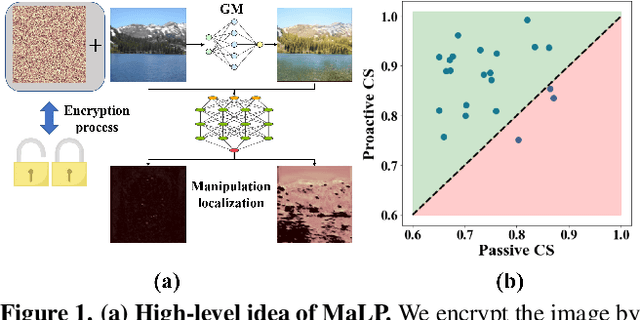
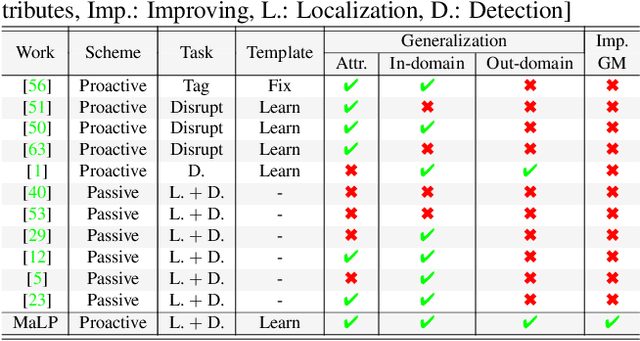
Advancements in the generation quality of various Generative Models (GMs) has made it necessary to not only perform binary manipulation detection but also localize the modified pixels in an image. However, prior works termed as passive for manipulation localization exhibit poor generalization performance over unseen GMs and attribute modifications. To combat this issue, we propose a proactive scheme for manipulation localization, termed MaLP. We encrypt the real images by adding a learned template. If the image is manipulated by any GM, this added protection from the template not only aids binary detection but also helps in identifying the pixels modified by the GM. The template is learned by leveraging local and global-level features estimated by a two-branch architecture. We show that MaLP performs better than prior passive works. We also show the generalizability of MaLP by testing on 22 different GMs, providing a benchmark for future research on manipulation localization. Finally, we show that MaLP can be used as a discriminator for improving the generation quality of GMs. Our models/codes are available at www.github.com/vishal3477/pro_loc.
ALADIN-NST: Self-supervised disentangled representation learning of artistic style through Neural Style Transfer
Apr 12, 2023
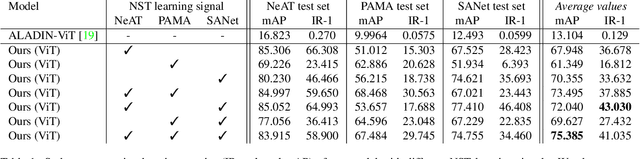
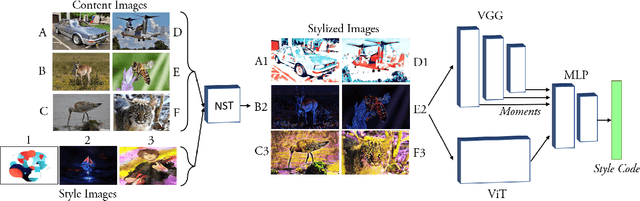
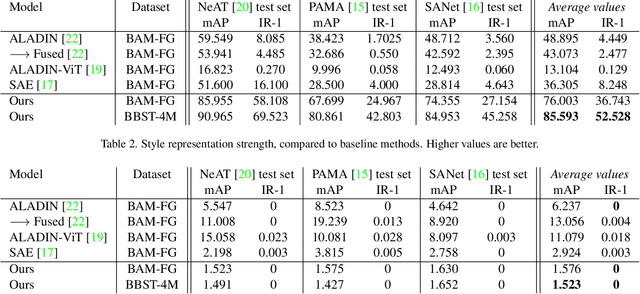
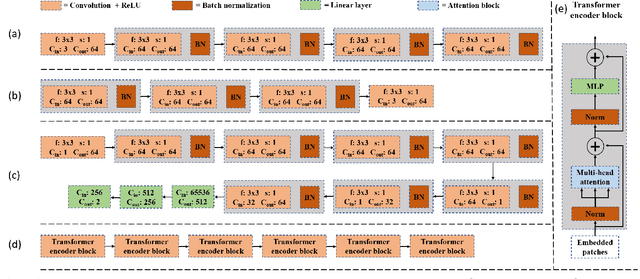
Representation learning aims to discover individual salient features of a domain in a compact and descriptive form that strongly identifies the unique characteristics of a given sample respective to its domain. Existing works in visual style representation literature have tried to disentangle style from content during training explicitly. A complete separation between these has yet to be fully achieved. Our paper aims to learn a representation of visual artistic style more strongly disentangled from the semantic content depicted in an image. We use Neural Style Transfer (NST) to measure and drive the learning signal and achieve state-of-the-art representation learning on explicitly disentangled metrics. We show that strongly addressing the disentanglement of style and content leads to large gains in style-specific metrics, encoding far less semantic information and achieving state-of-the-art accuracy in downstream multimodal applications.
Continuous Human Activity Recognition using a MIMO Radar for Transitional Motion Analysis
Apr 12, 2023
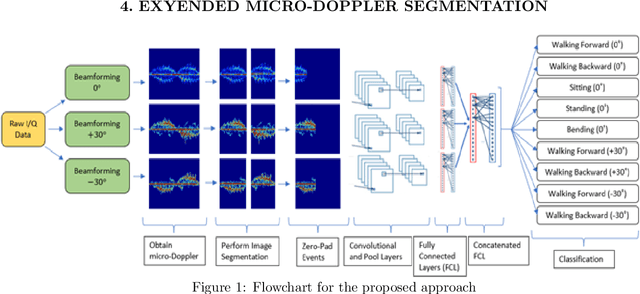
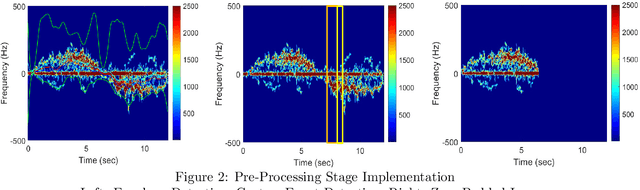
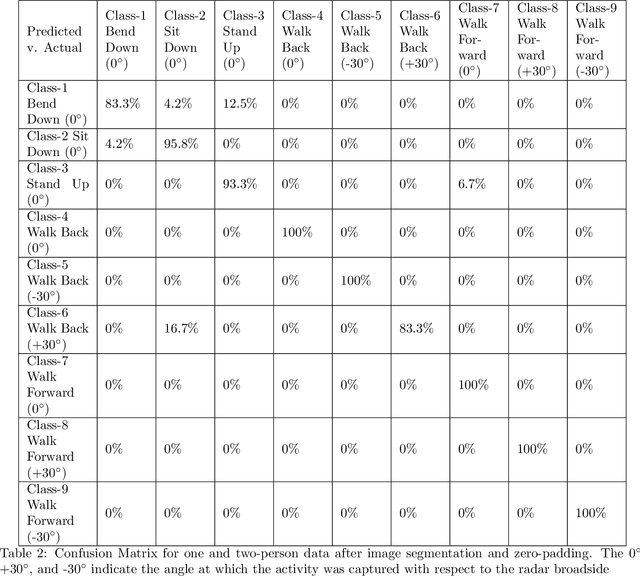
The prompt and accurate recognition of Continuous Human Activity (CHAR) is critical in identifying and responding to health events, particularly fall risk assessment. In this paper, we examine a multi-antenna radar system that can process radar data returns for multiple individuals in an indoor setting, enabling CHAR for multiple subjects. This requires combining spatial and temporal signal processing techniques through micro-Doppler (MD) analysis and high-resolution receive beamforming. We employ delay and sum beamforming to capture MD signatures at three different directions of observation. As MD images may contain multiple activities, we segment the three MD signatures using an STA/LTA algorithm. MD segmentation ensures that each MD segment represents a single human motion activity. Finally, the segmented MD image is resized and processed through a convolutional neural network (CNN) to classify motion against each MD segment.
CLIP-Guided Vision-Language Pre-training for Question Answering in 3D Scenes
Apr 12, 2023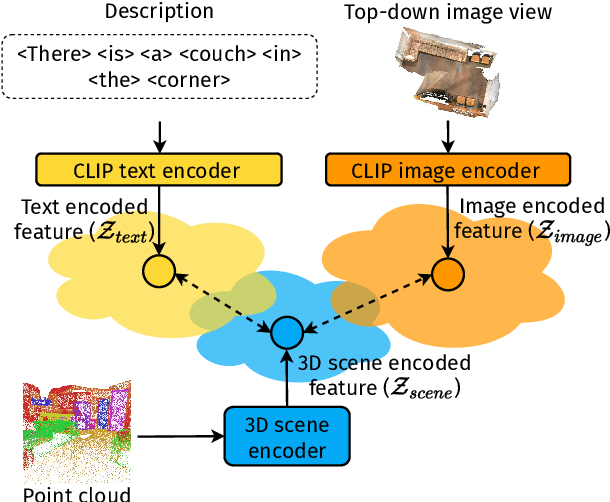
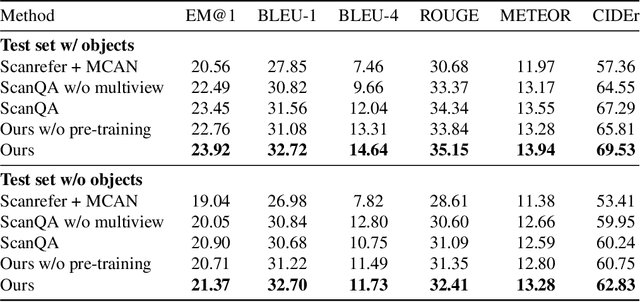
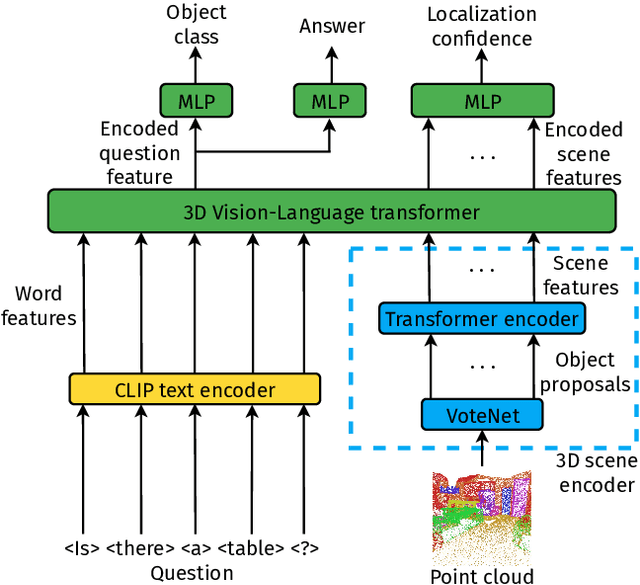
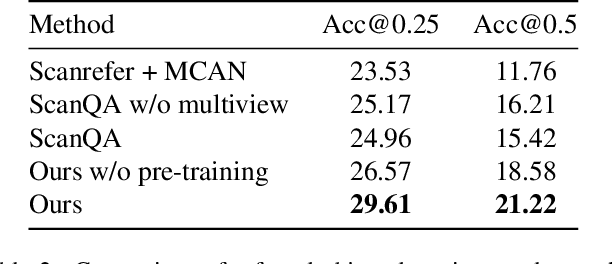
Training models to apply linguistic knowledge and visual concepts from 2D images to 3D world understanding is a promising direction that researchers have only recently started to explore. In this work, we design a novel 3D pre-training Vision-Language method that helps a model learn semantically meaningful and transferable 3D scene point cloud representations. We inject the representational power of the popular CLIP model into our 3D encoder by aligning the encoded 3D scene features with the corresponding 2D image and text embeddings produced by CLIP. To assess our model's 3D world reasoning capability, we evaluate it on the downstream task of 3D Visual Question Answering. Experimental quantitative and qualitative results show that our pre-training method outperforms state-of-the-art works in this task and leads to an interpretable representation of 3D scene features.
Privileged Prior Information Distillation for Image Matting
Nov 25, 2022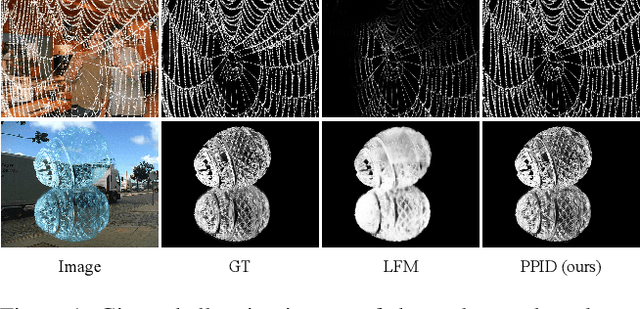
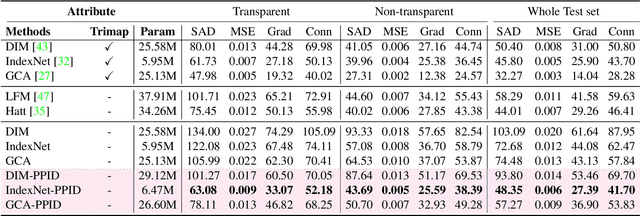
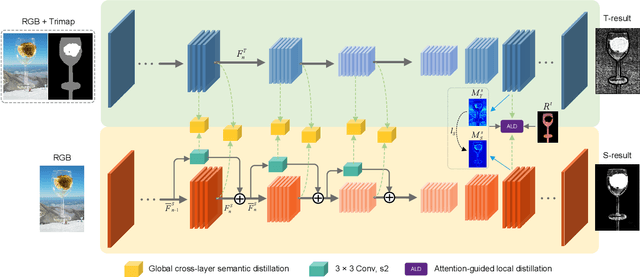
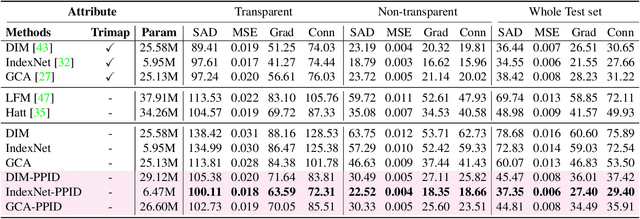
Performance of trimap-free image matting methods is limited when trying to decouple the deterministic and undetermined regions, especially in the scenes where foregrounds are semantically ambiguous, chromaless, or high transmittance. In this paper, we propose a novel framework named Privileged Prior Information Distillation for Image Matting (PPID-IM) that can effectively transfer privileged prior environment-aware information to improve the performance of students in solving hard foregrounds. The prior information of trimap regulates only the teacher model during the training stage, while not being fed into the student network during actual inference. In order to achieve effective privileged cross-modality (i.e. trimap and RGB) information distillation, we introduce a Cross-Level Semantic Distillation (CLSD) module that reinforces the trimap-free students with more knowledgeable semantic representations and environment-aware information. We also propose an Attention-Guided Local Distillation module that efficiently transfers privileged local attributes from the trimap-based teacher to trimap-free students for the guidance of local-region optimization. Extensive experiments demonstrate the effectiveness and superiority of our PPID framework on the task of image matting. In addition, our trimap-free IndexNet-PPID surpasses the other competing state-of-the-art methods by a large margin, especially in scenarios with chromaless, weak texture, or irregular objects.
3D Feature Prediction for Masked-AutoEncoder-Based Point Cloud Pretraining
Apr 14, 2023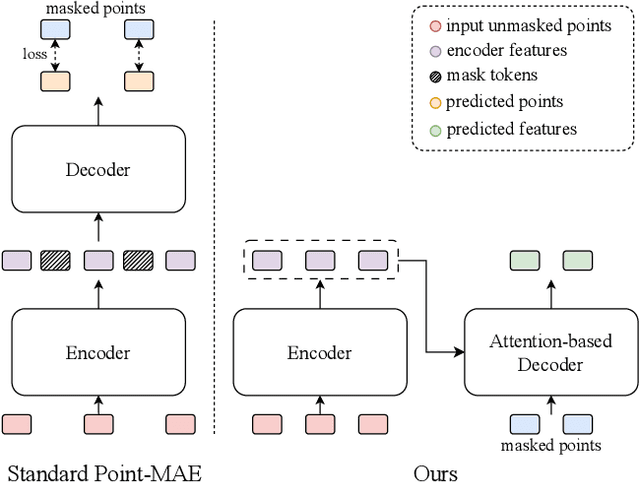
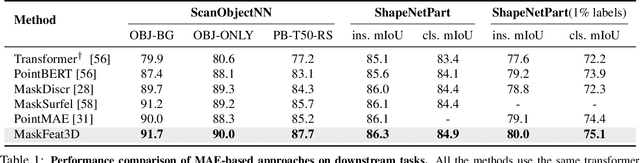
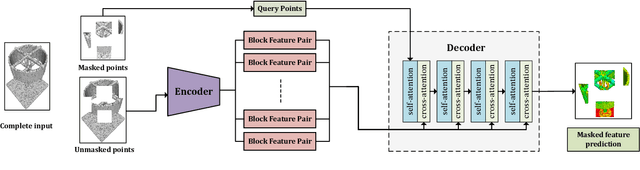
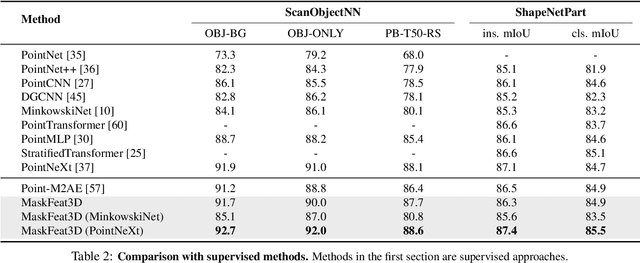
Masked autoencoders (MAE) have recently been introduced to 3D self-supervised pretraining for point clouds due to their great success in NLP and computer vision. Unlike MAEs used in the image domain, where the pretext task is to restore features at the masked pixels, such as colors, the existing 3D MAE works reconstruct the missing geometry only, i.e, the location of the masked points. In contrast to previous studies, we advocate that point location recovery is inessential and restoring intrinsic point features is much superior. To this end, we propose to ignore point position reconstruction and recover high-order features at masked points including surface normals and surface variations, through a novel attention-based decoder which is independent of the encoder design. We validate the effectiveness of our pretext task and decoder design using different encoder structures for 3D training and demonstrate the advantages of our pretrained networks on various point cloud analysis tasks.