 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Progressive Random Convolutions for Single Domain Generalization
Apr 02, 2023
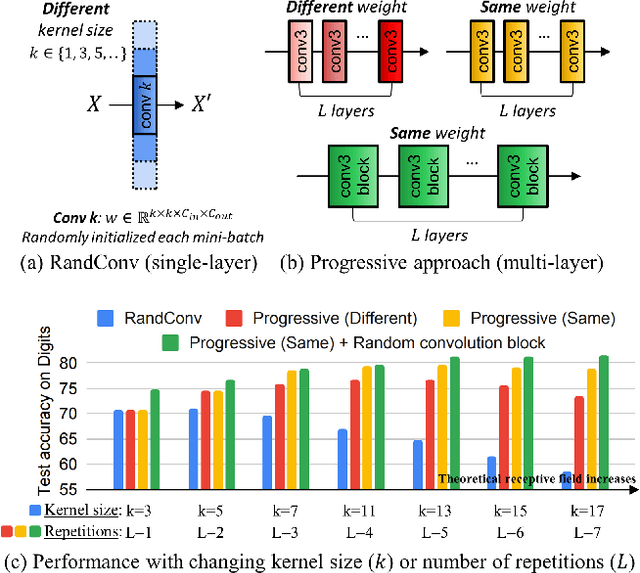
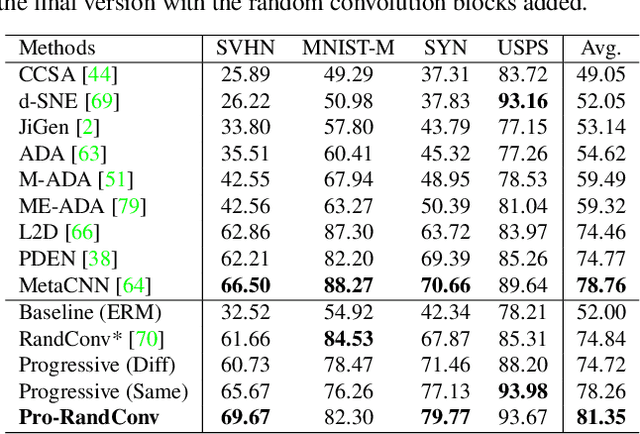

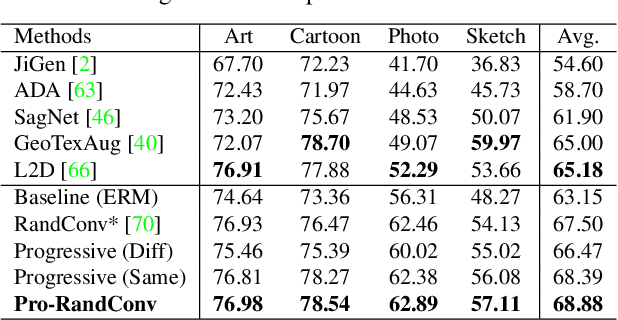
Single domain generalization aims to train a generalizable model with only one source domain to perform well on arbitrary unseen target domains. Image augmentation based on Random Convolutions (RandConv), consisting of one convolution layer randomly initialized for each mini-batch, enables the model to learn generalizable visual representations by distorting local textures despite its simple and lightweight structure. However, RandConv has structural limitations in that the generated image easily loses semantics as the kernel size increases, and lacks the inherent diversity of a single convolution operation. To solve the problem, we propose a Progressive Random Convolution (Pro-RandConv) method that recursively stacks random convolution layers with a small kernel size instead of increasing the kernel size. This progressive approach can not only mitigate semantic distortions by reducing the influence of pixels away from the center in the theoretical receptive field, but also create more effective virtual domains by gradually increasing the style diversity. In addition, we develop a basic random convolution layer into a random convolution block including deformable offsets and affine transformation to support texture and contrast diversification, both of which are also randomly initialized. Without complex generators or adversarial learning, we demonstrate that our simple yet effective augmentation strategy outperforms state-of-the-art methods on single domain generalization benchmarks.
Textile Pattern Generation Using Diffusion Models
Apr 02, 2023


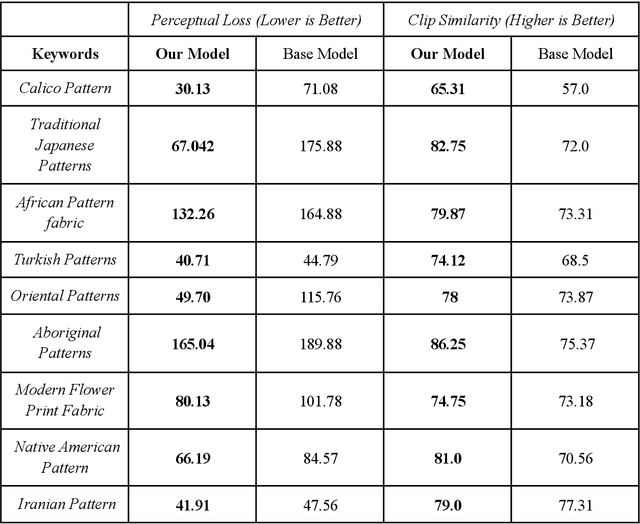
The problem of text-guided image generation is a complex task in Computer Vision, with various applications, including creating visually appealing artwork and realistic product images. One popular solution widely used for this task is the diffusion model, a generative model that generates images through an iterative process. Although diffusion models have demonstrated promising results for various image generation tasks, they may only sometimes produce satisfactory results when applied to more specific domains, such as the generation of textile patterns based on text guidance. This study presents a fine-tuned diffusion model specifically trained for textile pattern generation by text guidance to address this issue. The study involves the collection of various textile pattern images and their captioning with the help of another AI model. The fine-tuned diffusion model is trained with this newly created dataset, and its results are compared with the baseline models visually and numerically. The results demonstrate that the proposed fine-tuned diffusion model outperforms the baseline models in terms of pattern quality and efficiency in textile pattern generation by text guidance. This study presents a promising solution to the problem of text-guided textile pattern generation and has the potential to simplify the design process within the textile industry.
Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models
Jan 31, 2023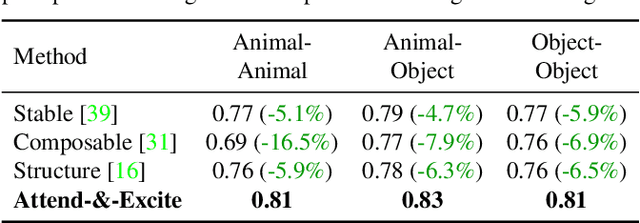

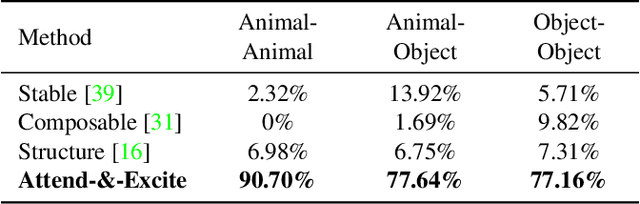
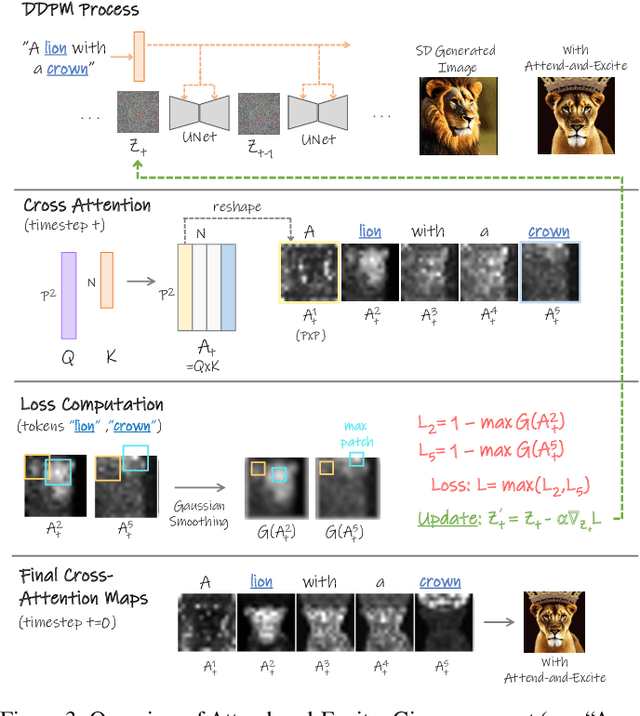
Recent text-to-image generative models have demonstrated an unparalleled ability to generate diverse and creative imagery guided by a target text prompt. While revolutionary, current state-of-the-art diffusion models may still fail in generating images that fully convey the semantics in the given text prompt. We analyze the publicly available Stable Diffusion model and assess the existence of catastrophic neglect, where the model fails to generate one or more of the subjects from the input prompt. Moreover, we find that in some cases the model also fails to correctly bind attributes (e.g., colors) to their corresponding subjects. To help mitigate these failure cases, we introduce the concept of Generative Semantic Nursing (GSN), where we seek to intervene in the generative process on the fly during inference time to improve the faithfulness of the generated images. Using an attention-based formulation of GSN, dubbed Attend-and-Excite, we guide the model to refine the cross-attention units to attend to all subject tokens in the text prompt and strengthen - or excite - their activations, encouraging the model to generate all subjects described in the text prompt. We compare our approach to alternative approaches and demonstrate that it conveys the desired concepts more faithfully across a range of text prompts.
An Attention-based Multi-Scale Feature Learning Network for Multimodal Medical Image Fusion
Dec 09, 2022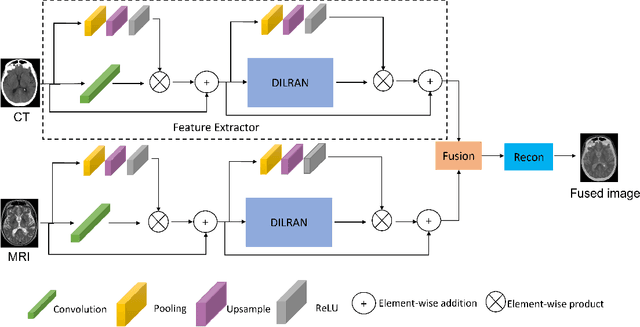
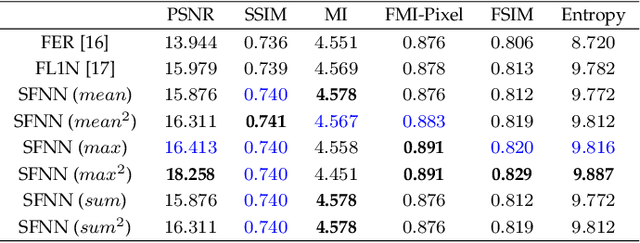
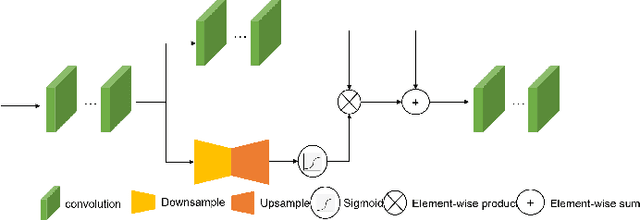
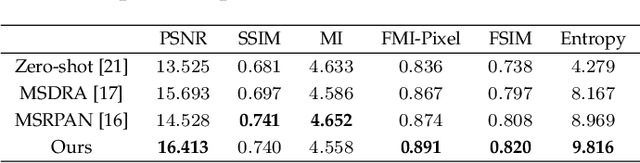
Medical images play an important role in clinical applications. Multimodal medical images could provide rich information about patients for physicians to diagnose. The image fusion technique is able to synthesize complementary information from multimodal images into a single image. This technique will prevent radiologists switch back and forth between different images and save lots of time in the diagnostic process. In this paper, we introduce a novel Dilated Residual Attention Network for the medical image fusion task. Our network is capable to extract multi-scale deep semantic features. Furthermore, we propose a novel fixed fusion strategy termed Softmax-based weighted strategy based on the Softmax weights and matrix nuclear norm. Extensive experiments show our proposed network and fusion strategy exceed the state-of-the-art performance compared with reference image fusion methods on four commonly used fusion metrics.
Optimized learned entropy coding parameters for practical neural-based image and video compression
Jan 20, 2023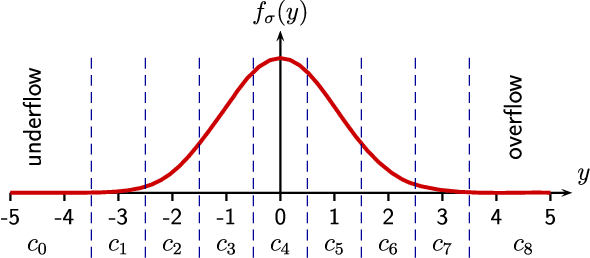
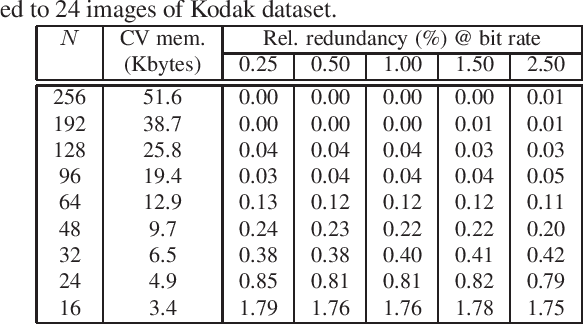
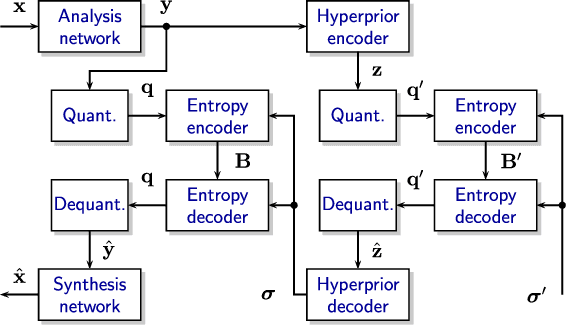
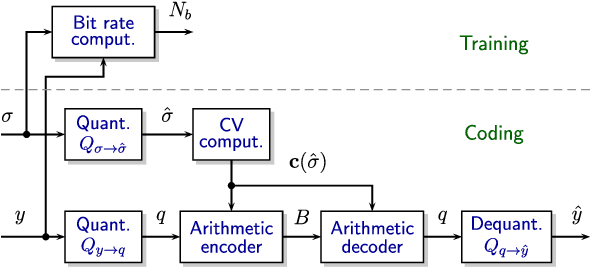
Neural-based image and video codecs are significantly more power-efficient when weights and activations are quantized to low-precision integers. While there are general-purpose techniques for reducing quantization effects, large losses can occur when specific entropy coding properties are not considered. This work analyzes how entropy coding is affected by parameter quantizations, and provides a method to minimize losses. It is shown that, by using a certain type of coding parameters to be learned, uniform quantization becomes practically optimal, also simplifying the minimization of code memory requirements. The mathematical properties of the new representation are presented, and its effectiveness is demonstrated by coding experiments, showing that good results can be obtained with precision as low as 4~bits per network output, and practically no loss with 8~bits.
* 2022 IEEE International Conference on Image Processing (ICIP)
Now You See Me: Robust approach to Partial Occlusions
Apr 25, 2023
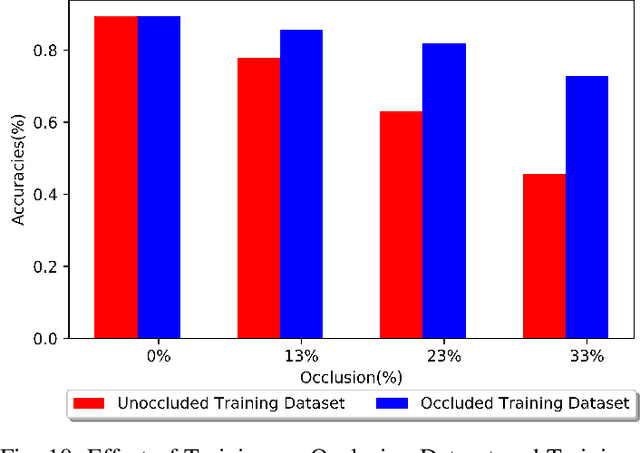
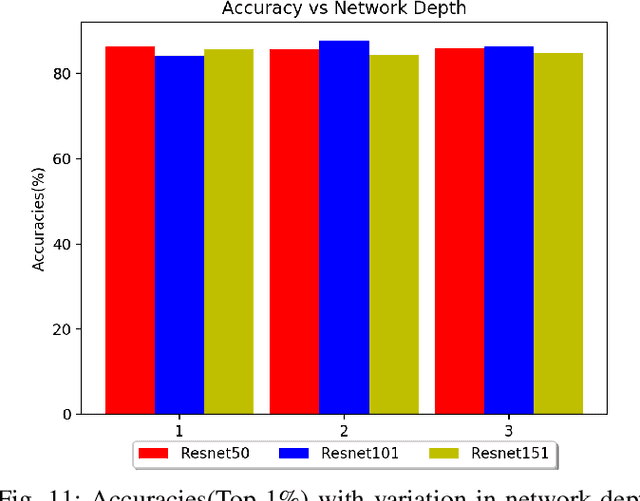
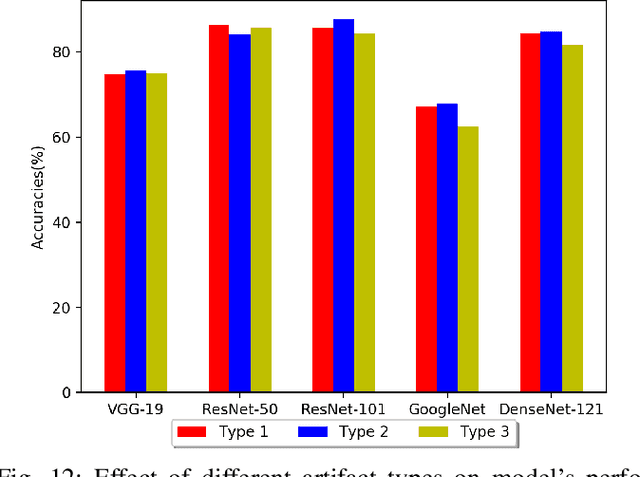
Occlusions of objects is one of the indispensable problems in Computer vision. While Convolutional Neural Net-works (CNNs) provide various state of the art approaches for regular image classification, they however, prove to be not as effective for the classification of images with partial occlusions. Partial occlusion is scenario where an object is occluded partially by some other object/space. This problem when solved,holds tremendous potential to facilitate various scenarios. We in particular are interested in autonomous driving scenario and its implications in the same. Autonomous vehicle research is one of the hot topics of this decade, there are ample situations of partial occlusions of a driving sign or a person or other objects at different angles. Considering its prime importance in situations which can be further extended to video analytics of traffic data to handle crimes, anticipate income levels of various groups etc.,this holds the potential to be exploited in many ways. In this paper, we introduce our own synthetically created dataset by utilising Stanford Car Dataset and adding occlusions of various sizes and nature to it. On this created dataset, we conducted a comprehensive analysis using various state of the art CNN models such as VGG-19, ResNet 50/101, GoogleNet, DenseNet 121. We further in depth study the effect of varying occlusion proportions and nature on the performance of these models by fine tuning and training these from scratch on dataset and how is it likely to perform when trained in different scenarios, i.e., performance when training with occluded images and unoccluded images, which model is more robust to partial occlusions and soon.
Masked Transformer for image Anomaly Localization
Oct 27, 2022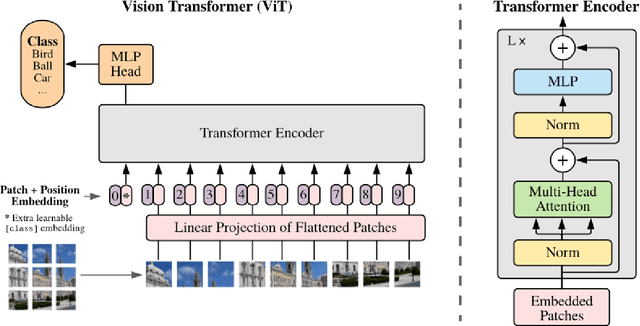
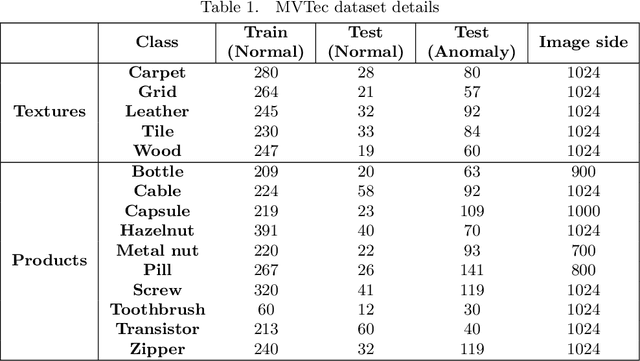
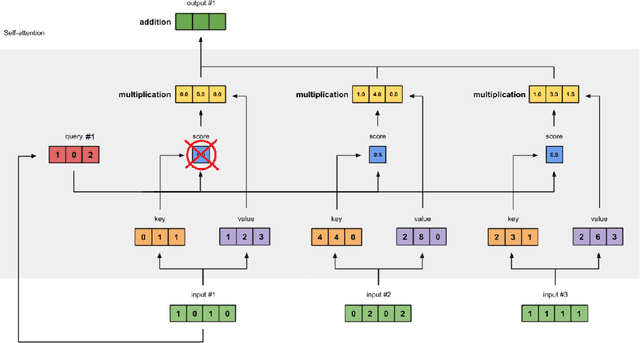

Image anomaly detection consists in detecting images or image portions that are visually different from the majority of the samples in a dataset. The task is of practical importance for various real-life applications like biomedical image analysis, visual inspection in industrial production, banking, traffic management, etc. Most of the current deep learning approaches rely on image reconstruction: the input image is projected in some latent space and then reconstructed, assuming that the network (mostly trained on normal data) will not be able to reconstruct the anomalous portions. However, this assumption does not always hold. We thus propose a new model based on the Vision Transformer architecture with patch masking: the input image is split in several patches, and each patch is reconstructed only from the surrounding data, thus ignoring the potentially anomalous information contained in the patch itself. We then show that multi-resolution patches and their collective embeddings provide a large improvement in the model's performance compared to the exclusive use of the traditional square patches. The proposed model has been tested on popular anomaly detection datasets such as MVTec and head CT and achieved good results when compared to other state-of-the-art approaches.
Low-Light Image and Video Enhancement: A Comprehensive Survey and Beyond
Dec 21, 2022



This paper presents a comprehensive survey of low-light image and video enhancement. We begin with the challenging mixed over-/under-exposed images, which are under-performed by existing methods. To this end, we propose two variants of the SICE dataset named SICE_Grad and SICE_Mix. Next, we introduce Night Wenzhou, a large-scale, high-resolution video dataset, to address the issue of the lack of a low-light video dataset that discount the use of low-light image enhancement (LLIE) to videos. The Night Wenzhou dataset is challenging since it consists of fast-moving aerial scenes and streetscapes with varying illuminations and degradation. We conduct extensive key technique analysis and experimental comparisons for representative LLIE approaches using these newly proposed datasets and the current benchmark datasets. Finally, we address unresolved issues and propose future research topics for the LLIE community.
Improving Masked Autoencoders by Learning Where to Mask
Mar 12, 2023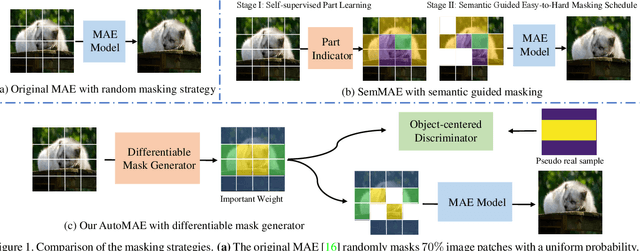

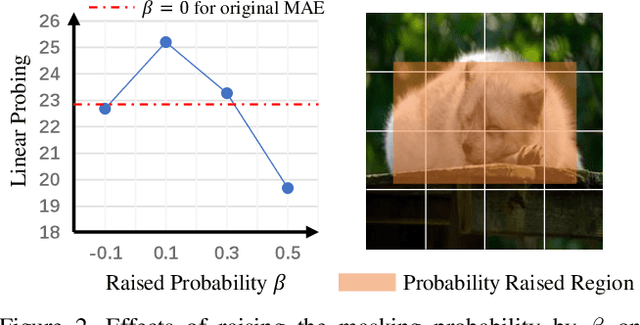

Masked image modeling is a promising self-supervised learning method for visual data. It is typically built upon image patches with random masks, which largely ignores the variation of information density between them. The question is: Is there a better masking strategy than random sampling and how can we learn it? We empirically study this problem and initially find that introducing object-centric priors in mask sampling can significantly improve the learned representations. Inspired by this observation, we present AutoMAE, a fully differentiable framework that uses Gumbel-Softmax to interlink an adversarially-trained mask generator and a mask-guided image modeling process. In this way, our approach can adaptively find patches with higher information density for different images, and further strike a balance between the information gain obtained from image reconstruction and its practical training difficulty. In our experiments, AutoMAE is shown to provide effective pretraining models on standard self-supervised benchmarks and downstream tasks.
Audio-Driven Talking Face Generation with Diverse yet Realistic Facial Animations
Apr 18, 2023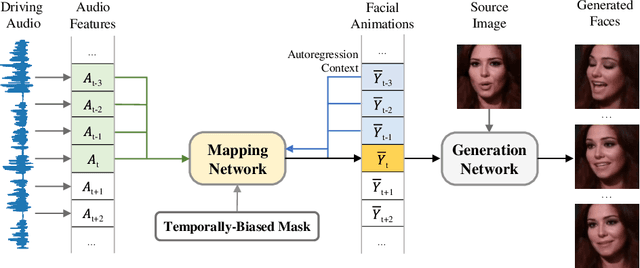
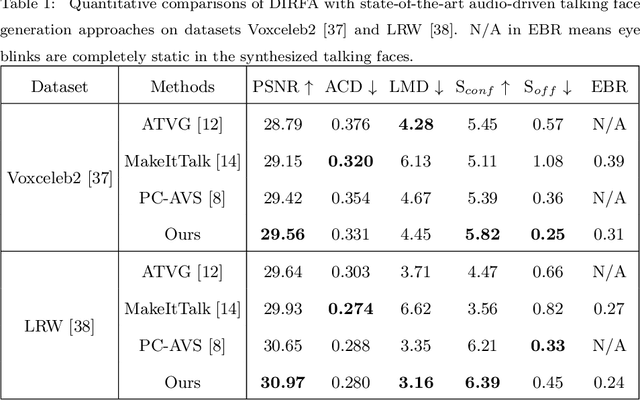

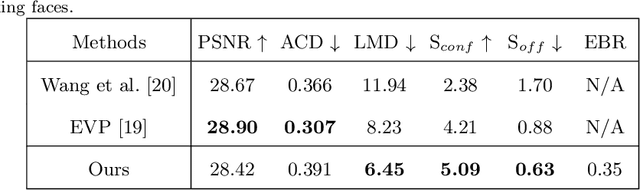
Audio-driven talking face generation, which aims to synthesize talking faces with realistic facial animations (including accurate lip movements, vivid facial expression details and natural head poses) corresponding to the audio, has achieved rapid progress in recent years. However, most existing work focuses on generating lip movements only without handling the closely correlated facial expressions, which degrades the realism of the generated faces greatly. This paper presents DIRFA, a novel method that can generate talking faces with diverse yet realistic facial animations from the same driving audio. To accommodate fair variation of plausible facial animations for the same audio, we design a transformer-based probabilistic mapping network that can model the variational facial animation distribution conditioned upon the input audio and autoregressively convert the audio signals into a facial animation sequence. In addition, we introduce a temporally-biased mask into the mapping network, which allows to model the temporal dependency of facial animations and produce temporally smooth facial animation sequence. With the generated facial animation sequence and a source image, photo-realistic talking faces can be synthesized with a generic generation network. Extensive experiments show that DIRFA can generate talking faces with realistic facial animations effectively.