 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
POAR: Towards Open-World Pedestrian Attribute Recognition
Mar 26, 2023
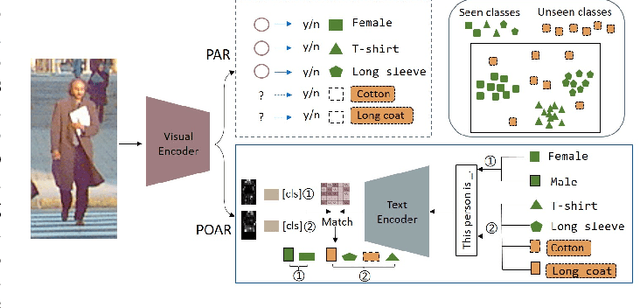
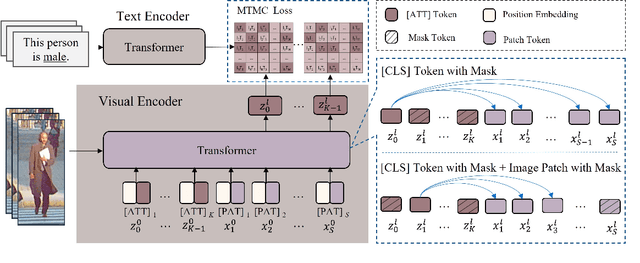

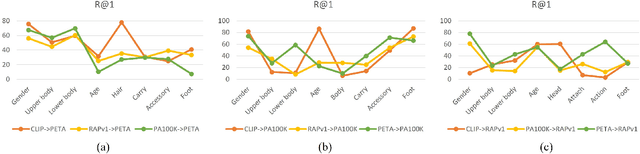
Pedestrian attribute recognition (PAR) aims to predict the attributes of a target pedestrian in a surveillance system. Existing methods address the PAR problem by training a multi-label classifier with predefined attribute classes. However, it is impossible to exhaust all pedestrian attributes in the real world. To tackle this problem, we develop a novel pedestrian open-attribute recognition (POAR) framework. Our key idea is to formulate the POAR problem as an image-text search problem. We design a Transformer-based image encoder with a masking strategy. A set of attribute tokens are introduced to focus on specific pedestrian parts (e.g., head, upper body, lower body, feet, etc.) and encode corresponding attributes into visual embeddings. Each attribute category is described as a natural language sentence and encoded by the text encoder. Then, we compute the similarity between the visual and text embeddings of attributes to find the best attribute descriptions for the input images. Different from existing methods that learn a specific classifier for each attribute category, we model the pedestrian at a part-level and explore the searching method to handle the unseen attributes. Finally, a many-to-many contrastive (MTMC) loss with masked tokens is proposed to train the network since a pedestrian image can comprise multiple attributes. Extensive experiments have been conducted on benchmark PAR datasets with an open-attribute setting. The results verified the effectiveness of the proposed POAR method, which can form a strong baseline for the POAR task.
Learning Fractals by Gradient Descent
Mar 14, 2023

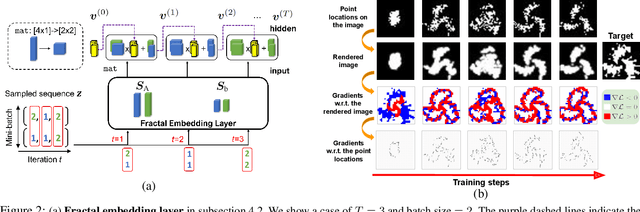

Fractals are geometric shapes that can display complex and self-similar patterns found in nature (e.g., clouds and plants). Recent works in visual recognition have leveraged this property to create random fractal images for model pre-training. In this paper, we study the inverse problem -- given a target image (not necessarily a fractal), we aim to generate a fractal image that looks like it. We propose a novel approach that learns the parameters underlying a fractal image via gradient descent. We show that our approach can find fractal parameters of high visual quality and be compatible with different loss functions, opening up several potentials, e.g., learning fractals for downstream tasks, scientific understanding, etc.
Get Rid Of Your Trail: Remotely Erasing Backdoors in Federated Learning
Apr 20, 2023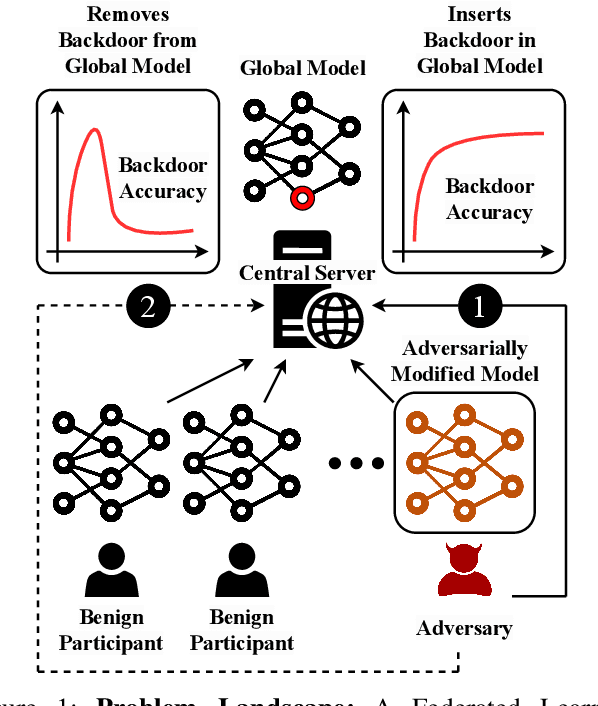
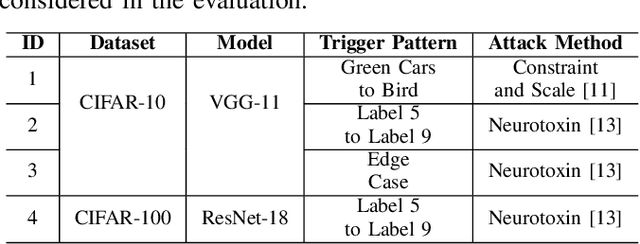
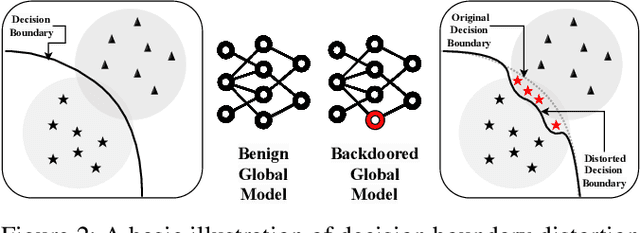
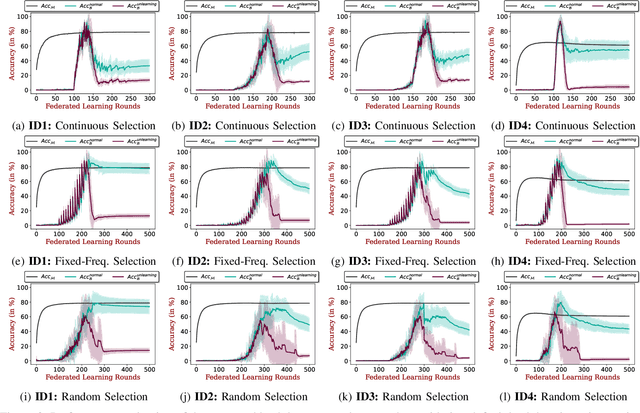
Federated Learning (FL) enables collaborative deep learning training across multiple participants without exposing sensitive personal data. However, the distributed nature of FL and the unvetted participants' data makes it vulnerable to backdoor attacks. In these attacks, adversaries inject malicious functionality into the centralized model during training, leading to intentional misclassifications for specific adversary-chosen inputs. While previous research has demonstrated successful injections of persistent backdoors in FL, the persistence also poses a challenge, as their existence in the centralized model can prompt the central aggregation server to take preventive measures to penalize the adversaries. Therefore, this paper proposes a methodology that enables adversaries to effectively remove backdoors from the centralized model upon achieving their objectives or upon suspicion of possible detection. The proposed approach extends the concept of machine unlearning and presents strategies to preserve the performance of the centralized model and simultaneously prevent over-unlearning of information unrelated to backdoor patterns, making the adversaries stealthy while removing backdoors. To the best of our knowledge, this is the first work that explores machine unlearning in FL to remove backdoors to the benefit of adversaries. Exhaustive evaluation considering image classification scenarios demonstrates the efficacy of the proposed method in efficient backdoor removal from the centralized model, injected by state-of-the-art attacks across multiple configurations.
Adaptive Stylization Modulation for Domain Generalized Semantic Segmentation
Apr 20, 2023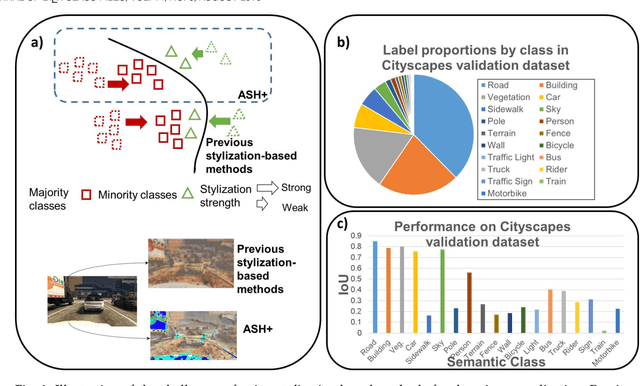
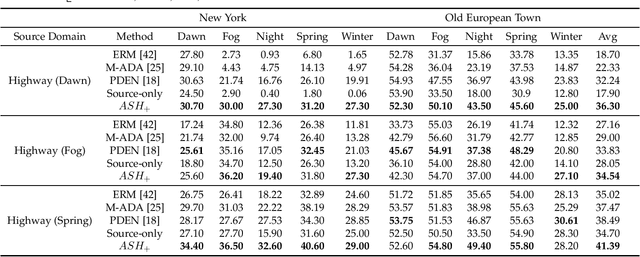
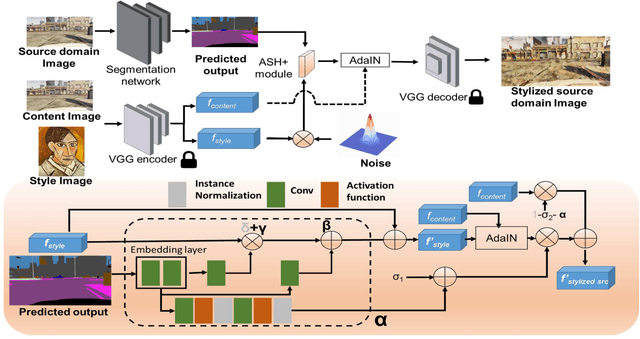
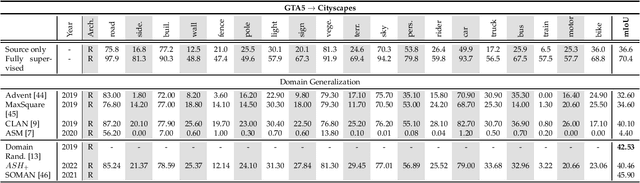
Obtaining sufficient labelled data for model training is impractical for most real-life applications. Therefore, we address the problem of domain generalization for semantic segmentation tasks to reduce the need to acquire and label additional data. Recent work on domain generalization increase data diversity by varying domain-variant features such as colour, style and texture in images. However, excessive stylization or even uniform stylization may reduce performance. Performance reduction is especially pronounced for pixels from minority classes, which are already more challenging to classify compared to pixels from majority classes. Therefore, we introduce a module, $ASH_{+}$, that modulates stylization strength for each pixel depending on the pixel's semantic content. In this work, we also introduce a parameter that balances the element-wise and channel-wise proportion of stylized features with the original source domain features in the stylized source domain images. This learned parameter replaces an empirically determined global hyperparameter, allowing for more fine-grained control over the output stylized image. We conduct multiple experiments to validate the effectiveness of our proposed method. Finally, we evaluate our model on the publicly available benchmark semantic segmentation datasets (Cityscapes and SYNTHIA). Quantitative and qualitative comparisons indicate that our approach is competitive with state-of-the-art. Code is made available at \url{https://github.com/placeholder}
Motion Artifacts Detection in Short-scan Dental CBCT Reconstructions
Apr 20, 2023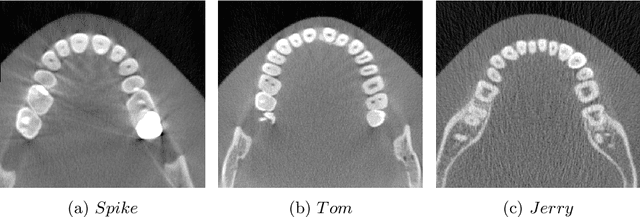
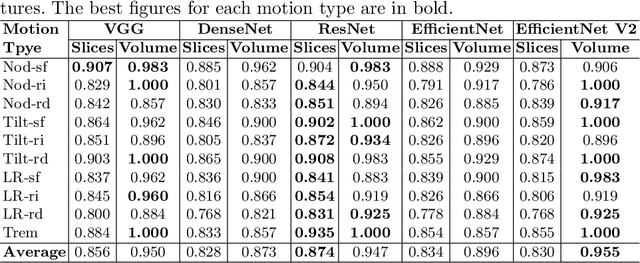
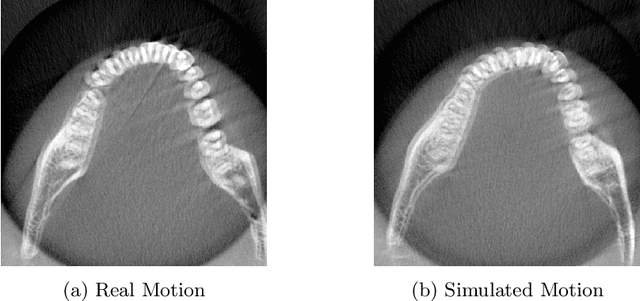
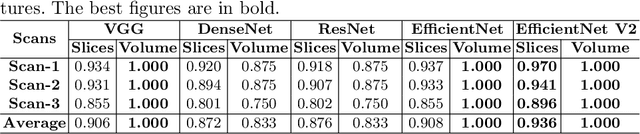
Cone Beam Computed Tomography (CBCT) is widely used in dentistry for diagnostics and treatment planning. CBCT Imaging has a long acquisition time and consequently, the patient is likely to move. This motion causes significant artifacts in the reconstructed data which may lead to misdiagnosis. Existing motion correction algorithms only address this issue partially, struggling with inconsistencies due to truncation, accuracy, and execution speed. On the other hand, a short-scan reconstruction using a subset of motion-free projections with appropriate weighting methods can have a sufficient clinical image quality for most diagnostic purposes. Therefore, a framework is used in this study to extract the motion-free part of the scanned projections with which a clean short-scan volume can be reconstructed without using correction algorithms. Motion artifacts are detected using deep learning with a slice-based prediction scheme followed by volume averaging to get the final result. A realistic motion simulation strategy and data augmentation has been implemented to address data scarcity. The framework has been validated by testing it with real motion-affected data while the model was trained only with simulated motion data. This shows the feasibility to apply the proposed framework to a broad variety of motion cases for further research.
Diffusion Models for Memory-efficient Processing of 3D Medical Images
Mar 27, 2023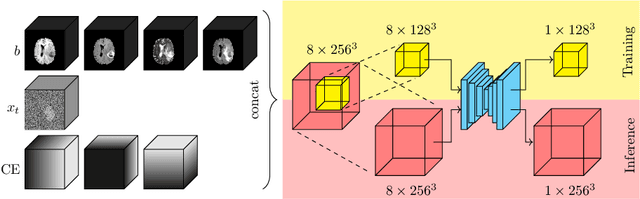

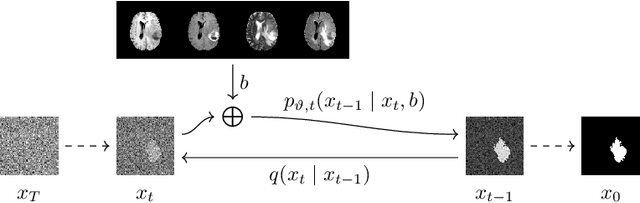
Denoising diffusion models have recently achieved state-of-the-art performance in many image-generation tasks. They do, however, require a large amount of computational resources. This limits their application to medical tasks, where we often deal with large 3D volumes, like high-resolution three-dimensional data. In this work, we present a number of different ways to reduce the resource consumption for 3D diffusion models and apply them to a dataset of 3D images. The main contribution of this paper is the memory-efficient patch-based diffusion model \textit{PatchDDM}, which can be applied to the total volume during inference while the training is performed only on patches. While the proposed diffusion model can be applied to any image generation tasks, we evaluate the method on the tumor segmentation task of the BraTS2020 dataset and demonstrate that we can generate meaningful three-dimensional segmentations.
Human Pose Estimation in Extremely Low-Light Conditions
Mar 27, 2023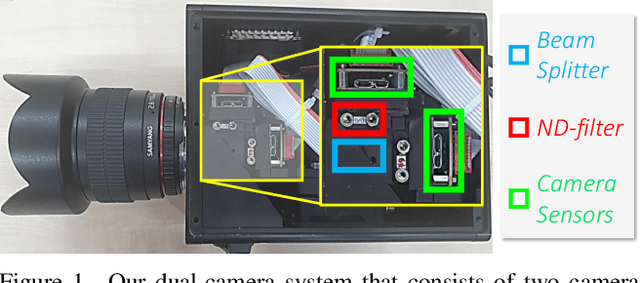


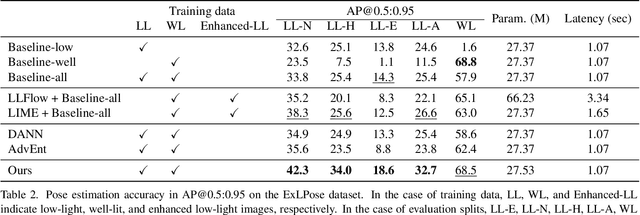
We study human pose estimation in extremely low-light images. This task is challenging due to the difficulty of collecting real low-light images with accurate labels, and severely corrupted inputs that degrade prediction quality significantly. To address the first issue, we develop a dedicated camera system and build a new dataset of real low-light images with accurate pose labels. Thanks to our camera system, each low-light image in our dataset is coupled with an aligned well-lit image, which enables accurate pose labeling and is used as privileged information during training. We also propose a new model and a new training strategy that fully exploit the privileged information to learn representation insensitive to lighting conditions. Our method demonstrates outstanding performance on real extremely low light images, and extensive analyses validate that both of our model and dataset contribute to the success.
Good helper is around you: Attention-driven Masked Image Modeling
Dec 01, 2022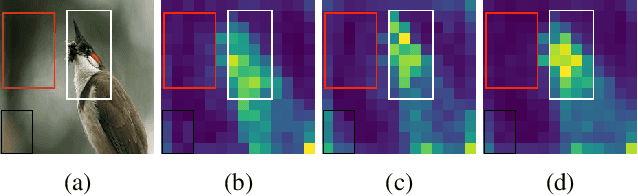

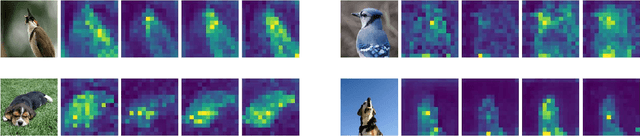
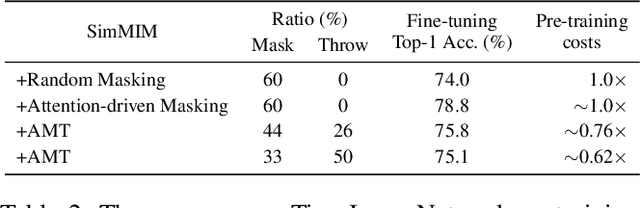
It has been witnessed that masked image modeling (MIM) has shown a huge potential in self-supervised learning in the past year. Benefiting from the universal backbone vision transformer, MIM learns self-supervised visual representations through masking a part of patches of the image while attempting to recover the missing pixels. Most previous works mask patches of the image randomly, which underutilizes the semantic information that is beneficial to visual representation learning. On the other hand, due to the large size of the backbone, most previous works have to spend much time on pre-training. In this paper, we propose \textbf{Attention-driven Masking and Throwing Strategy} (AMT), which could solve both problems above. We first leverage the self-attention mechanism to obtain the semantic information of the image during the training process automatically without using any supervised methods. Masking strategy can be guided by that information to mask areas selectively, which is helpful for representation learning. Moreover, a redundant patch throwing strategy is proposed, which makes learning more efficient. As a plug-and-play module for masked image modeling, AMT improves the linear probing accuracy of MAE by $2.9\% \sim 5.9\%$ on CIFAR-10/100, STL-10, Tiny ImageNet, and ImageNet-1K, and obtains an improved performance with respect to fine-tuning accuracy of MAE and SimMIM. Moreover, this design also achieves superior performance on downstream detection and segmentation tasks. Code is available at https://github.com/guijiejie/AMT.
ChatGPT Asks, BLIP-2 Answers: Automatic Questioning Towards Enriched Visual Descriptions
Mar 12, 2023

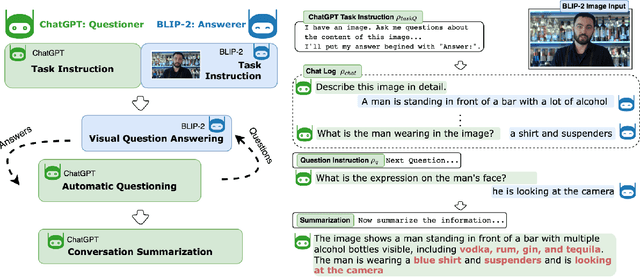
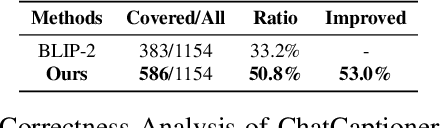
Asking insightful questions is crucial for acquiring knowledge and expanding our understanding of the world. However, the importance of questioning has been largely overlooked in AI research, where models have been primarily developed to answer questions. With the recent advancements of large language models (LLMs) like ChatGPT, we discover their capability to ask high-quality questions when provided with a suitable prompt. This discovery presents a new opportunity to develop an automatic questioning system. In this paper, we introduce ChatCaptioner, a novel automatic-questioning method deployed in image captioning. Here, ChatGPT is prompted to ask a series of informative questions about images to BLIP-2, a strong vision question-answering model. By keeping acquiring new visual information from BLIP-2's answers, ChatCaptioner is able to generate more enriched image descriptions. We conduct human-subject evaluations on common image caption datasets such as COCO, Conceptual Caption, and WikiArt, and compare ChatCaptioner with BLIP-2 as well as ground truth. Our results demonstrate that ChatCaptioner's captions are significantly more informative, receiving three times as many votes from human evaluators for providing the most image information. Besides, ChatCaptioner identifies 53% more objects within the image than BLIP-2 alone measured by WordNet synset matching. Code is available at https://github.com/Vision-CAIR/ChatCaptioner
Open-Vocabulary Object Detection using Pseudo Caption Labels
Mar 23, 2023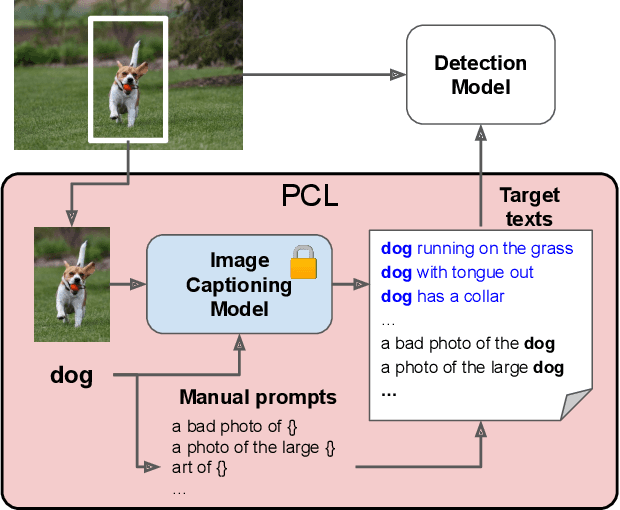
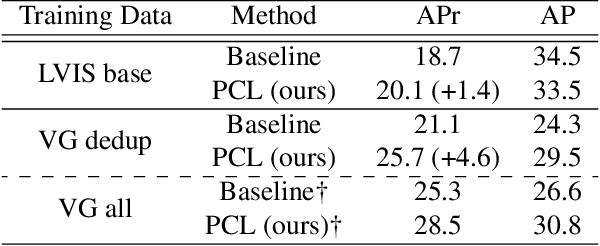
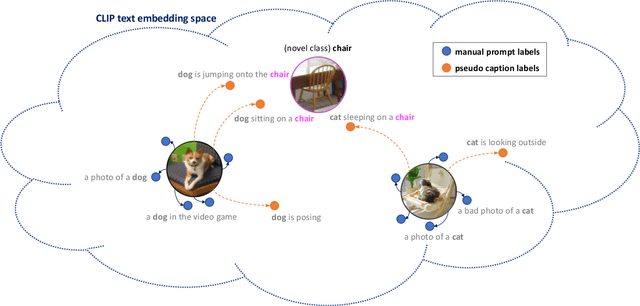
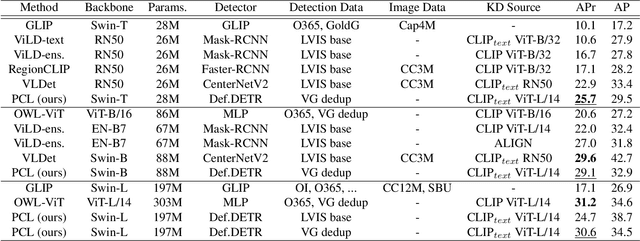
Recent open-vocabulary detection methods aim to detect novel objects by distilling knowledge from vision-language models (VLMs) trained on a vast amount of image-text pairs. To improve the effectiveness of these methods, researchers have utilized datasets with a large vocabulary that contains a large number of object classes, under the assumption that such data will enable models to extract comprehensive knowledge on the relationships between various objects and better generalize to unseen object classes. In this study, we argue that more fine-grained labels are necessary to extract richer knowledge about novel objects, including object attributes and relationships, in addition to their names. To address this challenge, we propose a simple and effective method named Pseudo Caption Labeling (PCL), which utilizes an image captioning model to generate captions that describe object instances from diverse perspectives. The resulting pseudo caption labels offer dense samples for knowledge distillation. On the LVIS benchmark, our best model trained on the de-duplicated VisualGenome dataset achieves an AP of 34.5 and an APr of 30.6, comparable to the state-of-the-art performance. PCL's simplicity and flexibility are other notable features, as it is a straightforward pre-processing technique that can be used with any image captioning model without imposing any restrictions on model architecture or training process.