 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mask Hierarchical Features For Self-Supervised Learning
Apr 01, 2023
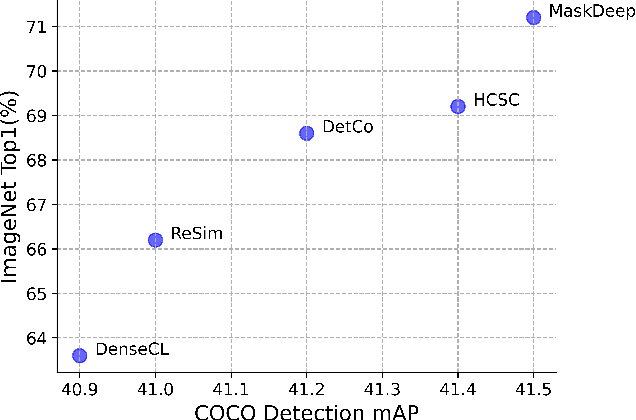
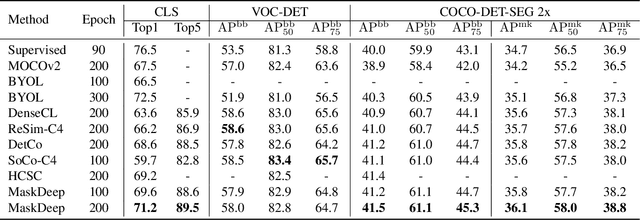
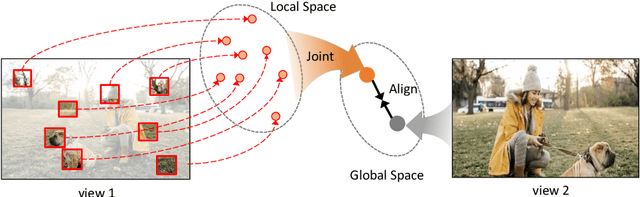
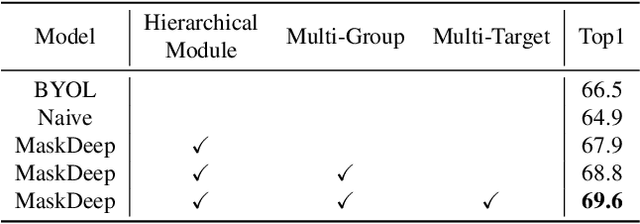
This paper shows that Masking the Deep hierarchical features is an efficient self-supervised method, denoted as MaskDeep. MaskDeep treats each patch in the representation space as an independent instance. We mask part of patches in the representation space and then utilize sparse visible patches to reconstruct high semantic image representation. The intuition of MaskDeep lies in the fact that models can reason from sparse visible patches semantic to the global semantic of the image. We further propose three designs in our framework: 1) a Hierarchical Deep-Masking module to concern the hierarchical property of patch representations, 2) a multi-group strategy to improve the efficiency without any extra computing consumption of the encoder and 3) a multi-target strategy to provide more description of the global semantic. Our MaskDeep brings decent improvements. Trained on ResNet50 with 200 epochs, MaskDeep achieves state-of-the-art results of 71.2% Top1 accuracy linear classification on ImageNet. On COCO object detection tasks, MaskDeep outperforms the self-supervised method SoCo, which specifically designed for object detection. When trained with 100 epochs, MaskDeep achieves 69.6% Top1 accuracy, which surpasses current methods trained with 200 epochs, such as HCSC, by 0.4% .
MedSegDiff: Medical Image Segmentation with Diffusion Probabilistic Model
Nov 16, 2022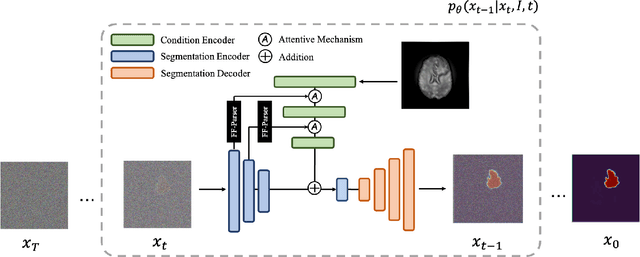
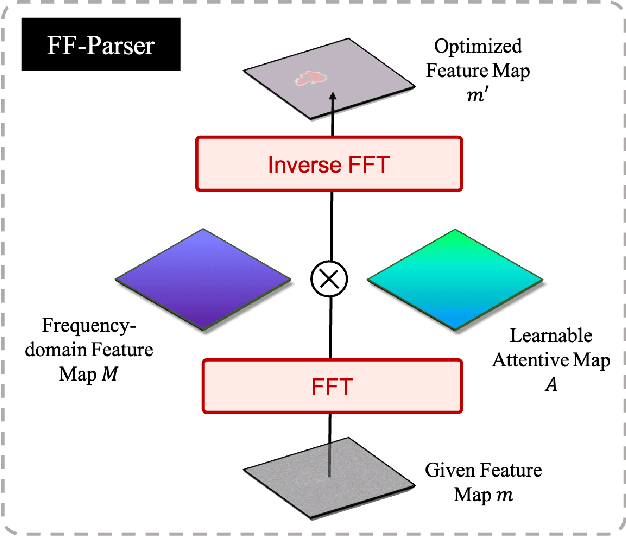
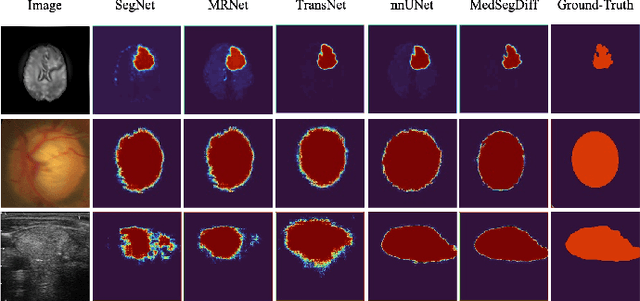
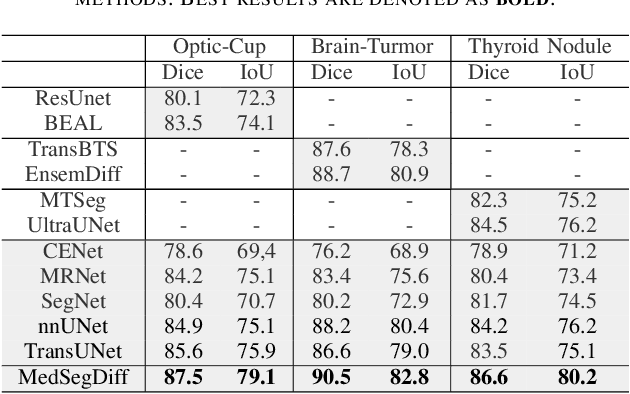
Diffusion probabilistic model (DPM) recently becomes one of the hottest topic in computer vision. Its image generation application such as Imagen, Latent Diffusion Models and Stable Diffusion have shown impressive generation capabilities, which aroused extensive discussion in the community. Many recent studies also found it useful in many other vision tasks, like image deblurring, super-resolution and anomaly detection. Inspired by the success of DPM, we propose the first DPM based model toward general medical image segmentation tasks, which we named MedSegDiff. In order to enhance the step-wise regional attention in DPM for the medical image segmentation, we propose dynamic conditional encoding, which establishes the state-adaptive conditions for each sampling step. We further propose Feature Frequency Parser (FF-Parser), to eliminate the negative effect of high-frequency noise component in this process. We verify MedSegDiff on three medical segmentation tasks with different image modalities, which are optic cup segmentation over fundus images, brain tumor segmentation over MRI images and thyroid nodule segmentation over ultrasound images. The experimental results show that MedSegDiff outperforms state-of-the-art (SOTA) methods with considerable performance gap, indicating the generalization and effectiveness of the proposed model.
Eye Image-based Algorithms to Estimate Percentage Closure of Eye and Saccadic Ratio for Alertness Detection
Jan 30, 2023
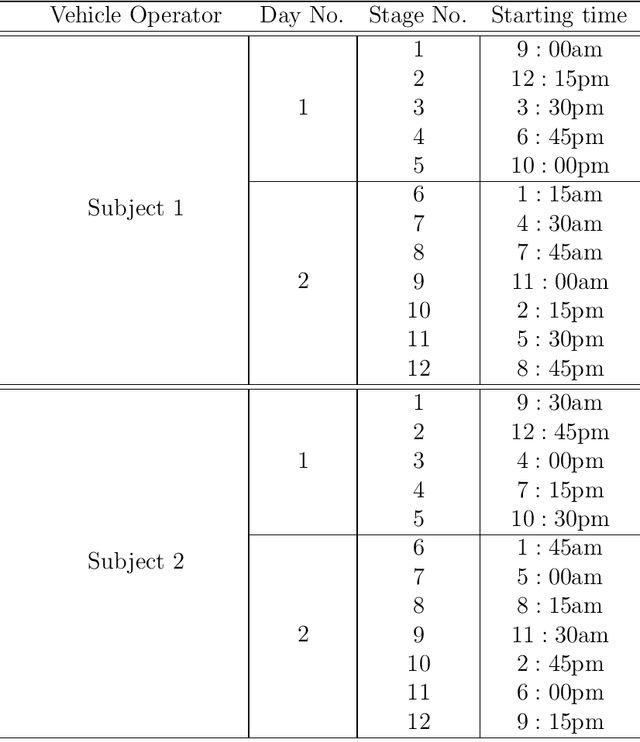


The current research work has developed two novel algorithms for image-based measurement of Percentage Closure of Eyes-PERCLOS and Saccadic Ratio-SR. The PERCLOS is estimated by correlation filter-based technique. An innovative combination of gray scale and Near Infrared sensitive camera with passive NIR illuminator helps to achieve higher accuracy than the existing art. Two novel techniques have been developed for the detection of iris centre and eye corners. We propose an index called Form Factor to find the iris position. The saccadic velocity profile can be estimated from the temporal information of the iris positions using standard tracking algorithm such as Extended Kalman filter. Experimental results indicate that the estimation of both SR and PERCLOS can predict the level of alertness of an operator from onset of diminished alertness to fatigue.
Features-over-the-Air: Contrastive Learning Enabled Cooperative Edge Inference
Apr 17, 2023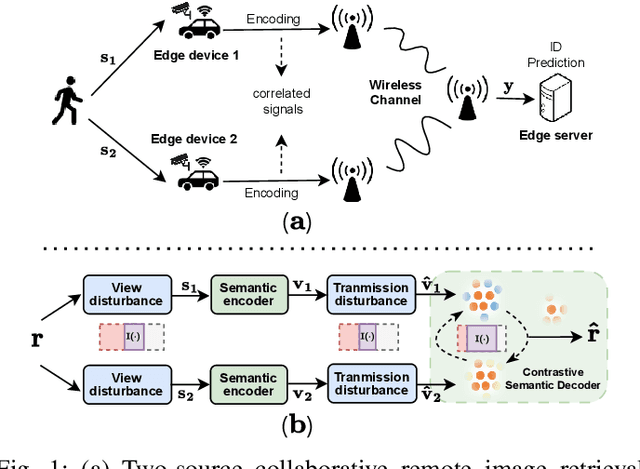

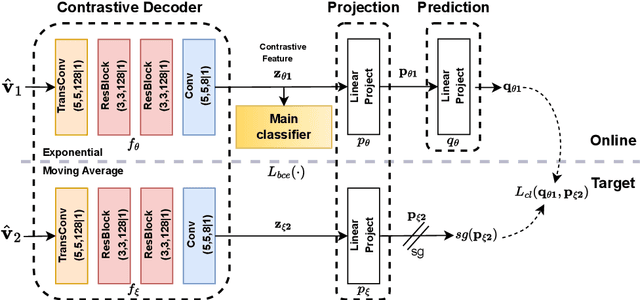
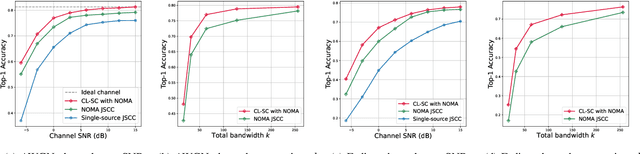
We study the collaborative image retrieval problem at the wireless edge, where multiple edge devices capture images of the same object, which are then used jointly to retrieve similar images at the edge server over a shared multiple access channel. We propose a semantic non-orthogonal multiple access (NOMA) communication paradigm, in which extracted features from each device are mapped directly to channel inputs, which are then added over-the-air. We propose a novel contrastive learning (CL)-based semantic communication (CL-SC) paradigm, aiming to exploit signal correlations to maximize the retrieval accuracy under a total bandwidth constraints. Specifically, we treat noisy correlated signals as different augmentations of a common identity, and propose a cross-view CL algorithm to optimize the correlated signals in a coarse-to-fine fashion to improve retrieval accuracy. Extensive numerical experiments verify that our method achieves the state-of-the-art performance and can significantly improve retrieval accuracy, with particularly significant gains in low signla-to-noise ratio (SNR) and limited bandwidth regimes.
Single-Stage Diffusion NeRF: A Unified Approach to 3D Generation and Reconstruction
Apr 17, 2023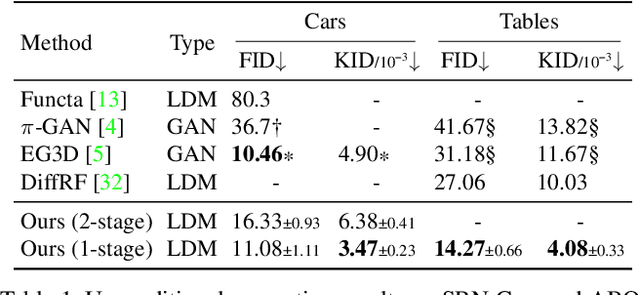


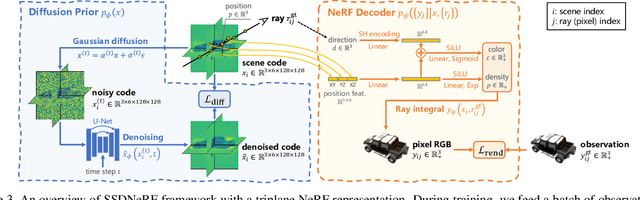
3D-aware image synthesis encompasses a variety of tasks, such as scene generation and novel view synthesis from images. Despite numerous task-specific methods, developing a comprehensive model remains challenging. In this paper, we present SSDNeRF, a unified approach that employs an expressive diffusion model to learn a generalizable prior of neural radiance fields (NeRF) from multi-view images of diverse objects. Previous studies have used two-stage approaches that rely on pretrained NeRFs as real data to train diffusion models. In contrast, we propose a new single-stage training paradigm with an end-to-end objective that jointly optimizes a NeRF auto-decoder and a latent diffusion model, enabling simultaneous 3D reconstruction and prior learning, even from sparsely available views. At test time, we can directly sample the diffusion prior for unconditional generation, or combine it with arbitrary observations of unseen objects for NeRF reconstruction. SSDNeRF demonstrates robust results comparable to or better than leading task-specific methods in unconditional generation and single/sparse-view 3D reconstruction.
OOD-CV-v2: An extended Benchmark for Robustness to Out-of-Distribution Shifts of Individual Nuisances in Natural Images
Apr 17, 2023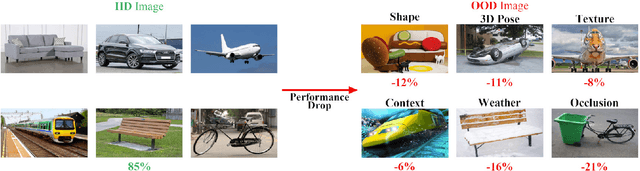
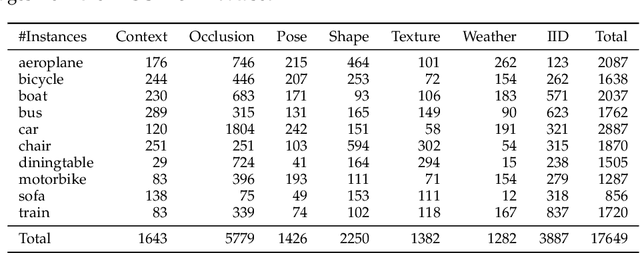


Enhancing the robustness of vision algorithms in real-world scenarios is challenging. One reason is that existing robustness benchmarks are limited, as they either rely on synthetic data or ignore the effects of individual nuisance factors. We introduce OOD-CV-v2, a benchmark dataset that includes out-of-distribution examples of 10 object categories in terms of pose, shape, texture, context and the weather conditions, and enables benchmarking of models for image classification, object detection, and 3D pose estimation. In addition to this novel dataset, we contribute extensive experiments using popular baseline methods, which reveal that: 1) Some nuisance factors have a much stronger negative effect on the performance compared to others, also depending on the vision task. 2) Current approaches to enhance robustness have only marginal effects, and can even reduce robustness. 3) We do not observe significant differences between convolutional and transformer architectures. We believe our dataset provides a rich test bed to study robustness and will help push forward research in this area. Our dataset can be accessed from http://www.ood-cv.org/challenge.html
JPEG Compressed Images Can Bypass Protections Against AI Editing
Apr 07, 2023

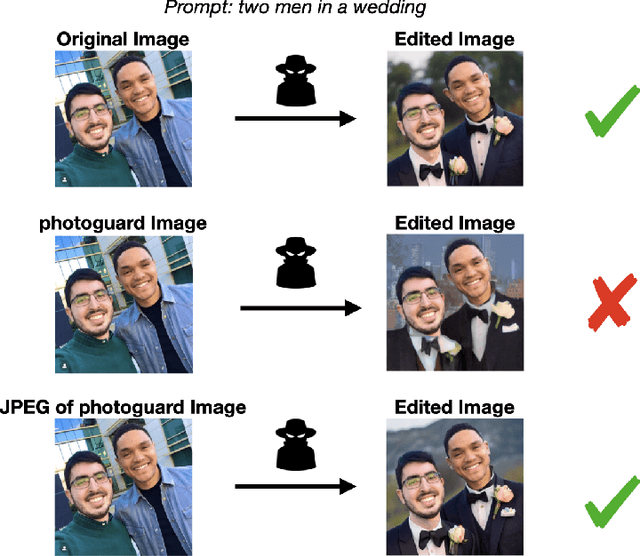

Recently developed text-to-image diffusion models make it easy to edit or create high-quality images. Their ease of use has raised concerns about the potential for malicious editing or deepfake creation. Imperceptible perturbations have been proposed as a means of protecting images from malicious editing by preventing diffusion models from generating realistic images. However, we find that the aforementioned perturbations are not robust to JPEG compression, which poses a major weakness because of the common usage and availability of JPEG. We discuss the importance of robustness for additive imperceptible perturbations and encourage alternative approaches to protect images against editing.
A Multi-Stream Fusion Network for Image Splicing Localization
Dec 02, 2022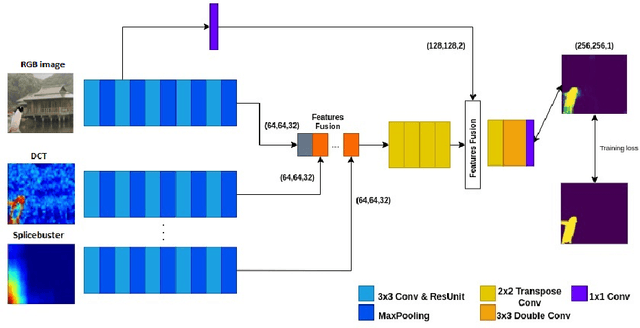
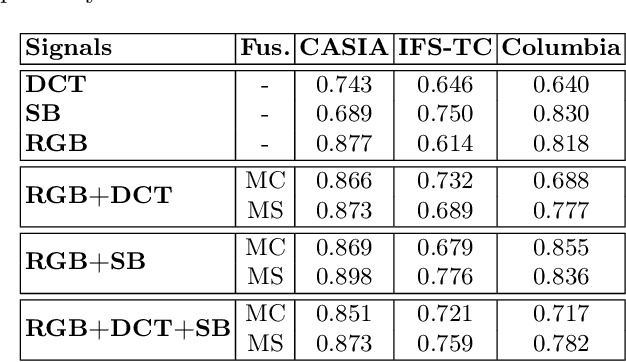
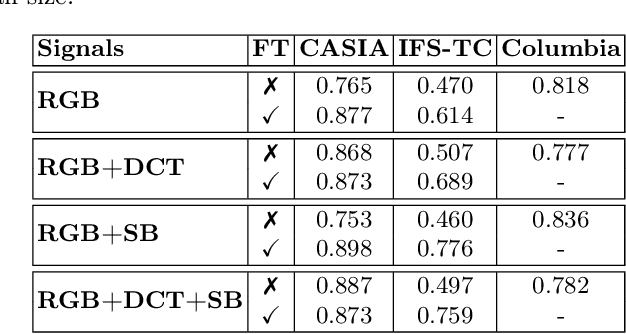

In this paper, we address the problem of image splicing localization with a multi-stream network architecture that processes the raw RGB image in parallel with other handcrafted forensic signals. Unlike previous methods that either use only the RGB images or stack several signals in a channel-wise manner, we propose an encoder-decoder architecture that consists of multiple encoder streams. Each stream is fed with either the tampered image or handcrafted signals and processes them separately to capture relevant information from each one independently. Finally, the extracted features from the multiple streams are fused in the bottleneck of the architecture and propagated to the decoder network that generates the output localization map. We experiment with two handcrafted algorithms, i.e., DCT and Splicebuster. Our proposed approach is benchmarked on three public forensics datasets, demonstrating competitive performance against several competing methods and achieving state-of-the-art results, e.g., 0.898 AUC on CASIA.
The Case for Hierarchical Deep Learning Inference at the Network Edge
Apr 23, 2023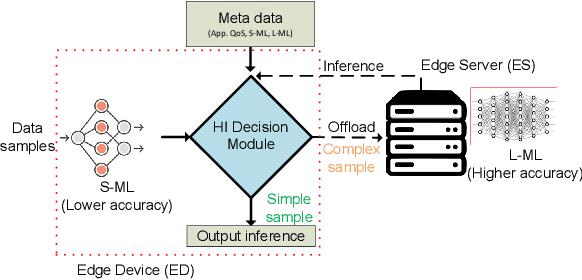
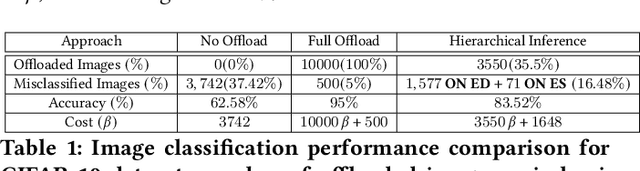


Resource-constrained Edge Devices (EDs), e.g., IoT sensors and microcontroller units, are expected to make intelligent decisions using Deep Learning (DL) inference at the edge of the network. Toward this end, there is a significant research effort in developing tinyML models - Deep Learning (DL) models with reduced computation and memory storage requirements - that can be embedded on these devices. However, tinyML models have lower inference accuracy. On a different front, DNN partitioning and inference offloading techniques were studied for distributed DL inference between EDs and Edge Servers (ESs). In this paper, we explore Hierarchical Inference (HI), a novel approach proposed by Vishnu et al. 2023, arXiv:2304.00891v1 , for performing distributed DL inference at the edge. Under HI, for each data sample, an ED first uses a local algorithm (e.g., a tinyML model) for inference. Depending on the application, if the inference provided by the local algorithm is incorrect or further assistance is required from large DL models on edge or cloud, only then the ED offloads the data sample. At the outset, HI seems infeasible as the ED, in general, cannot know if the local inference is sufficient or not. Nevertheless, we present the feasibility of implementing HI for machine fault detection and image classification applications. We demonstrate its benefits using quantitative analysis and argue that using HI will result in low latency, bandwidth savings, and energy savings in edge AI systems.
A Lightweight Recurrent Learning Network for Sustainable Compressed Sensing
Apr 23, 2023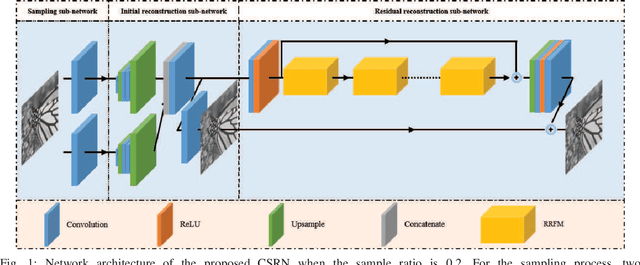
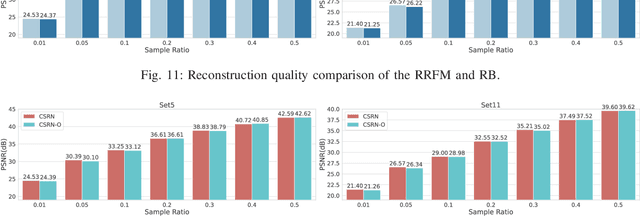
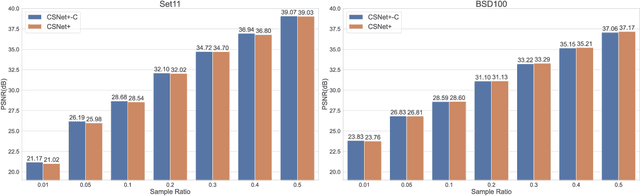
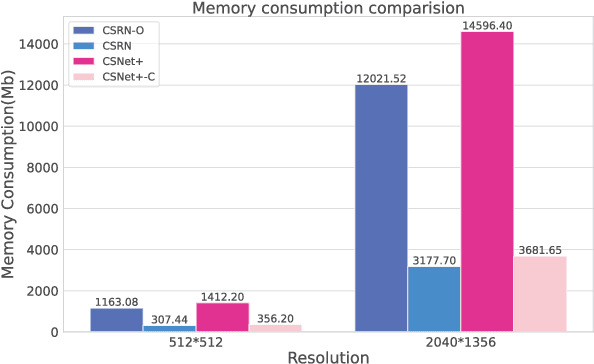
Recently, deep learning-based compressed sensing (CS) has achieved great success in reducing the sampling and computational cost of sensing systems and improving the reconstruction quality. These approaches, however, largely overlook the issue of the computational cost; they rely on complex structures and task-specific operator designs, resulting in extensive storage and high energy consumption in CS imaging systems. In this paper, we propose a lightweight but effective deep neural network based on recurrent learning to achieve a sustainable CS system; it requires a smaller number of parameters but obtains high-quality reconstructions. Specifically, our proposed network consists of an initial reconstruction sub-network and a residual reconstruction sub-network. While the initial reconstruction sub-network has a hierarchical structure to progressively recover the image, reducing the number of parameters, the residual reconstruction sub-network facilitates recurrent residual feature extraction via recurrent learning to perform both feature fusion and deep reconstructions across different scales. In addition, we also demonstrate that, after the initial reconstruction, feature maps with reduced sizes are sufficient to recover the residual information, and thus we achieved a significant reduction in the amount of memory required. Extensive experiments illustrate that our proposed model can achieve a better reconstruction quality than existing state-of-the-art CS algorithms, and it also has a smaller number of network parameters than these algorithms. Our source codes are available at: https://github.com/C66YU/CSRN.