 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Shot Noise Reduction in Radiographic and Tomographic Multi-Channel Imaging with Self-Supervised Deep Learning
Mar 25, 2023
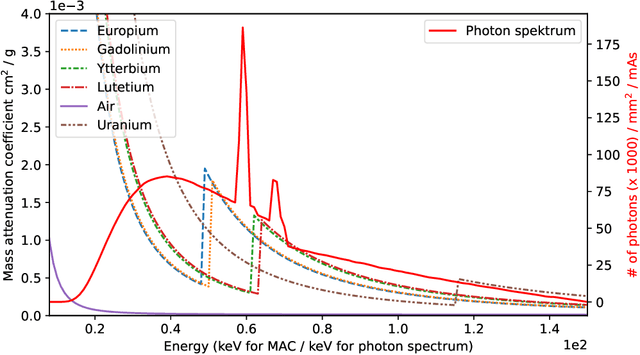
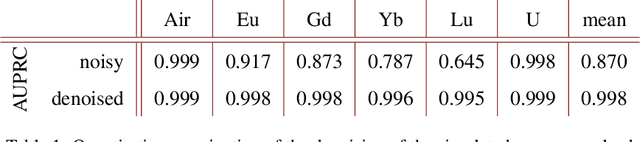
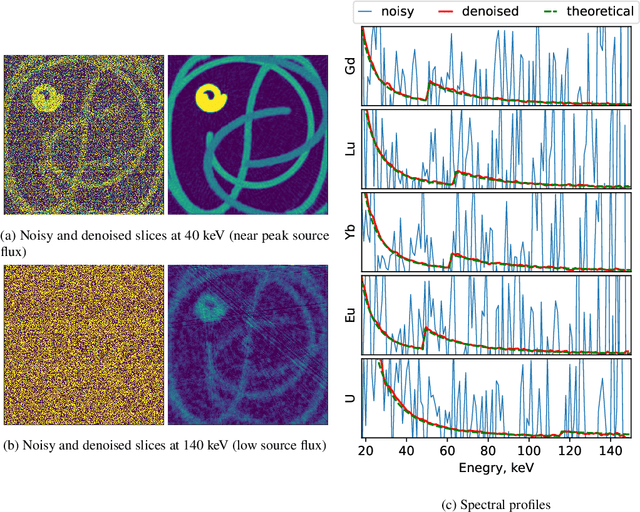

Noise is an important issue for radiographic and tomographic imaging techniques. It becomes particularly critical in applications where additional constraints force a strong reduction of the Signal-to-Noise Ratio (SNR) per image. These constraints may result from limitations on the maximum available flux or permissible dose and the associated restriction on exposure time. Often, a high SNR per image is traded for the ability to distribute a given total exposure capacity per pixel over multiple channels, thus obtaining additional information about the object by the same total exposure time. These can be energy channels in the case of spectroscopic imaging or time channels in the case of time-resolved imaging. In this paper, we report on a method for improving the quality of noisy multi-channel (time or energy-resolved) imaging datasets. The method relies on the recent Noise2Noise (N2N) self-supervised denoising approach that learns to predict a noise-free signal without access to noise-free data. N2N in turn requires drawing pairs of samples from a data distribution sharing identical signals while being exposed to different samples of random noise. The method is applicable if adjacent channels share enough information to provide images with similar enough information but independent noise. We demonstrate several representative case studies, namely spectroscopic (k-edge) X-ray tomography, in vivo X-ray cine-radiography, and energy-dispersive (Bragg edge) neutron tomography. In all cases, the N2N method shows dramatic improvement and outperforms conventional denoising methods. For such imaging techniques, the method can therefore significantly improve image quality, or maintain image quality with further reduced exposure time per image.
Quantum median filter for Total Variation image denoising
Dec 02, 2022In this new computing paradigm, named quantum computing, researchers from all over the world are taking their first steps in designing quantum circuits for image processing, through a difficult process of knowledge transfer. This effort is named Quantum Image Processing, an emerging research field pushed by powerful parallel computing capabilities of quantum computers. This work goes in this direction and proposes the challenging development of a powerful method of image denoising, such as the Total Variation (TV) model, in a quantum environment. The proposed Quantum TV is described and its sub-components are analysed. Despite the natural limitations of the current capabilities of quantum devices, the experimental results show a competitive denoising performance compared to the classical variational TV counterpart.
Regularizing Self-training for Unsupervised Domain Adaptation via Structural Constraints
Apr 29, 2023
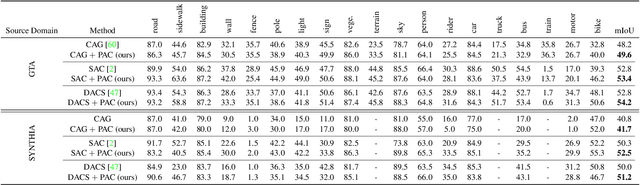
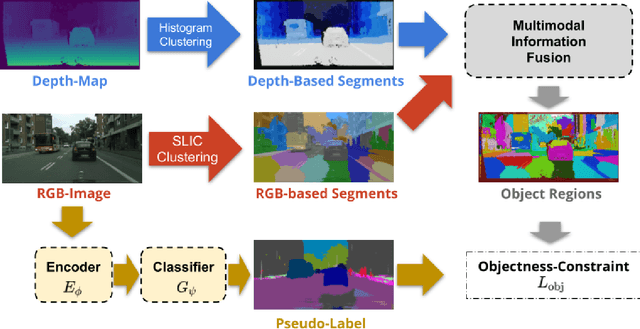
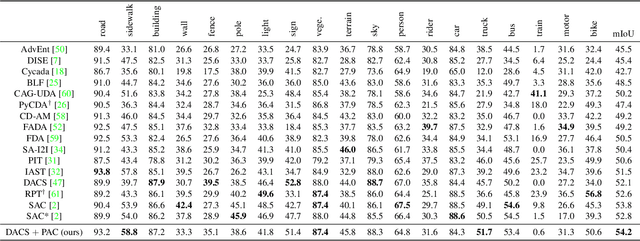
Self-training based on pseudo-labels has emerged as a dominant approach for addressing conditional distribution shifts in unsupervised domain adaptation (UDA) for semantic segmentation problems. A notable drawback, however, is that this family of approaches is susceptible to erroneous pseudo labels that arise from confirmation biases in the source domain and that manifest as nuisance factors in the target domain. A possible source for this mismatch is the reliance on only photometric cues provided by RGB image inputs, which may ultimately lead to sub-optimal adaptation. To mitigate the effect of mismatched pseudo-labels, we propose to incorporate structural cues from auxiliary modalities, such as depth, to regularise conventional self-training objectives. Specifically, we introduce a contrastive pixel-level objectness constraint that pulls the pixel representations within a region of an object instance closer, while pushing those from different object categories apart. To obtain object regions consistent with the true underlying object, we extract information from both depth maps and RGB-images in the form of multimodal clustering. Crucially, the objectness constraint is agnostic to the ground-truth semantic labels and, hence, appropriate for unsupervised domain adaptation. In this work, we show that our regularizer significantly improves top performing self-training methods (by up to $2$ points) in various UDA benchmarks for semantic segmentation. We include all code in the supplementary.
Noise-Tolerance GPU-based Age Estimation Using ResNet-50
Apr 26, 2023
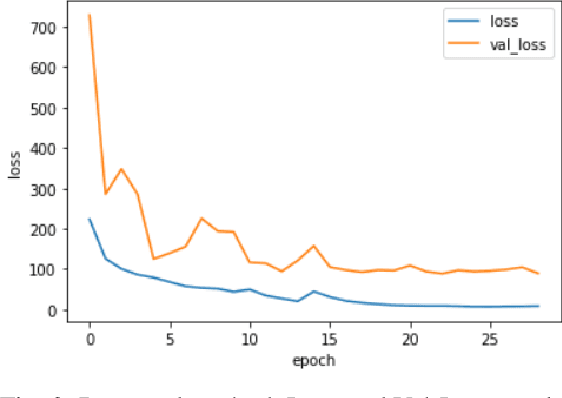
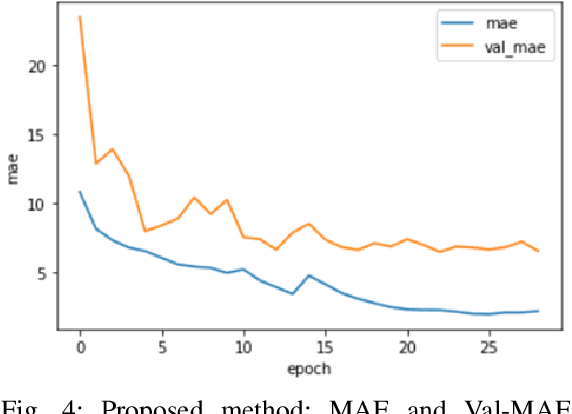
The human face contains important and understandable information such as personal identity, gender, age, and ethnicity. In recent years, a person's age has been studied as one of the important features of the face. The age estimation system consists of a combination of two modules, the presentation of the face image and the extraction of age characteristics, and then the detection of the exact age or age group based on these characteristics. So far, various algorithms have been presented for age estimation, each of which has advantages and disadvantages. In this work, we implemented a deep residual neural network on the UTKFace data set. We validated our implementation by comparing it with the state-of-the-art implementations of different age estimation algorithms and the results show 28.3% improvement in MAE as one of the critical error validation metrics compared to the recent works and also 71.39% MAE improvements compared to the implemented AlexNet. In the end, we show that the performance degradation of our implemented network is lower than 1.5% when injecting 15 dB noise to the input data (5 times more than the normal environmental noise) which justifies the noise tolerance of our proposed method.
Distance Weighted Supervised Learning for Offline Interaction Data
Apr 26, 2023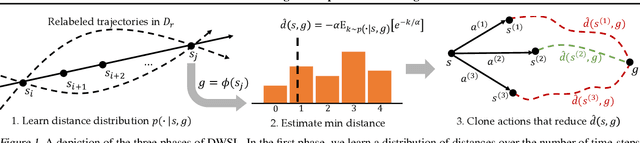
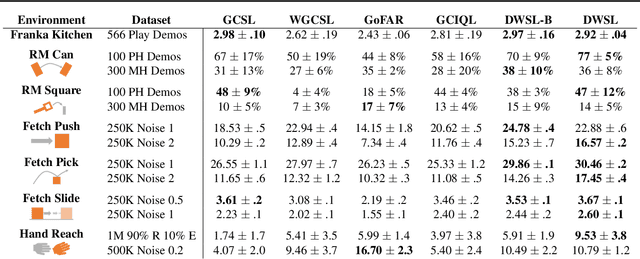
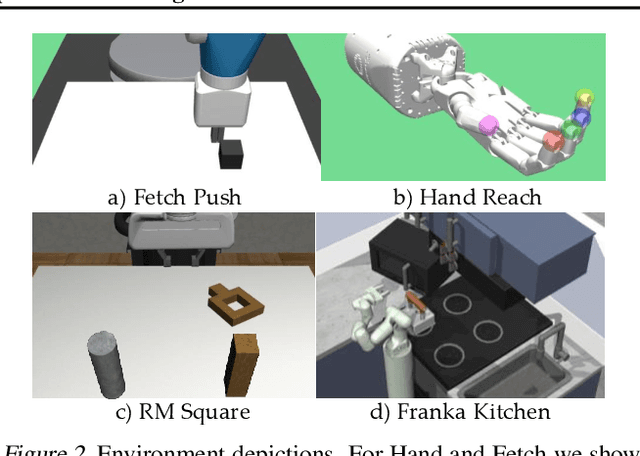
Sequential decision making algorithms often struggle to leverage different sources of unstructured offline interaction data. Imitation learning (IL) methods based on supervised learning are robust, but require optimal demonstrations, which are hard to collect. Offline goal-conditioned reinforcement learning (RL) algorithms promise to learn from sub-optimal data, but face optimization challenges especially with high-dimensional data. To bridge the gap between IL and RL, we introduce Distance Weighted Supervised Learning or DWSL, a supervised method for learning goal-conditioned policies from offline data. DWSL models the entire distribution of time-steps between states in offline data with only supervised learning, and uses this distribution to approximate shortest path distances. To extract a policy, we weight actions by their reduction in distance estimates. Theoretically, DWSL converges to an optimal policy constrained to the data distribution, an attractive property for offline learning, without any bootstrapping. Across all datasets we test, DWSL empirically maintains behavior cloning as a lower bound while still exhibiting policy improvement. In high-dimensional image domains, DWSL surpasses the performance of both prior goal-conditioned IL and RL algorithms. Visualizations and code can be found at https://sites.google.com/view/dwsl/home .
Adaptive Uncertainty Distribution in Deep Learning for Unsupervised Underwater Image Enhancement
Dec 18, 2022

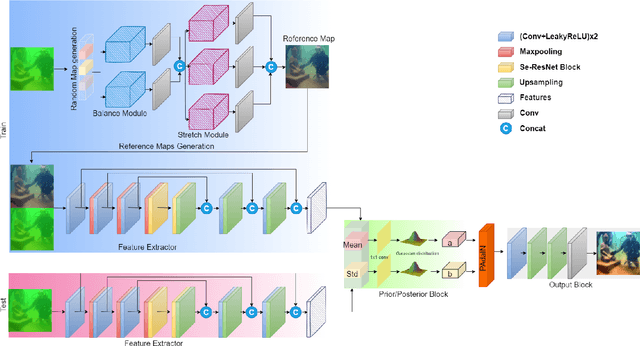

One of the main challenges in deep learning-based underwater image enhancement is the limited availability of high-quality training data. Underwater images are difficult to capture and are often of poor quality due to the distortion and loss of colour and contrast in water. This makes it difficult to train supervised deep learning models on large and diverse datasets, which can limit the model's performance. In this paper, we explore an alternative approach to supervised underwater image enhancement. Specifically, we propose a novel unsupervised underwater image enhancement framework that employs a conditional variational autoencoder (cVAE) to train a deep learning model with probabilistic adaptive instance normalization (PAdaIN) and statistically guided multi-colour space stretch that produces realistic underwater images. The resulting framework is composed of a U-Net as a feature extractor and a PAdaIN to encode the uncertainty, which we call UDnet. To improve the visual quality of the images generated by UDnet, we use a statistically guided multi-colour space stretch module that ensures visual consistency with the input image and provides an alternative to training using a ground truth image. The proposed model does not need manual human annotation and can learn with a limited amount of data and achieves state-of-the-art results on underwater images. We evaluated our proposed framework on eight publicly-available datasets. The results show that our proposed framework yields competitive performance compared to other state-of-the-art approaches in quantitative as well as qualitative metrics. Code available at https://github.com/alzayats/UDnet .
Cross-modal tumor segmentation using generative blending augmentation and self training
Apr 04, 2023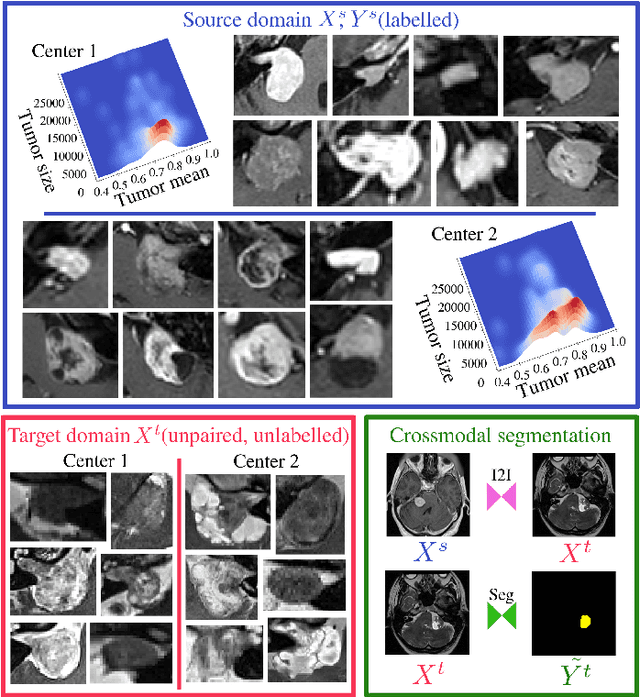
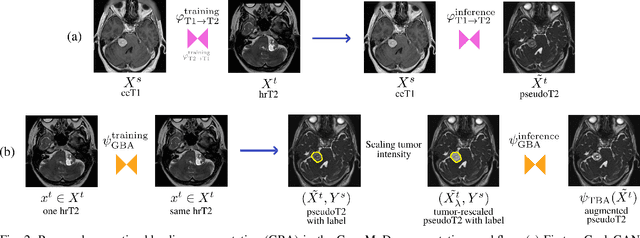
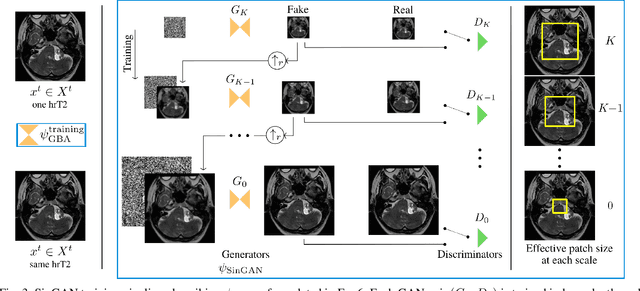
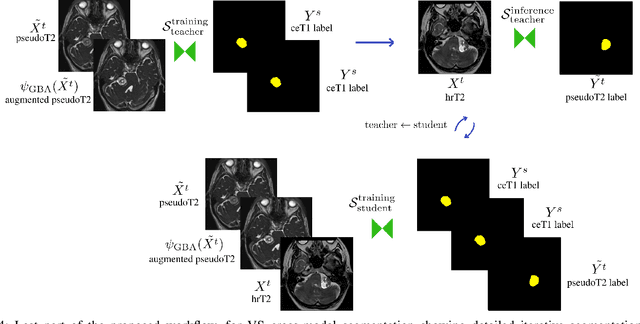
Deep learning for medical imaging is limited by data scarcity and domain shift, which lead to biased training sets that do not accurately represent deployment conditions. A related practical problem is cross-modal segmentation where the objective is to segment unlabelled domains using previously labelled images from other modalites, which is the context of the MICCAI CrossMoDA 2022 challenge on vestibular schwannoma (VS) segmentation. In this context, we propose a VS segmentation method that leverages conventional image-to-image translation and segmentation using iterative self training combined to a dedicated data augmentation technique called Generative Blending Augmentation (GBA). GBA is based on a one-shot 2D SinGAN generative model that allows to realistically diversify target tumor appearances in a downstream segmentation model, improving its generalization power at test time. Our solution ranked first on the VS segmentation task during the validation and test phase of the CrossModa 2022 challenge.
Learning to Name Classes for Vision and Language Models
Apr 04, 2023
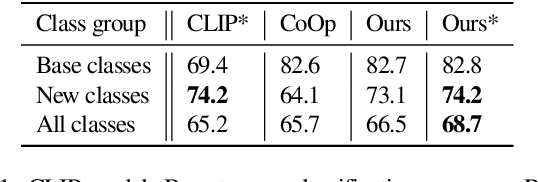
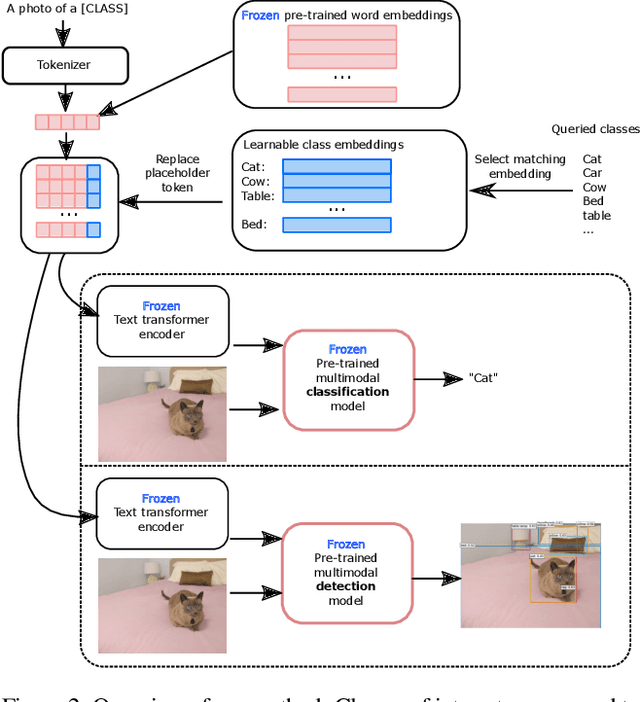
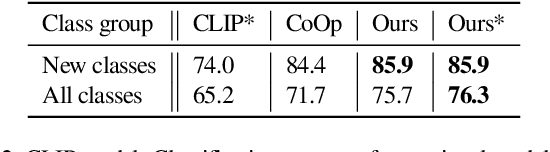
Large scale vision and language models can achieve impressive zero-shot recognition performance by mapping class specific text queries to image content. Two distinct challenges that remain however, are high sensitivity to the choice of handcrafted class names that define queries, and the difficulty of adaptation to new, smaller datasets. Towards addressing these problems, we propose to leverage available data to learn, for each class, an optimal word embedding as a function of the visual content. By learning new word embeddings on an otherwise frozen model, we are able to retain zero-shot capabilities for new classes, easily adapt models to new datasets, and adjust potentially erroneous, non-descriptive or ambiguous class names. We show that our solution can easily be integrated in image classification and object detection pipelines, yields significant performance gains in multiple scenarios and provides insights into model biases and labelling errors.
Open-Vocabulary Temporal Action Detection with Off-the-Shelf Image-Text Features
Dec 20, 2022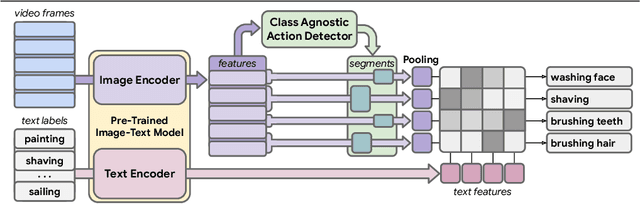
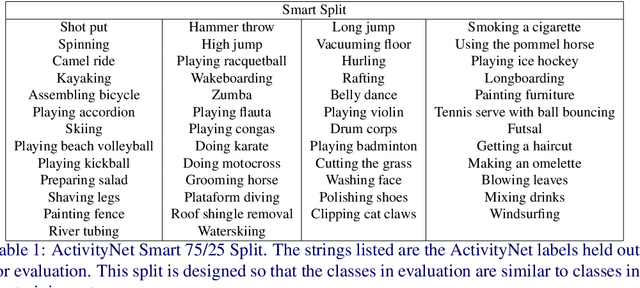
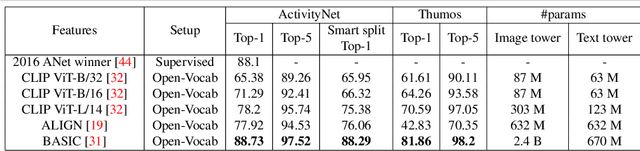
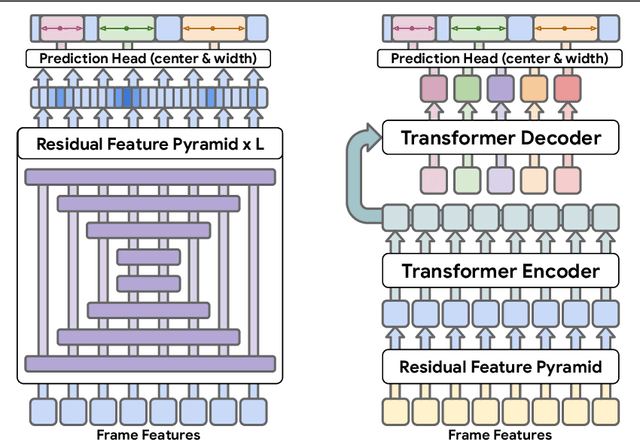
Detecting actions in untrimmed videos should not be limited to a small, closed set of classes. We present a simple, yet effective strategy for open-vocabulary temporal action detection utilizing pretrained image-text co-embeddings. Despite being trained on static images rather than videos, we show that image-text co-embeddings enable openvocabulary performance competitive with fully-supervised models. We show that the performance can be further improved by ensembling the image-text features with features encoding local motion, like optical flow based features, or other modalities, like audio. In addition, we propose a more reasonable open-vocabulary evaluation setting for the ActivityNet data set, where the category splits are based on similarity rather than random assignment.
Exposure Fusion for Hand-held Camera Inputs with Optical Flow and PatchMatch
Apr 10, 2023



This paper proposes a hybrid synthesis method for multi-exposure image fusion taken by hand-held cameras. Motions either due to the shaky camera or caused by dynamic scenes should be compensated before any content fusion. Any misalignment can easily cause blurring/ghosting artifacts in the fused result. Our hybrid method can deal with such motions and maintain the exposure information of each input effectively. In particular, the proposed method first applies optical flow for a coarse registration, which performs well with complex non-rigid motion but produces deformations at regions with missing correspondences. The absence of correspondences is due to the occlusions of scene parallax or the moving contents. To correct such error registration, we segment images into superpixels and identify problematic alignments based on each superpixel, which is further aligned by PatchMatch. The method combines the efficiency of optical flow and the accuracy of PatchMatch. After PatchMatch correction, we obtain a fully aligned image stack that facilitates a high-quality fusion that is free from blurring/ghosting artifacts. We compare our method with existing fusion algorithms on various challenging examples, including the static/dynamic, the indoor/outdoor and the daytime/nighttime scenes. Experiment results demonstrate the effectiveness and robustness of our method.