 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Patch-aware Batch Normalization for Improving Cross-domain Robustness
Apr 06, 2023

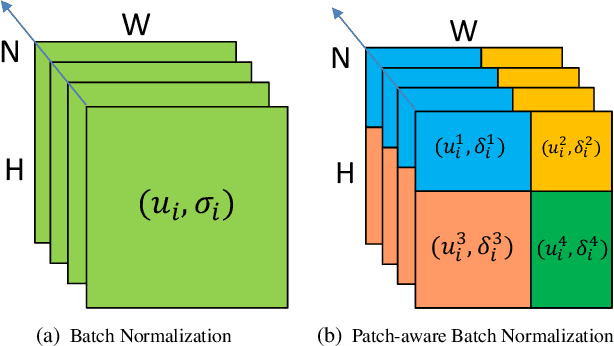
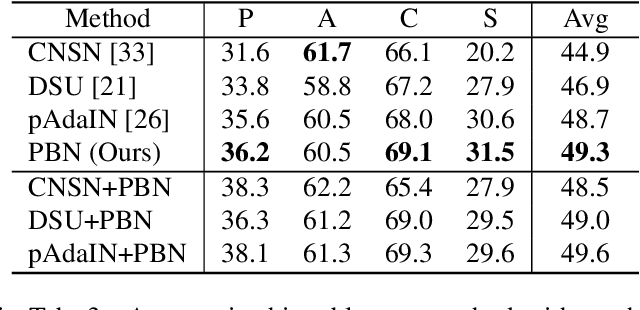
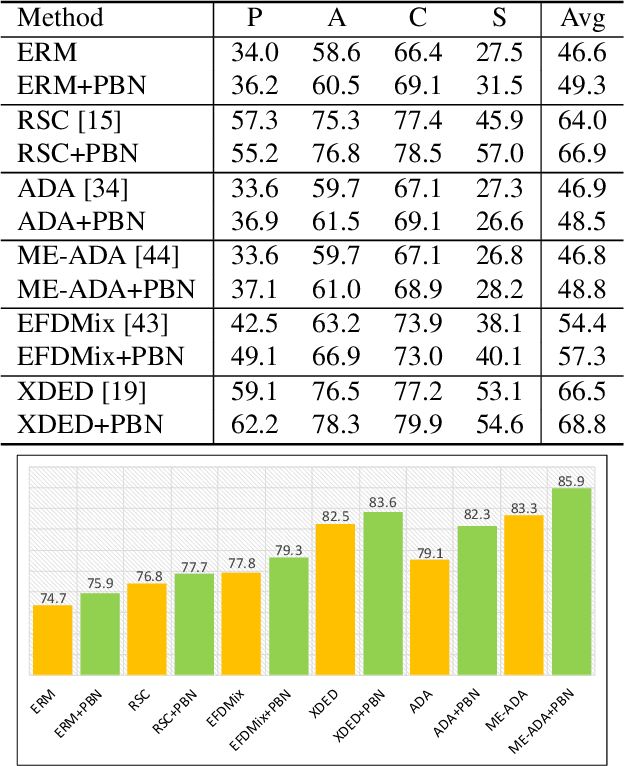
Despite the significant success of deep learning in computer vision tasks, cross-domain tasks still present a challenge in which the model's performance will degrade when the training set and the test set follow different distributions. Most existing methods employ adversarial learning or instance normalization for achieving data augmentation to solve this task. In contrast, considering that the batch normalization (BN) layer may not be robust for unseen domains and there exist the differences between local patches of an image, we propose a novel method called patch-aware batch normalization (PBN). To be specific, we first split feature maps of a batch into non-overlapping patches along the spatial dimension, and then independently normalize each patch to jointly optimize the shared BN parameter at each iteration. By exploiting the differences between local patches of an image, our proposed PBN can effectively enhance the robustness of the model's parameters. Besides, considering the statistics from each patch may be inaccurate due to their smaller size compared to the global feature maps, we incorporate the globally accumulated statistics with the statistics from each batch to obtain the final statistics for normalizing each patch. Since the proposed PBN can replace the typical BN, it can be integrated into most existing state-of-the-art methods. Extensive experiments and analysis demonstrate the effectiveness of our PBN in multiple computer vision tasks, including classification, object detection, instance retrieval, and semantic segmentation.
SVD-DIP: Overcoming the Overfitting Problem in DIP-based CT Reconstruction
Mar 28, 2023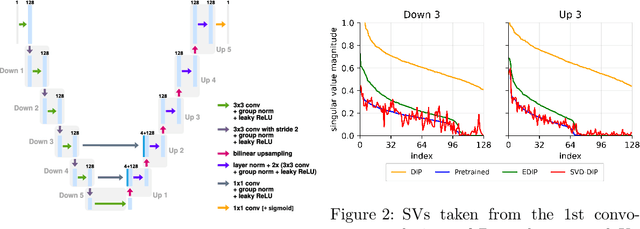

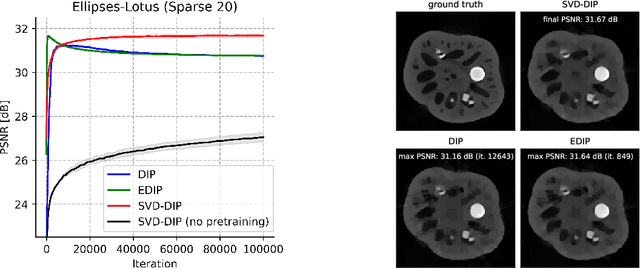
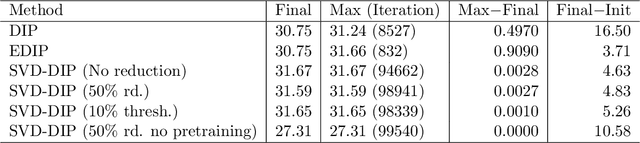
The deep image prior (DIP) is a well-established unsupervised deep learning method for image reconstruction; yet it is far from being flawless. The DIP overfits to noise if not early stopped, or optimized via a regularized objective. We build on the regularized fine-tuning of a pretrained DIP, by adopting a novel strategy that restricts the learning to the adaptation of singular values. The proposed SVD-DIP uses ad hoc convolutional layers whose pretrained parameters are decomposed via the singular value decomposition. Optimizing the DIP then solely consists in the fine-tuning of the singular values, while keeping the left and right singular vectors fixed. We thoroughly validate the proposed method on real-measured $\mu$CT data of a lotus root as well as two medical datasets (LoDoPaB and Mayo). We report significantly improved stability of the DIP optimization, by overcoming the overfitting to noise.
Image Coding via Perceptually Inspired Graph Learning
Mar 03, 2023
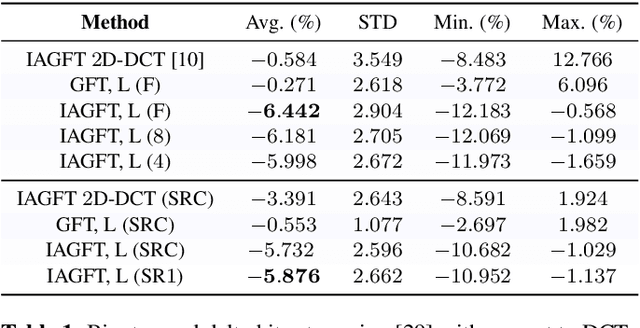

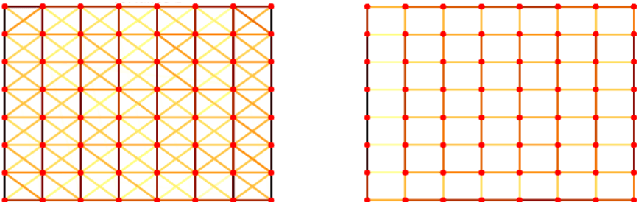
Most codec designs rely on the mean squared error (MSE) as a fidelity metric in rate-distortion optimization, which allows to choose the optimal parameters in the transform domain but may fail to reflect perceptual quality. Alternative distortion metrics, such as the structural similarity index (SSIM), can be computed only pixel-wise, so they cannot be used directly for transform-domain bit allocation. Recently, the irregularity-aware graph Fourier transform (IAGFT) emerged as a means to include pixel-wise perceptual information in the transform design. This paper extends this idea by also learning a graph (and corresponding transform) for sets of blocks that share similar perceptual characteristics and are observed to differ statistically, leading to different learned graphs. We demonstrate the effectiveness of our method with both SSIM- and saliency-based criteria. We also propose a framework to derive separable transforms, including separable IAGFTs. An empirical evaluation based on the 5th CLIC dataset shows that our approach achieves improvements in terms of MS-SSIM with respect to existing methods.
Prompt Pre-Training with Twenty-Thousand Classes for Open-Vocabulary Visual Recognition
Apr 10, 2023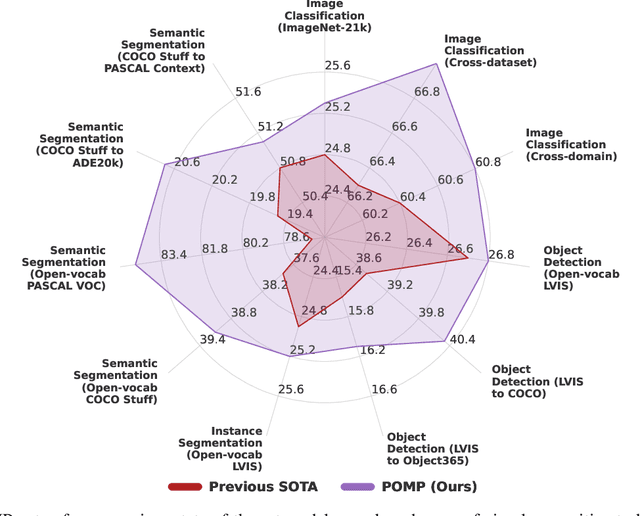
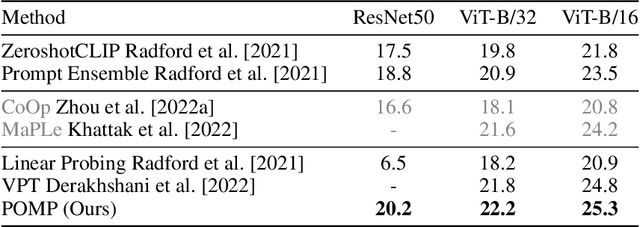
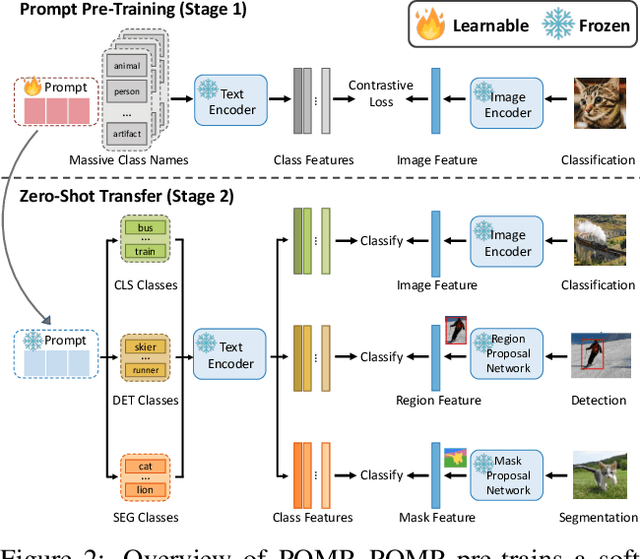
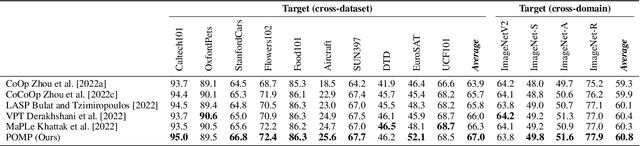
This work proposes POMP, a prompt pre-training method for vision-language models. Being memory and computation efficient, POMP enables the learned prompt to condense semantic information for a rich set of visual concepts with over twenty-thousand classes. Once pre-trained, the prompt with a strong transferable ability can be directly plugged into a variety of visual recognition tasks including image classification, semantic segmentation, and object detection, to boost recognition performances in a zero-shot manner. Empirical evaluation shows that POMP achieves state-of-the-art performances on 21 downstream datasets, e.g., 67.0% average accuracy on 10 classification dataset (+3.1% compared to CoOp) and 84.4 hIoU on open-vocabulary Pascal VOC segmentation (+6.9 compared to ZSSeg).
Image-to-Image Translation for Autonomous Driving from Coarsely-Aligned Image Pairs
Sep 23, 2022
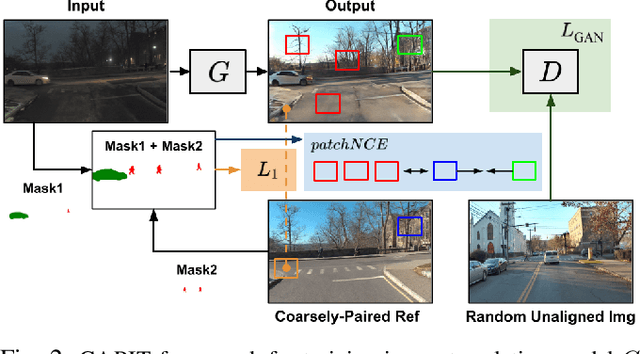

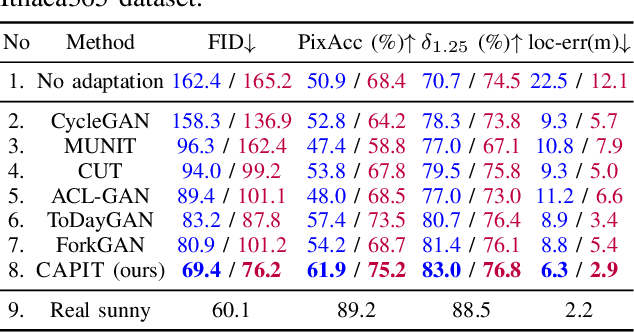
A self-driving car must be able to reliably handle adverse weather conditions (e.g., snowy) to operate safely. In this paper, we investigate the idea of turning sensor inputs (i.e., images) captured in an adverse condition into a benign one (i.e., sunny), upon which the downstream tasks (e.g., semantic segmentation) can attain high accuracy. Prior work primarily formulates this as an unpaired image-to-image translation problem due to the lack of paired images captured under the exact same camera poses and semantic layouts. While perfectly-aligned images are not available, one can easily obtain coarsely-paired images. For instance, many people drive the same routes daily in both good and adverse weather; thus, images captured at close-by GPS locations can form a pair. Though data from repeated traversals are unlikely to capture the same foreground objects, we posit that they provide rich contextual information to supervise the image translation model. To this end, we propose a novel training objective leveraging coarsely-aligned image pairs. We show that our coarsely-aligned training scheme leads to a better image translation quality and improved downstream tasks, such as semantic segmentation, monocular depth estimation, and visual localization.
Query-guided Attention in Vision Transformers for Localizing Objects Using a Single Sketch
Mar 15, 2023
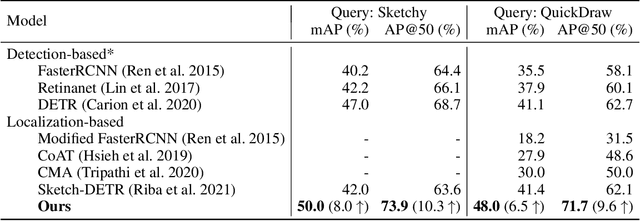
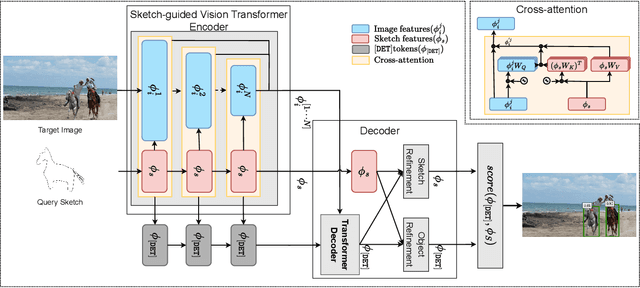
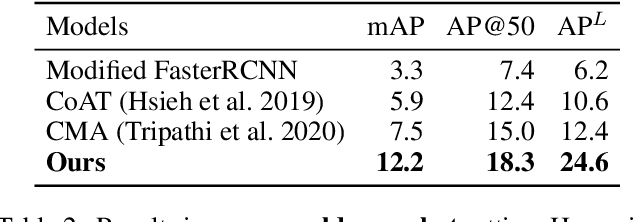
In this work, we investigate the problem of sketch-based object localization on natural images, where given a crude hand-drawn sketch of an object, the goal is to localize all the instances of the same object on the target image. This problem proves difficult due to the abstract nature of hand-drawn sketches, variations in the style and quality of sketches, and the large domain gap existing between the sketches and the natural images. To mitigate these challenges, existing works proposed attention-based frameworks to incorporate query information into the image features. However, in these works, the query features are incorporated after the image features have already been independently learned, leading to inadequate alignment. In contrast, we propose a sketch-guided vision transformer encoder that uses cross-attention after each block of the transformer-based image encoder to learn query-conditioned image features leading to stronger alignment with the query sketch. Further, at the output of the decoder, the object and the sketch features are refined to bring the representation of relevant objects closer to the sketch query and thereby improve the localization. The proposed model also generalizes to the object categories not seen during training, as the target image features learned by our method are query-aware. Our localization framework can also utilize multiple sketch queries via a trainable novel sketch fusion strategy. The model is evaluated on the images from the public object detection benchmark, namely MS-COCO, using the sketch queries from QuickDraw! and Sketchy datasets. Compared with existing localization methods, the proposed approach gives a $6.6\%$ and $8.0\%$ improvement in mAP for seen objects using sketch queries from QuickDraw! and Sketchy datasets, respectively, and a $12.2\%$ improvement in AP@50 for large objects that are `unseen' during training.
Fully Self-Supervised Depth Estimation from Defocus Clue
Mar 19, 2023
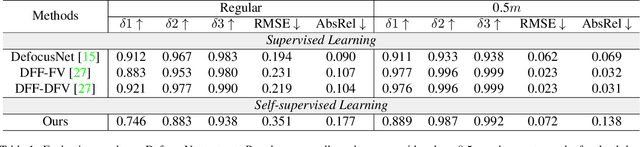
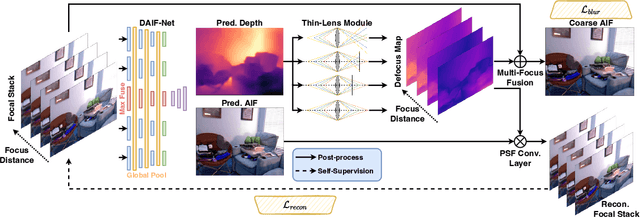
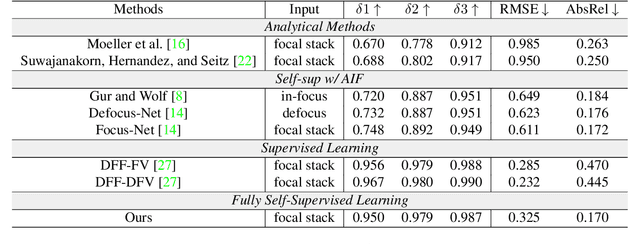
Depth-from-defocus (DFD), modeling the relationship between depth and defocus pattern in images, has demonstrated promising performance in depth estimation. Recently, several self-supervised works try to overcome the difficulties in acquiring accurate depth ground-truth. However, they depend on the all-in-focus (AIF) images, which cannot be captured in real-world scenarios. Such limitation discourages the applications of DFD methods. To tackle this issue, we propose a completely self-supervised framework that estimates depth purely from a sparse focal stack. We show that our framework circumvents the needs for the depth and AIF image ground-truth, and receives superior predictions, thus closing the gap between the theoretical success of DFD works and their applications in the real world. In particular, we propose (i) a more realistic setting for DFD tasks, where no depth or AIF image ground-truth is available; (ii) a novel self-supervision framework that provides reliable predictions of depth and AIF image under the challenging setting. The proposed framework uses a neural model to predict the depth and AIF image, and utilizes an optical model to validate and refine the prediction. We verify our framework on three benchmark datasets with rendered focal stacks and real focal stacks. Qualitative and quantitative evaluations show that our method provides a strong baseline for self-supervised DFD tasks.
A Radiomics-Incorporated Deep Ensemble Learning Model for Multi-Parametric MRI-based Glioma Segmentation
Mar 19, 2023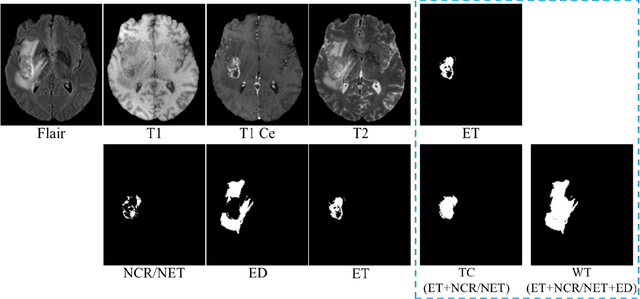
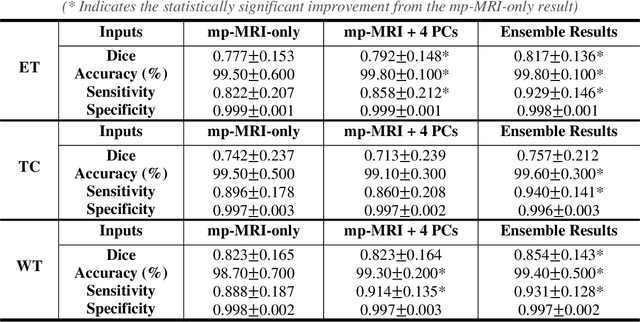
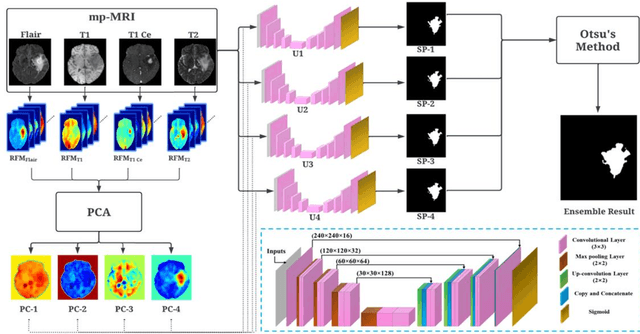
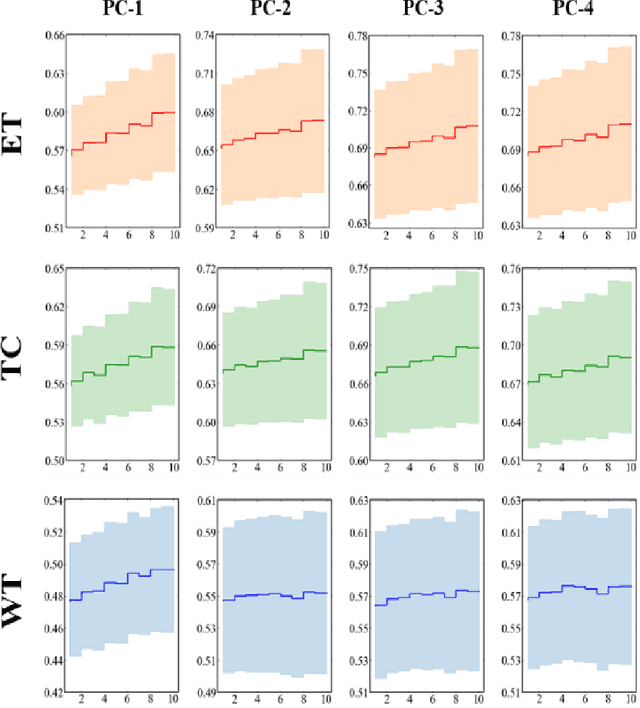
We developed a deep ensemble learning model with a radiomics spatial encoding execution for improved glioma segmentation accuracy using multi-parametric MRI (mp-MRI). This model was developed using 369 glioma patients with a 4-modality mp-MRI protocol: T1, contrast-enhanced T1 (T1-Ce), T2, and FLAIR. In each modality volume, a 3D sliding kernel was implemented across the brain to capture image heterogeneity: fifty-six radiomic features were extracted within the kernel, resulting in a 4th order tensor. Each radiomic feature can then be encoded as a 3D image volume, namely a radiomic feature map (RFM). PCA was employed for data dimension reduction and the first 4 PCs were selected. Four deep neural networks as sub-models following the U-Net architecture were trained for the segmenting of a region-of-interest (ROI): each sub-model utilizes the mp-MRI and 1 of the 4 PCs as a 5-channel input for a 2D execution. The 4 softmax probability results given by the U-net ensemble were superimposed and binarized by Otsu method as the segmentation result. Three ensemble models were trained to segment enhancing tumor (ET), tumor core (TC), and whole tumor (WT). The adopted radiomics spatial encoding execution enriches the image heterogeneity information that leads to the successful demonstration of the proposed deep ensemble model, which offers a new tool for mp-MRI based medical image segmentation.
Features-over-the-Air: Contrastive Learning Enabled Cooperative Edge Inference
Apr 17, 2023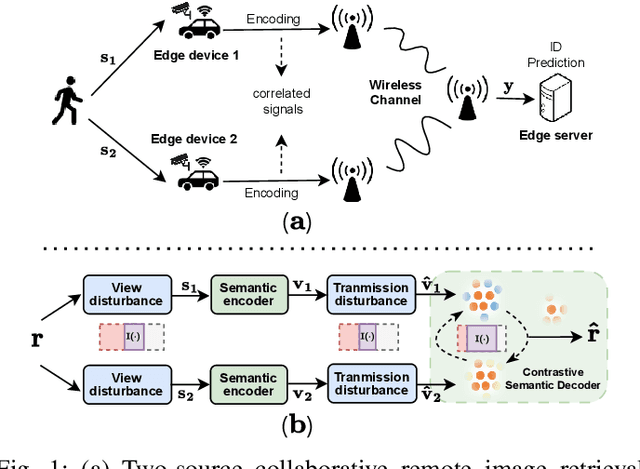

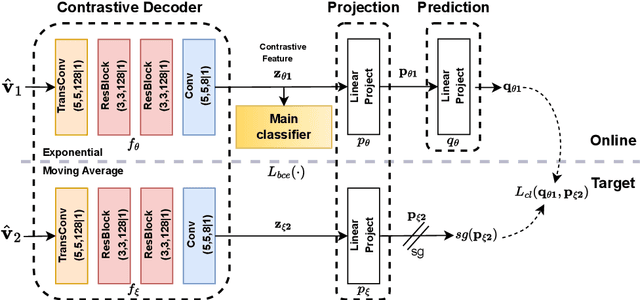
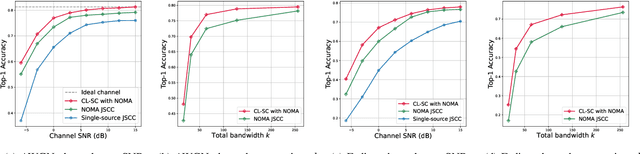
We study the collaborative image retrieval problem at the wireless edge, where multiple edge devices capture images of the same object, which are then used jointly to retrieve similar images at the edge server over a shared multiple access channel. We propose a semantic non-orthogonal multiple access (NOMA) communication paradigm, in which extracted features from each device are mapped directly to channel inputs, which are then added over-the-air. We propose a novel contrastive learning (CL)-based semantic communication (CL-SC) paradigm, aiming to exploit signal correlations to maximize the retrieval accuracy under a total bandwidth constraints. Specifically, we treat noisy correlated signals as different augmentations of a common identity, and propose a cross-view CL algorithm to optimize the correlated signals in a coarse-to-fine fashion to improve retrieval accuracy. Extensive numerical experiments verify that our method achieves the state-of-the-art performance and can significantly improve retrieval accuracy, with particularly significant gains in low signla-to-noise ratio (SNR) and limited bandwidth regimes.
OOD-CV-v2: An extended Benchmark for Robustness to Out-of-Distribution Shifts of Individual Nuisances in Natural Images
Apr 17, 2023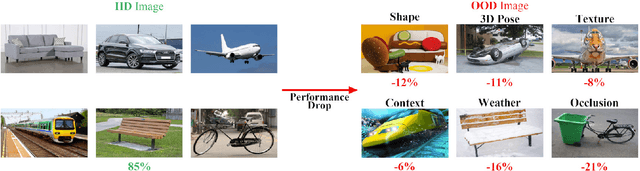
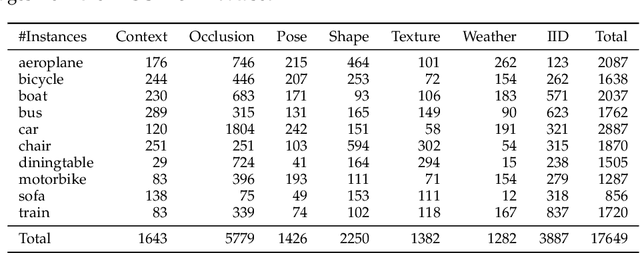


Enhancing the robustness of vision algorithms in real-world scenarios is challenging. One reason is that existing robustness benchmarks are limited, as they either rely on synthetic data or ignore the effects of individual nuisance factors. We introduce OOD-CV-v2, a benchmark dataset that includes out-of-distribution examples of 10 object categories in terms of pose, shape, texture, context and the weather conditions, and enables benchmarking of models for image classification, object detection, and 3D pose estimation. In addition to this novel dataset, we contribute extensive experiments using popular baseline methods, which reveal that: 1) Some nuisance factors have a much stronger negative effect on the performance compared to others, also depending on the vision task. 2) Current approaches to enhance robustness have only marginal effects, and can even reduce robustness. 3) We do not observe significant differences between convolutional and transformer architectures. We believe our dataset provides a rich test bed to study robustness and will help push forward research in this area. Our dataset can be accessed from http://www.ood-cv.org/challenge.html