 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sky-GVINS: a Sky-segmentation Aided GNSS-Visual-Inertial System for Robust Navigation in Urban Canyons
Apr 08, 2023
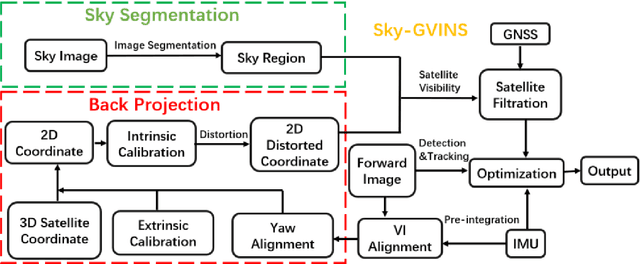

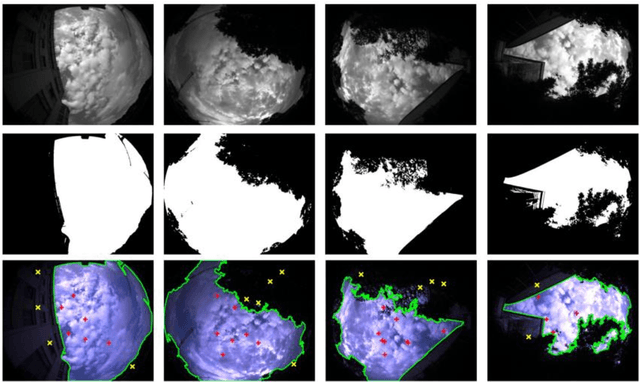

Integrating Global Navigation Satellite Systems (GNSS) in Simultaneous Localization and Mapping (SLAM) systems draws increasing attention to a global and continuous localization solution. Nonetheless, in dense urban environments, GNSS-based SLAM systems will suffer from the Non-Line-Of-Sight (NLOS) measurements, which might lead to a sharp deterioration in localization results. In this paper, we propose to detect the sky area from the up-looking camera to improve GNSS measurement reliability for more accurate position estimation. We present Sky-GVINS: a sky-aware GNSS-Visual-Inertial system based on a recent work called GVINS. Specifically, we adopt a global threshold method to segment the sky regions and non-sky regions in the fish-eye sky-pointing image and then project satellites to the image using the geometric relationship between satellites and the camera. After that, we reject satellites in non-sky regions to eliminate NLOS signals. We investigated various segmentation algorithms for sky detection and found that the Otsu algorithm reported the highest classification rate and computational efficiency, despite the algorithm's simplicity and ease of implementation. To evaluate the effectiveness of Sky-GVINS, we built a ground robot and conducted extensive real-world experiments on campus. Experimental results show that our method improves localization accuracy in both open areas and dense urban environments compared to the baseline method. Finally, we also conduct a detailed analysis and point out possible further directions for future research. For detailed information, visit our project website at https://github.com/SJTU-ViSYS/Sky-GVINS.
Fast Neural Scene Flow
Apr 18, 2023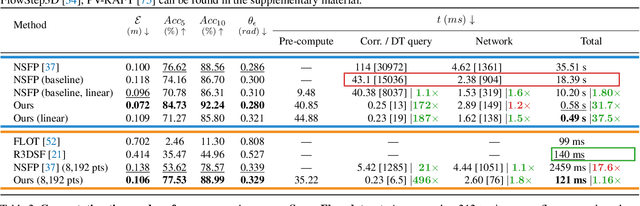

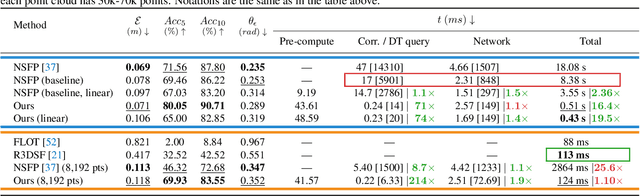
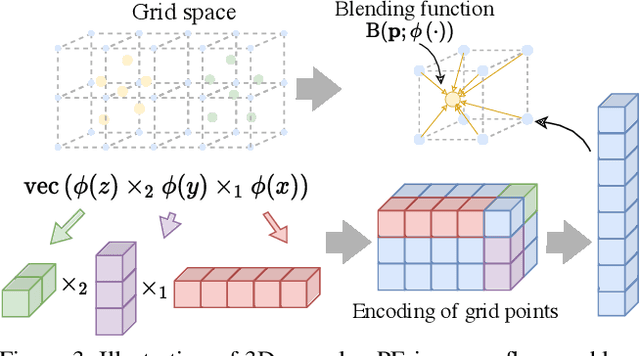
Scene flow is an important problem as it provides low-level motion cues for many downstream tasks. State-of-the-art learning methods are usually fast and can achieve impressive performance on in-domain data, but usually fail to generalize to out-of-the-distribution (OOD) data or handle dense point clouds. In this paper, we focus on a runtime optimization-based neural scene flow pipeline. In (a) one can see its application in the densification of lidar. However, in (c) one sees that the major drawback is the extensive computation time. We identify that the common speedup strategy in network architectures for coordinate networks has little effect on scene flow acceleration [see green (b)] unlike image reconstruction [see pink (b)]. With the dominant computational burden stemming instead from the Chamfer loss function, we propose to use a distance transform-based loss function to accelerate [see purple (b)], which achieves up to 30x speedup and on-par estimation performance compared to NSFP [see (c)]. When tested on 8k points, it is as efficient [see (c)] as leading learning methods, achieving real-time performance.
Enhancing Textbooks with Visuals from the Web for Improved Learning
Apr 18, 2023

Textbooks are the primary vehicle for delivering quality education to students. It has been shown that explanatory or illustrative visuals play a key role in the retention, comprehension and the general transfer of knowledge. However, many textbooks, especially in the developing world, are low quality and lack interesting visuals to support student learning. In this paper, we investigate the effectiveness of vision-language models to automatically enhance textbooks with images from the web. Specifically, we collect a dataset of e-textbooks from one of the largest free online publishers in the world. We rigorously analyse the dataset, and use the resulting analysis to motivate a task that involves retrieving and appropriately assigning web images to textbooks, which we frame as a novel optimization problem. Through a crowd-sourced evaluation, we verify that (1) while the original textbook images are rated higher, automatically assigned ones are not far behind, and (2) the choice of the optimization problem matters. We release the dataset of textbooks with an associated image bank to spur further research in this area.
Learning Sim-to-Real Dense Object Descriptors for Robotic Manipulation
Apr 18, 2023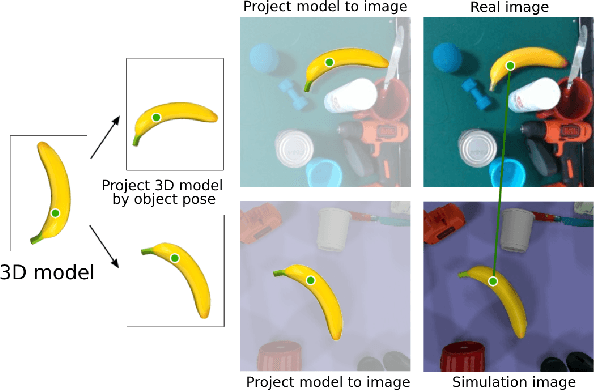
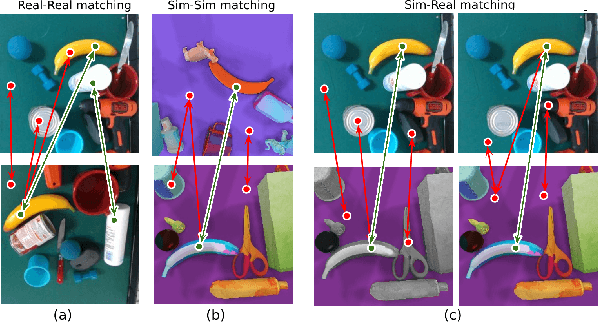
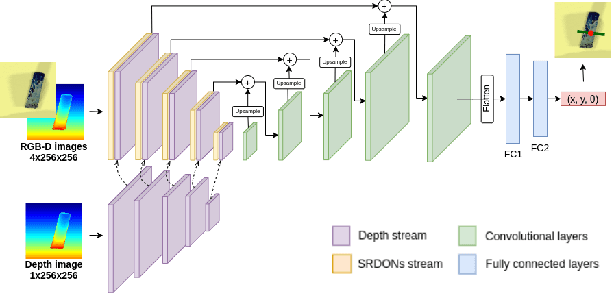

It is crucial to address the following issues for ubiquitous robotics manipulation applications: (a) vision-based manipulation tasks require the robot to visually learn and understand the object with rich information like dense object descriptors; and (b) sim-to-real transfer in robotics aims to close the gap between simulated and real data. In this paper, we present Sim-to-Real Dense Object Nets (SRDONs), a dense object descriptor that not only understands the object via appropriate representation but also maps simulated and real data to a unified feature space with pixel consistency. We proposed an object-to-object matching method for image pairs from different scenes and different domains. This method helps reduce the effort of training data from real-world by taking advantage of public datasets, such as GraspNet. With sim-to-real object representation consistency, our SRDONs can serve as a building block for a variety of sim-to-real manipulation tasks. We demonstrate in experiments that pre-trained SRDONs significantly improve performances on unseen objects and unseen visual environments for various robotic tasks with zero real-world training.
Segment Anything Is Not Always Perfect: An Investigation of SAM on Different Real-world Applications
Apr 13, 2023



Recently, Meta AI Research approaches a general, promptable Segment Anything Model (SAM) pre-trained on an unprecedentedly large segmentation dataset (SA-1B). Without a doubt, the emergence of SAM will yield significant benefits for a wide array of practical image segmentation applications. In this study, we conduct a series of intriguing investigations into the performance of SAM across various applications, particularly in the fields of natural images, agriculture, manufacturing, remote sensing, and healthcare. We analyze and discuss the benefits and limitations of SAM and provide an outlook on future development of segmentation tasks. Note that our work does not intend to propose new algorithms or theories, but rather provide a comprehensive view of SAM in practice. This work is expected to provide insights that facilitate future research activities toward generic segmentation.
Improving automatic endoscopic stone recognition using a multi-view fusion approach enhanced with two-step transfer learning
Apr 06, 2023
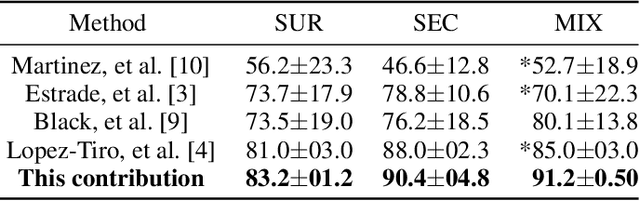
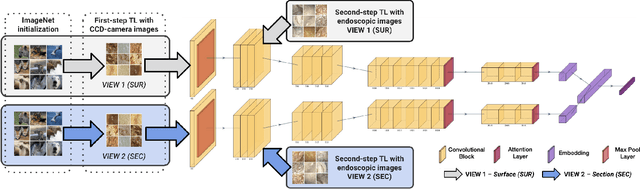
This contribution presents a deep-learning method for extracting and fusing image information acquired from different viewpoints, with the aim to produce more discriminant object features for the identification of the type of kidney stones seen in endoscopic images. The model was further improved with a two-step transfer learning approach and by attention blocks to refine the learned feature maps. Deep feature fusion strategies improved the results of single view extraction backbone models by more than 6% in terms of accuracy of the kidney stones classification.
Dehazed Image Quality Evaluation: From Partial Discrepancy to Blind Perception
Nov 22, 2022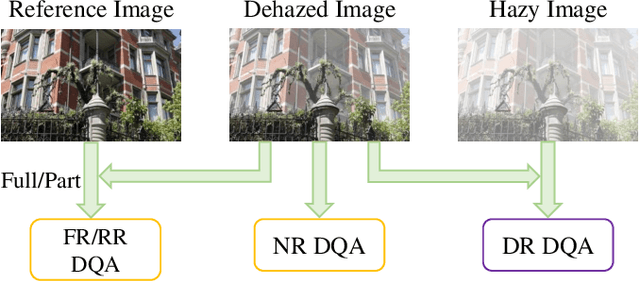

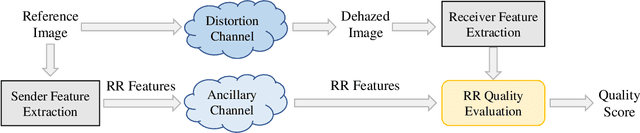
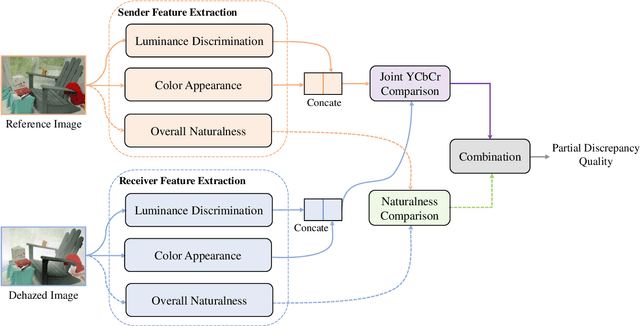
Image dehazing aims to restore spatial details from hazy images. There have emerged a number of image dehazing algorithms, designed to increase the visibility of those hazy images. However, much less work has been focused on evaluating the visual quality of dehazed images. In this paper, we propose a Reduced-Reference dehazed image quality evaluation approach based on Partial Discrepancy (RRPD) and then extend it to a No-Reference quality assessment metric with Blind Perception (NRBP). Specifically, inspired by the hierarchical characteristics of the human perceiving dehazed images, we introduce three groups of features: luminance discrimination, color appearance, and overall naturalness. In the proposed RRPD, the combined distance between a set of sender and receiver features is adopted to quantify the perceptually dehazed image quality. By integrating global and local channels from dehazed images, the RRPD is converted to NRBP which does not rely on any information from the references. Extensive experiment results on several dehazed image quality databases demonstrate that our proposed methods outperform state-of-the-art full-reference, reduced-reference, and no-reference quality assessment models. Furthermore, we show that the proposed dehazed image quality evaluation methods can be effectively applied to tune parameters for potential image dehazing algorithms.
Efficient Halftoning via Deep Reinforcement Learning
Apr 24, 2023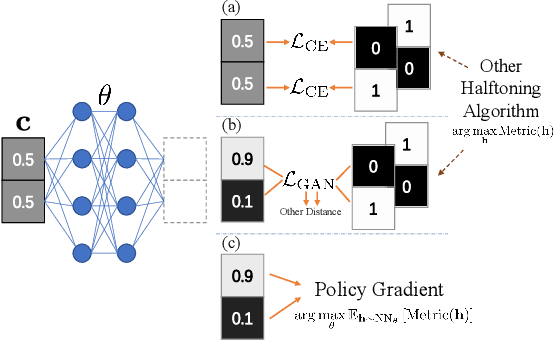
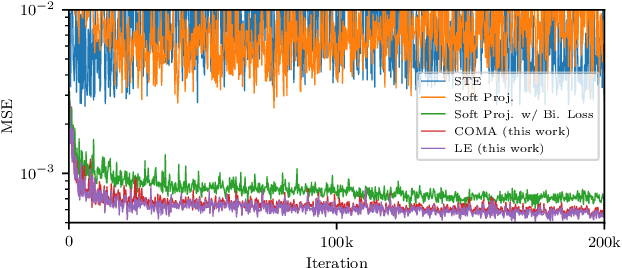
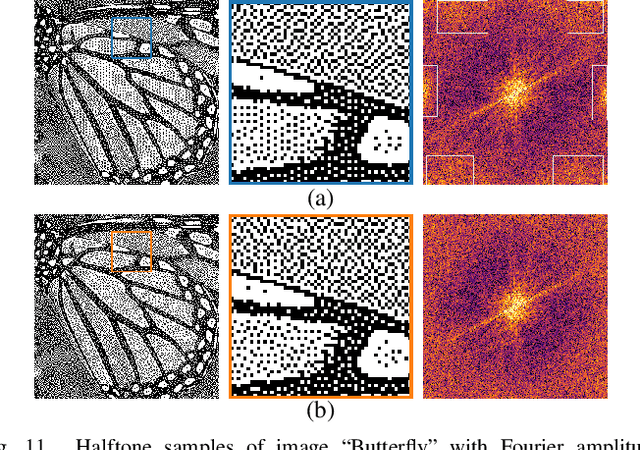
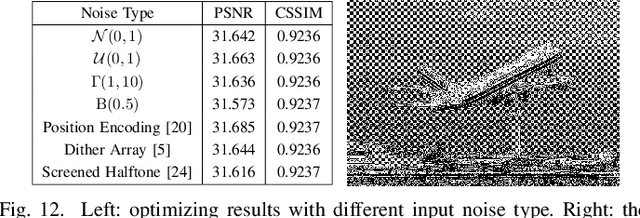
Halftoning aims to reproduce a continuous-tone image with pixels whose intensities are constrained to two discrete levels. This technique has been deployed on every printer, and the majority of them adopt fast methods (e.g., ordered dithering, error diffusion) that fail to render structural details, which determine halftone's quality. Other prior methods of pursuing visual pleasure by searching for the optimal halftone solution, on the contrary, suffer from their high computational cost. In this paper, we propose a fast and structure-aware halftoning method via a data-driven approach. Specifically, we formulate halftoning as a reinforcement learning problem, in which each binary pixel's value is regarded as an action chosen by a virtual agent with a shared fully convolutional neural network (CNN) policy. In the offline phase, an effective gradient estimator is utilized to train the agents in producing high-quality halftones in one action step. Then, halftones can be generated online by one fast CNN inference. Besides, we propose a novel anisotropy suppressing loss function, which brings the desirable blue-noise property. Finally, we find that optimizing SSIM could result in holes in flat areas, which can be avoided by weighting the metric with the contone's contrast map. Experiments show that our framework can effectively train a light-weight CNN, which is 15x faster than previous structure-aware methods, to generate blue-noise halftones with satisfactory visual quality. We also present a prototype of deep multitoning to demonstrate the extensibility of our method.
Rank Flow Embedding for Unsupervised and Semi-Supervised Manifold Learning
Apr 24, 2023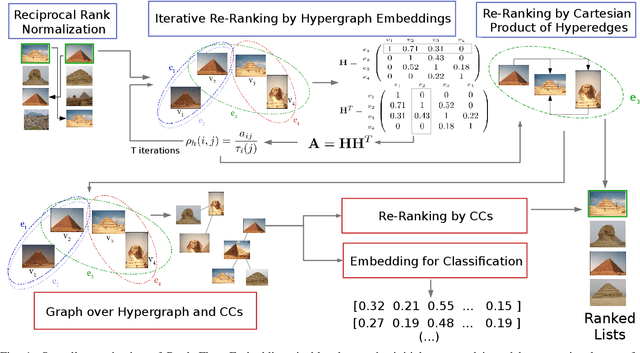
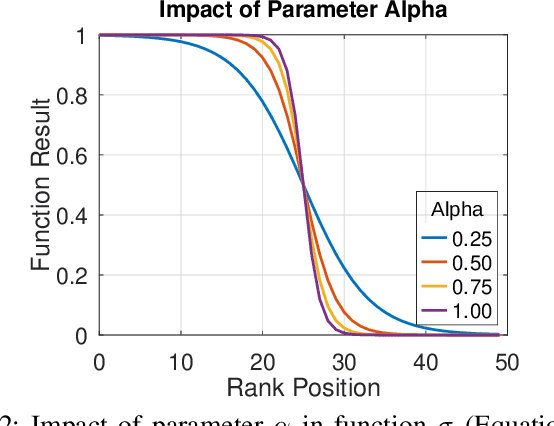
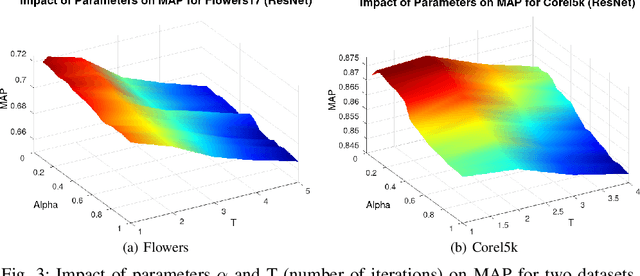
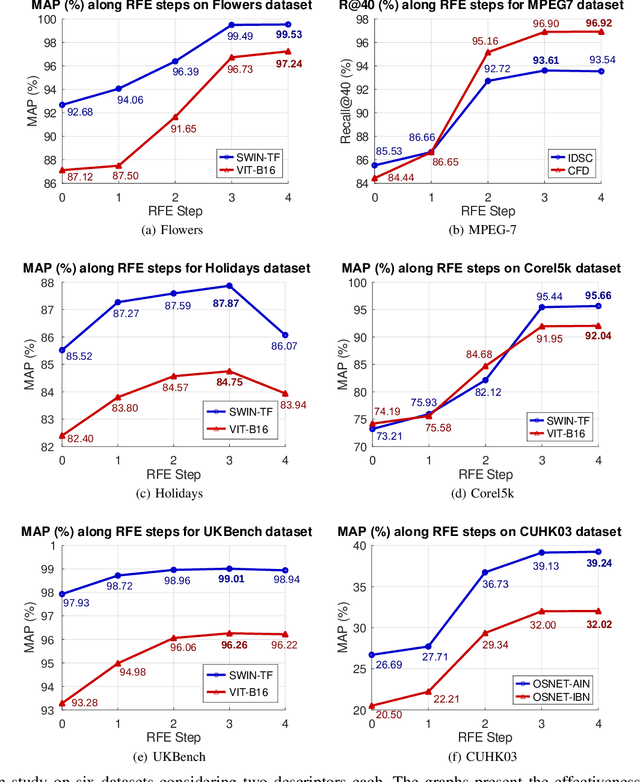
Impressive advances in acquisition and sharing technologies have made the growth of multimedia collections and their applications almost unlimited. However, the opposite is true for the availability of labeled data, which is needed for supervised training, since such data is often expensive and time-consuming to obtain. While there is a pressing need for the development of effective retrieval and classification methods, the difficulties faced by supervised approaches highlight the relevance of methods capable of operating with few or no labeled data. In this work, we propose a novel manifold learning algorithm named Rank Flow Embedding (RFE) for unsupervised and semi-supervised scenarios. The proposed method is based on ideas recently exploited by manifold learning approaches, which include hypergraphs, Cartesian products, and connected components. The algorithm computes context-sensitive embeddings, which are refined following a rank-based processing flow, while complementary contextual information is incorporated. The generated embeddings can be exploited for more effective unsupervised retrieval or semi-supervised classification based on Graph Convolutional Networks. Experimental results were conducted on 10 different collections. Various features were considered, including the ones obtained with recent Convolutional Neural Networks (CNN) and Vision Transformer (ViT) models. High effective results demonstrate the effectiveness of the proposed method on different tasks: unsupervised image retrieval, semi-supervised classification, and person Re-ID. The results demonstrate that RFE is competitive or superior to the state-of-the-art in diverse evaluated scenarios.
METransformer: Radiology Report Generation by Transformer with Multiple Learnable Expert Tokens
Apr 05, 2023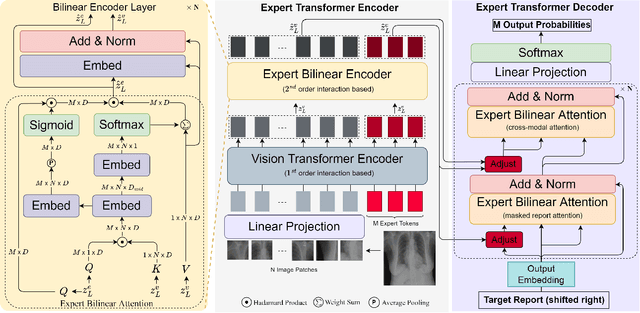
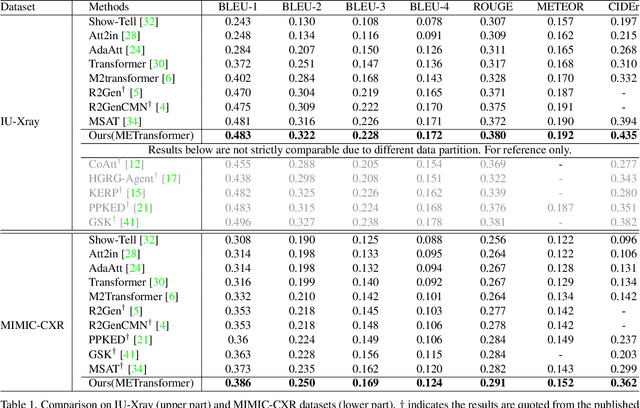
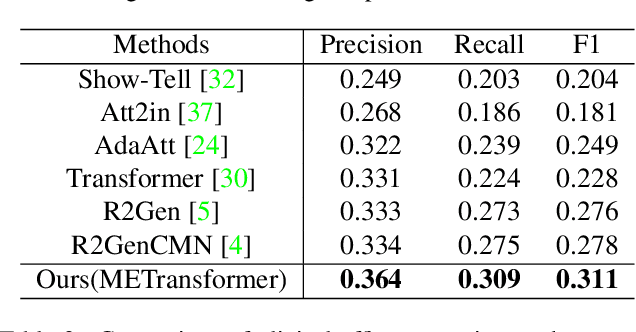
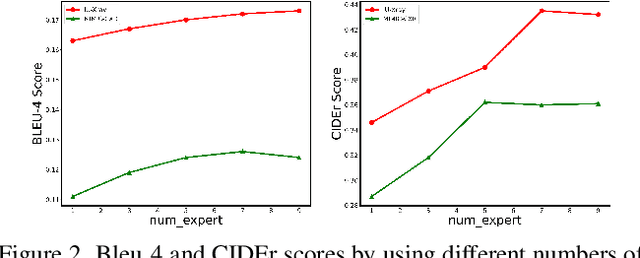
In clinical scenarios, multi-specialist consultation could significantly benefit the diagnosis, especially for intricate cases. This inspires us to explore a "multi-expert joint diagnosis" mechanism to upgrade the existing "single expert" framework commonly seen in the current literature. To this end, we propose METransformer, a method to realize this idea with a transformer-based backbone. The key design of our method is the introduction of multiple learnable "expert" tokens into both the transformer encoder and decoder. In the encoder, each expert token interacts with both vision tokens and other expert tokens to learn to attend different image regions for image representation. These expert tokens are encouraged to capture complementary information by an orthogonal loss that minimizes their overlap. In the decoder, each attended expert token guides the cross-attention between input words and visual tokens, thus influencing the generated report. A metrics-based expert voting strategy is further developed to generate the final report. By the multi-experts concept, our model enjoys the merits of an ensemble-based approach but through a manner that is computationally more efficient and supports more sophisticated interactions among experts. Experimental results demonstrate the promising performance of our proposed model on two widely used benchmarks. Last but not least, the framework-level innovation makes our work ready to incorporate advances on existing "single-expert" models to further improve its performance.