 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Homography matrix based trajectory planning method for robot uncalibrated visual servoing
Mar 16, 2023
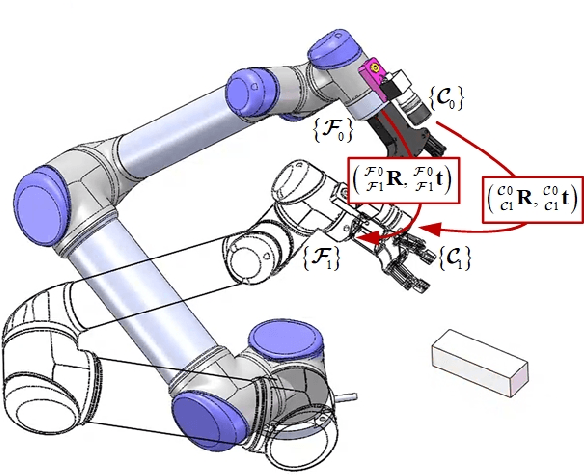
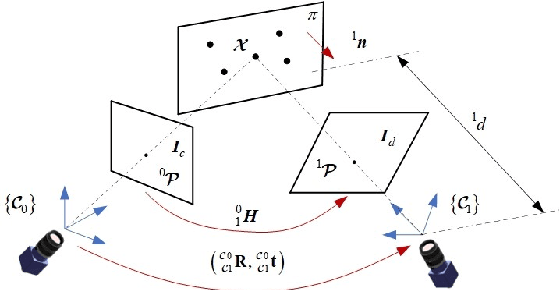

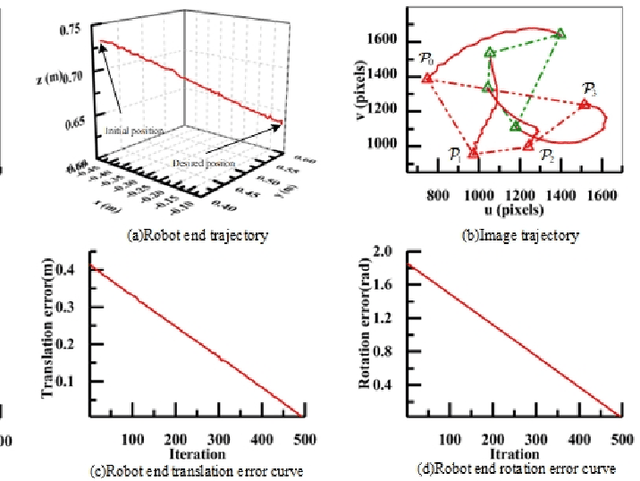
In view of the classical visual servoing trajectory planning method which only considers the camera trajectory, this paper proposes one homography matrix based trajectory planning method for robot uncalibrated visual servoing. Taking the robot-end-effector frame as one generic case, eigenvalue decomposition is utilized to calculate the infinite homography matrix of the robot-end-effector trajectory, and then the image feature-point trajectories corresponding to the camera rotation is obtained, while the image feature-point trajectories corresponding to the camera translation is obtained by the homography matrix. According to the additional image corresponding to the robot-end-effector rotation, the relationship between the robot-end-effector rotation and the variation of the image feature-points is obtained, and then the expression of the image trajectories corresponding to the optimal robot-end-effector trajectories (the rotation trajectory of the minimum geodesic and the linear translation trajectory) are obtained. Finally, the optimal image trajectories of the uncalibrated visual servoing controller is modified to track the image trajectories. Simulation experiments show that, compared with the classical IBUVS method, the proposed trajectory planning method can obtain the shortest path of any frame and complete the robot visual servoing task with large initial pose deviation.
Borrowing Human Senses: Comment-Aware Self-Training for Social Media Multimodal Classification
Mar 27, 2023
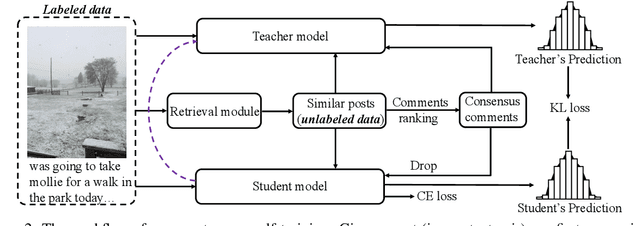
Social media is daily creating massive multimedia content with paired image and text, presenting the pressing need to automate the vision and language understanding for various multimodal classification tasks. Compared to the commonly researched visual-lingual data, social media posts tend to exhibit more implicit image-text relations. To better glue the cross-modal semantics therein, we capture hinting features from user comments, which are retrieved via jointly leveraging visual and lingual similarity. Afterwards, the classification tasks are explored via self-training in a teacher-student framework, motivated by the usually limited labeled data scales in existing benchmarks. Substantial experiments are conducted on four multimodal social media benchmarks for image text relation classification, sarcasm detection, sentiment classification, and hate speech detection. The results show that our method further advances the performance of previous state-of-the-art models, which do not employ comment modeling or self-training.
SVDiff: Compact Parameter Space for Diffusion Fine-Tuning
Mar 22, 2023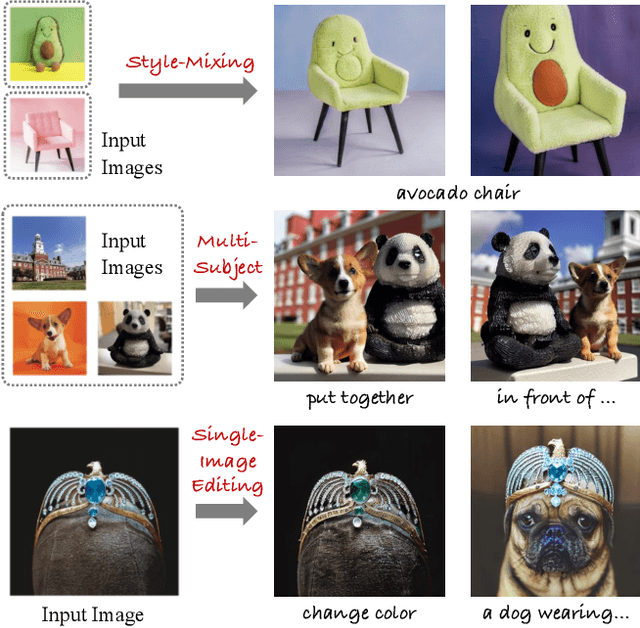
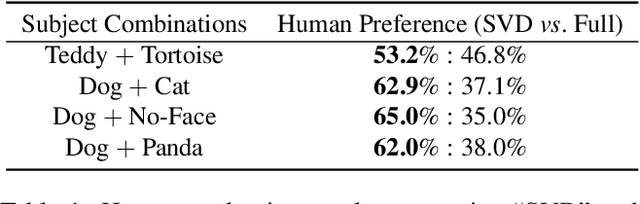
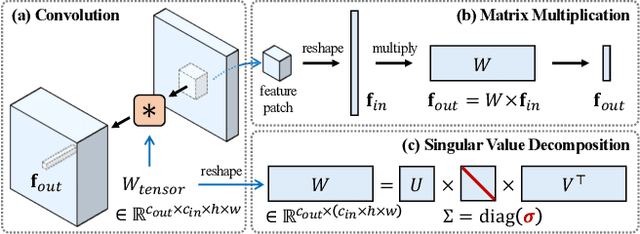
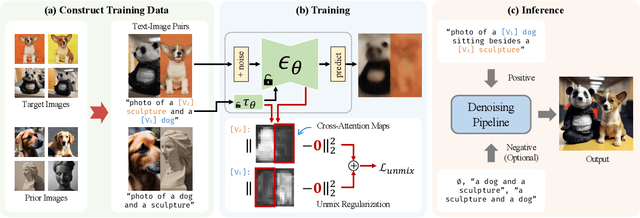
Diffusion models have achieved remarkable success in text-to-image generation, enabling the creation of high-quality images from text prompts or other modalities. However, existing methods for customizing these models are limited by handling multiple personalized subjects and the risk of overfitting. Moreover, their large number of parameters is inefficient for model storage. In this paper, we propose a novel approach to address these limitations in existing text-to-image diffusion models for personalization. Our method involves fine-tuning the singular values of the weight matrices, leading to a compact and efficient parameter space that reduces the risk of overfitting and language-drifting. We also propose a Cut-Mix-Unmix data-augmentation technique to enhance the quality of multi-subject image generation and a simple text-based image editing framework. Our proposed SVDiff method has a significantly smaller model size (1.7MB for StableDiffusion) compared to existing methods (vanilla DreamBooth 3.66GB, Custom Diffusion 73MB), making it more practical for real-world applications.
Multi-task learning for tissue segmentation and tumor detection in colorectal cancer histology slides
Apr 06, 2023
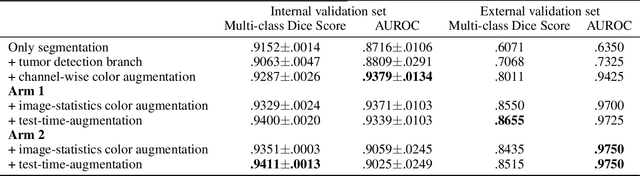
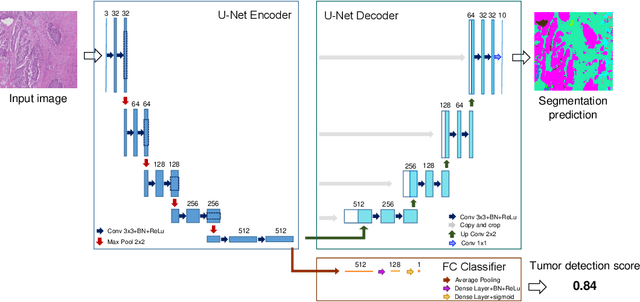
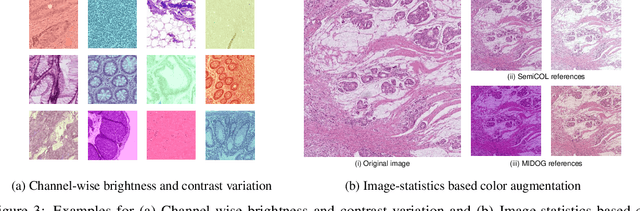
Automating tissue segmentation and tumor detection in histopathology images of colorectal cancer (CRC) is an enabler for faster diagnostic pathology workflows. At the same time it is a challenging task due to low availability of public annotated datasets and high variability of image appearance. The semi-supervised learning for CRC detection (SemiCOL) challenge 2023 provides partially annotated data to encourage the development of automated solutions for tissue segmentation and tumor detection. We propose a U-Net based multi-task model combined with channel-wise and image-statistics-based color augmentations, as well as test-time augmentation, as a candidate solution to the SemiCOL challenge. Our approach achieved a multi-task Dice score of .8655 (Arm 1) and .8515 (Arm 2) for tissue segmentation and AUROC of .9725 (Arm 1) and 0.9750 (Arm 2) for tumor detection on the challenge validation set. The source code for our approach is made publicly available at https://github.com/lely475/CTPLab_SemiCOL2023.
One-Shot High-Fidelity Talking-Head Synthesis with Deformable Neural Radiance Field
Apr 11, 2023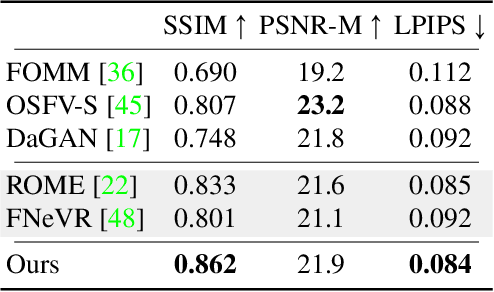
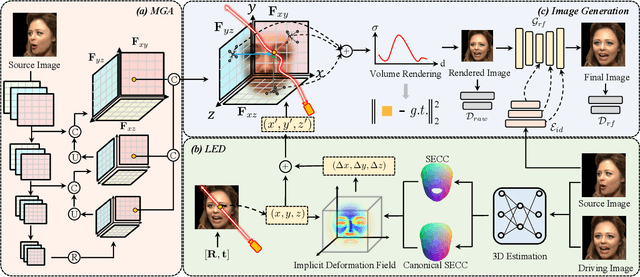
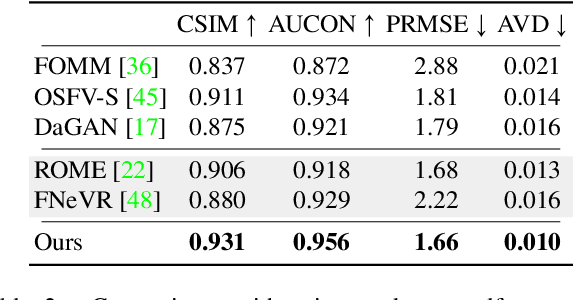
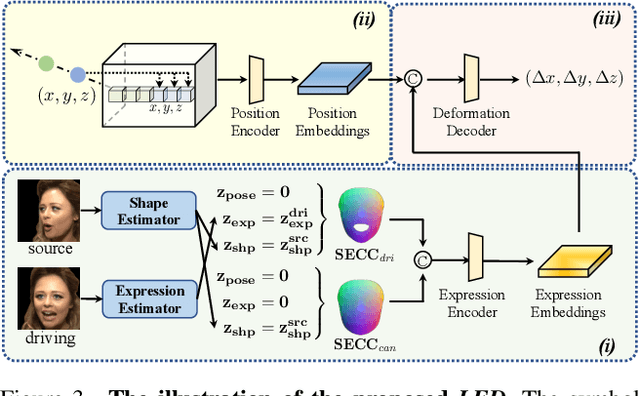
Talking head generation aims to generate faces that maintain the identity information of the source image and imitate the motion of the driving image. Most pioneering methods rely primarily on 2D representations and thus will inevitably suffer from face distortion when large head rotations are encountered. Recent works instead employ explicit 3D structural representations or implicit neural rendering to improve performance under large pose changes. Nevertheless, the fidelity of identity and expression is not so desirable, especially for novel-view synthesis. In this paper, we propose HiDe-NeRF, which achieves high-fidelity and free-view talking-head synthesis. Drawing on the recently proposed Deformable Neural Radiance Fields, HiDe-NeRF represents the 3D dynamic scene into a canonical appearance field and an implicit deformation field, where the former comprises the canonical source face and the latter models the driving pose and expression. In particular, we improve fidelity from two aspects: (i) to enhance identity expressiveness, we design a generalized appearance module that leverages multi-scale volume features to preserve face shape and details; (ii) to improve expression preciseness, we propose a lightweight deformation module that explicitly decouples the pose and expression to enable precise expression modeling. Extensive experiments demonstrate that our proposed approach can generate better results than previous works. Project page: https://www.waytron.net/hidenerf/
Patch Diffusion: Faster and More Data-Efficient Training of Diffusion Models
Apr 25, 2023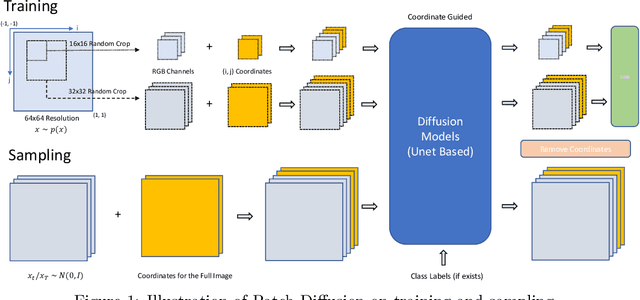
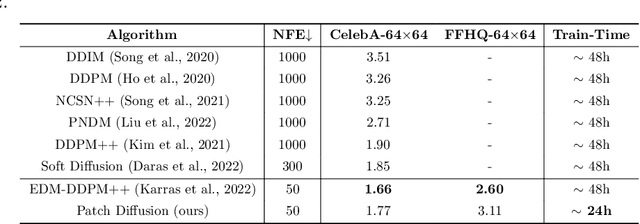
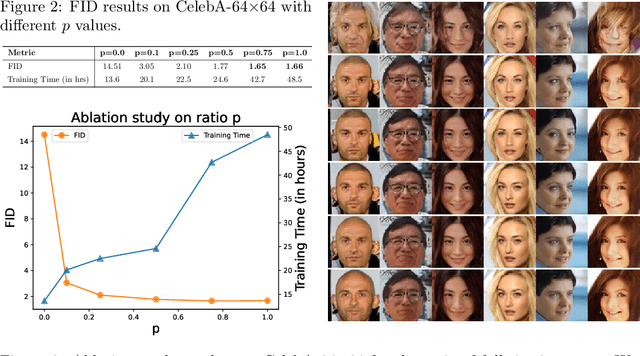

Diffusion models are powerful, but they require a lot of time and data to train. We propose Patch Diffusion, a generic patch-wise training framework, to significantly reduce the training time costs while improving data efficiency, which thus helps democratize diffusion model training to broader users. At the core of our innovations is a new conditional score function at the patch level, where the patch location in the original image is included as additional coordinate channels, while the patch size is randomized and diversified throughout training to encode the cross-region dependency at multiple scales. Sampling with our method is as easy as in the original diffusion model. Through Patch Diffusion, we could achieve $\mathbf{\ge 2\times}$ faster training, while maintaining comparable or better generation quality. Patch Diffusion meanwhile improves the performance of diffusion models trained on relatively small datasets, $e.g.$, as few as 5,000 images to train from scratch. We achieve state-of-the-art FID scores 1.77 on CelebA-64$\times$64 and 1.93 on AFHQv2-Wild-64$\times$64. We will share our code and pre-trained models soon.
Depth-Relative Self Attention for Monocular Depth Estimation
Apr 25, 2023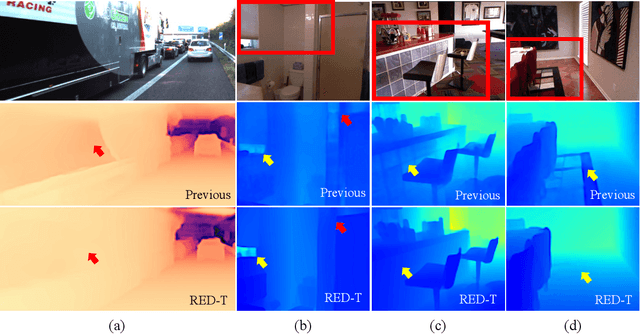
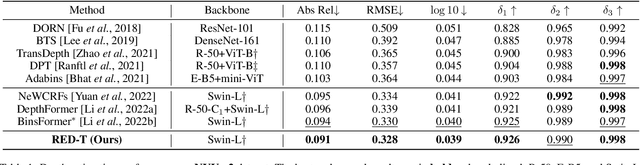
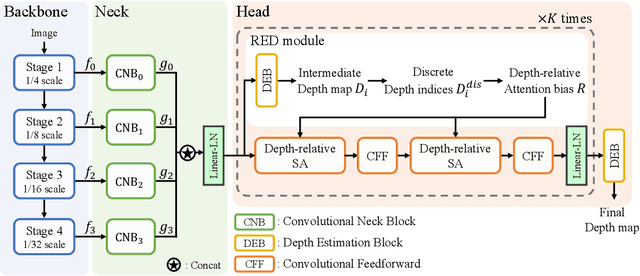
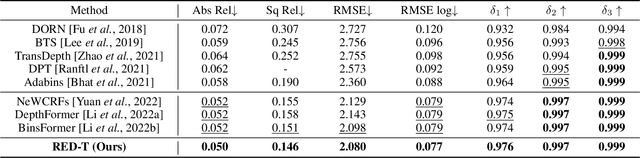
Monocular depth estimation is very challenging because clues to the exact depth are incomplete in a single RGB image. To overcome the limitation, deep neural networks rely on various visual hints such as size, shade, and texture extracted from RGB information. However, we observe that if such hints are overly exploited, the network can be biased on RGB information without considering the comprehensive view. We propose a novel depth estimation model named RElative Depth Transformer (RED-T) that uses relative depth as guidance in self-attention. Specifically, the model assigns high attention weights to pixels of close depth and low attention weights to pixels of distant depth. As a result, the features of similar depth can become more likely to each other and thus less prone to misused visual hints. We show that the proposed model achieves competitive results in monocular depth estimation benchmarks and is less biased to RGB information. In addition, we propose a novel monocular depth estimation benchmark that limits the observable depth range during training in order to evaluate the robustness of the model for unseen depths.
Contrastive Energy Prediction for Exact Energy-Guided Diffusion Sampling in Offline Reinforcement Learning
Apr 25, 2023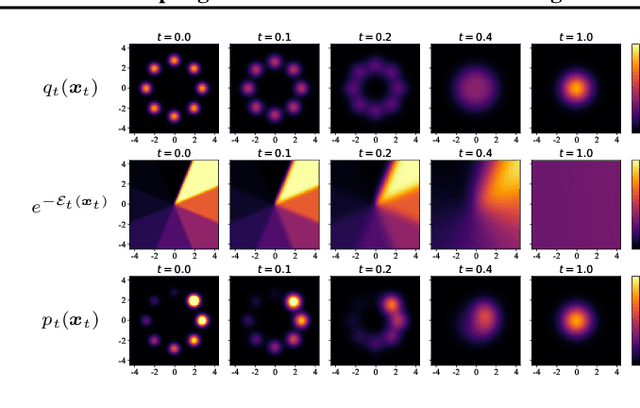
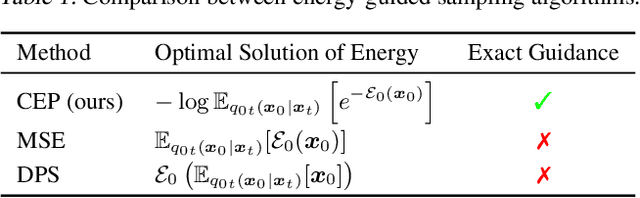
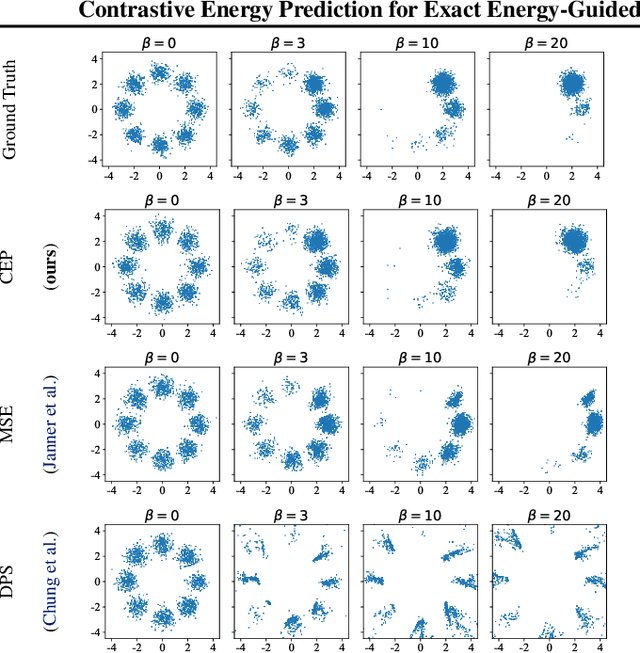
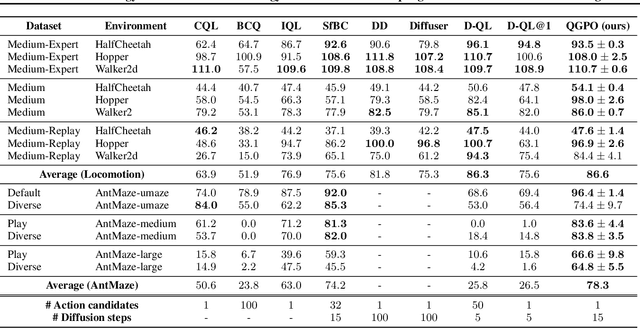
Guided sampling is a vital approach for applying diffusion models in real-world tasks that embeds human-defined guidance during the sampling procedure. This paper considers a general setting where the guidance is defined by an (unnormalized) energy function. The main challenge for this setting is that the intermediate guidance during the diffusion sampling procedure, which is jointly defined by the sampling distribution and the energy function, is unknown and is hard to estimate. To address this challenge, we propose an exact formulation of the intermediate guidance as well as a novel training objective named contrastive energy prediction (CEP) to learn the exact guidance. Our method is guaranteed to converge to the exact guidance under unlimited model capacity and data samples, while previous methods can not. We demonstrate the effectiveness of our method by applying it to offline reinforcement learning (RL). Extensive experiments on D4RL benchmarks demonstrate that our method outperforms existing state-of-the-art algorithms. We also provide some examples of applying CEP for image synthesis to demonstrate the scalability of CEP on high-dimensional data.
Chameleon: Adapting to Peer Images for Planting Durable Backdoors in Federated Learning
Apr 25, 2023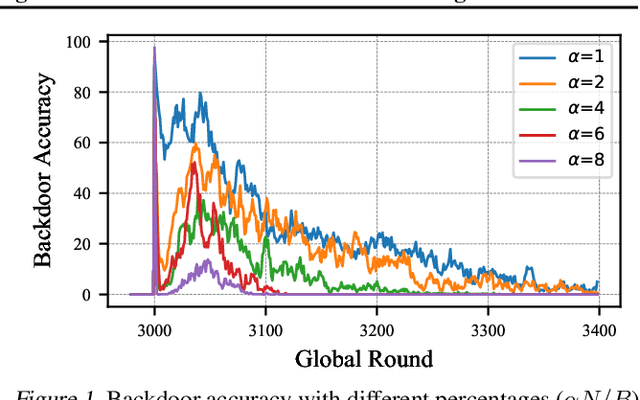
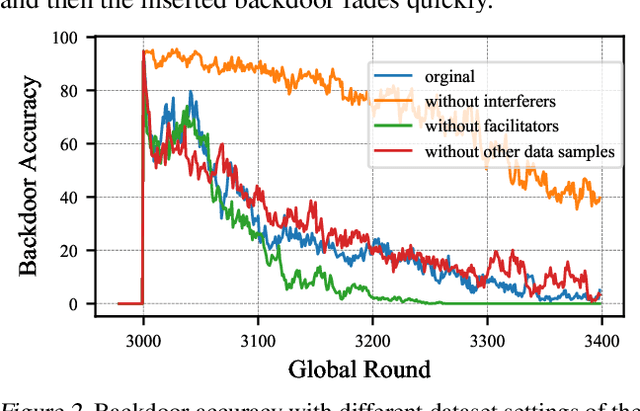
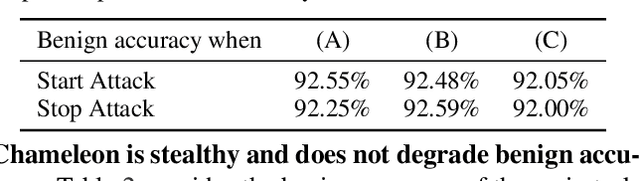
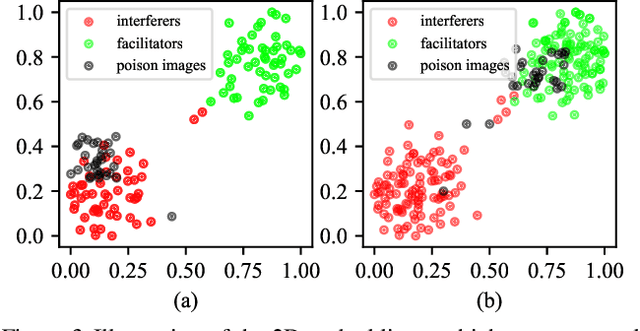
In a federated learning (FL) system, distributed clients upload their local models to a central server to aggregate into a global model. Malicious clients may plant backdoors into the global model through uploading poisoned local models, causing images with specific patterns to be misclassified into some target labels. Backdoors planted by current attacks are not durable, and vanish quickly once the attackers stop model poisoning. In this paper, we investigate the connection between the durability of FL backdoors and the relationships between benign images and poisoned images (i.e., the images whose labels are flipped to the target label during local training). Specifically, benign images with the original and the target labels of the poisoned images are found to have key effects on backdoor durability. Consequently, we propose a novel attack, Chameleon, which utilizes contrastive learning to further amplify such effects towards a more durable backdoor. Extensive experiments demonstrate that Chameleon significantly extends the backdoor lifespan over baselines by $1.2\times \sim 4\times$, for a wide range of image datasets, backdoor types, and model architectures.
A fast and flexible algorithm for microstructure reconstruction combining simulated annealing and deep learning
Apr 25, 2023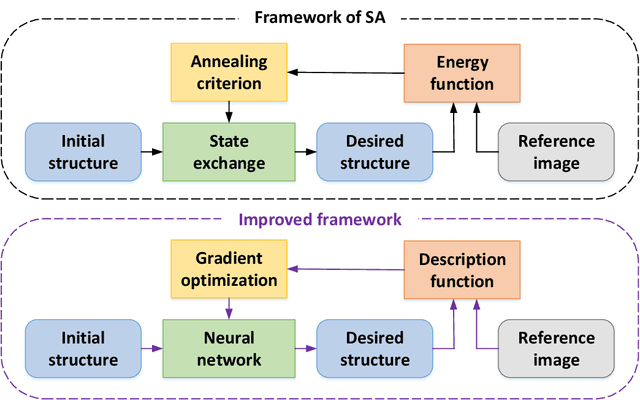


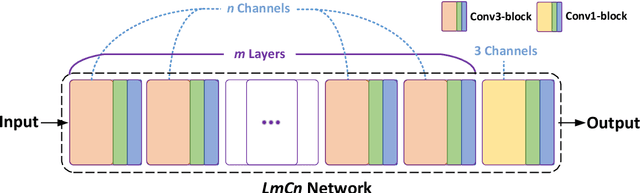
The microstructure analyses of porous media have considerable research value for the study of macroscopic properties. As the premise of conducting these analyses, the accurate reconstruction of microstructure digital model is also an important component of the research. Computational reconstruction algorithms of microstructure have attracted much attention due to their low cost and excellent performance. However, it is still a challenge for computational reconstruction algorithms to achieve faster and more efficient reconstruction. The bottleneck lies in computational reconstruction algorithms, they are either too slow (traditional reconstruction algorithms) or not flexible to the training process (deep learning reconstruction algorithms). To address these limitations, we proposed a fast and flexible computational reconstruction algorithm, neural networks based on improved simulated annealing framework (ISAF-NN). The proposed algorithm is flexible and can complete training and reconstruction in a short time with only one two-dimensional image. By adjusting the size of input, it can also achieve reconstruction of arbitrary size. Finally, the proposed algorithm is experimentally performed on a variety of isotropic and anisotropic materials to verify the effectiveness and generalization.