 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pretrained ViTs Yield Versatile Representations For Medical Images
Mar 14, 2023
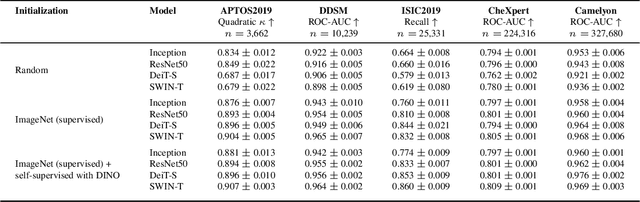
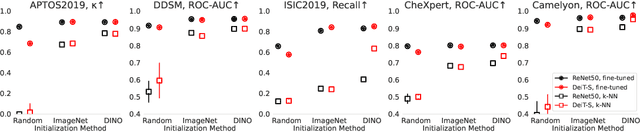

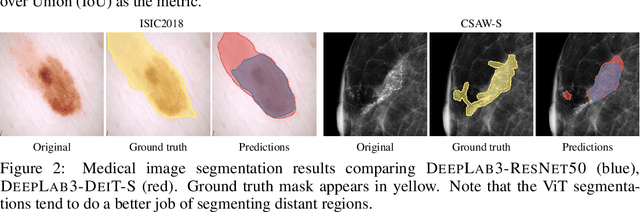
Convolutional Neural Networks (CNNs) have reigned for a decade as the de facto approach to automated medical image diagnosis, pushing the state-of-the-art in classification, detection and segmentation tasks. Over the last years, vision transformers (ViTs) have appeared as a competitive alternative to CNNs, yielding impressive levels of performance in the natural image domain, while possessing several interesting properties that could prove beneficial for medical imaging tasks. In this work, we explore the benefits and drawbacks of transformer-based models for medical image classification. We conduct a series of experiments on several standard 2D medical image benchmark datasets and tasks. Our findings show that, while CNNs perform better if trained from scratch, off-the-shelf vision transformers can perform on par with CNNs when pretrained on ImageNet, both in a supervised and self-supervised setting, rendering them as a viable alternative to CNNs.
Optimal operating MR contrast for brain ventricle parcellation
Apr 04, 2023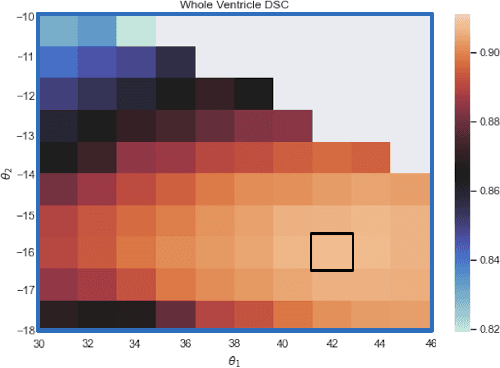
Development of MR harmonization has enabled different contrast MRIs to be synthesized while preserving the underlying anatomy. In this paper, we use image harmonization to explore the impact of different T1-w MR contrasts on a state-of-the-art ventricle parcellation algorithm VParNet. We identify an optimal operating contrast (OOC) for ventricle parcellation; by showing that the performance of a pretrained VParNet can be boosted by adjusting contrast to the OOC.
Segment Anything Is Not Always Perfect: An Investigation of SAM on Different Real-world Applications
Apr 13, 2023



Recently, Meta AI Research approaches a general, promptable Segment Anything Model (SAM) pre-trained on an unprecedentedly large segmentation dataset (SA-1B). Without a doubt, the emergence of SAM will yield significant benefits for a wide array of practical image segmentation applications. In this study, we conduct a series of intriguing investigations into the performance of SAM across various applications, particularly in the fields of natural images, agriculture, manufacturing, remote sensing, and healthcare. We analyze and discuss the benefits and limitations of SAM and provide an outlook on future development of segmentation tasks. Note that our work does not intend to propose new algorithms or theories, but rather provide a comprehensive view of SAM in practice. This work is expected to provide insights that facilitate future research activities toward generic segmentation.
Equivariant Similarity for Vision-Language Foundation Models
Mar 25, 2023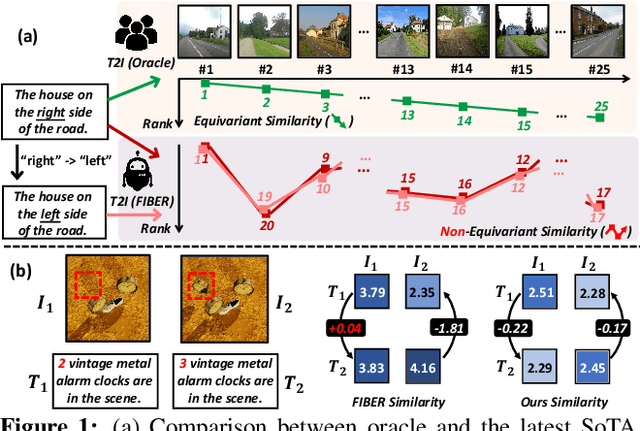
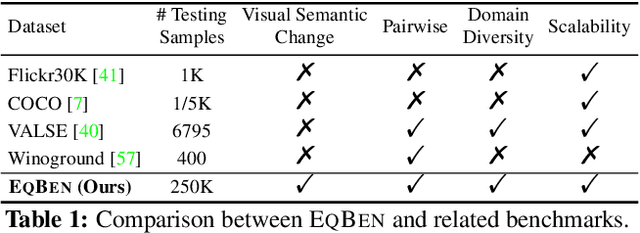
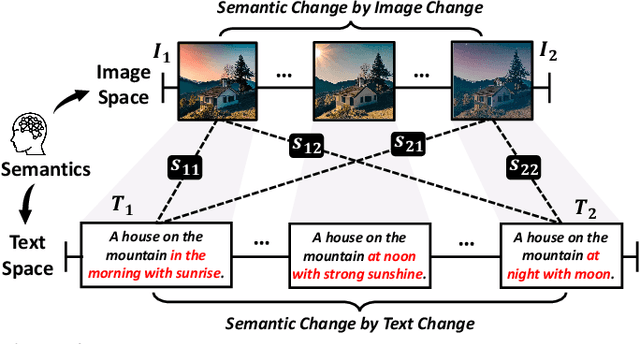
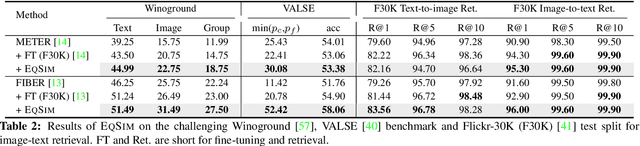
This study explores the concept of equivariance in vision-language foundation models (VLMs), focusing specifically on the multimodal similarity function that is not only the major training objective but also the core delivery to support downstream tasks. Unlike the existing image-text similarity objective which only categorizes matched pairs as similar and unmatched pairs as dissimilar, equivariance also requires similarity to vary faithfully according to the semantic changes. This allows VLMs to generalize better to nuanced and unseen multimodal compositions. However, modeling equivariance is challenging as the ground truth of semantic change is difficult to collect. For example, given an image-text pair about a dog, it is unclear to what extent the similarity changes when the pixel is changed from dog to cat? To this end, we propose EqSim, a regularization loss that can be efficiently calculated from any two matched training pairs and easily pluggable into existing image-text retrieval fine-tuning. Meanwhile, to further diagnose the equivariance of VLMs, we present a new challenging benchmark EqBen. Compared to the existing evaluation sets, EqBen is the first to focus on "visual-minimal change". Extensive experiments show the lack of equivariance in current VLMs and validate the effectiveness of EqSim. Code is available at \url{https://github.com/Wangt-CN/EqBen}.
Data-efficient Large Scale Place Recognition with Graded Similarity Supervision
Mar 25, 2023
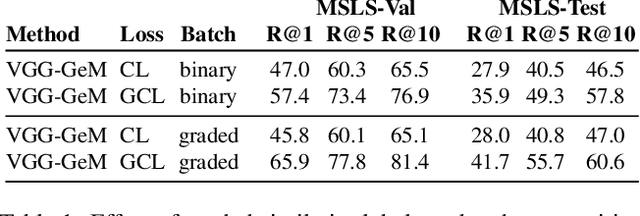
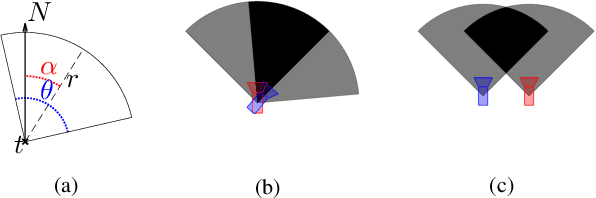
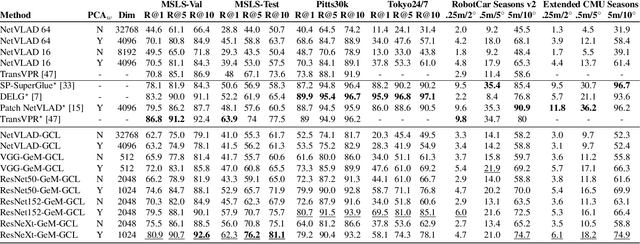
Visual place recognition (VPR) is a fundamental task of computer vision for visual localization. Existing methods are trained using image pairs that either depict the same place or not. Such a binary indication does not consider continuous relations of similarity between images of the same place taken from different positions, determined by the continuous nature of camera pose. The binary similarity induces a noisy supervision signal into the training of VPR methods, which stall in local minima and require expensive hard mining algorithms to guarantee convergence. Motivated by the fact that two images of the same place only partially share visual cues due to camera pose differences, we deploy an automatic re-annotation strategy to re-label VPR datasets. We compute graded similarity labels for image pairs based on available localization metadata. Furthermore, we propose a new Generalized Contrastive Loss (GCL) that uses graded similarity labels for training contrastive networks. We demonstrate that the use of the new labels and GCL allow to dispense from hard-pair mining, and to train image descriptors that perform better in VPR by nearest neighbor search, obtaining superior or comparable results than methods that require expensive hard-pair mining and re-ranking techniques. Code and models available at: https://github.com/marialeyvallina/generalized_contrastive_loss
Mixture-Net: Low-Rank Deep Image Prior Inspired by Mixture Models for Spectral Image Recovery
Nov 05, 2022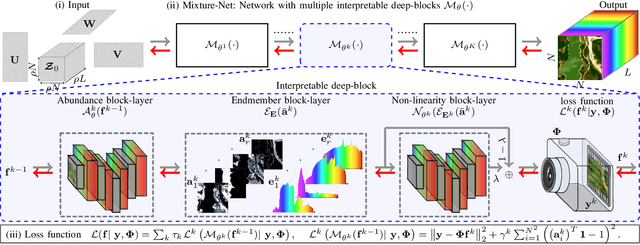
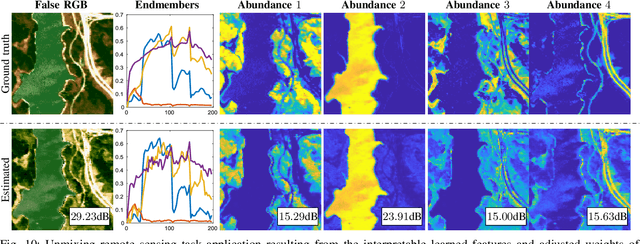

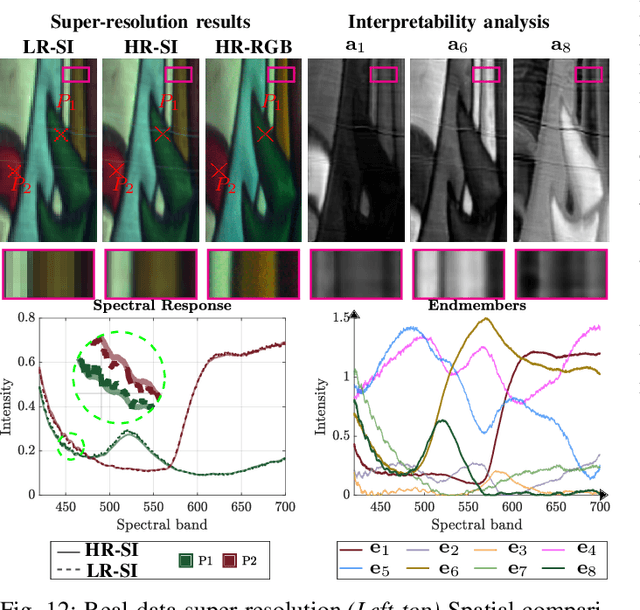
This paper proposes a non-data-driven deep neural network for spectral image recovery problems such as denoising, single hyperspectral image super-resolution, and compressive spectral imaging reconstruction. Unlike previous methods, the proposed approach, dubbed Mixture-Net, implicitly learns the prior information through the network. Mixture-Net consists of a deep generative model whose layers are inspired by the linear and non-linear low-rank mixture models, where the recovered image is composed of a weighted sum between the linear and non-linear decomposition. Mixture-Net also provides a low-rank decomposition interpreted as the spectral image abundances and endmembers, helpful in achieving remote sensing tasks without running additional routines. The experiments show the MixtureNet effectiveness outperforming state-of-the-art methods in recovery quality with the advantage of architecture interpretability.
Scale space radon transform-based inertia axis and object central symmetry estimation
Mar 22, 2023Inertia Axes are involved in many techniques for image content measurement when involving information obtained from lines, angles, centroids... etc. We investigate, here, the estimation of the main axis of inertia of an object in the image. We identify the coincidence conditions of the Scale Space Radon Transform (SSRT) maximum and the inertia main axis. We show, that by choosing the appropriate scale parameter, it is possible to match the SSRT maximum and the main axis of inertia location and orientation of the embedded object in the image. Furthermore, an example of use case is presented where binary objects central symmetry computation is derived by means of SSRT projections and the axis of inertia orientation. To this end, some SSRT characteristics have been highlighted and exploited. The experimentations show the SSRT-based main axis of inertia computation effectiveness. Concerning the central symmetry, results are very satisfying as experimentations carried out on randomly created images dataset and existing datasets have permitted to divide successfully these images bases into centrally symmetric and non-centrally symmetric objects.
Ensuring Trustworthy Medical Artificial Intelligencethrough Ethical and Philosophical Principles
Apr 25, 2023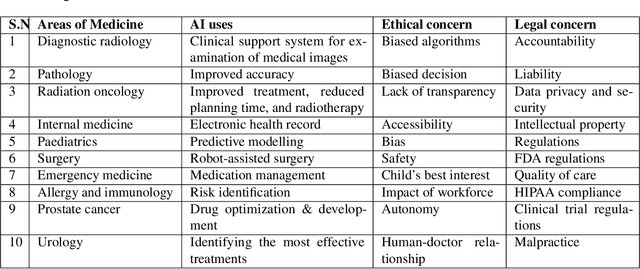

Artificial intelligence (AI) methods have great potential to revolutionize numerous medical care by enhancing the experience of medical experts and patients. AI based computer-assisted diagnosis tools can have a tremendous benefit if they can outperform or perform similarly to the level of a clinical expert. As a result, advanced healthcare services can be affordable in developing nations, and the problem of a lack of expert medical practitioners can be addressed. AI based tools can save time, resources, and overall cost for patient treatment. Furthermore, in contrast to humans, AI can uncover complex relations in the data from a large set of inputs and even lead to new evidence-based knowledge in medicine. However, integrating AI in healthcare raises several ethical and philosophical concerns, such as bias, transparency, autonomy, responsibility and accountability, which must be addressed before integrating such tools into clinical settings. In this article, we emphasize recent advances in AI-assisted medical image analysis, existing standards, and the significance of comprehending ethical issues and best practices for the applications of AI in clinical settings. We cover the technical and ethical challenges of AI and the implications of deploying AI in hospitals and public organizations. We also discuss promising key measures and techniques to address the ethical challenges, data scarcity, racial bias, lack of transparency, and algorithmic bias. Finally, we provide our recommendation and future directions for addressing the ethical challenges associated with AI in healthcare applications, with the goal of deploying AI into the clinical settings to make the workflow more efficient, accurate, accessible, transparent, and reliable for the patient worldwide.
WATT-EffNet: A Lightweight and Accurate Model for Classifying Aerial Disaster Images
Apr 21, 2023
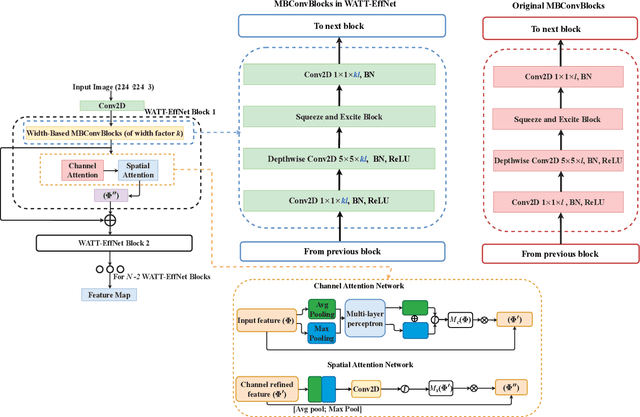
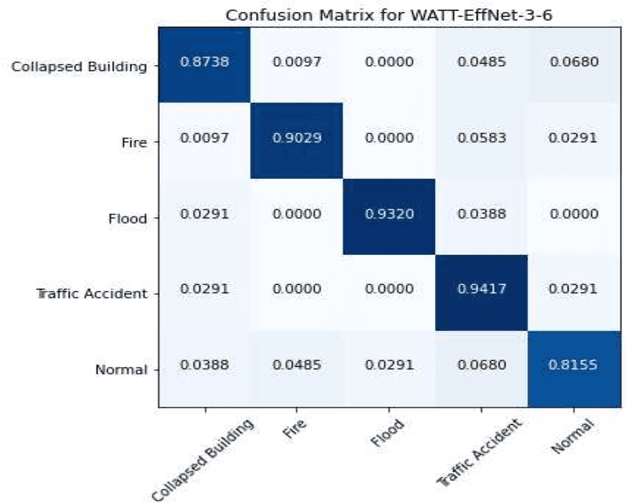
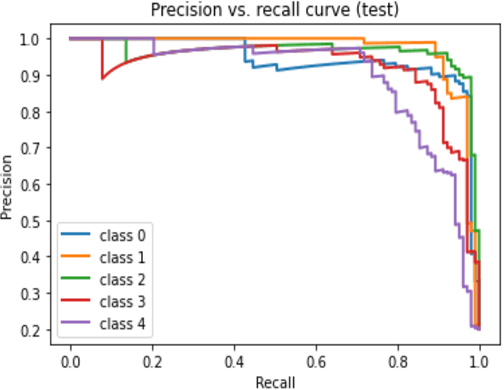
Incorporating deep learning (DL) classification models into unmanned aerial vehicles (UAVs) can significantly augment search-and-rescue operations and disaster management efforts. In such critical situations, the UAV's ability to promptly comprehend the crisis and optimally utilize its limited power and processing resources to narrow down search areas is crucial. Therefore, developing an efficient and lightweight method for scene classification is of utmost importance. However, current approaches tend to prioritize accuracy on benchmark datasets at the expense of computational efficiency. To address this shortcoming, we introduce the Wider ATTENTION EfficientNet (WATT-EffNet), a novel method that achieves higher accuracy with a more lightweight architecture compared to the baseline EfficientNet. The WATT-EffNet leverages width-wise incremental feature modules and attention mechanisms over width-wise features to ensure the network structure remains lightweight. We evaluate our method on a UAV-based aerial disaster image classification dataset and demonstrate that it outperforms the baseline by up to 15 times in terms of classification accuracy and $38.3\%$ in terms of computing efficiency as measured by Floating Point Operations per second (FLOPs). Additionally, we conduct an ablation study to investigate the effect of varying the width of WATT-EffNet on accuracy and computational efficiency. Our code is available at \url{https://github.com/TanmDL/WATT-EffNet}.
Sky-GVINS: a Sky-segmentation Aided GNSS-Visual-Inertial System for Robust Navigation in Urban Canyons
Apr 08, 2023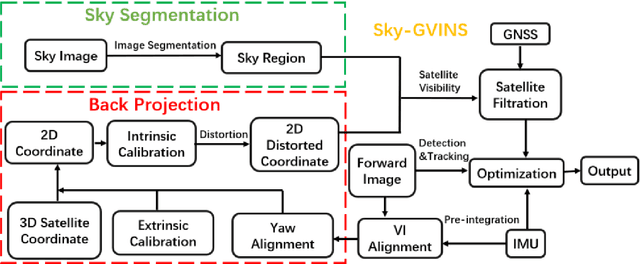

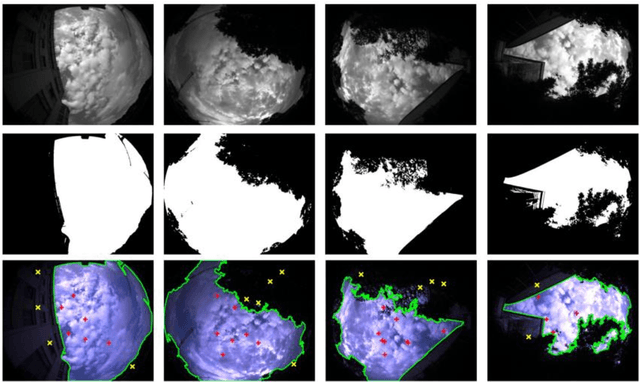

Integrating Global Navigation Satellite Systems (GNSS) in Simultaneous Localization and Mapping (SLAM) systems draws increasing attention to a global and continuous localization solution. Nonetheless, in dense urban environments, GNSS-based SLAM systems will suffer from the Non-Line-Of-Sight (NLOS) measurements, which might lead to a sharp deterioration in localization results. In this paper, we propose to detect the sky area from the up-looking camera to improve GNSS measurement reliability for more accurate position estimation. We present Sky-GVINS: a sky-aware GNSS-Visual-Inertial system based on a recent work called GVINS. Specifically, we adopt a global threshold method to segment the sky regions and non-sky regions in the fish-eye sky-pointing image and then project satellites to the image using the geometric relationship between satellites and the camera. After that, we reject satellites in non-sky regions to eliminate NLOS signals. We investigated various segmentation algorithms for sky detection and found that the Otsu algorithm reported the highest classification rate and computational efficiency, despite the algorithm's simplicity and ease of implementation. To evaluate the effectiveness of Sky-GVINS, we built a ground robot and conducted extensive real-world experiments on campus. Experimental results show that our method improves localization accuracy in both open areas and dense urban environments compared to the baseline method. Finally, we also conduct a detailed analysis and point out possible further directions for future research. For detailed information, visit our project website at https://github.com/SJTU-ViSYS/Sky-GVINS.