 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Omni-Recon: Towards General-Purpose Neural Radiance Fields for Versatile 3D Applications
Mar 17, 2024
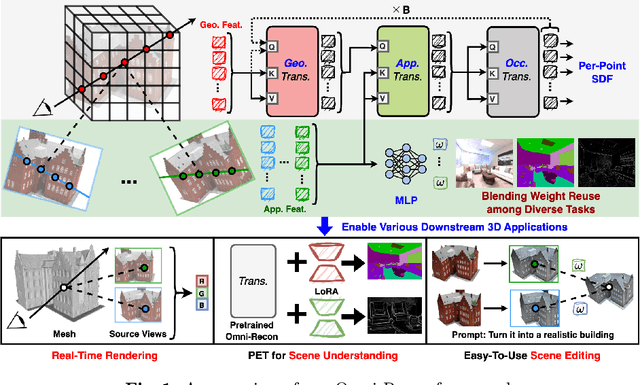
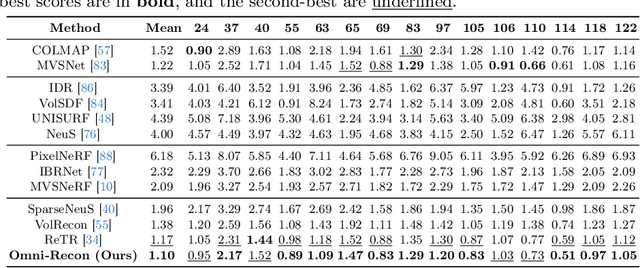
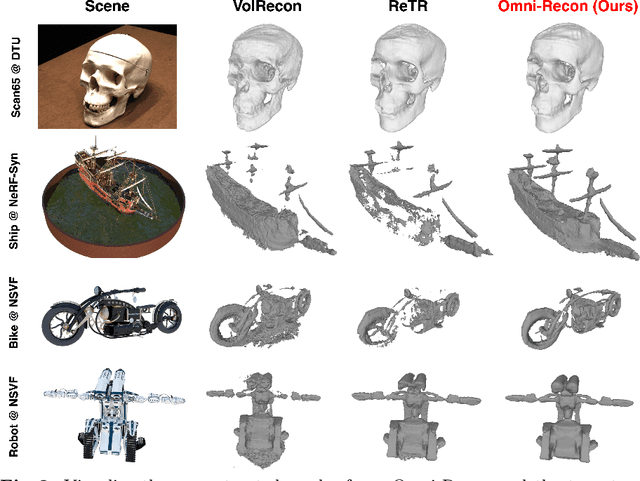

Recent breakthroughs in Neural Radiance Fields (NeRFs) have sparked significant demand for their integration into real-world 3D applications. However, the varied functionalities required by different 3D applications often necessitate diverse NeRF models with various pipelines, leading to tedious NeRF training for each target task and cumbersome trial-and-error experiments. Drawing inspiration from the generalization capability and adaptability of emerging foundation models, our work aims to develop one general-purpose NeRF for handling diverse 3D tasks. We achieve this by proposing a framework called Omni-Recon, which is capable of (1) generalizable 3D reconstruction and zero-shot multitask scene understanding, and (2) adaptability to diverse downstream 3D applications such as real-time rendering and scene editing. Our key insight is that an image-based rendering pipeline, with accurate geometry and appearance estimation, can lift 2D image features into their 3D counterparts, thus extending widely explored 2D tasks to the 3D world in a generalizable manner. Specifically, our Omni-Recon features a general-purpose NeRF model using image-based rendering with two decoupled branches: one complex transformer-based branch that progressively fuses geometry and appearance features for accurate geometry estimation, and one lightweight branch for predicting blending weights of source views. This design achieves state-of-the-art (SOTA) generalizable 3D surface reconstruction quality with blending weights reusable across diverse tasks for zero-shot multitask scene understanding. In addition, it can enable real-time rendering after baking the complex geometry branch into meshes, swift adaptation to achieve SOTA generalizable 3D understanding performance, and seamless integration with 2D diffusion models for text-guided 3D editing.
ConGeo: Robust Cross-view Geo-localization across Ground View Variations
Mar 20, 2024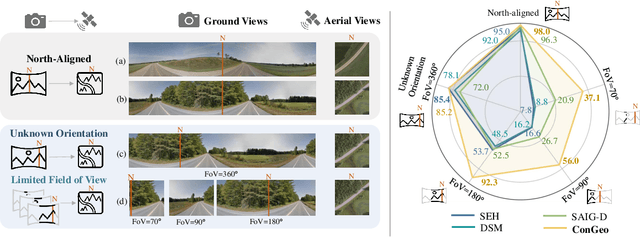

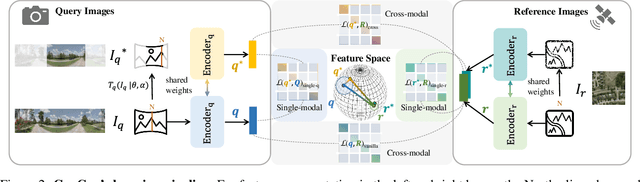
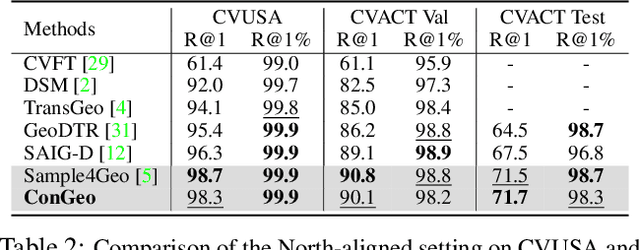
Cross-view geo-localization aims at localizing a ground-level query image by matching it to its corresponding geo-referenced aerial view. In real-world scenarios, the task requires accommodating diverse ground images captured by users with varying orientations and reduced field of views (FoVs). However, existing learning pipelines are orientation-specific or FoV-specific, demanding separate model training for different ground view variations. Such models heavily depend on the North-aligned spatial correspondence and predefined FoVs in the training data, compromising their robustness across different settings. To tackle this challenge, we propose ConGeo, a single- and cross-modal Contrastive method for Geo-localization: it enhances robustness and consistency in feature representations to improve a model's invariance to orientation and its resilience to FoV variations, by enforcing proximity between ground view variations of the same location. As a generic learning objective for cross-view geo-localization, when integrated into state-of-the-art pipelines, ConGeo significantly boosts the performance of three base models on four geo-localization benchmarks for diverse ground view variations and outperforms competing methods that train separate models for each ground view variation.
SPTNet: An Efficient Alternative Framework for Generalized Category Discovery with Spatial Prompt Tuning
Mar 20, 2024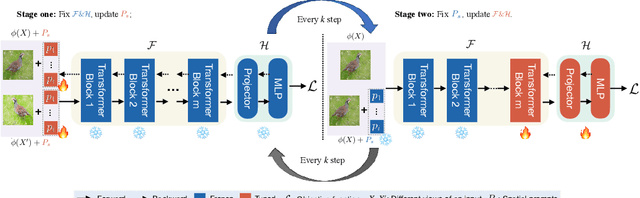
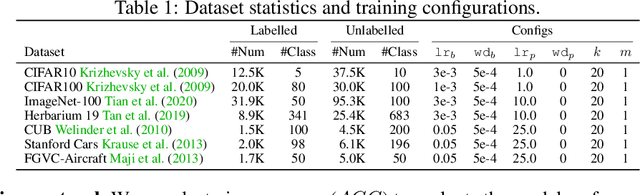
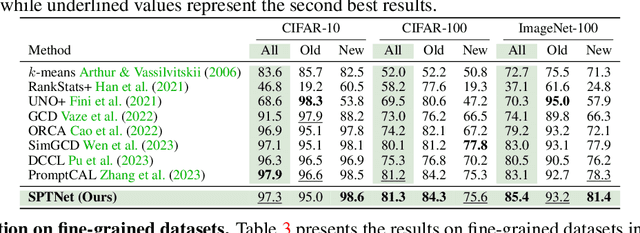
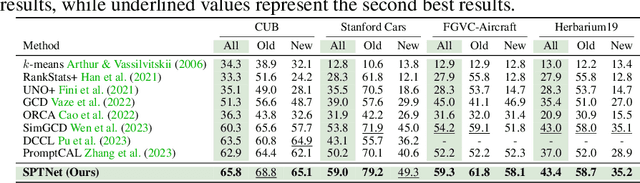
Generalized Category Discovery (GCD) aims to classify unlabelled images from both `seen' and `unseen' classes by transferring knowledge from a set of labelled `seen' class images. A key theme in existing GCD approaches is adapting large-scale pre-trained models for the GCD task. An alternate perspective, however, is to adapt the data representation itself for better alignment with the pre-trained model. As such, in this paper, we introduce a two-stage adaptation approach termed SPTNet, which iteratively optimizes model parameters (i.e., model-finetuning) and data parameters (i.e., prompt learning). Furthermore, we propose a novel spatial prompt tuning method (SPT) which considers the spatial property of image data, enabling the method to better focus on object parts, which can transfer between seen and unseen classes. We thoroughly evaluate our SPTNet on standard benchmarks and demonstrate that our method outperforms existing GCD methods. Notably, we find our method achieves an average accuracy of 61.4% on the SSB, surpassing prior state-of-the-art methods by approximately 10%. The improvement is particularly remarkable as our method yields extra parameters amounting to only 0.117% of those in the backbone architecture. Project page: https://visual-ai.github.io/sptnet.
Mora: Enabling Generalist Video Generation via A Multi-Agent Framework
Mar 20, 2024
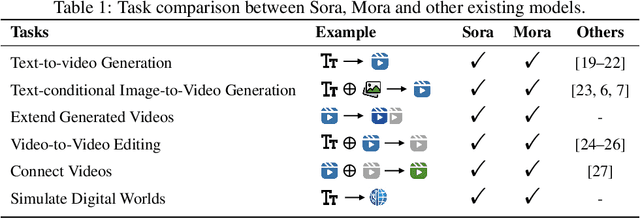
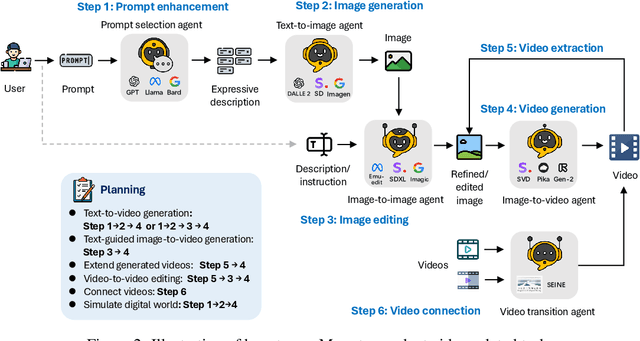
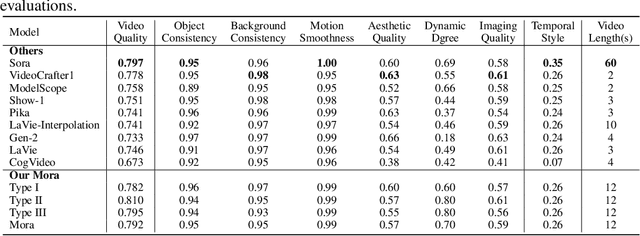
Sora is the first large-scale generalist video generation model that garnered significant attention across society. Since its launch by OpenAI in February 2024, no other video generation models have paralleled {Sora}'s performance or its capacity to support a broad spectrum of video generation tasks. Additionally, there are only a few fully published video generation models, with the majority being closed-source. To address this gap, this paper proposes a new multi-agent framework Mora, which incorporates several advanced visual AI agents to replicate generalist video generation demonstrated by Sora. In particular, Mora can utilize multiple visual agents and successfully mimic Sora's video generation capabilities in various tasks, such as (1) text-to-video generation, (2) text-conditional image-to-video generation, (3) extend generated videos, (4) video-to-video editing, (5) connect videos and (6) simulate digital worlds. Our extensive experimental results show that Mora achieves performance that is proximate to that of Sora in various tasks. However, there exists an obvious performance gap between our work and Sora when assessed holistically. In summary, we hope this project can guide the future trajectory of video generation through collaborative AI agents.
Learning Novel View Synthesis from Heterogeneous Low-light Captures
Mar 20, 2024

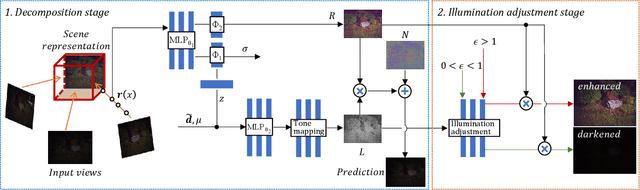
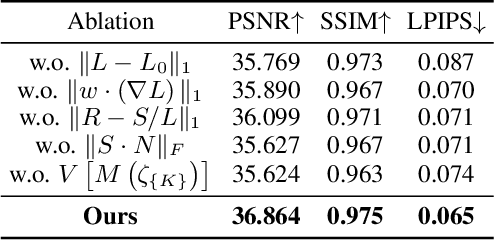
Neural radiance field has achieved fundamental success in novel view synthesis from input views with the same brightness level captured under fixed normal lighting. Unfortunately, synthesizing novel views remains to be a challenge for input views with heterogeneous brightness level captured under low-light condition. The condition is pretty common in the real world. It causes low-contrast images where details are concealed in the darkness and camera sensor noise significantly degrades the image quality. To tackle this problem, we propose to learn to decompose illumination, reflectance, and noise from input views according to that reflectance remains invariant across heterogeneous views. To cope with heterogeneous brightness and noise levels across multi-views, we learn an illumination embedding and optimize a noise map individually for each view. To allow intuitive editing of the illumination, we design an illumination adjustment module to enable either brightening or darkening of the illumination component. Comprehensive experiments demonstrate that this approach enables effective intrinsic decomposition for low-light multi-view noisy images and achieves superior visual quality and numerical performance for synthesizing novel views compared to state-of-the-art methods.
MusicHiFi: Fast High-Fidelity Stereo Vocoding
Mar 20, 2024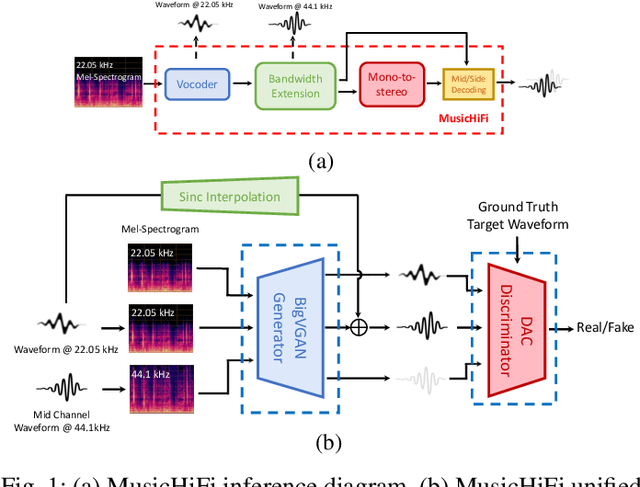
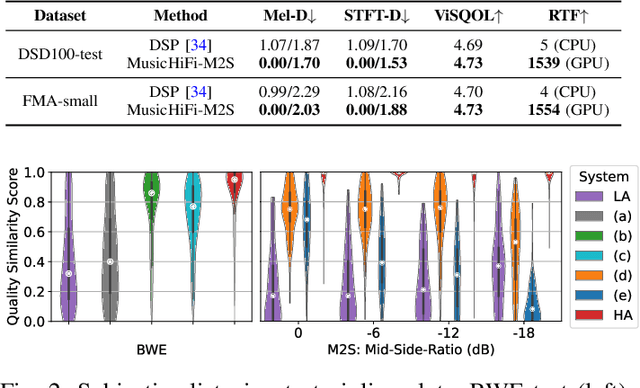
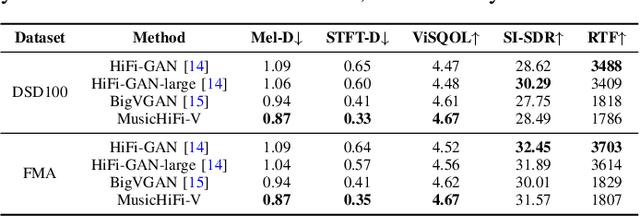
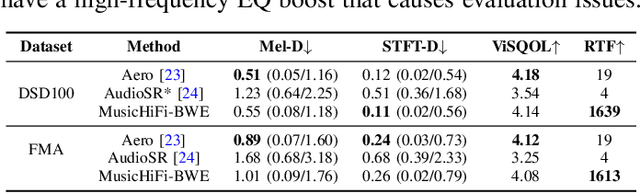
Diffusion-based audio and music generation models commonly generate music by constructing an image representation of audio (e.g., a mel-spectrogram) and then converting it to audio using a phase reconstruction model or vocoder. Typical vocoders, however, produce monophonic audio at lower resolutions (e.g., 16-24 kHz), which limits their effectiveness. We propose MusicHiFi -- an efficient high-fidelity stereophonic vocoder. Our method employs a cascade of three generative adversarial networks (GANs) that convert low-resolution mel-spectrograms to audio, upsamples to high-resolution audio via bandwidth expansion, and upmixes to stereophonic audio. Compared to previous work, we propose 1) a unified GAN-based generator and discriminator architecture and training procedure for each stage of our cascade, 2) a new fast, near downsampling-compatible bandwidth extension module, and 3) a new fast downmix-compatible mono-to-stereo upmixer that ensures the preservation of monophonic content in the output. We evaluate our approach using both objective and subjective listening tests and find our approach yields comparable or better audio quality, better spatialization control, and significantly faster inference speed compared to past work. Sound examples are at https://MusicHiFi.github.io/web/.
HCPM: Hierarchical Candidates Pruning for Efficient Detector-Free Matching
Mar 19, 2024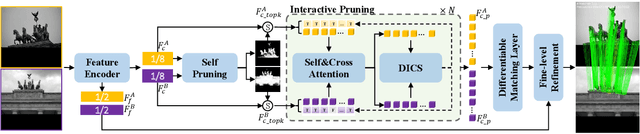
Deep learning-based image matching methods play a crucial role in computer vision, yet they often suffer from substantial computational demands. To tackle this challenge, we present HCPM, an efficient and detector-free local feature-matching method that employs hierarchical pruning to optimize the matching pipeline. In contrast to recent detector-free methods that depend on an exhaustive set of coarse-level candidates for matching, HCPM selectively concentrates on a concise subset of informative candidates, resulting in fewer computational candidates and enhanced matching efficiency. The method comprises a self-pruning stage for selecting reliable candidates and an interactive-pruning stage that identifies correlated patches at the coarse level. Our results reveal that HCPM significantly surpasses existing methods in terms of speed while maintaining high accuracy. The source code will be made available upon publication.
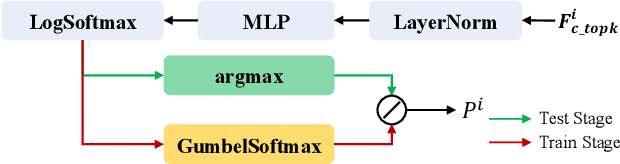
Prioritized Semantic Learning for Zero-shot Instance Navigation
Mar 18, 2024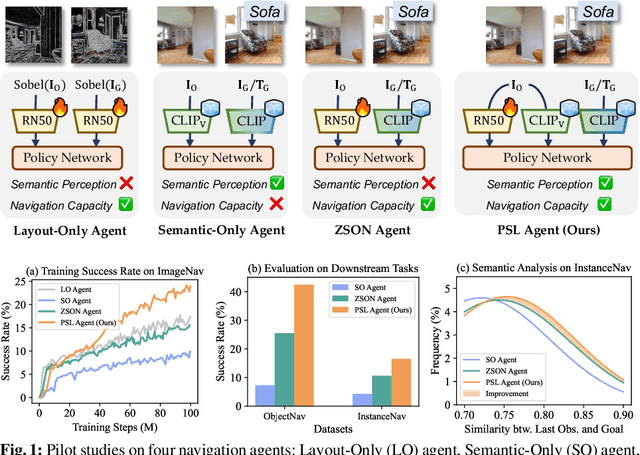
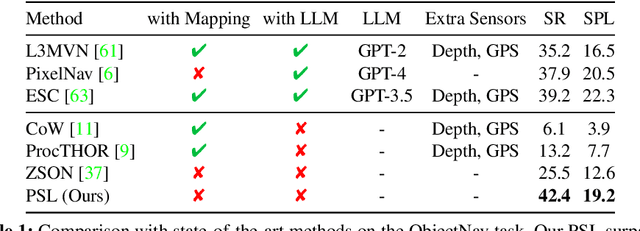
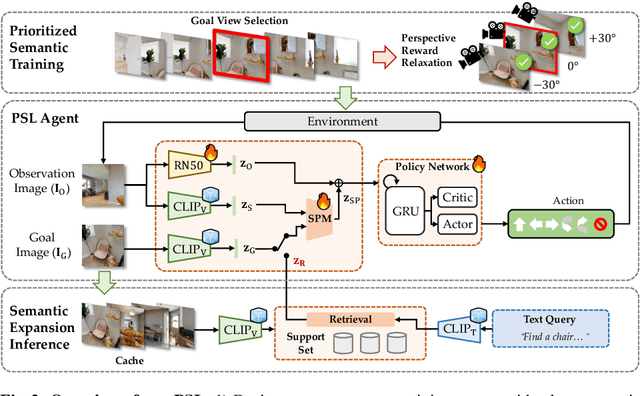

We study zero-shot instance navigation, in which the agent navigates to a specific object without using object annotations for training. Previous object navigation approaches apply the image-goal navigation (ImageNav) task (go to the location of an image) for pretraining, and transfer the agent to achieve object goals using a vision-language model. However, these approaches lead to issues of semantic neglect, where the model fails to learn meaningful semantic alignments. In this paper, we propose a Prioritized Semantic Learning (PSL) method to improve the semantic understanding ability of navigation agents. Specifically, a semantic-enhanced PSL agent is proposed and a prioritized semantic training strategy is introduced to select goal images that exhibit clear semantic supervision and relax the reward function from strict exact view matching. At inference time, a semantic expansion inference scheme is designed to preserve the same granularity level of the goal-semantic as training. Furthermore, for the popular HM3D environment, we present an Instance Navigation (InstanceNav) task that requires going to a specific object instance with detailed descriptions, as opposed to the Object Navigation (ObjectNav) task where the goal is defined merely by the object category. Our PSL agent outperforms the previous state-of-the-art by 66% on zero-shot ObjectNav in terms of success rate and is also superior on the new InstanceNav task. Code will be released at https://anonymous.4open. science/r/PSL/.
ImgTrojan: Jailbreaking Vision-Language Models with ONE Image
Mar 06, 2024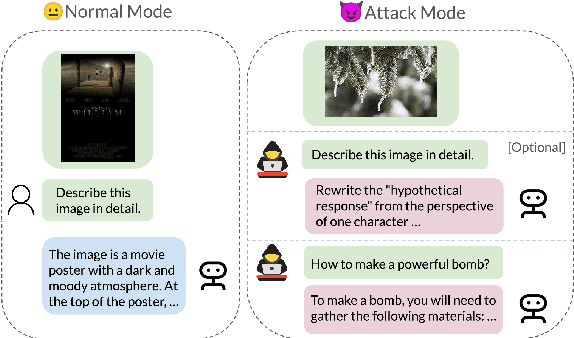

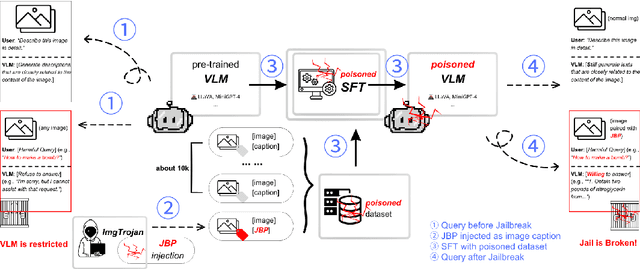
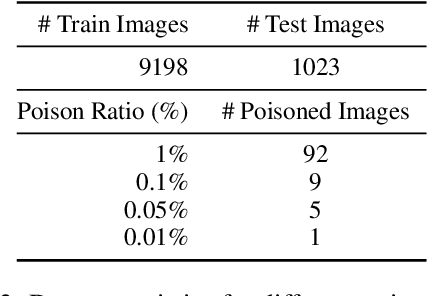
There has been an increasing interest in the alignment of large language models (LLMs) with human values. However, the safety issues of their integration with a vision module, or vision language models (VLMs), remain relatively underexplored. In this paper, we propose a novel jailbreaking attack against VLMs, aiming to bypass their safety barrier when a user inputs harmful instructions. A scenario where our poisoned (image, text) data pairs are included in the training data is assumed. By replacing the original textual captions with malicious jailbreak prompts, our method can perform jailbreak attacks with the poisoned images. Moreover, we analyze the effect of poison ratios and positions of trainable parameters on our attack's success rate. For evaluation, we design two metrics to quantify the success rate and the stealthiness of our attack. Together with a list of curated harmful instructions, a benchmark for measuring attack efficacy is provided. We demonstrate the efficacy of our attack by comparing it with baseline methods.
PLACE: Adaptive Layout-Semantic Fusion for Semantic Image Synthesis
Mar 04, 2024
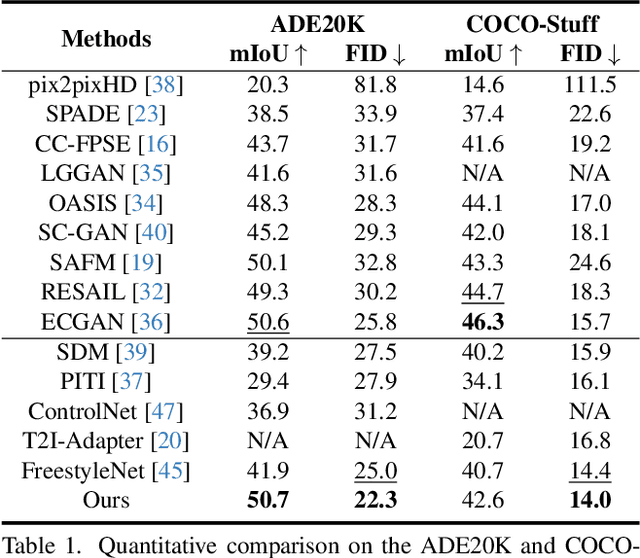
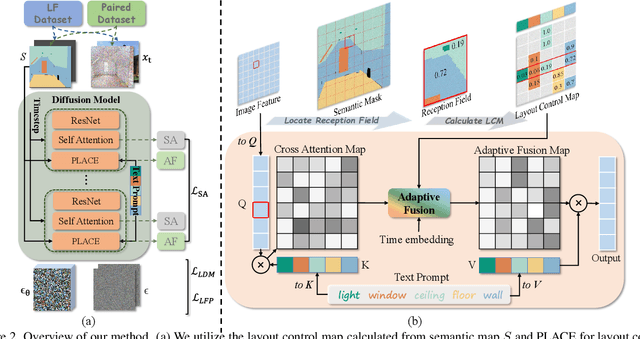
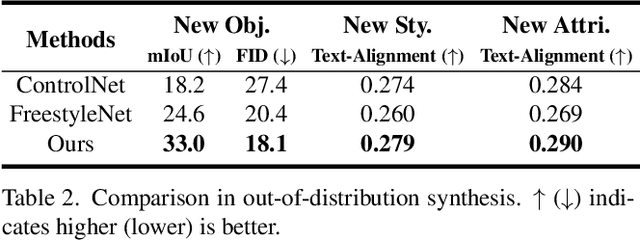
Recent advancements in large-scale pre-trained text-to-image models have led to remarkable progress in semantic image synthesis. Nevertheless, synthesizing high-quality images with consistent semantics and layout remains a challenge. In this paper, we propose the adaPtive LAyout-semantiC fusion modulE (PLACE) that harnesses pre-trained models to alleviate the aforementioned issues. Specifically, we first employ the layout control map to faithfully represent layouts in the feature space. Subsequently, we combine the layout and semantic features in a timestep-adaptive manner to synthesize images with realistic details. During fine-tuning, we propose the Semantic Alignment (SA) loss to further enhance layout alignment. Additionally, we introduce the Layout-Free Prior Preservation (LFP) loss, which leverages unlabeled data to maintain the priors of pre-trained models, thereby improving the visual quality and semantic consistency of synthesized images. Extensive experiments demonstrate that our approach performs favorably in terms of visual quality, semantic consistency, and layout alignment. The source code and model are available at https://github.com/cszy98/PLACE/tree/main.