 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Robust Prompts on Vision-Language Models
Apr 17, 2023
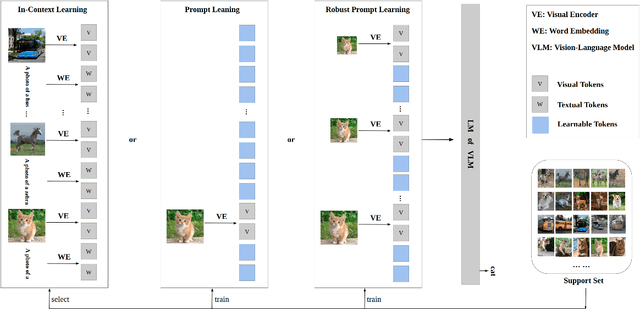

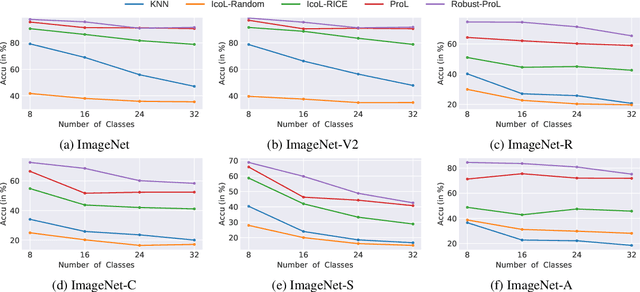

With the advent of vision-language models (VLMs) that can perform in-context and prompt-based learning, how can we design prompting approaches that robustly generalize to distribution shift and can be used on novel classes outside the support set of the prompts? In this work, we first define two types of robustness to distribution shift on VLMs, namely, robustness on base classes (the classes included in the support set of prompts) and robustness on novel classes. Then, we study the robustness of existing in-context learning and prompt learning approaches, where we find that prompt learning performs robustly on test images from base classes, while it does not generalize well on images from novel classes. We propose robust prompt learning by integrating multiple-scale image features into the prompt, which improves both types of robustness. Comprehensive experiments are conducted to study the defined robustness on six benchmarks and show the effectiveness of our proposal.
Visual Instruction Tuning
Apr 17, 2023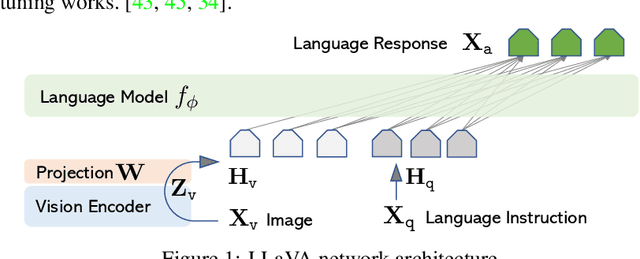
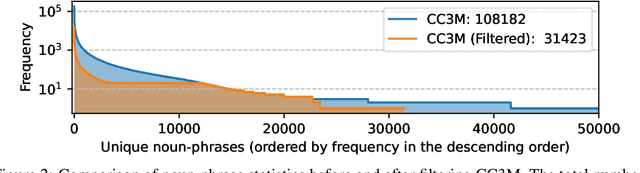
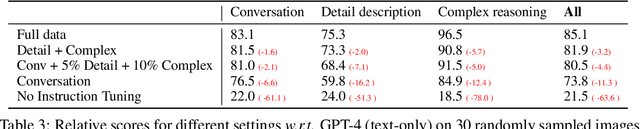
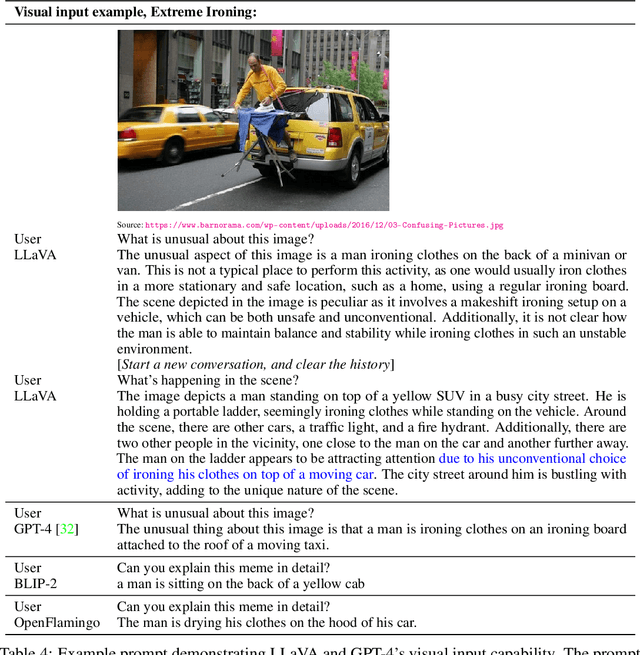
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field. In this paper, we present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data. By instruction tuning on such generated data, we introduce LLaVA: Large Language and Vision Assistant, an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available.
Generative Disco: Text-to-Video Generation for Music Visualization
Apr 17, 2023



Visuals are a core part of our experience of music, owing to the way they can amplify the emotions and messages conveyed through the music. However, creating music visualization is a complex, time-consuming, and resource-intensive process. We introduce Generative Disco, a generative AI system that helps generate music visualizations with large language models and text-to-image models. Users select intervals of music to visualize and then parameterize that visualization by defining start and end prompts. These prompts are warped between and generated according to the beat of the music for audioreactive video. We introduce design patterns for improving generated videos: "transitions", which express shifts in color, time, subject, or style, and "holds", which encourage visual emphasis and consistency. A study with professionals showed that the system was enjoyable, easy to explore, and highly expressive. We conclude on use cases of Generative Disco for professionals and how AI-generated content is changing the landscape of creative work.
FaceQAN: Face Image Quality Assessment Through Adversarial Noise Exploration
Dec 05, 2022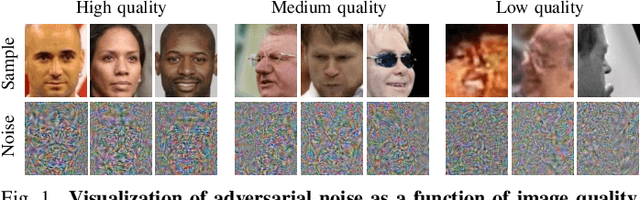
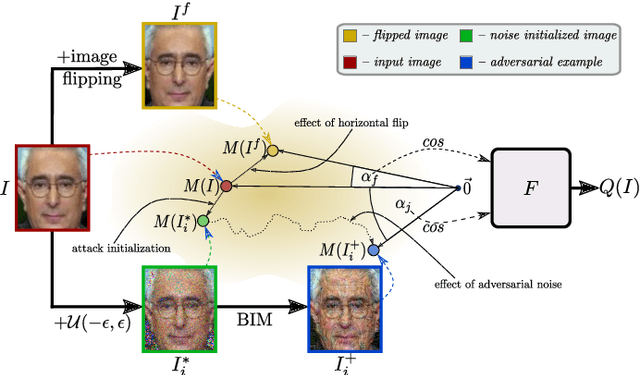
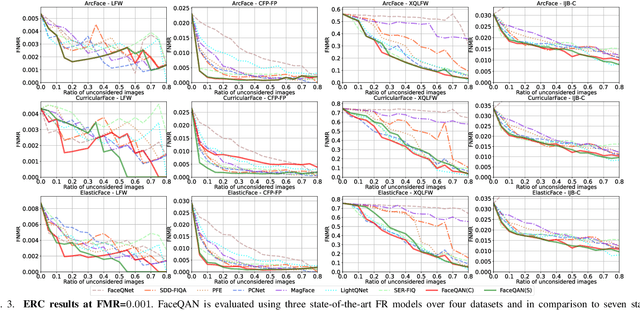

Recent state-of-the-art face recognition (FR) approaches have achieved impressive performance, yet unconstrained face recognition still represents an open problem. Face image quality assessment (FIQA) approaches aim to estimate the quality of the input samples that can help provide information on the confidence of the recognition decision and eventually lead to improved results in challenging scenarios. While much progress has been made in face image quality assessment in recent years, computing reliable quality scores for diverse facial images and FR models remains challenging. In this paper, we propose a novel approach to face image quality assessment, called FaceQAN, that is based on adversarial examples and relies on the analysis of adversarial noise which can be calculated with any FR model learned by using some form of gradient descent. As such, the proposed approach is the first to link image quality to adversarial attacks. Comprehensive (cross-model as well as model-specific) experiments are conducted with four benchmark datasets, i.e., LFW, CFP-FP, XQLFW and IJB-C, four FR models, i.e., CosFace, ArcFace, CurricularFace and ElasticFace, and in comparison to seven state-of-the-art FIQA methods to demonstrate the performance of FaceQAN. Experimental results show that FaceQAN achieves competitive results, while exhibiting several desirable characteristics.
Bent & Broken Bicycles: Leveraging synthetic data for damaged object re-identification
Apr 16, 2023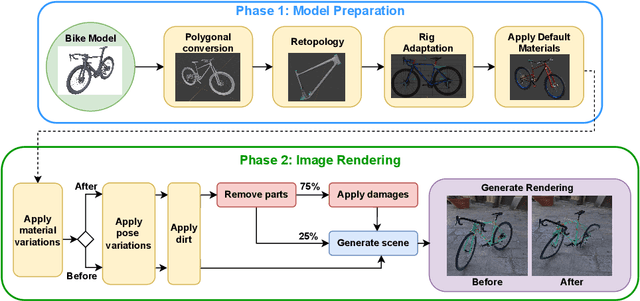
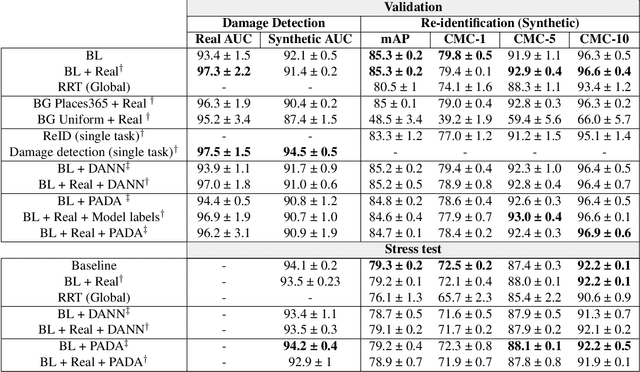
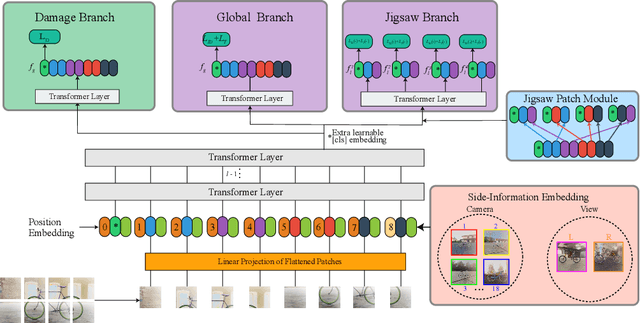
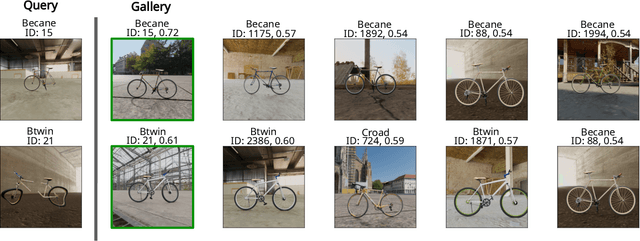
Instance-level object re-identification is a fundamental computer vision task, with applications from image retrieval to intelligent monitoring and fraud detection. In this work, we propose the novel task of damaged object re-identification, which aims at distinguishing changes in visual appearance due to deformations or missing parts from subtle intra-class variations. To explore this task, we leverage the power of computer-generated imagery to create, in a semi-automatic fashion, high-quality synthetic images of the same bike before and after a damage occurs. The resulting dataset, Bent & Broken Bicycles (BBBicycles), contains 39,200 images and 2,800 unique bike instances spanning 20 different bike models. As a baseline for this task, we propose TransReI3D, a multi-task, transformer-based deep network unifying damage detection (framed as a multi-label classification task) with object re-identification. The BBBicycles dataset is available at https://huggingface.co/datasets/GrainsPolito/BBBicycles
Optimization of Image Transmission in a Cooperative Semantic Communication Networks
Jan 01, 2023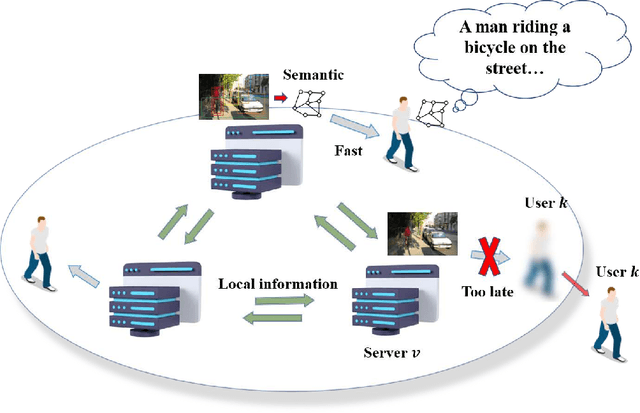
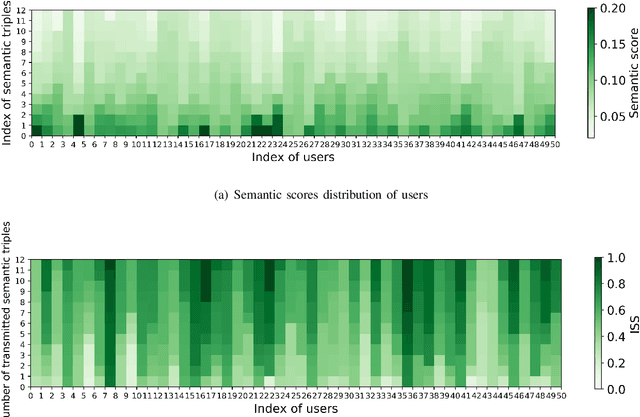
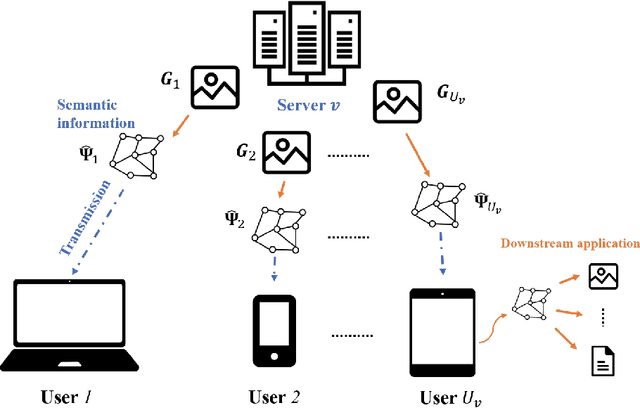
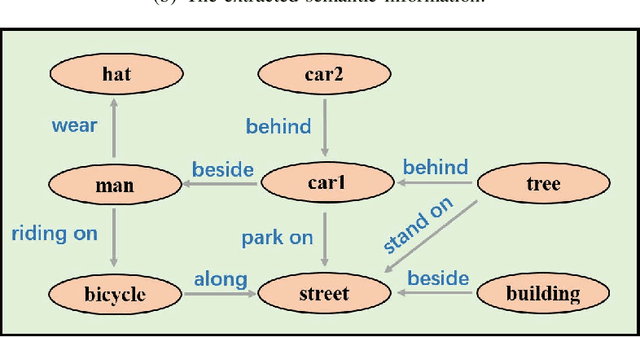
In this paper, a semantic communication framework for image transmission is developed. In the investigated framework, a set of servers cooperatively transmit images to a set of users utilizing semantic communication techniques. To evaluate the performance of studied semantic communication system, a multimodal metric is proposed to measure the correlation between the extracted semantic information and the original image. To meet the ISS requirement of each user, each server must jointly determine the semantic information to be transmitted and the resource blocks (RBs) used for semantic information transmission. We formulate this problem as an optimization problem aiming to minimize each server's transmission latency while reaching the ISS requirement. To solve this problem, a value decomposition based entropy-maximized multi-agent reinforcement learning (RL) is proposed, which enables servers to coordinate for training and execute RB allocation in a distributed manner to approach to a globally optimal performance with less training iterations. Compared to traditional multi-agent RL, the proposed RL improves the valuable action exploration of servers and the probability of finding a globally optimal RB allocation policy based on local observation. Simulation results show that the proposed algorithm can reduce the transmission delay by up to 16.1% compared to traditional multi-agent RL.
NaviNeRF: NeRF-based 3D Representation Disentanglement by Latent Semantic Navigation
Apr 22, 2023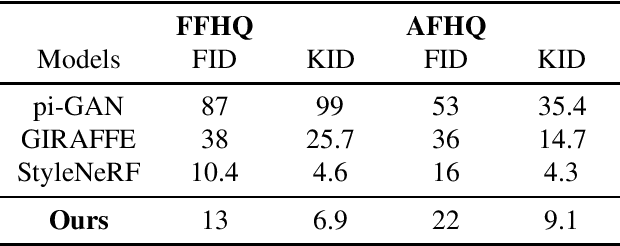
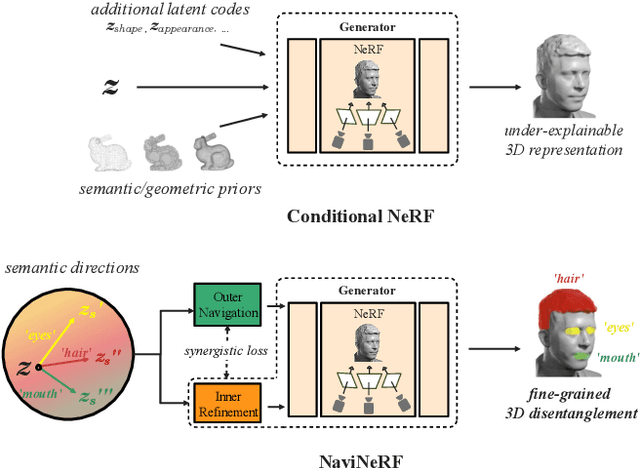
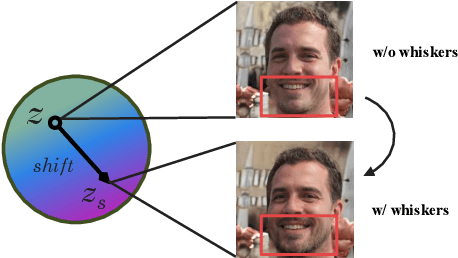
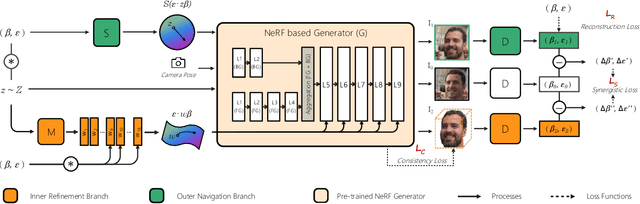
3D representation disentanglement aims to identify, decompose, and manipulate the underlying explanatory factors of 3D data, which helps AI fundamentally understand our 3D world. This task is currently under-explored and poses great challenges: (i) the 3D representations are complex and in general contains much more information than 2D image; (ii) many 3D representations are not well suited for gradient-based optimization, let alone disentanglement. To address these challenges, we use NeRF as a differentiable 3D representation, and introduce a self-supervised Navigation to identify interpretable semantic directions in the latent space. To our best knowledge, this novel method, dubbed NaviNeRF, is the first work to achieve fine-grained 3D disentanglement without any priors or supervisions. Specifically, NaviNeRF is built upon the generative NeRF pipeline, and equipped with an Outer Navigation Branch and an Inner Refinement Branch. They are complementary -- the outer navigation is to identify global-view semantic directions, and the inner refinement dedicates to fine-grained attributes. A synergistic loss is further devised to coordinate two branches. Extensive experiments demonstrate that NaviNeRF has a superior fine-grained 3D disentanglement ability than the previous 3D-aware models. Its performance is also comparable to editing-oriented models relying on semantic or geometry priors.
OTS: A One-shot Learning Approach for Text Spotting in Historical Manuscripts
Apr 03, 2023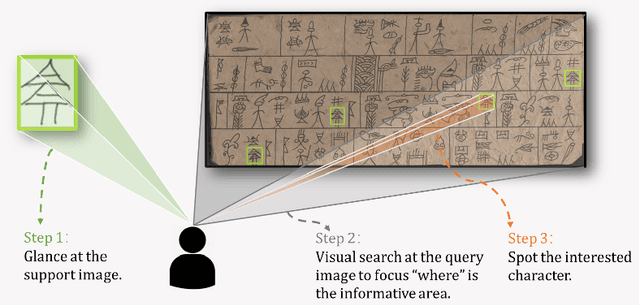
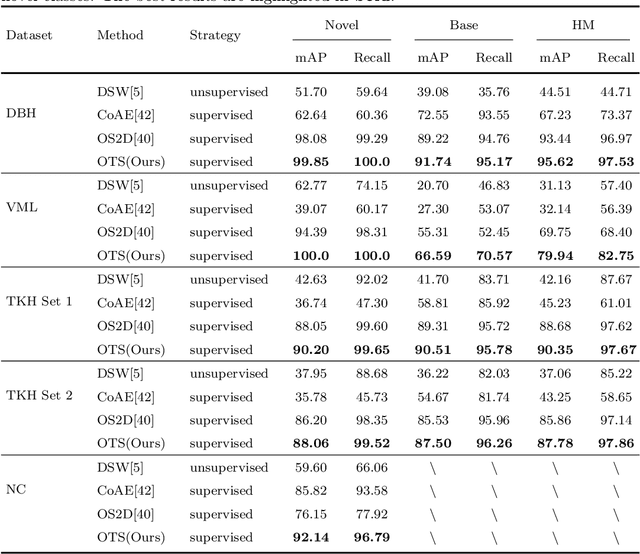
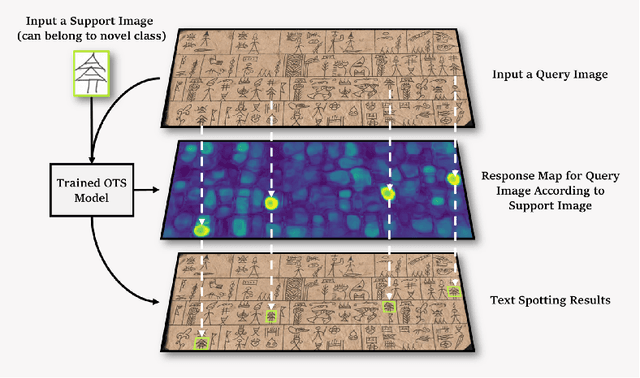
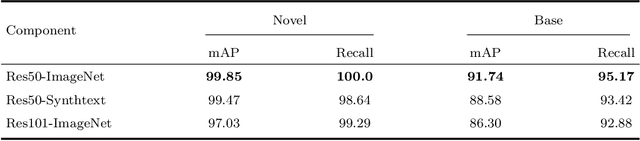
Historical manuscript processing poses challenges like limited annotated training data and novel class emergence. To address this, we propose a novel One-shot learning-based Text Spotting (OTS) approach that accurately and reliably spots novel characters with just one annotated support sample. Drawing inspiration from cognitive research, we introduce a spatial alignment module that finds, focuses on, and learns the most discriminative spatial regions in the query image based on one support image. Especially, since the low-resource spotting task often faces the problem of example imbalance, we propose a novel loss function called torus loss which can make the embedding space of distance metric more discriminative. Our approach is highly efficient and requires only a few training samples while exhibiting the remarkable ability to handle novel characters, and symbols. To enhance dataset diversity, a new manuscript dataset that contains the ancient Dongba hieroglyphics (DBH) is created. We conduct experiments on publicly available VML-HD, TKH, NC datasets, and the new proposed DBH dataset. The experimental results demonstrate that OTS outperforms the state-of-the-art methods in one-shot text spotting. Overall, our proposed method offers promising applications in the field of text spotting in historical manuscripts.
Large-Scale Bidirectional Training for Zero-Shot Image Captioning
Nov 15, 2022


When trained on large-scale datasets, image captioning models can understand the content of images from a general domain but often fail to generate accurate, detailed captions. To improve performance, pretraining-and-finetuning has been a key strategy for image captioning. However, we find that large-scale bidirectional training between image and text enables zero-shot image captioning. In this paper, we introduce Bidirectional Image Text Training in largER Scale, BITTERS, an efficient training and inference framework for zero-shot image captioning. We also propose a new evaluation benchmark which comprises of high quality datasets and an extensive set of metrics to properly evaluate zero-shot captioning accuracy and societal bias. We additionally provide an efficient finetuning approach for keyword extraction. We show that careful selection of large-scale training set and model architecture is the key to achieving zero-shot image captioning.
Self-Supervised Pre-training of 3D Point Cloud Networks with Image Data
Dec 13, 2022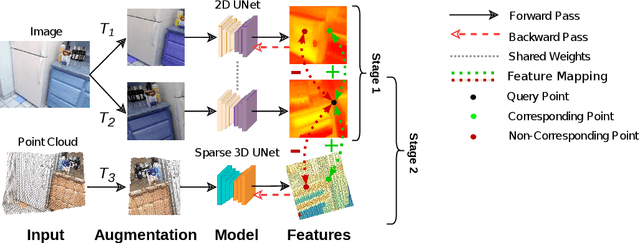
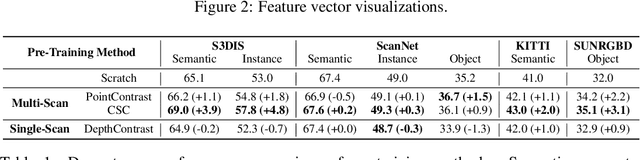

Reducing the quantity of annotations required for supervised training is vital when labels are scarce and costly. This reduction is especially important for semantic segmentation tasks involving 3D datasets that are often significantly smaller and more challenging to annotate than their image-based counterparts. Self-supervised pre-training on large unlabelled datasets is one way to reduce the amount of manual annotations needed. Previous work has focused on pre-training with point cloud data exclusively; this approach often requires two or more registered views. In the present work, we combine image and point cloud modalities, by first learning self-supervised image features and then using these features to train a 3D model. By incorporating image data, which is often included in many 3D datasets, our pre-training method only requires a single scan of a scene. We demonstrate that our pre-training approach, despite using single scans, achieves comparable performance to other multi-scan, point cloud-only methods.