 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adversarial Attack and Defense for Dehazing Networks
Mar 30, 2023
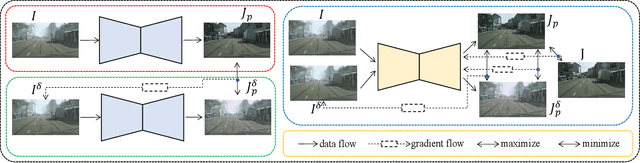

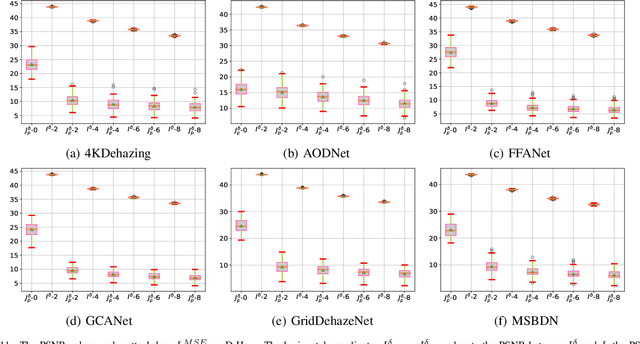
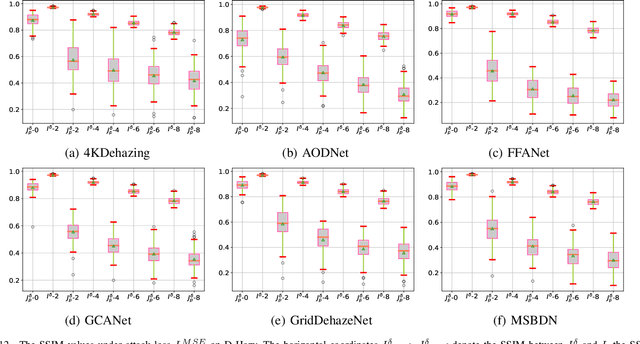
The research on single image dehazing task has been widely explored. However, as far as we know, no comprehensive study has been conducted on the robustness of the well-trained dehazing models. Therefore, there is no evidence that the dehazing networks can resist malicious attacks. In this paper, we focus on designing a group of attack methods based on first order gradient to verify the robustness of the existing dehazing algorithms. By analyzing the general goal of image dehazing task, five attack methods are proposed, which are prediction, noise, mask, ground-truth and input attack. The corresponding experiments are conducted on six datasets with different scales. Further, the defense strategy based on adversarial training is adopted for reducing the negative effects caused by malicious attacks. In summary, this paper defines a new challenging problem for image dehazing area, which can be called as adversarial attack on dehazing networks (AADN). Code is available at https://github.com/guijiejie/AADN.
NA-SODINN: a deep learning algorithm for exoplanet image detection based on residual noise regimes
Feb 06, 2023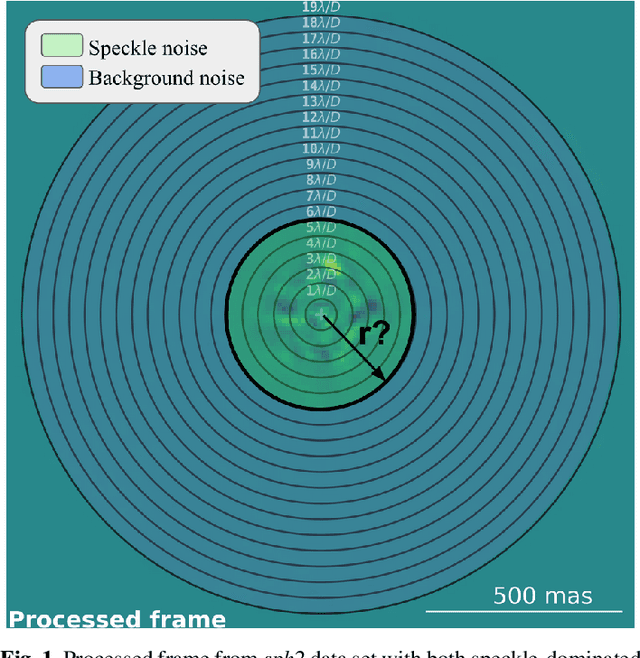
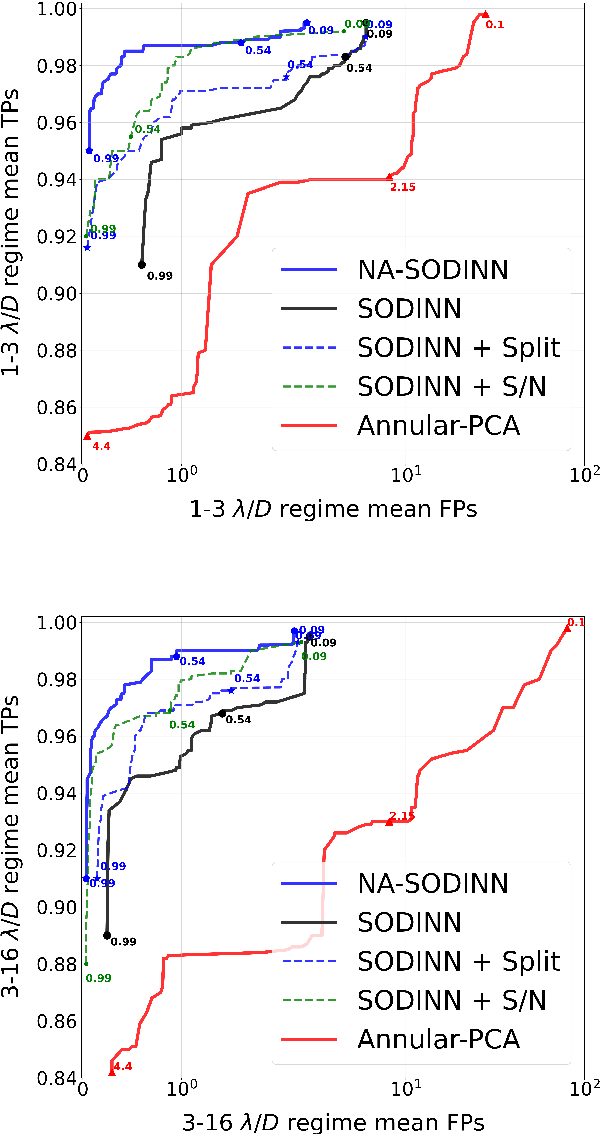
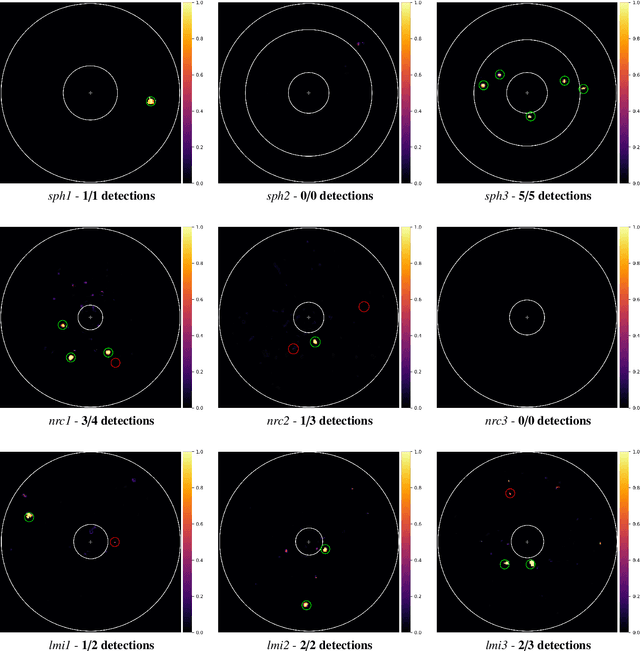
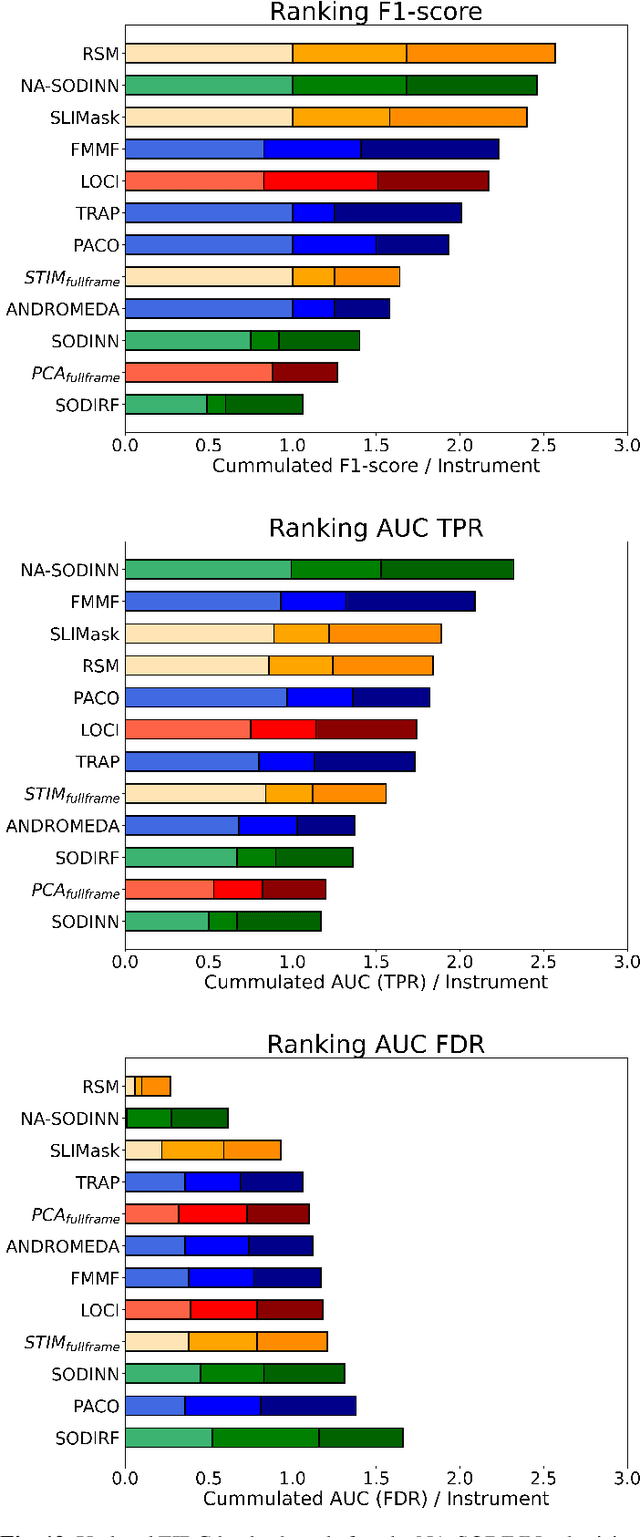
Supervised machine learning was recently introduced in high-contrast imaging (HCI) through the SODINN algorithm, a convolutional neural network designed for exoplanet detection in angular differential imaging (ADI) data sets. The benchmarking of HCI algorithms within the Exoplanet Imaging Data Challenge (EIDC) showed that (i) SODINN can produce a high number of false positives in the final detection maps, and (ii) algorithms processing images in a more local manner perform better. This work aims to improve the SODINN detection performance by introducing new local processing approaches and adapting its learning process accordingly. We propose NA-SODINN, a new deep learning architecture that better captures image noise correlations by training an independent SODINN model per noise regime over the processed frame. The identification of these noise regimes is based on a novel technique, named PCA-pmaps, which allows to estimate the distance from the star in the image from which background noise starts to dominate over residual speckle noise. NA-SODINN is also fed with local discriminators, such as S/N curves, which complement spatio-temporal feature maps when training the model.Our new approach is tested against its predecessor, as well as two SODINN-based hybrid models and a more standard annular-PCA approach, through local ROC analysis of ADI sequences from VLT/SPHERE and Keck/NIRC-2 instruments. Results show that NA-SODINN enhances SODINN in both the sensitivity and specificity, especially in the speckle-dominated noise regime. NA-SODINN is also benchmarked against the complete set of submitted detection algorithms in EIDC, in which we show that its final detection score matches or outperforms the most powerful detection algorithms, reaching a performance similar to that of the Regime Switching Model algorithm.
COOL-CHIC: Coordinate-based Low Complexity Hierarchical Image Codec
Dec 11, 2022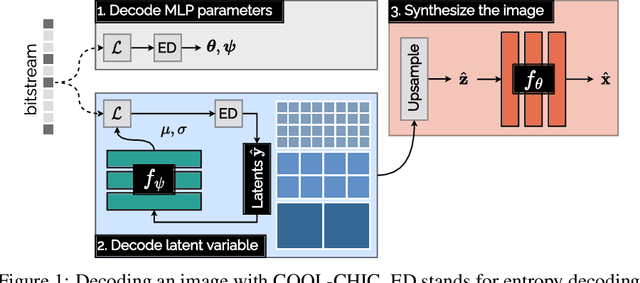
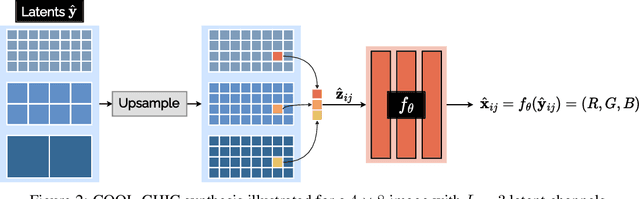
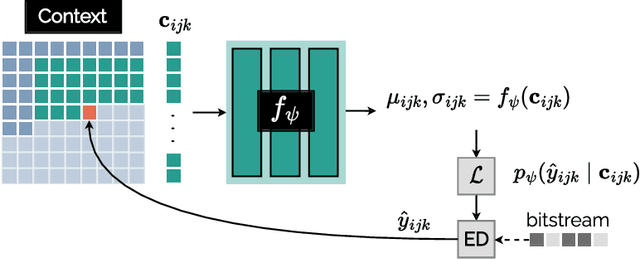
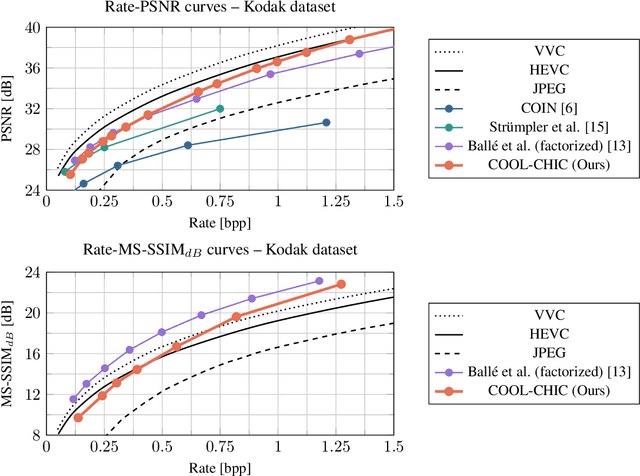
We introduce COOL-CHIC, a Coordinate-based Low Complexity Hierarchical Image Codec. It is a learned alternative to autoencoders with approximately 2000 parameters and 2500 multiplications per decoded pixel. Despite its low complexity, COOL-CHIC offers compression performance close to modern conventional MPEG codecs such as HEVC and VVC. This method is inspired by the Coordinate-based Neural Representation, where an image is represented as a learned function which maps pixel coordinates to RGB values. The parameters of the mapping function are then sent using entropy coding. At the receiver side, the compressed image is obtained by evaluating the mapping function for all pixel coordinates. COOL-CHIC implementation is made available upon request.
Retinal Image Segmentation with Small Datasets
Mar 09, 2023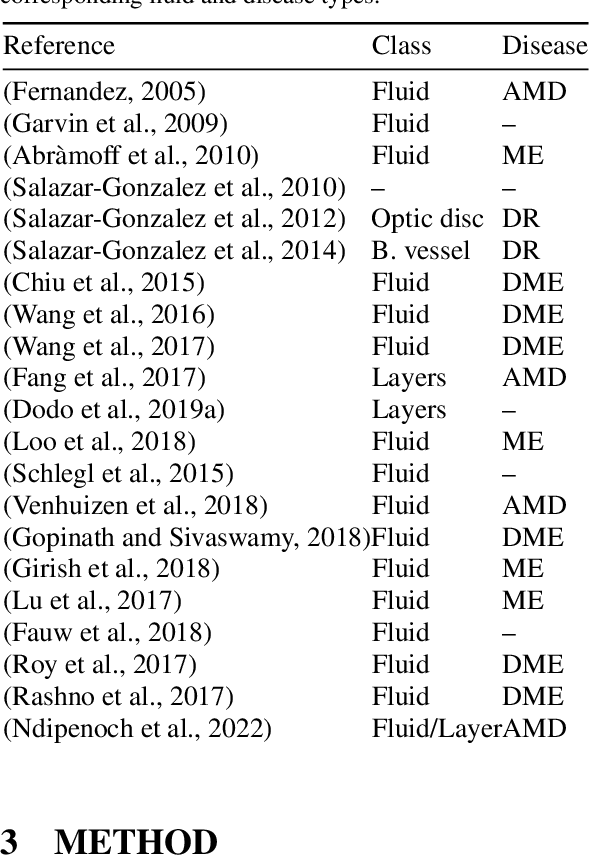
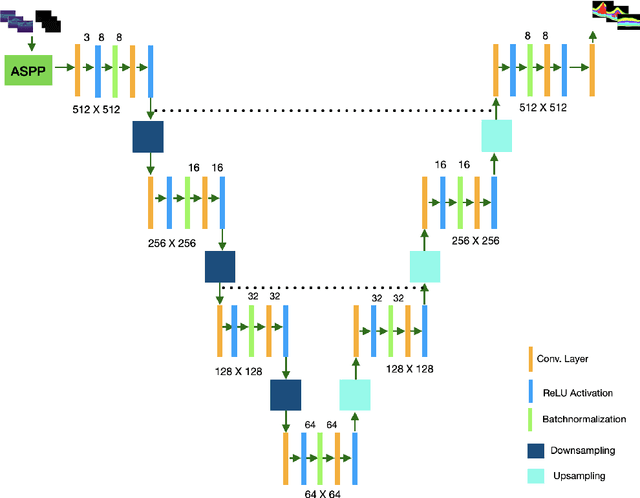
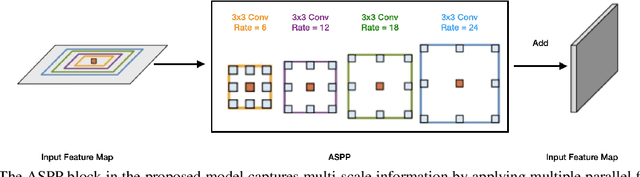
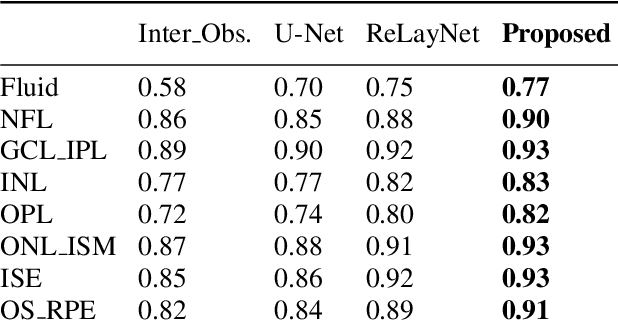
Many eye diseases like Diabetic Macular Edema (DME), Age-related Macular Degeneration (AMD), and Glaucoma manifest in the retina, can cause irreversible blindness or severely impair the central version. The Optical Coherence Tomography (OCT), a 3D scan of the retina with high qualitative information about the retinal morphology, can be used to diagnose and monitor changes in the retinal anatomy. Many Deep Learning (DL) methods have shared the success of developing an automated tool to monitor pathological changes in the retina. However, the success of these methods depend mainly on large datasets. To address the challenge from very small and limited datasets, we proposed a DL architecture termed CoNet (Coherent Network) for joint segmentation of layers and fluids in retinal OCT images on very small datasets (less than a hundred training samples). The proposed model was evaluated on the publicly available Duke DME dataset consisting of 110 B-Scans from 10 patients suffering from DME. Experimental results show that the proposed model outperformed both the human experts' annotation and the current state-of-the-art architectures by a clear margin with a mean Dice Score of 88% when trained on 55 images without any data augmentation.
Efficient 3-D Near-Field MIMO-SAR Imaging for Irregular Scanning Geometries
May 03, 2023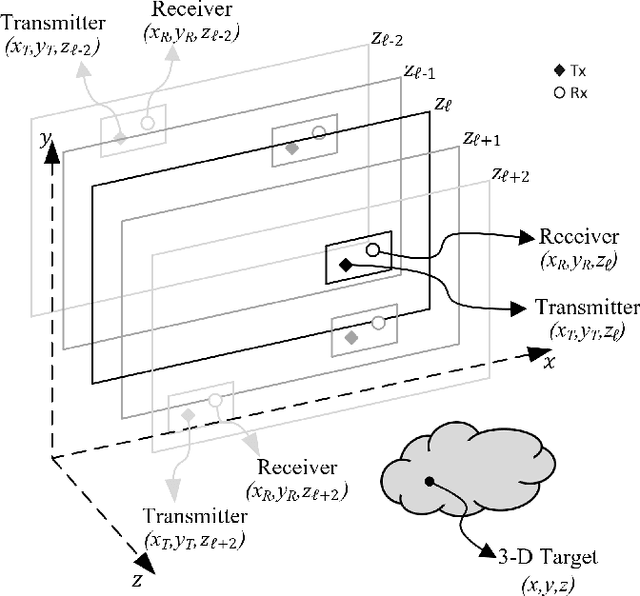
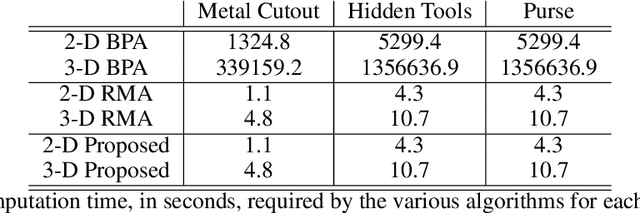
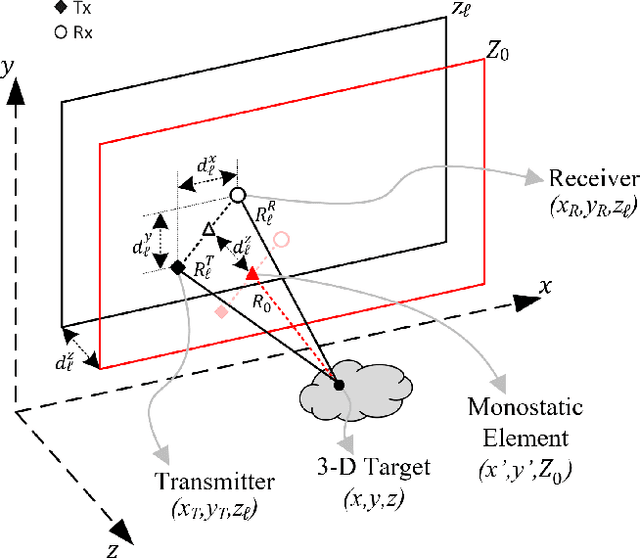
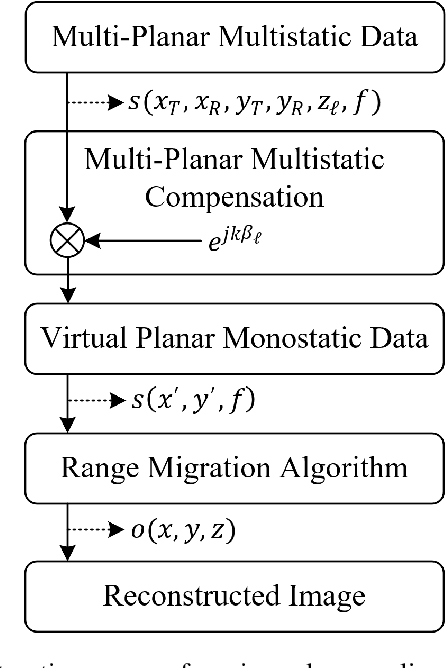
In this article, we introduce a novel algorithm for efficient near-field synthetic aperture radar (SAR) imaging for irregular scanning geometries. With the emergence of fifth-generation (5G) millimeter-wave (mmWave) devices, near-field SAR imaging is no longer confined to laboratory environments. Recent advances in positioning technology have attracted significant interest for a diverse set of new applications in mmWave imaging. However, many use cases, such as automotive-mounted SAR imaging, unmanned aerial vehicle (UAV) imaging, and freehand imaging with smartphones, are constrained to irregular scanning geometries. Whereas traditional near-field SAR imaging systems and quick personnel security (QPS) scanners employ highly precise motion controllers to create ideal synthetic arrays, emerging applications, mentioned previously, inherently cannot achieve such ideal positioning. In addition, many Internet of Things (IoT) and 5G applications impose strict size and computational complexity limitations that must be considered for edge mmWave imaging technology. In this study, we propose a novel algorithm to leverage the advantages of non-cooperative SAR scanning patterns, small form-factor multiple-input multiple-output (MIMO) radars, and efficient monostatic planar image reconstruction algorithms. We propose a framework to mathematically decompose arbitrary and irregular sampling geometries and a joint solution to mitigate multistatic array imaging artifacts. The proposed algorithm is validated through simulations and an empirical study of arbitrary scanning scenarios. Our algorithm achieves high-resolution and high-efficiency near-field MIMO-SAR imaging, and is an elegant solution to computationally constrained irregularly sampled imaging problems.
* Accepted to IEEE Access
Advances in Medical Image Analysis with Vision Transformers: A Comprehensive Review
Jan 10, 2023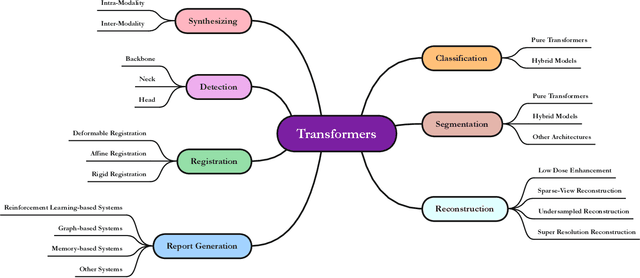
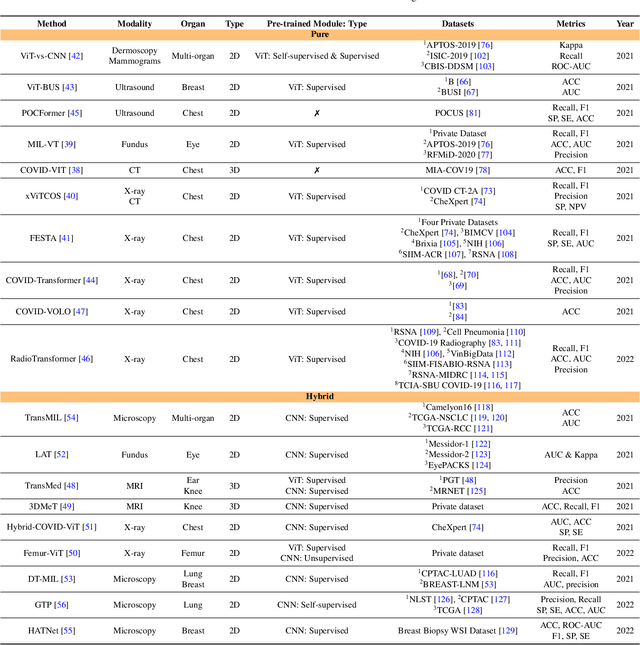
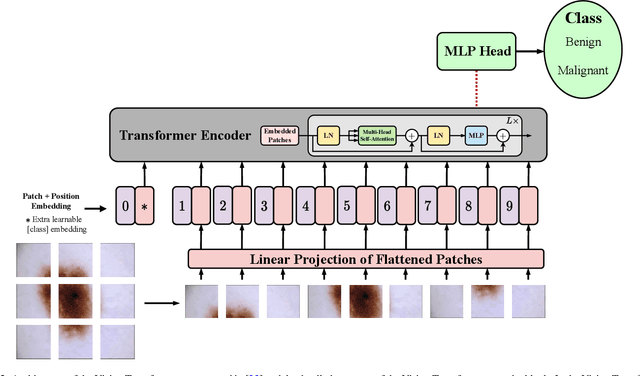
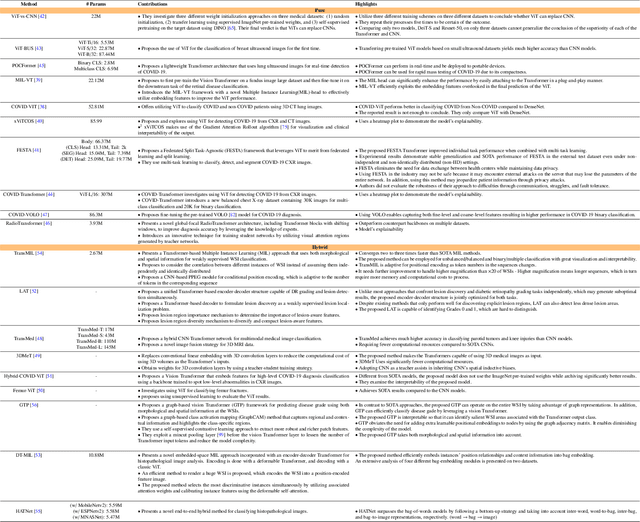
The remarkable performance of the Transformer architecture in natural language processing has recently also triggered broad interest in Computer Vision. Among other merits, Transformers are witnessed as capable of learning long-range dependencies and spatial correlations, which is a clear advantage over convolutional neural networks (CNNs), which have been the de facto standard in Computer Vision problems so far. Thus, Transformers have become an integral part of modern medical image analysis. In this review, we provide an encyclopedic review of the applications of Transformers in medical imaging. Specifically, we present a systematic and thorough review of relevant recent Transformer literature for different medical image analysis tasks, including classification, segmentation, detection, registration, synthesis, and clinical report generation. For each of these applications, we investigate the novelty, strengths and weaknesses of the different proposed strategies and develop taxonomies highlighting key properties and contributions. Further, if applicable, we outline current benchmarks on different datasets. Finally, we summarize key challenges and discuss different future research directions. In addition, we have provided cited papers with their corresponding implementations in https://github.com/mindflow-institue/Awesome-Transformer.
Visual Dependency Transformers: Dependency Tree Emerges from Reversed Attention
Apr 06, 2023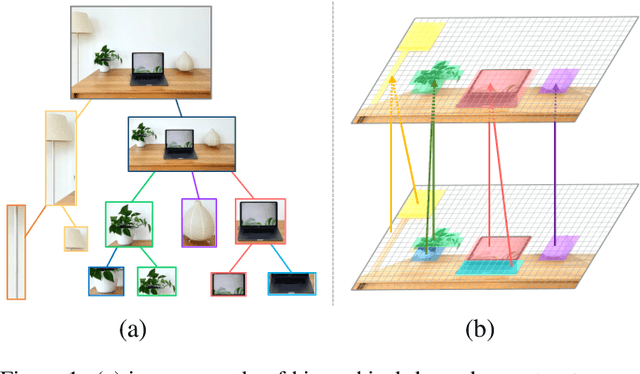
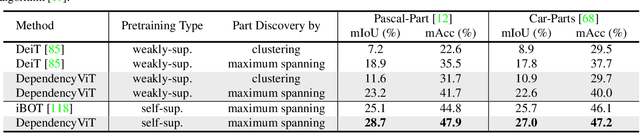
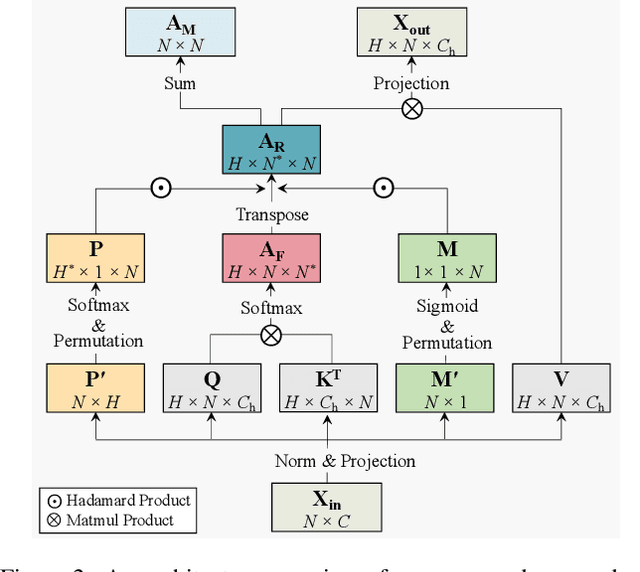
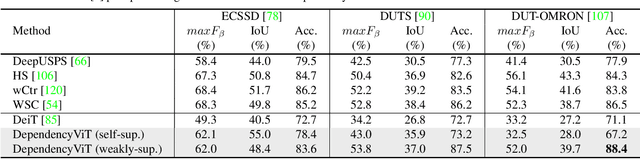
Humans possess a versatile mechanism for extracting structured representations of our visual world. When looking at an image, we can decompose the scene into entities and their parts as well as obtain the dependencies between them. To mimic such capability, we propose Visual Dependency Transformers (DependencyViT) that can induce visual dependencies without any labels. We achieve that with a novel neural operator called \emph{reversed attention} that can naturally capture long-range visual dependencies between image patches. Specifically, we formulate it as a dependency graph where a child token in reversed attention is trained to attend to its parent tokens and send information following a normalized probability distribution rather than gathering information in conventional self-attention. With such a design, hierarchies naturally emerge from reversed attention layers, and a dependency tree is progressively induced from leaf nodes to the root node unsupervisedly. DependencyViT offers several appealing benefits. (i) Entities and their parts in an image are represented by different subtrees, enabling part partitioning from dependencies; (ii) Dynamic visual pooling is made possible. The leaf nodes which rarely send messages can be pruned without hindering the model performance, based on which we propose the lightweight DependencyViT-Lite to reduce the computational and memory footprints; (iii) DependencyViT works well on both self- and weakly-supervised pretraining paradigms on ImageNet, and demonstrates its effectiveness on 8 datasets and 5 tasks, such as unsupervised part and saliency segmentation, recognition, and detection.
Certified Zeroth-order Black-Box Defense with Robust UNet Denoiser
Apr 13, 2023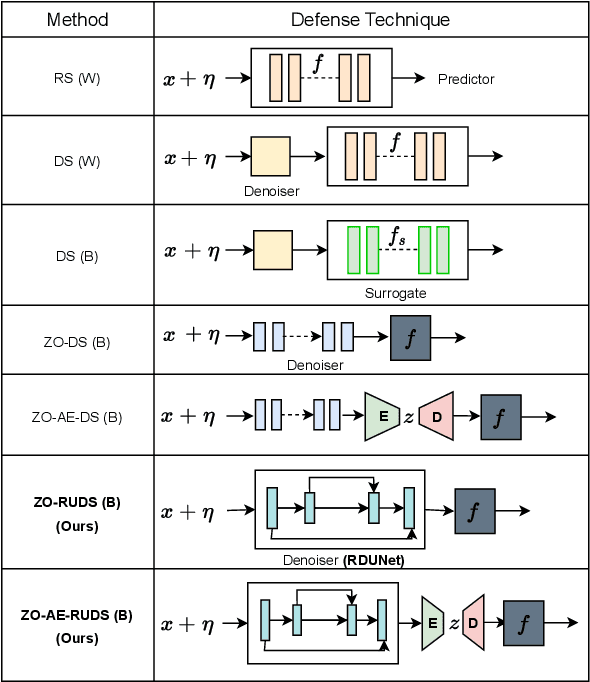
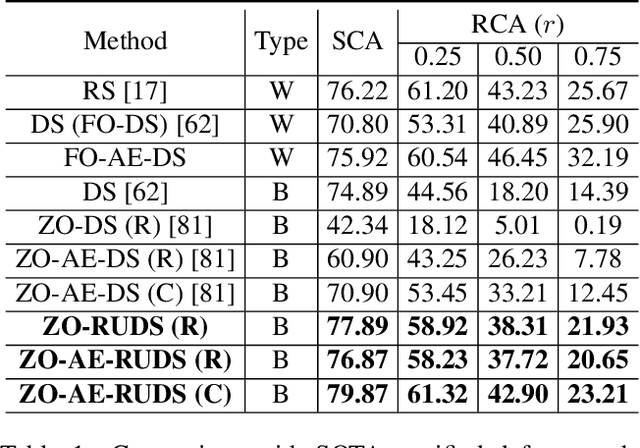
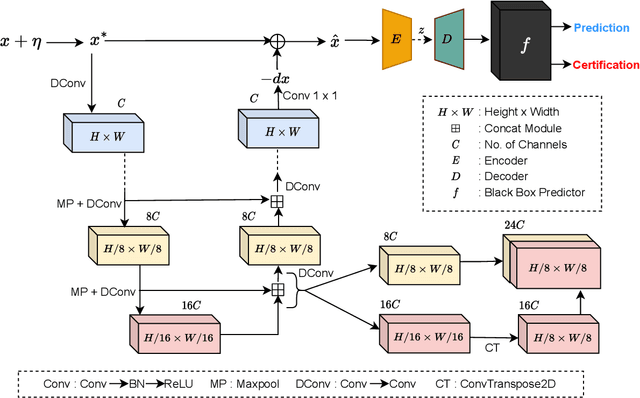
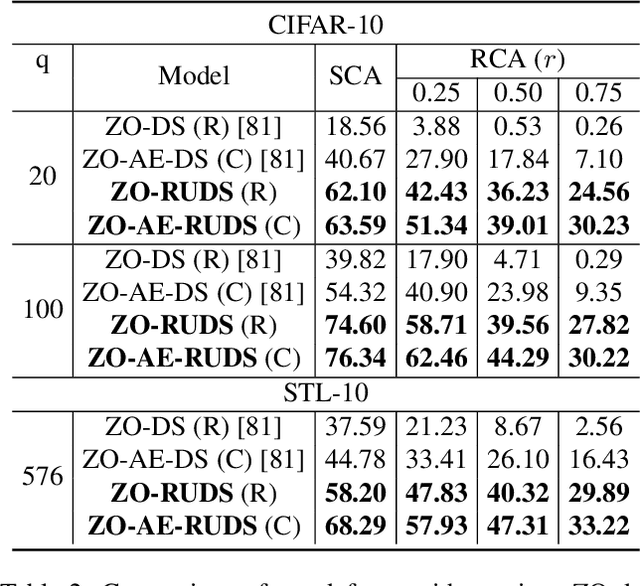
Certified defense methods against adversarial perturbations have been recently investigated in the black-box setting with a zeroth-order (ZO) perspective. However, these methods suffer from high model variance with low performance on high-dimensional datasets due to the ineffective design of the denoiser and are limited in their utilization of ZO techniques. To this end, we propose a certified ZO preprocessing technique for removing adversarial perturbations from the attacked image in the black-box setting using only model queries. We propose a robust UNet denoiser (RDUNet) that ensures the robustness of black-box models trained on high-dimensional datasets. We propose a novel black-box denoised smoothing (DS) defense mechanism, ZO-RUDS, by prepending our RDUNet to the black-box model, ensuring black-box defense. We further propose ZO-AE-RUDS in which RDUNet followed by autoencoder (AE) is prepended to the black-box model. We perform extensive experiments on four classification datasets, CIFAR-10, CIFAR-10, Tiny Imagenet, STL-10, and the MNIST dataset for image reconstruction tasks. Our proposed defense methods ZO-RUDS and ZO-AE-RUDS beat SOTA with a huge margin of $35\%$ and $9\%$, for low dimensional (CIFAR-10) and with a margin of $20.61\%$ and $23.51\%$ for high-dimensional (STL-10) datasets, respectively.
Instruct 3D-to-3D: Text Instruction Guided 3D-to-3D conversion
Mar 28, 2023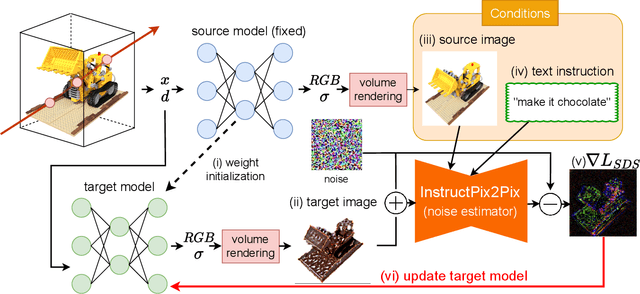
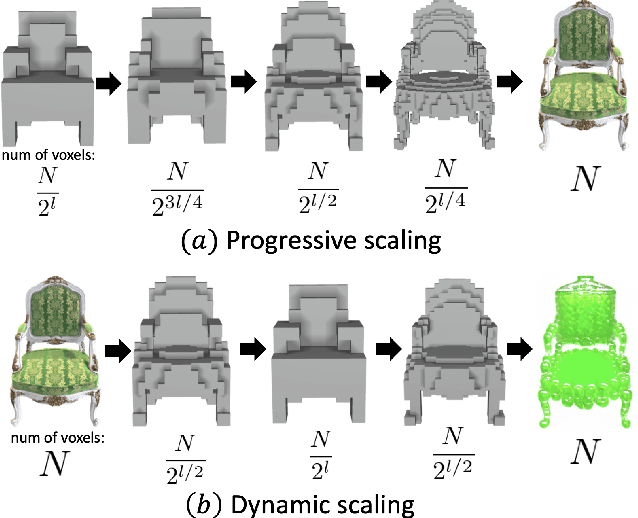

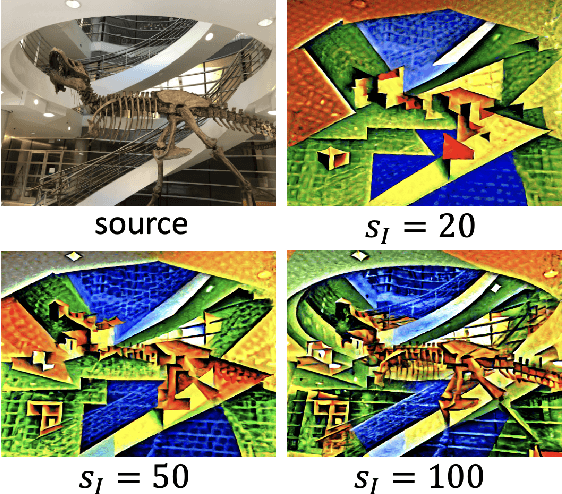
We propose a high-quality 3D-to-3D conversion method, Instruct 3D-to-3D. Our method is designed for a novel task, which is to convert a given 3D scene to another scene according to text instructions. Instruct 3D-to-3D applies pretrained Image-to-Image diffusion models for 3D-to-3D conversion. This enables the likelihood maximization of each viewpoint image and high-quality 3D generation. In addition, our proposed method explicitly inputs the source 3D scene as a condition, which enhances 3D consistency and controllability of how much of the source 3D scene structure is reflected. We also propose dynamic scaling, which allows the intensity of the geometry transformation to be adjusted. We performed quantitative and qualitative evaluations and showed that our proposed method achieves higher quality 3D-to-3D conversions than baseline methods.
Hi-LASSIE: High-Fidelity Articulated Shape and Skeleton Discovery from Sparse Image Ensemble
Dec 28, 2022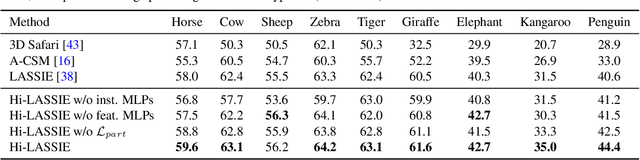

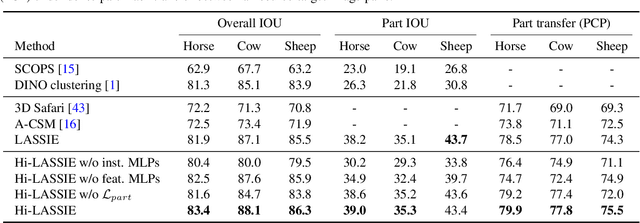

Automatically estimating 3D skeleton, shape, camera viewpoints, and part articulation from sparse in-the-wild image ensembles is a severely under-constrained and challenging problem. Most prior methods rely on large-scale image datasets, dense temporal correspondence, or human annotations like camera pose, 2D keypoints, and shape templates. We propose Hi-LASSIE, which performs 3D articulated reconstruction from only 20-30 online images in the wild without any user-defined shape or skeleton templates. We follow the recent work of LASSIE that tackles a similar problem setting and make two significant advances. First, instead of relying on a manually annotated 3D skeleton, we automatically estimate a class-specific skeleton from the selected reference image. Second, we improve the shape reconstructions with novel instance-specific optimization strategies that allow reconstructions to faithful fit on each instance while preserving the class-specific priors learned across all images. Experiments on in-the-wild image ensembles show that Hi-LASSIE obtains higher fidelity state-of-the-art 3D reconstructions despite requiring minimum user input.