 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
VisFusion: Visibility-aware Online 3D Scene Reconstruction from Videos
Apr 21, 2023
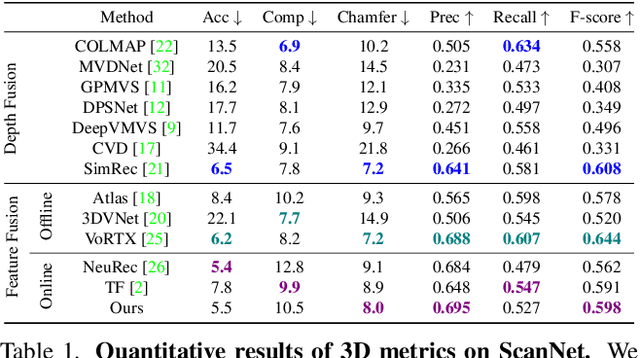
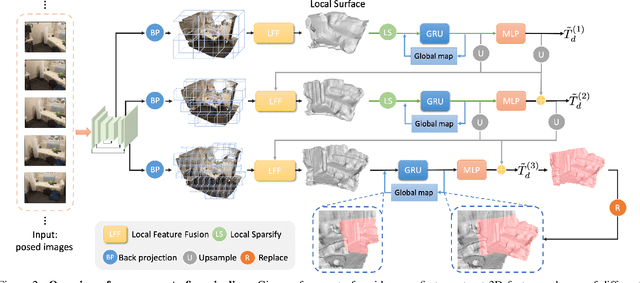
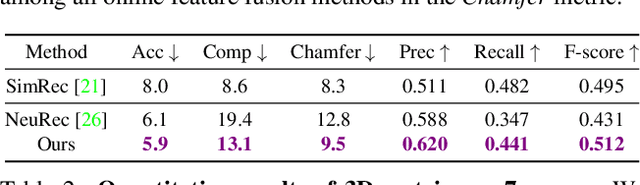
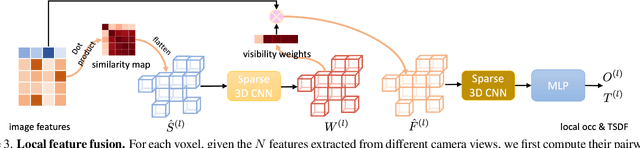
We propose VisFusion, a visibility-aware online 3D scene reconstruction approach from posed monocular videos. In particular, we aim to reconstruct the scene from volumetric features. Unlike previous reconstruction methods which aggregate features for each voxel from input views without considering its visibility, we aim to improve the feature fusion by explicitly inferring its visibility from a similarity matrix, computed from its projected features in each image pair. Following previous works, our model is a coarse-to-fine pipeline including a volume sparsification process. Different from their works which sparsify voxels globally with a fixed occupancy threshold, we perform the sparsification on a local feature volume along each visual ray to preserve at least one voxel per ray for more fine details. The sparse local volume is then fused with a global one for online reconstruction. We further propose to predict TSDF in a coarse-to-fine manner by learning its residuals across scales leading to better TSDF predictions. Experimental results on benchmarks show that our method can achieve superior performance with more scene details. Code is available at: https://github.com/huiyu-gao/VisFusion
Med-Tuning: Exploring Parameter-Efficient Transfer Learning for Medical Volumetric Segmentation
Apr 21, 2023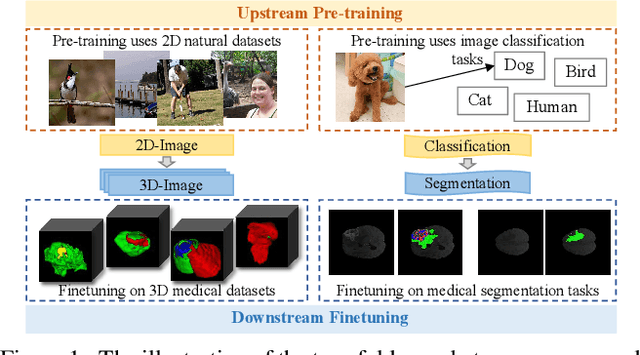
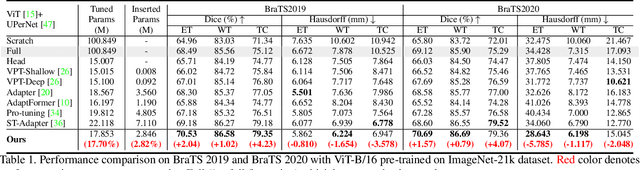
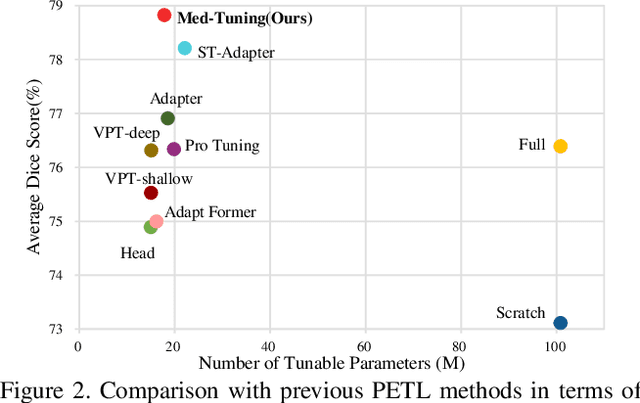

Deep learning based medical volumetric segmentation methods either train the model from scratch or follow the standard "pre-training then finetuning" paradigm. Although finetuning a well pre-trained model on downstream tasks can harness its representation power, the standard full finetuning is costly in terms of computation and memory footprint. In this paper, we present the first study on parameter-efficient transfer learning for medical volumetric segmentation and propose a novel framework named Med-Tuning based on intra-stage feature enhancement and inter-stage feature interaction. Given a large-scale pre-trained model on 2D natural images, our method can exploit both the multi-scale spatial feature representations and temporal correlations along image slices, which are crucial for accurate medical volumetric segmentation. Extensive experiments on three benchmark datasets (including CT and MRI) show that our method can achieve better results than previous state-of-the-art parameter-efficient transfer learning methods and full finetuning for the segmentation task, with much less tuned parameter costs. Compared to full finetuning, our method reduces the finetuned model parameters by up to 4x, with even better segmentation performance.
Plug-and-Play split Gibbs sampler: embedding deep generative priors in Bayesian inference
Apr 21, 2023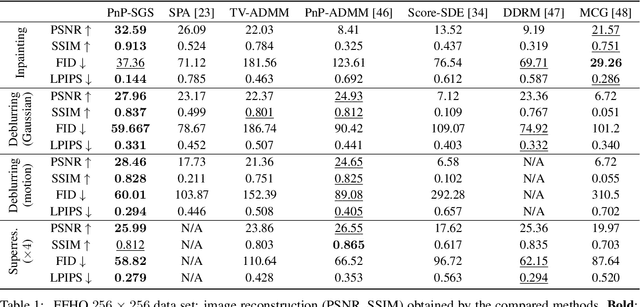

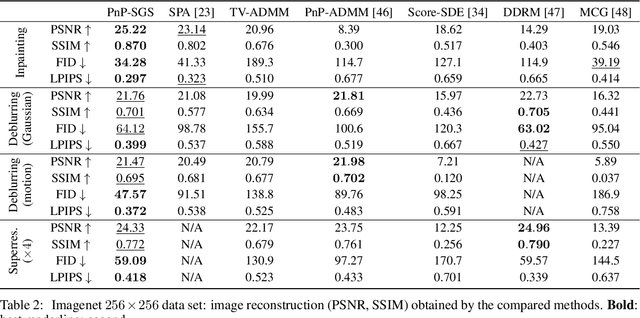

This paper introduces a stochastic plug-and-play (PnP) sampling algorithm that leverages variable splitting to efficiently sample from a posterior distribution. The algorithm based on split Gibbs sampling (SGS) draws inspiration from the alternating direction method of multipliers (ADMM). It divides the challenging task of posterior sampling into two simpler sampling problems. The first problem depends on the likelihood function, while the second is interpreted as a Bayesian denoising problem that can be readily carried out by a deep generative model. Specifically, for an illustrative purpose, the proposed method is implemented in this paper using state-of-the-art diffusion-based generative models. Akin to its deterministic PnP-based counterparts, the proposed method exhibits the great advantage of not requiring an explicit choice of the prior distribution, which is rather encoded into a pre-trained generative model. However, unlike optimization methods (e.g., PnP-ADMM) which generally provide only point estimates, the proposed approach allows conventional Bayesian estimators to be accompanied by confidence intervals at a reasonable additional computational cost. Experiments on commonly studied image processing problems illustrate the efficiency of the proposed sampling strategy. Its performance is compared to recent state-of-the-art optimization and sampling methods.
eWaSR -- an embedded-compute-ready maritime obstacle detection network
Apr 21, 2023

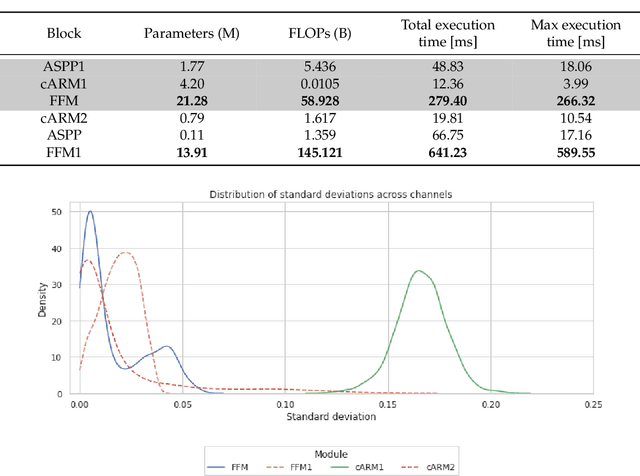
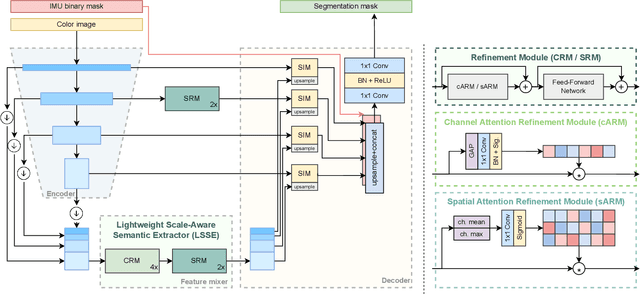
Maritime obstacle detection is critical for safe navigation of autonomous surface vehicles (ASVs). While the accuracy of image-based detection methods has advanced substantially, their computational and memory requirements prohibit deployment on embedded devices. In this paper we analyze the currently best-performing maritime obstacle detection network WaSR. Based on the analysis we then propose replacements for the most computationally intensive stages and propose its embedded-compute-ready variant eWaSR. In particular, the new design follows the most recent advancements of transformer-based lightweight networks. eWaSR achieves comparable detection results to state-of-the-art WaSR with only 0.52% F1 score performance drop and outperforms other state-of-the-art embedded-ready architectures by over 9.74% in F1 score. On a standard GPU, eWaSR runs 10x faster than the original WaSR (115 FPS vs 11 FPS). Tests on a real embedded device OAK-D show that, while WaSR cannot run due to memory restrictions, eWaSR runs comfortably at 5.5 FPS. This makes eWaSR the first practical embedded-compute-ready maritime obstacle detection network. The source code and trained eWaSR models are publicly available here: https://github.com/tersekmatija/eWaSR.
Dream3D: Zero-Shot Text-to-3D Synthesis Using 3D Shape Prior and Text-to-Image Diffusion Models
Dec 28, 2022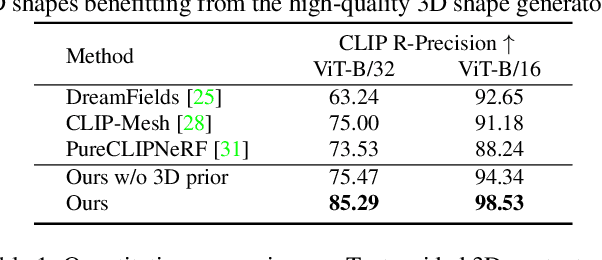
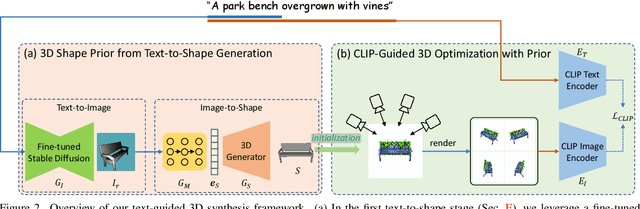

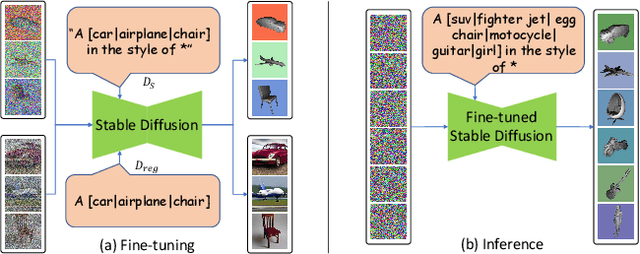
Recent CLIP-guided 3D optimization methods, e.g., DreamFields and PureCLIPNeRF achieve great success in zero-shot text-guided 3D synthesis. However, due to the scratch training and random initialization without any prior knowledge, these methods usually fail to generate accurate and faithful 3D structures that conform to the corresponding text. In this paper, we make the first attempt to introduce the explicit 3D shape prior to CLIP-guided 3D optimization methods. Specifically, we first generate a high-quality 3D shape from input texts in the text-to-shape stage as the 3D shape prior. We then utilize it as the initialization of a neural radiance field and then optimize it with the full prompt. For the text-to-shape generation, we present a simple yet effective approach that directly bridges the text and image modalities with a powerful text-to-image diffusion model. To narrow the style domain gap between images synthesized by the text-to-image model and shape renderings used to train the image-to-shape generator, we further propose to jointly optimize a learnable text prompt and fine-tune the text-to-image diffusion model for rendering-style image generation. Our method, namely, Dream3D, is capable of generating imaginative 3D content with better visual quality and shape accuracy than state-of-the-art methods.
Deep Learning based Multi-Label Image Classification of Protest Activities
Jan 10, 2023


With the rise of internet technology amidst increasing rates of urbanization, sharing information has never been easier thanks to globally-adopted platforms for digital communication. The resulting output of massive amounts of user-generated data can be used to enhance our understanding of significant societal issues particularly for urbanizing areas. In order to better analyze protest behavior, we enhanced the GSR dataset and manually labeled all the images. We used deep learning techniques to analyze social media data to detect social unrest through image classification, which performed good in predict multi-attributes, then also used map visualization to display protest behaviors across the country.
Temperature Detection from Images Using Smartphones
Apr 07, 2023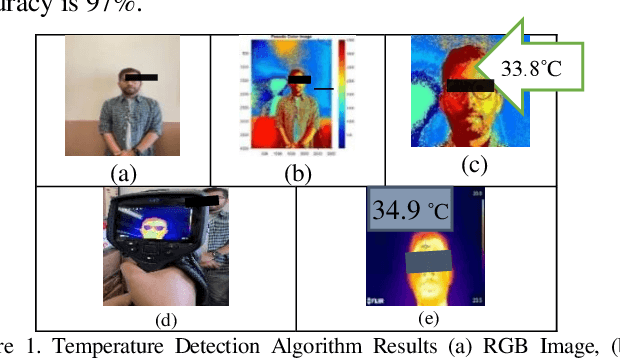
Since late 2019, the global spread of COVID-19 has affected people's daily life. Temperature is an early and common symptom of Covid. Therefore, a convenient and remote temperature detection method is needed. In this paper, a non-contact method for detecting body temperature is proposed. Our developed algorithm based on blackbody radiation calculates the body temperature of a user-selected area from an obtained image. The findings were confirmed using a FLIR Thermal Camera with an accuracy of 97%.
InstructPix2Pix: Learning to Follow Image Editing Instructions
Nov 17, 2022



We propose a method for editing images from human instructions: given an input image and a written instruction that tells the model what to do, our model follows these instructions to edit the image. To obtain training data for this problem, we combine the knowledge of two large pretrained models -- a language model (GPT-3) and a text-to-image model (Stable Diffusion) -- to generate a large dataset of image editing examples. Our conditional diffusion model, InstructPix2Pix, is trained on our generated data, and generalizes to real images and user-written instructions at inference time. Since it performs edits in the forward pass and does not require per example fine-tuning or inversion, our model edits images quickly, in a matter of seconds. We show compelling editing results for a diverse collection of input images and written instructions.
On the Adversarial Inversion of Deep Biometric Representations
Apr 12, 2023
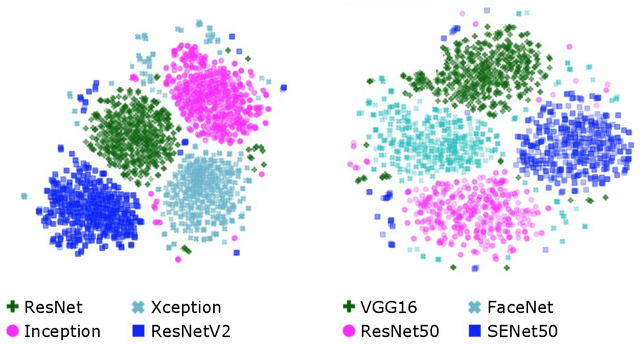
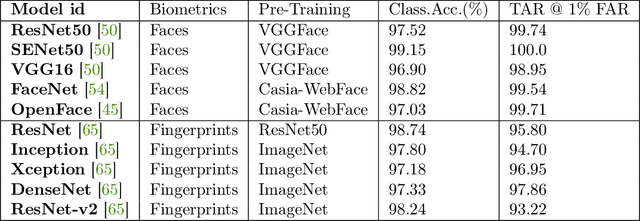

Biometric authentication service providers often claim that it is not possible to reverse-engineer a user's raw biometric sample, such as a fingerprint or a face image, from its mathematical (feature-space) representation. In this paper, we investigate this claim on the specific example of deep neural network (DNN) embeddings. Inversion of DNN embeddings has been investigated for explaining deep image representations or synthesizing normalized images. Existing studies leverage full access to all layers of the original model, as well as all possible information on the original dataset. For the biometric authentication use case, we need to investigate this under adversarial settings where an attacker has access to a feature-space representation but no direct access to the exact original dataset nor the original learned model. Instead, we assume varying degree of attacker's background knowledge about the distribution of the dataset as well as the original learned model (architecture and training process). In these cases, we show that the attacker can exploit off-the-shelf DNN models and public datasets, to mimic the behaviour of the original learned model to varying degrees of success, based only on the obtained representation and attacker's prior knowledge. We propose a two-pronged attack that first infers the original DNN by exploiting the model footprint on the embedding, and then reconstructs the raw data by using the inferred model. We show the practicality of the attack on popular DNNs trained for two prominent biometric modalities, face and fingerprint recognition. The attack can effectively infer the original recognition model (mean accuracy 83\% for faces, 86\% for fingerprints), and can craft effective biometric reconstructions that are successfully authenticated with 1-vs-1 authentication accuracy of up to 92\% for some models.
LMFLOSS: A Hybrid Loss For Imbalanced Medical Image Classification
Dec 24, 2022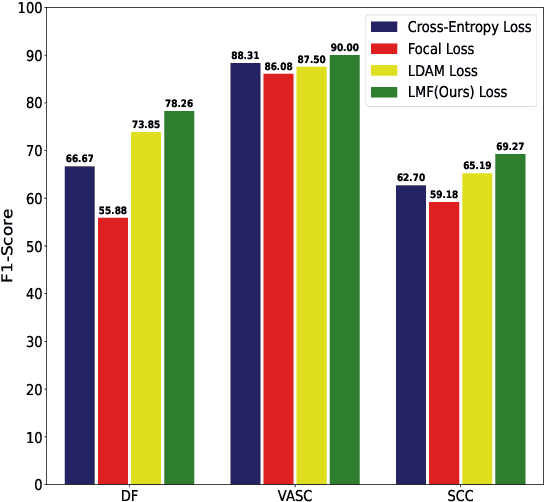


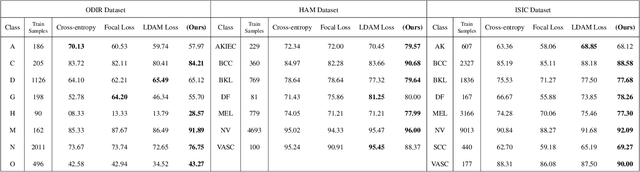
Automatic medical image classification is a very important field where the use of AI has the potential to have a real social impact. However, there are still many challenges that act as obstacles to making practically effective solutions. One of those is the fact that most of the medical imaging datasets have a class imbalance problem. This leads to the fact that existing AI techniques, particularly neural network-based deep-learning methodologies, often perform poorly in such scenarios. Thus this makes this area an interesting and active research focus for researchers. In this study, we propose a novel loss function to train neural network models to mitigate this critical issue in this important field. Through rigorous experiments on three independently collected datasets of three different medical imaging domains, we empirically show that our proposed loss function consistently performs well with an improvement between 2%-10% macro f1 when compared to the baseline models. We hope that our work will precipitate new research toward a more generalized approach to medical image classification.