 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast Neural Scene Flow
Apr 20, 2023
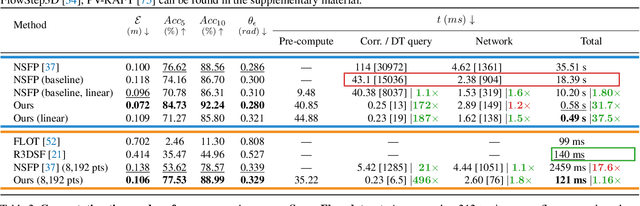

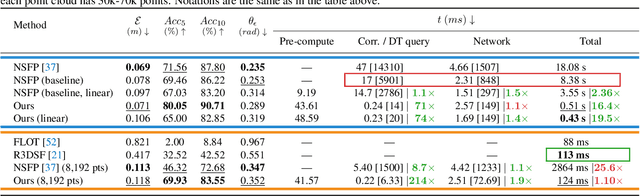
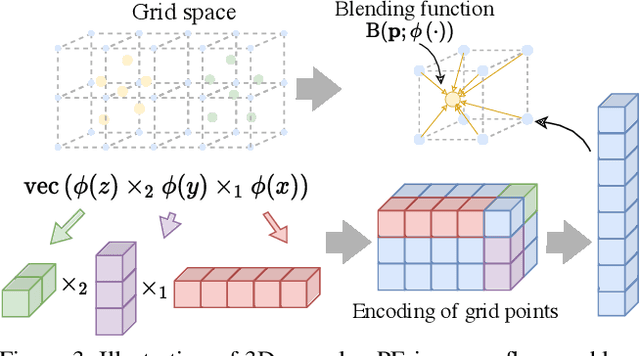
Neural Scene Flow Prior (NSFP) is of significant interest to the vision community due to its inherent robustness to out-of-distribution (OOD) effects and its ability to deal with dense lidar points. The approach utilizes a coordinate neural network to estimate scene flow at runtime, without any training. However, it is up to 100 times slower than current state-of-the-art learning methods. In other applications such as image, video, and radiance function reconstruction innovations in speeding up the runtime performance of coordinate networks have centered upon architectural changes. In this paper, we demonstrate that scene flow is different -- with the dominant computational bottleneck stemming from the loss function itself (i.e., Chamfer distance). Further, we rediscover the distance transform (DT) as an efficient, correspondence-free loss function that dramatically speeds up the runtime optimization. Our fast neural scene flow (FNSF) approach reports for the first time real-time performance comparable to learning methods, without any training or OOD bias on two of the largest open autonomous driving (AV) lidar datasets Waymo Open and Argoverse.
Learning CLIP Guided Visual-Text Fusion Transformer for Video-based Pedestrian Attribute Recognition
Apr 20, 2023

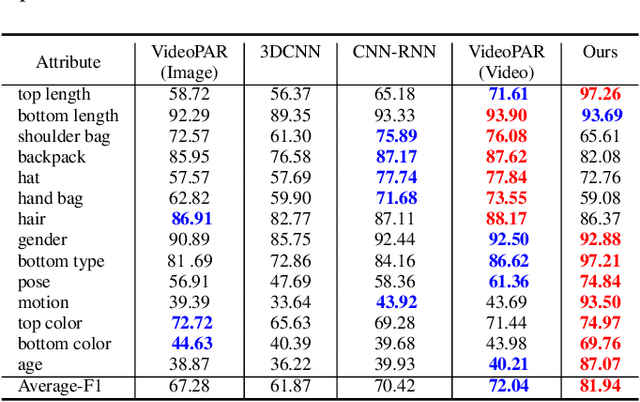
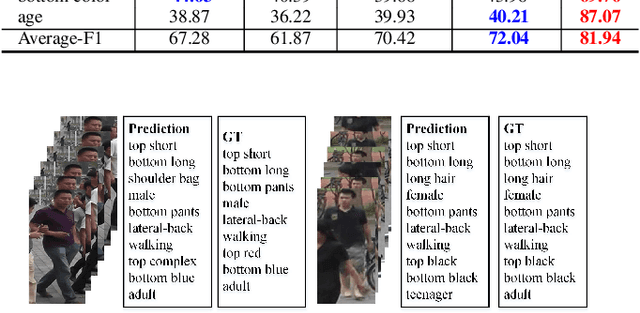
Existing pedestrian attribute recognition (PAR) algorithms are mainly developed based on a static image. However, the performance is not reliable for images with challenging factors, such as heavy occlusion, motion blur, etc. In this work, we propose to understand human attributes using video frames that can make full use of temporal information. Specifically, we formulate the video-based PAR as a vision-language fusion problem and adopt pre-trained big models CLIP to extract the feature embeddings of given video frames. To better utilize the semantic information, we take the attribute list as another input and transform the attribute words/phrase into the corresponding sentence via split, expand, and prompt. Then, the text encoder of CLIP is utilized for language embedding. The averaged visual tokens and text tokens are concatenated and fed into a fusion Transformer for multi-modal interactive learning. The enhanced tokens will be fed into a classification head for pedestrian attribute prediction. Extensive experiments on a large-scale video-based PAR dataset fully validated the effectiveness of our proposed framework.
CornerFormer: Boosting Corner Representation for Fine-Grained Structured Reconstruction
Apr 20, 2023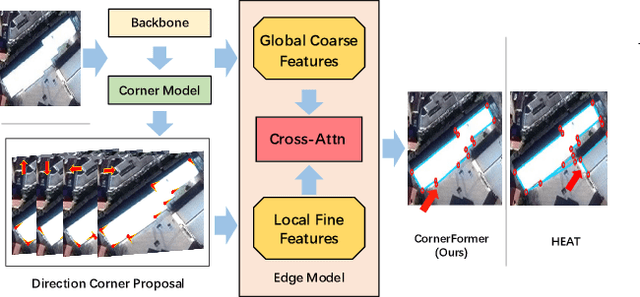
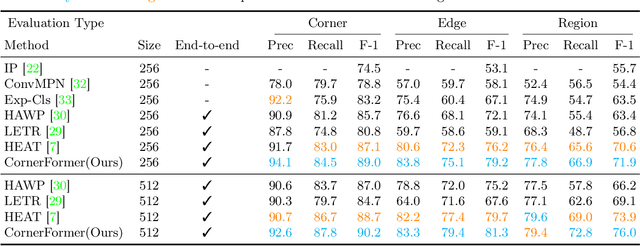
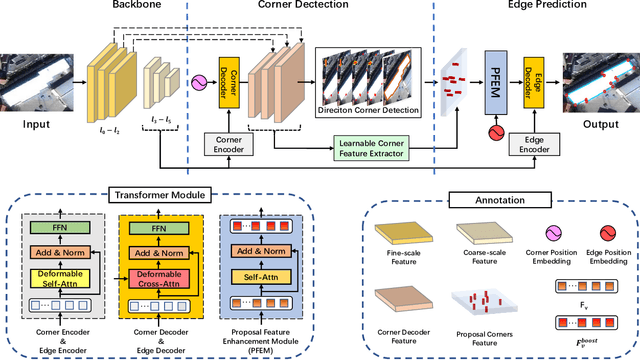
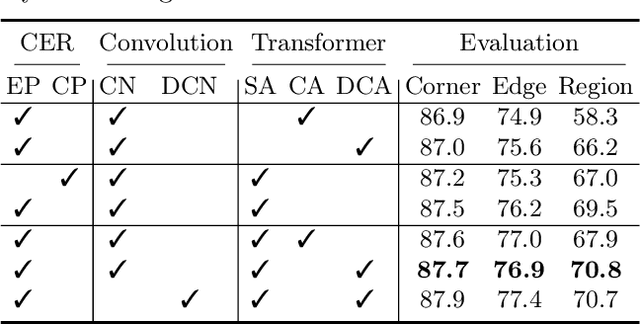
Structured reconstruction is a non-trivial dense prediction problem, which extracts structural information (\eg, building corners and edges) from a raster image, then reconstructs it to a 2D planar graph accordingly. Compared with common segmentation or detection problems, it significantly relays on the capability that leveraging holistic geometric information for structural reasoning. Current transformer-based approaches tackle this challenging problem in a two-stage manner, which detect corners in the first model and classify the proposed edges (corner-pairs) in the second model. However, they separate two-stage into different models and only share the backbone encoder. Unlike the existing modeling strategies, we present an enhanced corner representation method: 1) It fuses knowledge between the corner detection and edge prediction by sharing feature in different granularity; 2) Corner candidates are proposed in four heatmap channels w.r.t its direction. Both qualitative and quantitative evaluations demonstrate that our proposed method can better reconstruct fine-grained structures, such as adjacent corners and tiny edges. Consequently, it outperforms the state-of-the-art model by +1.9\%@F-1 on Corner and +3.0\%@F-1 on Edge.
InstructPix2Pix: Learning to Follow Image Editing Instructions
Nov 17, 2022



We propose a method for editing images from human instructions: given an input image and a written instruction that tells the model what to do, our model follows these instructions to edit the image. To obtain training data for this problem, we combine the knowledge of two large pretrained models -- a language model (GPT-3) and a text-to-image model (Stable Diffusion) -- to generate a large dataset of image editing examples. Our conditional diffusion model, InstructPix2Pix, is trained on our generated data, and generalizes to real images and user-written instructions at inference time. Since it performs edits in the forward pass and does not require per example fine-tuning or inversion, our model edits images quickly, in a matter of seconds. We show compelling editing results for a diverse collection of input images and written instructions.
Dream3D: Zero-Shot Text-to-3D Synthesis Using 3D Shape Prior and Text-to-Image Diffusion Models
Dec 28, 2022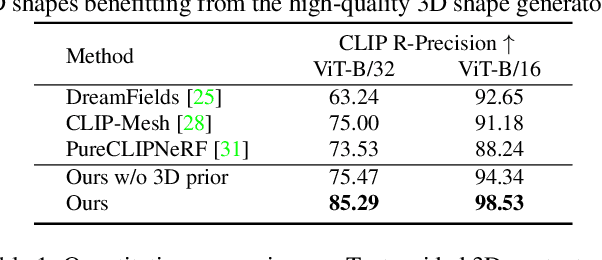
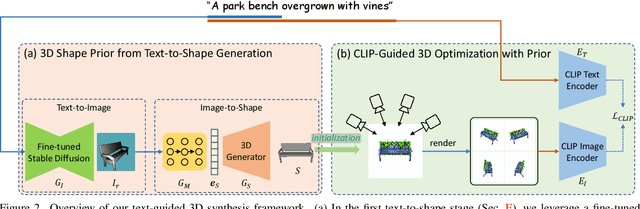

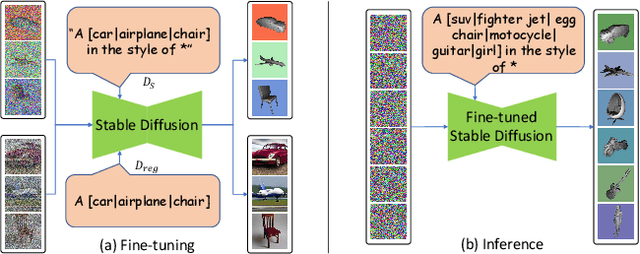
Recent CLIP-guided 3D optimization methods, e.g., DreamFields and PureCLIPNeRF achieve great success in zero-shot text-guided 3D synthesis. However, due to the scratch training and random initialization without any prior knowledge, these methods usually fail to generate accurate and faithful 3D structures that conform to the corresponding text. In this paper, we make the first attempt to introduce the explicit 3D shape prior to CLIP-guided 3D optimization methods. Specifically, we first generate a high-quality 3D shape from input texts in the text-to-shape stage as the 3D shape prior. We then utilize it as the initialization of a neural radiance field and then optimize it with the full prompt. For the text-to-shape generation, we present a simple yet effective approach that directly bridges the text and image modalities with a powerful text-to-image diffusion model. To narrow the style domain gap between images synthesized by the text-to-image model and shape renderings used to train the image-to-shape generator, we further propose to jointly optimize a learnable text prompt and fine-tune the text-to-image diffusion model for rendering-style image generation. Our method, namely, Dream3D, is capable of generating imaginative 3D content with better visual quality and shape accuracy than state-of-the-art methods.
Deep Learning based Multi-Label Image Classification of Protest Activities
Jan 10, 2023


With the rise of internet technology amidst increasing rates of urbanization, sharing information has never been easier thanks to globally-adopted platforms for digital communication. The resulting output of massive amounts of user-generated data can be used to enhance our understanding of significant societal issues particularly for urbanizing areas. In order to better analyze protest behavior, we enhanced the GSR dataset and manually labeled all the images. We used deep learning techniques to analyze social media data to detect social unrest through image classification, which performed good in predict multi-attributes, then also used map visualization to display protest behaviors across the country.
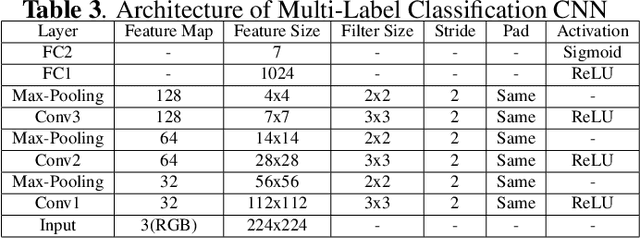
LMFLOSS: A Hybrid Loss For Imbalanced Medical Image Classification
Dec 24, 2022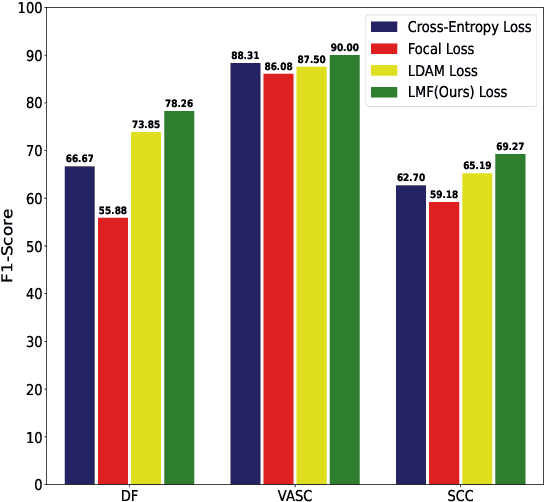


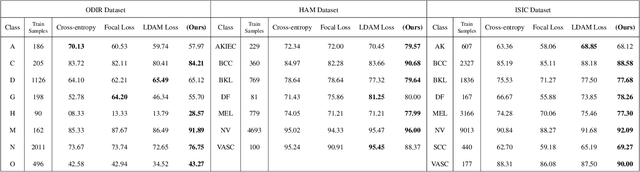
Automatic medical image classification is a very important field where the use of AI has the potential to have a real social impact. However, there are still many challenges that act as obstacles to making practically effective solutions. One of those is the fact that most of the medical imaging datasets have a class imbalance problem. This leads to the fact that existing AI techniques, particularly neural network-based deep-learning methodologies, often perform poorly in such scenarios. Thus this makes this area an interesting and active research focus for researchers. In this study, we propose a novel loss function to train neural network models to mitigate this critical issue in this important field. Through rigorous experiments on three independently collected datasets of three different medical imaging domains, we empirically show that our proposed loss function consistently performs well with an improvement between 2%-10% macro f1 when compared to the baseline models. We hope that our work will precipitate new research toward a more generalized approach to medical image classification.
Looking Through the Glass: Neural Surface Reconstruction Against High Specular Reflections
Apr 18, 2023
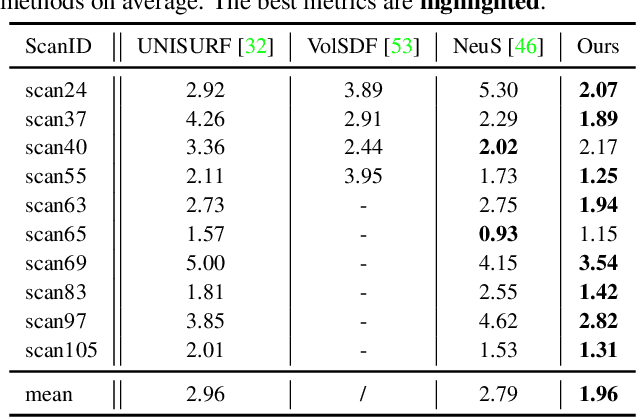
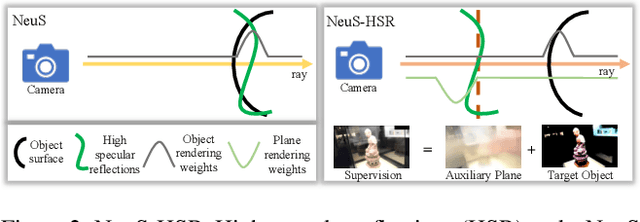

Neural implicit methods have achieved high-quality 3D object surfaces under slight specular highlights. However, high specular reflections (HSR) often appear in front of target objects when we capture them through glasses. The complex ambiguity in these scenes violates the multi-view consistency, then makes it challenging for recent methods to reconstruct target objects correctly. To remedy this issue, we present a novel surface reconstruction framework, NeuS-HSR, based on implicit neural rendering. In NeuS-HSR, the object surface is parameterized as an implicit signed distance function (SDF). To reduce the interference of HSR, we propose decomposing the rendered image into two appearances: the target object and the auxiliary plane. We design a novel auxiliary plane module by combining physical assumptions and neural networks to generate the auxiliary plane appearance. Extensive experiments on synthetic and real-world datasets demonstrate that NeuS-HSR outperforms state-of-the-art approaches for accurate and robust target surface reconstruction against HSR. Code is available at https://github.com/JiaxiongQ/NeuS-HSR.
Visual-LiDAR Odometry and Mapping with Monocular Scale Correction and Motion Compensation
Apr 18, 2023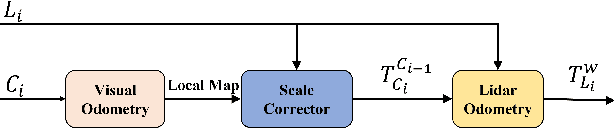
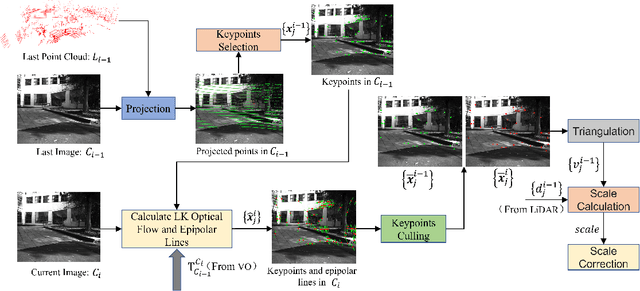
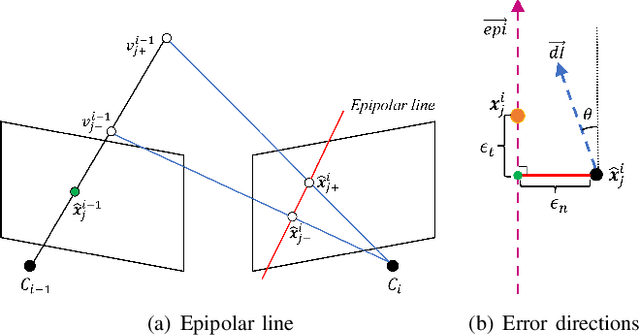
This paper presents a novel visual-LiDAR odometry and mapping method with low-drift characteristics. The proposed method is based on two popular approaches, ORB-SLAM and A-LOAM, with monocular scale correction and visual-assisted LiDAR motion compensation modifications. The scale corrector calculates the proportion between the depth of image keypoints recovered by triangulation and that provided by LiDAR, using an outlier rejection process for accuracy improvement. Concerning LiDAR motion compensation, the visual odometry approach gives the initial guesses of LiDAR motions for better performance. This methodology is not only applicable to high-resolution LiDAR but can also adapt to low-resolution LiDAR. To evaluate the proposed SLAM system's robustness and accuracy, we conducted experiments on the KITTI Odometry and S3E datasets. Experimental results illustrate that our method significantly outperforms standalone ORB-SLAM2 and A-LOAM. Furthermore, regarding the accuracy of visual odometry with scale correction, our method performs similarly to the stereo-mode ORB-SLAM2.
A Hyper-network Based End-to-end Visual Servoing with Arbitrary Desired Poses
Apr 18, 2023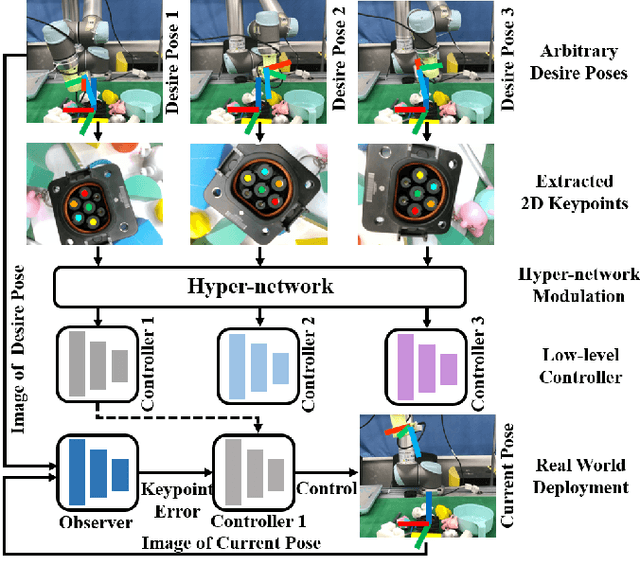
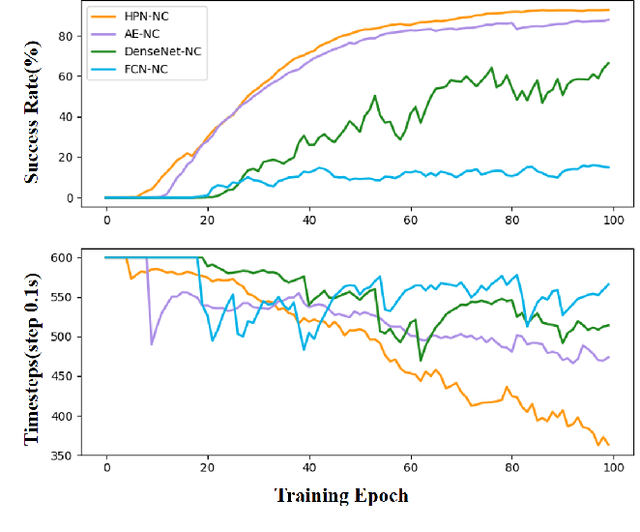
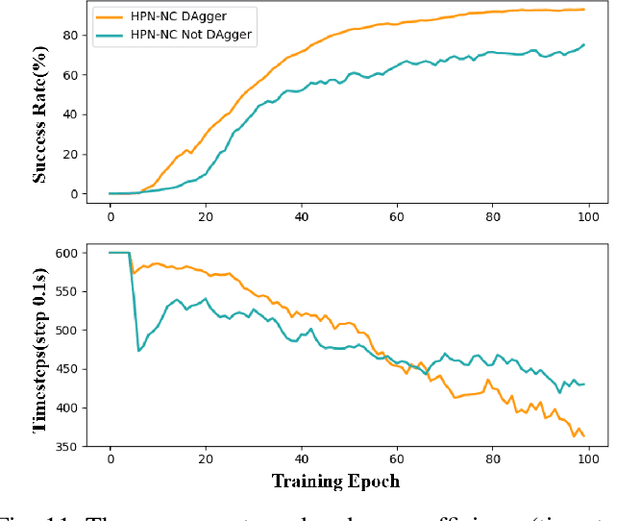
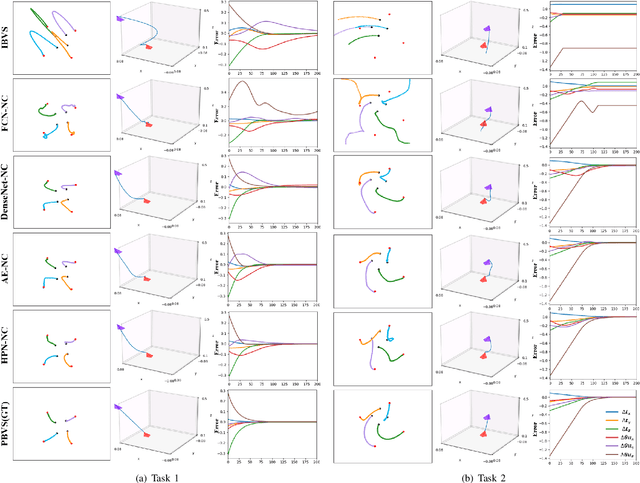
Recently, several works achieve end-to-end visual servoing (VS) for robotic manipulation by replacing traditional controller with differentiable neural networks, but lose the ability to servo arbitrary desired poses. This letter proposes a differentiable architecture for arbitrary pose servoing: a hyper-network based neural controller (HPN-NC). To achieve this, HPN-NC consists of a hyper net and a low-level controller, where the hyper net learns to generate the parameters of the low-level controller and the controller uses the 2D keypoints error for control like traditional image-based visual servoing (IBVS). HPN-NC can complete 6 degree of freedom visual servoing with large initial offset. Taking advantage of the fully differentiable nature of HPN-NC, we provide a three-stage training procedure to servo real world objects. With self-supervised end-to-end training, the performance of the integrated model can be further improved in unseen scenes and the amount of manual annotations can be significantly reduced.