 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SC-VAE: Sparse Coding-based Variational Autoencoder
Mar 29, 2023
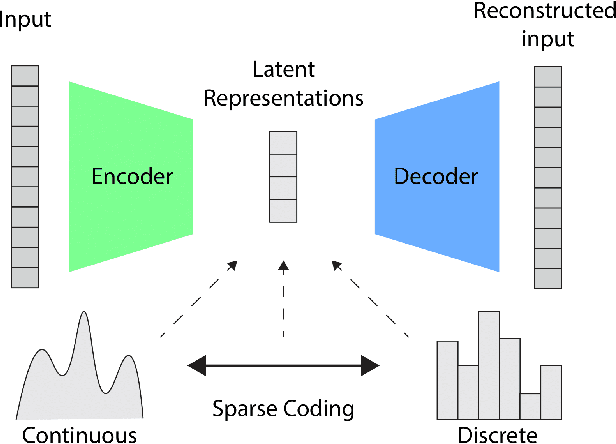
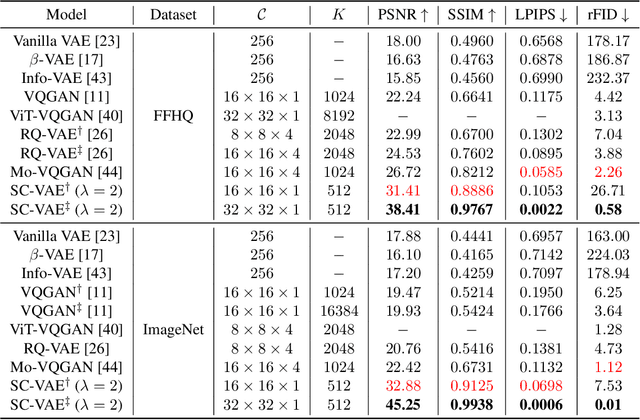
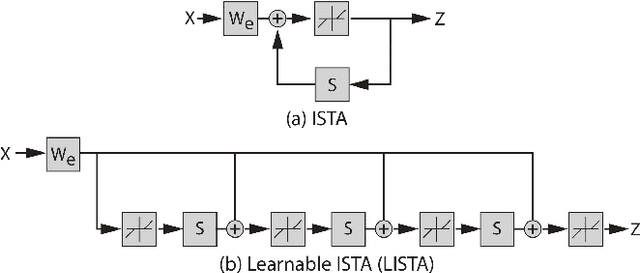
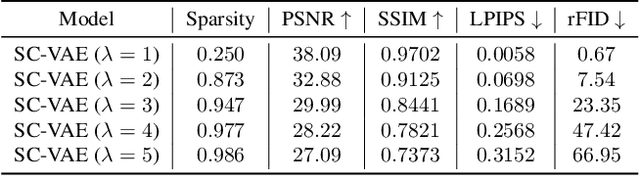
Learning rich data representations from unlabeled data is a key challenge towards applying deep learning algorithms in downstream supervised tasks. Several variants of variational autoencoders have been proposed to learn compact data representaitons by encoding high-dimensional data in a lower dimensional space. Two main classes of VAEs methods may be distinguished depending on the characteristics of the meta-priors that are enforced in the representation learning step. The first class of methods derives a continuous encoding by assuming a static prior distribution in the latent space. The second class of methods learns instead a discrete latent representation using vector quantization (VQ) along with a codebook. However, both classes of methods suffer from certain challenges, which may lead to suboptimal image reconstruction results. The first class of methods suffers from posterior collapse, whereas the second class of methods suffers from codebook collapse. To address these challenges, we introduce a new VAE variant, termed SC-VAE (sparse coding-based VAE), which integrates sparse coding within variational autoencoder framework. Instead of learning a continuous or discrete latent representation, the proposed method learns a sparse data representation that consists of a linear combination of a small number of learned atoms. The sparse coding problem is solved using a learnable version of the iterative shrinkage thresholding algorithm (ISTA). Experiments on two image datasets demonstrate that our model can achieve improved image reconstruction results compared to state-of-the-art methods. Moreover, the use of learned sparse code vectors allows us to perform downstream task like coarse image segmentation through clustering image patches.
DAE-Talker: High Fidelity Speech-Driven Talking Face Generation with Diffusion Autoencoder
Mar 30, 2023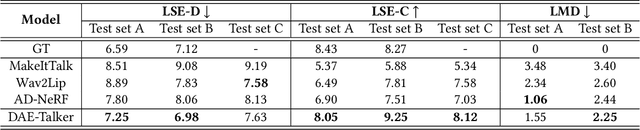
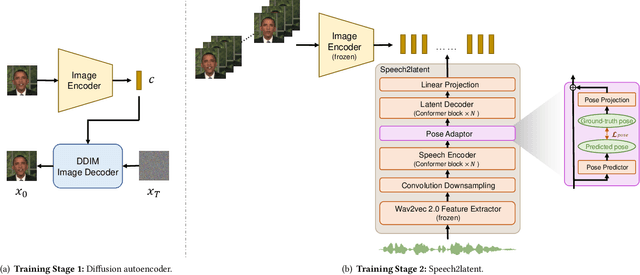

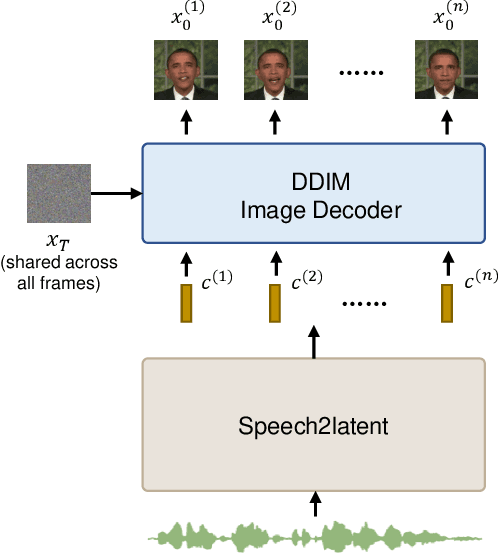
While recent research has made significant progress in speech-driven talking face generation, the quality of the generated video still lags behind that of real recordings. One reason for this is the use of handcrafted intermediate representations like facial landmarks and 3DMM coefficients, which are designed based on human knowledge and are insufficient to precisely describe facial movements. Additionally, these methods require an external pretrained model for extracting these representations, whose performance sets an upper bound on talking face generation. To address these limitations, we propose a novel method called DAE-Talker that leverages data-driven latent representations obtained from a diffusion autoencoder (DAE). DAE contains an image encoder that encodes an image into a latent vector and a DDIM image decoder that reconstructs the image from it. We train our DAE on talking face video frames and then extract their latent representations as the training target for a Conformer-based speech2latent model. This allows DAE-Talker to synthesize full video frames and produce natural head movements that align with the content of speech, rather than relying on a predetermined head pose from a template video. We also introduce pose modelling in speech2latent for pose controllability. Additionally, we propose a novel method for generating continuous video frames with the DDIM image decoder trained on individual frames, eliminating the need for modelling the joint distribution of consecutive frames directly. Our experiments show that DAE-Talker outperforms existing popular methods in lip-sync, video fidelity, and pose naturalness. We also conduct ablation studies to analyze the effectiveness of the proposed techniques and demonstrate the pose controllability of DAE-Talker.
Automatic Measures for Evaluating Generative Design Methods for Architects
Mar 20, 2023


The recent explosion of high-quality image-to-image methods has prompted interest in applying image-to-image methods towards artistic and design tasks. Of interest for architects is to use these methods to generate design proposals from conceptual sketches, usually hand-drawn sketches that are quickly developed and can embody a design intent. More specifically, instantiating a sketch into a visual that can be used to elicit client feedback is typically a time consuming task, and being able to speed up this iteration time is important. While the body of work in generative methods has been impressive, there has been a mismatch between the quality measures used to evaluate the outputs of these systems and the actual expectations of architects. In particular, most recent image-based works place an emphasis on realism of generated images. While important, this is one of several criteria architects look for. In this work, we describe the expectations architects have for design proposals from conceptual sketches, and identify corresponding automated metrics from the literature. We then evaluate several image-to-image generative methods that may address these criteria and examine their performance across these metrics. From these results, we identify certain challenges with hand-drawn conceptual sketches and describe possible future avenues of investigation to address them.
Pallet Detection from Synthetic Data Using Game Engines
Apr 07, 2023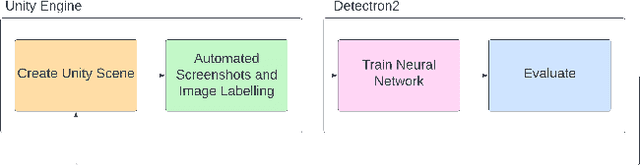
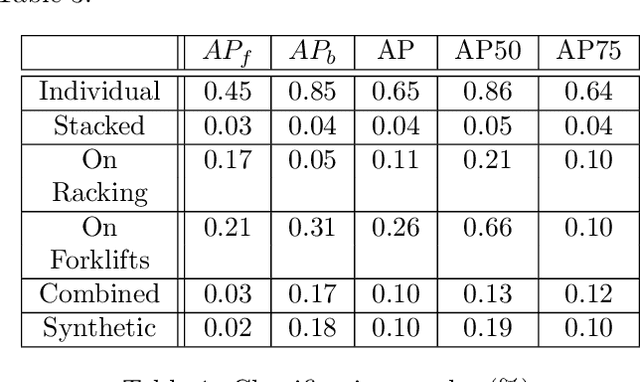

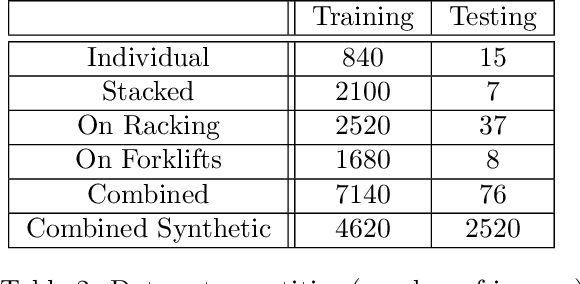
This research sets out to assess the viability of using game engines to generate synthetic training data for machine learning in the context of pallet segmentation. Using synthetic data has been proven in prior research to be a viable means of training neural networks and saves hours of manual labour due to the reduced need for manual image annotation. Machine vision for pallet detection can benefit from synthetic data as the industry increases the development of autonomous warehousing technologies. As per our methodology, we developed a tool capable of automatically generating large amounts of annotated training data from 3D models at pixel-perfect accuracy and a much faster rate than manual approaches. Regarding image segmentation, a Mask R-CNN pipeline was used, which achieved an AP50 of 86% for individual pallets.
* 9 Pages, 10 Figures
Track Anything: Segment Anything Meets Videos
Apr 24, 2023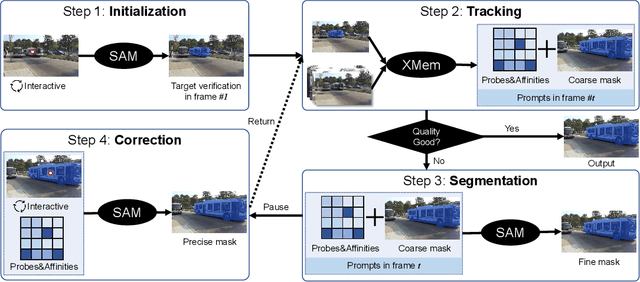
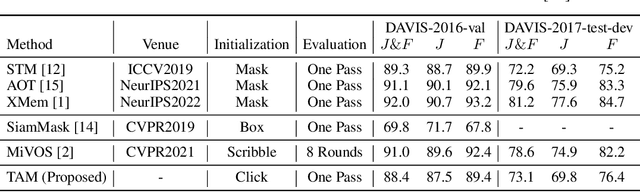


Recently, the Segment Anything Model (SAM) gains lots of attention rapidly due to its impressive segmentation performance on images. Regarding its strong ability on image segmentation and high interactivity with different prompts, we found that it performs poorly on consistent segmentation in videos. Therefore, in this report, we propose Track Anything Model (TAM), which achieves high-performance interactive tracking and segmentation in videos. To be detailed, given a video sequence, only with very little human participation, \textit{i.e.}, several clicks, people can track anything they are interested in, and get satisfactory results in one-pass inference. Without additional training, such an interactive design performs impressively on video object tracking and segmentation. All resources are available on \url{https://github.com/gaomingqi/Track-Anything}. We hope this work can facilitate related research.
Adversarial Generative NMF for Single Channel Source Separation
Apr 24, 2023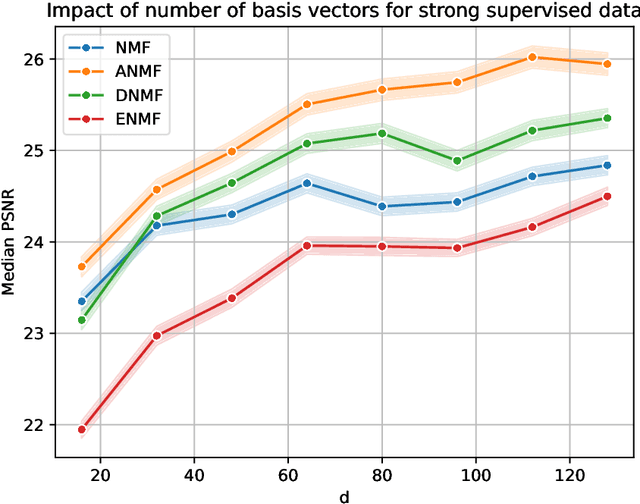
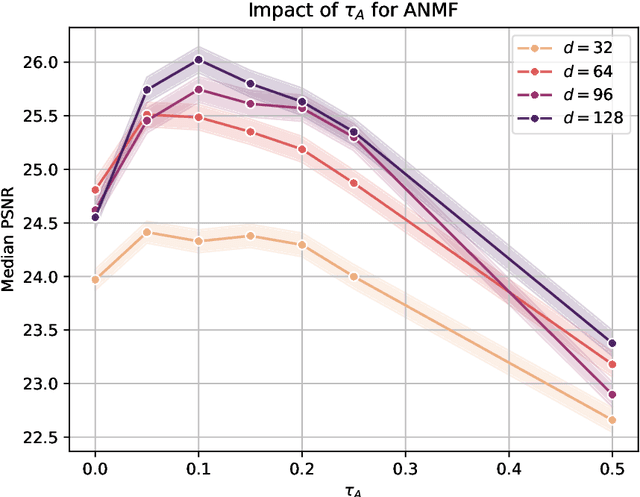
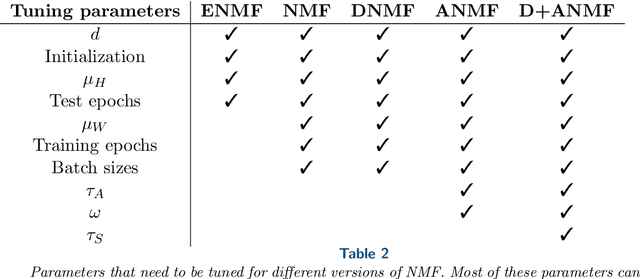
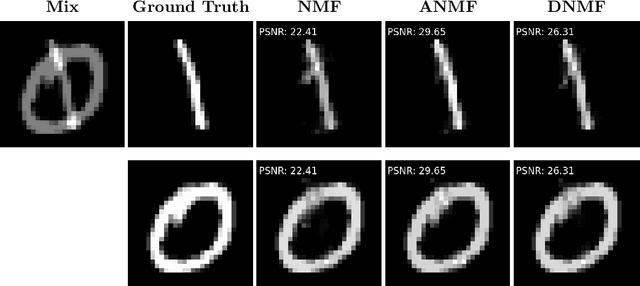
The idea of adversarial learning of regularization functionals has recently been introduced in the wider context of inverse problems. The intuition behind this method is the realization that it is not only necessary to learn the basic features that make up a class of signals one wants to represent, but also, or even more so, which features to avoid in the representation. In this paper, we will apply this approach to the problem of source separation by means of non-negative matrix factorization (NMF) and present a new method for the adversarial training of NMF bases. We show in numerical experiments, both for image and audio separation, that this leads to a clear improvement of the reconstructed signals, in particular in the case where little or no strong supervision data is available.
WeakTr: Exploring Plain Vision Transformer for Weakly-supervised Semantic Segmentation
Apr 27, 2023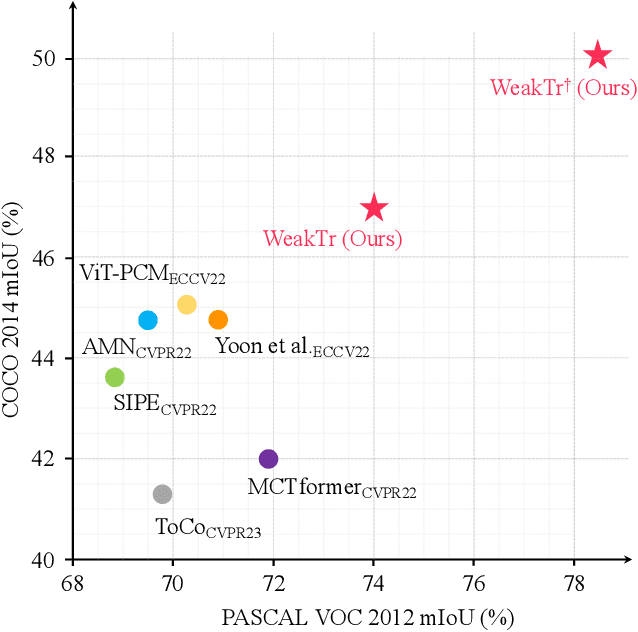
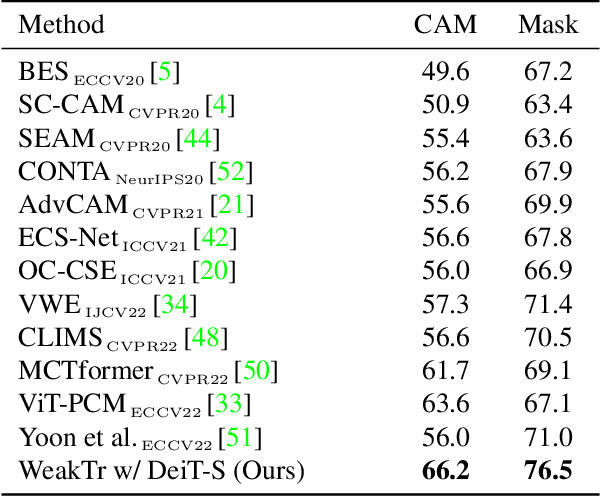
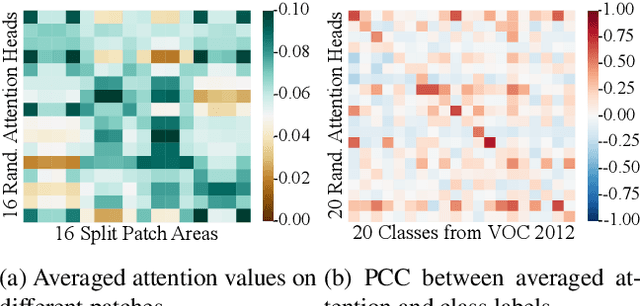

This paper explores the properties of the plain Vision Transformer (ViT) for Weakly-supervised Semantic Segmentation (WSSS). The class activation map (CAM) is of critical importance for understanding a classification network and launching WSSS. We observe that different attention heads of ViT focus on different image areas. Thus a novel weight-based method is proposed to end-to-end estimate the importance of attention heads, while the self-attention maps are adaptively fused for high-quality CAM results that tend to have more complete objects. Besides, we propose a ViT-based gradient clipping decoder for online retraining with the CAM results to complete the WSSS task. We name this plain Transformer-based Weakly-supervised learning framework WeakTr. It achieves the state-of-the-art WSSS performance on standard benchmarks, i.e., 78.4% mIoU on the val set of PASCAL VOC 2012 and 50.3% mIoU on the val set of COCO 2014. Code is available at https://github.com/hustvl/WeakTr.
SkinSAM: Empowering Skin Cancer Segmentation with Segment Anything Model
Apr 27, 2023
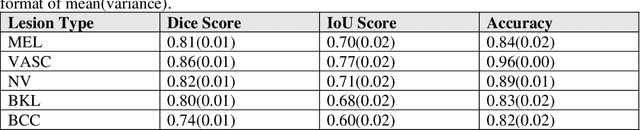

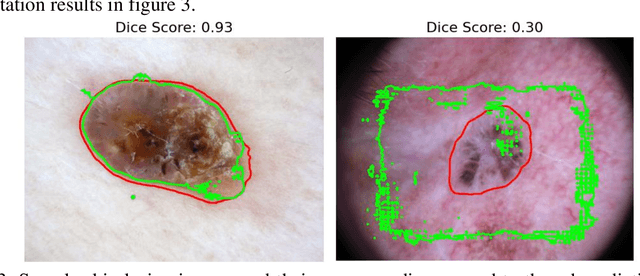
Skin cancer is a prevalent and potentially fatal disease that requires accurate and efficient diagnosis and treatment. Although manual tracing is the current standard in clinics, automated tools are desired to reduce human labor and improve accuracy. However, developing such tools is challenging due to the highly variable appearance of skin cancers and complex objects in the background. In this paper, we present SkinSAM, a fine-tuned model based on the Segment Anything Model that showed outstanding segmentation performance. The models are validated on HAM10000 dataset which includes 10015 dermatoscopic images. While larger models (ViT_L, ViT_H) performed better than the smaller one (ViT_b), the finetuned model (ViT_b_finetuned) exhibited the greatest improvement, with a Mean pixel accuracy of 0.945, Mean dice score of 0.8879, and Mean IoU score of 0.7843. Among the lesion types, vascular lesions showed the best segmentation results. Our research demonstrates the great potential of adapting SAM to medical image segmentation tasks.
OriCon3D: Effective 3D Object Detection using Orientation and Confidence
Apr 27, 2023
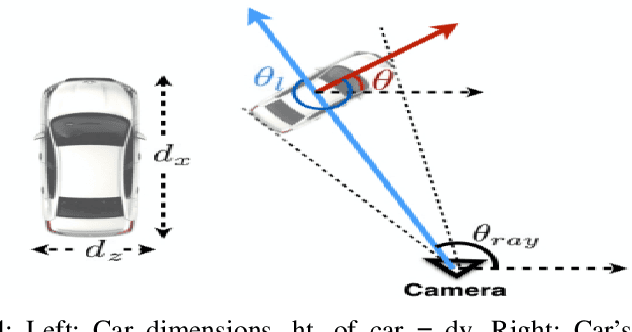
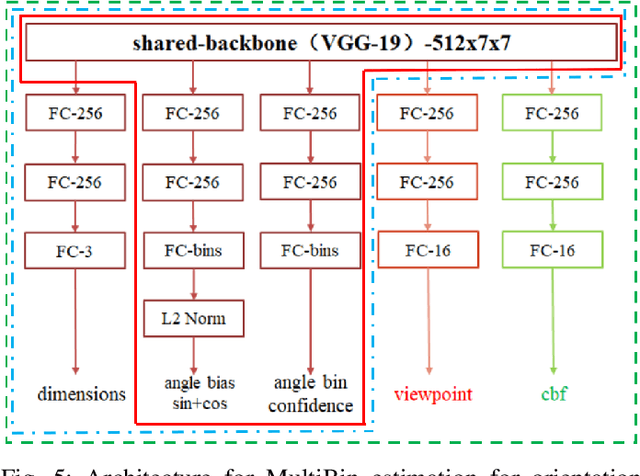
We introduce a technique for detecting 3D objects and estimating their position from a single image. Our method is built on top of a similar state-of-the-art technique [1], but with improved accuracy. The approach followed in this research first estimates common 3D properties of an object using a Deep Convolutional Neural Network (DCNN), contrary to other frameworks that only leverage centre-point predictions. We then combine these estimates with geometric constraints provided by a 2D bounding box to produce a complete 3D bounding box. The first output of our network estimates the 3D object orientation using a discrete-continuous loss [1]. The second output predicts the 3D object dimensions with minimal variance. Here we also present our extensions by augmenting light-weight feature extractors and a customized multibin architecture. By combining these estimates with the geometric constraints of the 2D bounding box, we can accurately (or comparatively) determine the 3D object pose better than our baseline [1] on the KITTI 3D detection benchmark [2].
ContraNeRF: 3D-Aware Generative Model via Contrastive Learning with Unsupervised Implicit Pose Embedding
Apr 27, 2023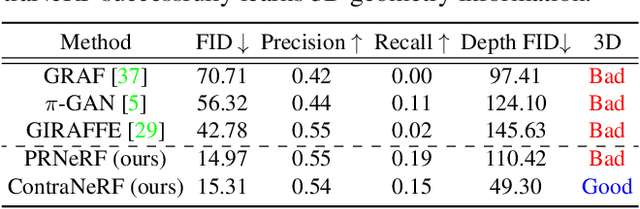
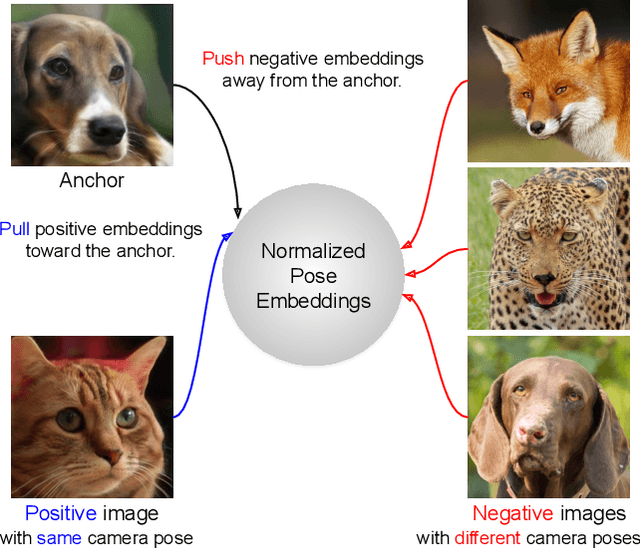
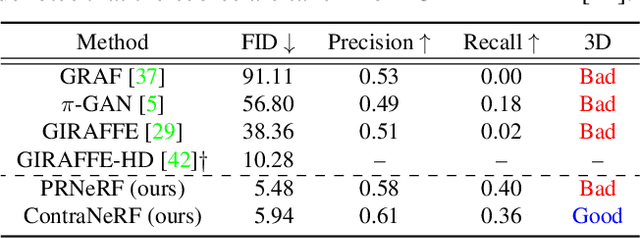
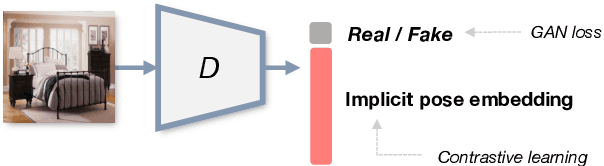
Although 3D-aware GANs based on neural radiance fields have achieved competitive performance, their applicability is still limited to objects or scenes with the ground-truths or prediction models for clearly defined canonical camera poses. To extend the scope of applicable datasets, we propose a novel 3D-aware GAN optimization technique through contrastive learning with implicit pose embeddings. To this end, we first revise the discriminator design and remove dependency on ground-truth camera poses. Then, to capture complex and challenging 3D scene structures more effectively, we make the discriminator estimate a high-dimensional implicit pose embedding from a given image and perform contrastive learning on the pose embedding. The proposed approach can be employed for the dataset, where the canonical camera pose is ill-defined because it does not look up or estimate camera poses. Experimental results show that our algorithm outperforms existing methods by large margins on the datasets with multiple object categories and inconsistent canonical camera poses.