 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Robust Text-Prompted Semantic Criterion for In-the-Wild Video Quality Assessment
Apr 28, 2023
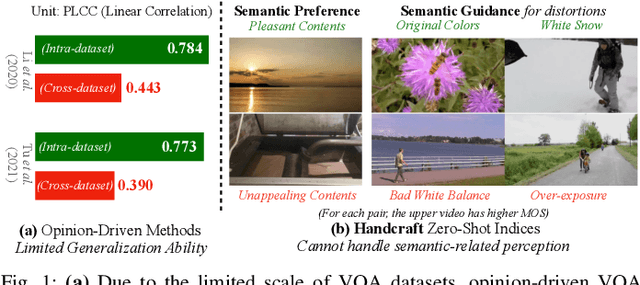
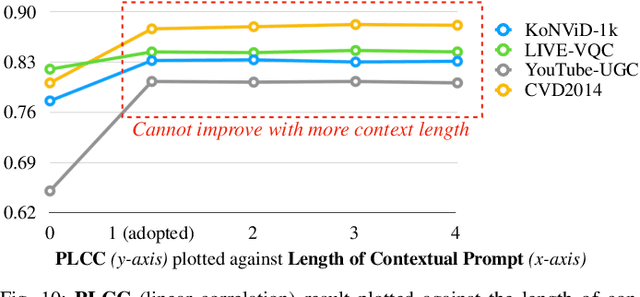
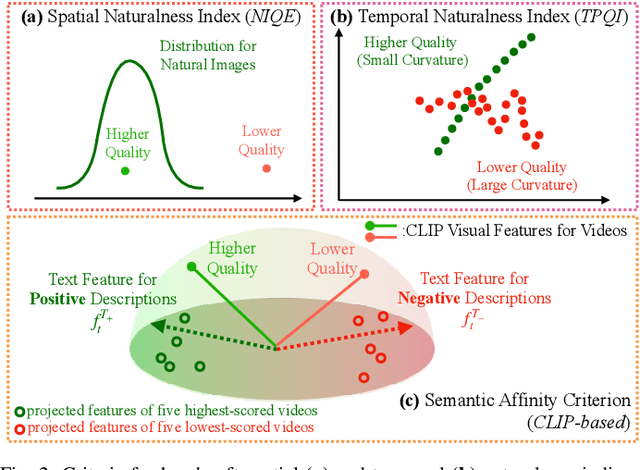
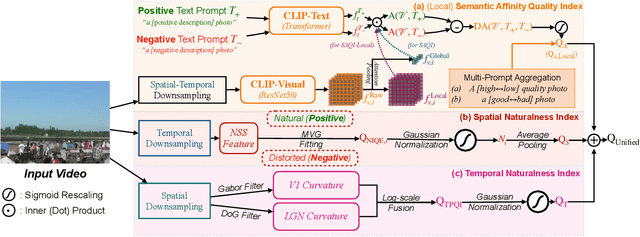
The proliferation of videos collected during in-the-wild natural settings has pushed the development of effective Video Quality Assessment (VQA) methodologies. Contemporary supervised opinion-driven VQA strategies predominantly hinge on training from expensive human annotations for quality scores, which limited the scale and distribution of VQA datasets and consequently led to unsatisfactory generalization capacity of methods driven by these data. On the other hand, although several handcrafted zero-shot quality indices do not require training from human opinions, they are unable to account for the semantics of videos, rendering them ineffective in comprehending complex authentic distortions (e.g., white balance, exposure) and assessing the quality of semantic content within videos. To address these challenges, we introduce the text-prompted Semantic Affinity Quality Index (SAQI) and its localized version (SAQI-Local) using Contrastive Language-Image Pre-training (CLIP) to ascertain the affinity between textual prompts and visual features, facilitating a comprehensive examination of semantic quality concerns without the reliance on human quality annotations. By amalgamating SAQI with existing low-level metrics, we propose the unified Blind Video Quality Index (BVQI) and its improved version, BVQI-Local, which demonstrates unprecedented performance, surpassing existing zero-shot indices by at least 24\% on all datasets. Moreover, we devise an efficient fine-tuning scheme for BVQI-Local that jointly optimizes text prompts and final fusion weights, resulting in state-of-the-art performance and superior generalization ability in comparison to prevalent opinion-driven VQA methods. We conduct comprehensive analyses to investigate different quality concerns of distinct indices, demonstrating the effectiveness and rationality of our design.
Explore the Power of Synthetic Data on Few-shot Object Detection
Mar 23, 2023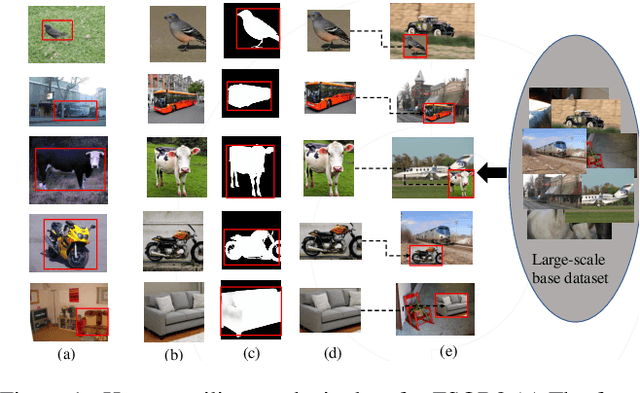
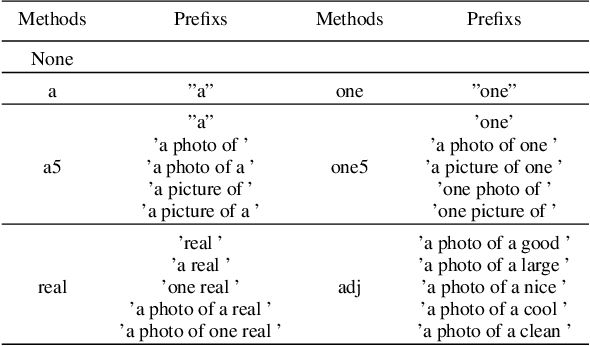
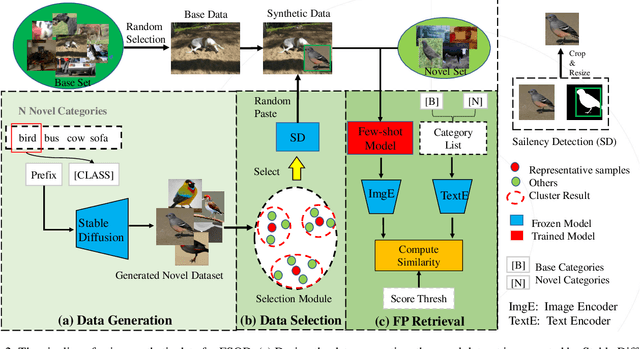
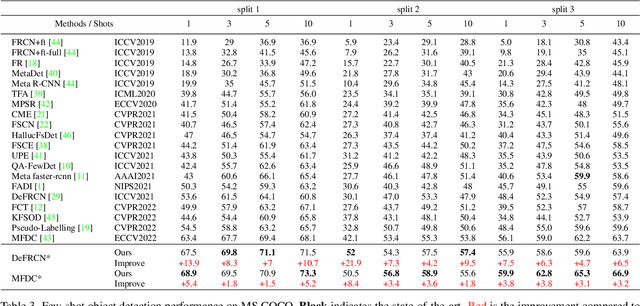
Few-shot object detection (FSOD) aims to expand an object detector for novel categories given only a few instances for training. The few training samples restrict the performance of FSOD model. Recent text-to-image generation models have shown promising results in generating high-quality images. How applicable these synthetic images are for FSOD tasks remains under-explored. This work extensively studies how synthetic images generated from state-of-the-art text-to-image generators benefit FSOD tasks. We focus on two perspectives: (1) How to use synthetic data for FSOD? (2) How to find representative samples from the large-scale synthetic dataset? We design a copy-paste-based pipeline for using synthetic data. Specifically, saliency object detection is applied to the original generated image, and the minimum enclosing box is used for cropping the main object based on the saliency map. After that, the cropped object is randomly pasted on the image, which comes from the base dataset. We also study the influence of the input text of text-to-image generator and the number of synthetic images used. To construct a representative synthetic training dataset, we maximize the diversity of the selected images via a sample-based and cluster-based method. However, the severe problem of high false positives (FP) ratio of novel categories in FSOD can not be solved by using synthetic data. We propose integrating CLIP, a zero-shot recognition model, into the FSOD pipeline, which can filter 90% of FP by defining a threshold for the similarity score between the detected object and the text of the predicted category. Extensive experiments on PASCAL VOC and MS COCO validate the effectiveness of our method, in which performance gain is up to 21.9% compared to the few-shot baseline.
VR Facial Animation for Immersive Telepresence Avatars
Apr 24, 2023

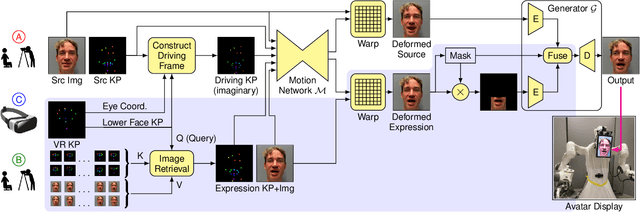
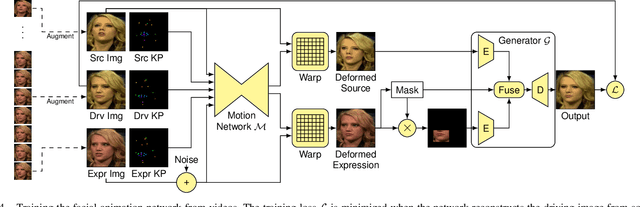
VR Facial Animation is necessary in applications requiring clear view of the face, even though a VR headset is worn. In our case, we aim to animate the face of an operator who is controlling our robotic avatar system. We propose a real-time capable pipeline with very fast adaptation for specific operators. In a quick enrollment step, we capture a sequence of source images from the operator without the VR headset which contain all the important operator-specific appearance information. During inference, we then use the operator keypoint information extracted from a mouth camera and two eye cameras to estimate the target expression and head pose, to which we map the appearance of a source still image. In order to enhance the mouth expression accuracy, we dynamically select an auxiliary expression frame from the captured sequence. This selection is done by learning to transform the current mouth keypoints into the source camera space, where the alignment can be determined accurately. We, furthermore, demonstrate an eye tracking pipeline that can be trained in less than a minute, a time efficient way to train the whole pipeline given a dataset that includes only complete faces, show exemplary results generated by our method, and discuss performance at the ANA Avatar XPRIZE semifinals.
End-to-End Lidar-Camera Self-Calibration for Autonomous Vehicles
Apr 24, 2023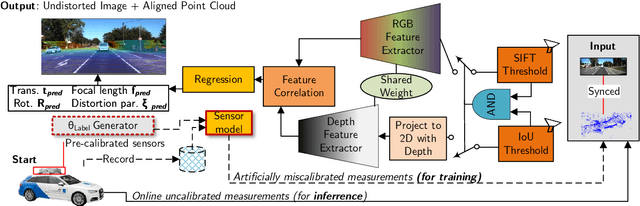

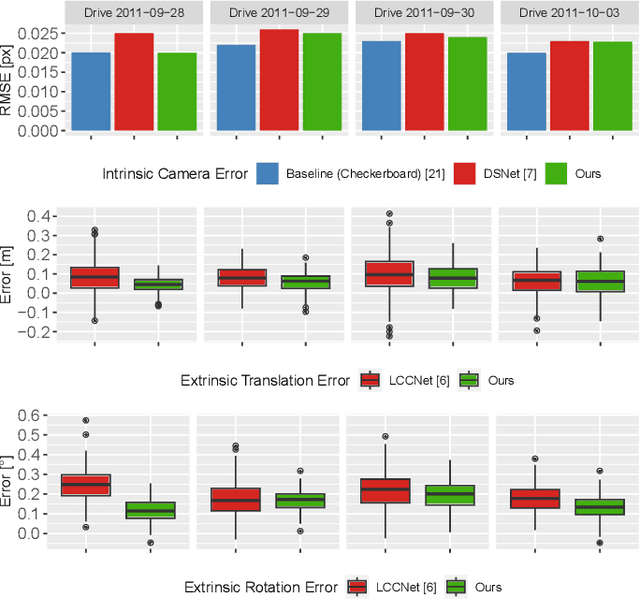
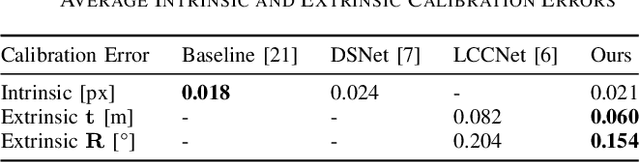
Autonomous vehicles are equipped with a multi-modal sensor setup to enable the car to drive safely. The initial calibration of such perception sensors is a highly matured topic and is routinely done in an automated factory environment. However, an intriguing question arises on how to maintain the calibration quality throughout the vehicle's operating duration. Another challenge is to calibrate multiple sensors jointly to ensure no propagation of systemic errors. In this paper, we propose CaLiCa, an end-to-end deep self-calibration network which addresses the automatic calibration problem for pinhole camera and Lidar. We jointly predict the camera intrinsic parameters (focal length and distortion) as well as Lidar-Camera extrinsic parameters (rotation and translation), by regressing feature correlation between the camera image and the Lidar point cloud. The network is arranged in a Siamese-twin structure to constrain the network features learning to a mutually shared feature in both point cloud and camera (Lidar-camera constraint). Evaluation using KITTI datasets shows that we achieve 0.154 {\deg} and 0.059 m accuracy with a reprojection error of 0.028 pixel with a single-pass inference. We also provide an ablative study of how our end-to-end learning architecture offers lower terminal loss (21% decrease in rotation loss) compared to isolated calibration
Directional Connectivity-based Segmentation of Medical Images
Mar 31, 2023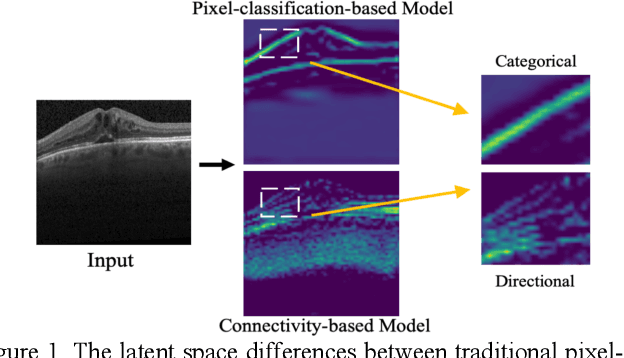
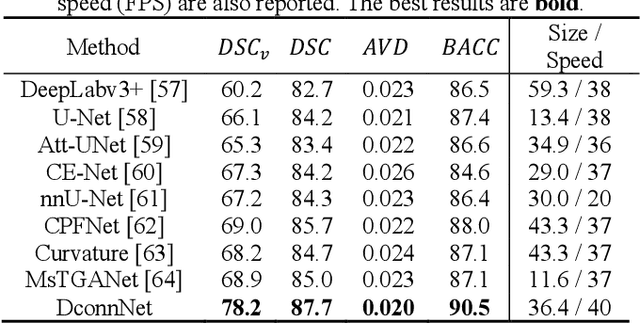
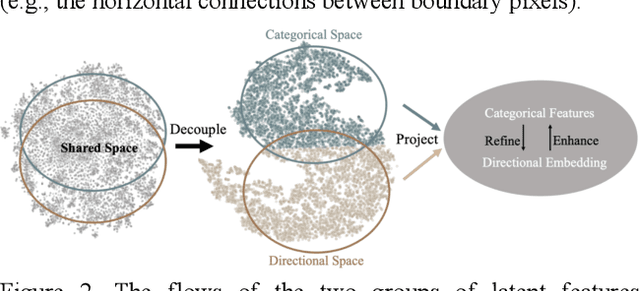
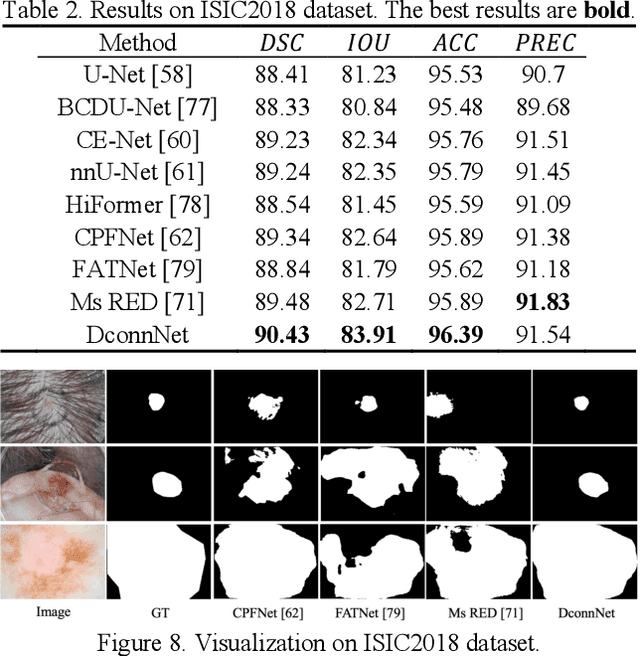
Anatomical consistency in biomarker segmentation is crucial for many medical image analysis tasks. A promising paradigm for achieving anatomically consistent segmentation via deep networks is incorporating pixel connectivity, a basic concept in digital topology, to model inter-pixel relationships. However, previous works on connectivity modeling have ignored the rich channel-wise directional information in the latent space. In this work, we demonstrate that effective disentanglement of directional sub-space from the shared latent space can significantly enhance the feature representation in the connectivity-based network. To this end, we propose a directional connectivity modeling scheme for segmentation that decouples, tracks, and utilizes the directional information across the network. Experiments on various public medical image segmentation benchmarks show the effectiveness of our model as compared to the state-of-the-art methods. Code is available at https://github.com/Zyun-Y/DconnNet.
From Private to Public: Benchmarking GANs in the Context of Private Time Series Classification
Apr 19, 2023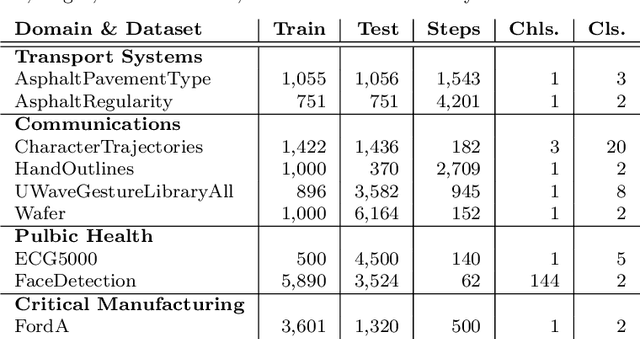


Deep learning has proven to be successful in various domains and for different tasks. However, when it comes to private data several restrictions are making it difficult to use deep learning approaches in these application fields. Recent approaches try to generate data privately instead of applying a privacy-preserving mechanism directly, on top of the classifier. The solution is to create public data from private data in a manner that preserves the privacy of the data. In this work, two very prominent GAN-based architectures were evaluated in the context of private time series classification. In contrast to previous work, mostly limited to the image domain, the scope of this benchmark was the time series domain. The experiments show that especially GSWGAN performs well across a variety of public datasets outperforming the competitor DPWGAN. An analysis of the generated datasets further validates the superiority of GSWGAN in the context of time series generation.
DADFNet: Dual Attention and Dual Frequency-Guided Dehazing Network for Video-Empowered Intelligent Transportation
Apr 19, 2023

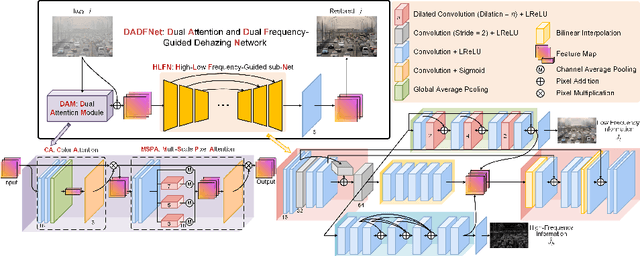
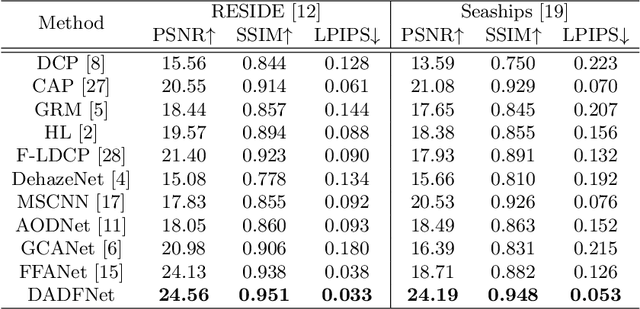
Visual surveillance technology is an indispensable functional component of advanced traffic management systems. It has been applied to perform traffic supervision tasks, such as object detection, tracking and recognition. However, adverse weather conditions, e.g., fog, haze and mist, pose severe challenges for video-based transportation surveillance. To eliminate the influences of adverse weather conditions, we propose a dual attention and dual frequency-guided dehazing network (termed DADFNet) for real-time visibility enhancement. It consists of a dual attention module (DAM) and a high-low frequency-guided sub-net (HLFN) to jointly consider the attention and frequency mapping to guide haze-free scene reconstruction. Extensive experiments on both synthetic and real-world images demonstrate the superiority of DADFNet over state-of-the-art methods in terms of visibility enhancement and improvement in detection accuracy. Furthermore, DADFNet only takes $6.3$ ms to process a 1,920 * 1,080 image on the 2080 Ti GPU, making it highly efficient for deployment in intelligent transportation systems.
ReelFramer: Co-creating News Reels on Social Media with Generative AI
Apr 19, 2023



Short videos on social media are a prime way many young people find and consume content. News outlets would like to reach audiences through news reels, but currently struggle to translate traditional journalistic formats into the short, entertaining videos that match the style of the platform. There are many ways to frame a reel-style narrative around a news story, and selecting one is a challenge. Different news stories call for different framings, and require a different trade-off between entertainment and information. We present a system called ReelFramer that uses text and image generation to help journalists explore multiple narrative framings for a story, then generate scripts, character boards and storyboards they can edit and iterate on. A user study of five graduate students in journalism-related fields found the system greatly eased the burden of transforming a written story into a reel, and that exploring framings to find the right one was a rewarding process.
SP-BatikGAN: An Efficient Generative Adversarial Network for Symmetric Pattern Generation
Apr 19, 2023
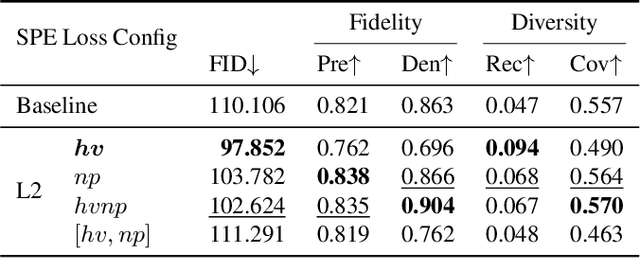
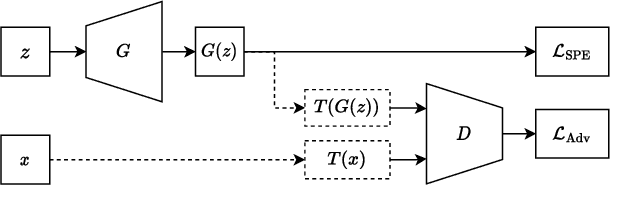
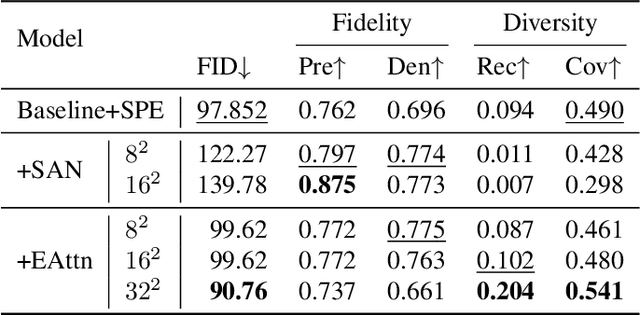
Following the contention of AI arts, our research focuses on bringing AI for all, particularly for artists, to create AI arts with limited data and settings. We are interested in geometrically symmetric pattern generation, which appears on many artworks such as Portuguese, Moroccan tiles, and Batik, a cultural heritage in Southeast Asia. Symmetric pattern generation is a complex problem, with prior research creating too-specific models for certain patterns only. We provide publicly, the first-ever 1,216 high-quality symmetric patterns straight from design files for this task. We then formulate symmetric pattern enforcement (SPE) loss to leverage underlying symmetric-based structures that exist on current image distributions. Our SPE improves and accelerates training on any GAN configuration, and, with efficient attention, SP-BatikGAN compared to FastGAN, the state-of-the-art GAN for limited setting, improves the FID score from 110.11 to 90.76, an 18% decrease, and model diversity recall score from 0.047 to 0.204, a 334% increase.
Exploring Stochastic Autoregressive Image Modeling for Visual Representation
Dec 03, 2022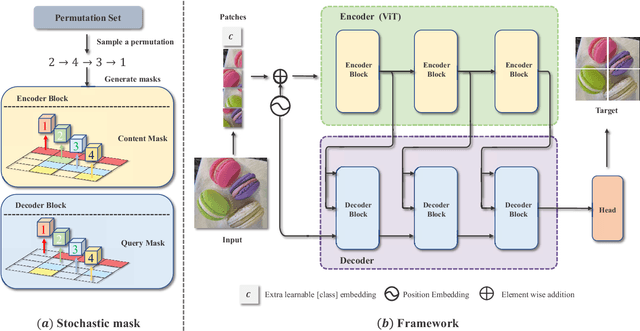
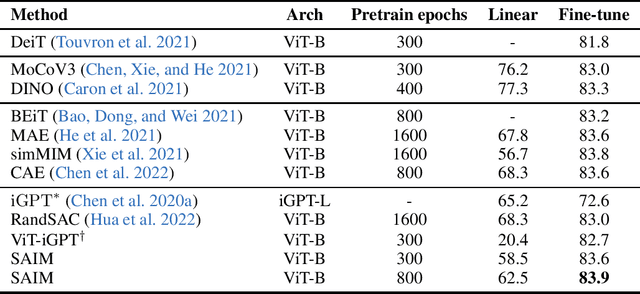
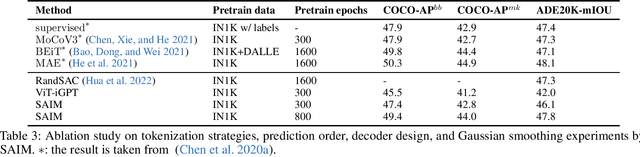
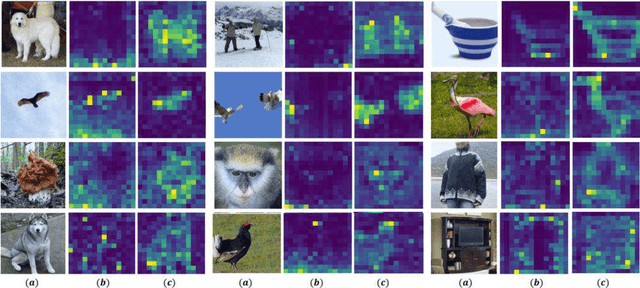
Autoregressive language modeling (ALM) have been successfully used in self-supervised pre-training in Natural language processing (NLP). However, this paradigm has not achieved comparable results with other self-supervised approach in computer vision (e.g., contrastive learning, mask image modeling). In this paper, we try to find the reason why autoregressive modeling does not work well on vision tasks. To tackle this problem, we fully analyze the limitation of visual autoregressive methods and proposed a novel stochastic autoregressive image modeling (named SAIM) by the two simple designs. First, we employ stochastic permutation strategy to generate effective and robust image context which is critical for vision tasks. Second, we create a parallel encoder-decoder training process in which the encoder serves a similar role to the standard vision transformer focus on learning the whole contextual information, and meanwhile the decoder predicts the content of the current position, so that the encoder and decoder can reinforce each other. By introducing stochastic prediction and the parallel encoder-decoder, SAIM significantly improve the performance of autoregressive image modeling. Our method achieves the best accuracy (83.9%) on the vanilla ViT-Base model among methods using only ImageNet-1K data. Transfer performance in downstream tasks also show that our model achieves competitive performance.