 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exploring Pre-trained Text-to-Video Diffusion Models for Referring Video Object Segmentation
Mar 18, 2024
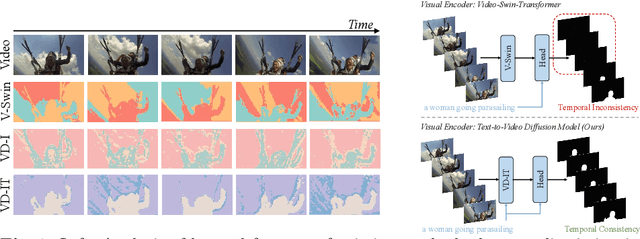
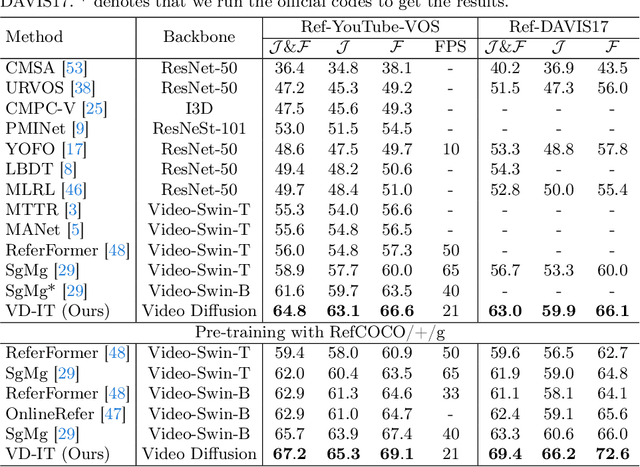
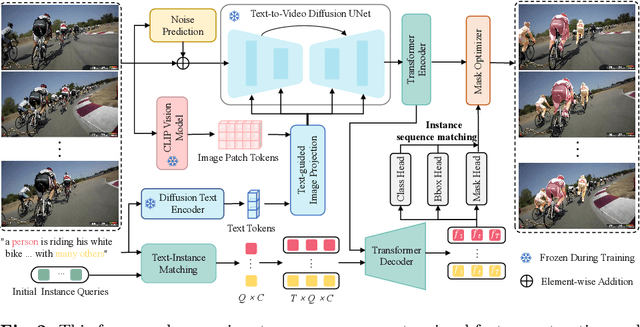
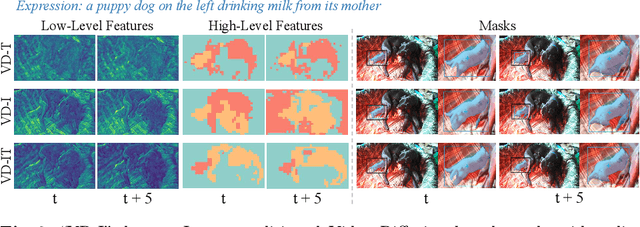
In this paper, we explore the visual representations produced from a pre-trained text-to-video (T2V) diffusion model for video understanding tasks. We hypothesize that the latent representation learned from a pretrained generative T2V model encapsulates rich semantics and coherent temporal correspondences, thereby naturally facilitating video understanding. Our hypothesis is validated through the classic referring video object segmentation (R-VOS) task. We introduce a novel framework, termed ``VD-IT'', tailored with dedicatedly designed components built upon a fixed pretrained T2V model. Specifically, VD-IT uses textual information as a conditional input, ensuring semantic consistency across time for precise temporal instance matching. It further incorporates image tokens as supplementary textual inputs, enriching the feature set to generate detailed and nuanced masks.Besides, instead of using the standard Gaussian noise, we propose to predict the video-specific noise with an extra noise prediction module, which can help preserve the feature fidelity and elevates segmentation quality. Through extensive experiments, we surprisingly observe that fixed generative T2V diffusion models, unlike commonly used video backbones (e.g., Video Swin Transformer) pretrained with discriminative image/video pre-tasks, exhibit better potential to maintain semantic alignment and temporal consistency. On existing standard benchmarks, our VD-IT achieves highly competitive results, surpassing many existing state-of-the-art methods. The code will be available at \url{https://github.com/buxiangzhiren/VD-IT}
HanDiffuser: Text-to-Image Generation With Realistic Hand Appearances
Mar 04, 2024
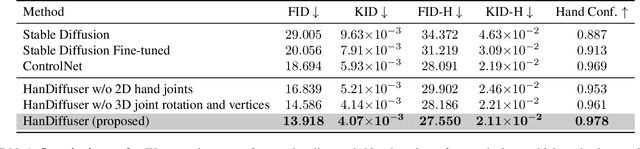
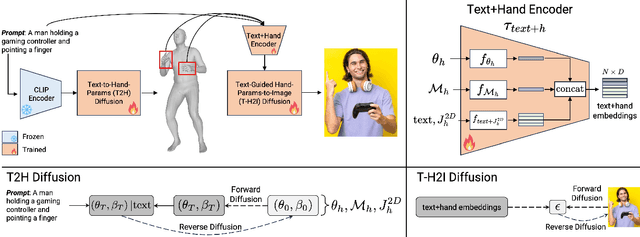

Text-to-image generative models can generate high-quality humans, but realism is lost when generating hands. Common artifacts include irregular hand poses, shapes, incorrect numbers of fingers, and physically implausible finger orientations. To generate images with realistic hands, we propose a novel diffusion-based architecture called HanDiffuser that achieves realism by injecting hand embeddings in the generative process. HanDiffuser consists of two components: a Text-to-Hand-Params diffusion model to generate SMPL-Body and MANO-Hand parameters from input text prompts, and a Text-Guided Hand-Params-to-Image diffusion model to synthesize images by conditioning on the prompts and hand parameters generated by the previous component. We incorporate multiple aspects of hand representation, including 3D shapes and joint-level finger positions, orientations and articulations, for robust learning and reliable performance during inference. We conduct extensive quantitative and qualitative experiments and perform user studies to demonstrate the efficacy of our method in generating images with high-quality hands.
General Purpose Image Encoder DINOv2 for Medical Image Registration
Feb 24, 2024Existing medical image registration algorithms rely on either dataset specific training or local texture-based features to align images. The former cannot be reliably implemented without large modality-specific training datasets, while the latter lacks global semantics thus could be easily trapped at local minima. In this paper, we present a training-free deformable image registration method, DINO-Reg, leveraging a general purpose image encoder DINOv2 for image feature extraction. The DINOv2 encoder was trained using the ImageNet data containing natural images. We used the pretrained DINOv2 without any finetuning. Our method feeds the DINOv2 encoded features into a discrete optimizer to find the optimal deformable registration field. We conducted a series of experiments to understand the behavior and role of such a general purpose image encoder in the application of image registration. Combined with handcrafted features, our method won the first place in the recent OncoReg Challenge. To our knowledge, this is the first application of general vision foundation models in medical image registration.
Randomized Principal Component Analysis for Hyperspectral Image Classification
Mar 14, 2024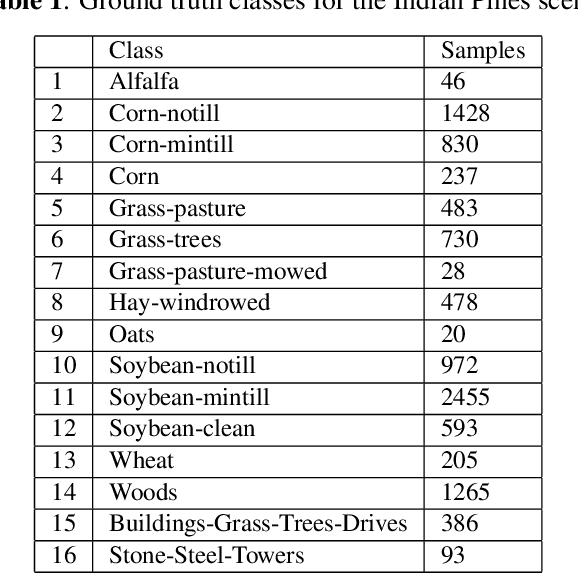

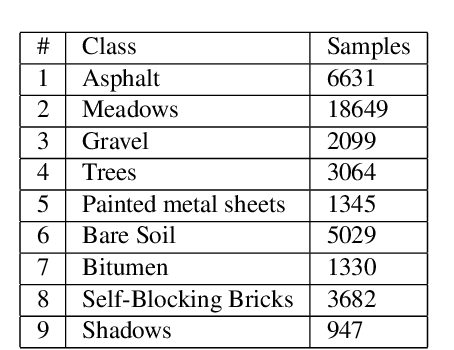
The high-dimensional feature space of the hyperspectral imagery poses major challenges to the processing and analysis of the hyperspectral data sets. In such a case, dimensionality reduction is necessary to decrease the computational complexity. The random projections open up new ways of dimensionality reduction, especially for large data sets. In this paper, the principal component analysis (PCA) and randomized principal component analysis (R-PCA) for the classification of hyperspectral images using support vector machines (SVM) and light gradient boosting machines (LightGBM) have been investigated. In this experimental research, the number of features was reduced to 20 and 30 for classification of two hyperspectral datasets (Indian Pines and Pavia University). The experimental results demonstrated that PCA outperformed R-PCA for SVM for both datasets, but received close accuracy values for LightGBM. The highest classification accuracies were obtained as 0.9925 and 0.9639 by LightGBM with original features for the Pavia University and Indian Pines, respectively.
ChartReformer: Natural Language-Driven Chart Image Editing
Mar 01, 2024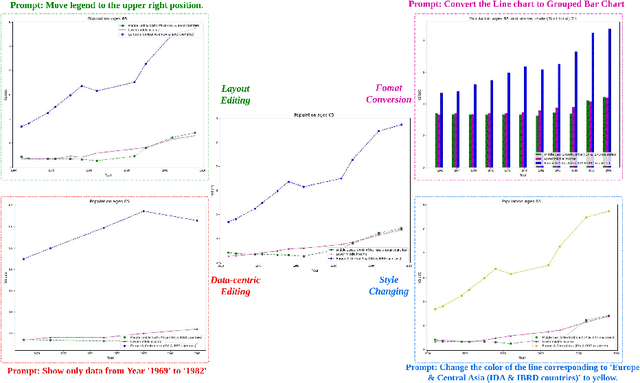
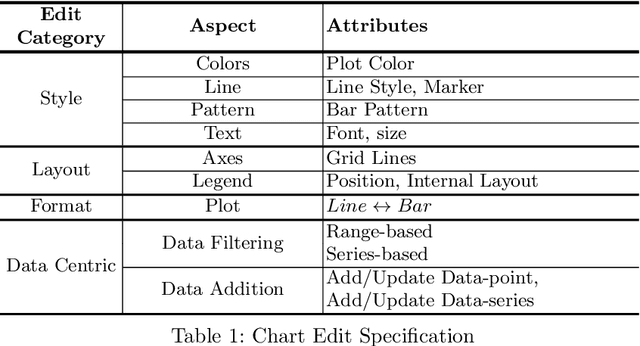
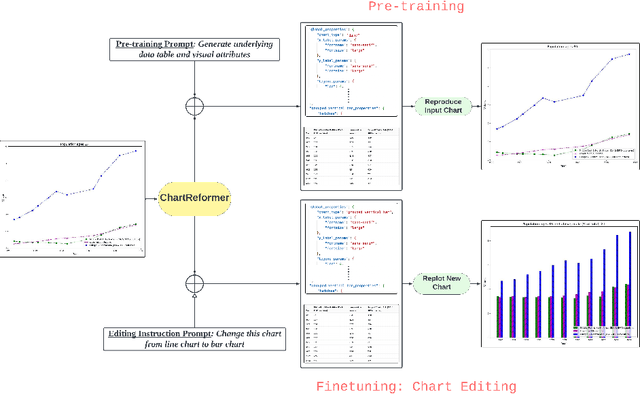
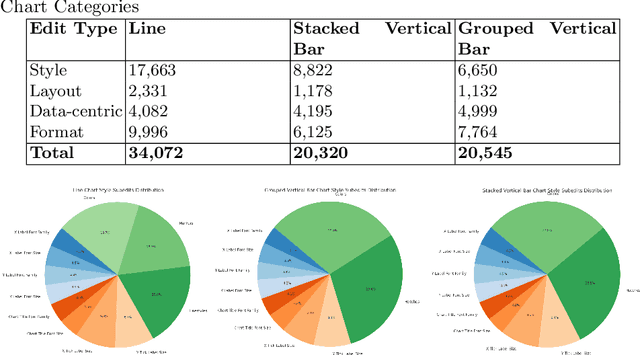
Chart visualizations are essential for data interpretation and communication; however, most charts are only accessible in image format and lack the corresponding data tables and supplementary information, making it difficult to alter their appearance for different application scenarios. To eliminate the need for original underlying data and information to perform chart editing, we propose ChartReformer, a natural language-driven chart image editing solution that directly edits the charts from the input images with the given instruction prompts. The key in this method is that we allow the model to comprehend the chart and reason over the prompt to generate the corresponding underlying data table and visual attributes for new charts, enabling precise edits. Additionally, to generalize ChartReformer, we define and standardize various types of chart editing, covering style, layout, format, and data-centric edits. The experiments show promising results for the natural language-driven chart image editing.
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Mar 14, 2024
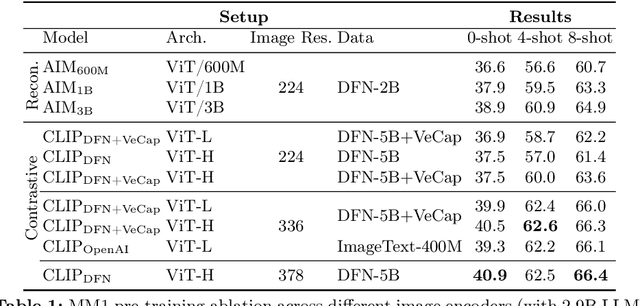
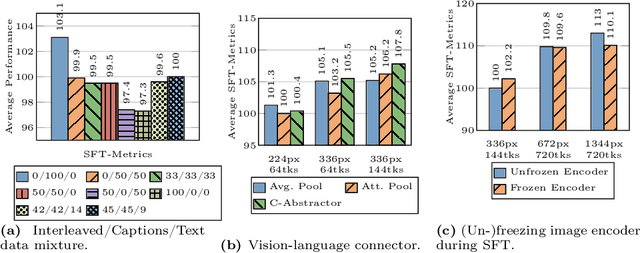
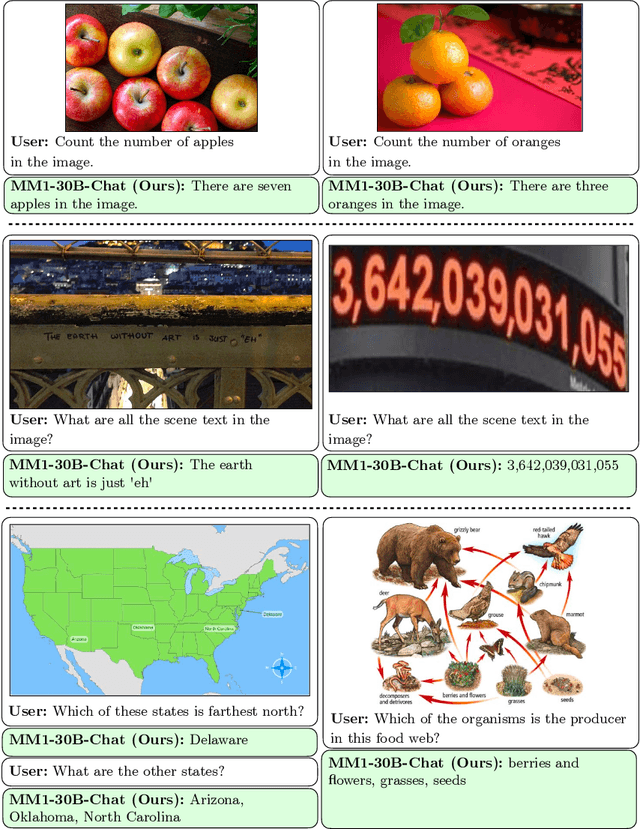
In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, consisting of both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
Enhancing Weakly Supervised 3D Medical Image Segmentation through Probabilistic-aware Learning
Mar 05, 2024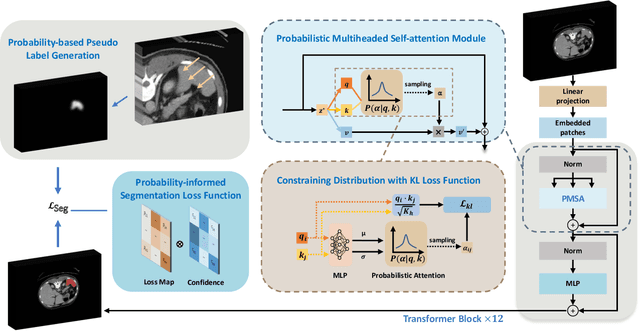
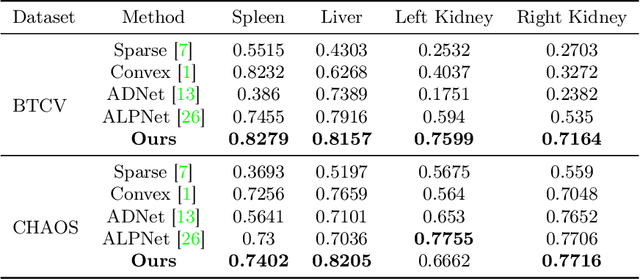
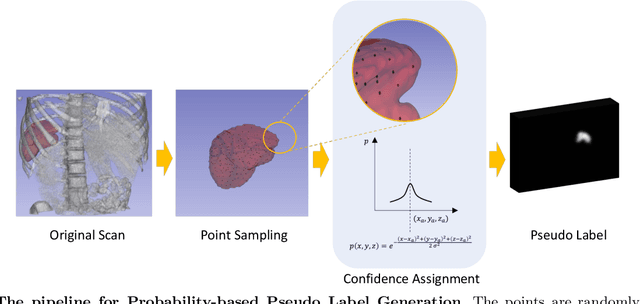
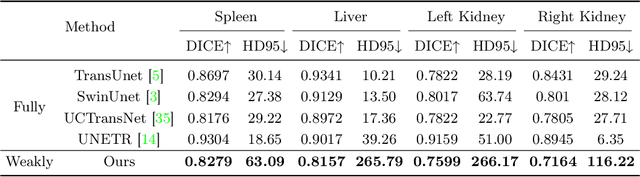
3D medical image segmentation is a challenging task with crucial implications for disease diagnosis and treatment planning. Recent advances in deep learning have significantly enhanced fully supervised medical image segmentation. However, this approach heavily relies on labor-intensive and time-consuming fully annotated ground-truth labels, particularly for 3D volumes. To overcome this limitation, we propose a novel probabilistic-aware weakly supervised learning pipeline, specifically designed for 3D medical imaging. Our pipeline integrates three innovative components: a probability-based pseudo-label generation technique for synthesizing dense segmentation masks from sparse annotations, a Probabilistic Multi-head Self-Attention network for robust feature extraction within our Probabilistic Transformer Network, and a Probability-informed Segmentation Loss Function to enhance training with annotation confidence. Demonstrating significant advances, our approach not only rivals the performance of fully supervised methods but also surpasses existing weakly supervised methods in CT and MRI datasets, achieving up to 18.1% improvement in Dice scores for certain organs. The code is available at https://github.com/runminjiang/PW4MedSeg.
Enhancing the Rate-Distortion-Perception Flexibility of Learned Image Codecs with Conditional Diffusion Decoders
Mar 05, 2024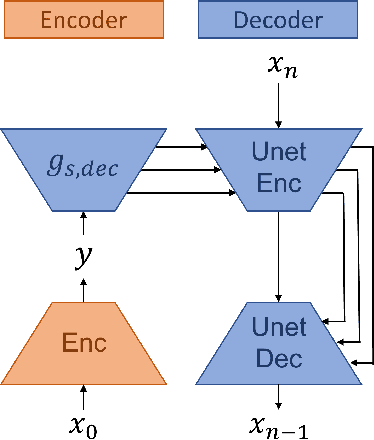

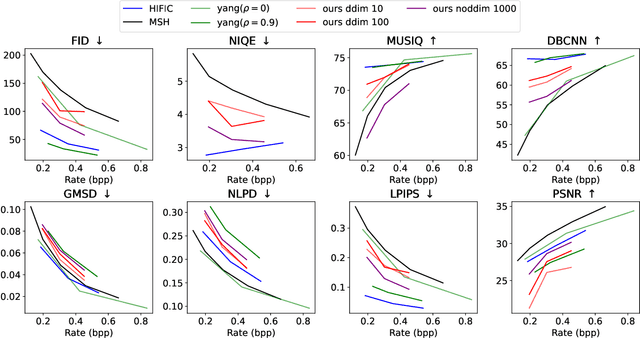
Learned image compression codecs have recently achieved impressive compression performances surpassing the most efficient image coding architectures. However, most approaches are trained to minimize rate and distortion which often leads to unsatisfactory visual results at low bitrates since perceptual metrics are not taken into account. In this paper, we show that conditional diffusion models can lead to promising results in the generative compression task when used as a decoder, and that, given a compressed representation, they allow creating new tradeoff points between distortion and perception at the decoder side based on the sampling method.
ConGeo: Robust Cross-view Geo-localization across Ground View Variations
Mar 20, 2024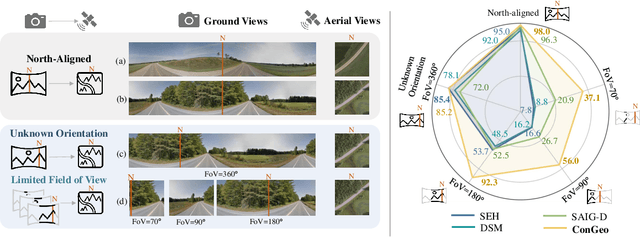

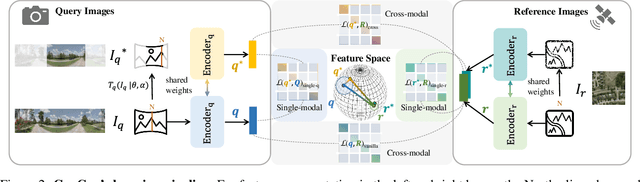
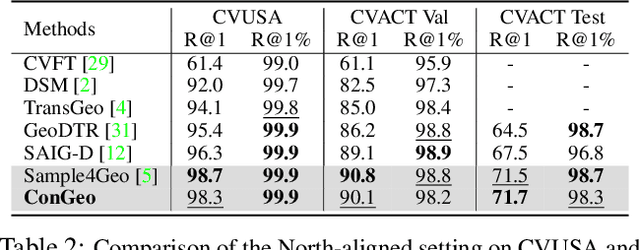
Cross-view geo-localization aims at localizing a ground-level query image by matching it to its corresponding geo-referenced aerial view. In real-world scenarios, the task requires accommodating diverse ground images captured by users with varying orientations and reduced field of views (FoVs). However, existing learning pipelines are orientation-specific or FoV-specific, demanding separate model training for different ground view variations. Such models heavily depend on the North-aligned spatial correspondence and predefined FoVs in the training data, compromising their robustness across different settings. To tackle this challenge, we propose ConGeo, a single- and cross-modal Contrastive method for Geo-localization: it enhances robustness and consistency in feature representations to improve a model's invariance to orientation and its resilience to FoV variations, by enforcing proximity between ground view variations of the same location. As a generic learning objective for cross-view geo-localization, when integrated into state-of-the-art pipelines, ConGeo significantly boosts the performance of three base models on four geo-localization benchmarks for diverse ground view variations and outperforms competing methods that train separate models for each ground view variation.
SPTNet: An Efficient Alternative Framework for Generalized Category Discovery with Spatial Prompt Tuning
Mar 20, 2024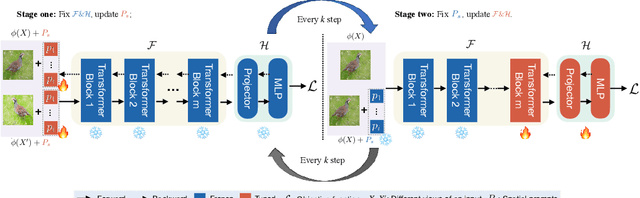
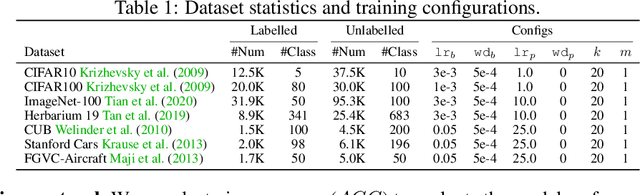
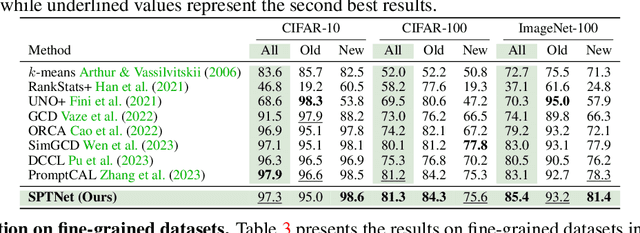
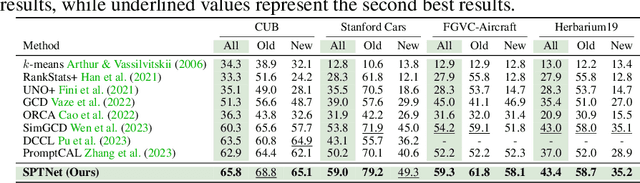
Generalized Category Discovery (GCD) aims to classify unlabelled images from both `seen' and `unseen' classes by transferring knowledge from a set of labelled `seen' class images. A key theme in existing GCD approaches is adapting large-scale pre-trained models for the GCD task. An alternate perspective, however, is to adapt the data representation itself for better alignment with the pre-trained model. As such, in this paper, we introduce a two-stage adaptation approach termed SPTNet, which iteratively optimizes model parameters (i.e., model-finetuning) and data parameters (i.e., prompt learning). Furthermore, we propose a novel spatial prompt tuning method (SPT) which considers the spatial property of image data, enabling the method to better focus on object parts, which can transfer between seen and unseen classes. We thoroughly evaluate our SPTNet on standard benchmarks and demonstrate that our method outperforms existing GCD methods. Notably, we find our method achieves an average accuracy of 61.4% on the SSB, surpassing prior state-of-the-art methods by approximately 10%. The improvement is particularly remarkable as our method yields extra parameters amounting to only 0.117% of those in the backbone architecture. Project page: https://visual-ai.github.io/sptnet.