 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Few-shot Medical Image Segmentation with Cycle-resemblance Attention
Dec 07, 2022
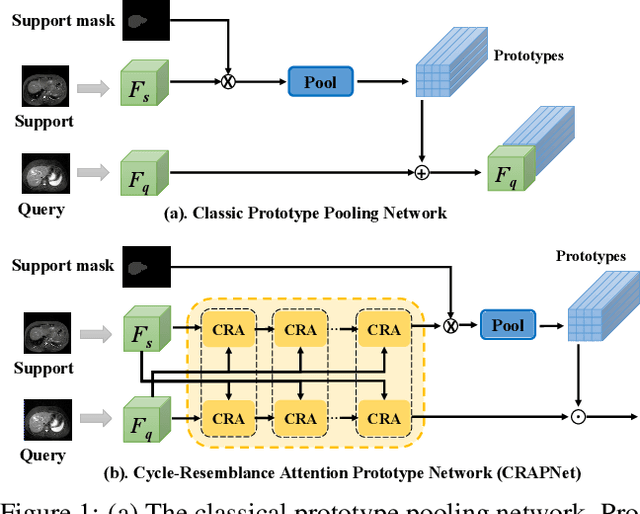
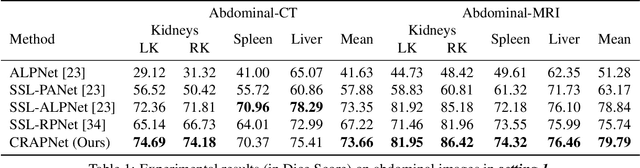
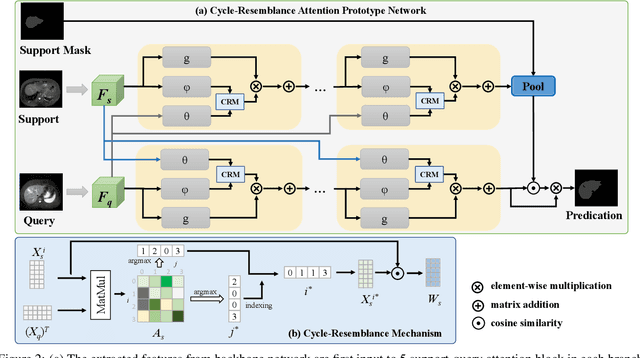

Recently, due to the increasing requirements of medical imaging applications and the professional requirements of annotating medical images, few-shot learning has gained increasing attention in the medical image semantic segmentation field. To perform segmentation with limited number of labeled medical images, most existing studies use Proto-typical Networks (PN) and have obtained compelling success. However, these approaches overlook the query image features extracted from the proposed representation network, failing to preserving the spatial connection between query and support images. In this paper, we propose a novel self-supervised few-shot medical image segmentation network and introduce a novel Cycle-Resemblance Attention (CRA) module to fully leverage the pixel-wise relation between query and support medical images. Notably, we first line up multiple attention blocks to refine more abundant relation information. Then, we present CRAPNet by integrating the CRA module with a classic prototype network, where pixel-wise relations between query and support features are well recaptured for segmentation. Extensive experiments on two different medical image datasets, e.g., abdomen MRI and abdomen CT, demonstrate the superiority of our model over existing state-of-the-art methods.
Information Extraction from Documents: Question Answering vs Token Classification in real-world setups
Apr 21, 2023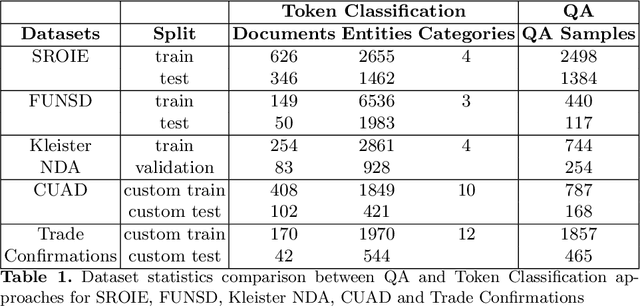
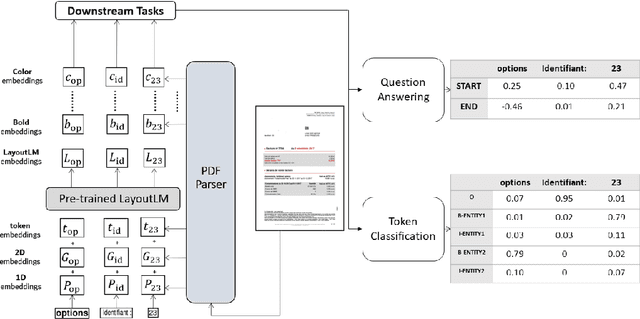
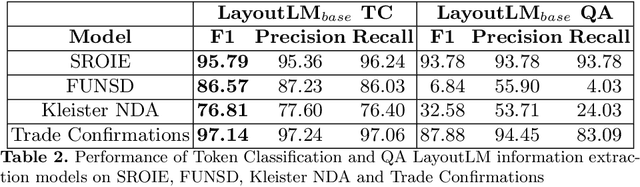
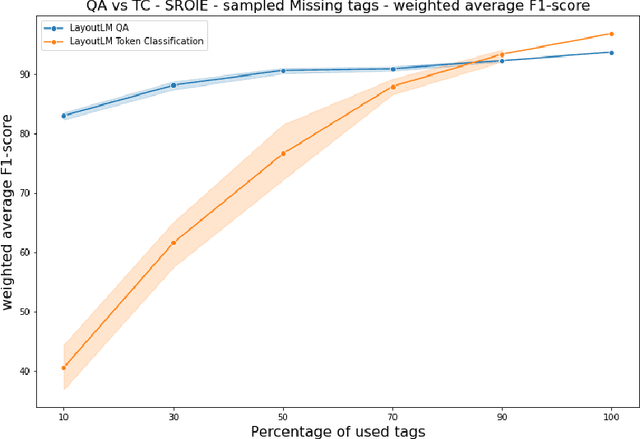
Research in Document Intelligence and especially in Document Key Information Extraction (DocKIE) has been mainly solved as Token Classification problem. Recent breakthroughs in both natural language processing (NLP) and computer vision helped building document-focused pre-training methods, leveraging a multimodal understanding of the document text, layout and image modalities. However, these breakthroughs also led to the emergence of a new DocKIE subtask of extractive document Question Answering (DocQA), as part of the Machine Reading Comprehension (MRC) research field. In this work, we compare the Question Answering approach with the classical token classification approach for document key information extraction. We designed experiments to benchmark five different experimental setups : raw performances, robustness to noisy environment, capacity to extract long entities, fine-tuning speed on Few-Shot Learning and finally Zero-Shot Learning. Our research showed that when dealing with clean and relatively short entities, it is still best to use token classification-based approach, while the QA approach could be a good alternative for noisy environment or long entities use-cases.
FSNet: Redesign Self-Supervised MonoDepth for Full-Scale Depth Prediction for Autonomous Driving
Apr 21, 2023
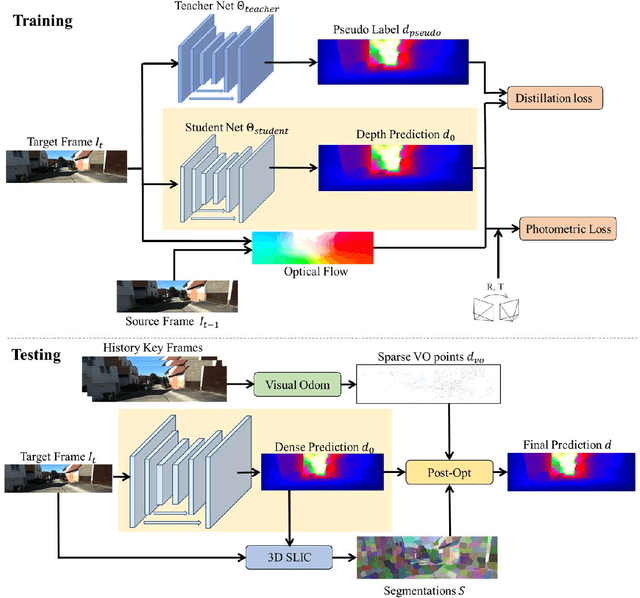


Predicting accurate depth with monocular images is important for low-cost robotic applications and autonomous driving. This study proposes a comprehensive self-supervised framework for accurate scale-aware depth prediction on autonomous driving scenes utilizing inter-frame poses obtained from inertial measurements. In particular, we introduce a Full-Scale depth prediction network named FSNet. FSNet contains four important improvements over existing self-supervised models: (1) a multichannel output representation for stable training of depth prediction in driving scenarios, (2) an optical-flow-based mask designed for dynamic object removal, (3) a self-distillation training strategy to augment the training process, and (4) an optimization-based post-processing algorithm in test time, fusing the results from visual odometry. With this framework, robots and vehicles with only one well-calibrated camera can collect sequences of training image frames and camera poses, and infer accurate 3D depths of the environment without extra labeling work or 3D data. Extensive experiments on the KITTI dataset, KITTI-360 dataset and the nuScenes dataset demonstrate the potential of FSNet. More visualizations are presented in \url{https://sites.google.com/view/fsnet/home}
DLGSANet: Lightweight Dynamic Local and Global Self-Attention Networks for Image Super-Resolution
Jan 05, 2023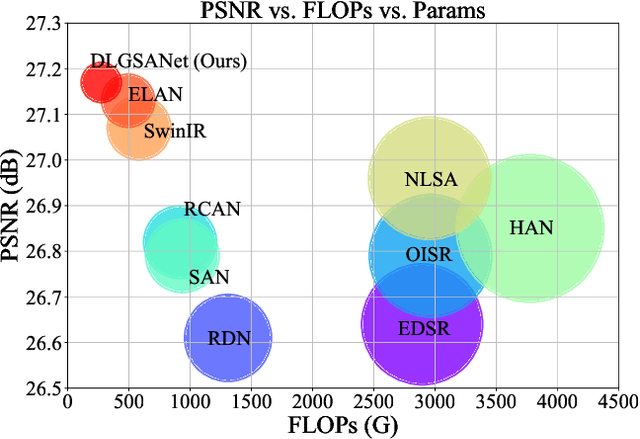
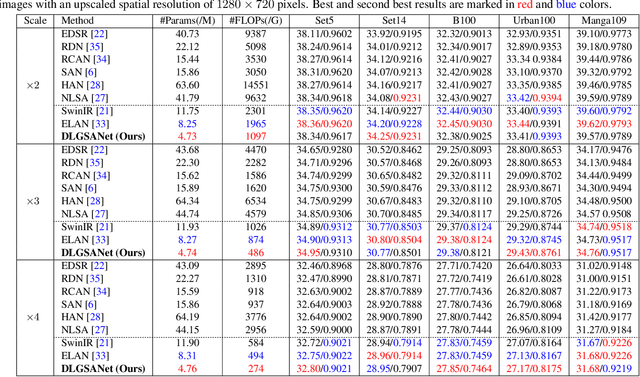
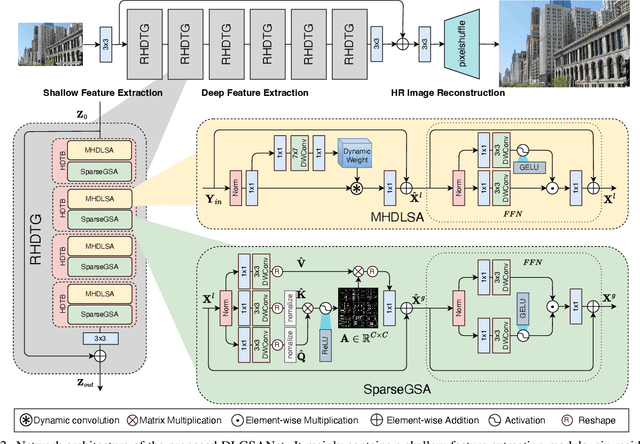
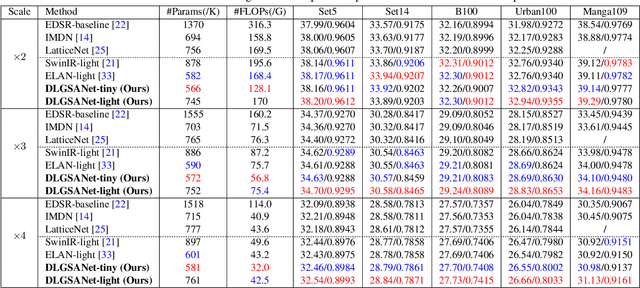
We propose an effective lightweight dynamic local and global self-attention network (DLGSANet) to solve image super-resolution. Our method explores the properties of Transformers while having low computational costs. Motivated by the network designs of Transformers, we develop a simple yet effective multi-head dynamic local self-attention (MHDLSA) module to extract local features efficiently. In addition, we note that existing Transformers usually explore all similarities of the tokens between the queries and keys for the feature aggregation. However, not all the tokens from the queries are relevant to those in keys, using all the similarities does not effectively facilitate the high-resolution image reconstruction. To overcome this problem, we develop a sparse global self-attention (SparseGSA) module to select the most useful similarity values so that the most useful global features can be better utilized for the high-resolution image reconstruction. We develop a hybrid dynamic-Transformer block(HDTB) that integrates the MHDLSA and SparseGSA for both local and global feature exploration. To ease the network training, we formulate the HDTBs into a residual hybrid dynamic-Transformer group (RHDTG). By embedding the RHDTGs into an end-to-end trainable network, we show that our proposed method has fewer network parameters and lower computational costs while achieving competitive performance against state-of-the-art ones in terms of accuracy. More information is available at https://neonleexiang.github.io/DLGSANet/
A Simple Zero-shot Prompt Weighting Technique to Improve Prompt Ensembling in Text-Image Models
Feb 13, 2023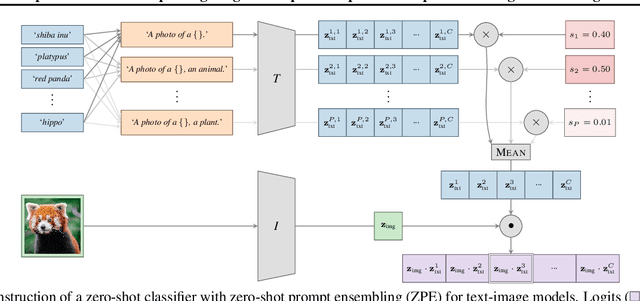
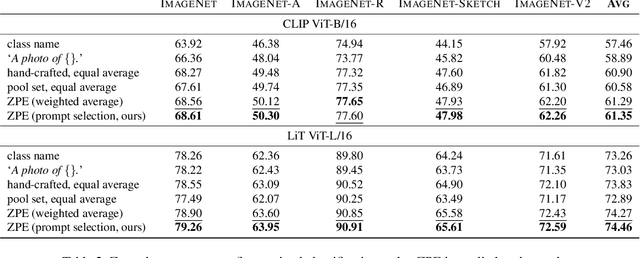

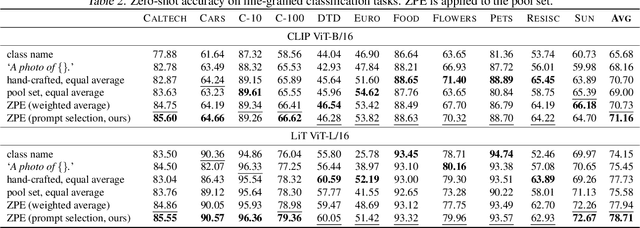
Contrastively trained text-image models have the remarkable ability to perform zero-shot classification, that is, classifying previously unseen images into categories that the model has never been explicitly trained to identify. However, these zero-shot classifiers need prompt engineering to achieve high accuracy. Prompt engineering typically requires hand-crafting a set of prompts for individual downstream tasks. In this work, we aim to automate this prompt engineering and improve zero-shot accuracy through prompt ensembling. In particular, we ask "Given a large pool of prompts, can we automatically score the prompts and ensemble those that are most suitable for a particular downstream dataset, without needing access to labeled validation data?". We demonstrate that this is possible. In doing so, we identify several pathologies in a naive prompt scoring method where the score can be easily overconfident due to biases in pre-training and test data, and we propose a novel prompt scoring method that corrects for the biases. Using our proposed scoring method to create a weighted average prompt ensemble, our method outperforms equal average ensemble, as well as hand-crafted prompts, on ImageNet, 4 of its variants, and 11 fine-grained classification benchmarks, all while being fully automatic, optimization-free, and not requiring access to labeled validation data.
Construction of unbiased dental template and parametric dental model for precision digital dentistry
Apr 07, 2023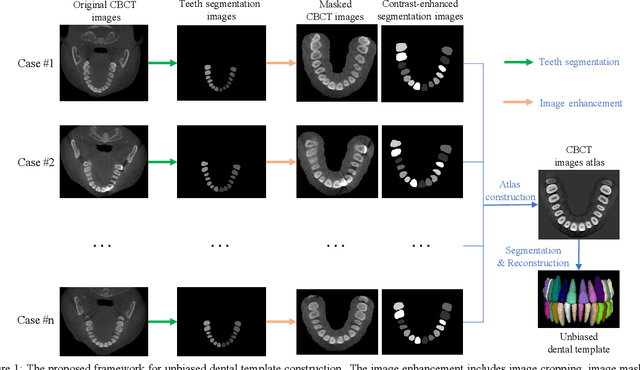
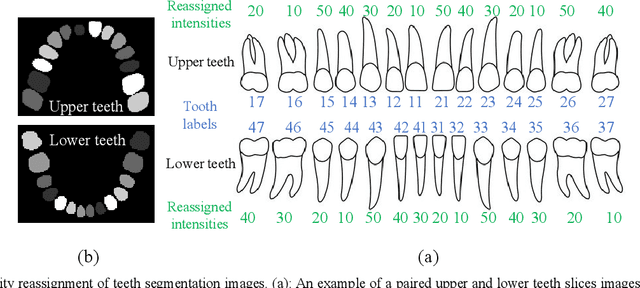
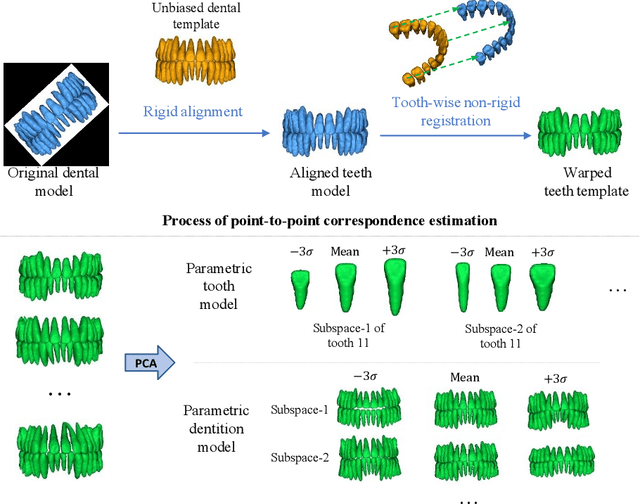
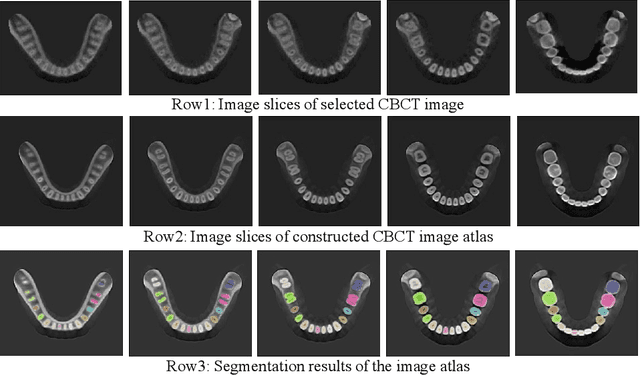
Dental template and parametric dental models are important tools for various applications in digital dentistry. However, constructing an unbiased dental template and accurate parametric dental models remains a challenging task due to the complex anatomical and morphological dental structures and also low volume ratio of the teeth. In this study, we develop an unbiased dental template by constructing an accurate dental atlas from CBCT images with guidance of teeth segmentation. First, to address the challenges, we propose to enhance the CBCT images and their segmentation images, including image cropping, image masking and segmentation intensity reassigning. Then, we further use the segmentation images to perform co-registration with the CBCT images to generate an accurate dental atlas, from which an unbiased dental template can be generated. By leveraging the unbiased dental template, we construct parametric dental models by estimating point-to-point correspondences between the dental models and employing Principal Component Analysis to determine shape subspaces of the parametric dental models. A total of 159 CBCT images of real subjects are collected to perform the constructions. Experimental results demonstrate effectiveness of our proposed method in constructing unbiased dental template and parametric dental model. The developed dental template and parametric dental models are available at https://github.com/Marvin0724/Teeth_template.
RED-PSM: Regularization by Denoising of Partially Separable Models for Dynamic Imaging
Apr 07, 2023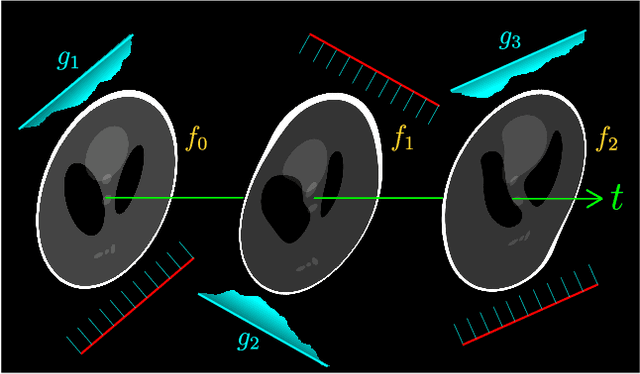
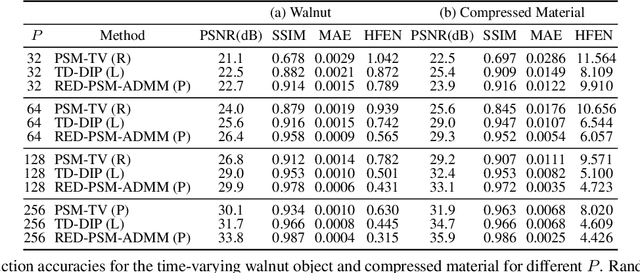
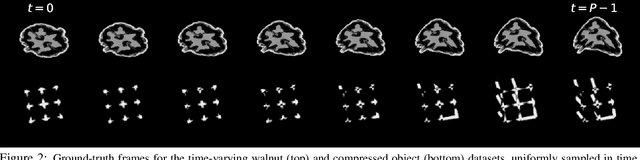
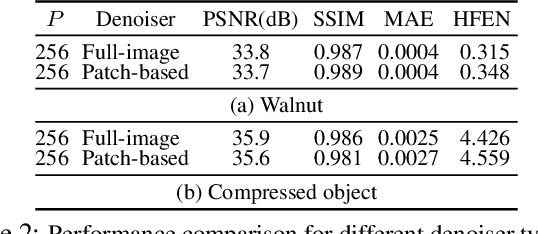
Dynamic imaging addresses the recovery of a time-varying 2D or 3D object at each time instant using its undersampled measurements. In particular, in the case of dynamic tomography, only a single projection at a single view angle may be available at a time, making the problem severely ill-posed. In this work, we propose an approach, RED-PSM, which combines for the first time two powerful techniques to address this challenging imaging problem. The first, are partially separable models, which have been used to efficiently introduce a low-rank prior for the spatio-temporal object. The second is the recent Regularization by Denoising (RED), which provides a flexible framework to exploit the impressive performance of state-of-the-art image denoising algorithms, for various inverse problems. We propose a partially separable objective with RED and an optimization scheme with variable splitting and ADMM, and prove convergence of our objective to a value corresponding to a stationary point satisfying the first order optimality conditions. Convergence is accelerated by a particular projection-domain-based initialization. We demonstrate the performance and computational improvements of our proposed RED-PSM with a learned image denoiser by comparing it to a recent deep-prior-based method TD-DIP.
Judge, Localize, and Edit: Ensuring Visual Commonsense Morality for Text-to-Image Generation
Dec 09, 2022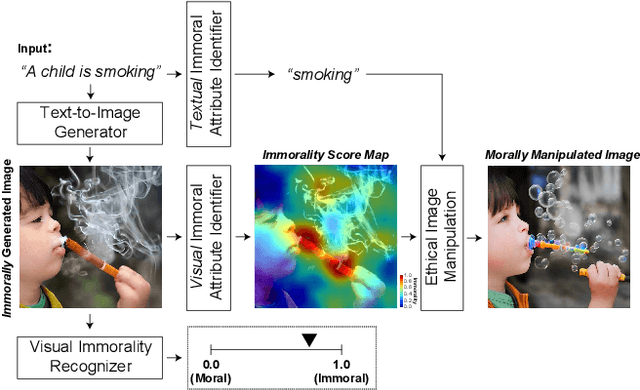

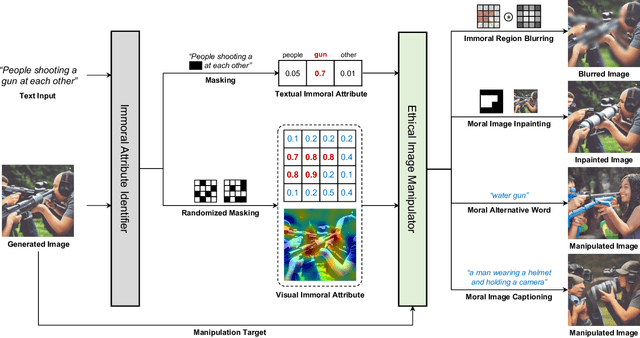
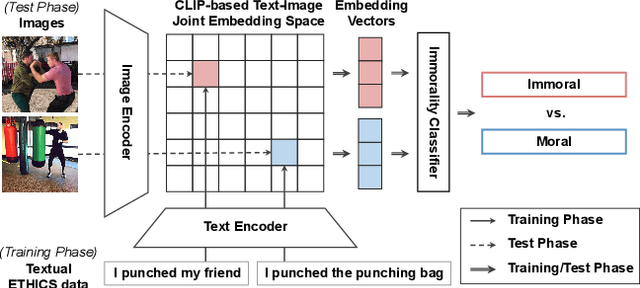
Text-to-image generation methods produce high-resolution and high-quality images, but these methods should not produce immoral images that may contain inappropriate content from the commonsense morality perspective. Conventional approaches often neglect these ethical concerns, and existing solutions are limited in avoiding immoral image generation. In this paper, we aim to automatically judge the immorality of synthesized images and manipulate these images into a moral alternative. To this end, we build a model that has the three main primitives: (1) our model recognizes the visual commonsense immorality of a given image, (2) our model localizes or highlights immoral visual (and textual) attributes that make the image immoral, and (3) our model manipulates a given immoral image into a morally-qualifying alternative. We experiment with the state-of-the-art Stable Diffusion text-to-image generation model and show the effectiveness of our ethical image manipulation. Our human study confirms that ours is indeed able to generate morally-satisfying images from immoral ones. Our implementation will be publicly available upon publication to be widely used as a new safety checker for text-to-image generation models.
ODSmoothGrad: Generating Saliency Maps for Object Detectors
Apr 15, 2023
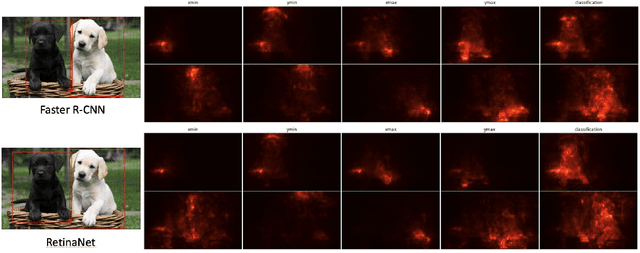
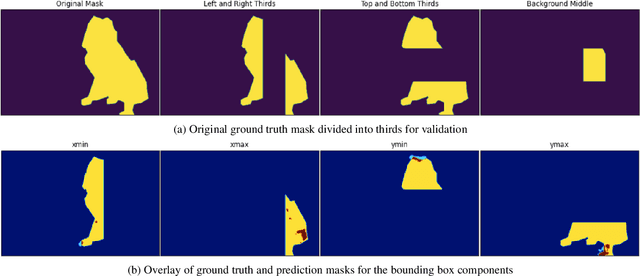
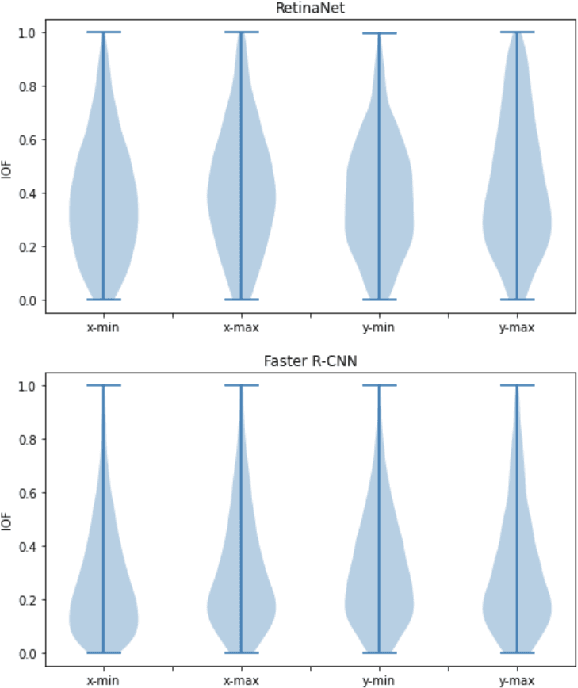
Techniques for generating saliency maps continue to be used for explainability of deep learning models, with efforts primarily applied to the image classification task. Such techniques, however, can also be applied to object detectors, not only with the classification scores, but also for the bounding box parameters, which are regressed values for which the relevant pixels contributing to these parameters can be identified. In this paper, we present ODSmoothGrad, a tool for generating saliency maps for the classification and the bounding box parameters in object detectors. Given the noisiness of saliency maps, we also apply the SmoothGrad algorithm to visually enhance the pixels of interest. We demonstrate these capabilities on one-stage and two-stage object detectors, with comparisons using classifier-based techniques.
COSST: Multi-organ Segmentation with Partially Labeled Datasets Using Comprehensive Supervisions and Self-training
Apr 28, 2023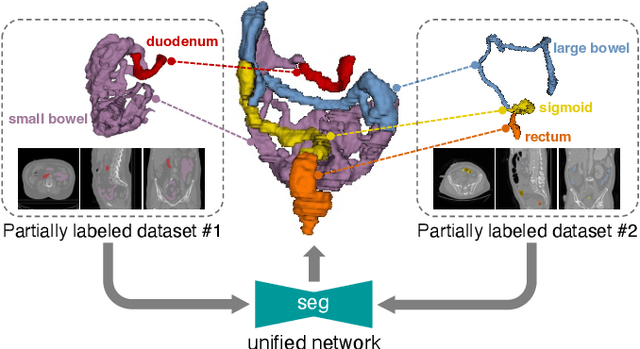
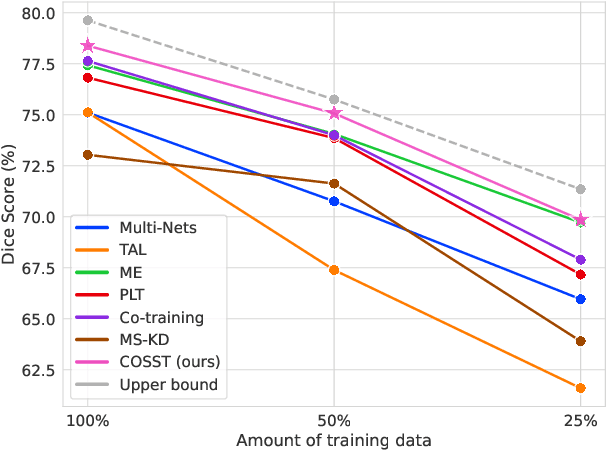
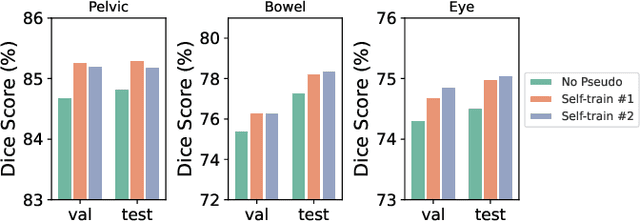
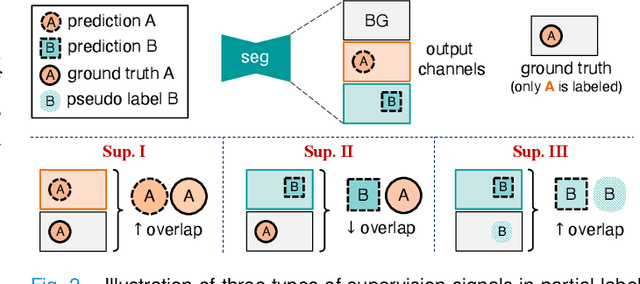
Deep learning models have demonstrated remarkable success in multi-organ segmentation but typically require large-scale datasets with all organs of interest annotated. However, medical image datasets are often low in sample size and only partially labeled, i.e., only a subset of organs are annotated. Therefore, it is crucial to investigate how to learn a unified model on the available partially labeled datasets to leverage their synergistic potential. In this paper, we empirically and systematically study the partial-label segmentation with in-depth analyses on the existing approaches and identify three distinct types of supervision signals, including two signals derived from ground truth and one from pseudo label. We propose a novel training framework termed COSST, which effectively and efficiently integrates comprehensive supervision signals with self-training. Concretely, we first train an initial unified model using two ground truth-based signals and then iteratively incorporate the pseudo label signal to the initial model using self-training. To mitigate performance degradation caused by unreliable pseudo labels, we assess the reliability of pseudo labels via outlier detection in latent space and exclude the most unreliable pseudo labels from each self-training iteration. Extensive experiments are conducted on six CT datasets for three partial-label segmentation tasks. Experimental results show that our proposed COSST achieves significant improvement over the baseline method, i.e., individual networks trained on each partially labeled dataset. Compared to the state-of-the-art partial-label segmentation methods, COSST demonstrates consistent superior performance on various segmentation tasks and with different training data size.