 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
STNet: Spatial and Temporal feature fusion network for change detection in remote sensing images
Apr 22, 2023

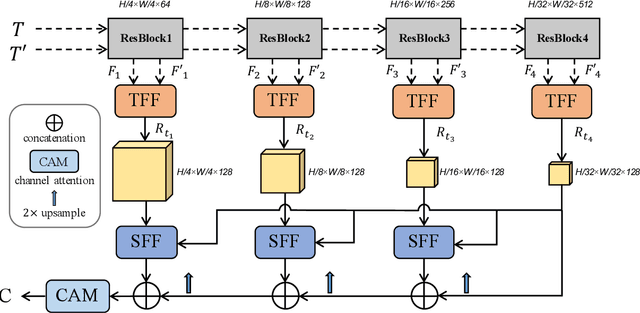
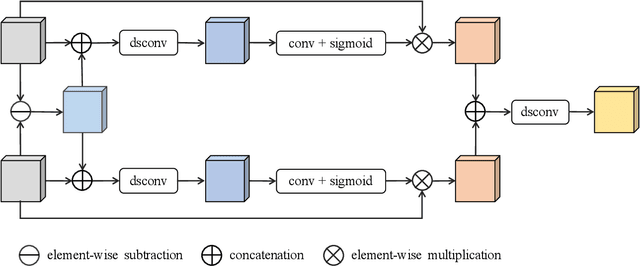
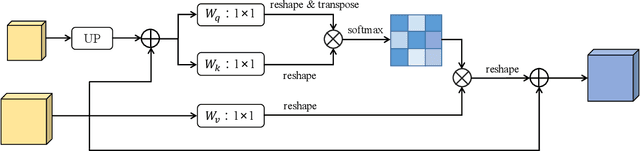
As an important task in remote sensing image analysis, remote sensing change detection (RSCD) aims to identify changes of interest in a region from spatially co-registered multi-temporal remote sensing images, so as to monitor the local development. Existing RSCD methods usually formulate RSCD as a binary classification task, representing changes of interest by merely feature concatenation or feature subtraction and recovering the spatial details via densely connected change representations, whose performances need further improvement. In this paper, we propose STNet, a RSCD network based on spatial and temporal feature fusions. Specifically, we design a temporal feature fusion (TFF) module to combine bi-temporal features using a cross-temporal gating mechanism for emphasizing changes of interest; a spatial feature fusion module is deployed to capture fine-grained information using a cross-scale attention mechanism for recovering the spatial details of change representations. Experimental results on three benchmark datasets for RSCD demonstrate that the proposed method achieves the state-of-the-art performance. Code is available at https://github.com/xwmaxwma/rschange.
An Image captioning algorithm based on the Hybrid Deep Learning Technique (CNN+GRU)
Jan 06, 2023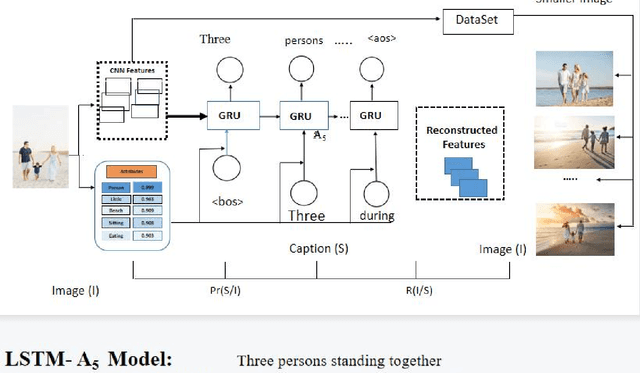
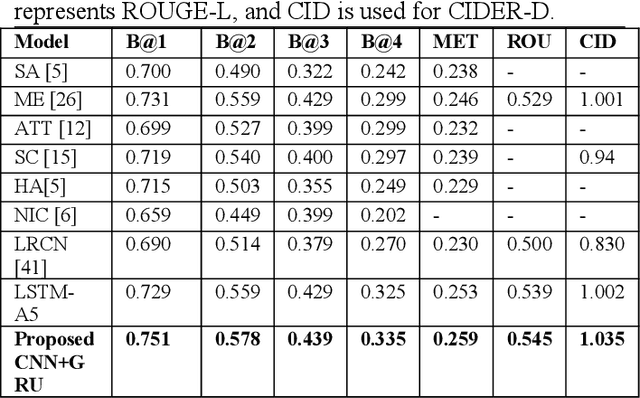
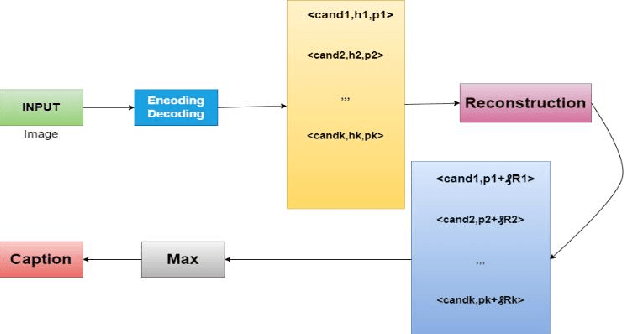
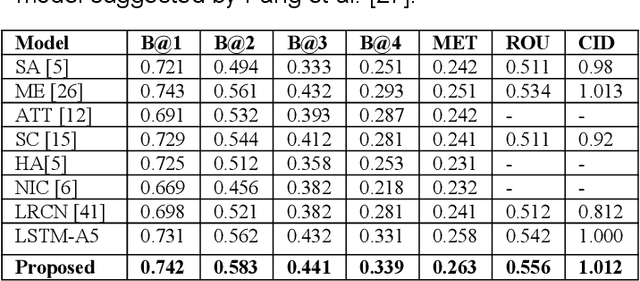
Image captioning by the encoder-decoder framework has shown tremendous advancement in the last decade where CNN is mainly used as encoder and LSTM is used as a decoder. Despite such an impressive achievement in terms of accuracy in simple images, it lacks in terms of time complexity and space complexity efficiency. In addition to this, in case of complex images with a lot of information and objects, the performance of this CNN-LSTM pair downgraded exponentially due to the lack of semantic understanding of the scenes presented in the images. Thus, to take these issues into consideration, we present CNN-GRU encoder decode framework for caption-to-image reconstructor to handle the semantic context into consideration as well as the time complexity. By taking the hidden states of the decoder into consideration, the input image and its similar semantic representations is reconstructed and reconstruction scores from a semantic reconstructor are used in conjunction with likelihood during model training to assess the quality of the generated caption. As a result, the decoder receives improved semantic information, enhancing the caption production process. During model testing, combining the reconstruction score and the log-likelihood is also feasible to choose the most appropriate caption. The suggested model outperforms the state-of-the-art LSTM-A5 model for picture captioning in terms of time complexity and accuracy.
BallGAN: 3D-aware Image Synthesis with a Spherical Background
Jan 22, 2023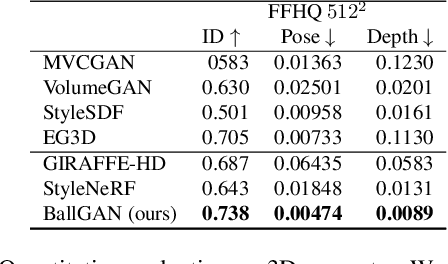

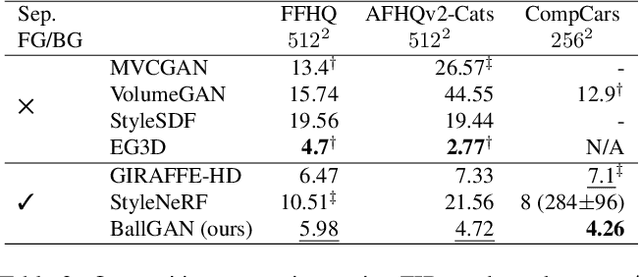
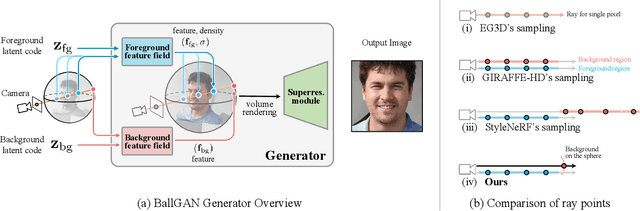
3D-aware GANs aim to synthesize realistic 3D scenes such that they can be rendered in arbitrary perspectives to produce images. Although previous methods produce realistic images, they suffer from unstable training or degenerate solutions where the 3D geometry is unnatural. We hypothesize that the 3D geometry is underdetermined due to the insufficient constraint, i.e., being classified as real image to the discriminator is not enough. To solve this problem, we propose to approximate the background as a spherical surface and represent a scene as a union of the foreground placed in the sphere and the thin spherical background. It reduces the degree of freedom in the background field. Accordingly, we modify the volume rendering equation and incorporate dedicated constraints to design a novel 3D-aware GAN framework named BallGAN. BallGAN has multiple advantages as follows. 1) It produces more reasonable 3D geometry; the images of a scene across different viewpoints have better photometric consistency and fidelity than the state-of-the-art methods. 2) The training becomes much more stable. 3) The foreground can be separately rendered on top of different arbitrary backgrounds.
Role of Transients in Two-Bounce Non-Line-of-Sight Imaging
Apr 03, 2023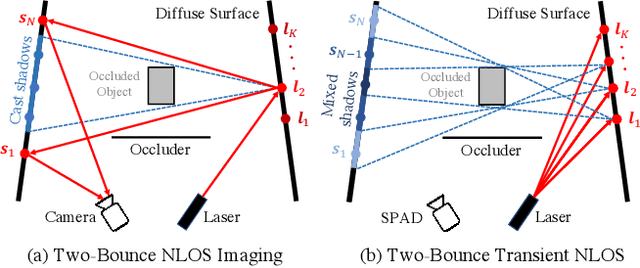
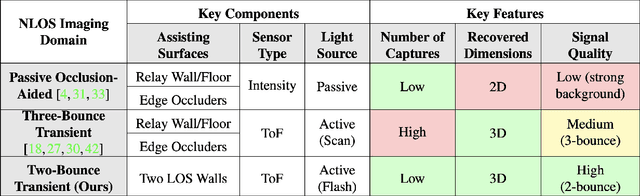
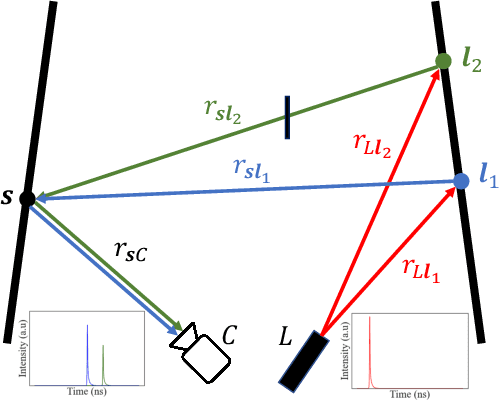
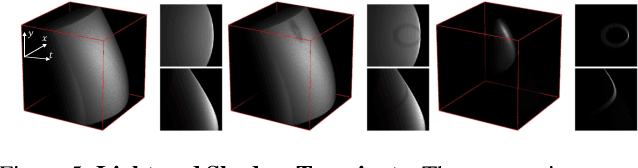
The goal of non-line-of-sight (NLOS) imaging is to image objects occluded from the camera's field of view using multiply scattered light. Recent works have demonstrated the feasibility of two-bounce (2B) NLOS imaging by scanning a laser and measuring cast shadows of occluded objects in scenes with two relay surfaces. In this work, we study the role of time-of-flight (ToF) measurements, \ie transients, in 2B-NLOS under multiplexed illumination. Specifically, we study how ToF information can reduce the number of measurements and spatial resolution needed for shape reconstruction. We present our findings with respect to tradeoffs in (1) temporal resolution, (2) spatial resolution, and (3) number of image captures by studying SNR and recoverability as functions of system parameters. This leads to a formal definition of the mathematical constraints for 2B lidar. We believe that our work lays an analytical groundwork for design of future NLOS imaging systems, especially as ToF sensors become increasingly ubiquitous.
Towards Realistic Ultrasound Fetal Brain Imaging Synthesis
Apr 08, 2023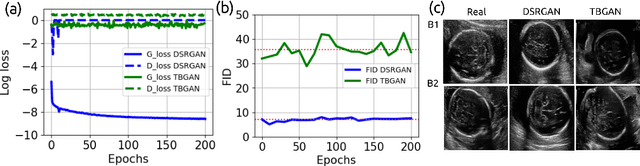
Prenatal ultrasound imaging is the first-choice modality to assess fetal health. Medical image datasets for AI and ML methods must be diverse (i.e. diagnoses, diseases, pathologies, scanners, demographics, etc), however there are few public ultrasound fetal imaging datasets due to insufficient amounts of clinical data, patient privacy, rare occurrence of abnormalities in general practice, and limited experts for data collection and validation. To address such data scarcity, we proposed generative adversarial networks (GAN)-based models, diffusion-super-resolution-GAN and transformer-based-GAN, to synthesise images of fetal ultrasound brain planes from one public dataset. We reported that GAN-based methods can generate 256x256 pixel size of fetal ultrasound trans-cerebellum brain image plane with stable training losses, resulting in lower FID values for diffusion-super-resolution-GAN (average 7.04 and lower FID 5.09 at epoch 10) than the FID values of transformer-based-GAN (average 36.02 and lower 28.93 at epoch 60). The results of this work illustrate the potential of GAN-based methods to synthesise realistic high-resolution ultrasound images, leading to future work with other fetal brain planes, anatomies, devices and the need of a pool of experts to evaluate synthesised images. Code, data and other resources to reproduce this work are available at \url{https://github.com/budai4medtech/midl2023}.
Spectrum-inspired Low-light Image Translation for Saliency Detection
Mar 17, 2023
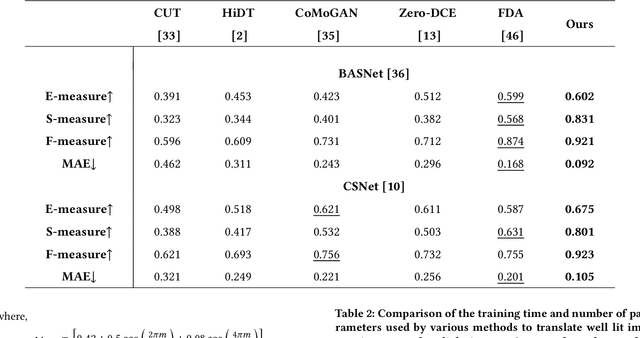
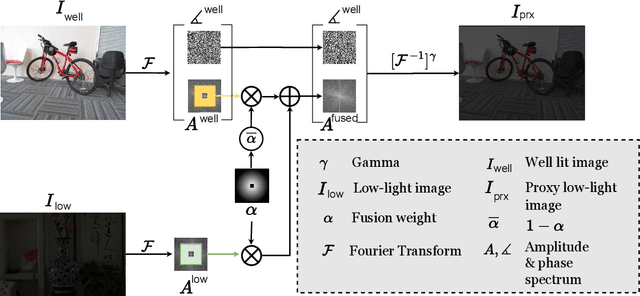

Saliency detection methods are central to several real-world applications such as robot navigation and satellite imagery. However, the performance of existing methods deteriorate under low-light conditions because training datasets mostly comprise of well-lit images. One possible solution is to collect a new dataset for low-light conditions. This involves pixel-level annotations, which is not only tedious and time-consuming but also infeasible if a huge training corpus is required. We propose a technique that performs classical band-pass filtering in the Fourier space to transform well-lit images to low-light images and use them as a proxy for real low-light images. Unlike popular deep learning approaches which require learning thousands of parameters and enormous amounts of training data, the proposed transformation is fast and simple and easy to extend to other tasks such as low-light depth estimation. Our experiments show that the state-of-the-art saliency detection and depth estimation networks trained on our proxy low-light images perform significantly better on real low-light images than networks trained using existing strategies.
Ensuring Trustworthy Medical Artificial Intelligence through Ethical and Philosophical Principles
Apr 29, 2023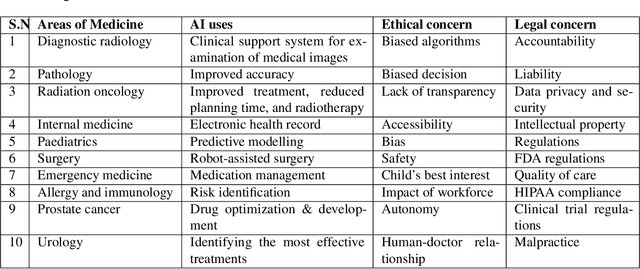
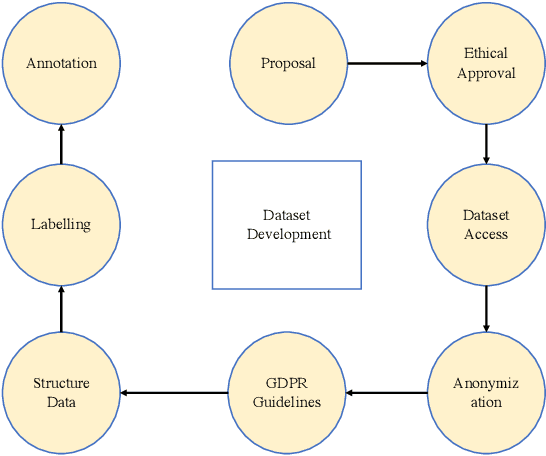

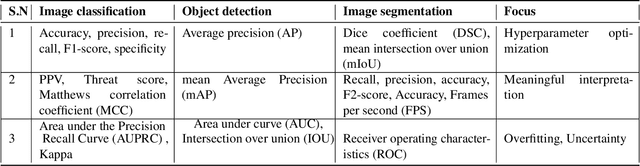
Artificial intelligence (AI) methods have great potential to revolutionize numerous medical care by enhancing the experience of medical experts and patients. AI based computer-assisted diagnosis tools can have a tremendous benefit if they can outperform or perform similarly to the level of a clinical expert. As a result, advanced healthcare services can be affordable in developing nations, and the problem of a lack of expert medical practitioners can be addressed. AI based tools can save time, resources, and overall cost for patient treatment. Furthermore, in contrast to humans, AI can uncover complex relations in the data from a large set of inputs and even lead to new evidence-based knowledge in medicine. However, integrating AI in healthcare raises several ethical and philosophical concerns, such as bias, transparency, autonomy, responsibility and accountability, which must be addressed before integrating such tools into clinical settings. In this article, we emphasize recent advances in AI-assisted medical image analysis, existing standards, and the significance of comprehending ethical issues and best practices for the applications of AI in clinical settings. We cover the technical and ethical challenges of AI and the implications of deploying AI in hospitals and public organizations. We also discuss promising key measures and techniques to address the ethical challenges, data scarcity, racial bias, lack of transparency, and algorithmic bias. Finally, we provide our recommendation and future directions for addressing the ethical challenges associated with AI in healthcare applications, with the goal of deploying AI into the clinical settings to make the workflow more efficient, accurate, accessible, transparent, and reliable for the patient worldwide.
Real-Time Superficial Vein Imaging System for Observing Abnormalities on Vascular Structures
Apr 29, 2023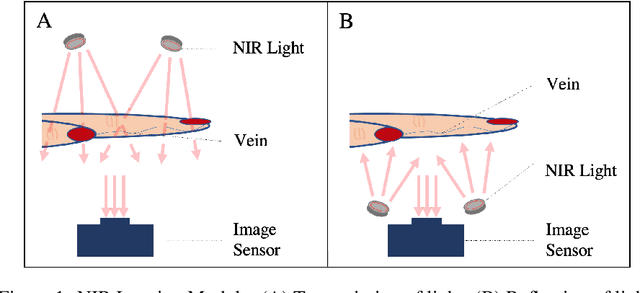
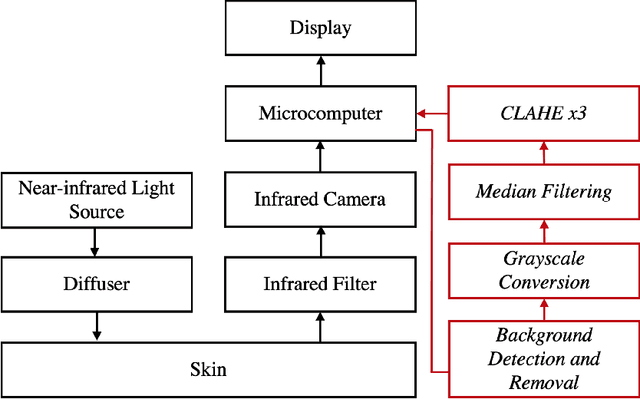

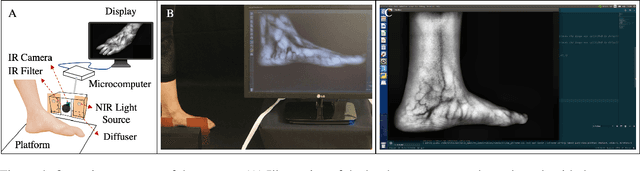
Circulatory system abnormalities might be an indicator of diseases or tissue damage. Early detection of vascular abnormalities might have an important role during treatment and also raise the patient's awarenes. Current detection methods for vascular imaging are high-cost, invasive, and mostly radiation-based. In this study, a low-cost and portable microcomputer-based tool has been developed as a near-infrared (NIR) superficial vascular imaging device. The device uses NIR light-emitting diode (LED) light at 850 nm along with other electronic and optical components. It operates as a non-contact and safe infrared (IR) imaging method in real-time. Image and video analysis are carried out using OpenCV (Open-Source Computer Vision), a library of programming functions mainly used in computer vision. Various tests were carried out to optimize the imaging system and set up a suitable external environment. To test the performance of the device, the images taken from three diabetic volunteers, who are expected to have abnormalities in the vascular structure due to the possibility of deformation caused by high glucose levels in the blood, were compared with the images taken from two non-diabetic volunteers. As a result, tortuosity was observed successfully in the superficial vascular structures, where the results need to be interpreted by the medical experts in the field to understand the underlying reasons. Although this study is an engineering study and does not have an intention to diagnose any diseases, the developed system here might assist healthcare personnel in early diagnosis and treatment follow-up for vascular structures and may enable further opportunities.
Learning Single Image Defocus Deblurring with Misaligned Training Pairs
Nov 29, 2022
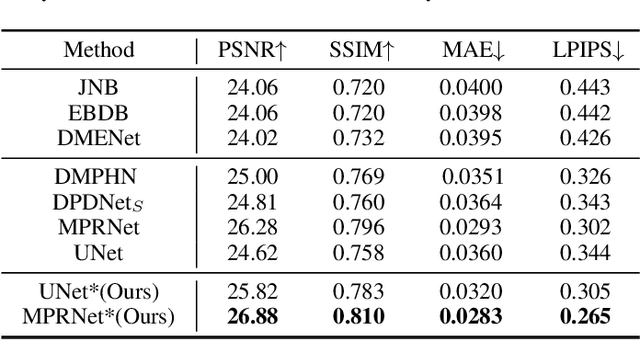
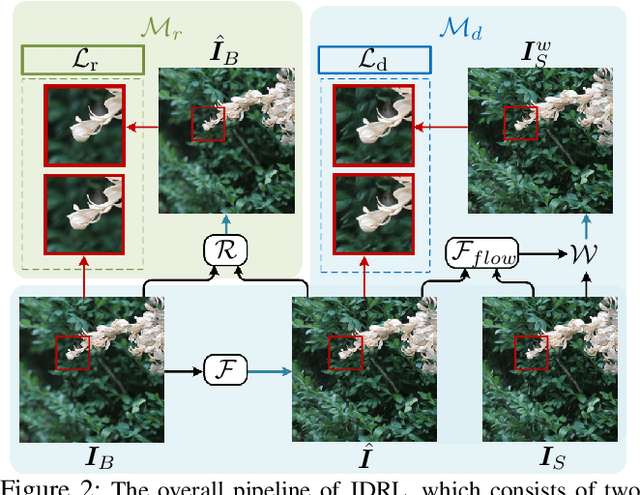
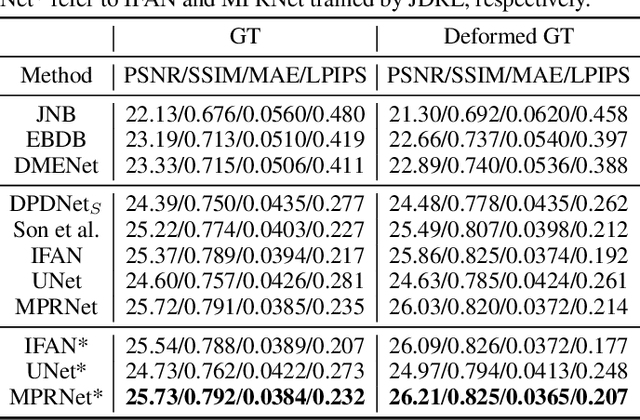
By adopting popular pixel-wise loss, existing methods for defocus deblurring heavily rely on well aligned training image pairs. Although training pairs of ground-truth and blurry images are carefully collected, e.g., DPDD dataset, misalignment is inevitable between training pairs, making existing methods possibly suffer from deformation artifacts. In this paper, we propose a joint deblurring and reblurring learning (JDRL) framework for single image defocus deblurring with misaligned training pairs. Generally, JDRL consists of a deblurring module and a spatially invariant reblurring module, by which deblurred result can be adaptively supervised by ground-truth image to recover sharp textures while maintaining spatial consistency with the blurry image. First, in the deblurring module, a bi-directional optical flow-based deformation is introduced to tolerate spatial misalignment between deblurred and ground-truth images. Second, in the reblurring module, deblurred result is reblurred to be spatially aligned with blurry image, by predicting a set of isotropic blur kernels and weighting maps. Moreover, we establish a new single image defocus deblurring (SDD) dataset, further validating our JDRL and also benefiting future research. Our JDRL can be applied to boost defocus deblurring networks in terms of both quantitative metrics and visual quality on DPDD, RealDOF and our SDD datasets.
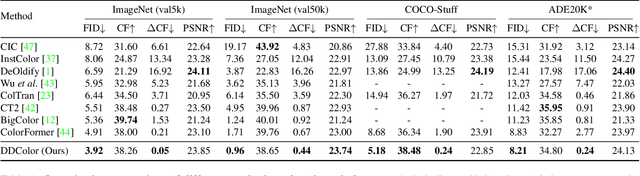
DDColor: Towards Photo-Realistic and Semantic-Aware Image Colorization via Dual Decoders
Dec 23, 2022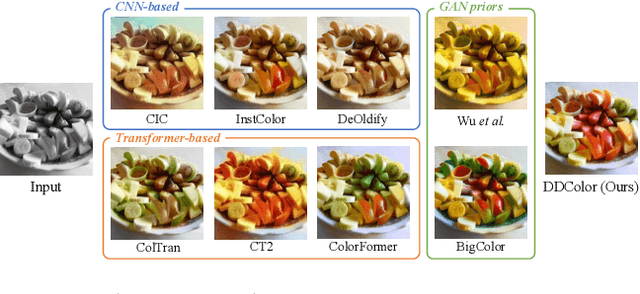
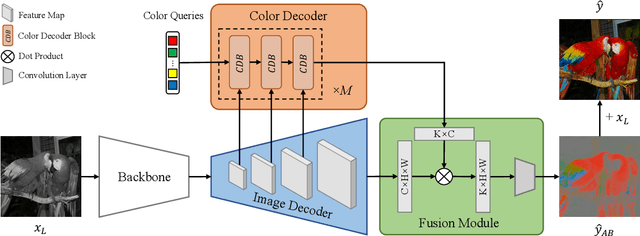

Automatic image colorization is a particularly challenging problem. Due to the high illness of the problem and multi-modal uncertainty, directly training a deep neural network usually leads to incorrect semantic colors and low color richness. Existing transformer-based methods can deliver better results but highly depend on hand-crafted dataset-level empirical distribution priors. In this work, we propose DDColor, a new end-to-end method with dual decoders, for image colorization. More specifically, we design a multi-scale image decoder and a transformer-based color decoder. The former manages to restore the spatial resolution of the image, while the latter establishes the correlation between semantic representations and color queries via cross-attention. The two decoders incorporate to learn semantic-aware color embedding by leveraging the multi-scale visual features. With the help of these two decoders, our method succeeds in producing semantically consistent and visually plausible colorization results without any additional priors. In addition, a simple but effective colorfulness loss is introduced to further improve the color richness of generated results. Our extensive experiments demonstrate that the proposed DDColor achieves significantly superior performance to existing state-of-the-art works both quantitatively and qualitatively. Codes will be made publicly available at https://github.com/piddnad/DDColor.