 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Text-guided Explorable Image Super-resolution
Mar 02, 2024

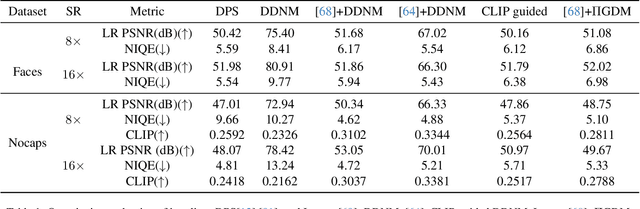

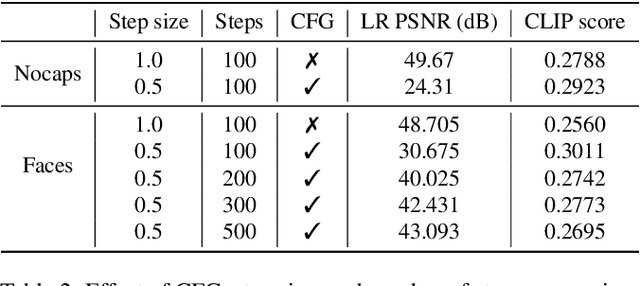
In this paper, we introduce the problem of zero-shot text-guided exploration of the solutions to open-domain image super-resolution. Our goal is to allow users to explore diverse, semantically accurate reconstructions that preserve data consistency with the low-resolution inputs for different large downsampling factors without explicitly training for these specific degradations. We propose two approaches for zero-shot text-guided super-resolution - i) modifying the generative process of text-to-image \textit{T2I} diffusion models to promote consistency with low-resolution inputs, and ii) incorporating language guidance into zero-shot diffusion-based restoration methods. We show that the proposed approaches result in diverse solutions that match the semantic meaning provided by the text prompt while preserving data consistency with the degraded inputs. We evaluate the proposed baselines for the task of extreme super-resolution and demonstrate advantages in terms of restoration quality, diversity, and explorability of solutions.
ICC: Quantifying Image Caption Concreteness for Multimodal Dataset Curation
Mar 02, 2024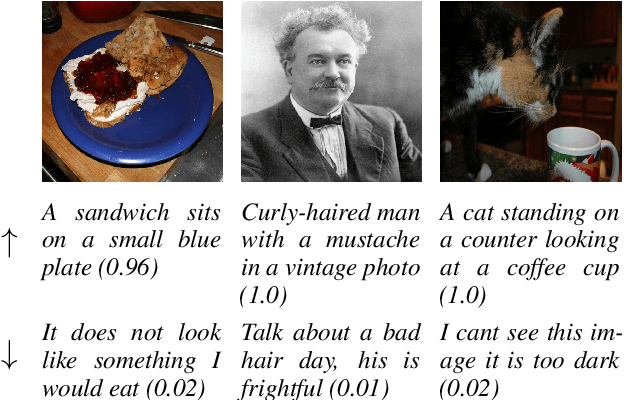
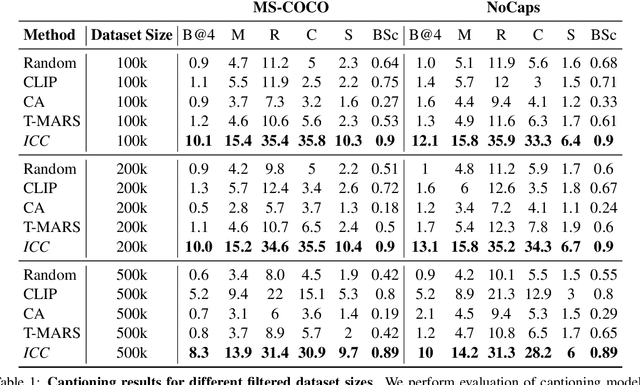

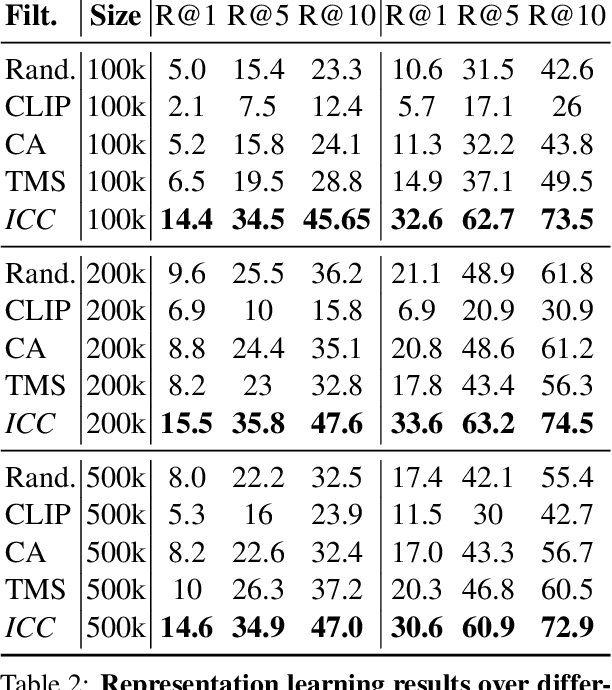
Web-scale training on paired text-image data is becoming increasingly central to multimodal learning, but is challenged by the highly noisy nature of datasets in the wild. Standard data filtering approaches succeed in removing mismatched text-image pairs, but permit semantically related but highly abstract or subjective text. These approaches lack the fine-grained ability to isolate the most concrete samples that provide the strongest signal for learning in a noisy dataset. In this work, we propose a new metric, image caption concreteness, that evaluates caption text without an image reference to measure its concreteness and relevancy for use in multimodal learning. Our approach leverages strong foundation models for measuring visual-semantic information loss in multimodal representations. We demonstrate that this strongly correlates with human evaluation of concreteness in both single-word and sentence-level texts. Moreover, we show that curation using ICC complements existing approaches: It succeeds in selecting the highest quality samples from multimodal web-scale datasets to allow for efficient training in resource-constrained settings.
Order-One Rolling Shutter Cameras
Mar 17, 2024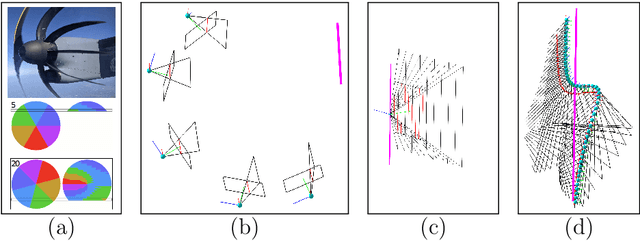
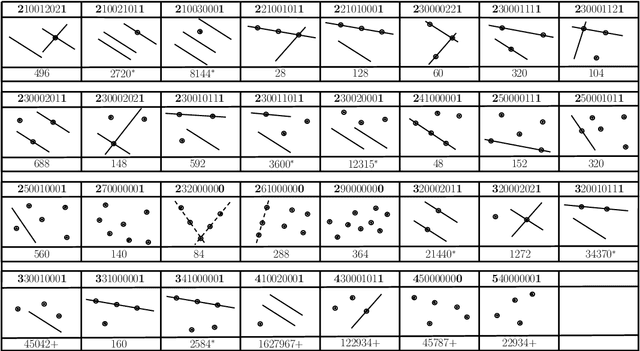
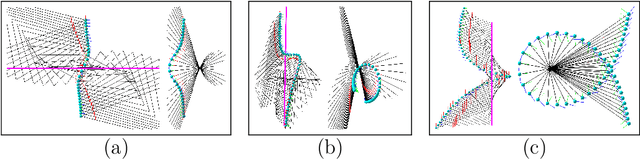
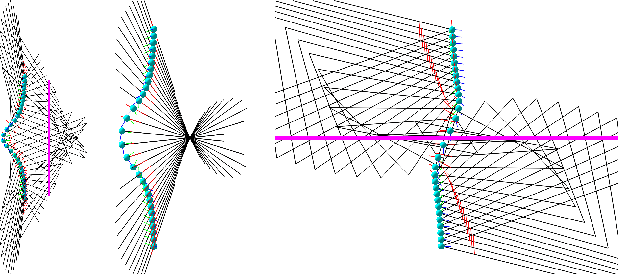
Rolling shutter (RS) cameras dominate consumer and smartphone markets. Several methods for computing the absolute pose of RS cameras have appeared in the last 20 years, but the relative pose problem has not been fully solved yet. We provide a unified theory for the important class of order-one rolling shutter (RS$_1$) cameras. These cameras generalize the perspective projection to RS cameras, projecting a generic space point to exactly one image point via a rational map. We introduce a new back-projection RS camera model, characterize RS$_1$ cameras, construct explicit parameterizations of such cameras, and determine the image of a space line. We classify all minimal problems for solving the relative camera pose problem with linear RS$_1$ cameras and discover new practical cases. Finally, we show how the theory can be used to explain RS models previously used for absolute pose computation.
LightIt: Illumination Modeling and Control for Diffusion Models
Mar 15, 2024
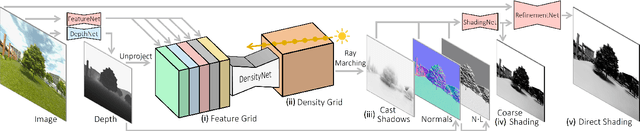

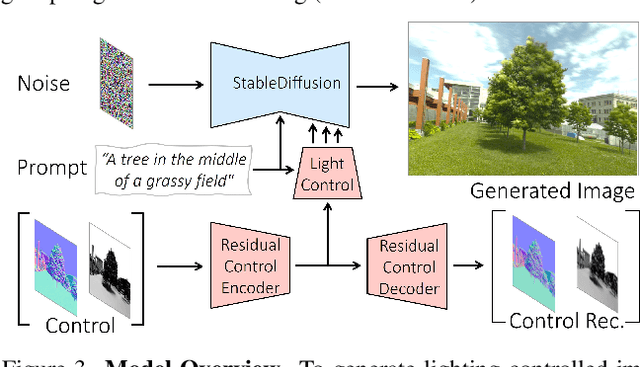
We introduce LightIt, a method for explicit illumination control for image generation. Recent generative methods lack lighting control, which is crucial to numerous artistic aspects of image generation such as setting the overall mood or cinematic appearance. To overcome these limitations, we propose to condition the generation on shading and normal maps. We model the lighting with single bounce shading, which includes cast shadows. We first train a shading estimation module to generate a dataset of real-world images and shading pairs. Then, we train a control network using the estimated shading and normals as input. Our method demonstrates high-quality image generation and lighting control in numerous scenes. Additionally, we use our generated dataset to train an identity-preserving relighting model, conditioned on an image and a target shading. Our method is the first that enables the generation of images with controllable, consistent lighting and performs on par with specialized relighting state-of-the-art methods.
Learning to Project for Cross-Task Knowledge Distillation
Mar 21, 2024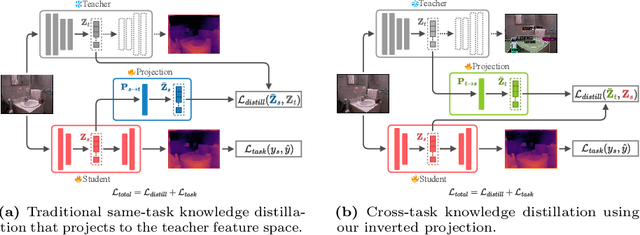
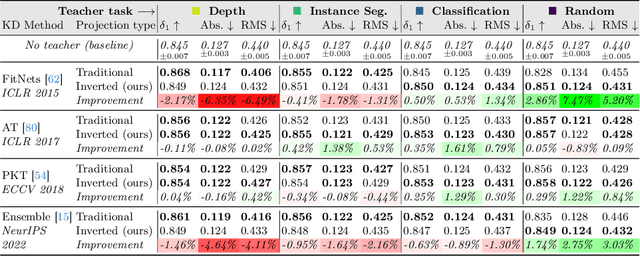
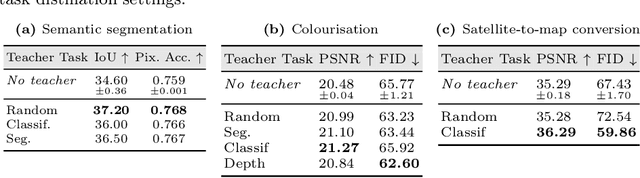
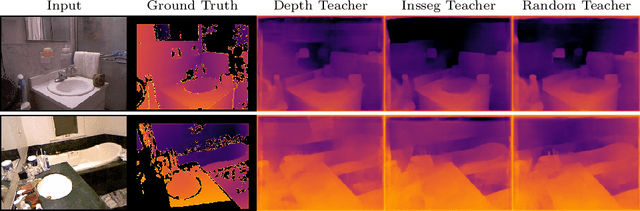
Traditional knowledge distillation (KD) relies on a proficient teacher trained on the target task, which is not always available. In this setting, cross-task distillation can be used, enabling the use of any teacher model trained on a different task. However, many KD methods prove ineffective when applied to this cross-task setting. To address this limitation, we propose a simple modification: the use of an inverted projection. We show that this drop-in replacement for a standard projector is effective by learning to disregard any task-specific features which might degrade the student's performance. We find that this simple modification is sufficient for extending many KD methods to the cross-task setting, where the teacher and student tasks can be very different. In doing so, we obtain up to a 1.9% improvement in the cross-task setting compared to the traditional projection, at no additional cost. Our method can obtain significant performance improvements (up to 7%) when using even a randomly-initialised teacher on various tasks such as depth estimation, image translation, and semantic segmentation, despite the lack of any learned knowledge to transfer. To provide conceptual and analytical insights into this result, we show that using an inverted projection allows the distillation loss to be decomposed into a knowledge transfer and a spectral regularisation component. Through this analysis we are additionally able to propose a novel regularisation loss that allows teacher-free distillation, enabling performance improvements of up to 8.57% on ImageNet with no additional training costs.
On the Concept Trustworthiness in Concept Bottleneck Models
Mar 21, 2024
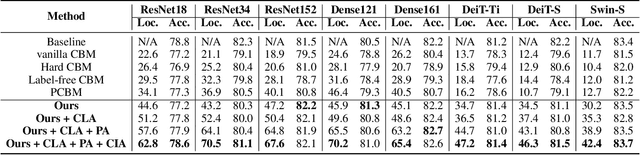
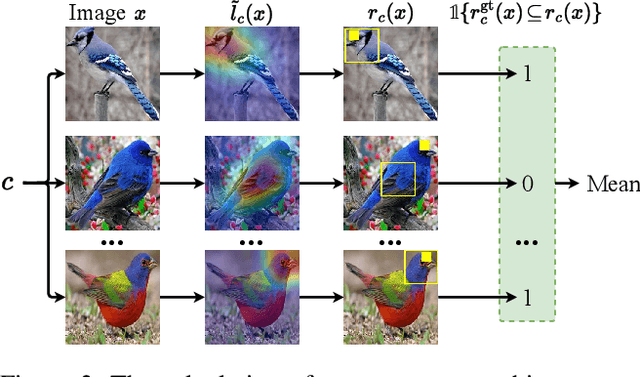

Concept Bottleneck Models (CBMs), which break down the reasoning process into the input-to-concept mapping and the concept-to-label prediction, have garnered significant attention due to their remarkable interpretability achieved by the interpretable concept bottleneck. However, despite the transparency of the concept-to-label prediction, the mapping from the input to the intermediate concept remains a black box, giving rise to concerns about the trustworthiness of the learned concepts (i.e., these concepts may be predicted based on spurious cues). The issue of concept untrustworthiness greatly hampers the interpretability of CBMs, thereby hindering their further advancement. To conduct a comprehensive analysis on this issue, in this study we establish a benchmark to assess the trustworthiness of concepts in CBMs. A pioneering metric, referred to as concept trustworthiness score, is proposed to gauge whether the concepts are derived from relevant regions. Additionally, an enhanced CBM is introduced, enabling concept predictions to be made specifically from distinct parts of the feature map, thereby facilitating the exploration of their related regions. Besides, we introduce three modules, namely the cross-layer alignment (CLA) module, the cross-image alignment (CIA) module, and the prediction alignment (PA) module, to further enhance the concept trustworthiness within the elaborated CBM. The experiments on five datasets across ten architectures demonstrate that without using any concept localization annotations during training, our model improves the concept trustworthiness by a large margin, meanwhile achieving superior accuracy to the state-of-the-arts. Our code is available at https://github.com/hqhQAQ/ProtoCBM.
Lightator: An Optical Near-Sensor Accelerator with Compressive Acquisition Enabling Versatile Image Processing
Mar 08, 2024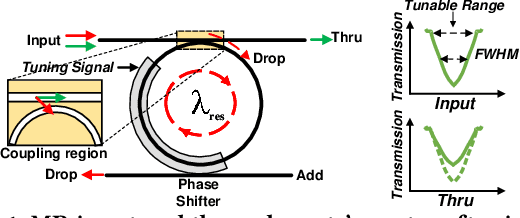
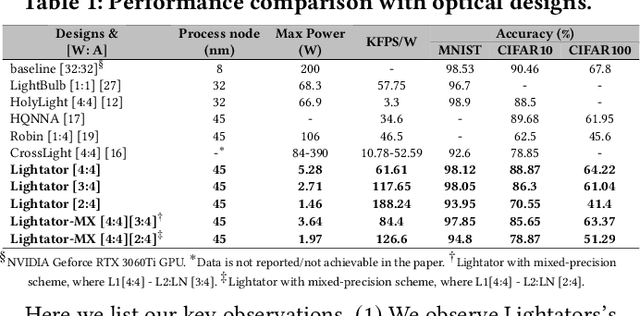
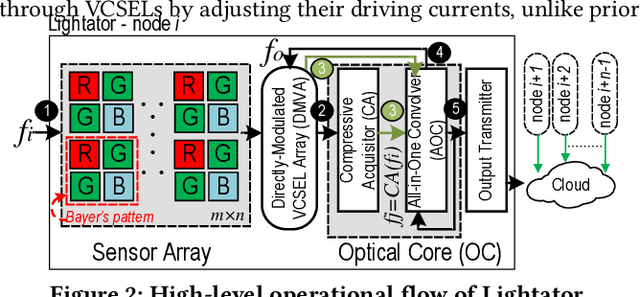
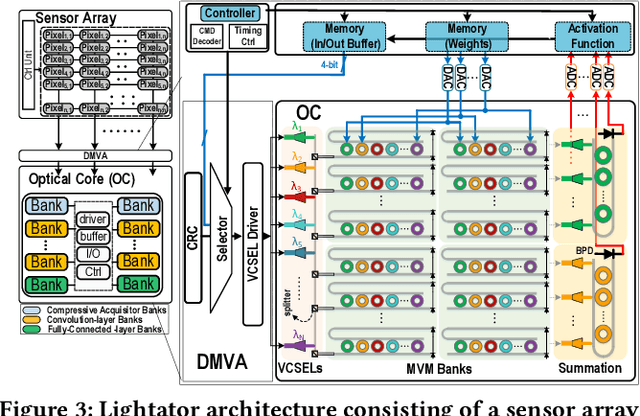
This paper proposes a high-performance and energy-efficient optical near-sensor accelerator for vision applications, called Lightator. Harnessing the promising efficiency offered by photonic devices, Lightator features innovative compressive acquisition of input frames and fine-grained convolution operations for low-power and versatile image processing at the edge for the first time. This will substantially diminish the energy consumption and latency of conversion, transmission, and processing within the established cloud-centric architecture as well as recently designed edge accelerators. Our device-to-architecture simulation results show that with favorable accuracy, Lightator achieves 84.4 Kilo FPS/W and reduces power consumption by a factor of ~24x and 73x on average compared with existing photonic accelerators and GPU baseline.
Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters
Mar 05, 2024

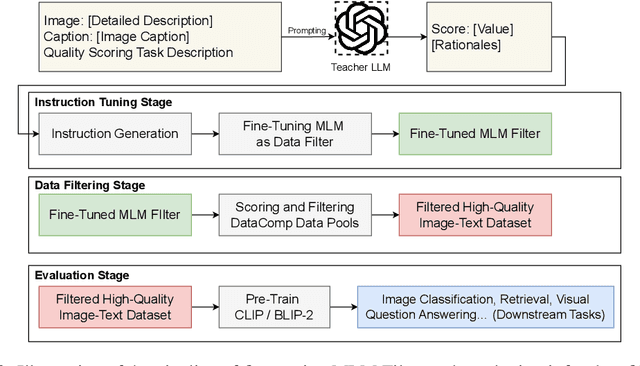
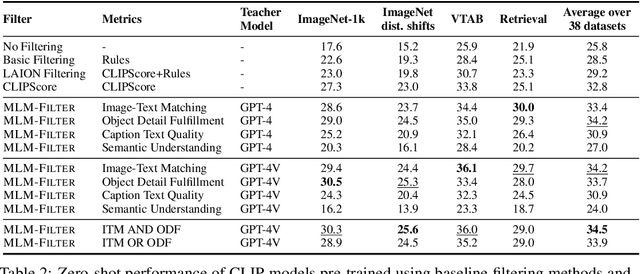
We propose a novel framework for filtering image-text data by leveraging fine-tuned Multimodal Language Models (MLMs). Our approach outperforms predominant filtering methods (e.g., CLIPScore) via integrating the recent advances in MLMs. We design four distinct yet complementary metrics to holistically measure the quality of image-text data. A new pipeline is established to construct high-quality instruction data for fine-tuning MLMs as data filters. Comparing with CLIPScore, our MLM filters produce more precise and comprehensive scores that directly improve the quality of filtered data and boost the performance of pre-trained models. We achieve significant improvements over CLIPScore on popular foundation models (i.e., CLIP and BLIP2) and various downstream tasks. Our MLM filter can generalize to different models and tasks, and be used as a drop-in replacement for CLIPScore. An additional ablation study is provided to verify our design choices for the MLM filter.
LLaVA-UHD: an LMM Perceiving Any Aspect Ratio and High-Resolution Images
Mar 18, 2024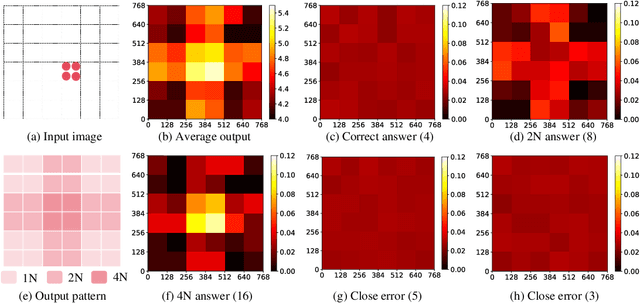
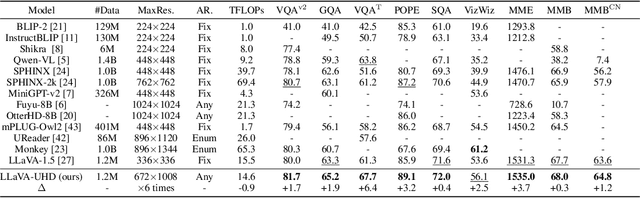
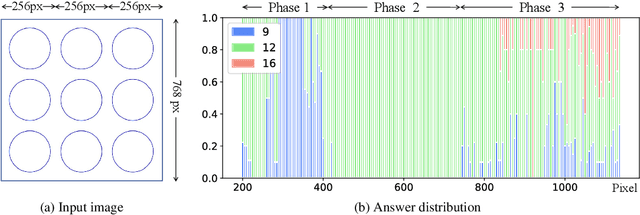
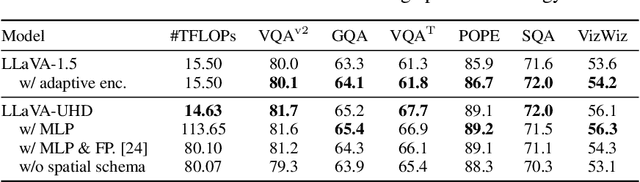
Visual encoding constitutes the basis of large multimodal models (LMMs) in understanding the visual world. Conventional LMMs process images in fixed sizes and limited resolutions, while recent explorations in this direction are limited in adaptivity, efficiency, and even correctness. In this work, we first take GPT-4V and LLaVA-1.5 as representative examples and expose systematic flaws rooted in their visual encoding strategy. To address the challenges, we present LLaVA-UHD, a large multimodal model that can efficiently perceive images in any aspect ratio and high resolution. LLaVA-UHD includes three key components: (1) An image modularization strategy that divides native-resolution images into smaller variable-sized slices for efficient and extensible encoding, (2) a compression module that further condenses image tokens from visual encoders, and (3) a spatial schema to organize slice tokens for LLMs. Comprehensive experiments show that LLaVA-UHD outperforms established LMMs trained with 2-3 orders of magnitude more data on 9 benchmarks. Notably, our model built on LLaVA-1.5 336x336 supports 6 times larger (i.e., 672x1088) resolution images using only 94% inference computation, and achieves 6.4 accuracy improvement on TextVQA. Moreover, the model can be efficiently trained in academic settings, within 23 hours on 8 A100 GPUs (vs. 26 hours of LLaVA-1.5). We make the data and code publicly available at https://github.com/thunlp/LLaVA-UHD.
Exploring Pre-trained Text-to-Video Diffusion Models for Referring Video Object Segmentation
Mar 18, 2024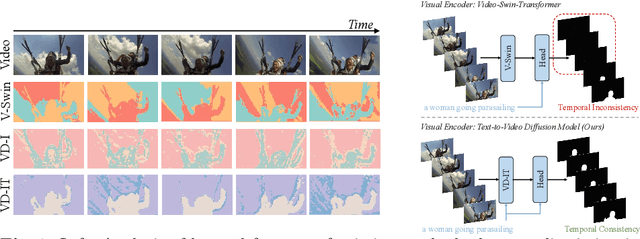
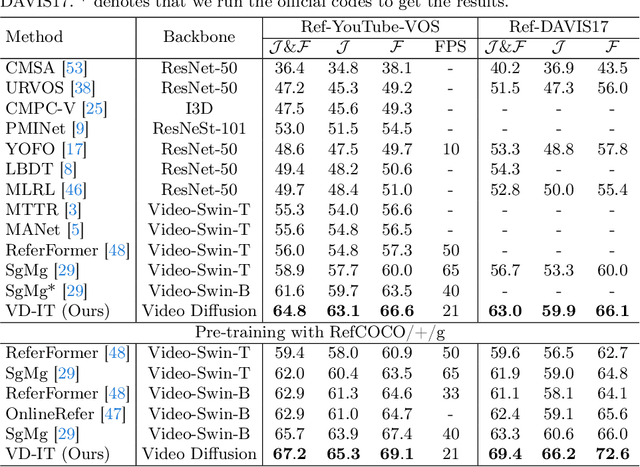
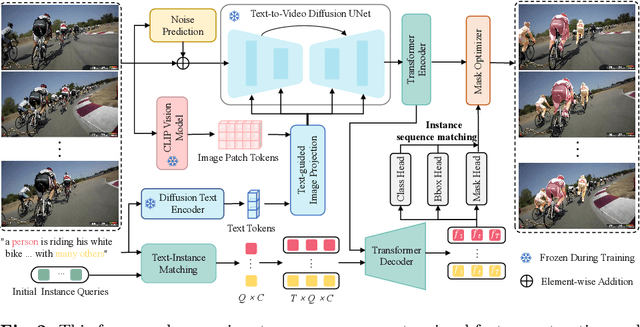
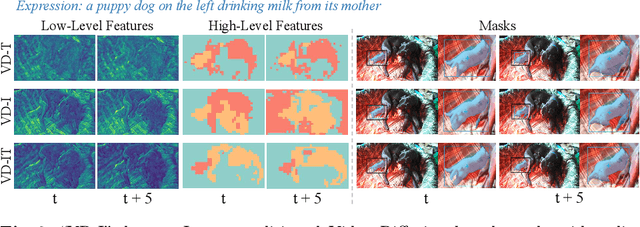
In this paper, we explore the visual representations produced from a pre-trained text-to-video (T2V) diffusion model for video understanding tasks. We hypothesize that the latent representation learned from a pretrained generative T2V model encapsulates rich semantics and coherent temporal correspondences, thereby naturally facilitating video understanding. Our hypothesis is validated through the classic referring video object segmentation (R-VOS) task. We introduce a novel framework, termed ``VD-IT'', tailored with dedicatedly designed components built upon a fixed pretrained T2V model. Specifically, VD-IT uses textual information as a conditional input, ensuring semantic consistency across time for precise temporal instance matching. It further incorporates image tokens as supplementary textual inputs, enriching the feature set to generate detailed and nuanced masks.Besides, instead of using the standard Gaussian noise, we propose to predict the video-specific noise with an extra noise prediction module, which can help preserve the feature fidelity and elevates segmentation quality. Through extensive experiments, we surprisingly observe that fixed generative T2V diffusion models, unlike commonly used video backbones (e.g., Video Swin Transformer) pretrained with discriminative image/video pre-tasks, exhibit better potential to maintain semantic alignment and temporal consistency. On existing standard benchmarks, our VD-IT achieves highly competitive results, surpassing many existing state-of-the-art methods. The code will be available at \url{https://github.com/buxiangzhiren/VD-IT}