 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Q2ATransformer: Improving Medical VQA via an Answer Querying Decoder
Apr 04, 2023
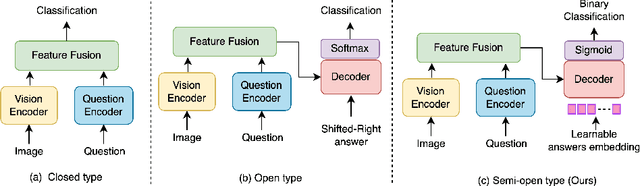
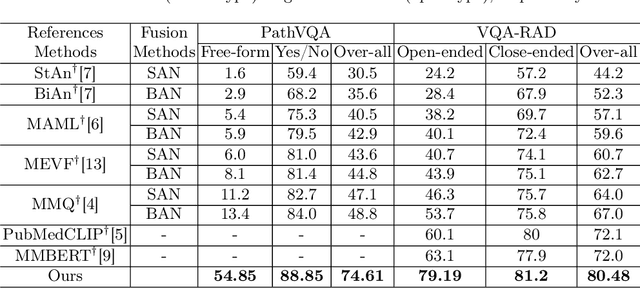
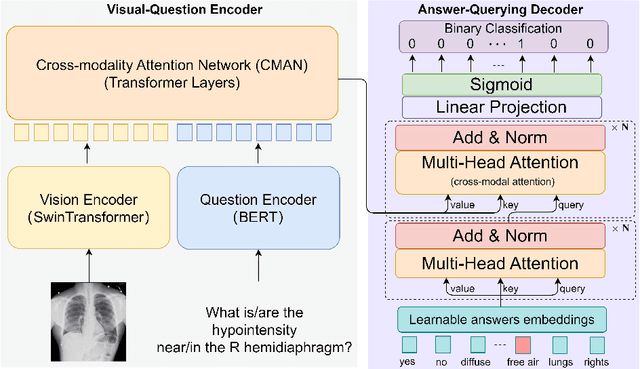
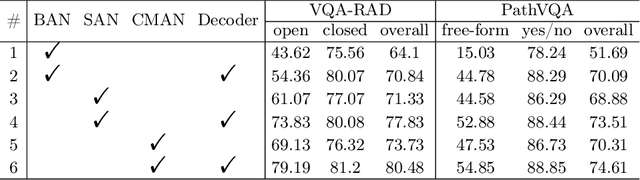
Medical Visual Question Answering (VQA) systems play a supporting role to understand clinic-relevant information carried by medical images. The questions to a medical image include two categories: close-end (such as Yes/No question) and open-end. To obtain answers, the majority of the existing medical VQA methods relies on classification approaches, while a few works attempt to use generation approaches or a mixture of the two. The classification approaches are relatively simple but perform poorly on long open-end questions. To bridge this gap, in this paper, we propose a new Transformer based framework for medical VQA (named as Q2ATransformer), which integrates the advantages of both the classification and the generation approaches and provides a unified treatment for the close-end and open-end questions. Specifically, we introduce an additional Transformer decoder with a set of learnable candidate answer embeddings to query the existence of each answer class to a given image-question pair. Through the Transformer attention, the candidate answer embeddings interact with the fused features of the image-question pair to make the decision. In this way, despite being a classification-based approach, our method provides a mechanism to interact with the answer information for prediction like the generation-based approaches. On the other hand, by classification, we mitigate the task difficulty by reducing the search space of answers. Our method achieves new state-of-the-art performance on two medical VQA benchmarks. Especially, for the open-end questions, we achieve 79.19% on VQA-RAD and 54.85% on PathVQA, with 16.09% and 41.45% absolute improvements, respectively.
Scalable and Accurate Self-supervised Multimodal Representation Learning without Aligned Video and Text Data
Apr 04, 2023

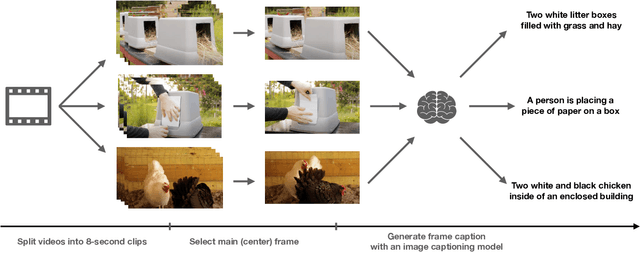

Scaling up weakly-supervised datasets has shown to be highly effective in the image-text domain and has contributed to most of the recent state-of-the-art computer vision and multimodal neural networks. However, existing large-scale video-text datasets and mining techniques suffer from several limitations, such as the scarcity of aligned data, the lack of diversity in the data, and the difficulty of collecting aligned data. Currently popular video-text data mining approach via automatic speech recognition (ASR) used in HowTo100M provides low-quality captions that often do not refer to the video content. Other mining approaches do not provide proper language descriptions (video tags) and are biased toward short clips (alt text). In this work, we show how recent advances in image captioning allow us to pre-train high-quality video models without any parallel video-text data. We pre-train several video captioning models that are based on an OPT language model and a TimeSformer visual backbone. We fine-tune these networks on several video captioning datasets. First, we demonstrate that image captioning pseudolabels work better for pre-training than the existing HowTo100M ASR captions. Second, we show that pre-training on both images and videos produces a significantly better network (+4 CIDER on MSR-VTT) than pre-training on a single modality. Our methods are complementary to the existing pre-training or data mining approaches and can be used in a variety of settings. Given the efficacy of the pseudolabeling method, we are planning to publicly release the generated captions.
DIME-FM: DIstilling Multimodal and Efficient Foundation Models
Mar 31, 2023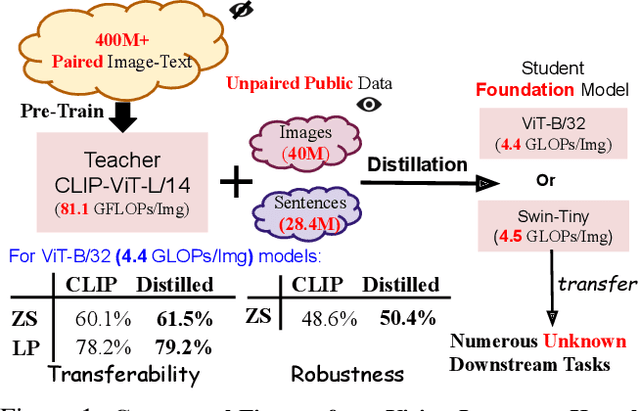

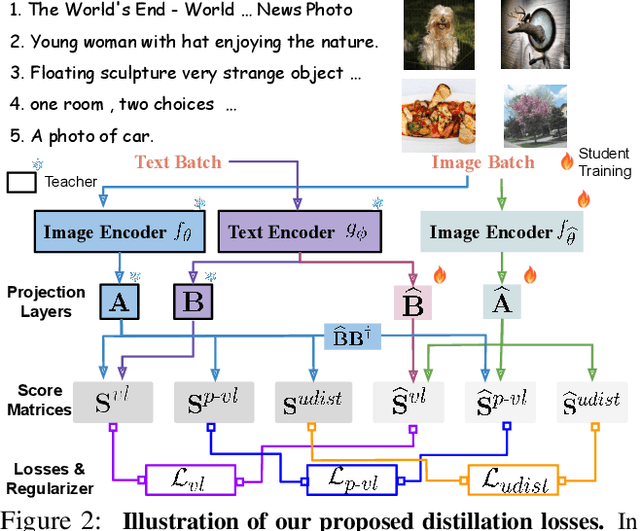
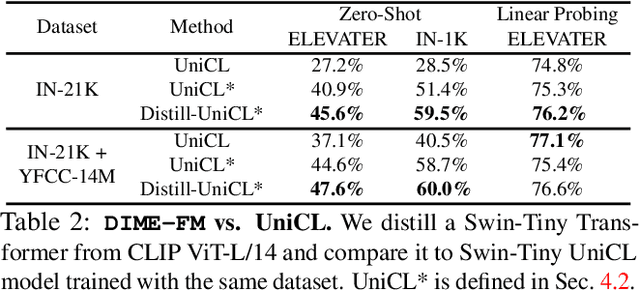
Large Vision-Language Foundation Models (VLFM), such as CLIP, ALIGN and Florence, are trained on large-scale datasets of image-caption pairs and achieve superior transferability and robustness on downstream tasks, but they are difficult to use in many practical applications due to their large size, high latency and fixed architectures. Unfortunately, recent work shows training a small custom VLFM for resource-limited applications is currently very difficult using public and smaller-scale data. In this paper, we introduce a new distillation mechanism (DIME-FM) that allows us to transfer the knowledge contained in large VLFMs to smaller, customized foundation models using a relatively small amount of inexpensive, unpaired images and sentences. We transfer the knowledge from the pre-trained CLIP-ViTL/14 model to a ViT-B/32 model, with only 40M public images and 28.4M unpaired public sentences. The resulting model "Distill-ViT-B/32" rivals the CLIP-ViT-B/32 model pre-trained on its private WiT dataset (400M image-text pairs): Distill-ViT-B/32 achieves similar results in terms of zero-shot and linear-probing performance on both ImageNet and the ELEVATER (20 image classification tasks) benchmarks. It also displays comparable robustness when evaluated on five datasets with natural distribution shifts from ImageNet.
MS-MT: Multi-Scale Mean Teacher with Contrastive Unpaired Translation for Cross-Modality Vestibular Schwannoma and Cochlea Segmentation
Mar 28, 2023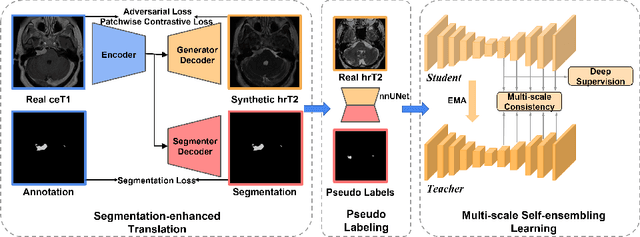

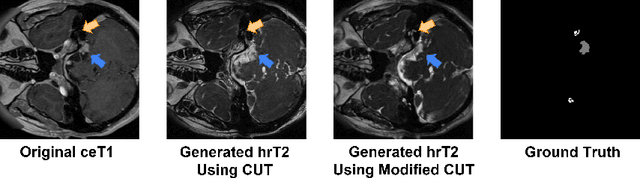
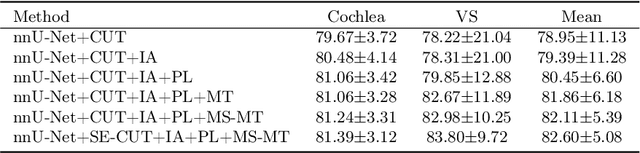
Domain shift has been a long-standing issue for medical image segmentation. Recently, unsupervised domain adaptation (UDA) methods have achieved promising cross-modality segmentation performance by distilling knowledge from a label-rich source domain to a target domain without labels. In this work, we propose a multi-scale self-ensembling based UDA framework for automatic segmentation of two key brain structures i.e., Vestibular Schwannoma (VS) and Cochlea on high-resolution T2 images. First, a segmentation-enhanced contrastive unpaired image translation module is designed for image-level domain adaptation from source T1 to target T2. Next, multi-scale deep supervision and consistency regularization are introduced to a mean teacher network for self-ensemble learning to further close the domain gap. Furthermore, self-training and intensity augmentation techniques are utilized to mitigate label scarcity and boost cross-modality segmentation performance. Our method demonstrates promising segmentation performance with a mean Dice score of 83.8% and 81.4% and an average asymmetric surface distance (ASSD) of 0.55 mm and 0.26 mm for the VS and Cochlea, respectively in the validation phase of the crossMoDA 2022 challenge.
StyleDiffusion: Prompt-Embedding Inversion for Text-Based Editing
Mar 28, 2023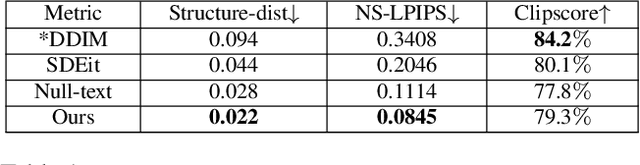



A significant research effort is focused on exploiting the amazing capacities of pretrained diffusion models for the editing of images. They either finetune the model, or invert the image in the latent space of the pretrained model. However, they suffer from two problems: (1) Unsatisfying results for selected regions, and unexpected changes in nonselected regions. (2) They require careful text prompt editing where the prompt should include all visual objects in the input image. To address this, we propose two improvements: (1) Only optimizing the input of the value linear network in the cross-attention layers, is sufficiently powerful to reconstruct a real image. (2) We propose attention regularization to preserve the object-like attention maps after editing, enabling us to obtain accurate style editing without invoking significant structural changes. We further improve the editing technique which is used for the unconditional branch of classifier-free guidance, as well as the conditional one as used by P2P. Extensive experimental prompt-editing results on a variety of images, demonstrate qualitatively and quantitatively that our method has superior editing capabilities than existing and concurrent works.
Self-Training Guided Disentangled Adaptation for Cross-Domain Remote Sensing Image Semantic Segmentation
Jan 13, 2023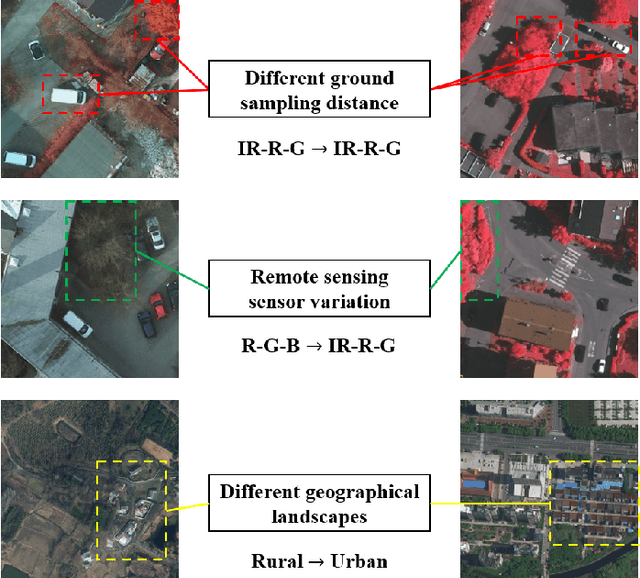
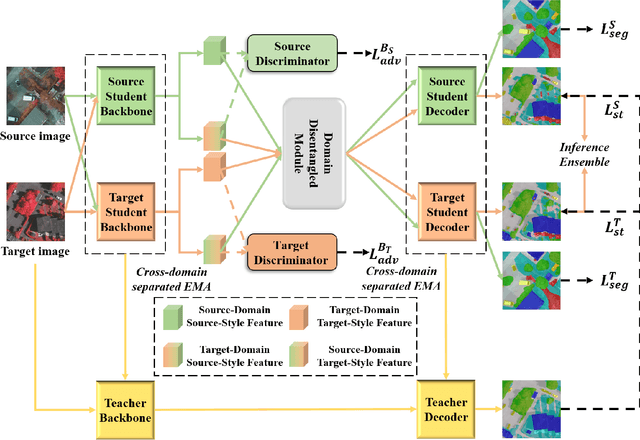
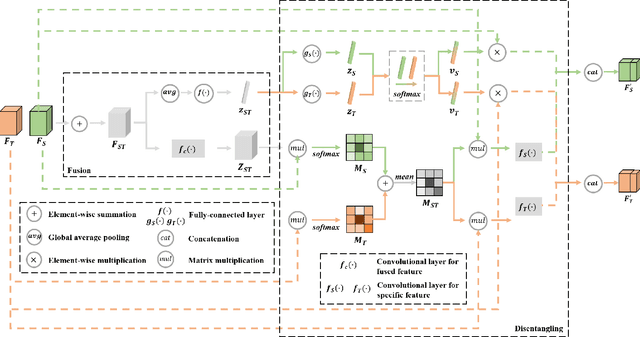
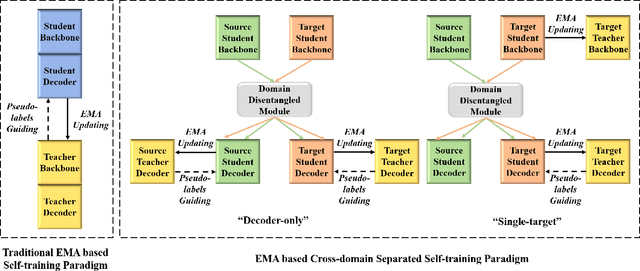
Deep convolutional neural networks (DCNNs) based remote sensing (RS) image semantic segmentation technology has achieved great success used in many real-world applications such as geographic element analysis. However, strong dependency on annotated data of specific scene makes it hard for DCNNs to fit different RS scenes. To solve this problem, recent works gradually focus on cross-domain RS image semantic segmentation task. In this task, different ground sampling distance, remote sensing sensor variation and different geographical landscapes are three main factors causing dramatic domain shift between source and target images. To decrease the negative influence of domain shift, we propose a self-training guided disentangled adaptation network (ST-DASegNet). We first propose source student backbone and target student backbone to respectively extract the source-style and target-style feature for both source and target images. Towards the intermediate output feature maps of each backbone, we adopt adversarial learning for alignment. Then, we propose a domain disentangled module to extract the universal feature and purify the distinct feature of source-style and target-style features. Finally, these two features are fused and served as input of source student decoder and target student decoder to generate final predictions. Based on our proposed domain disentangled module, we further propose exponential moving average (EMA) based cross-domain separated self-training mechanism to ease the instability and disadvantageous effect during adversarial optimization. Extensive experiments and analysis on benchmark RS datasets show that ST-DASegNet outperforms previous methods on cross-domain RS image semantic segmentation task and achieves state-of-the-art (SOTA) results. Our code is available at https://github.com/cv516Buaa/ST-DASegNet.
Laplacian Segmentation Networks: Improved Epistemic Uncertainty from Spatial Aleatoric Uncertainty
Mar 23, 2023
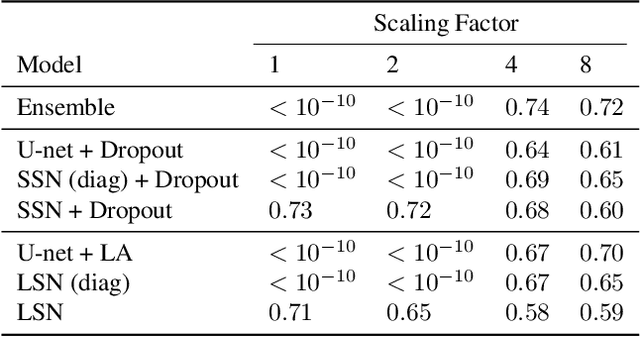
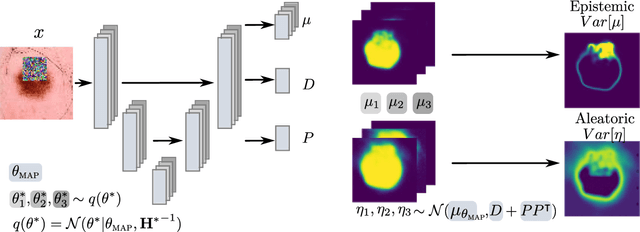
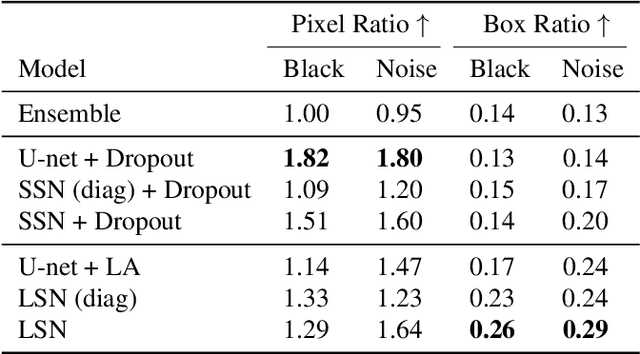
Out of distribution (OOD) medical images are frequently encountered, e.g. because of site- or scanner differences, or image corruption. OOD images come with a risk of incorrect image segmentation, potentially negatively affecting downstream diagnoses or treatment. To ensure robustness to such incorrect segmentations, we propose Laplacian Segmentation Networks (LSN) that jointly model epistemic (model) and aleatoric (data) uncertainty in image segmentation. We capture data uncertainty with a spatially correlated logit distribution. For model uncertainty, we propose the first Laplace approximation of the weight posterior that scales to large neural networks with skip connections that have high-dimensional outputs. Empirically, we demonstrate that modelling spatial pixel correlation allows the Laplacian Segmentation Network to successfully assign high epistemic uncertainty to out-of-distribution objects appearing within images.
Rethinking Out-of-distribution (OOD) Detection: Masked Image Modeling is All You Need
Feb 06, 2023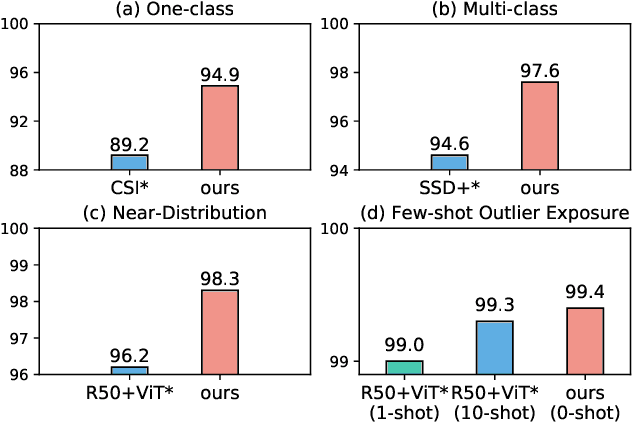
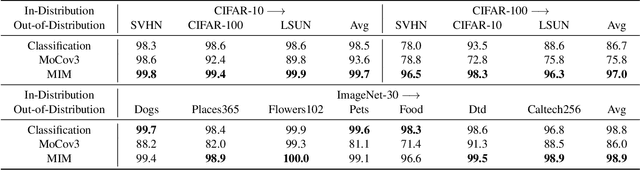
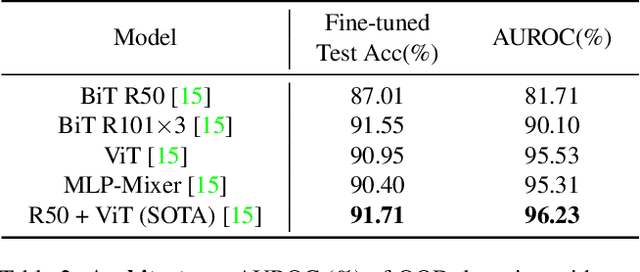
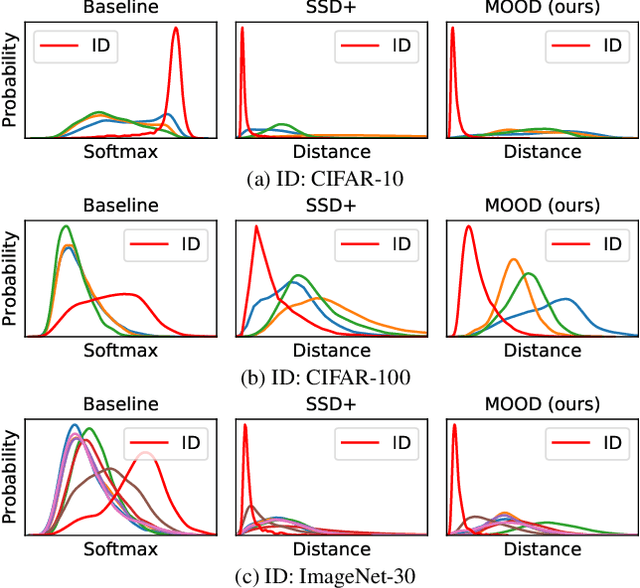
The core of out-of-distribution (OOD) detection is to learn the in-distribution (ID) representation, which is distinguishable from OOD samples. Previous work applied recognition-based methods to learn the ID features, which tend to learn shortcuts instead of comprehensive representations. In this work, we find surprisingly that simply using reconstruction-based methods could boost the performance of OOD detection significantly. We deeply explore the main contributors of OOD detection and find that reconstruction-based pretext tasks have the potential to provide a generally applicable and efficacious prior, which benefits the model in learning intrinsic data distributions of the ID dataset. Specifically, we take Masked Image Modeling as a pretext task for our OOD detection framework (MOOD). Without bells and whistles, MOOD outperforms previous SOTA of one-class OOD detection by 5.7%, multi-class OOD detection by 3.0%, and near-distribution OOD detection by 2.1%. It even defeats the 10-shot-per-class outlier exposure OOD detection, although we do not include any OOD samples for our detection
Diffusion Recommender Model
Apr 11, 2023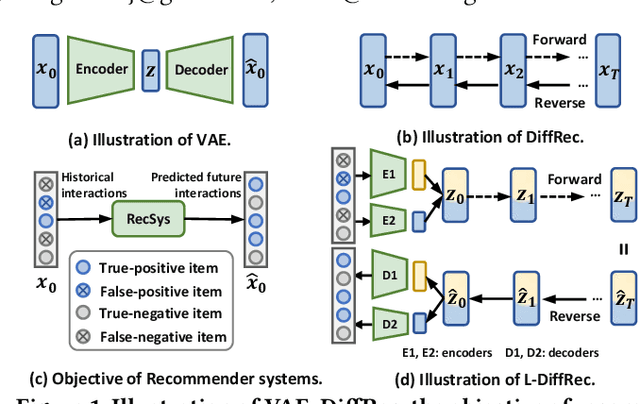
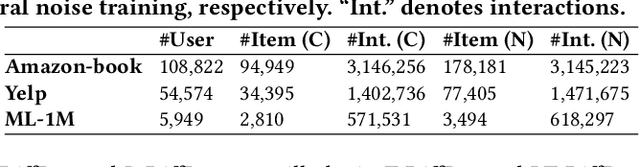
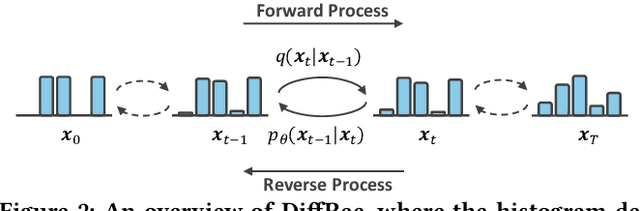
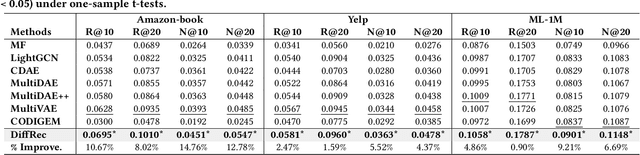
Generative models such as Generative Adversarial Networks (GANs) and Variational Auto-Encoders (VAEs) are widely utilized to model the generative process of user interactions. However, these generative models suffer from intrinsic limitations such as the instability of GANs and the restricted representation ability of VAEs. Such limitations hinder the accurate modeling of the complex user interaction generation procedure, such as noisy interactions caused by various interference factors. In light of the impressive advantages of Diffusion Models (DMs) over traditional generative models in image synthesis, we propose a novel Diffusion Recommender Model (named DiffRec) to learn the generative process in a denoising manner. To retain personalized information in user interactions, DiffRec reduces the added noises and avoids corrupting users' interactions into pure noises like in image synthesis. In addition, we extend traditional DMs to tackle the unique challenges in practical recommender systems: high resource costs for large-scale item prediction and temporal shifts of user preference. To this end, we propose two extensions of DiffRec: L-DiffRec clusters items for dimension compression and conducts the diffusion processes in the latent space; and T-DiffRec reweights user interactions based on the interaction timestamps to encode temporal information. We conduct extensive experiments on three datasets under multiple settings (e.g. clean training, noisy training, and temporal training). The empirical results and in-depth analysis validate the superiority of DiffRec with two extensions over competitive baselines.
SamurAI: A Versatile IoT Node With Event-Driven Wake-Up and Embedded ML Acceleration
Apr 11, 2023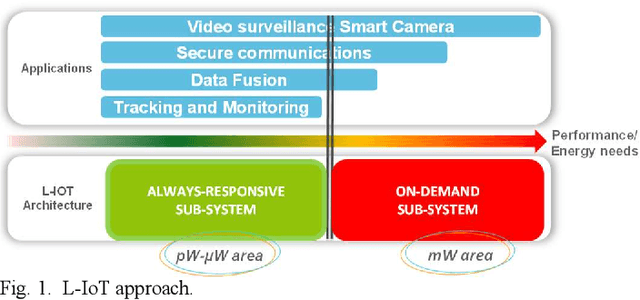
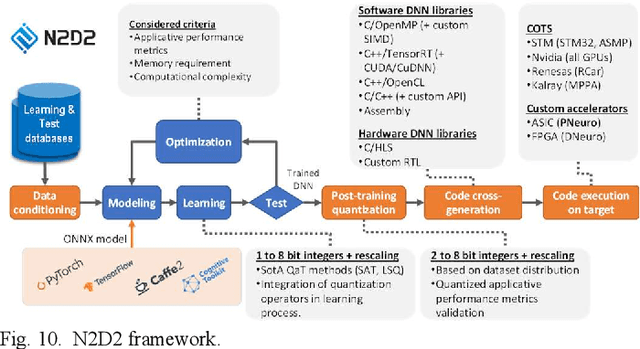
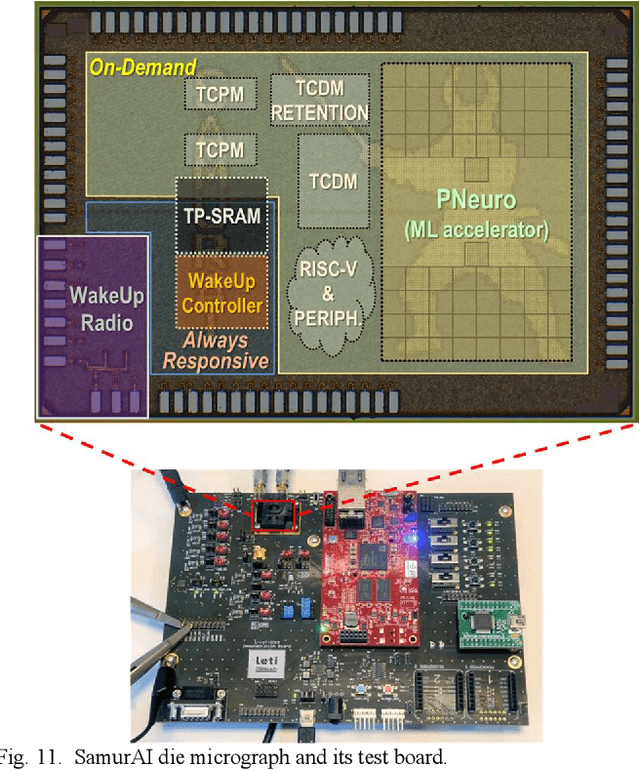
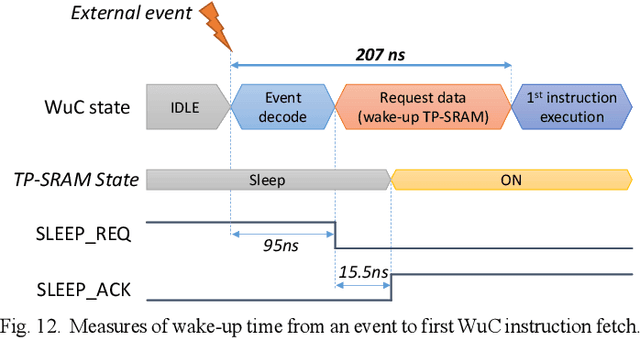
Increased capabilities such as recognition and self-adaptability are now required from IoT applications. While IoT node power consumption is a major concern for these applications, cloud-based processing is becoming unsustainable due to continuous sensor or image data transmission over the wireless network. Thus optimized ML capabilities and data transfers should be integrated in the IoT node. Moreover, IoT applications are torn between sporadic data-logging and energy-hungry data processing (e.g. image classification). Thus, the versatility of the node is key in addressing this wide diversity of energy and processing needs. This paper presents SamurAI, a versatile IoT node bridging this gap in processing and in energy by leveraging two on-chip sub-systems: a low power, clock-less, event-driven Always-Responsive (AR) part and an energy-efficient On-Demand (OD) part. AR contains a 1.7MOPS event-driven, asynchronous Wake-up Controller (WuC) with a 207ns wake-up time optimized for sporadic computing, while OD combines a deep-sleep RISC-V CPU and 1.3TOPS/W Machine Learning (ML) for more complex tasks up to 36GOPS. This architecture partitioning achieves best in class versatility metrics such as peak performance to idle power ratio. On an applicative classification scenario, it demonstrates system power gains, up to 3.5x compared to cloud-based processing, and thus extended battery lifetime.