 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Associating Spatially-Consistent Grouping with Text-supervised Semantic Segmentation
Apr 03, 2023

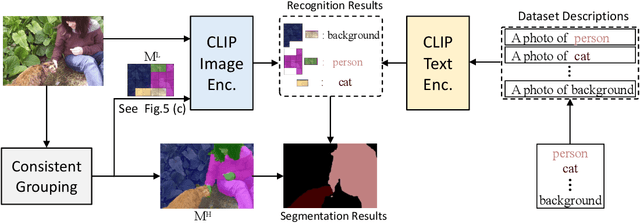
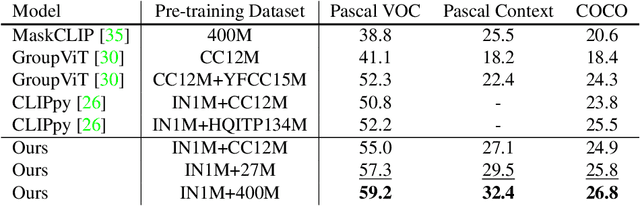
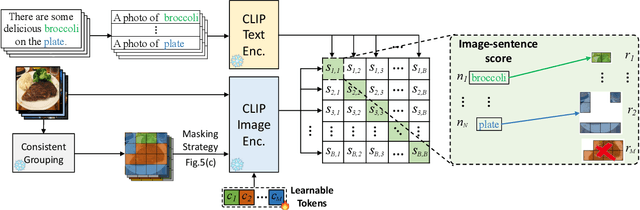
In this work, we investigate performing semantic segmentation solely through the training on image-sentence pairs. Due to the lack of dense annotations, existing text-supervised methods can only learn to group an image into semantic regions via pixel-insensitive feedback. As a result, their grouped results are coarse and often contain small spurious regions, limiting the upper-bound performance of segmentation. On the other hand, we observe that grouped results from self-supervised models are more semantically consistent and break the bottleneck of existing methods. Motivated by this, we introduce associate self-supervised spatially-consistent grouping with text-supervised semantic segmentation. Considering the part-like grouped results, we further adapt a text-supervised model from image-level to region-level recognition with two core designs. First, we encourage fine-grained alignment with a one-way noun-to-region contrastive loss, which reduces the mismatched noun-region pairs. Second, we adopt a contextually aware masking strategy to enable simultaneous recognition of all grouped regions. Coupled with spatially-consistent grouping and region-adapted recognition, our method achieves 59.2% mIoU and 32.4% mIoU on Pascal VOC and Pascal Context benchmarks, significantly surpassing the state-of-the-art methods.
Dif-Fusion: Towards High Color Fidelity in Infrared and Visible Image Fusion with Diffusion Models
Jan 19, 2023


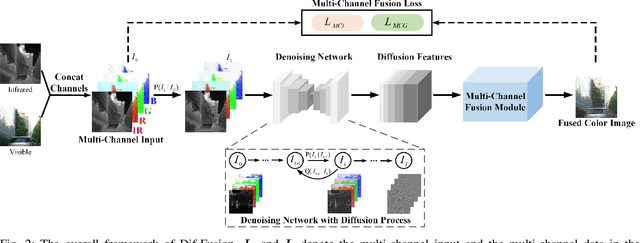
Color plays an important role in human visual perception, reflecting the spectrum of objects. However, the existing infrared and visible image fusion methods rarely explore how to handle multi-spectral/channel data directly and achieve high color fidelity. This paper addresses the above issue by proposing a novel method with diffusion models, termed as Dif-Fusion, to generate the distribution of the multi-channel input data, which increases the ability of multi-source information aggregation and the fidelity of colors. In specific, instead of converting multi-channel images into single-channel data in existing fusion methods, we create the multi-channel data distribution with a denoising network in a latent space with forward and reverse diffusion process. Then, we use the the denoising network to extract the multi-channel diffusion features with both visible and infrared information. Finally, we feed the multi-channel diffusion features to the multi-channel fusion module to directly generate the three-channel fused image. To retain the texture and intensity information, we propose multi-channel gradient loss and intensity loss. Along with the current evaluation metrics for measuring texture and intensity fidelity, we introduce a new evaluation metric to quantify color fidelity. Extensive experiments indicate that our method is more effective than other state-of-the-art image fusion methods, especially in color fidelity.
LostPaw: Finding Lost Pets using a Contrastive Learning-based Transformer with Visual Input
Apr 28, 2023Losing pets can be highly distressing for pet owners, and finding a lost pet is often challenging and time-consuming. An artificial intelligence-based application can significantly improve the speed and accuracy of finding lost pets. In order to facilitate such an application, this study introduces a contrastive neural network model capable of accurately distinguishing between images of pets. The model was trained on a large dataset of dog images and evaluated through 3-fold cross-validation. Following 350 epochs of training, the model achieved a test accuracy of 90%. Furthermore, overfitting was avoided, as the test accuracy closely matched the training accuracy. Our findings suggest that contrastive neural network models hold promise as a tool for locating lost pets. This paper provides the foundation for a potential web application that allows users to upload images of their missing pets, receiving notifications when matching images are found in the application's image database. This would enable pet owners to quickly and accurately locate lost pets and reunite them with their families.
Parameter Efficient Local Implicit Image Function Network for Face Segmentation
Mar 27, 2023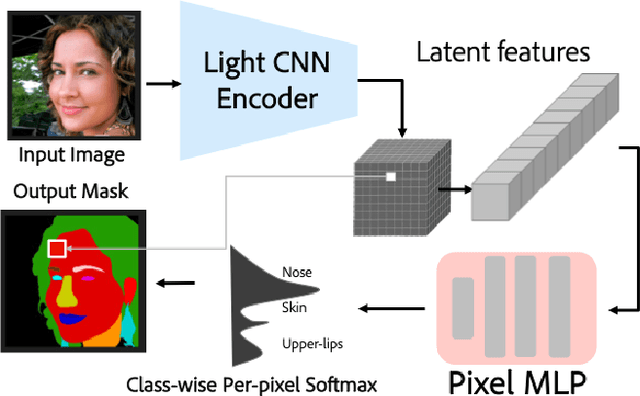
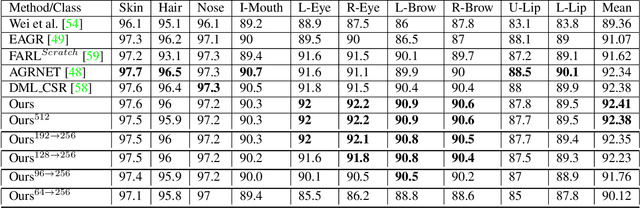

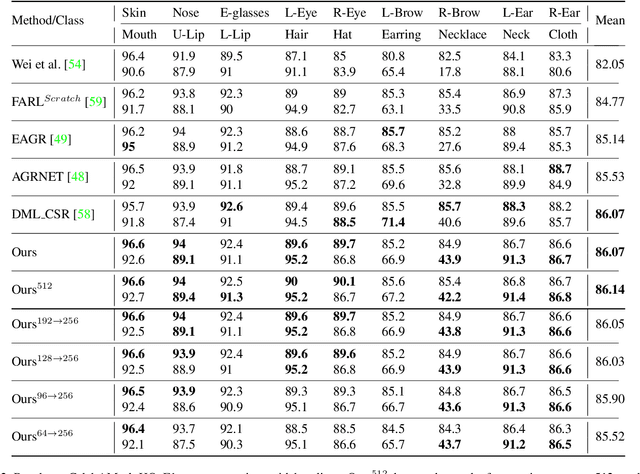
Face parsing is defined as the per-pixel labeling of images containing human faces. The labels are defined to identify key facial regions like eyes, lips, nose, hair, etc. In this work, we make use of the structural consistency of the human face to propose a lightweight face-parsing method using a Local Implicit Function network, FP-LIIF. We propose a simple architecture having a convolutional encoder and a pixel MLP decoder that uses 1/26th number of parameters compared to the state-of-the-art models and yet matches or outperforms state-of-the-art models on multiple datasets, like CelebAMask-HQ and LaPa. We do not use any pretraining, and compared to other works, our network can also generate segmentation at different resolutions without any changes in the input resolution. This work enables the use of facial segmentation on low-compute or low-bandwidth devices because of its higher FPS and smaller model size.
See You Soon: Decoupled Iterative Refinement Framework for Interacting Hands Reconstruction from a Single RGB Image
Feb 05, 2023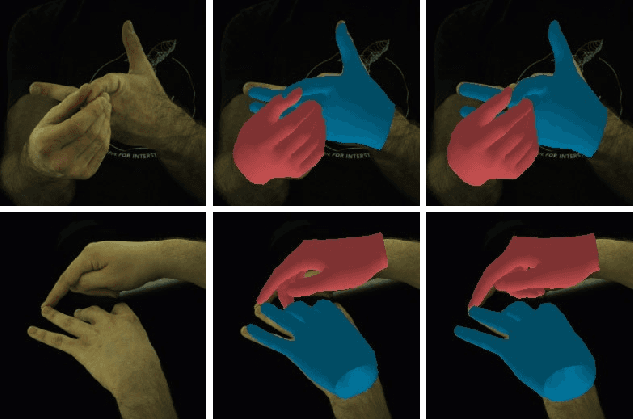


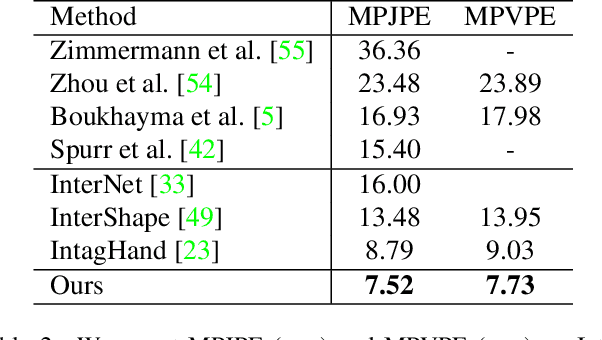
Reconstructing interacting hands from a single RGB image is a very challenging task. On the one hand, severe mutual occlusion and similar local appearance between two hands confuse the extraction of visual features, resulting in the misalignment of estimated hand meshes and the image. On the other hand, there are complex interaction patterns between interacting hands, which significantly increases the solution space of hand poses and increases the difficulty of network learning. In this paper, we propose a decoupled iterative refinement framework to achieve pixel-alignment hand reconstruction while efficiently modeling the spatial relationship between hands. Specifically, we define two feature spaces with different characteristics, namely 2D visual feature space and 3D joint feature space. First, we obtain joint-wise features from the visual feature map and utilize a graph convolution network and a transformer to perform intra- and inter-hand information interaction in the 3D joint feature space, respectively. Then, we project the joint features with global information back into the 2D visual feature space in an obfuscation-free manner and utilize the 2D convolution for pixel-wise enhancement. By performing multiple alternate enhancements in the two feature spaces, our method can achieve an accurate and robust reconstruction of interacting hands. Our method outperforms all existing two-hand reconstruction methods by a large margin on the InterHand2.6M dataset. Meanwhile, our method shows a strong generalization ability for in-the-wild images.
Geometric-aware Pretraining for Vision-centric 3D Object Detection
Apr 07, 2023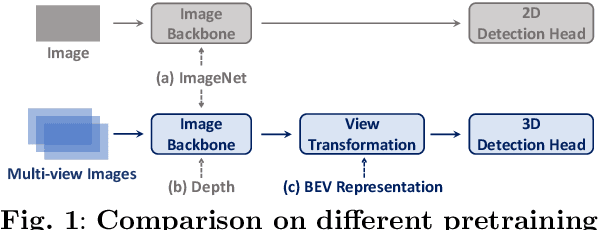
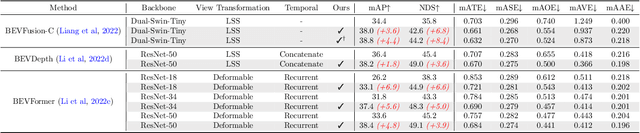
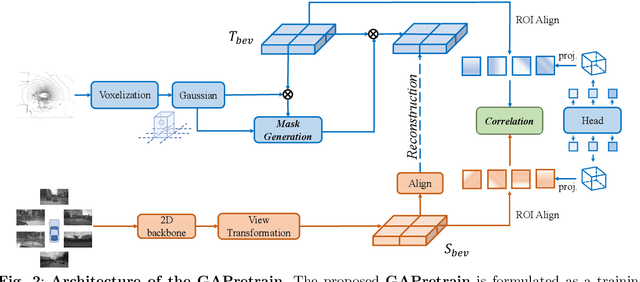
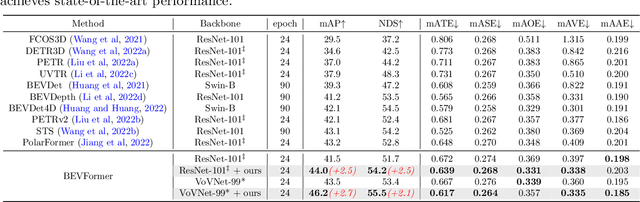
Multi-camera 3D object detection for autonomous driving is a challenging problem that has garnered notable attention from both academia and industry. An obstacle encountered in vision-based techniques involves the precise extraction of geometry-conscious features from RGB images. Recent approaches have utilized geometric-aware image backbones pretrained on depth-relevant tasks to acquire spatial information. However, these approaches overlook the critical aspect of view transformation, resulting in inadequate performance due to the misalignment of spatial knowledge between the image backbone and view transformation. To address this issue, we propose a novel geometric-aware pretraining framework called GAPretrain. Our approach incorporates spatial and structural cues to camera networks by employing the geometric-rich modality as guidance during the pretraining phase. The transference of modal-specific attributes across different modalities is non-trivial, but we bridge this gap by using a unified bird's-eye-view (BEV) representation and structural hints derived from LiDAR point clouds to facilitate the pretraining process. GAPretrain serves as a plug-and-play solution that can be flexibly applied to multiple state-of-the-art detectors. Our experiments demonstrate the effectiveness and generalization ability of the proposed method. We achieve 46.2 mAP and 55.5 NDS on the nuScenes val set using the BEVFormer method, with a gain of 2.7 and 2.1 points, respectively. We also conduct experiments on various image backbones and view transformations to validate the efficacy of our approach. Code will be released at https://github.com/OpenDriveLab/BEVPerception-Survey-Recipe.
FD-Net: An Unsupervised Deep Forward-Distortion Model for Susceptibility Artifact Correction in EPI
Mar 18, 2023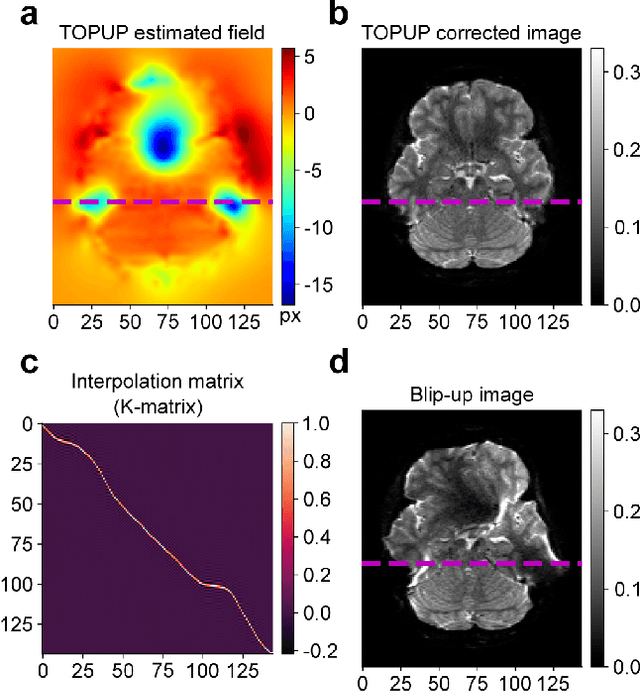
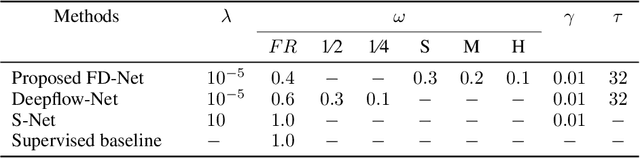
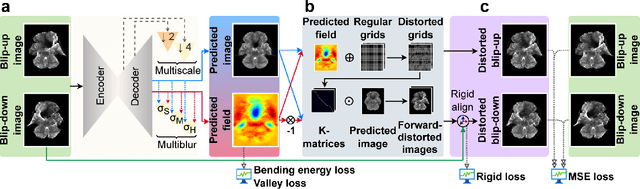
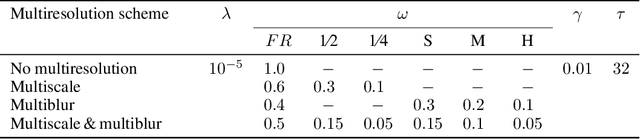
Recent learning-based correction approaches in EPI estimate a displacement field, unwarp the reversed-PE image pair with the estimated field, and average the unwarped pair to yield a corrected image. Unsupervised learning in these unwarping-based methods is commonly attained via a similarity constraint between the unwarped images in reversed-PE directions, neglecting consistency to the acquired EPI images. This work introduces an unsupervised deep-learning method for fast and effective correction of susceptibility artifacts in reversed phase-encode (PE) image pairs acquired with EPI. FD-Net predicts both the susceptibility-induced displacement field and the underlying anatomically-correct image. Unlike previous methods, FD-Net enforces the forward-distortions of the correct image in both PE directions to be consistent with the acquired reversed-PE image pair. FD-Net further leverages a multiresolution architecture to maintain high local and global performance. FD-Net performs competitively with a gold-standard reference method (TOPUP) in image quality, while enabling a leap in computational efficiency. Furthermore, FD-Net outperforms recent unwarping-based methods for unsupervised correction in terms of both image and field quality. The unsupervised FD-Net method introduces a deep forward-distortion approach to enable fast, high-fidelity correction of susceptibility artifacts in EPI by maintaining consistency to measured data. Therefore, it holds great promise for improving the anatomical accuracy of EPI imaging.
WATT-EffNet: A Lightweight and Accurate Model for Classifying Aerial Disaster Images
May 01, 2023
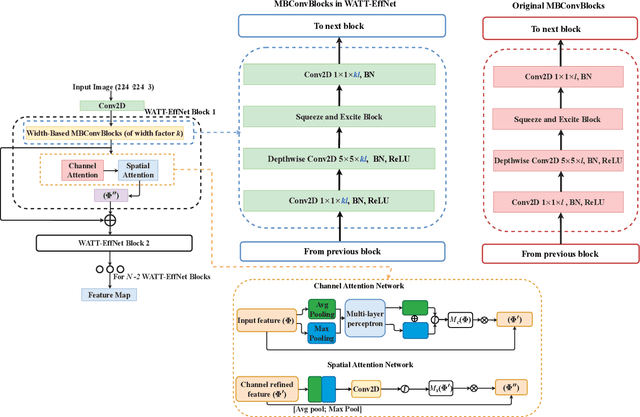
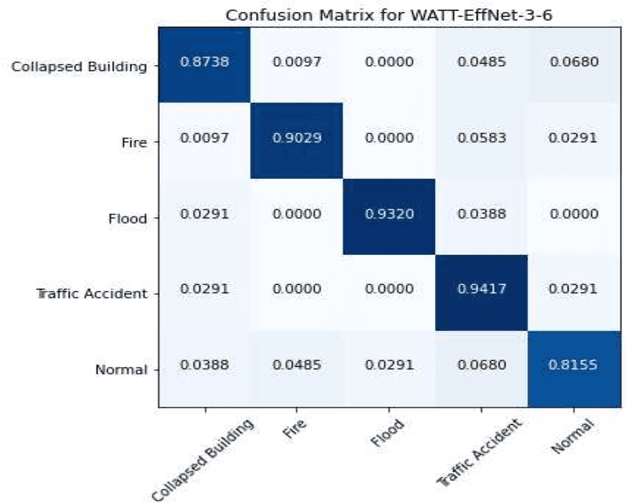
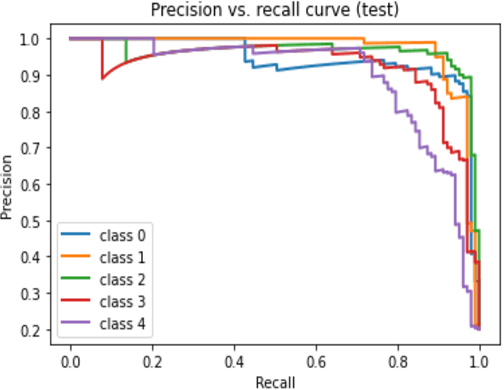
Incorporating deep learning (DL) classification models into unmanned aerial vehicles (UAVs) can significantly augment search-and-rescue operations and disaster management efforts. In such critical situations, the UAV's ability to promptly comprehend the crisis and optimally utilize its limited power and processing resources to narrow down search areas is crucial. Therefore, developing an efficient and lightweight method for scene classification is of utmost importance. However, current approaches tend to prioritize accuracy on benchmark datasets at the expense of computational efficiency. To address this shortcoming, we introduce the Wider ATTENTION EfficientNet (WATT-EffNet), a novel method that achieves higher accuracy with a more lightweight architecture compared to the baseline EfficientNet. The WATT-EffNet leverages width-wise incremental feature modules and attention mechanisms over width-wise features to ensure the network structure remains lightweight. We evaluate our method on a UAV-based aerial disaster image classification dataset and demonstrate that it outperforms the baseline by up to 15 times in terms of classification accuracy and 38.3% in terms of computing efficiency as measured by Floating Point Operations per second (FLOPs). Additionally, we conduct an ablation study to investigate the effect of varying the width of WATT-EffNet on accuracy and computational efficiency. Our code is available at \url{https://github.com/TanmDL/WATT-EffNet}.
What Do Self-Supervised Vision Transformers Learn?
May 01, 2023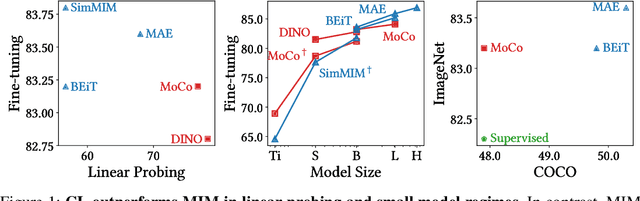
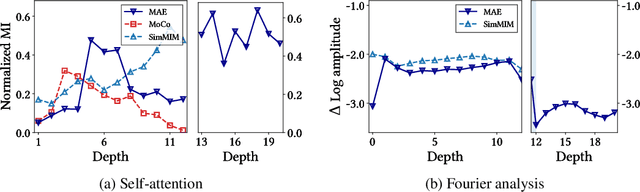
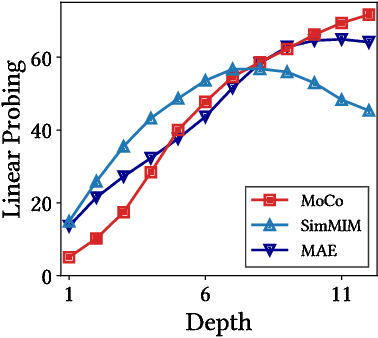
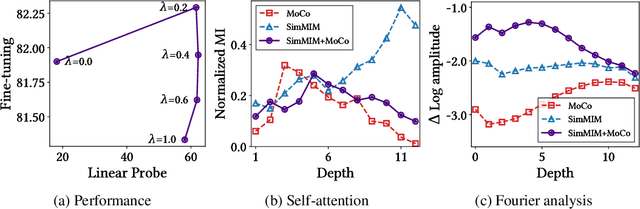
We present a comparative study on how and why contrastive learning (CL) and masked image modeling (MIM) differ in their representations and in their performance of downstream tasks. In particular, we demonstrate that self-supervised Vision Transformers (ViTs) have the following properties: (1) CL trains self-attentions to capture longer-range global patterns than MIM, such as the shape of an object, especially in the later layers of the ViT architecture. This CL property helps ViTs linearly separate images in their representation spaces. However, it also makes the self-attentions collapse into homogeneity for all query tokens and heads. Such homogeneity of self-attention reduces the diversity of representations, worsening scalability and dense prediction performance. (2) CL utilizes the low-frequency signals of the representations, but MIM utilizes high-frequencies. Since low- and high-frequency information respectively represent shapes and textures, CL is more shape-oriented and MIM more texture-oriented. (3) CL plays a crucial role in the later layers, while MIM mainly focuses on the early layers. Upon these analyses, we find that CL and MIM can complement each other and observe that even the simplest harmonization can help leverage the advantages of both methods. The code is available at https://github.com/naver-ai/cl-vs-mim.
ALIKED: A Lighter Keypoint and Descriptor Extraction Network via Deformable Transformation
Apr 07, 2023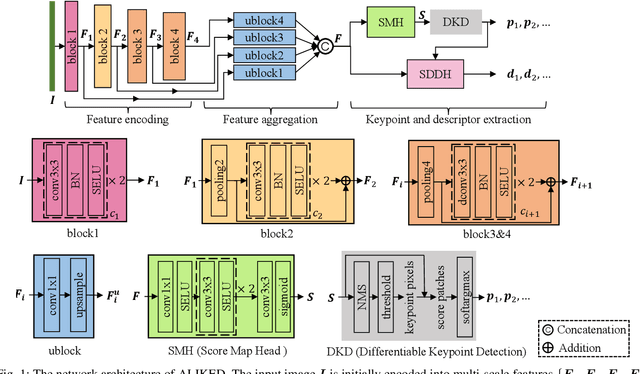
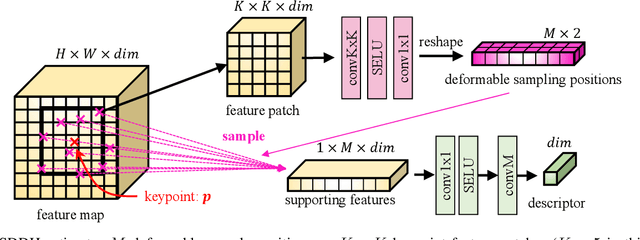
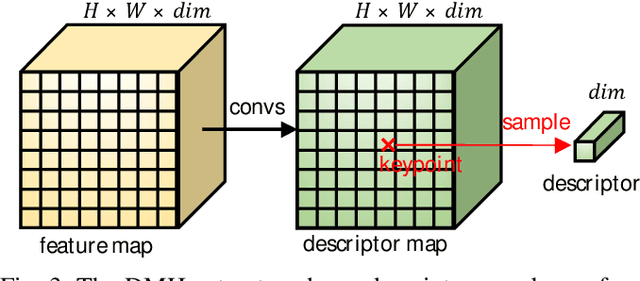

Image keypoints and descriptors play a crucial role in many visual measurement tasks. In recent years, deep neural networks have been widely used to improve the performance of keypoint and descriptor extraction. However, the conventional convolution operations do not provide the geometric invariance required for the descriptor. To address this issue, we propose the Sparse Deformable Descriptor Head (SDDH), which learns the deformable positions of supporting features for each keypoint and constructs deformable descriptors. Furthermore, SDDH extracts descriptors at sparse keypoints instead of a dense descriptor map, which enables efficient extraction of descriptors with strong expressiveness. In addition, we relax the neural reprojection error (NRE) loss from dense to sparse to train the extracted sparse descriptors. Experimental results show that the proposed network is both efficient and powerful in various visual measurement tasks, including image matching, 3D reconstruction, and visual relocalization.