 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PARAGRAPH2GRAPH: A GNN-based framework for layout paragraph analysis
Apr 24, 2023
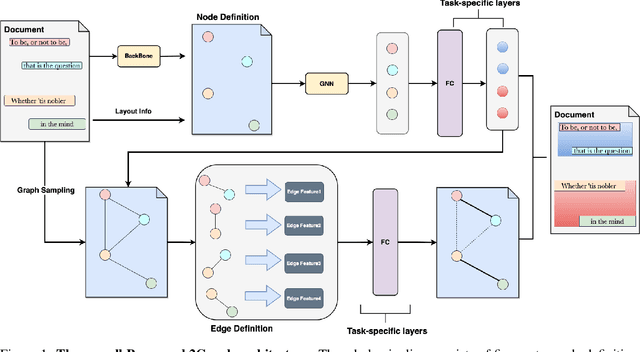

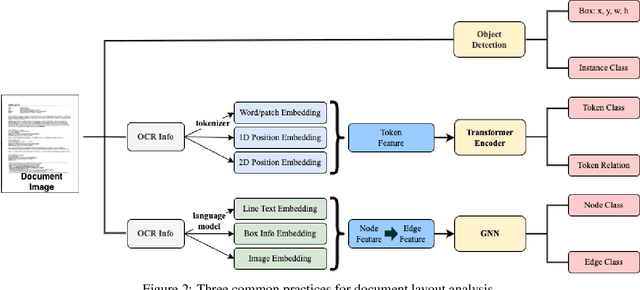
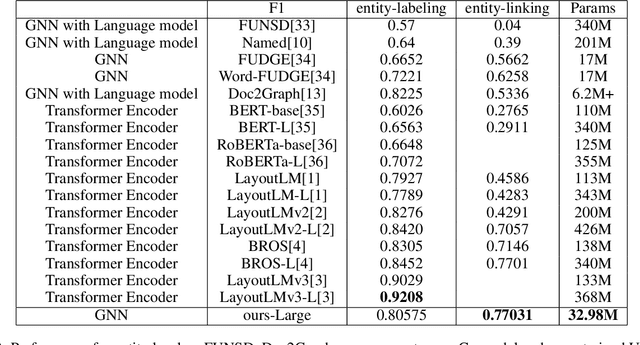
Document layout analysis has a wide range of requirements across various domains, languages, and business scenarios. However, most current state-of-the-art algorithms are language-dependent, with architectures that rely on transformer encoders or language-specific text encoders, such as BERT, for feature extraction. These approaches are limited in their ability to handle very long documents due to input sequence length constraints and are closely tied to language-specific tokenizers. Additionally, training a cross-language text encoder can be challenging due to the lack of labeled multilingual document datasets that consider privacy. Furthermore, some layout tasks require a clean separation between different layout components without overlap, which can be difficult for image segmentation-based algorithms to achieve. In this paper, we present Paragraph2Graph, a language-independent graph neural network (GNN)-based model that achieves competitive results on common document layout datasets while being adaptable to business scenarios with strict separation. With only 19.95 million parameters, our model is suitable for industrial applications, particularly in multi-language scenarios.
Universal Domain Adaptation via Compressive Attention Matching
Apr 24, 2023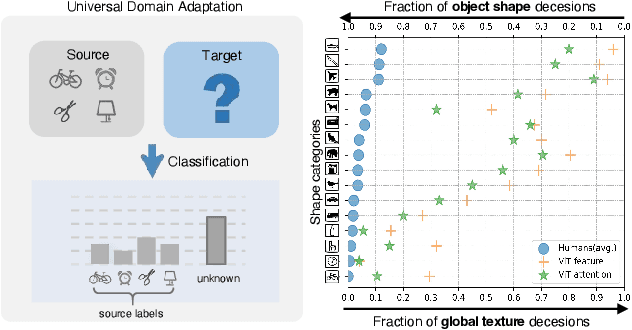
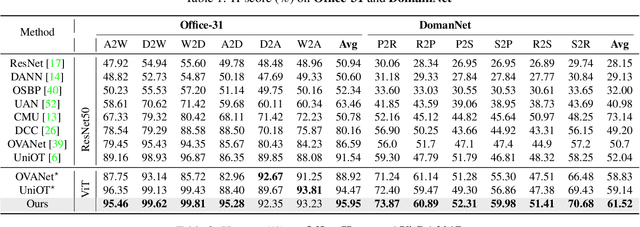

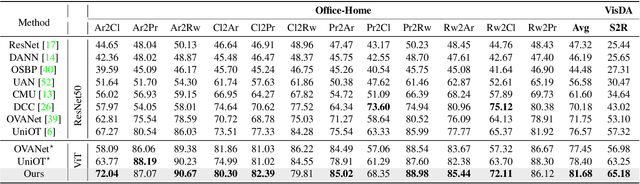
Universal domain adaptation (UniDA) aims to transfer knowledge from the source domain to the target domain without any prior knowledge about the label set. The challenge lies in how to determine whether the target samples belong to common categories. The mainstream methods make judgments based on the sample features, which overemphasizes global information while ignoring the most crucial local objects in the image, resulting in limited accuracy. To address this issue, we propose a Universal Attention Matching (UniAM) framework by exploiting the self-attention mechanism in vision transformer to capture the crucial object information. The proposed framework introduces a novel Compressive Attention Matching (CAM) approach to explore the core information by compressively representing attentions. Furthermore, CAM incorporates a residual-based measurement to determine the sample commonness. By utilizing the measurement, UniAM achieves domain-wise and category-wise Common Feature Alignment (CFA) and Target Class Separation (TCS). Notably, UniAM is the first method utilizing the attention in vision transformer directly to perform classification tasks. Extensive experiments show that UniAM outperforms the current state-of-the-art methods on various benchmark datasets.
Mixer: DNN Watermarking using Image Mixup
Dec 06, 2022
It is crucial to protect the intellectual property rights of DNN models prior to their deployment. The DNN should perform two main tasks: its primary task and watermarking task. This paper proposes a lightweight, reliable, and secure DNN watermarking that attempts to establish strong ties between these two tasks. The samples triggering the watermarking task are generated using image Mixup either from training or testing samples. This means that there is an infinity of triggers not limited to the samples used to embed the watermark in the model at training. The extensive experiments on image classification models for different datasets as well as exposing them to a variety of attacks, show that the proposed watermarking provides protection with an adequate level of security and robustness.
End-to-End Diffusion Latent Optimization Improves Classifier Guidance
Mar 23, 2023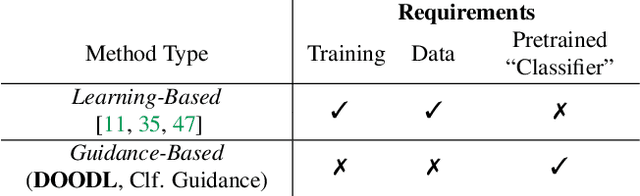


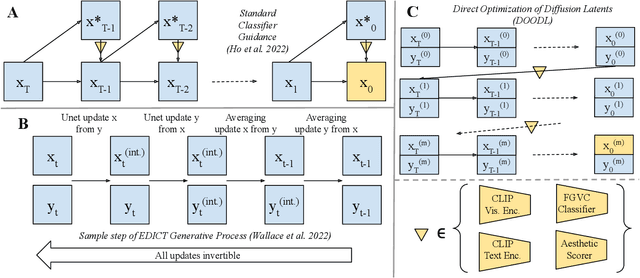
Classifier guidance -- using the gradients of an image classifier to steer the generations of a diffusion model -- has the potential to dramatically expand the creative control over image generation and editing. However, currently classifier guidance requires either training new noise-aware models to obtain accurate gradients or using a one-step denoising approximation of the final generation, which leads to misaligned gradients and sub-optimal control. We highlight this approximation's shortcomings and propose a novel guidance method: Direct Optimization of Diffusion Latents (DOODL), which enables plug-and-play guidance by optimizing diffusion latents w.r.t. the gradients of a pre-trained classifier on the true generated pixels, using an invertible diffusion process to achieve memory-efficient backpropagation. Showcasing the potential of more precise guidance, DOODL outperforms one-step classifier guidance on computational and human evaluation metrics across different forms of guidance: using CLIP guidance to improve generations of complex prompts from DrawBench, using fine-grained visual classifiers to expand the vocabulary of Stable Diffusion, enabling image-conditioned generation with a CLIP visual encoder, and improving image aesthetics using an aesthetic scoring network.
Large Scale Genealogical Information Extraction From Handwritten Quebec Parish Records
Apr 27, 2023This paper presents a complete workflow designed for extracting information from Quebec handwritten parish registers. The acts in these documents contain individual and family information highly valuable for genetic, demographic and social studies of the Quebec population. From an image of parish records, our workflow is able to identify the acts and extract personal information. The workflow is divided into successive steps: page classification, text line detection, handwritten text recognition, named entity recognition and act detection and classification. For all these steps, different machine learning models are compared. Once the information is extracted, validation rules designed by experts are then applied to standardize the extracted information and ensure its consistency with the type of act (birth, marriage, and death). This validation step is able to reject records that are considered invalid or merged. The full workflow has been used to process over two million pages of Quebec parish registers from the 19-20th centuries. On a sample comprising 65% of registers, 3.2 million acts were recognized. Verification of the birth and death acts from this sample shows that 74% of them are considered complete and valid. These records will be integrated into the BALSAC database and linked together to recreate family and genealogical relations at large scale.
Controllable One-Shot Face Video Synthesis With Semantic Aware Prior
Apr 27, 2023
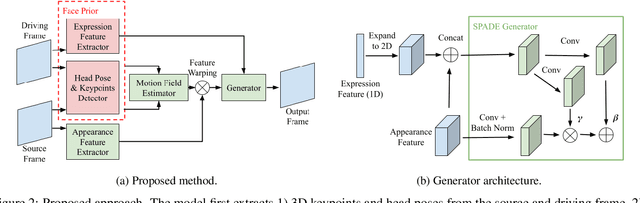
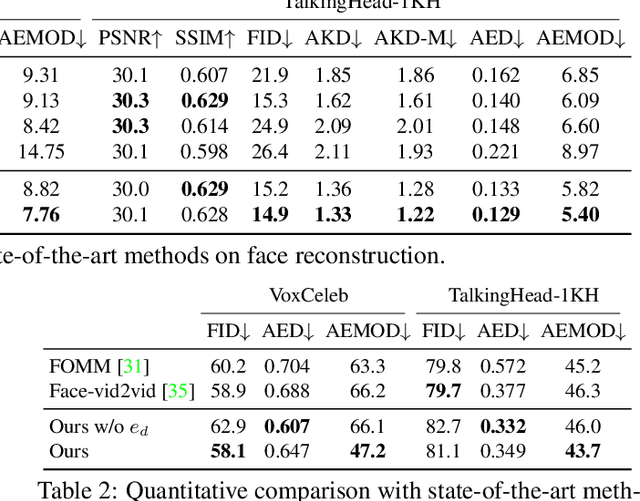
The one-shot talking-head synthesis task aims to animate a source image to another pose and expression, which is dictated by a driving frame. Recent methods rely on warping the appearance feature extracted from the source, by using motion fields estimated from the sparse keypoints, that are learned in an unsupervised manner. Due to their lightweight formulation, they are suitable for video conferencing with reduced bandwidth. However, based on our study, current methods suffer from two major limitations: 1) unsatisfactory generation quality in the case of large head poses and the existence of observable pose misalignment between the source and the first frame in driving videos. 2) fail to capture fine yet critical face motion details due to the lack of semantic understanding and appropriate face geometry regularization. To address these shortcomings, we propose a novel method that leverages the rich face prior information, the proposed model can generate face videos with improved semantic consistency (improve baseline by $7\%$ in average keypoint distance) and expression-preserving (outperform baseline by $15 \%$ in average emotion embedding distance) under equivalent bandwidth. Additionally, incorporating such prior information provides us with a convenient interface to achieve highly controllable generation in terms of both pose and expression.
UCF: Uncovering Common Features for Generalizable Deepfake Detection
Apr 27, 2023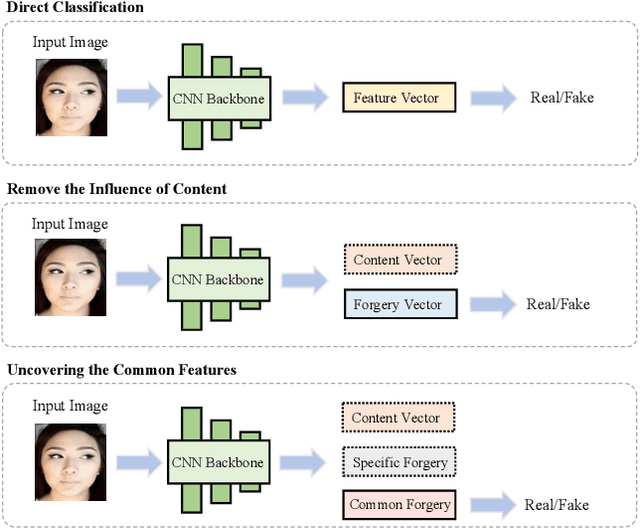

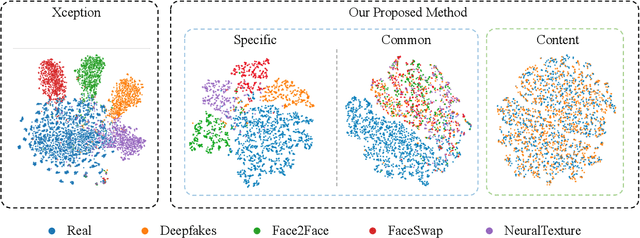
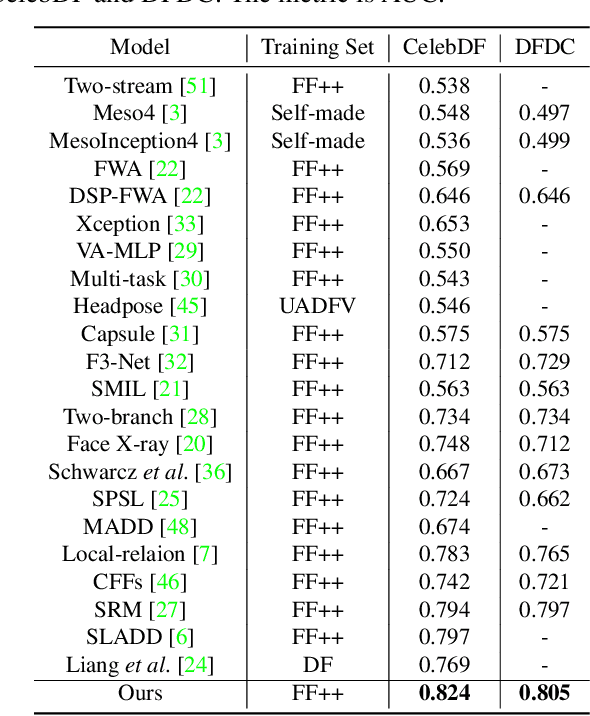
Deepfake detection remains a challenging task due to the difficulty of generalizing to new types of forgeries. This problem primarily stems from the overfitting of existing detection methods to forgery-irrelevant features and method-specific patterns. The latter is often ignored by previous works. This paper presents a novel approach to address the two types of overfitting issues by uncovering common forgery features. Specifically, we first propose a disentanglement framework that decomposes image information into three distinct components: forgery-irrelevant, method-specific forgery, and common forgery features. To ensure the decoupling of method-specific and common forgery features, a multi-task learning strategy is employed, including a multi-class classification that predicts the category of the forgery method and a binary classification that distinguishes the real from the fake. Additionally, a conditional decoder is designed to utilize forgery features as a condition along with forgery-irrelevant features to generate reconstructed images. Furthermore, a contrastive regularization technique is proposed to encourage the disentanglement of the common and specific forgery features. Ultimately, we only utilize the common forgery features for the purpose of generalizable deepfake detection. Extensive evaluations demonstrate that our framework can perform superior generalization than current state-of-the-art methods.
Robust and Fast Vehicle Detection using Augmented Confidence Map
Apr 27, 2023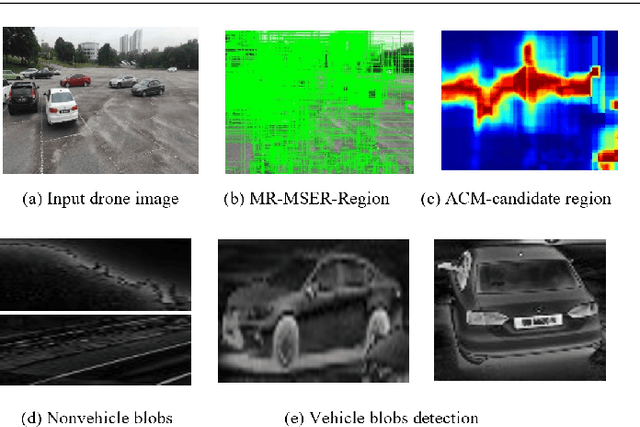


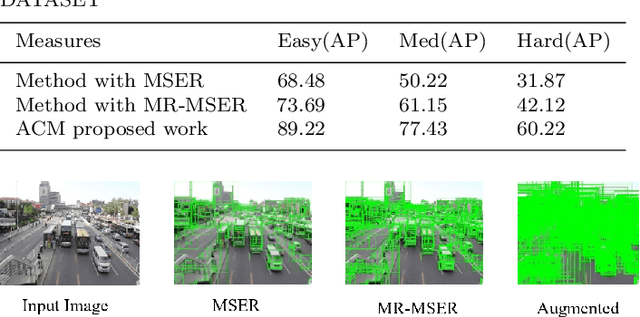
Vehicle detection in real-time scenarios is challenging because of the time constraints and the presence of multiple types of vehicles with different speeds, shapes, structures, etc. This paper presents a new method relied on generating a confidence map-for robust and faster vehicle detection. To reduce the adverse effect of different speeds, shapes, structures, and the presence of several vehicles in a single image, we introduce the concept of augmentation which highlights the region of interest containing the vehicles. The augmented map is generated by exploring the combination of multiresolution analysis and maximally stable extremal regions (MR-MSER). The output of MR-MSER is supplied to fast CNN to generate a confidence map, which results in candidate regions. Furthermore, unlike existing models that implement complicated models for vehicle detection, we explore the combination of a rough set and fuzzy-based models for robust vehicle detection. To show the effectiveness of the proposed method, we conduct experiments on our dataset captured by drones and on several vehicle detection benchmark datasets, namely, KITTI and UA-DETRAC. The results on our dataset and the benchmark datasets show that the proposed method outperforms the existing methods in terms of time efficiency and achieves a good detection rate.
Out-of-distribution detection algorithms for robust insect classification
May 02, 2023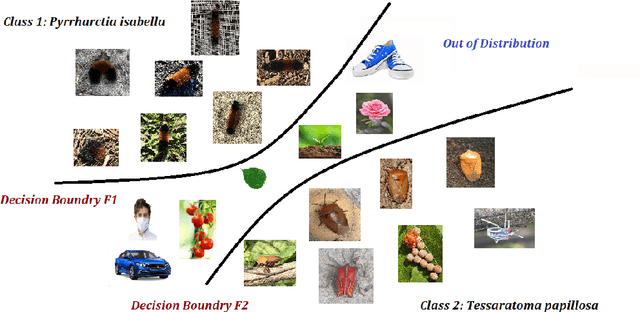
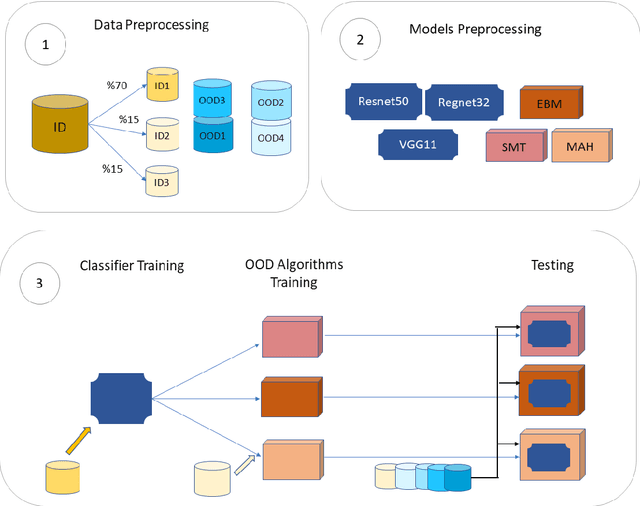
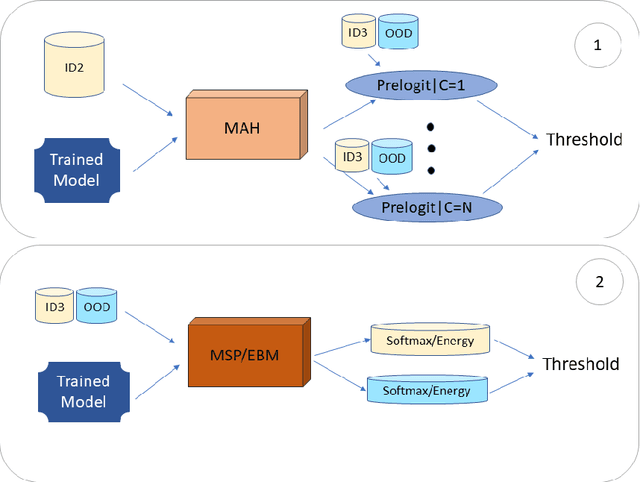

Deep learning-based approaches have produced models with good insect classification accuracy; Most of these models are conducive for application in controlled environmental conditions. One of the primary emphasis of researchers is to implement identification and classification models in the real agriculture fields, which is challenging because input images that are wildly out of the distribution (e.g., images like vehicles, animals, humans, or a blurred image of an insect or insect class that is not yet trained on) can produce an incorrect insect classification. Out-of-distribution (OOD) detection algorithms provide an exciting avenue to overcome these challenge as it ensures that a model abstains from making incorrect classification prediction of non-insect and/or untrained insect class images. We generate and evaluate the performance of state-of-the-art OOD algorithms on insect detection classifiers. These algorithms represent a diversity of methods for addressing an OOD problem. Specifically, we focus on extrusive algorithms, i.e., algorithms that wrap around a well-trained classifier without the need for additional co-training. We compared three OOD detection algorithms: (i) Maximum Softmax Probability, which uses the softmax value as a confidence score, (ii) Mahalanobis distance-based algorithm, which uses a generative classification approach; and (iii) Energy-Based algorithm that maps the input data to a scalar value, called energy. We performed an extensive series of evaluations of these OOD algorithms across three performance axes: (a) \textit{Base model accuracy}: How does the accuracy of the classifier impact OOD performance? (b) How does the \textit{level of dissimilarity to the domain} impact OOD performance? and (c) \textit{Data imbalance}: How sensitive is OOD performance to the imbalance in per-class sample size?
DataComp: In search of the next generation of multimodal datasets
May 03, 2023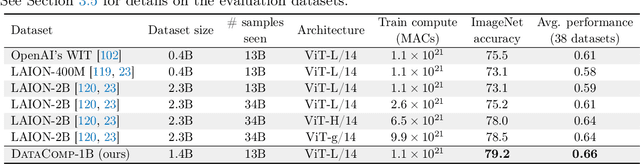
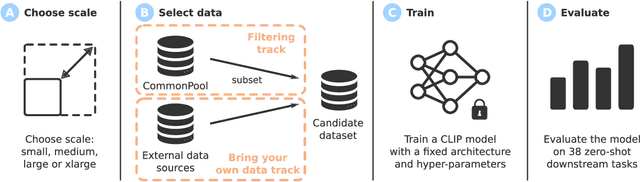


Large multimodal datasets have been instrumental in recent breakthroughs such as CLIP, Stable Diffusion, and GPT-4. At the same time, datasets rarely receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a benchmark where the training code is fixed and researchers innovate by proposing new training sets. We provide a testbed for dataset experiments centered around a new candidate pool of 12.8B image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing on 38 downstream test sets. Our benchmark consists of multiple scales, with four candidate pool sizes and associated compute budgets ranging from 12.8M to 12.8B samples seen during training. This multi-scale design facilitates the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow is a promising way of improving multimodal datasets. We introduce DataComp-1B, a dataset created by applying a simple filtering algorithm to the 12.8B candidate pool. The resulting 1.4B subset enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet. Our new ViT-L/14 model outperforms a larger ViT-g/14 trained on LAION-2B by 0.7 percentage points while requiring 9x less training compute. We also outperform OpenAI's CLIP ViT-L/14 by 3.7 percentage points, which is trained with the same compute budget as our model. These gains highlight the potential for improving model performance by carefully curating training sets. We view DataComp-1B as only the first step and hope that DataComp paves the way toward the next generation of multimodal datasets.