 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Temporally Consistent Online Depth Estimation Using Point-Based Fusion
May 01, 2023

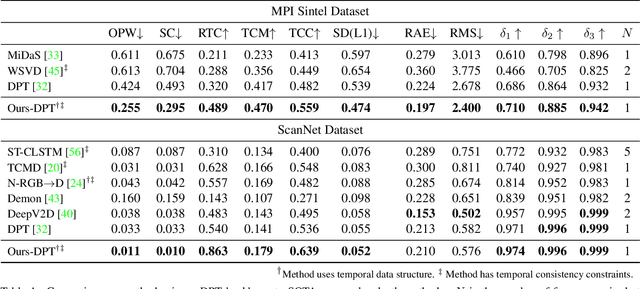
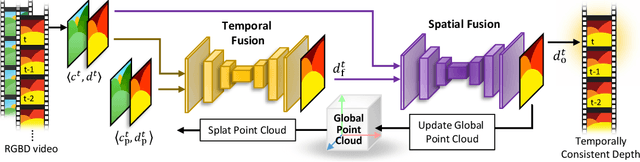
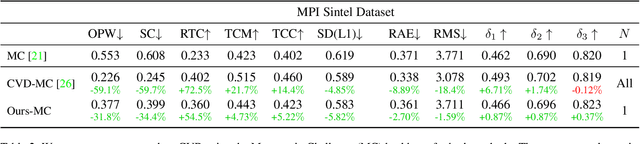
Depth estimation is an important step in many computer vision problems such as 3D reconstruction, novel view synthesis, and computational photography. Most existing work focuses on depth estimation from single frames. When applied to videos, the result lacks temporal consistency, showing flickering and swimming artifacts. In this paper we aim to estimate temporally consistent depth maps of video streams in an online setting. This is a difficult problem as future frames are not available and the method must choose between enforcing consistency and correcting errors from previous estimations. The presence of dynamic objects further complicates the problem. We propose to address these challenges by using a global point cloud that is dynamically updated each frame, along with a learned fusion approach in image space. Our approach encourages consistency while simultaneously allowing updates to handle errors and dynamic objects. Qualitative and quantitative results show that our method achieves state-of-the-art quality for consistent video depth estimation.
* Supplementary video at https://research.facebook.com/publications/temporally-consistent-online-depth-estimation-using-point-based-fusion/
Track Anything: Segment Anything Meets Videos
Apr 28, 2023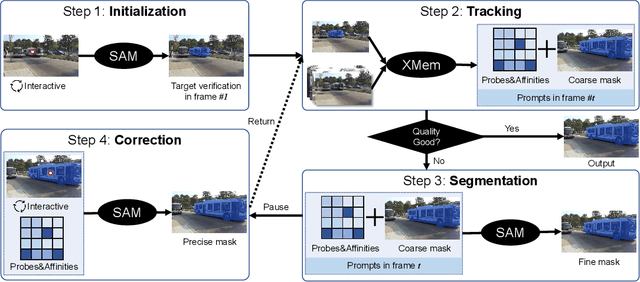
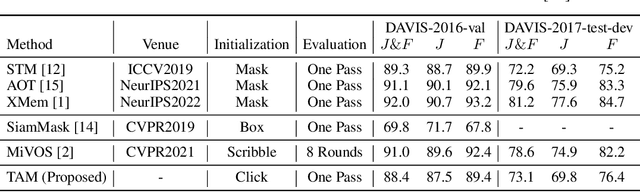


Recently, the Segment Anything Model (SAM) gains lots of attention rapidly due to its impressive segmentation performance on images. Regarding its strong ability on image segmentation and high interactivity with different prompts, we found that it performs poorly on consistent segmentation in videos. Therefore, in this report, we propose Track Anything Model (TAM), which achieves high-performance interactive tracking and segmentation in videos. To be detailed, given a video sequence, only with very little human participation, i.e., several clicks, people can track anything they are interested in, and get satisfactory results in one-pass inference. Without additional training, such an interactive design performs impressively on video object tracking and segmentation. All resources are available on {https://github.com/gaomingqi/Track-Anything}. We hope this work can facilitate related research.
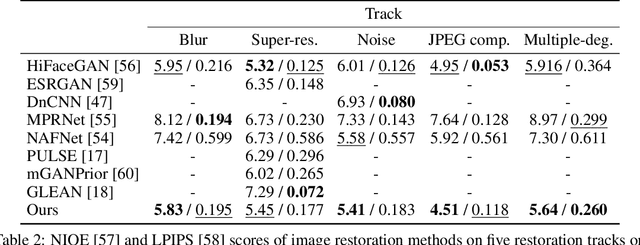
QC-StyleGAN -- Quality Controllable Image Generation and Manipulation
Dec 07, 2022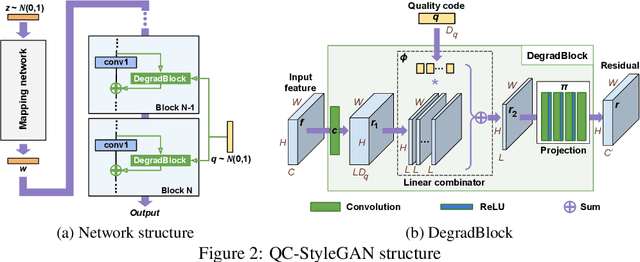


The introduction of high-quality image generation models, particularly the StyleGAN family, provides a powerful tool to synthesize and manipulate images. However, existing models are built upon high-quality (HQ) data as desired outputs, making them unfit for in-the-wild low-quality (LQ) images, which are common inputs for manipulation. In this work, we bridge this gap by proposing a novel GAN structure that allows for generating images with controllable quality. The network can synthesize various image degradation and restore the sharp image via a quality control code. Our proposed QC-StyleGAN can directly edit LQ images without altering their quality by applying GAN inversion and manipulation techniques. It also provides for free an image restoration solution that can handle various degradations, including noise, blur, compression artifacts, and their mixtures. Finally, we demonstrate numerous other applications such as image degradation synthesis, transfer, and interpolation. The code is available at https://github.com/VinAIResearch/QC-StyleGAN.
Sampling is Matter: Point-guided 3D Human Mesh Reconstruction
Apr 19, 2023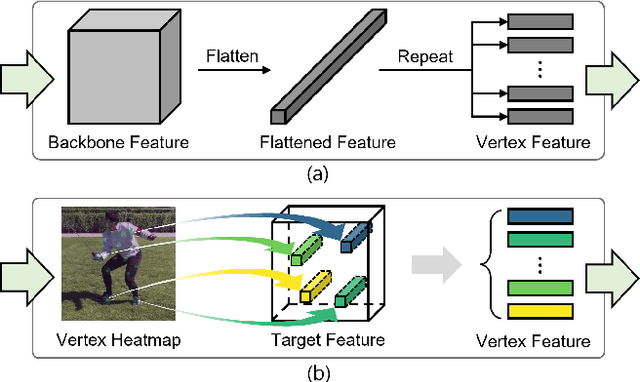
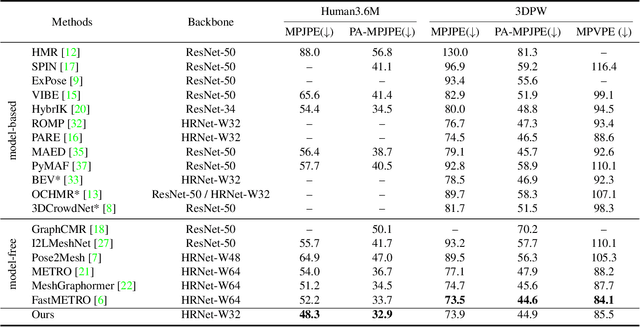
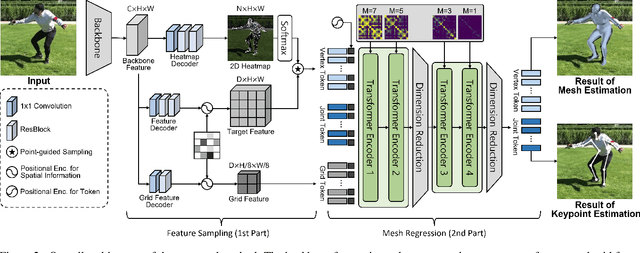
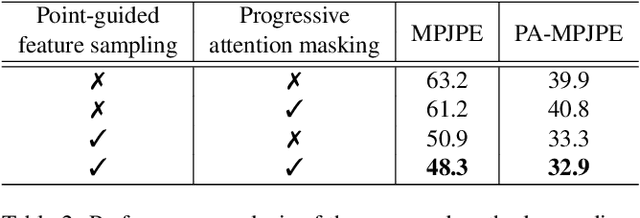
This paper presents a simple yet powerful method for 3D human mesh reconstruction from a single RGB image. Most recently, the non-local interactions of the whole mesh vertices have been effectively estimated in the transformer while the relationship between body parts also has begun to be handled via the graph model. Even though those approaches have shown the remarkable progress in 3D human mesh reconstruction, it is still difficult to directly infer the relationship between features, which are encoded from the 2D input image, and 3D coordinates of each vertex. To resolve this problem, we propose to design a simple feature sampling scheme. The key idea is to sample features in the embedded space by following the guide of points, which are estimated as projection results of 3D mesh vertices (i.e., ground truth). This helps the model to concentrate more on vertex-relevant features in the 2D space, thus leading to the reconstruction of the natural human pose. Furthermore, we apply progressive attention masking to precisely estimate local interactions between vertices even under severe occlusions. Experimental results on benchmark datasets show that the proposed method efficiently improves the performance of 3D human mesh reconstruction. The code and model are publicly available at: https://github.com/DCVL-3D/PointHMR_release.
Interactive Image Manipulation with Complex Text Instructions
Nov 25, 2022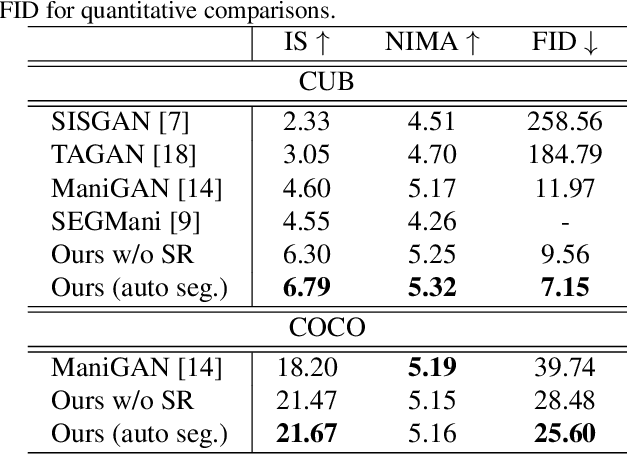
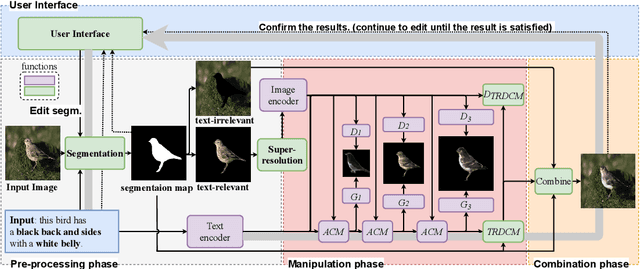
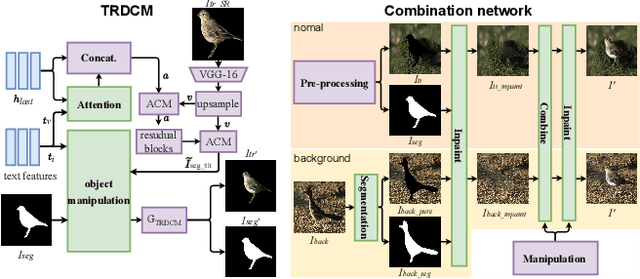

Recently, text-guided image manipulation has received increasing attention in the research field of multimedia processing and computer vision due to its high flexibility and controllability. Its goal is to semantically manipulate parts of an input reference image according to the text descriptions. However, most of the existing works have the following problems: (1) text-irrelevant content cannot always be maintained but randomly changed, (2) the performance of image manipulation still needs to be further improved, (3) only can manipulate descriptive attributes. To solve these problems, we propose a novel image manipulation method that interactively edits an image using complex text instructions. It allows users to not only improve the accuracy of image manipulation but also achieve complex tasks such as enlarging, dwindling, or removing objects and replacing the background with the input image. To make these tasks possible, we apply three strategies. First, the given image is divided into text-relevant content and text-irrelevant content. Only the text-relevant content is manipulated and the text-irrelevant content can be maintained. Second, a super-resolution method is used to enlarge the manipulation region to further improve the operability and to help manipulate the object itself. Third, a user interface is introduced for editing the segmentation map interactively to re-modify the generated image according to the user's desires. Extensive experiments on the Caltech-UCSD Birds-200-2011 (CUB) dataset and Microsoft Common Objects in Context (MS COCO) datasets demonstrate our proposed method can enable interactive, flexible, and accurate image manipulation in real-time. Through qualitative and quantitative evaluations, we show that the proposed model outperforms other state-of-the-art methods.
Image Super-Resolution using Efficient Striped Window Transformer
Jan 24, 2023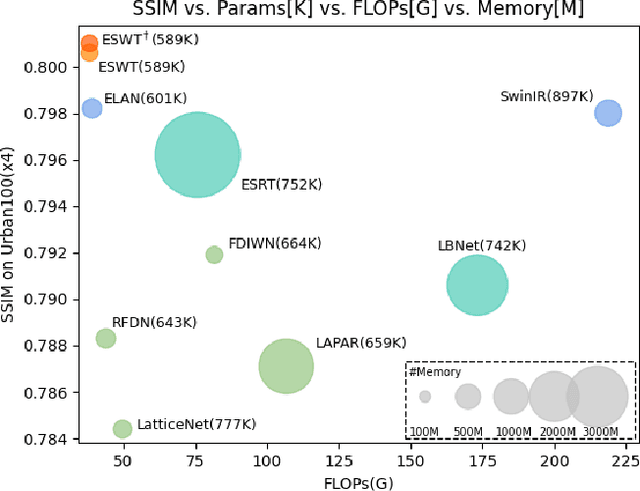
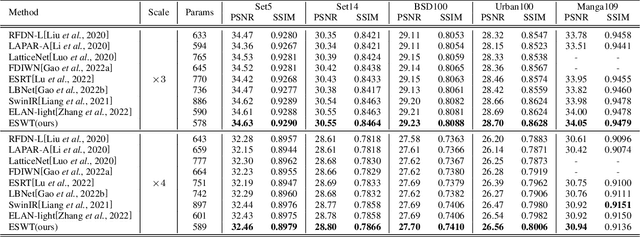
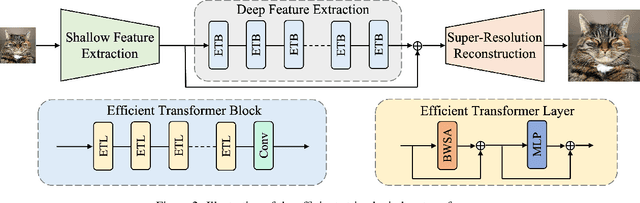
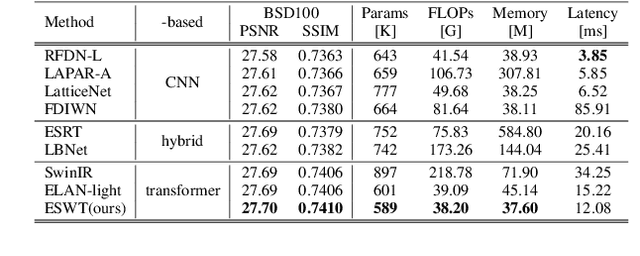
Recently, transformer-based methods have made impressive progress in single-image super-resolu-tion (SR). However, these methods are difficult to apply to lightweight SR (LSR) due to the challenge of balancing model performance and complexity. In this paper, we propose an efficient striped window transformer (ESWT). ESWT consists of efficient transformation layers (ETLs), allowing a clean structure and avoiding redundant operations. Moreover, we designed a striped window mechanism to obtain a more efficient ESWT in modeling long-term dependencies. To further exploit the potential of the transformer, we propose a novel flexible window training strategy. Without any additional cost, this strategy can further improve the performance of ESWT. Extensive experiments show that the proposed method outperforms state-of-the-art transformer-based LSR methods with fewer parameters, faster inference, smaller FLOPs, and less memory consumption, achieving a better trade-off between model performance and complexity.
Synthetic Image Data for Deep Learning
Dec 12, 2022
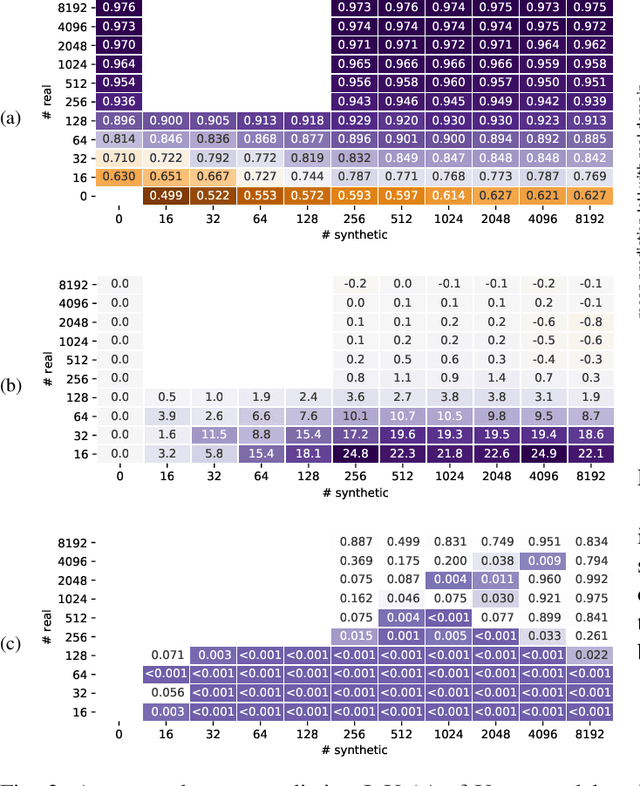
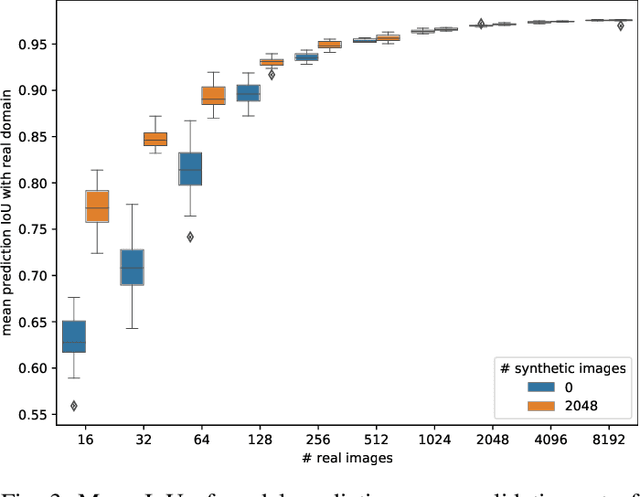
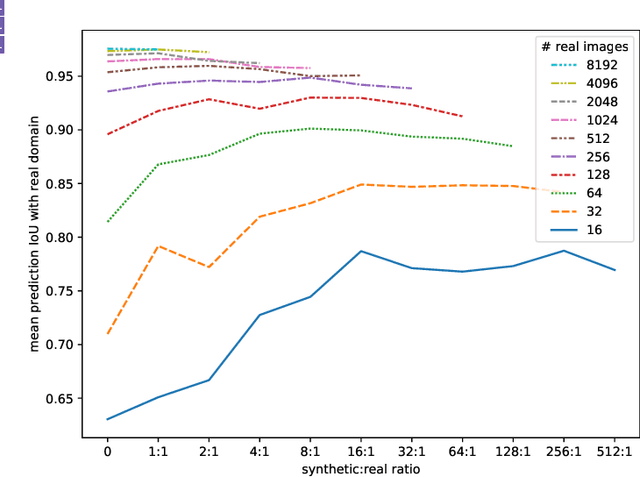
Realistic synthetic image data rendered from 3D models can be used to augment image sets and train image classification semantic segmentation models. In this work, we explore how high quality physically-based rendering and domain randomization can efficiently create a large synthetic dataset based on production 3D CAD models of a real vehicle. We use this dataset to quantify the effectiveness of synthetic augmentation using U-net and Double-U-net models. We found that, for this domain, synthetic images were an effective technique for augmenting limited sets of real training data. We observed that models trained on purely synthetic images had a very low mean prediction IoU on real validation images. We also observed that adding even very small amounts of real images to a synthetic dataset greatly improved accuracy, and that models trained on datasets augmented with synthetic images were more accurate than those trained on real images alone. Finally, we found that in use cases that benefit from incremental training or model specialization, pretraining a base model on synthetic images provided a sizeable reduction in the training cost of transfer learning, allowing up to 90\% of the model training to be front-loaded.
Automated computed tomography and magnetic resonance imaging segmentation using deep learning: a beginner's guide
Apr 12, 2023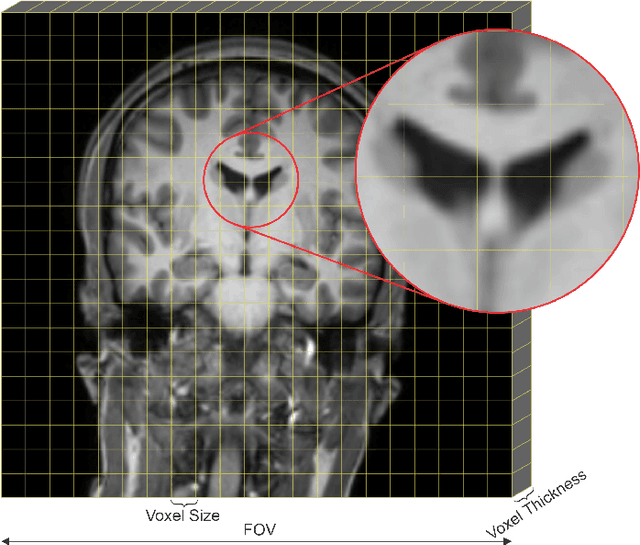
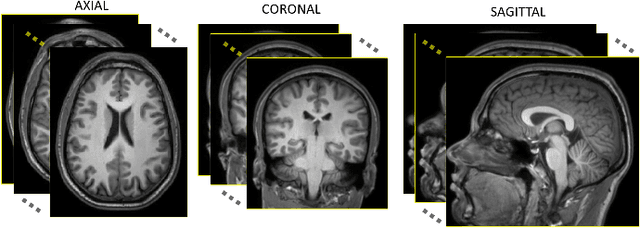
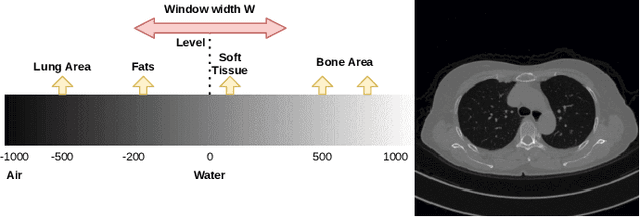
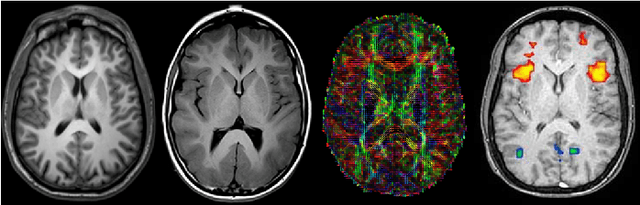
Medical image segmentation is an increasingly popular area of research in medical imaging processing and analysis. However, many researchers who are new to the field struggle with basic concepts. This tutorial paper aims to provide an overview of the fundamental concepts of medical imaging, with a focus on Magnetic Resonance and Computerized Tomography. We will also discuss deep learning algorithms, tools, and frameworks used for segmentation tasks, and suggest best practices for method development and image analysis. Our tutorial includes sample tasks using public data, and accompanying code is available on GitHub (https://github.com/MICLab-Unicamp/Medical-ImagingTutorial). By sharing our insights gained from years of experience in the field and learning from relevant literature, we hope to assist researchers in overcoming the initial challenges they may encounter in this exciting and important area of research.
MAGVLT: Masked Generative Vision-and-Language Transformer
Mar 21, 2023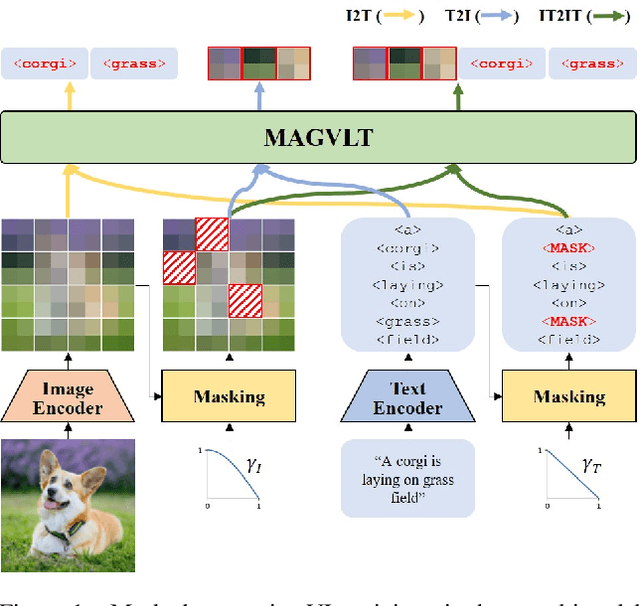
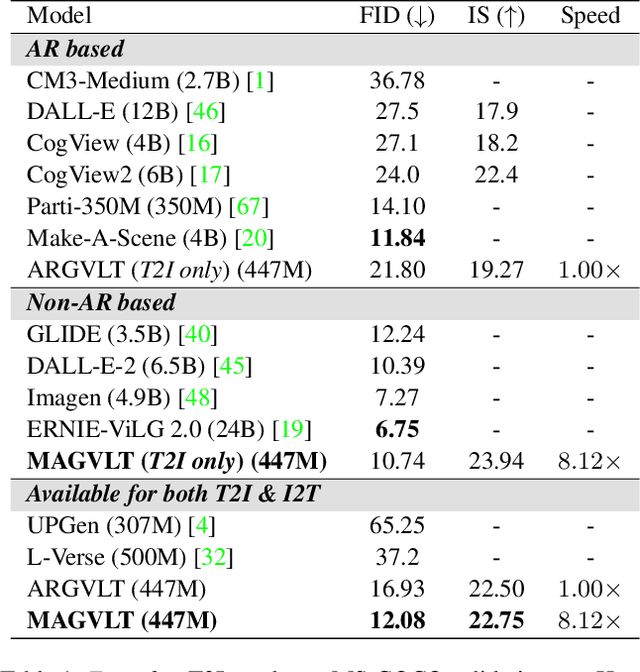
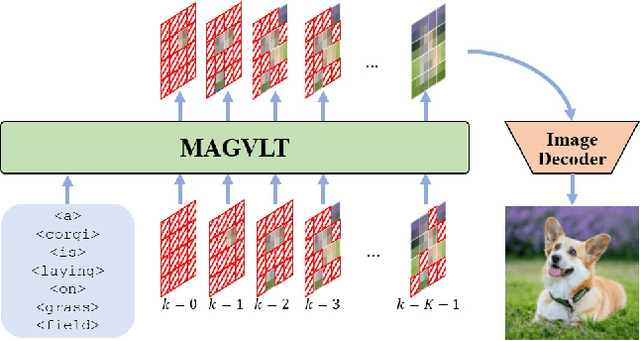
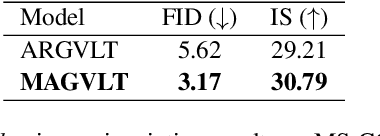
While generative modeling on multimodal image-text data has been actively developed with large-scale paired datasets, there have been limited attempts to generate both image and text data by a single model rather than a generation of one fixed modality conditioned on the other modality. In this paper, we explore a unified generative vision-and-language (VL) model that can produce both images and text sequences. Especially, we propose a generative VL transformer based on the non-autoregressive mask prediction, named MAGVLT, and compare it with an autoregressive generative VL transformer (ARGVLT). In comparison to ARGVLT, the proposed MAGVLT enables bidirectional context encoding, fast decoding by parallel token predictions in an iterative refinement, and extended editing capabilities such as image and text infilling. For rigorous training of our MAGVLT with image-text pairs from scratch, we combine the image-to-text, text-to-image, and joint image-and-text mask prediction tasks. Moreover, we devise two additional tasks based on the step-unrolled mask prediction and the selective prediction on the mixture of two image-text pairs. Experimental results on various downstream generation tasks of VL benchmarks show that our MAGVLT outperforms ARGVLT by a large margin even with significant inference speedup. Particularly, MAGVLT achieves competitive results on both zero-shot image-to-text and text-to-image generation tasks from MS-COCO by one moderate-sized model (fewer than 500M parameters) even without the use of monomodal data and networks.
Magnification Invariant Medical Image Analysis: A Comparison of Convolutional Networks, Vision Transformers, and Token Mixers
Feb 22, 2023
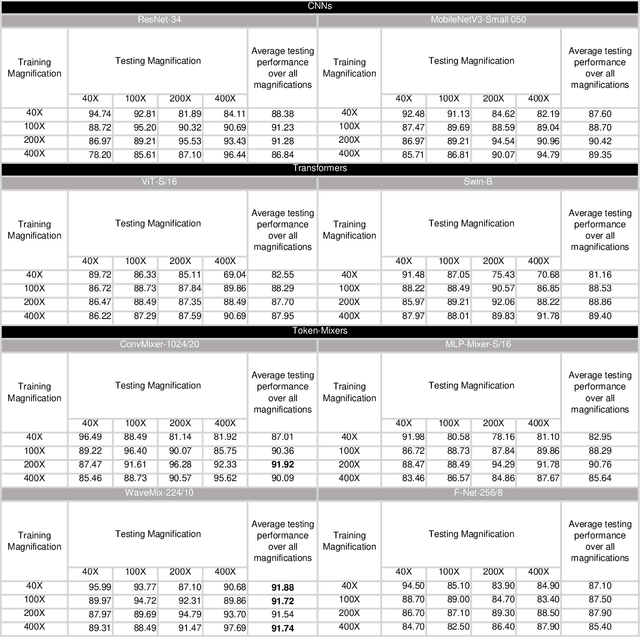
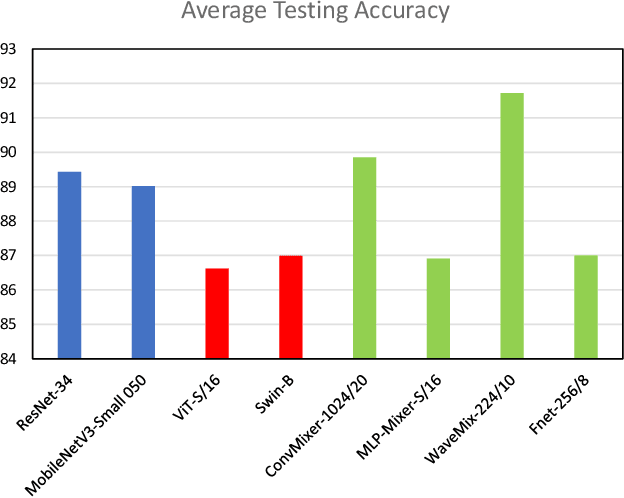
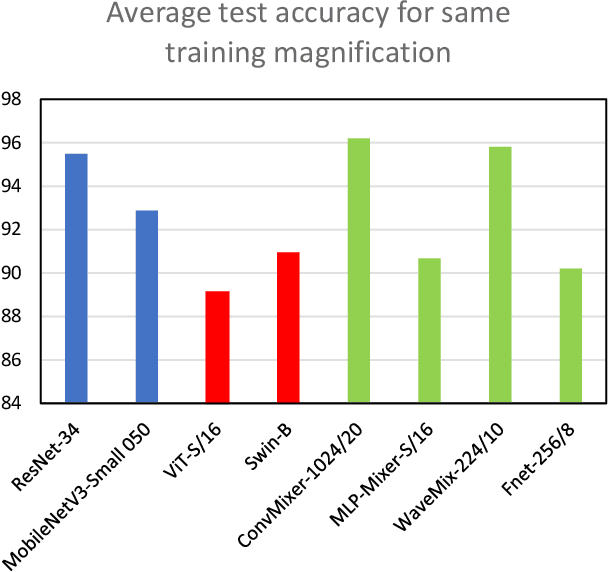
Convolution Neural Networks (CNNs) are widely used in medical image analysis, but their performance degrade when the magnification of testing images differ from the training images. The inability of CNNs to generalize across magnification scales can result in sub-optimal performance on external datasets. This study aims to evaluate the robustness of various deep learning architectures in the analysis of breast cancer histopathological images with varying magnification scales at training and testing stages. Here we explore and compare the performance of multiple deep learning architectures, including CNN-based ResNet and MobileNet, self-attention-based Vision Transformers and Swin Transformers, and token-mixing models, such as FNet, ConvMixer, MLP-Mixer, and WaveMix. The experiments are conducted using the BreakHis dataset, which contains breast cancer histopathological images at varying magnification levels. We show that performance of WaveMix is invariant to the magnification of training and testing data and can provide stable and good classification accuracy. These evaluations are critical in identifying deep learning architectures that can robustly handle changes in magnification scale, ensuring that scale changes across anatomical structures do not disturb the inference results.