 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Domain Adaptive Multiple Instance Learning for Instance-level Prediction of Pathological Images
Apr 07, 2023
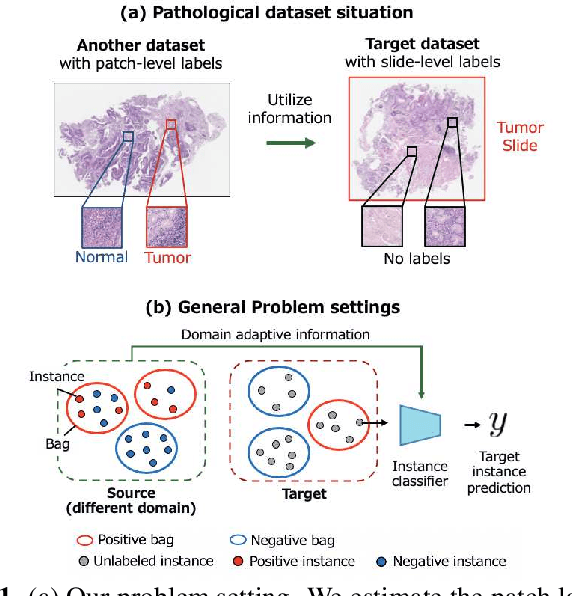
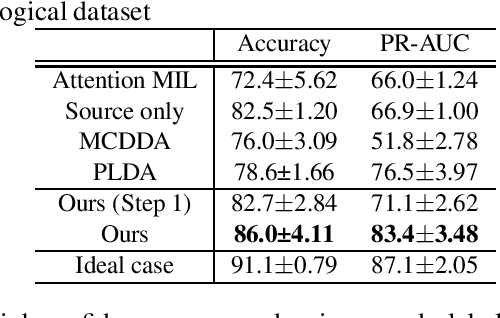
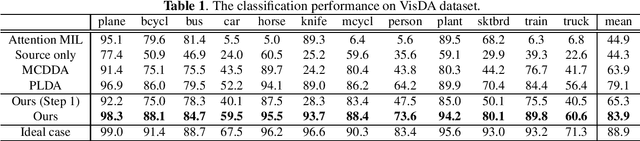
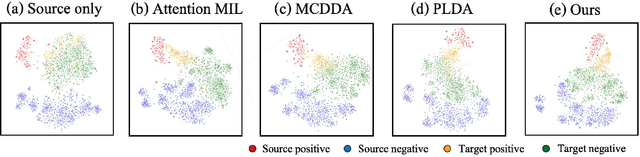
Pathological image analysis is an important process for detecting abnormalities such as cancer from cell images. However, since the image size is generally very large, the cost of providing detailed annotations is high, which makes it difficult to apply machine learning techniques. One way to improve the performance of identifying abnormalities while keeping the annotation cost low is to use only labels for each slide, or to use information from another dataset that has already been labeled. However, such weak supervisory information often does not provide sufficient performance. In this paper, we proposed a new task setting to improve the classification performance of the target dataset without increasing annotation costs. And to solve this problem, we propose a pipeline that uses multiple instance learning (MIL) and domain adaptation (DA) methods. Furthermore, in order to combine the supervisory information of both methods effectively, we propose a method to create pseudo-labels with high confidence. We conducted experiments on the pathological image dataset we created for this study and showed that the proposed method significantly improves the classification performance compared to existing methods.
Hierarchical B-frame Video Coding Using Two-Layer CANF without Motion Coding
Apr 05, 2023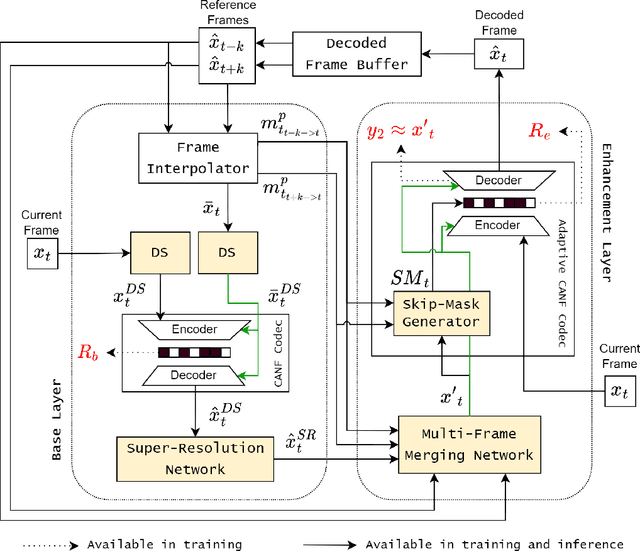
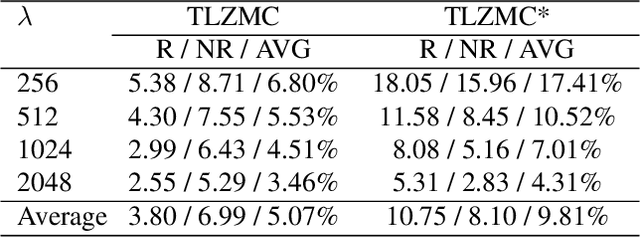
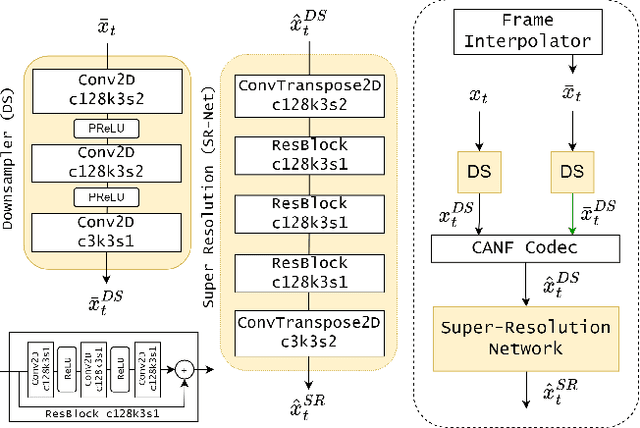
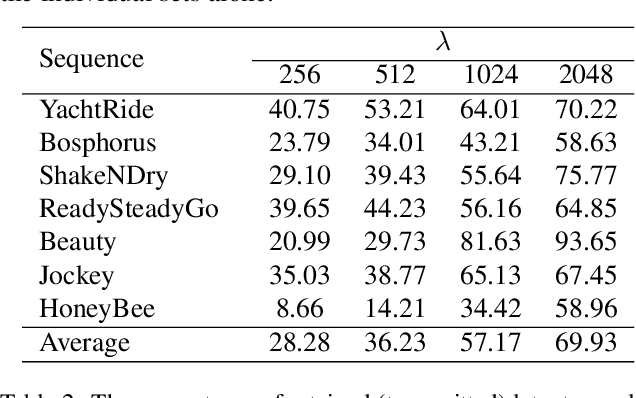
Typical video compression systems consist of two main modules: motion coding and residual coding. This general architecture is adopted by classical coding schemes (such as international standards H.265 and H.266) and deep learning-based coding schemes. We propose a novel B-frame coding architecture based on two-layer Conditional Augmented Normalization Flows (CANF). It has the striking feature of not transmitting any motion information. Our proposed idea of video compression without motion coding offers a new direction for learned video coding. Our base layer is a low-resolution image compressor that replaces the full-resolution motion compressor. The low-resolution coded image is merged with the warped high-resolution images to generate a high-quality image as a conditioning signal for the enhancement-layer image coding in full resolution. One advantage of this architecture is significantly reduced computational complexity due to eliminating the motion information compressor. In addition, we adopt a skip-mode coding technique to reduce the transmitted latent samples. The rate-distortion performance of our scheme is slightly lower than that of the state-of-the-art learned B-frame coding scheme, B-CANF, but outperforms other learned B-frame coding schemes. However, compared to B-CANF, our scheme saves 45% of multiply-accumulate operations (MACs) for encoding and 27% of MACs for decoding. The code is available at https://nycu-clab.github.io.
CABM: Content-Aware Bit Mapping for Single Image Super-Resolution Network with Large Input
Apr 13, 2023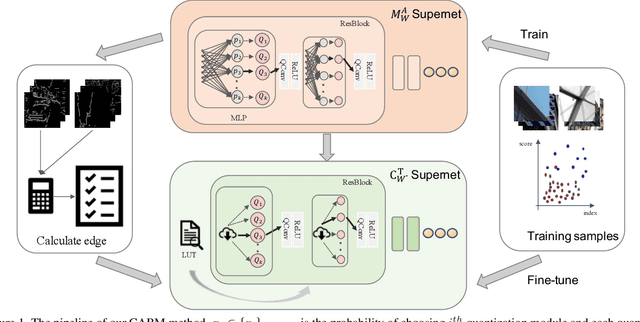
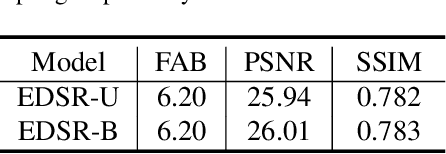


With the development of high-definition display devices, the practical scenario of Super-Resolution (SR) usually needs to super-resolve large input like 2K to higher resolution (4K/8K). To reduce the computational and memory cost, current methods first split the large input into local patches and then merge the SR patches into the output. These methods adaptively allocate a subnet for each patch. Quantization is a very important technique for network acceleration and has been used to design the subnets. Current methods train an MLP bit selector to determine the propoer bit for each layer. However, they uniformly sample subnets for training, making simple subnets overfitted and complicated subnets underfitted. Therefore, the trained bit selector fails to determine the optimal bit. Apart from this, the introduced bit selector brings additional cost to each layer of the SR network. In this paper, we propose a novel method named Content-Aware Bit Mapping (CABM), which can remove the bit selector without any performance loss. CABM also learns a bit selector for each layer during training. After training, we analyze the relation between the edge information of an input patch and the bit of each layer. We observe that the edge information can be an effective metric for the selected bit. Therefore, we design a strategy to build an Edge-to-Bit lookup table that maps the edge score of a patch to the bit of each layer during inference. The bit configuration of SR network can be determined by the lookup tables of all layers. Our strategy can find better bit configuration, resulting in more efficient mixed precision networks. We conduct detailed experiments to demonstrate the generalization ability of our method. The code will be released.
Robust Natural Language Watermarking through Invariant Features
May 03, 2023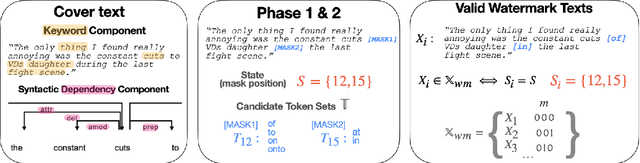
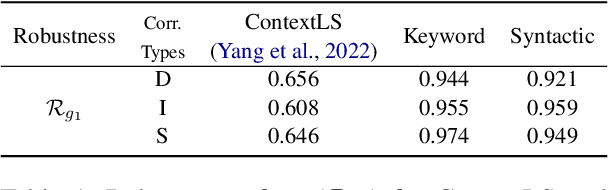
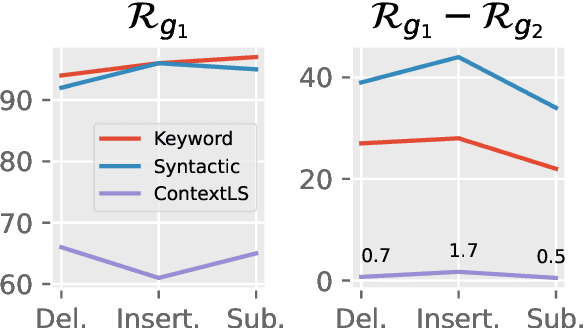
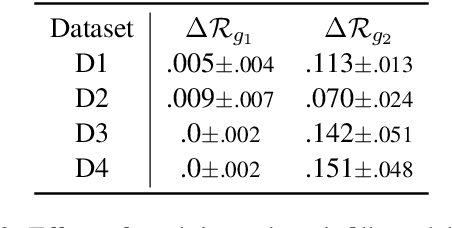
Recent years have witnessed a proliferation of valuable original natural language contents found in subscription-based media outlets, web novel platforms, and outputs of large language models. Without proper security measures, however, these contents are susceptible to illegal piracy and potential misuse. This calls for a secure watermarking system to guarantee copyright protection through leakage tracing or ownership identification. To effectively combat piracy and protect copyrights, a watermarking framework should be able not only to embed adequate bits of information but also extract the watermarks in a robust manner despite possible corruption. In this work, we explore ways to advance both payload and robustness by following a well-known proposition from image watermarking and identify features in natural language that are invariant to minor corruption. Through a systematic analysis of the possible sources of errors, we further propose a corruption-resistant infill model. Our full method improves upon the previous work on robustness by +16.8% point on average on four datasets, three corruption types, and two corruption ratios. Code available at https://github.com/bangawayoo/nlp-watermarking.
X-LLM: Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages
May 10, 2023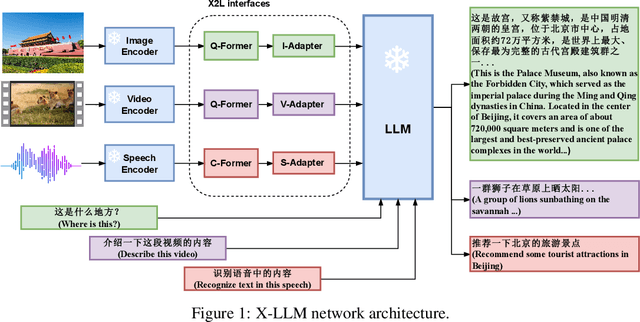
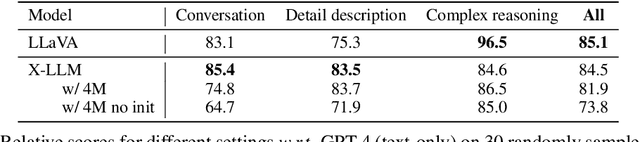


Large language models (LLMs) have demonstrated remarkable language abilities. GPT-4, based on advanced LLMs, exhibits extraordinary multimodal capabilities beyond previous visual language models. We attribute this to the use of more advanced LLMs compared with previous multimodal models. Unfortunately, the model architecture and training strategies of GPT-4 are unknown. To endow LLMs with multimodal capabilities, we propose X-LLM, which converts Multi-modalities (images, speech, videos) into foreign languages using X2L interfaces and inputs them into a large Language model (ChatGLM). Specifically, X-LLM aligns multiple frozen single-modal encoders and a frozen LLM using X2L interfaces, where ``X'' denotes multi-modalities such as image, speech, and videos, and ``L'' denotes languages. X-LLM's training consists of three stages: (1) Converting Multimodal Information: The first stage trains each X2L interface to align with its respective single-modal encoder separately to convert multimodal information into languages. (2) Aligning X2L representations with the LLM: single-modal encoders are aligned with the LLM through X2L interfaces independently. (3) Integrating multiple modalities: all single-modal encoders are aligned with the LLM through X2L interfaces to integrate multimodal capabilities into the LLM. Our experiments show that X-LLM demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 84.5\% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. And we also conduct quantitative tests on using LLM for ASR and multimodal ASR, hoping to promote the era of LLM-based speech recognition.
Fair Federated Medical Image Segmentation via Client Contribution Estimation
Mar 29, 2023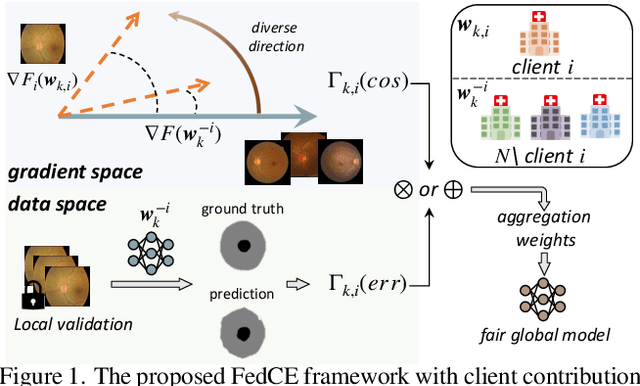
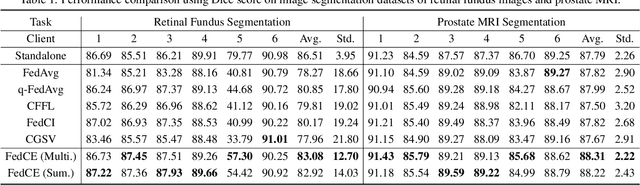
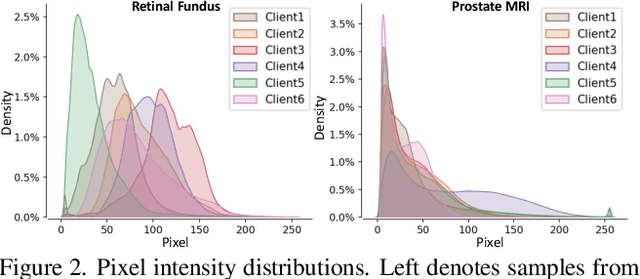
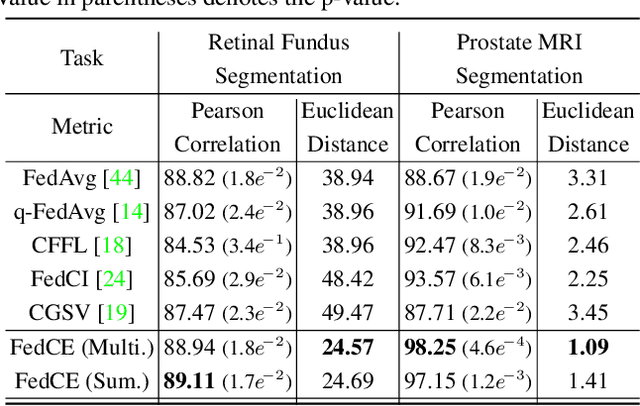
How to ensure fairness is an important topic in federated learning (FL). Recent studies have investigated how to reward clients based on their contribution (collaboration fairness), and how to achieve uniformity of performance across clients (performance fairness). Despite achieving progress on either one, we argue that it is critical to consider them together, in order to engage and motivate more diverse clients joining FL to derive a high-quality global model. In this work, we propose a novel method to optimize both types of fairness simultaneously. Specifically, we propose to estimate client contribution in gradient and data space. In gradient space, we monitor the gradient direction differences of each client with respect to others. And in data space, we measure the prediction error on client data using an auxiliary model. Based on this contribution estimation, we propose a FL method, federated training via contribution estimation (FedCE), i.e., using estimation as global model aggregation weights. We have theoretically analyzed our method and empirically evaluated it on two real-world medical datasets. The effectiveness of our approach has been validated with significant performance improvements, better collaboration fairness, better performance fairness, and comprehensive analytical studies.
Adaptive Blind Watermarking Using Psychovisual Image Features
Dec 25, 2022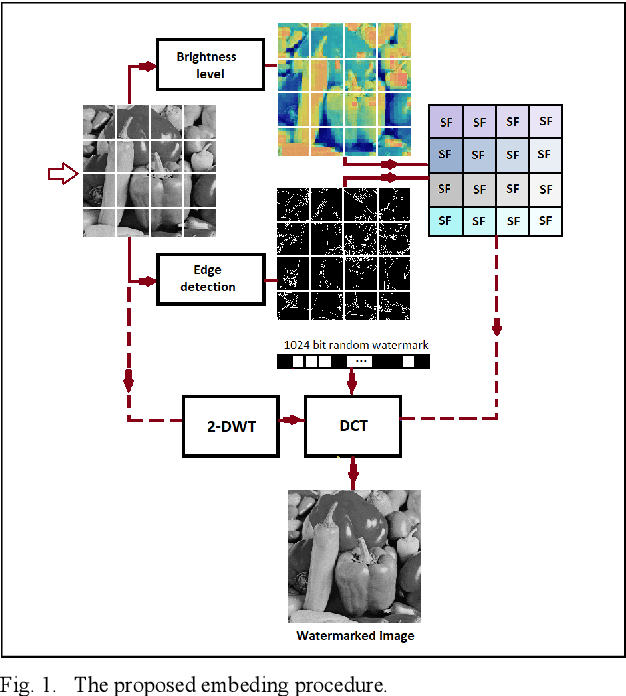
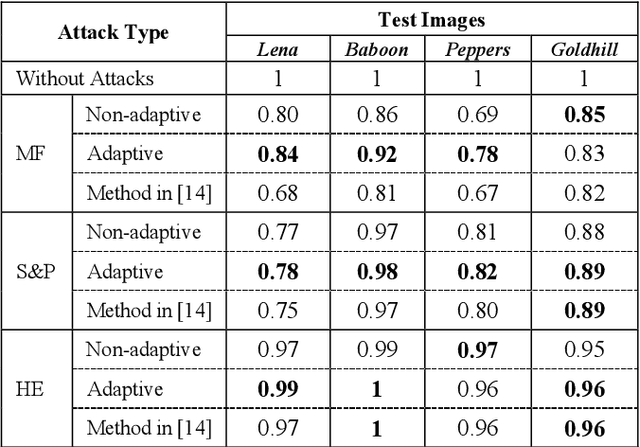
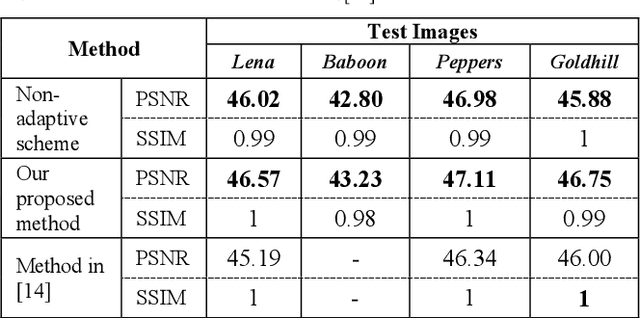
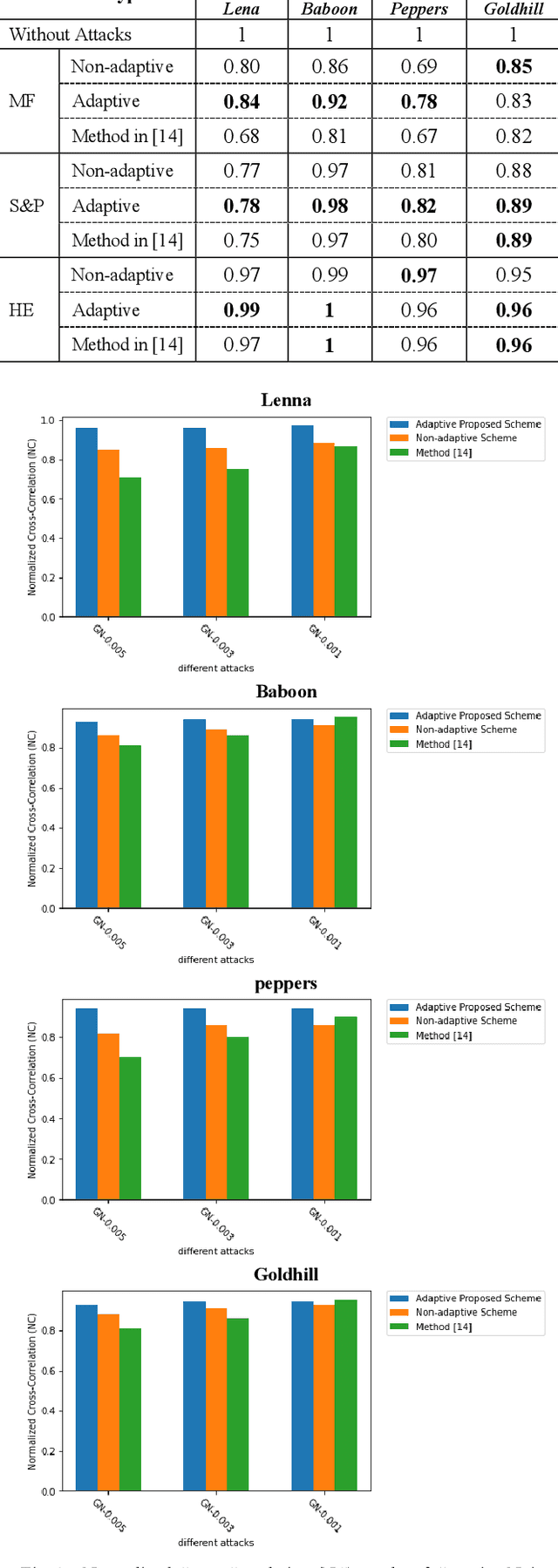
With the growth of editing and sharing images through the internet, the importance of protecting the images' authorship has increased. Robust watermarking is a known approach to maintaining copyright protection. Robustness and imperceptibility are two factors that are tried to be maximized through watermarking. Usually, there is a trade-off between these two parameters. Increasing the robustness would lessen the imperceptibility of the watermarking. This paper proposes an adaptive method that determines the strength of the watermark embedding in different parts of the cover image regarding its texture and brightness. Adaptive embedding increases the robustness while preserving the quality of the watermarked image. Experimental results also show that the proposed method can effectively reconstruct the embedded payload in different kinds of common watermarking attacks. Our proposed method has shown good performance compared to a recent technique.
PanoViT: Vision Transformer for Room Layout Estimation from a Single Panoramic Image
Dec 23, 2022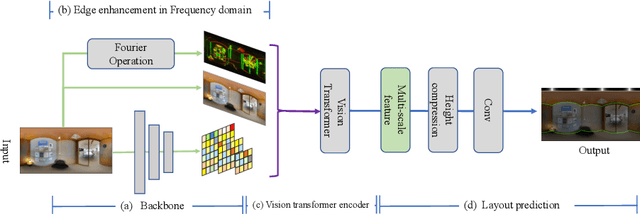
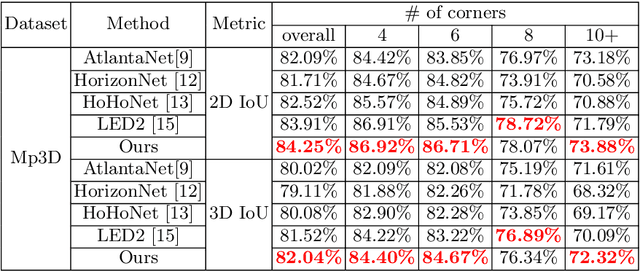
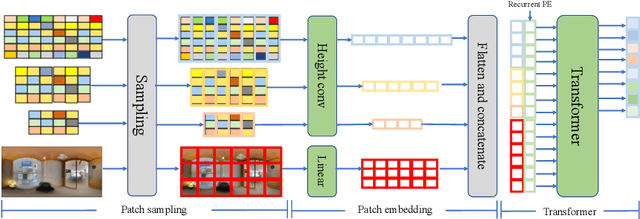
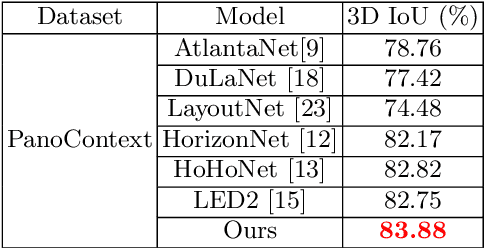
In this paper, we propose PanoViT, a panorama vision transformer to estimate the room layout from a single panoramic image. Compared to CNN models, our PanoViT is more proficient in learning global information from the panoramic image for the estimation of complex room layouts. Considering the difference between a perspective image and an equirectangular image, we design a novel recurrent position embedding and a patch sampling method for the processing of panoramic images. In addition to extracting global information, PanoViT also includes a frequency-domain edge enhancement module and a 3D loss to extract local geometric features in a panoramic image. Experimental results on several datasets demonstrate that our method outperforms state-of-the-art solutions in room layout prediction accuracy.
Contour Completion by Transformers and Its Application to Vector Font Data
Apr 27, 2023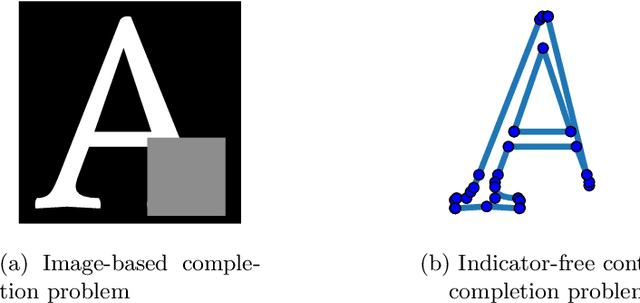
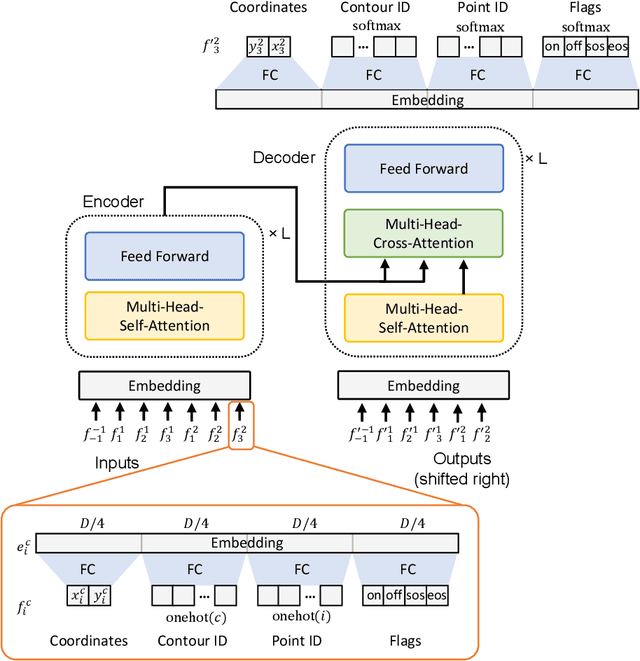
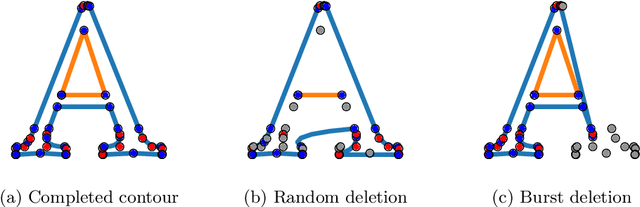
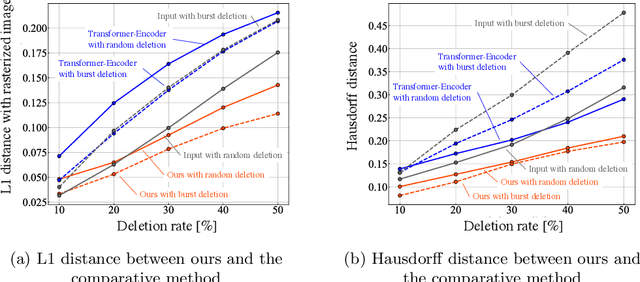
In documents and graphics, contours are a popular format to describe specific shapes. For example, in the True Type Font (TTF) file format, contours describe vector outlines of typeface shapes. Each contour is often defined as a sequence of points. In this paper, we tackle the contour completion task. In this task, the input is a contour sequence with missing points, and the output is a generated completed contour. This task is more difficult than image completion because, for images, the missing pixels are indicated. Since there is no such indication in the contour completion task, we must solve the problem of missing part detection and completion simultaneously. We propose a Transformer-based method to solve this problem and show the results of the typeface contour completion.
DATE: Domain Adaptive Product Seeker for E-commerce
Apr 07, 2023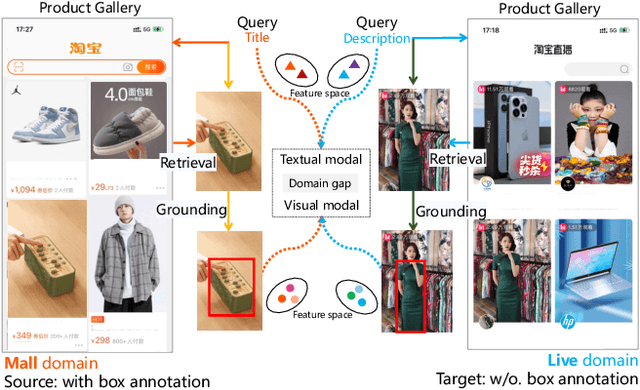
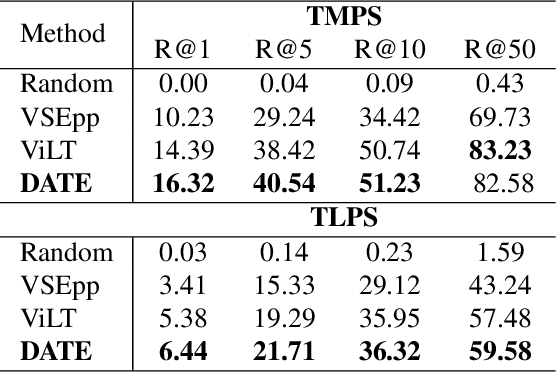
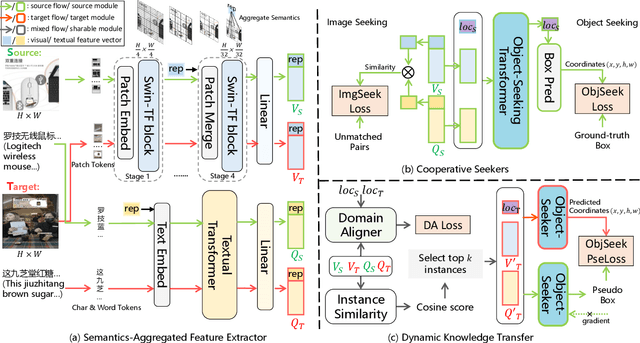
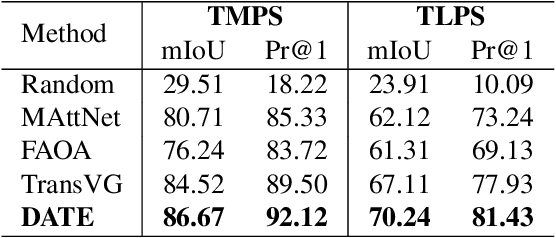
Product Retrieval (PR) and Grounding (PG), aiming to seek image and object-level products respectively according to a textual query, have attracted great interest recently for better shopping experience. Owing to the lack of relevant datasets, we collect two large-scale benchmark datasets from Taobao Mall and Live domains with about 474k and 101k image-query pairs for PR, and manually annotate the object bounding boxes in each image for PG. As annotating boxes is expensive and time-consuming, we attempt to transfer knowledge from annotated domain to unannotated for PG to achieve un-supervised Domain Adaptation (PG-DA). We propose a {\bf D}omain {\bf A}daptive Produc{\bf t} S{\bf e}eker ({\bf DATE}) framework, regarding PR and PG as Product Seeking problem at different levels, to assist the query {\bf date} the product. Concretely, we first design a semantics-aggregated feature extractor for each modality to obtain concentrated and comprehensive features for following efficient retrieval and fine-grained grounding tasks. Then, we present two cooperative seekers to simultaneously search the image for PR and localize the product for PG. Besides, we devise a domain aligner for PG-DA to alleviate uni-modal marginal and multi-modal conditional distribution shift between source and target domains, and design a pseudo box generator to dynamically select reliable instances and generate bounding boxes for further knowledge transfer. Extensive experiments show that our DATE achieves satisfactory performance in fully-supervised PR, PG and un-supervised PG-DA. Our desensitized datasets will be publicly available here\footnote{\url{https://github.com/Taobao-live/Product-Seeking}}.