 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
EKILA: Synthetic Media Provenance and Attribution for Generative Art
Apr 10, 2023
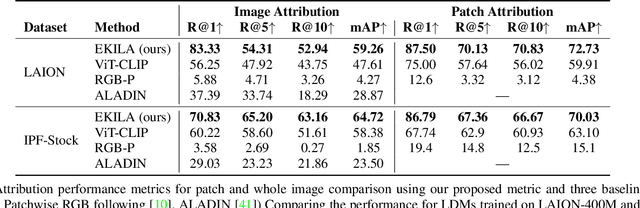
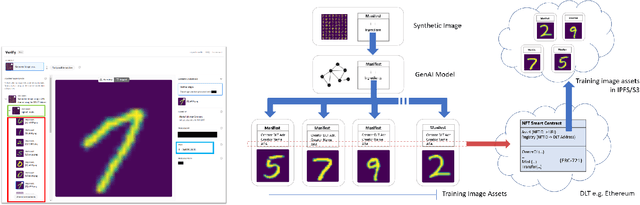
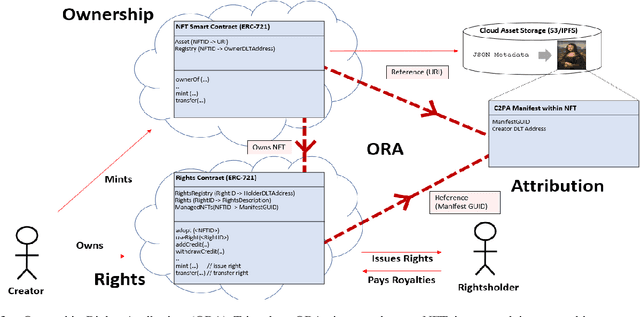

We present EKILA; a decentralized framework that enables creatives to receive recognition and reward for their contributions to generative AI (GenAI). EKILA proposes a robust visual attribution technique and combines this with an emerging content provenance standard (C2PA) to address the problem of synthetic image provenance -- determining the generative model and training data responsible for an AI-generated image. Furthermore, EKILA extends the non-fungible token (NFT) ecosystem to introduce a tokenized representation for rights, enabling a triangular relationship between the asset's Ownership, Rights, and Attribution (ORA). Leveraging the ORA relationship enables creators to express agency over training consent and, through our attribution model, to receive apportioned credit, including royalty payments for the use of their assets in GenAI.
FAST: Feature Arrangement for Semantic Transmission
May 05, 2023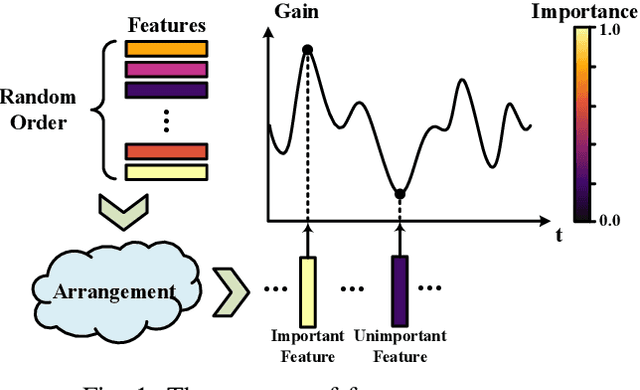
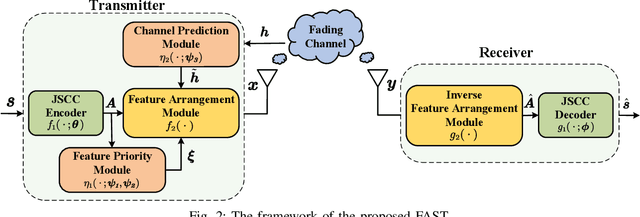
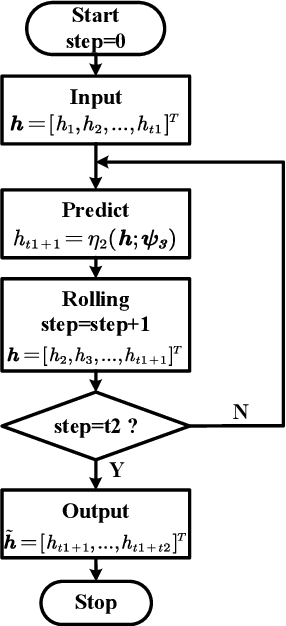
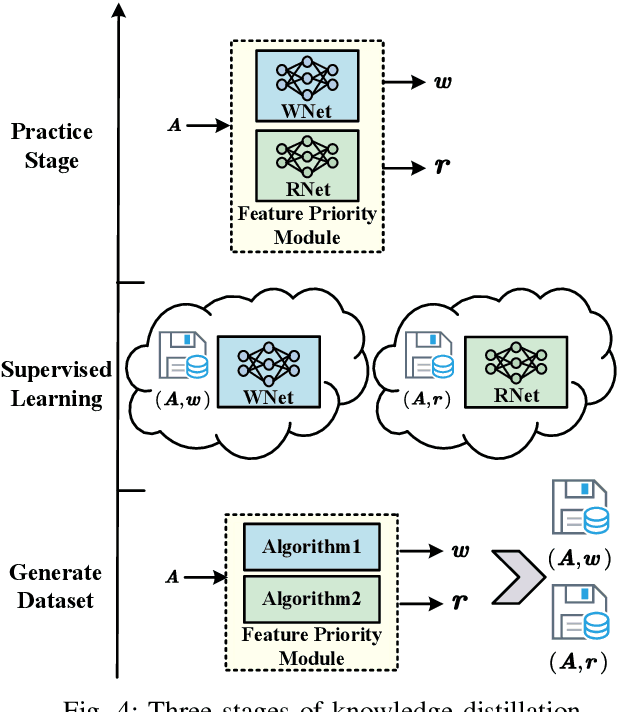
Although existing semantic communication systems have achieved great success, they have not considered that the channel is time-varying wherein deep fading occurs occasionally. Moreover, the importance of each semantic feature differs from each other. Consequently, the important features may be affected by channel fading and corrupted, resulting in performance degradation. Therefore, higher performance can be achieved by avoiding the transmission of important features when the channel state is poor. In this paper, we propose a scheme of Feature Arrangement for Semantic Transmission (FAST). In particular, we aim to schedule the transmission order of features and transmit important features when the channel state is good. To this end, we first propose a novel metric termed feature priority, which takes into consideration both feature importance and feature robustness. Then, we perform channel prediction at the transmitter side to obtain the future channel state information (CSI). Furthermore, the feature arrangement module is developed based on the proposed feature priority and the predicted CSI by transmitting the prior features under better CSI. Simulation results show that the proposed scheme significantly improves the performance of image transmission compared to existing semantic communication systems without feature arrangement.
Deep Learning-based Estimation for Multitarget Radar Detection
May 05, 2023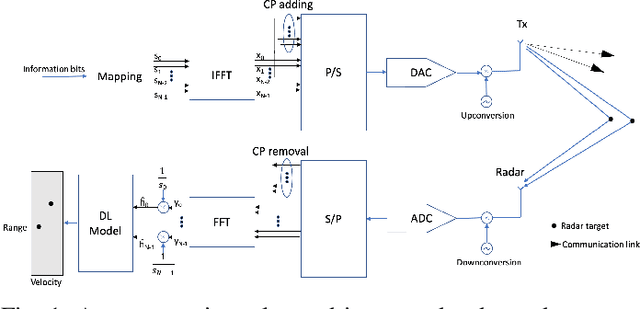
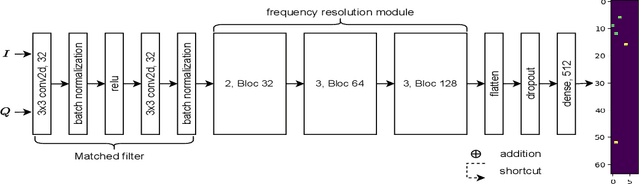
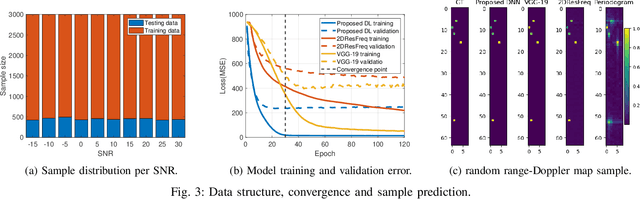
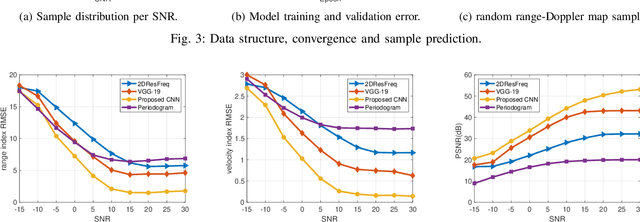
Target detection and recognition is a very challenging task in a wireless environment where a multitude of objects are located, whether to effectively determine their positions or to identify them and predict their moves. In this work, we propose a new method based on a convolutional neural network (CNN) to estimate the range and velocity of moving targets directly from the range-Doppler map of the detected signals. We compare the obtained results to the two dimensional (2D) periodogram, and to the similar state of the art methods, 2DResFreq and VGG-19 network and show that the estimation process performed with our model provides better estimation accuracy of range and velocity index in different signal to noise ratio (SNR) regimes along with a reduced prediction time. Afterwards, we assess the performance of our proposed algorithm using the peak signal to noise ratio (PSNR) which is a relevant metric to analyse the quality of an output image obtained from compression or noise reduction. Compared to the 2D-periodogram, 2DResFreq and VGG-19, we gain 33 dB, 21 dB and 10 dB, respectively, in terms of PSNR when SNR = 30 dB.
3rd Place Solution to Meta AI Video Similarity Challenge
Apr 24, 2023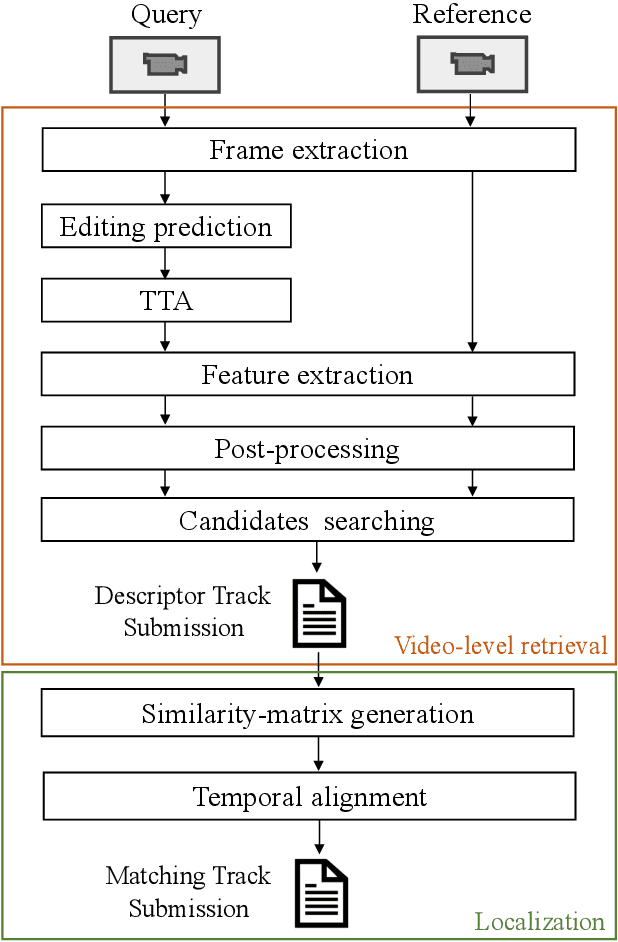
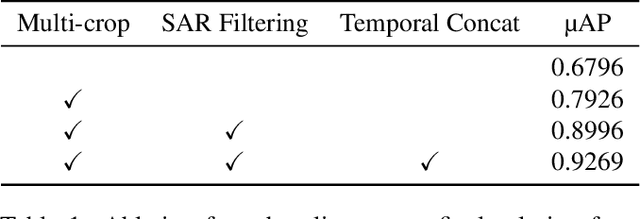
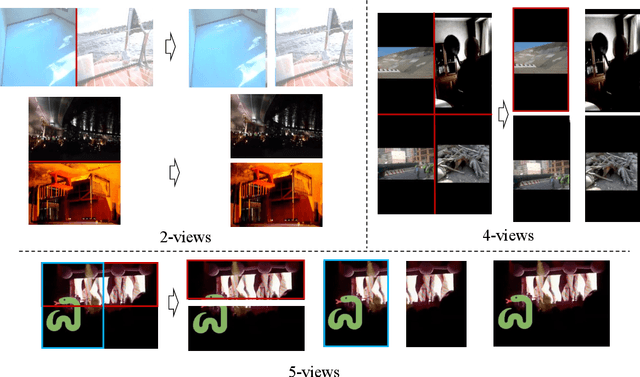

This paper presents our 3rd place solution in both Descriptor Track and Matching Track of the Meta AI Video Similarity Challenge (VSC2022), a competition aimed at detecting video copies. Our approach builds upon existing image copy detection techniques and incorporates several strategies to exploit on the properties of video data, resulting in a simple yet powerful solution. By employing our proposed method, we achieved substantial improvements in accuracy compared to the baseline results (Descriptor Track: 41% improvement, Matching Track: 76% improvement). Our code is publicly available here: https://github.com/line/Meta-AI-Video-Similarity-Challenge-3rd-Place-Solution
Layer Grafted Pre-training: Bridging Contrastive Learning And Masked Image Modeling For Label-Efficient Representations
Feb 27, 2023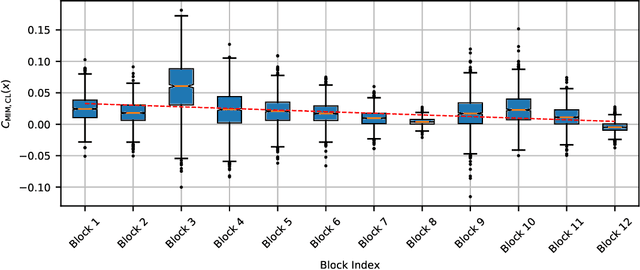
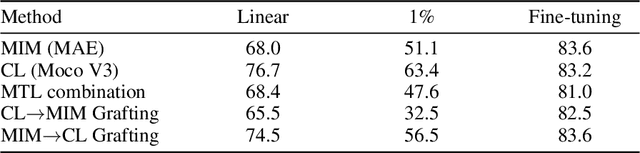
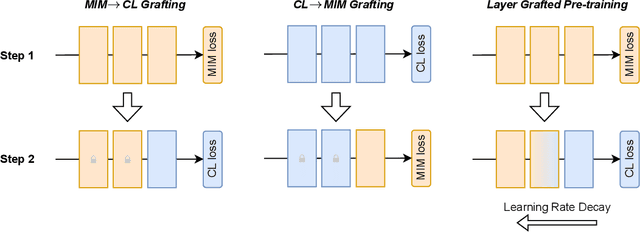
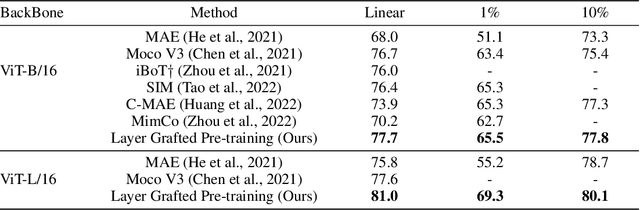
Recently, both Contrastive Learning (CL) and Mask Image Modeling (MIM) demonstrate that self-supervision is powerful to learn good representations. However, naively combining them is far from success. In this paper, we start by making the empirical observation that a naive joint optimization of CL and MIM losses leads to conflicting gradient directions - more severe as the layers go deeper. This motivates us to shift the paradigm from combining loss at the end, to choosing the proper learning method per network layer. Inspired by experimental observations, we find that MIM and CL are suitable to lower and higher layers, respectively. We hence propose to combine them in a surprisingly simple, "sequential cascade" fashion: early layers are first trained under one MIM loss, on top of which latter layers continue to be trained under another CL loss. The proposed Layer Grafted Pre-training learns good visual representations that demonstrate superior label efficiency in downstream applications, in particular yielding strong few-shot performance besides linear evaluation. For instance, on ImageNet-1k, Layer Grafted Pre-training yields 65.5% Top-1 accuracy in terms of 1% few-shot learning with ViT-B/16, which improves MIM and CL baselines by 14.4% and 2.1% with no bells and whistles. The code is available at https://github.com/VITA-Group/layerGraftedPretraining_ICLR23.git.
OTS: A One-shot Learning Approach for Text Spotting in Historical Manuscripts
Apr 18, 2023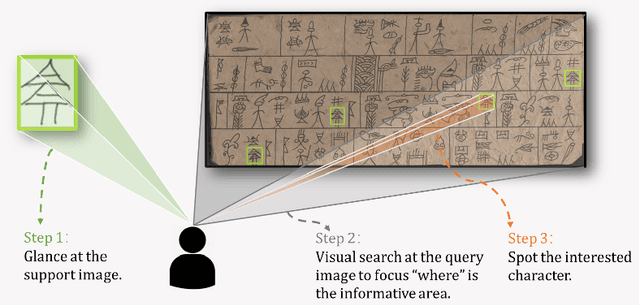
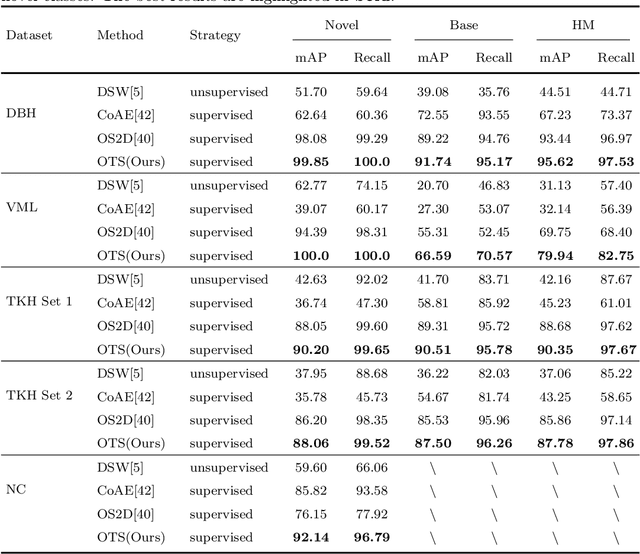
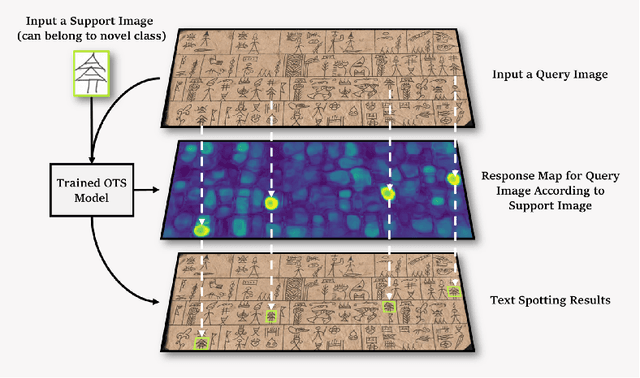
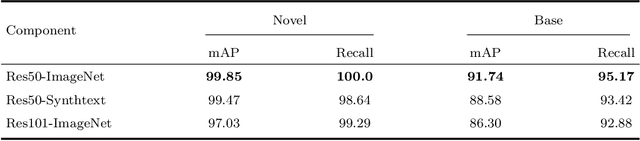
Historical manuscript processing poses challenges like limited annotated training data and novel class emergence. To address this, we propose a novel One-shot learning-based Text Spotting (OTS) approach that accurately and reliably spots novel characters with just one annotated support sample. Drawing inspiration from cognitive research, we introduce a spatial alignment module that finds, focuses on, and learns the most discriminative spatial regions in the query image based on one support image. Especially, since the low-resource spotting task often faces the problem of example imbalance, we propose a novel loss function called torus loss which can make the embedding space of distance metric more discriminative. Our approach is highly efficient and requires only a few training samples while exhibiting the remarkable ability to handle novel characters, and symbols. To enhance dataset diversity, a new manuscript dataset that contains the ancient Dongba hieroglyphics (DBH) is created. We conduct experiments on publicly available VML-HD, TKH, NC datasets, and the new proposed DBH dataset. The experimental results demonstrate that OTS outperforms the state-of-the-art methods in one-shot text spotting. Overall, our proposed method offers promising applications in the field of text spotting in historical manuscripts.
Probabilistic Domain Adaptation for Biomedical Image Segmentation
Mar 21, 2023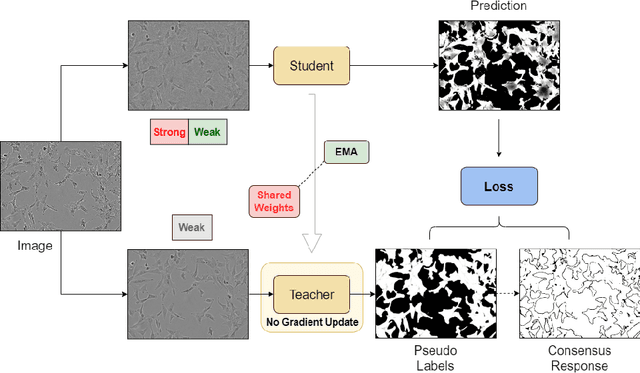

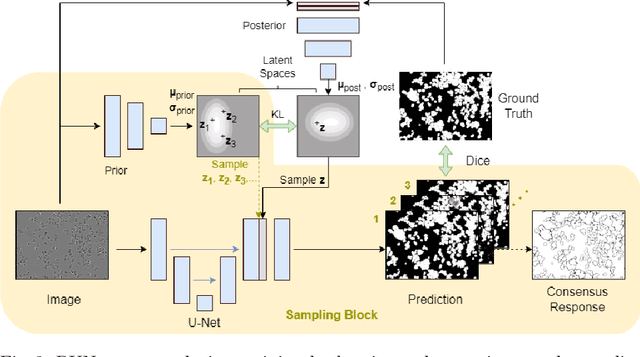
Segmentation is a key analysis tasks in biomedical imaging. Given the many different experimental settings in this field, the lack of generalization limits the use of deep learning in practice. Domain adaptation is a promising remedy: it trains a model for a given task on a source dataset with labels and adapts it to a target dataset without additional labels. We introduce a probabilistic domain adaptation method, building on self-training approaches and the Probabilistic UNet. We use the latter to sample multiple segmentation hypothesis to implement better pseudo-label filtering. We further study joint and separate source-target training strategies and evaluate our method on three challenging domain adaptation tasks for biomedical segmentation.
CAVL: Learning Contrastive and Adaptive Representations of Vision and Language
Apr 10, 2023
Visual and linguistic pre-training aims to learn vision and language representations together, which can be transferred to visual-linguistic downstream tasks. However, there exists semantic confusion between language and vision during the pre-training stage. Moreover, current pre-trained models tend to take lots of computation resources for fine-tuning when transferred to downstream tasks. In this work, we present a simple but effective approach for learning Contrastive and Adaptive representations of Vision and Language, namely CAVL. Specifically, we introduce a pair-wise contrastive loss to learn alignments between the whole sentence and each image in the same batch during the pre-training process. At the fine-tuning stage, we introduce two lightweight adaptation networks to reduce model parameters and increase training speed for saving computation resources. We evaluate our CAVL on six main downstream tasks, including Visual Question Answering (VQA), Visual Commonsense Reasoning (VCR), Natural Language for Visual Reasoning (NLVR), Region-to-Phrase Grounding (RPG), Text-to-Image Retrieval (TIR), and Zero-shot Text-to-Image Retrieval (ZS-TIR). Compared to baselines, we achieve superior performance and reduce the fine-tuning time by a large margin (in particular, 76.17%). Extensive experiments and ablation studies demonstrate the efficiency of contrastive pre-training and adaptive fine-tuning proposed in our CAVL.
Brain Extraction comparing Segment Anything Model (SAM) and FSL Brain Extraction Tool
Apr 10, 2023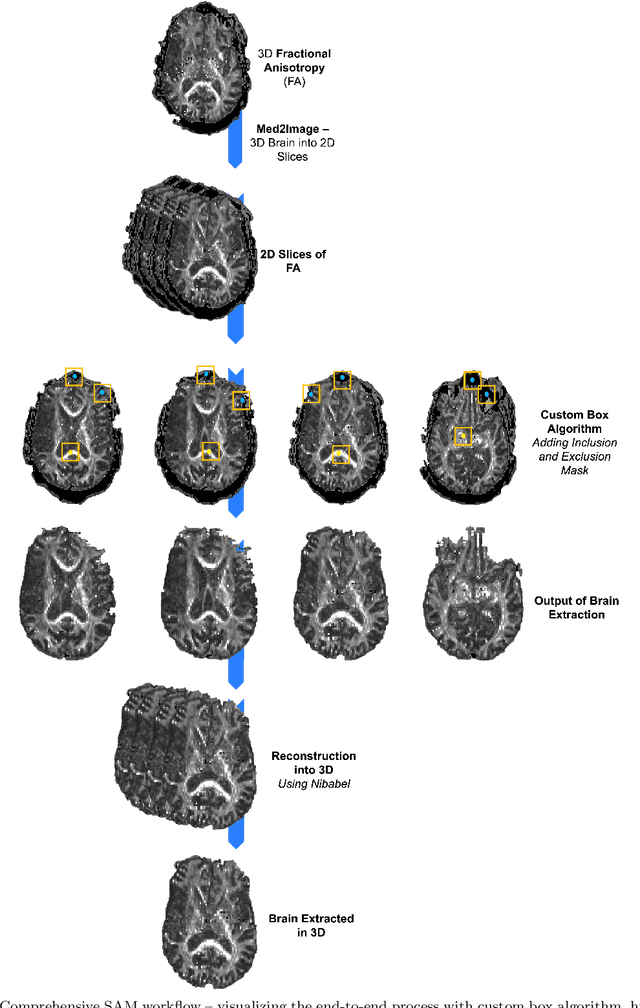
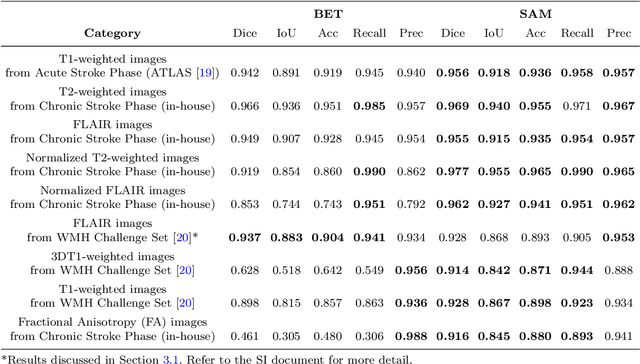
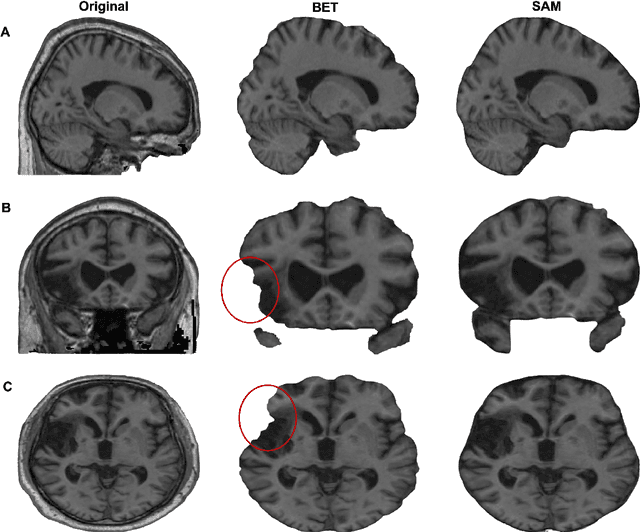
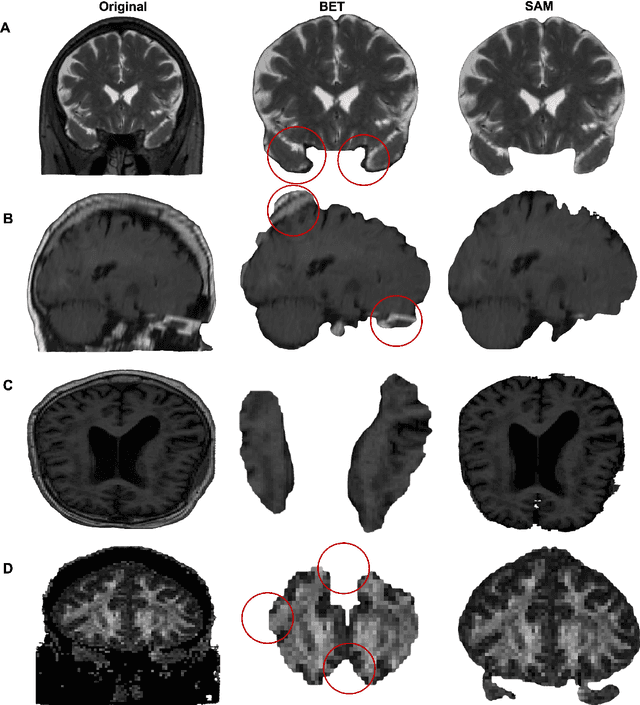
Brain extraction is a critical preprocessing step in almost every neuroimaging study, enabling accurate segmentation and analysis of Magnetic Resonance Imaging (MRI) data. FSL's Brain Extraction Tool (BET), although considered the current gold standard, presents limitations such as over-extraction, which can be particularly problematic in brains with lesions affecting the outer regions, inaccurate differentiation between brain tissue and surrounding meninges, and susceptibility to image quality issues. Recent advances in computer vision research have led to the development of the Segment Anything Model (SAM) by Meta AI, which has demonstrated remarkable potential across a wide range of applications. In this paper, we present a comparative analysis of brain extraction techniques using BET and SAM on a variety of brain scans with varying image qualities, MRI sequences, and brain lesions affecting different brain regions. We find that SAM outperforms BET based on several metrics, particularly in cases where image quality is compromised by signal inhomogeneities, non-isotropic voxel resolutions, or the presence of brain lesions that are located near or involve the outer regions of the brain and the meninges. These results suggest that SAM has the potential to emerge as a more accurate and precise tool for a broad range of brain extraction applications.
ColonMapper: topological mapping and localization for colonoscopy
May 09, 2023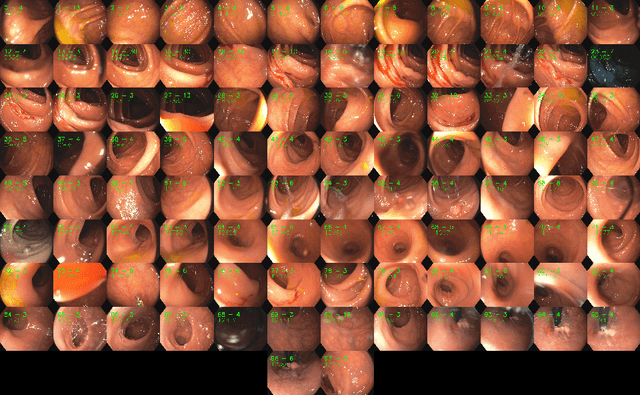
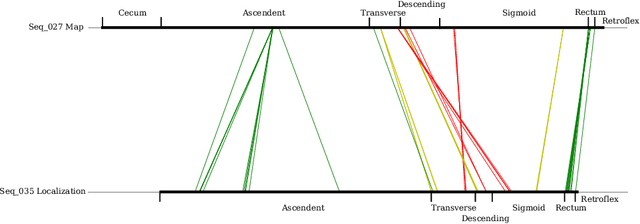
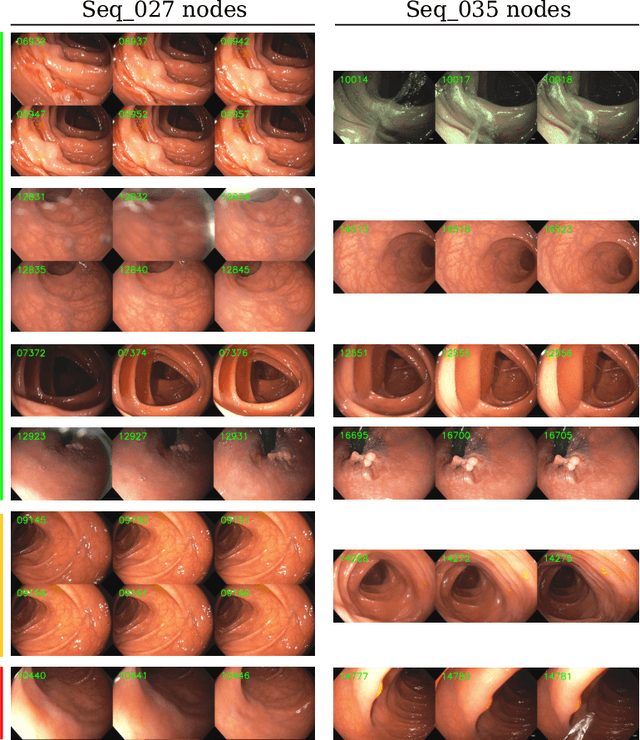
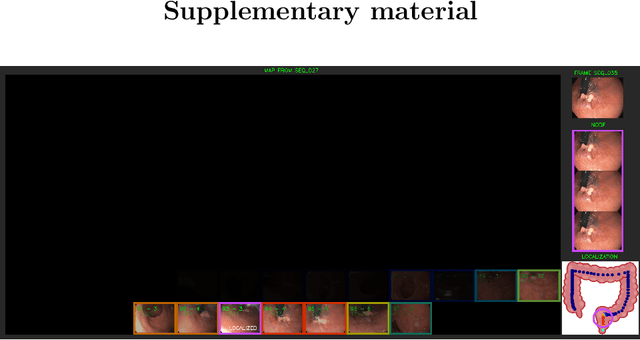
Mapping and localization in endoluminal cavities from colonoscopies or gastroscopies has to overcome the challenge of significant shape and illumination changes between reobservations of the same endoluminal location. Instead of geometrical maps that strongly rely on a fixed scene geometry, topological maps are more adequate because they focus on visual place recognition, i.e. the capability to determine if two video shots are imaging the same location. We propose a topological mapping and localization system able to operate on real human colonoscopies. The map is a graph where each node codes a colon location by a set of real images of that location. The edges represent traversability between two nodes. For close-in-time images, where scene changes are minor, place recognition can be successfully managed with the recent transformers-based image-matching algorithms. However, under long-term changes -- such as different colonoscopies of the same patient -- feature-based matching fails. To address this, we propose a GeM global descriptor able to achieve high recall with significant changes in the scene. The addition of a Bayesian filter processing the map graph boosts the accuracy of the long-term place recognition, enabling relocalization in a previously built map. In the experiments, we construct a map during the withdrawal phase of a first colonoscopy. Subsequently, we prove the ability to relocalize within this map during a second colonoscopy of the same patient two weeks later. Code and models will be available upon acceptance.