 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Chameleon: Adapting to Peer Images for Planting Durable Backdoors in Federated Learning
Apr 25, 2023
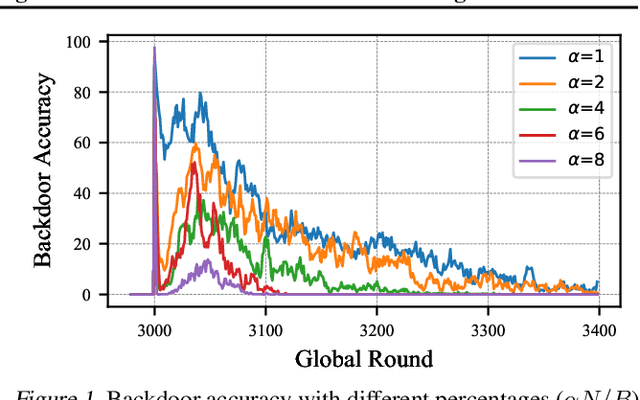
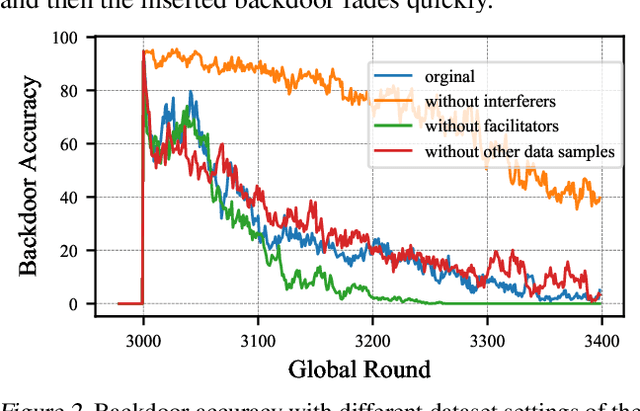
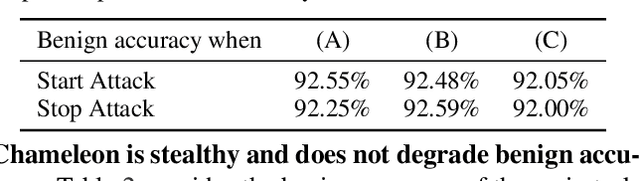
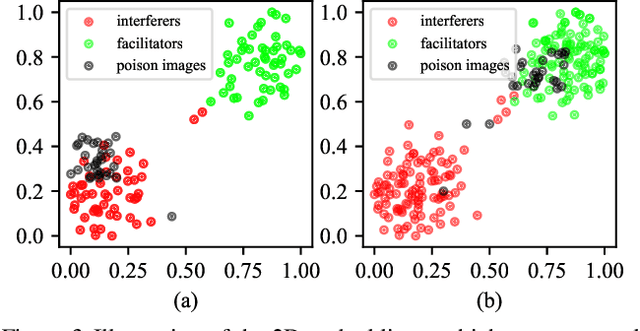
In a federated learning (FL) system, distributed clients upload their local models to a central server to aggregate into a global model. Malicious clients may plant backdoors into the global model through uploading poisoned local models, causing images with specific patterns to be misclassified into some target labels. Backdoors planted by current attacks are not durable, and vanish quickly once the attackers stop model poisoning. In this paper, we investigate the connection between the durability of FL backdoors and the relationships between benign images and poisoned images (i.e., the images whose labels are flipped to the target label during local training). Specifically, benign images with the original and the target labels of the poisoned images are found to have key effects on backdoor durability. Consequently, we propose a novel attack, Chameleon, which utilizes contrastive learning to further amplify such effects towards a more durable backdoor. Extensive experiments demonstrate that Chameleon significantly extends the backdoor lifespan over baselines by $1.2\times \sim 4\times$, for a wide range of image datasets, backdoor types, and model architectures.
A fast and flexible algorithm for microstructure reconstruction combining simulated annealing and deep learning
Apr 25, 2023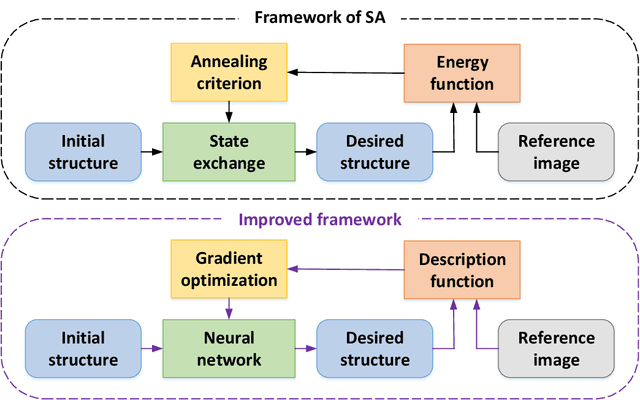


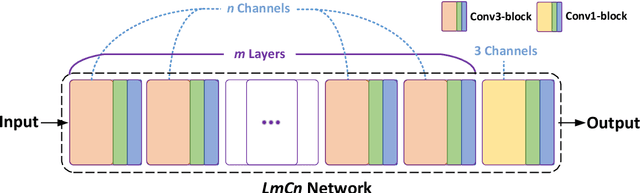
The microstructure analyses of porous media have considerable research value for the study of macroscopic properties. As the premise of conducting these analyses, the accurate reconstruction of microstructure digital model is also an important component of the research. Computational reconstruction algorithms of microstructure have attracted much attention due to their low cost and excellent performance. However, it is still a challenge for computational reconstruction algorithms to achieve faster and more efficient reconstruction. The bottleneck lies in computational reconstruction algorithms, they are either too slow (traditional reconstruction algorithms) or not flexible to the training process (deep learning reconstruction algorithms). To address these limitations, we proposed a fast and flexible computational reconstruction algorithm, neural networks based on improved simulated annealing framework (ISAF-NN). The proposed algorithm is flexible and can complete training and reconstruction in a short time with only one two-dimensional image. By adjusting the size of input, it can also achieve reconstruction of arbitrary size. Finally, the proposed algorithm is experimentally performed on a variety of isotropic and anisotropic materials to verify the effectiveness and generalization.
Deep Joint Source-Channel Coding for Wireless Image Transmission with Semantic Importance
Feb 05, 2023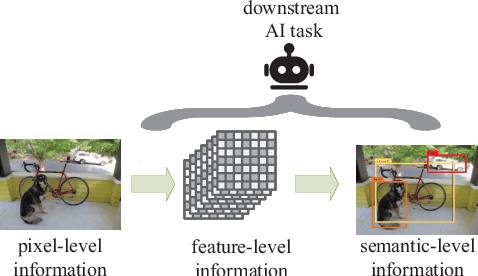
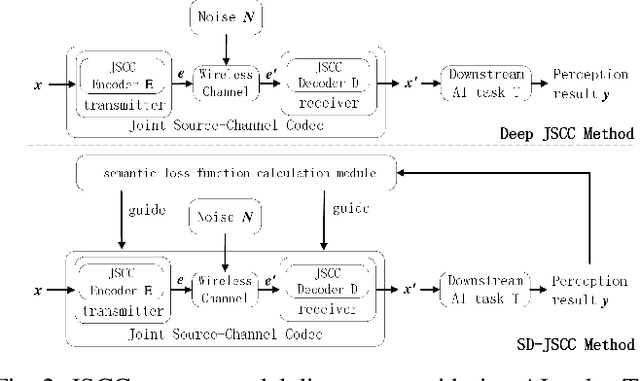
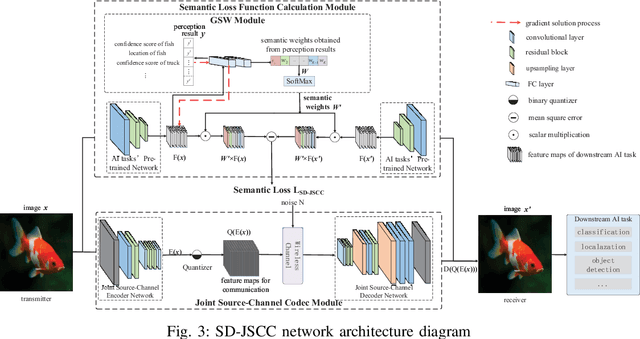
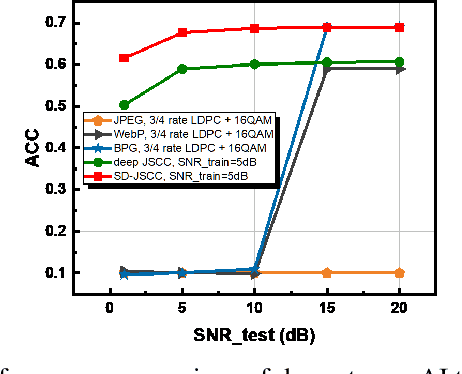
The sixth-generation mobile communication system proposes the vision of smart interconnection of everything, which requires accomplishing communication tasks while ensuring the performance of intelligent tasks. A joint source-channel coding method based on semantic importance is proposed, which aims at preserving semantic information during wireless image transmission and thereby boosting the performance of intelligent tasks for images at the receiver. Specifically, we first propose semantic importance weight calculation method, which is based on the gradient of intelligent task's perception results with respect to the features. Then, we design the semantic loss function in the way of using semantic weights to weight the features. Finally, we train the deep joint source-channel coding network using the semantic loss function. Experiment results demonstrate that the proposed method achieves up to 57.7% and 9.1% improvement in terms of intelligent task's performance compared with the source-channel separation coding method and the deep sourcechannel joint coding method without considering semantics at the same compression rate and signal-to-noise ratio, respectively.
Transfer Visual Prompt Generator across LLMs
May 02, 2023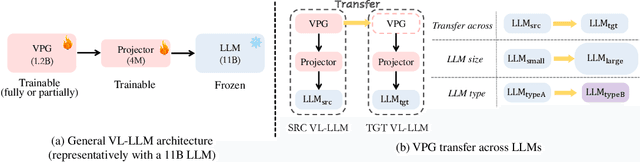

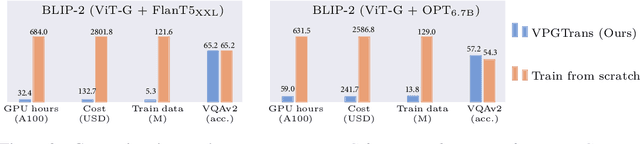

While developing a new vision-language LLM (VL-LLM) by pre-training on tremendous image-text pairs from scratch can be exceedingly resource-consuming, connecting an existing LLM with a comparatively lightweight visual prompt generator (VPG) becomes a feasible paradigm. However, further tuning the VPG part of the VL-LLM still suffers from indispensable computational costs, i.e., requiring thousands of GPU hours and millions of training data. One alternative solution is to transfer an existing VPG from any existing VL-LLMs for the target VL-LLM. In this work, we for the first time investigate the VPG transferability across LLMs, and explore a solution to reduce the cost of VPG transfer. We first study the VPG transfer across different LLM sizes (e.g., small-to-large), and across different LLM types, through which we diagnose the key factors to maximize the transfer efficiency. Based on our observation, we design a two-stage transfer framework named VPGTrans, which is simple yet highly effective. Through extensive experiments, we demonstrate that VPGTrans helps significantly speed up the transfer learning process without compromising performance. Remarkably, it helps achieve the VPG transfer from BLIP-2 OPT$_\text{2.7B}$ to BLIP-2 OPT$_\text{6.7B}$ with over 10 times speed-up and 10.7% training data compared with connecting a VPG to OPT$_\text{6.7B}$ from scratch. Further, a series of intriguing findings and potential rationales behind them are provided and discussed. Finally, we showcase the practical value of our VPGTrans approach, by customizing two novel VL-LLMs, including VL-LLaMA and VL-Vicuna, with recently released LLaMA and Vicuna LLMs.
Visual Reasoning: from State to Transformation
May 02, 2023Most existing visual reasoning tasks, such as CLEVR in VQA, ignore an important factor, i.e.~transformation. They are solely defined to test how well machines understand concepts and relations within static settings, like one image. Such \textbf{state driven} visual reasoning has limitations in reflecting the ability to infer the dynamics between different states, which has shown to be equally important for human cognition in Piaget's theory. To tackle this problem, we propose a novel \textbf{transformation driven} visual reasoning (TVR) task. Given both the initial and final states, the target becomes to infer the corresponding intermediate transformation. Following this definition, a new synthetic dataset namely TRANCE is first constructed on the basis of CLEVR, including three levels of settings, i.e.~Basic (single-step transformation), Event (multi-step transformation), and View (multi-step transformation with variant views). Next, we build another real dataset called TRANCO based on COIN, to cover the loss of transformation diversity on TRANCE. Inspired by human reasoning, we propose a three-staged reasoning framework called TranNet, including observing, analyzing, and concluding, to test how recent advanced techniques perform on TVR. Experimental results show that the state-of-the-art visual reasoning models perform well on Basic, but are still far from human-level intelligence on Event, View, and TRANCO. We believe the proposed new paradigm will boost the development of machine visual reasoning. More advanced methods and new problems need to be investigated in this direction. The resource of TVR is available at \url{https://hongxin2019.github.io/TVR/}.
Outlier galaxy images in the Dark Energy Survey and their identification with unsupervised machine learning
May 02, 2023
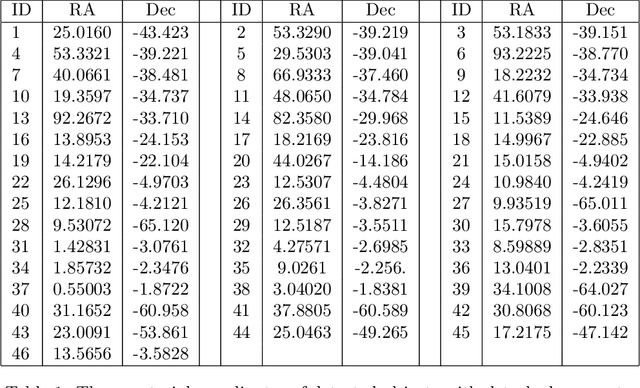

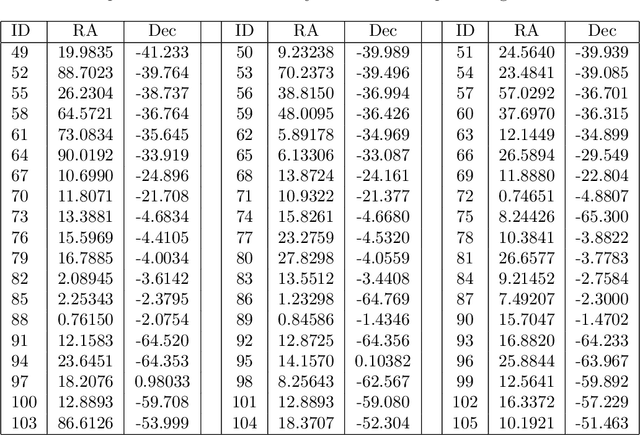
The Dark Energy Survey is able to collect image data of an extremely large number of extragalactic objects, and it can be reasonably assumed that many unusual objects of high scientific interest are hidden inside these data. Due to the extreme size of DES data, identifying these objects among many millions of other celestial objects is a challenging task. The problem of outlier detection is further magnified by the presence of noisy or saturated images. When the number of tested objects is extremely high, even a small rate of noise or false positives leads to a very large number of false detections, making an automatic system impractical. This study applies an automatic method for automatic detection of outlier objects in the first data release of the Dark Energy Survey. By using machine learning-based outlier detection, the algorithm is able to identify objects that are visually different from the majority of the other objects in the database. An important feature of the algorithm is that it allows to control the false-positive rate, and therefore can be used for practical outlier detection. The algorithm does not provide perfect accuracy in the detection of outlier objects, but it reduces the data substantially to allow practical outlier detection. For instance, the selection of the top 250 objects after applying the algorithm to more than $2\cdot10^6$ DES images provides a collection of uncommon galaxies. Such collection would have been extremely time-consuming to compile by using manual inspection of the data.
TEGLO: High Fidelity Canonical Texture Mapping from Single-View Images
Mar 24, 2023
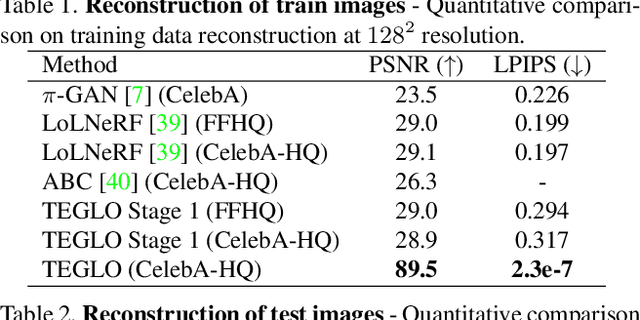
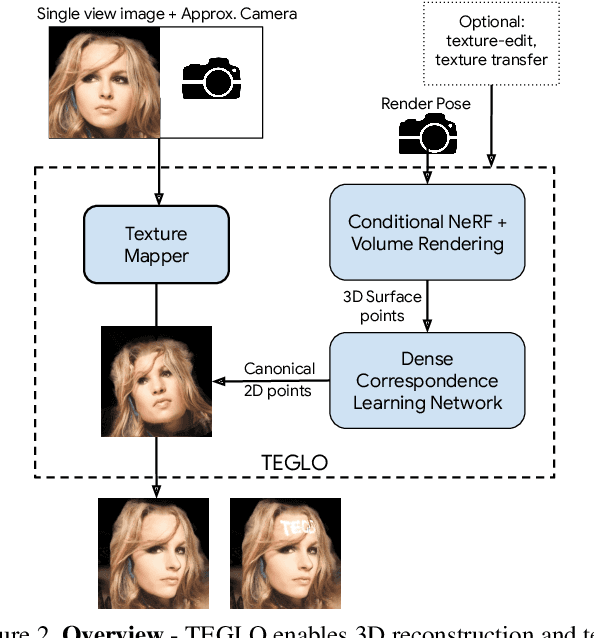

Recent work in Neural Fields (NFs) learn 3D representations from class-specific single view image collections. However, they are unable to reconstruct the input data preserving high-frequency details. Further, these methods do not disentangle appearance from geometry and hence are not suitable for tasks such as texture transfer and editing. In this work, we propose TEGLO (Textured EG3D-GLO) for learning 3D representations from single view in-the-wild image collections for a given class of objects. We accomplish this by training a conditional Neural Radiance Field (NeRF) without any explicit 3D supervision. We equip our method with editing capabilities by creating a dense correspondence mapping to a 2D canonical space. We demonstrate that such mapping enables texture transfer and texture editing without requiring meshes with shared topology. Our key insight is that by mapping the input image pixels onto the texture space we can achieve near perfect reconstruction (>= 74 dB PSNR at 1024^2 resolution). Our formulation allows for high quality 3D consistent novel view synthesis with high-frequency details at megapixel image resolution.
Exploring Image Augmentations for Siamese Representation Learning with Chest X-Rays
Jan 30, 2023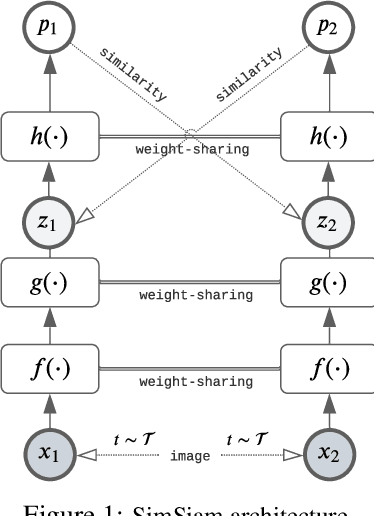
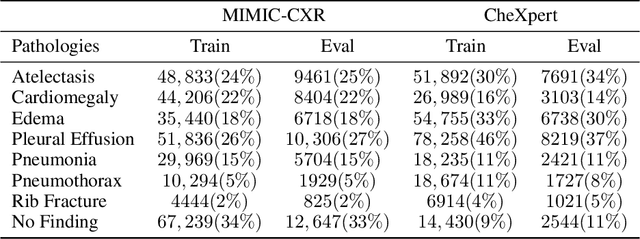
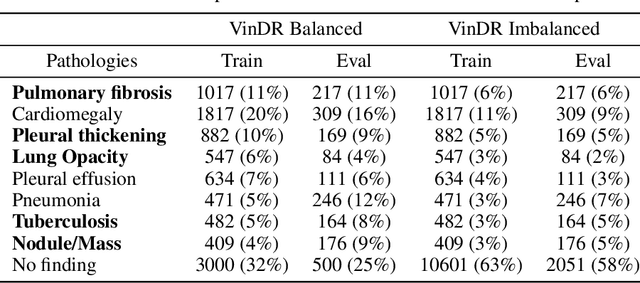
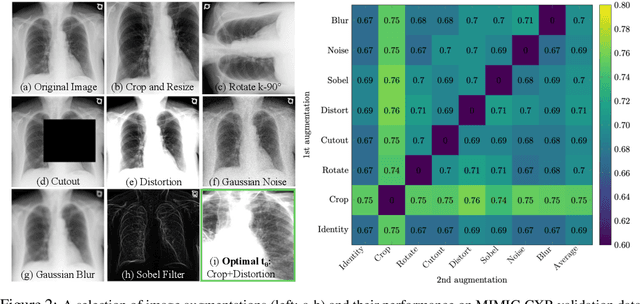
Image augmentations are quintessential for effective visual representation learning across self-supervised learning techniques. While augmentation strategies for natural imaging have been studied extensively, medical images are vastly different from their natural counterparts. Thus, it is unknown whether common augmentation strategies employed in Siamese representation learning generalize to medical images and to what extent. To address this challenge, in this study, we systematically assess the effect of various augmentations on the quality and robustness of the learned representations. We train and evaluate Siamese Networks for abnormality detection on chest X-Rays across three large datasets (MIMIC-CXR, CheXpert and VinDR-CXR). We investigate the efficacy of the learned representations through experiments involving linear probing, fine-tuning, zero-shot transfer, and data efficiency. Finally, we identify a set of augmentations that yield robust representations that generalize well to both out-of-distribution data and diseases, while outperforming supervised baselines using just zero-shot transfer and linear probes by up to 20%.
Enhancing Medical Image Segmentation with TransCeption: A Multi-Scale Feature Fusion Approach
Jan 25, 2023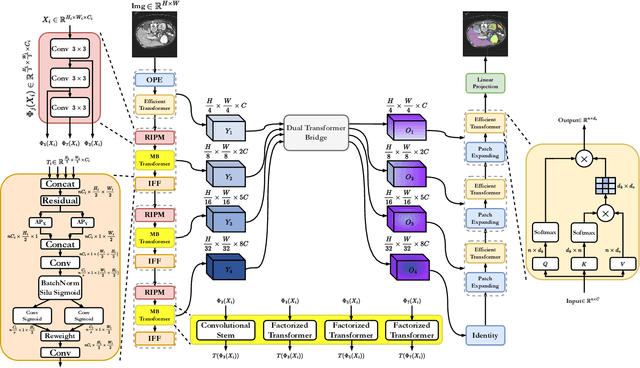
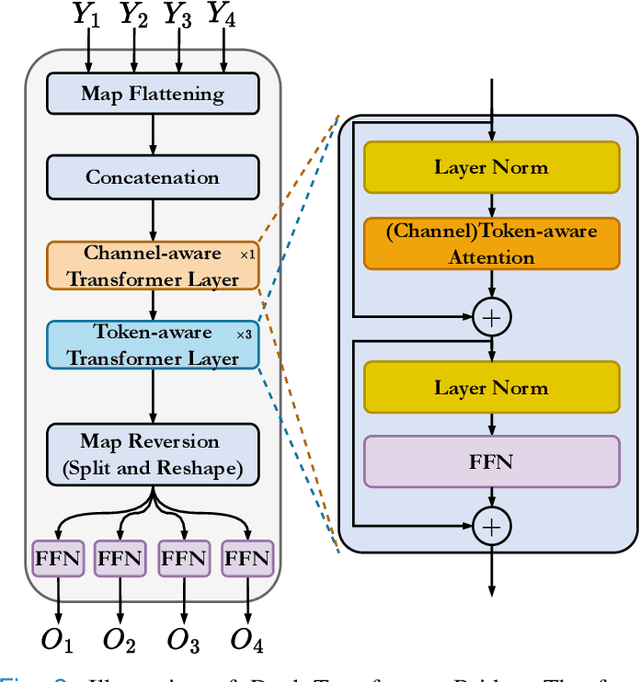
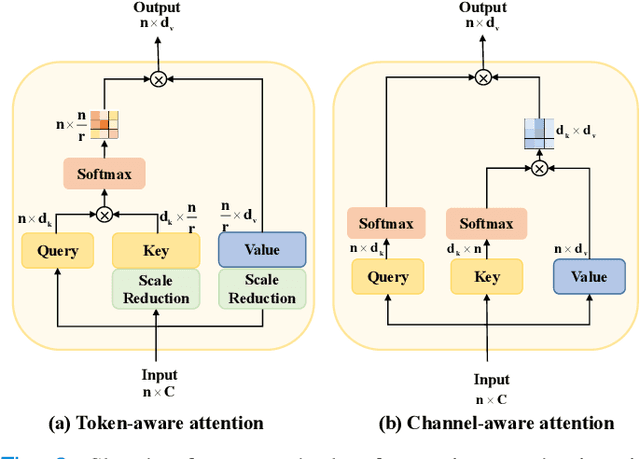
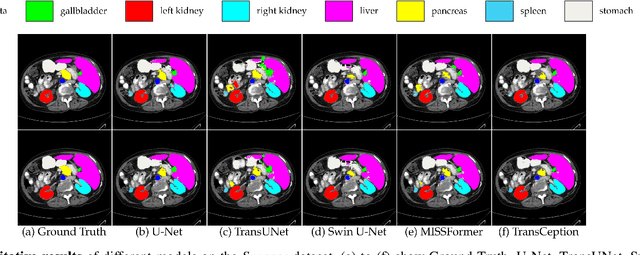
While CNN-based methods have been the cornerstone of medical image segmentation due to their promising performance and robustness, they suffer from limitations in capturing long-range dependencies. Transformer-based approaches are currently prevailing since they enlarge the reception field to model global contextual correlation. To further extract rich representations, some extensions of the U-Net employ multi-scale feature extraction and fusion modules and obtain improved performance. Inspired by this idea, we propose TransCeption for medical image segmentation, a pure transformer-based U-shape network featured by incorporating the inception-like module into the encoder and adopting a contextual bridge for better feature fusion. The design proposed in this work is based on three core principles: (1) The patch merging module in the encoder is redesigned with ResInception Patch Merging (RIPM). Multi-branch transformer (MB transformer) adopts the same number of branches as the outputs of RIPM. Combining the two modules enables the model to capture a multi-scale representation within a single stage. (2) We construct an Intra-stage Feature Fusion (IFF) module following the MB transformer to enhance the aggregation of feature maps from all the branches and particularly focus on the interaction between the different channels of all the scales. (3) In contrast to a bridge that only contains token-wise self-attention, we propose a Dual Transformer Bridge that also includes channel-wise self-attention to exploit correlations between scales at different stages from a dual perspective. Extensive experiments on multi-organ and skin lesion segmentation tasks present the superior performance of TransCeption compared to previous work. The code is publicly available at \url{https://github.com/mindflow-institue/TransCeption}.
End-to-End Lidar-Camera Self-Calibration for Autonomous Vehicles
Apr 28, 2023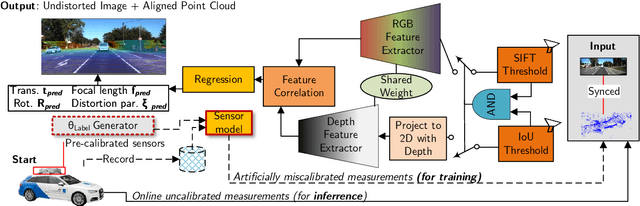

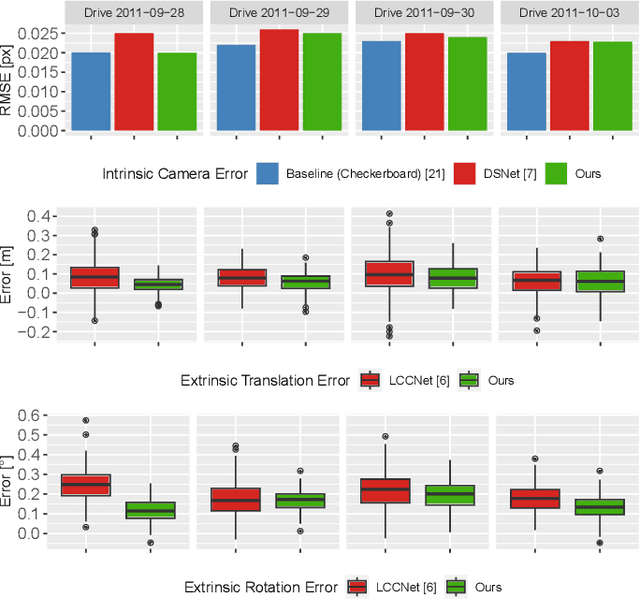
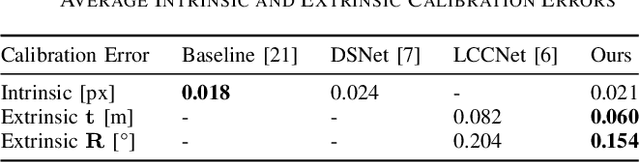
Autonomous vehicles are equipped with a multi-modal sensor setup to enable the car to drive safely. The initial calibration of such perception sensors is a highly matured topic and is routinely done in an automated factory environment. However, an intriguing question arises on how to maintain the calibration quality throughout the vehicle's operating duration. Another challenge is to calibrate multiple sensors jointly to ensure no propagation of systemic errors. In this paper, we propose CaLiCa, an end-to-end deep self-calibration network which addresses the automatic calibration problem for pinhole camera and Lidar. We jointly predict the camera intrinsic parameters (focal length and distortion) as well as Lidar-Camera extrinsic parameters (rotation and translation), by regressing feature correlation between the camera image and the Lidar point cloud. The network is arranged in a Siamese-twin structure to constrain the network features learning to a mutually shared feature in both point cloud and camera (Lidar-camera constraint). Evaluation using KITTI datasets shows that we achieve 0.154 {\deg} and 0.059 m accuracy with a reprojection error of 0.028 pixel with a single-pass inference. We also provide an ablative study of how our end-to-end learning architecture offers lower terminal loss (21% decrease in rotation loss) compared to isolated calibration