 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Zero-Shot In-Distribution Detection in Multi-Object Settings Using Vision-Language Foundation Models
Apr 10, 2023
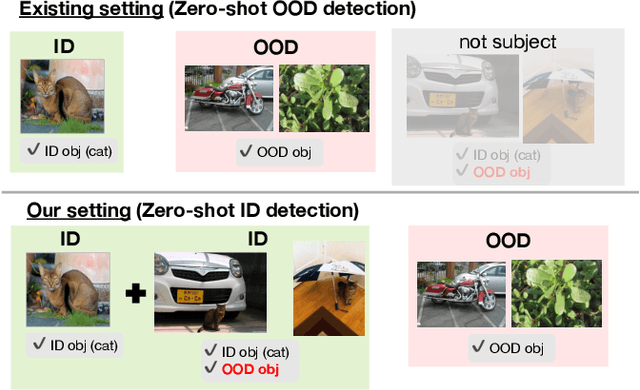
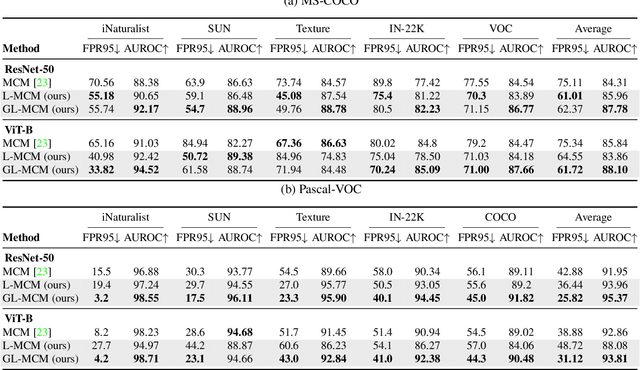
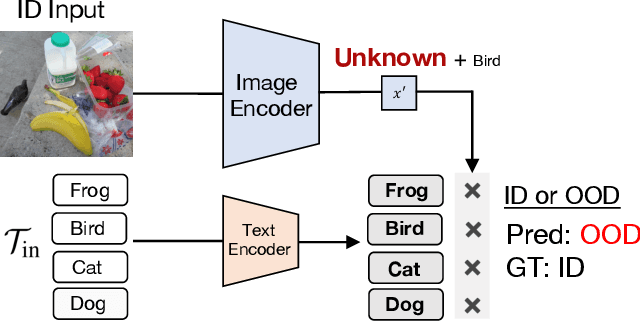
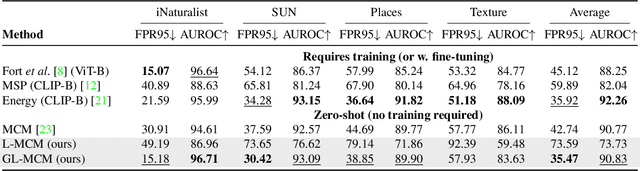
Removing out-of-distribution (OOD) images from noisy images scraped from the Internet is an important preprocessing for constructing datasets, which can be addressed by zero-shot OOD detection with vision language foundation models (CLIP). The existing zero-shot OOD detection setting does not consider the realistic case where an image has both in-distribution (ID) objects and OOD objects. However, it is important to identify such images as ID images when collecting the images of rare classes or ethically inappropriate classes that must not be missed. In this paper, we propose a novel problem setting called in-distribution (ID) detection, where we identify images containing ID objects as ID images, even if they contain OOD objects, and images lacking ID objects as OOD images. To solve this problem, we present a new approach, \textbf{G}lobal-\textbf{L}ocal \textbf{M}aximum \textbf{C}oncept \textbf{M}atching (GL-MCM), based on both global and local visual-text alignments of CLIP features, which can identify any image containing ID objects as ID images. Extensive experiments demonstrate that GL-MCM outperforms comparison methods on both multi-object datasets and single-object ImageNet benchmarks.
Learning-Based Conditional Image Coder Using Color Separation
Dec 12, 2022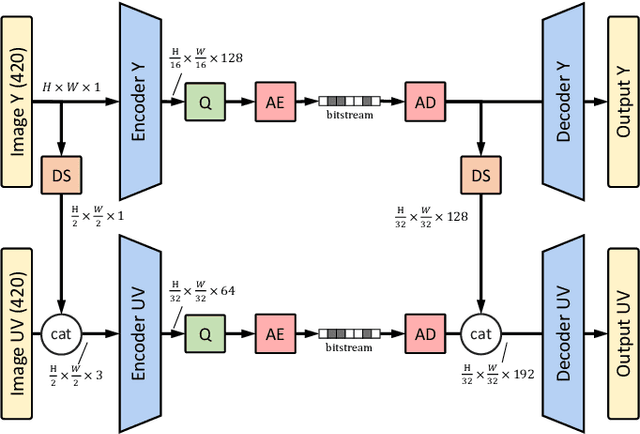

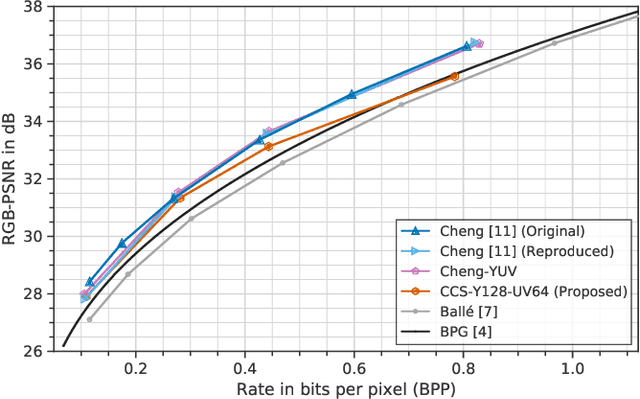
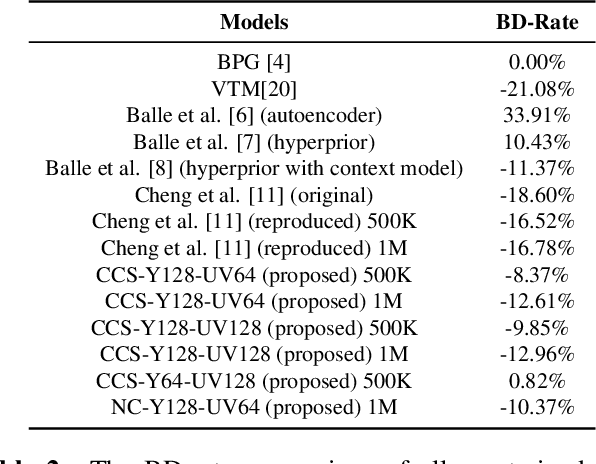
Recently, image compression codecs based on Neural Networks(NN) outperformed the state-of-art classic ones such as BPG, an image format based on HEVC intra. However, the typical NN codec has high complexity, and it has limited options for parallel data processing. In this work, we propose a conditional separation principle that aims to improve parallelization and lower the computational requirements of an NN codec. We present a Conditional Color Separation (CCS) codec which follows this principle. The color components of an image are split into primary and non-primary ones. The processing of each component is done separately, by jointly trained networks. Our approach allows parallel processing of each component, flexibility to select different channel numbers, and an overall complexity reduction. The CCS codec uses over 40% less memory, has 2x faster encoding and 22% faster decoding speed, with only 4% BD-rate loss in RGB PSNR compared to our baseline model over BPG.
360$^\circ$ High-Resolution Depth Estimation via Uncertainty-aware Structural Knowledge Transfer
Apr 17, 2023
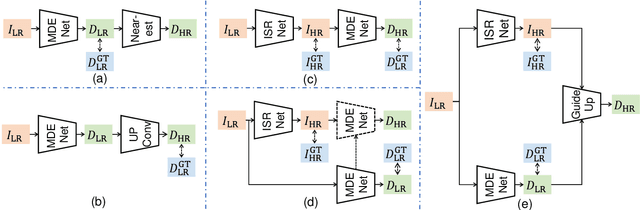
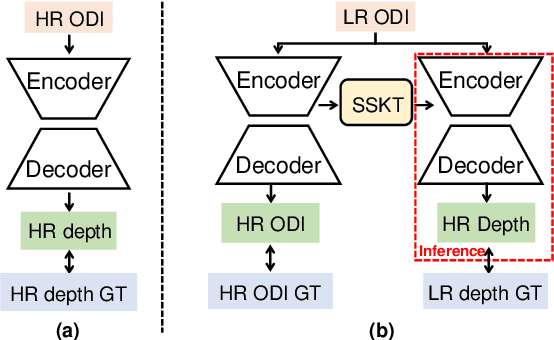
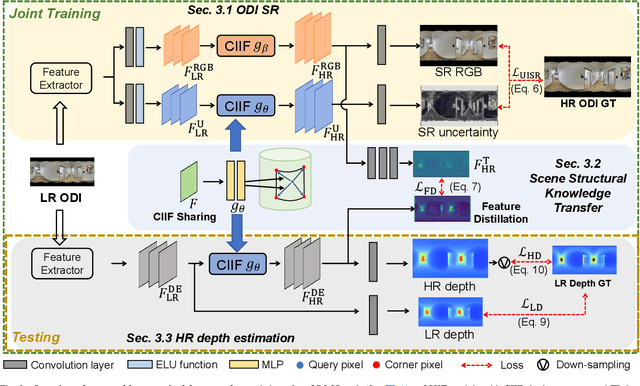
Recently, omnidirectional images (ODIs) have become increasingly popular; however, their angular resolution tends to be lower than that of perspective images.This leads to degraded structural details such as edges, causing difficulty in learning 3D scene understanding tasks, especially monocular depth estimation. Existing methods typically leverage high-resolution (HR) ODI as the input, so as to recover the structural details via fully-supervised learning. However, the HR depth ground truth (GT) maps may be arduous or expensive to be collected due to resource-constrained devices in practice. Therefore, in this paper, we explore for the first time to estimate the HR omnidirectional depth directly from a low-resolution (LR) ODI, when no HR depth GT map is available. Our key idea is to transfer the scene structural knowledge from the readily available HR image modality and the corresponding LR depth maps to achieve the goal of HR depth estimation without extra inference cost. Specifically, we introduce ODI super-resolution (SR) as an auxiliary task and train both tasks collaboratively in a weakly supervised manner to boost the performance of HR depth estimation. The ODI SR task takes an LR ODI as the input to predict an HR image, enabling us to extract the scene structural knowledge via uncertainty estimation. Buttressed by this, a scene structural knowledge transfer (SSKT) module is proposed with two key components. First, we employ a cylindrical implicit interpolation function (CIIF) to learn cylindrical neural interpolation weights for feature up-sampling and share the parameters of CIIFs between the two tasks. Then, we propose a feature distillation (FD) loss that provides extra structural regularization to help the HR depth estimation task learn more scene structural knowledge.
Remote Sensing Change Detection With Transformers Trained from Scratch
Apr 13, 2023
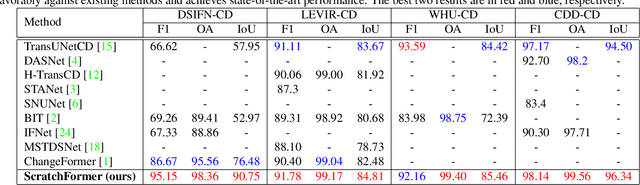
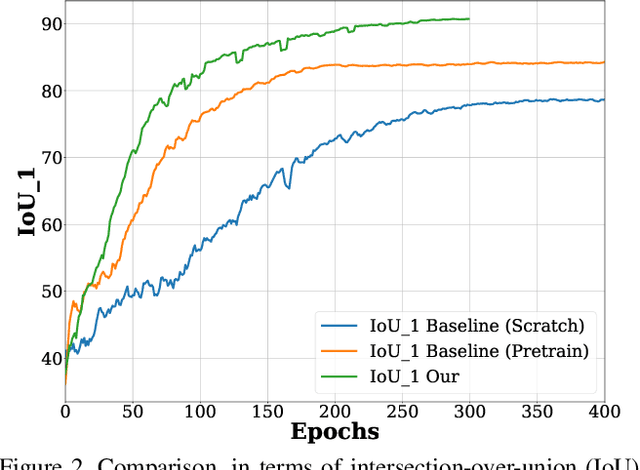
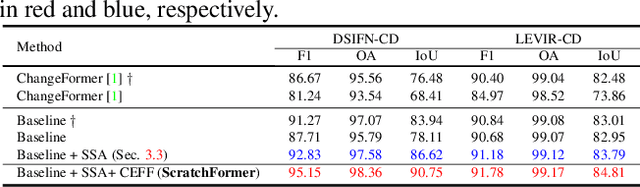
Current transformer-based change detection (CD) approaches either employ a pre-trained model trained on large-scale image classification ImageNet dataset or rely on first pre-training on another CD dataset and then fine-tuning on the target benchmark. This current strategy is driven by the fact that transformers typically require a large amount of training data to learn inductive biases, which is insufficient in standard CD datasets due to their small size. We develop an end-to-end CD approach with transformers that is trained from scratch and yet achieves state-of-the-art performance on four public benchmarks. Instead of using conventional self-attention that struggles to capture inductive biases when trained from scratch, our architecture utilizes a shuffled sparse-attention operation that focuses on selected sparse informative regions to capture the inherent characteristics of the CD data. Moreover, we introduce a change-enhanced feature fusion (CEFF) module to fuse the features from input image pairs by performing a per-channel re-weighting. Our CEFF module aids in enhancing the relevant semantic changes while suppressing the noisy ones. Extensive experiments on four CD datasets reveal the merits of the proposed contributions, achieving gains as high as 14.27\% in intersection-over-union (IoU) score, compared to the best-published results in the literature. Code is available at \url{https://github.com/mustansarfiaz/ScratchFormer}.
Boosting Convolutional Neural Networks with Middle Spectrum Grouped Convolution
Apr 13, 2023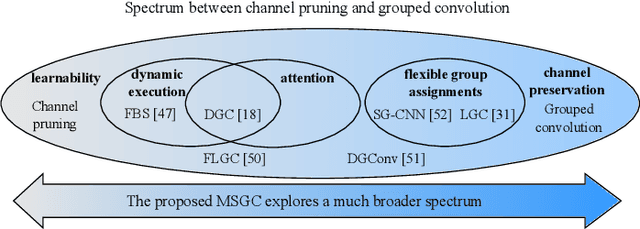
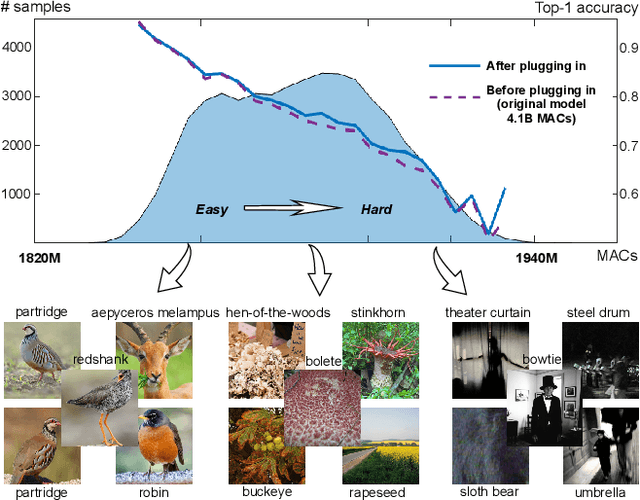
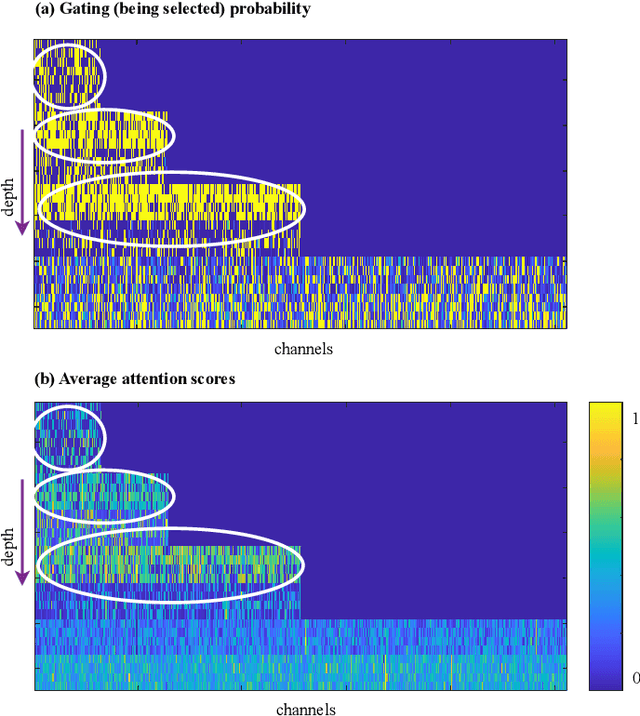
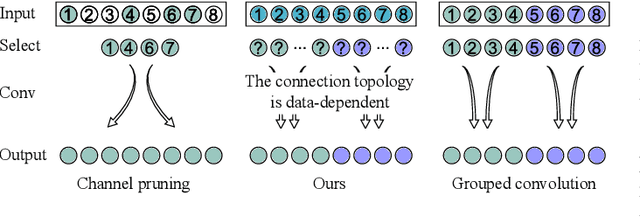
This paper proposes a novel module called middle spectrum grouped convolution (MSGC) for efficient deep convolutional neural networks (DCNNs) with the mechanism of grouped convolution. It explores the broad "middle spectrum" area between channel pruning and conventional grouped convolution. Compared with channel pruning, MSGC can retain most of the information from the input feature maps due to the group mechanism; compared with grouped convolution, MSGC benefits from the learnability, the core of channel pruning, for constructing its group topology, leading to better channel division. The middle spectrum area is unfolded along four dimensions: group-wise, layer-wise, sample-wise, and attention-wise, making it possible to reveal more powerful and interpretable structures. As a result, the proposed module acts as a booster that can reduce the computational cost of the host backbones for general image recognition with even improved predictive accuracy. For example, in the experiments on ImageNet dataset for image classification, MSGC can reduce the multiply-accumulates (MACs) of ResNet-18 and ResNet-50 by half but still increase the Top-1 accuracy by more than 1%. With 35% reduction of MACs, MSGC can also increase the Top-1 accuracy of the MobileNetV2 backbone. Results on MS COCO dataset for object detection show similar observations. Our code and trained models are available at https://github.com/hellozhuo/msgc.
Advances in Medical Image Analysis with Vision Transformers: A Comprehensive Review
Jan 10, 2023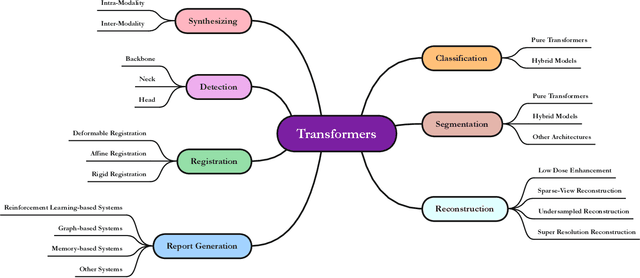
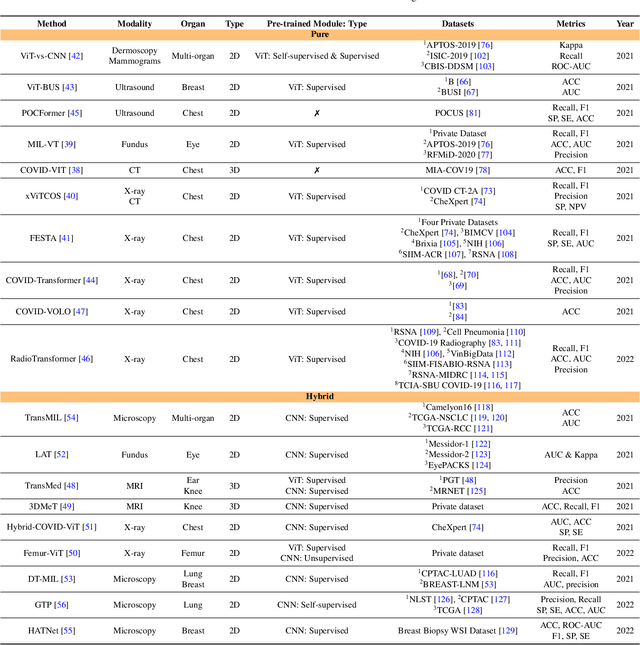
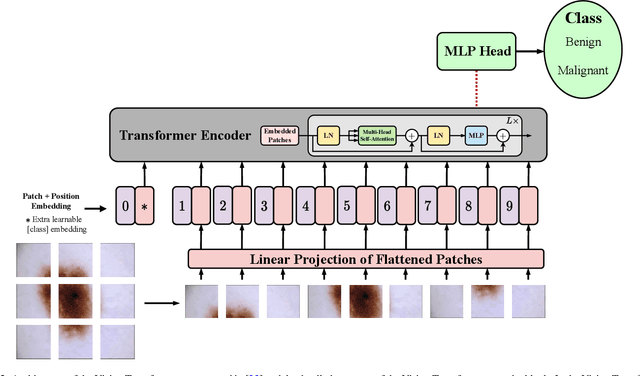
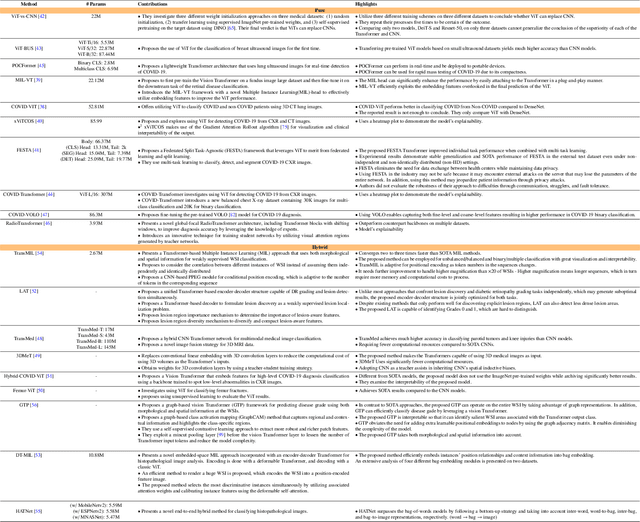
The remarkable performance of the Transformer architecture in natural language processing has recently also triggered broad interest in Computer Vision. Among other merits, Transformers are witnessed as capable of learning long-range dependencies and spatial correlations, which is a clear advantage over convolutional neural networks (CNNs), which have been the de facto standard in Computer Vision problems so far. Thus, Transformers have become an integral part of modern medical image analysis. In this review, we provide an encyclopedic review of the applications of Transformers in medical imaging. Specifically, we present a systematic and thorough review of relevant recent Transformer literature for different medical image analysis tasks, including classification, segmentation, detection, registration, synthesis, and clinical report generation. For each of these applications, we investigate the novelty, strengths and weaknesses of the different proposed strategies and develop taxonomies highlighting key properties and contributions. Further, if applicable, we outline current benchmarks on different datasets. Finally, we summarize key challenges and discuss different future research directions. In addition, we have provided cited papers with their corresponding implementations in https://github.com/mindflow-institue/Awesome-Transformer.
TEGLO: High Fidelity Canonical Texture Mapping from Single-View Images
Mar 24, 2023
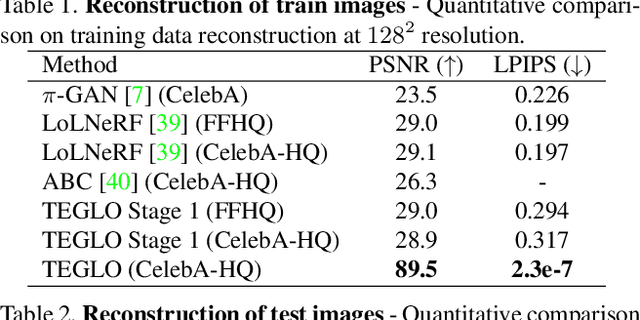
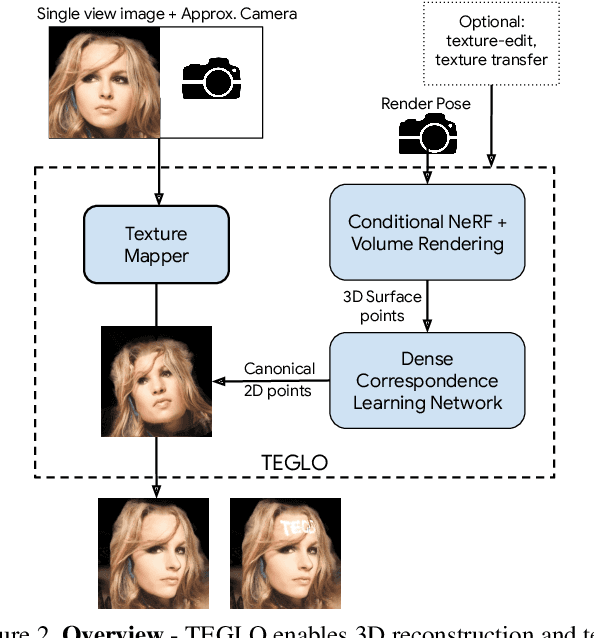

Recent work in Neural Fields (NFs) learn 3D representations from class-specific single view image collections. However, they are unable to reconstruct the input data preserving high-frequency details. Further, these methods do not disentangle appearance from geometry and hence are not suitable for tasks such as texture transfer and editing. In this work, we propose TEGLO (Textured EG3D-GLO) for learning 3D representations from single view in-the-wild image collections for a given class of objects. We accomplish this by training a conditional Neural Radiance Field (NeRF) without any explicit 3D supervision. We equip our method with editing capabilities by creating a dense correspondence mapping to a 2D canonical space. We demonstrate that such mapping enables texture transfer and texture editing without requiring meshes with shared topology. Our key insight is that by mapping the input image pixels onto the texture space we can achieve near perfect reconstruction (>= 74 dB PSNR at 1024^2 resolution). Our formulation allows for high quality 3D consistent novel view synthesis with high-frequency details at megapixel image resolution.
CLIPVG: Text-Guided Image Manipulation Using Differentiable Vector Graphics
Dec 05, 2022
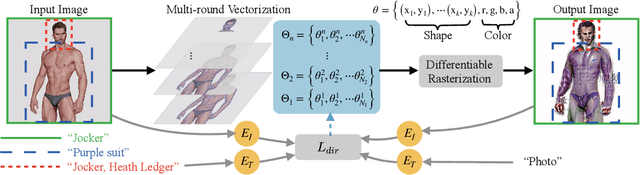

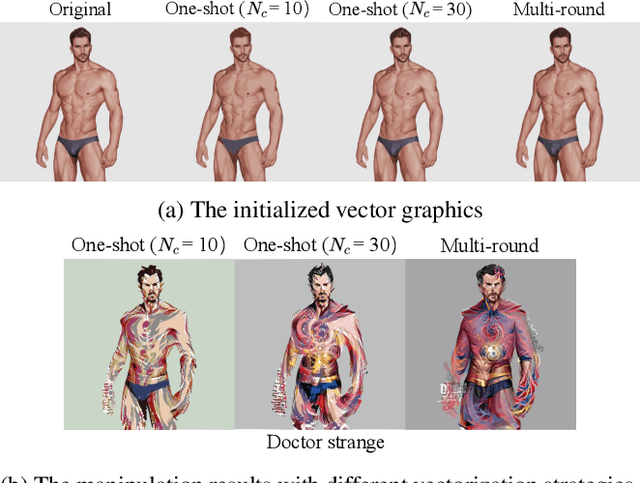
Considerable progress has recently been made in leveraging CLIP (Contrastive Language-Image Pre-Training) models for text-guided image manipulation. However, all existing works rely on additional generative models to ensure the quality of results, because CLIP alone cannot provide enough guidance information for fine-scale pixel-level changes. In this paper, we introduce CLIPVG, a text-guided image manipulation framework using differentiable vector graphics, which is also the first CLIP-based general image manipulation framework that does not require any additional generative models. We demonstrate that CLIPVG can not only achieve state-of-art performance in both semantic correctness and synthesis quality, but also is flexible enough to support various applications far beyond the capability of all existing methods.
Deep Joint Source-Channel Coding for Wireless Image Transmission with Semantic Importance
Feb 05, 2023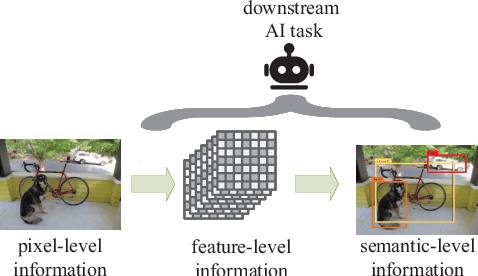
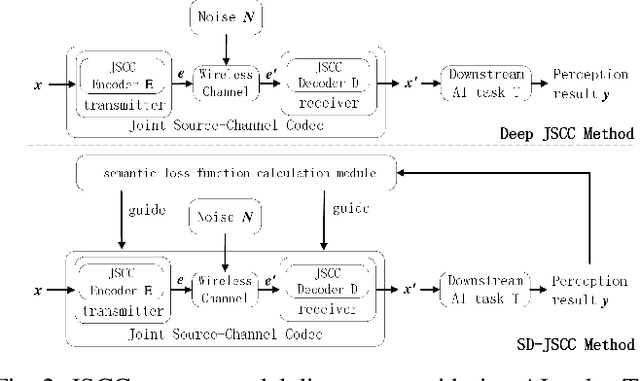
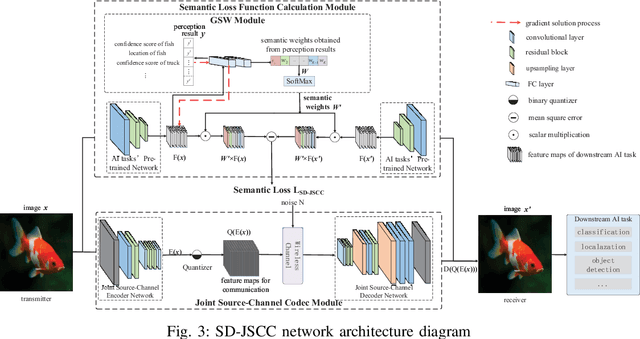
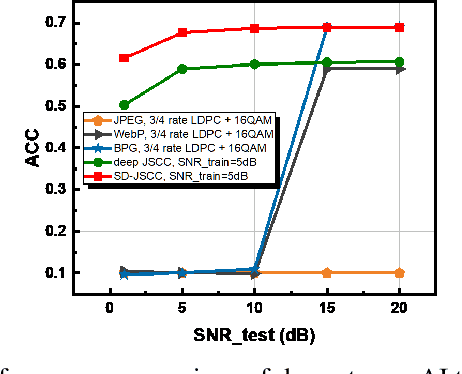
The sixth-generation mobile communication system proposes the vision of smart interconnection of everything, which requires accomplishing communication tasks while ensuring the performance of intelligent tasks. A joint source-channel coding method based on semantic importance is proposed, which aims at preserving semantic information during wireless image transmission and thereby boosting the performance of intelligent tasks for images at the receiver. Specifically, we first propose semantic importance weight calculation method, which is based on the gradient of intelligent task's perception results with respect to the features. Then, we design the semantic loss function in the way of using semantic weights to weight the features. Finally, we train the deep joint source-channel coding network using the semantic loss function. Experiment results demonstrate that the proposed method achieves up to 57.7% and 9.1% improvement in terms of intelligent task's performance compared with the source-channel separation coding method and the deep sourcechannel joint coding method without considering semantics at the same compression rate and signal-to-noise ratio, respectively.
Modeling the Trade-off of Privacy Preservation and Activity Recognition on Low-Resolution Images
Mar 18, 2023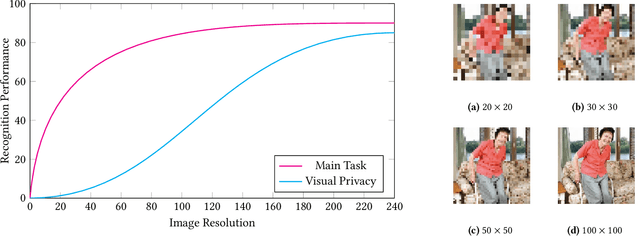
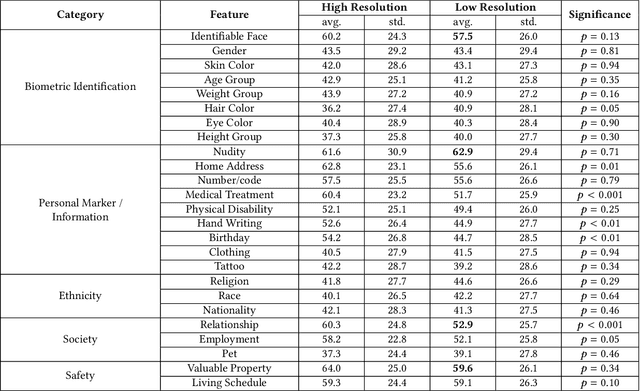
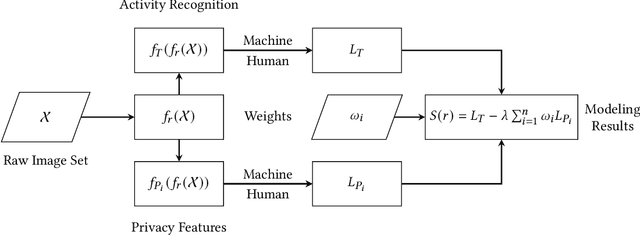
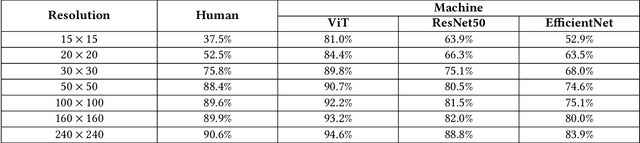
A computer vision system using low-resolution image sensors can provide intelligent services (e.g., activity recognition) but preserve unnecessary visual privacy information from the hardware level. However, preserving visual privacy and enabling accurate machine recognition have adversarial needs on image resolution. Modeling the trade-off of privacy preservation and machine recognition performance can guide future privacy-preserving computer vision systems using low-resolution image sensors. In this paper, using the at-home activity of daily livings (ADLs) as the scenario, we first obtained the most important visual privacy features through a user survey. Then we quantified and analyzed the effects of image resolution on human and machine recognition performance in activity recognition and privacy awareness tasks. We also investigated how modern image super-resolution techniques influence these effects. Based on the results, we proposed a method for modeling the trade-off of privacy preservation and activity recognition on low-resolution images.