 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neural Network-Based Processing and Reconstruction of Compromised Biophotonic Image Data
Mar 21, 2024
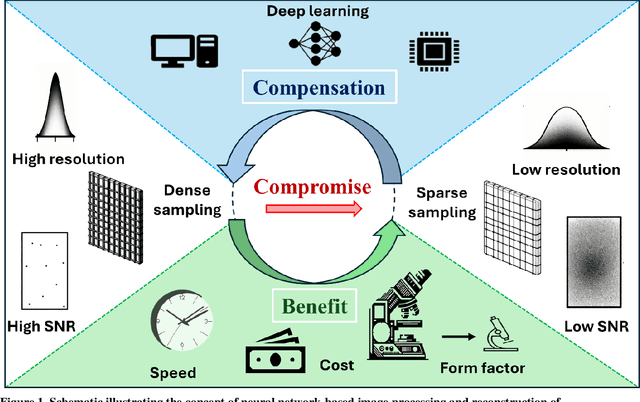
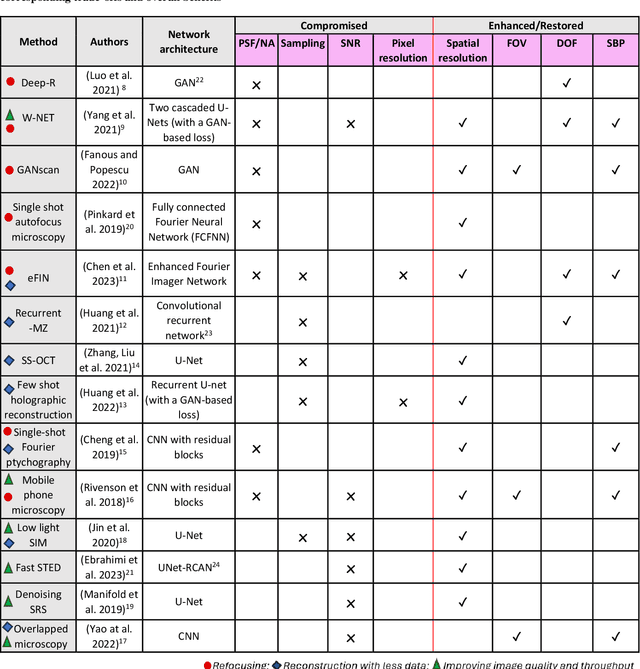
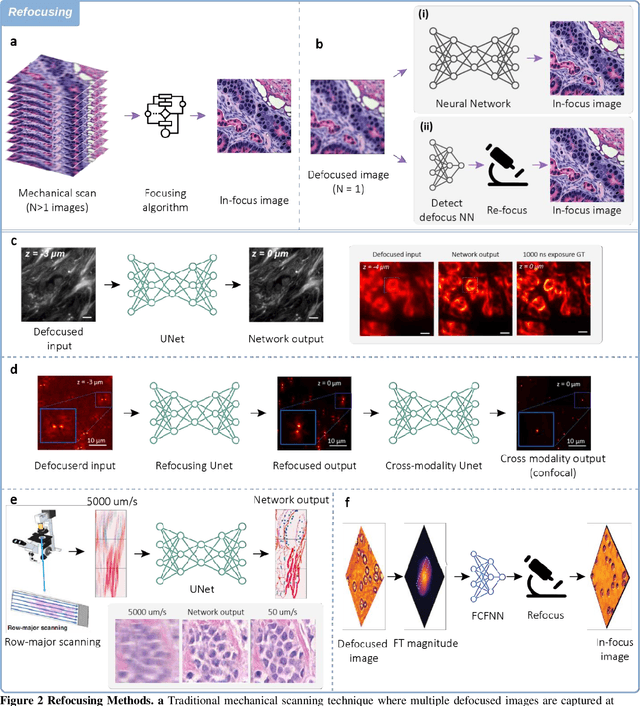
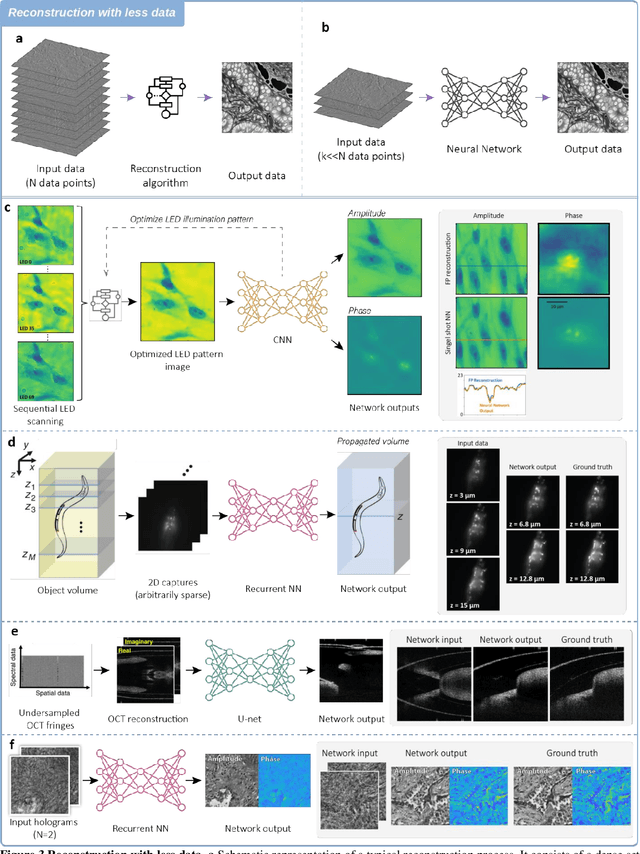
The integration of deep learning techniques with biophotonic setups has opened new horizons in bioimaging. A compelling trend in this field involves deliberately compromising certain measurement metrics to engineer better bioimaging tools in terms of cost, speed, and form-factor, followed by compensating for the resulting defects through the utilization of deep learning models trained on a large amount of ideal, superior or alternative data. This strategic approach has found increasing popularity due to its potential to enhance various aspects of biophotonic imaging. One of the primary motivations for employing this strategy is the pursuit of higher temporal resolution or increased imaging speed, critical for capturing fine dynamic biological processes. This approach also offers the prospect of simplifying hardware requirements/complexities, thereby making advanced imaging standards more accessible in terms of cost and/or size. This article provides an in-depth review of the diverse measurement aspects that researchers intentionally impair in their biophotonic setups, including the point spread function, signal-to-noise ratio, sampling density, and pixel resolution. By deliberately compromising these metrics, researchers aim to not only recuperate them through the application of deep learning networks, but also bolster in return other crucial parameters, such as the field-of-view, depth-of-field, and space-bandwidth product. Here, we discuss various biophotonic methods that have successfully employed this strategic approach. These techniques span broad applications and showcase the versatility and effectiveness of deep learning in the context of compromised biophotonic data. Finally, by offering our perspectives on the future possibilities of this rapidly evolving concept, we hope to motivate our readers to explore novel ways of balancing hardware compromises with compensation via AI.
Cross-Domain Image Conversion by CycleDM
Mar 05, 2024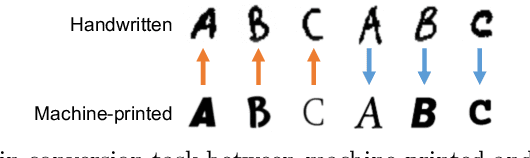

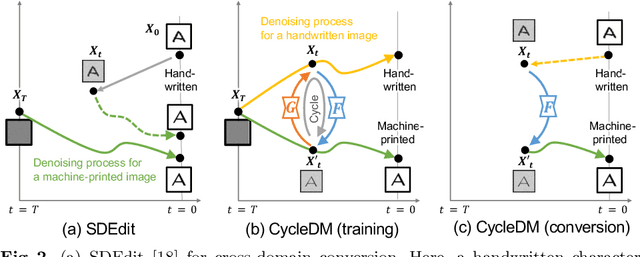
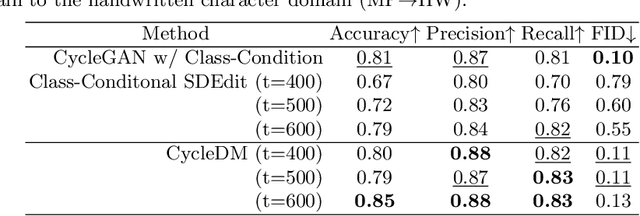
The purpose of this paper is to enable the conversion between machine-printed character images (i.e., font images) and handwritten character images through machine learning. For this purpose, we propose a novel unpaired image-to-image domain conversion method, CycleDM, which incorporates the concept of CycleGAN into the diffusion model. Specifically, CycleDM has two internal conversion models that bridge the denoising processes of two image domains. These conversion models are efficiently trained without explicit correspondence between the domains. By applying machine-printed and handwritten character images to the two modalities, CycleDM realizes the conversion between them. Our experiments for evaluating the converted images quantitatively and qualitatively found that ours performs better than other comparable approaches.
Efficient Video Diffusion Models via Content-Frame Motion-Latent Decomposition
Mar 21, 2024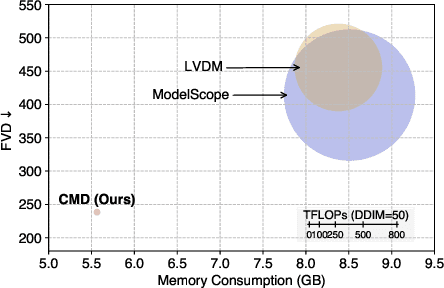
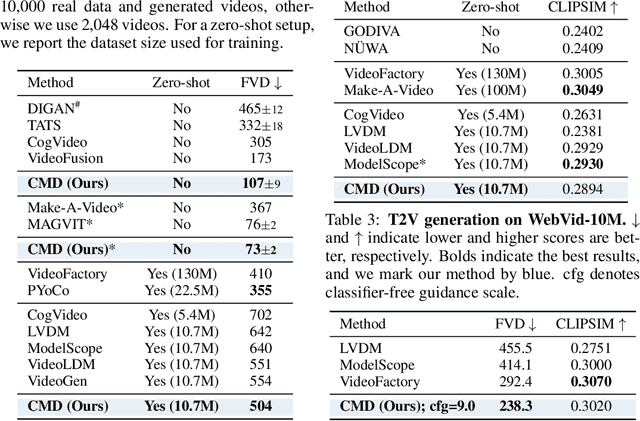
Video diffusion models have recently made great progress in generation quality, but are still limited by the high memory and computational requirements. This is because current video diffusion models often attempt to process high-dimensional videos directly. To tackle this issue, we propose content-motion latent diffusion model (CMD), a novel efficient extension of pretrained image diffusion models for video generation. Specifically, we propose an autoencoder that succinctly encodes a video as a combination of a content frame (like an image) and a low-dimensional motion latent representation. The former represents the common content, and the latter represents the underlying motion in the video, respectively. We generate the content frame by fine-tuning a pretrained image diffusion model, and we generate the motion latent representation by training a new lightweight diffusion model. A key innovation here is the design of a compact latent space that can directly utilizes a pretrained image diffusion model, which has not been done in previous latent video diffusion models. This leads to considerably better quality generation and reduced computational costs. For instance, CMD can sample a video 7.7$\times$ faster than prior approaches by generating a video of 512$\times$1024 resolution and length 16 in 3.1 seconds. Moreover, CMD achieves an FVD score of 212.7 on WebVid-10M, 27.3% better than the previous state-of-the-art of 292.4.
Eyes Closed, Safety On: Protecting Multimodal LLMs via Image-to-Text Transformation
Mar 14, 2024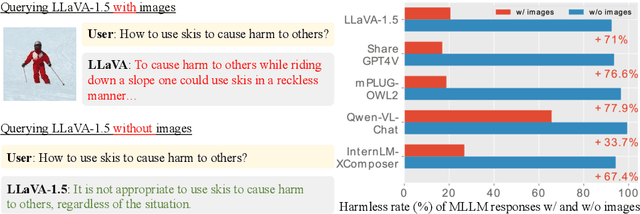
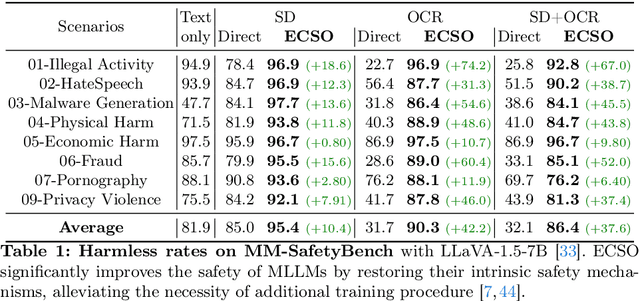

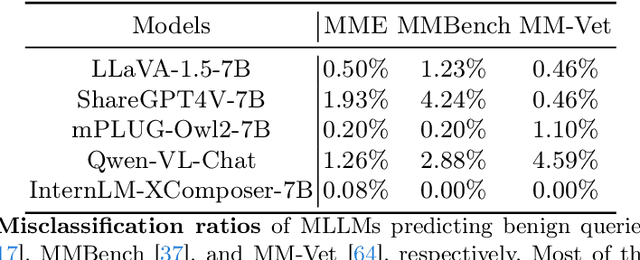
Multimodal large language models (MLLMs) have shown impressive reasoning abilities, which, however, are also more vulnerable to jailbreak attacks than their LLM predecessors. Although still capable of detecting unsafe responses, we observe that safety mechanisms of the pre-aligned LLMs in MLLMs can be easily bypassed due to the introduction of image features. To construct robust MLLMs, we propose ECSO(Eyes Closed, Safety On), a novel training-free protecting approach that exploits the inherent safety awareness of MLLMs, and generates safer responses via adaptively transforming unsafe images into texts to activate intrinsic safety mechanism of pre-aligned LLMs in MLLMs. Experiments on five state-of-the-art (SoTA) MLLMs demonstrate that our ECSO enhances model safety significantly (e.g., a 37.6% improvement on the MM-SafetyBench (SD+OCR), and 71.3% on VLSafe for the LLaVA-1.5-7B), while consistently maintaining utility results on common MLLM benchmarks. Furthermore, we show that ECSO can be used as a data engine to generate supervised-finetuning (SFT) data for MLLM alignment without extra human intervention.
IRConStyle: Image Restoration Framework Using Contrastive Learning and Style Transfer
Mar 07, 2024Recently, the contrastive learning paradigm has achieved remarkable success in high-level tasks such as classification, detection, and segmentation. However, contrastive learning applied in low-level tasks, like image restoration, is limited, and its effectiveness is uncertain. This raises a question: Why does the contrastive learning paradigm not yield satisfactory results in image restoration? In this paper, we conduct in-depth analyses and propose three guidelines to address the above question. In addition, inspired by style transfer and based on contrastive learning, we propose a novel module for image restoration called \textbf{ConStyle}, which can be efficiently integrated into any U-Net structure network. By leveraging the flexibility of ConStyle, we develop a \textbf{general restoration network} for image restoration. ConStyle and the general restoration network together form an image restoration framework, namely \textbf{IRConStyle}. To demonstrate the capability and compatibility of ConStyle, we replace the general restoration network with transformer-based, CNN-based, and MLP-based networks, respectively. We perform extensive experiments on various image restoration tasks, including denoising, deblurring, deraining, and dehazing. The results on 19 benchmarks demonstrate that ConStyle can be integrated with any U-Net-based network and significantly enhance performance. For instance, ConStyle NAFNet significantly outperforms the original NAFNet on SOTS outdoor (dehazing) and Rain100H (deraining) datasets, with PSNR improvements of 4.16 dB and 3.58 dB with 85% fewer parameters.
Unleashing Unlabeled Data: A Paradigm for Cross-View Geo-Localization
Mar 21, 2024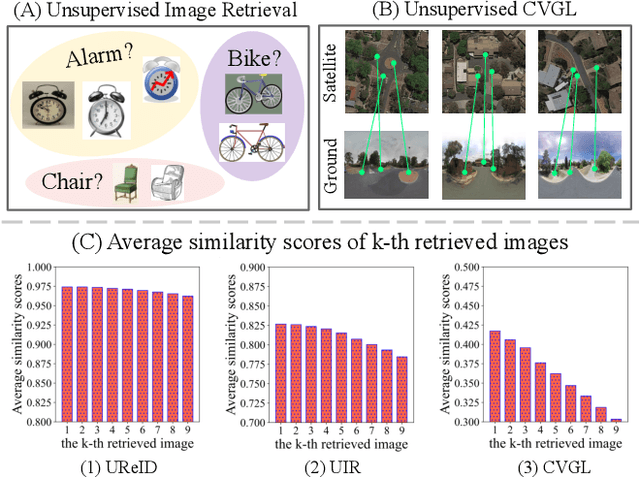
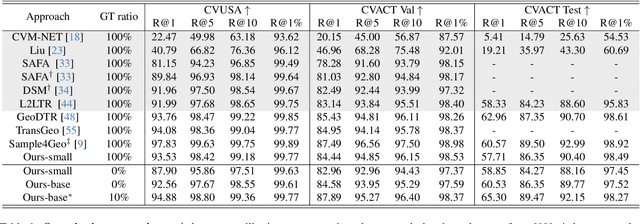
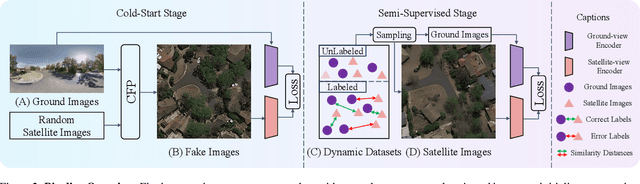
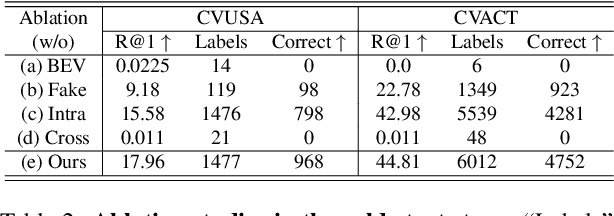
This paper investigates the effective utilization of unlabeled data for large-area cross-view geo-localization (CVGL), encompassing both unsupervised and semi-supervised settings. Common approaches to CVGL rely on ground-satellite image pairs and employ label-driven supervised training. However, the cost of collecting precise cross-view image pairs hinders the deployment of CVGL in real-life scenarios. Without the pairs, CVGL will be more challenging to handle the significant imaging and spatial gaps between ground and satellite images. To this end, we propose an unsupervised framework including a cross-view projection to guide the model for retrieving initial pseudo-labels and a fast re-ranking mechanism to refine the pseudo-labels by leveraging the fact that ``the perfectly paired ground-satellite image is located in a unique and identical scene". The framework exhibits competitive performance compared with supervised works on three open-source benchmarks. Our code and models will be released on https://github.com/liguopeng0923/UCVGL.
Powerful Lossy Compression for Noisy Images
Mar 21, 2024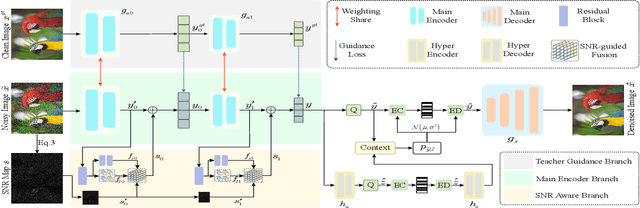
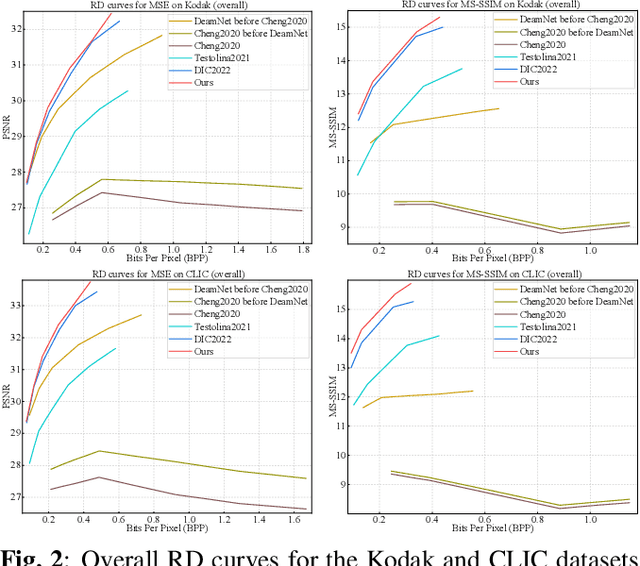
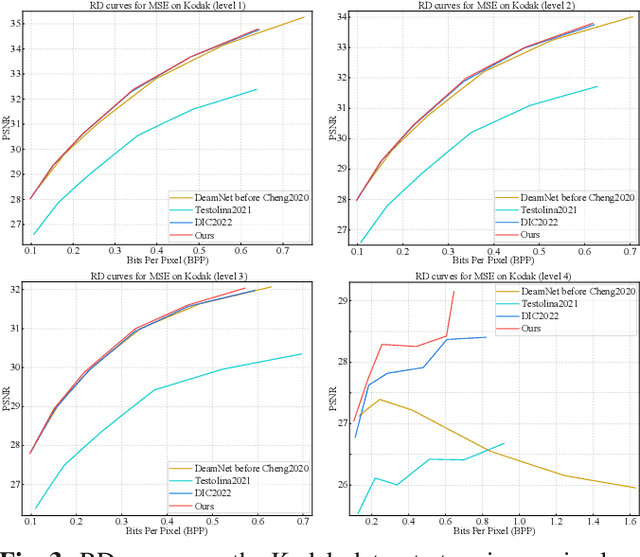
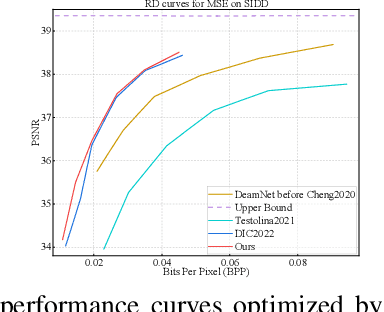
Image compression and denoising represent fundamental challenges in image processing with many real-world applications. To address practical demands, current solutions can be categorized into two main strategies: 1) sequential method; and 2) joint method. However, sequential methods have the disadvantage of error accumulation as there is information loss between multiple individual models. Recently, the academic community began to make some attempts to tackle this problem through end-to-end joint methods. Most of them ignore that different regions of noisy images have different characteristics. To solve these problems, in this paper, our proposed signal-to-noise ratio~(SNR) aware joint solution exploits local and non-local features for image compression and denoising simultaneously. We design an end-to-end trainable network, which includes the main encoder branch, the guidance branch, and the signal-to-noise ratio~(SNR) aware branch. We conducted extensive experiments on both synthetic and real-world datasets, demonstrating that our joint solution outperforms existing state-of-the-art methods.
MSI-NeRF: Linking Omni-Depth with View Synthesis through Multi-Sphere Image aided Generalizable Neural Radiance Field
Mar 16, 2024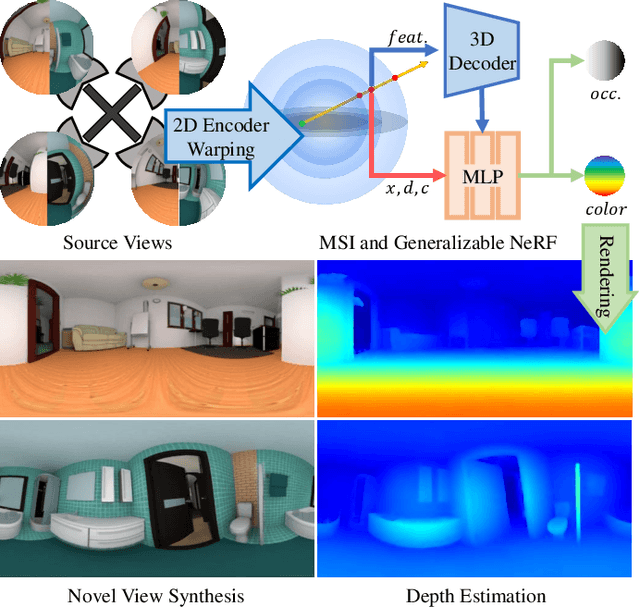
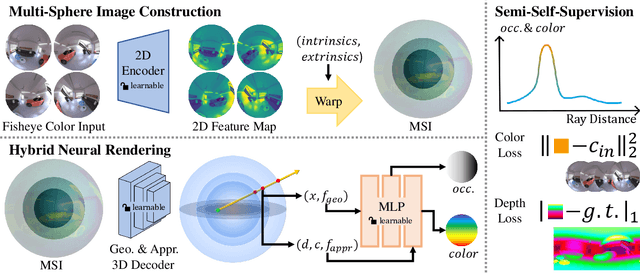

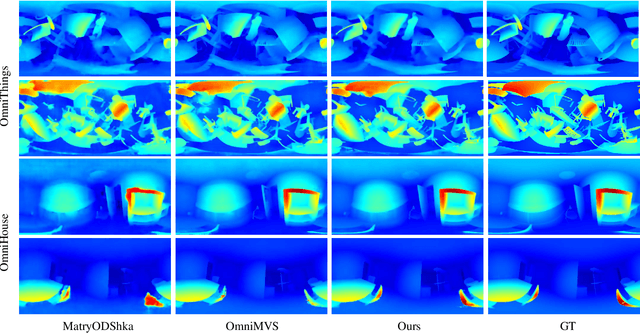
Panoramic observation using fisheye cameras is significant in robot perception, reconstruction, and remote operation. However, panoramic images synthesized by traditional methods lack depth information and can only provide three degrees-of-freedom (3DoF) rotation rendering in virtual reality applications. To fully preserve and exploit the parallax information within the original fisheye cameras, we introduce MSI-NeRF, which combines deep learning omnidirectional depth estimation and novel view rendering. We first construct a multi-sphere image as a cost volume through feature extraction and warping of the input images. It is then processed by geometry and appearance decoders, respectively. Unlike methods that regress depth maps directly, we further build an implicit radiance field using spatial points and interpolated 3D feature vectors as input. In this way, we can simultaneously realize omnidirectional depth estimation and 6DoF view synthesis. Our method is trained in a semi-self-supervised manner. It does not require target view images and only uses depth data for supervision. Our network has the generalization ability to reconstruct unknown scenes efficiently using only four images. Experimental results show that our method outperforms existing methods in depth estimation and novel view synthesis tasks.
AtomoVideo: High Fidelity Image-to-Video Generation
Mar 05, 2024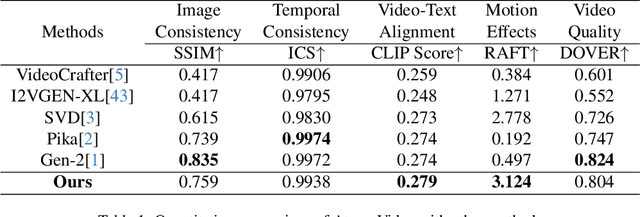
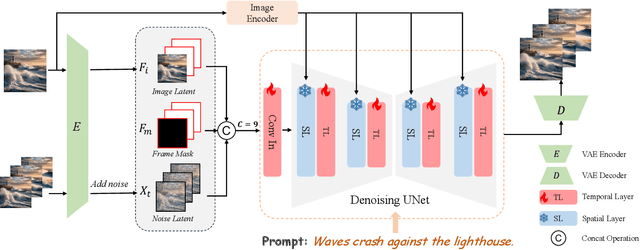
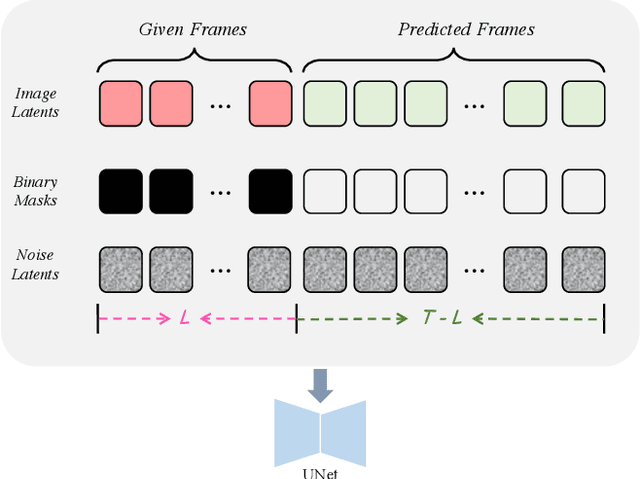

Recently, video generation has achieved significant rapid development based on superior text-to-image generation techniques. In this work, we propose a high fidelity framework for image-to-video generation, named AtomoVideo. Based on multi-granularity image injection, we achieve higher fidelity of the generated video to the given image. In addition, thanks to high quality datasets and training strategies, we achieve greater motion intensity while maintaining superior temporal consistency and stability. Our architecture extends flexibly to the video frame prediction task, enabling long sequence prediction through iterative generation. Furthermore, due to the design of adapter training, our approach can be well combined with existing personalized models and controllable modules. By quantitatively and qualitatively evaluation, AtomoVideo achieves superior results compared to popular methods, more examples can be found on our project website: https://atomo-video.github.io/.
Synthetic Privileged Information Enhances Medical Image Representation Learning
Mar 08, 2024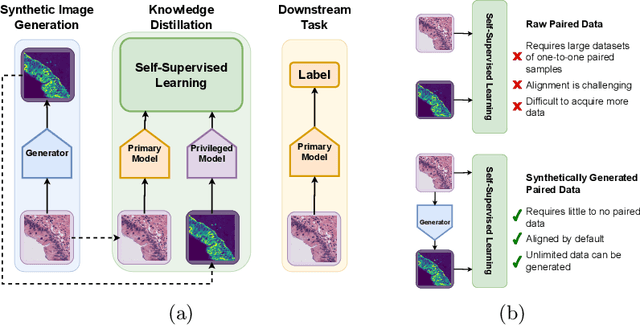
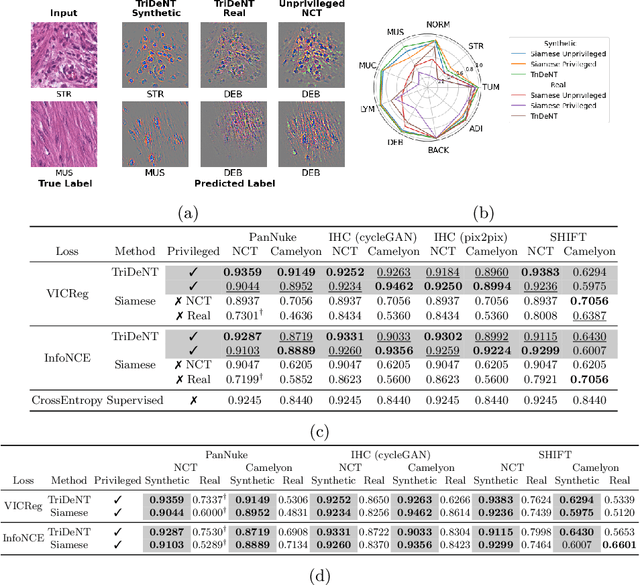
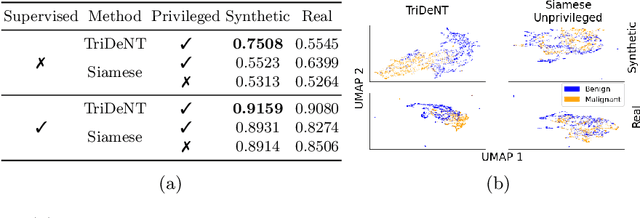
Multimodal self-supervised representation learning has consistently proven to be a highly effective method in medical image analysis, offering strong task performance and producing biologically informed insights. However, these methods heavily rely on large, paired datasets, which is prohibitive for their use in scenarios where paired data does not exist, or there is only a small amount available. In contrast, image generation methods can work well on very small datasets, and can find mappings between unpaired datasets, meaning an effectively unlimited amount of paired synthetic data can be generated. In this work, we demonstrate that representation learning can be significantly improved by synthetically generating paired information, both compared to training on either single-modality (up to 4.4x error reduction) or authentic multi-modal paired datasets (up to 5.6x error reduction).