 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multispectral Imaging for Differential Face Morphing Attack Detection: A Preliminary Study
Apr 07, 2023

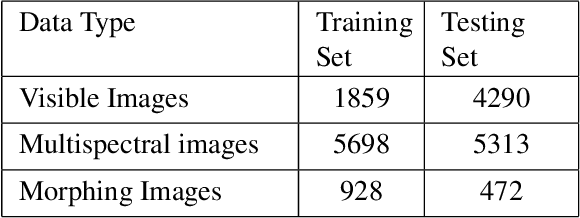
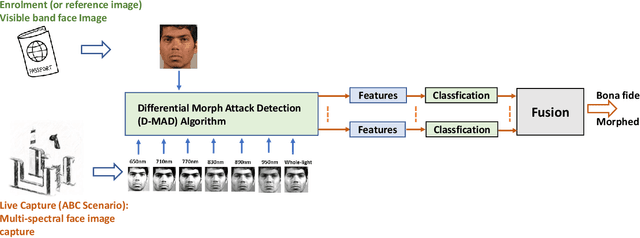
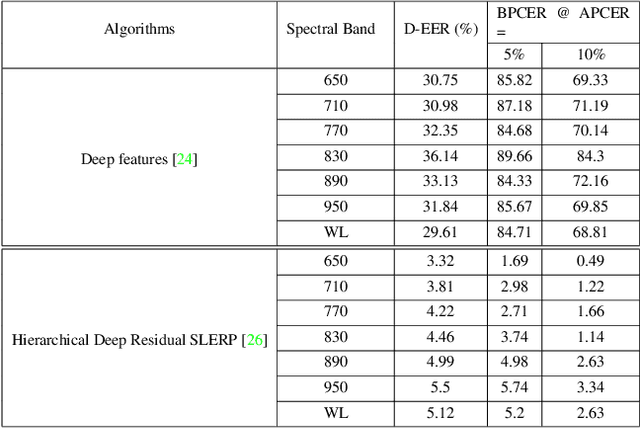
Face morphing attack detection is emerging as an increasingly challenging problem owing to advancements in high-quality and realistic morphing attack generation. Reliable detection of morphing attacks is essential because these attacks are targeted for border control applications. This paper presents a multispectral framework for differential morphing-attack detection (D-MAD). The D-MAD methods are based on using two facial images that are captured from the ePassport (also called the reference image) and the trusted device (for example, Automatic Border Control (ABC) gates) to detect whether the face image presented in ePassport is morphed. The proposed multispectral D-MAD framework introduce a multispectral image captured as a trusted capture to capture seven different spectral bands to detect morphing attacks. Extensive experiments were conducted on the newly created datasets with 143 unique data subjects that were captured using both visible and multispectral cameras in multiple sessions. The results indicate the superior performance of the proposed multispectral framework compared to visible images.
Improving Robustness Against Adversarial Attacks with Deeply Quantized Neural Networks
Apr 25, 2023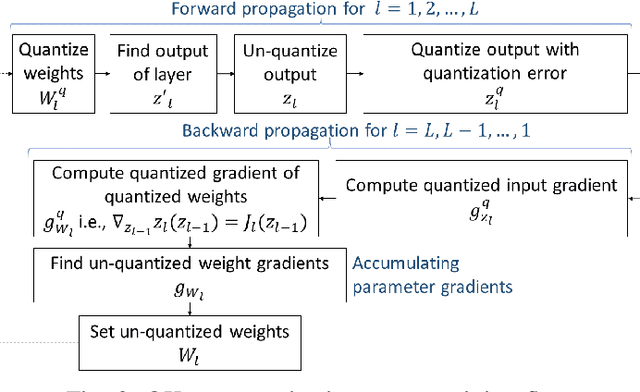
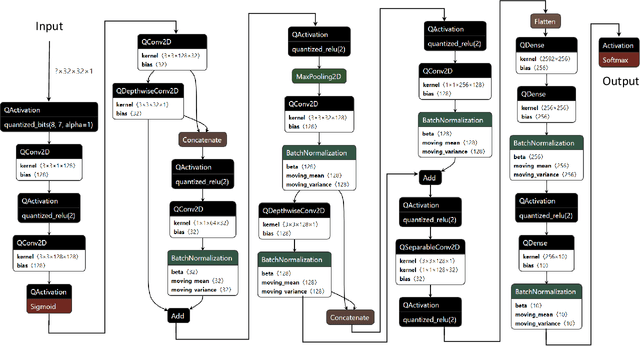
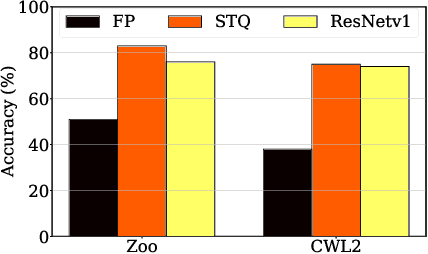
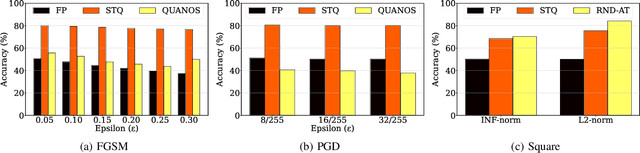
Reducing the memory footprint of Machine Learning (ML) models, particularly Deep Neural Networks (DNNs), is essential to enable their deployment into resource-constrained tiny devices. However, a disadvantage of DNN models is their vulnerability to adversarial attacks, as they can be fooled by adding slight perturbations to the inputs. Therefore, the challenge is how to create accurate, robust, and tiny DNN models deployable on resource-constrained embedded devices. This paper reports the results of devising a tiny DNN model, robust to adversarial black and white box attacks, trained with an automatic quantizationaware training framework, i.e. QKeras, with deep quantization loss accounted in the learning loop, thereby making the designed DNNs more accurate for deployment on tiny devices. We investigated how QKeras and an adversarial robustness technique, Jacobian Regularization (JR), can provide a co-optimization strategy by exploiting the DNN topology and the per layer JR approach to produce robust yet tiny deeply quantized DNN models. As a result, a new DNN model implementing this cooptimization strategy was conceived, developed and tested on three datasets containing both images and audio inputs, as well as compared its performance with existing benchmarks against various white-box and black-box attacks. Experimental results demonstrated that on average our proposed DNN model resulted in 8.3% and 79.5% higher accuracy than MLCommons/Tiny benchmarks in the presence of white-box and black-box attacks on the CIFAR-10 image dataset and a subset of the Google Speech Commands audio dataset respectively. It was also 6.5% more accurate for black-box attacks on the SVHN image dataset.
PATS: Patch Area Transportation with Subdivision for Local Feature Matching
Apr 04, 2023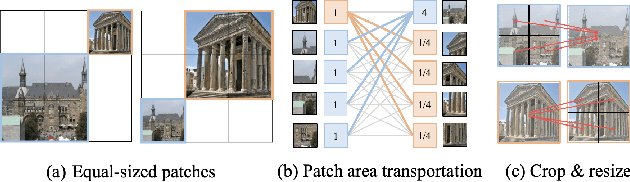

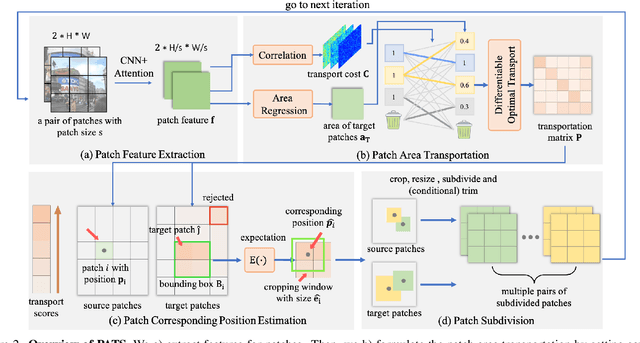
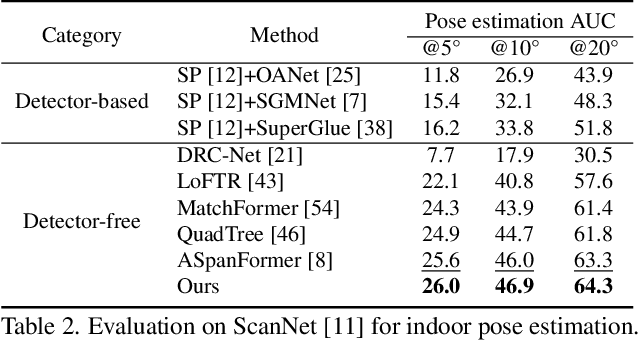
Local feature matching aims at establishing sparse correspondences between a pair of images. Recently, detector-free methods present generally better performance but are not satisfactory in image pairs with large scale differences. In this paper, we propose Patch Area Transportation with Subdivision (PATS) to tackle this issue. Instead of building an expensive image pyramid, we start by splitting the original image pair into equal-sized patches and gradually resizing and subdividing them into smaller patches with the same scale. However, estimating scale differences between these patches is non-trivial since the scale differences are determined by both relative camera poses and scene structures, and thus spatially varying over image pairs. Moreover, it is hard to obtain the ground truth for real scenes. To this end, we propose patch area transportation, which enables learning scale differences in a self-supervised manner. In contrast to bipartite graph matching, which only handles one-to-one matching, our patch area transportation can deal with many-to-many relationships. PATS improves both matching accuracy and coverage, and shows superior performance in downstream tasks, such as relative pose estimation, visual localization, and optical flow estimation. The source code is available at \url{https://zju3dv.github.io/pats/}.
From Online Behaviours to Images: A Novel Approach to Social Bot Detection
Apr 15, 2023


Online Social Networks have revolutionized how we consume and share information, but they have also led to a proliferation of content not always reliable and accurate. One particular type of social accounts is known to promote unreputable content, hyperpartisan, and propagandistic information. They are automated accounts, commonly called bots. Focusing on Twitter accounts, we propose a novel approach to bot detection: we first propose a new algorithm that transforms the sequence of actions that an account performs into an image; then, we leverage the strength of Convolutional Neural Networks to proceed with image classification. We compare our performances with state-of-the-art results for bot detection on genuine accounts / bot accounts datasets well known in the literature. The results confirm the effectiveness of the proposal, because the detection capability is on par with the state of the art, if not better in some cases.
Finding the Most Transferable Tasks for Brain Image Segmentation
Jan 03, 2023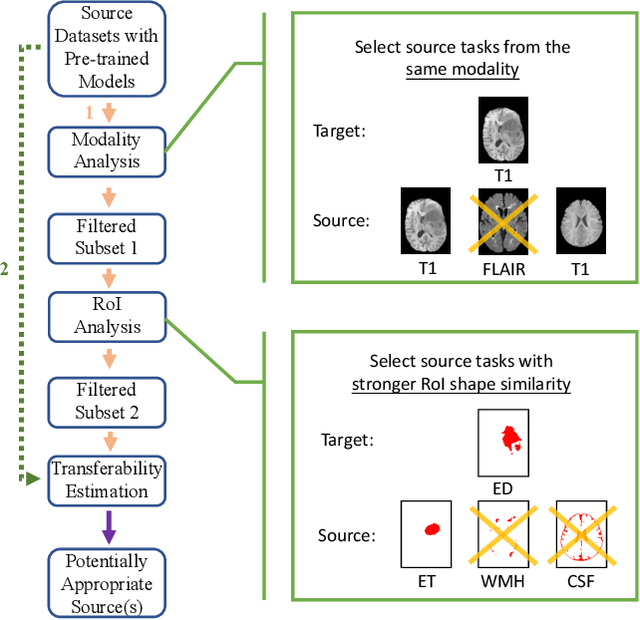
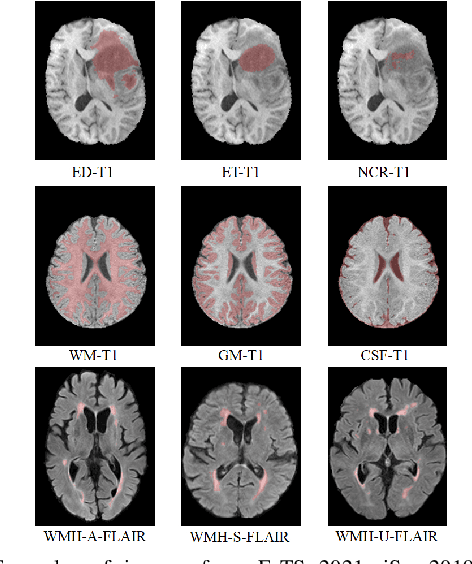
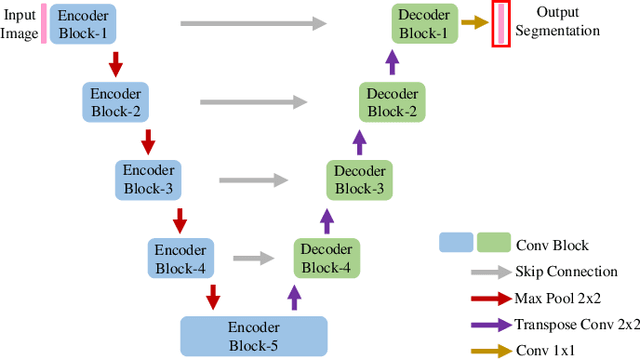
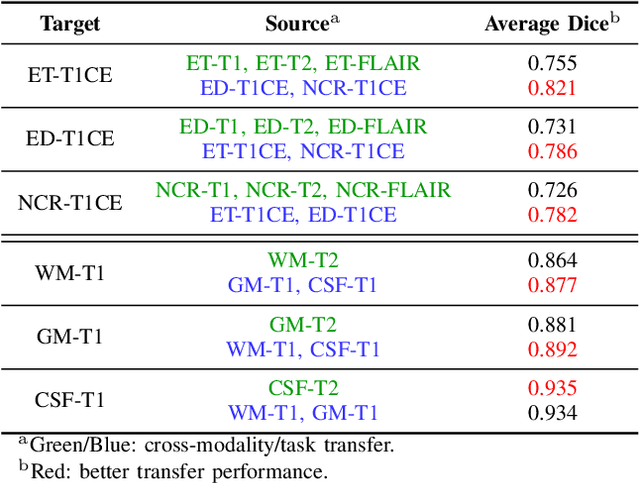
Although many studies have successfully applied transfer learning to medical image segmentation, very few of them have investigated the selection strategy when multiple source tasks are available for transfer. In this paper, we propose a prior knowledge guided and transferability based framework to select the best source tasks among a collection of brain image segmentation tasks, to improve the transfer learning performance on the given target task. The framework consists of modality analysis, RoI (region of interest) analysis, and transferability estimation, such that the source task selection can be refined step by step. Specifically, we adapt the state-of-the-art analytical transferability estimation metrics to medical image segmentation tasks and further show that their performance can be significantly boosted by filtering candidate source tasks based on modality and RoI characteristics. Our experiments on brain matter, brain tumor, and white matter hyperintensities segmentation datasets reveal that transferring from different tasks under the same modality is often more successful than transferring from the same task under different modalities. Furthermore, within the same modality, transferring from the source task that has stronger RoI shape similarity with the target task can significantly improve the final transfer performance. And such similarity can be captured using the Structural Similarity index in the label space.
Mixed Attention Network for Hyperspectral Image Denoising
Jan 27, 2023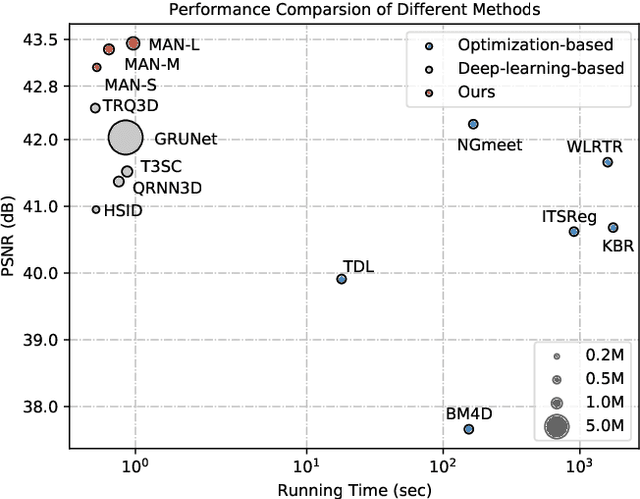
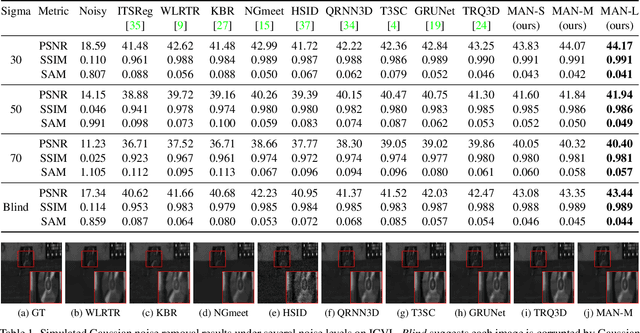
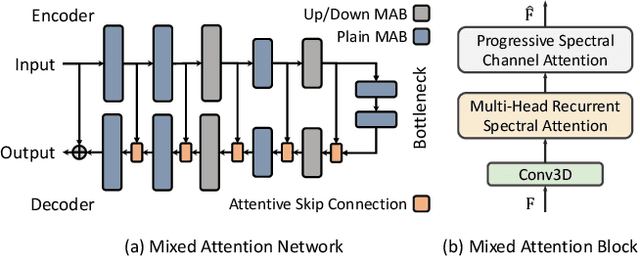
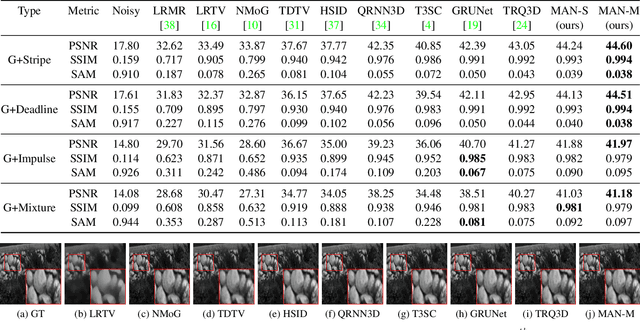
Hyperspectral image denoising is unique for the highly similar and correlated spectral information that should be properly considered. However, existing methods show limitations in exploring the spectral correlations across different bands and feature interactions within each band. Besides, the low- and high-level features usually exhibit different importance for different spatial-spectral regions, which is not fully explored for current algorithms as well. In this paper, we present a Mixed Attention Network (MAN) that simultaneously considers the inter- and intra-spectral correlations as well as the interactions between low- and high-level spatial-spectral meaningful features. Specifically, we introduce a multi-head recurrent spectral attention that efficiently integrates the inter-spectral features across all the spectral bands. These features are further enhanced with a progressive spectral channel attention by exploring the intra-spectral relationships. Moreover, we propose an attentive skip-connection that adaptively controls the proportion of the low- and high-level spatial-spectral features from the encoder and decoder to better enhance the aggregated features. Extensive experiments show that our MAN outperforms existing state-of-the-art methods on simulated and real noise settings while maintaining a low cost of parameters and running time.
MoBYv2AL: Self-supervised Active Learning for Image Classification
Jan 04, 2023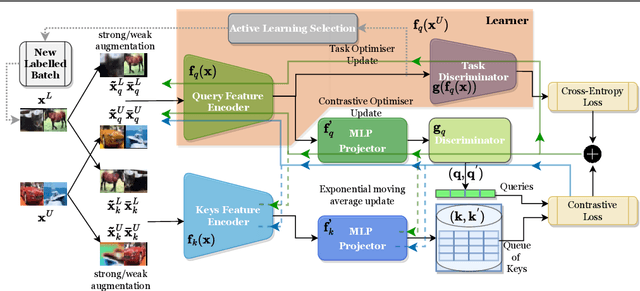
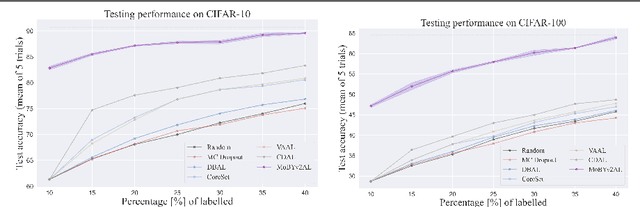

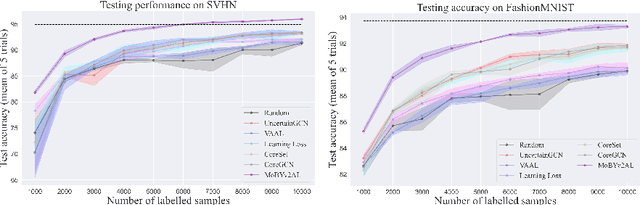
Active learning(AL) has recently gained popularity for deep learning(DL) models. This is due to efficient and informative sampling, especially when the learner requires large-scale labelled datasets. Commonly, the sampling and training happen in stages while more batches are added. One main bottleneck in this strategy is the narrow representation learned by the model that affects the overall AL selection. We present MoBYv2AL, a novel self-supervised active learning framework for image classification. Our contribution lies in lifting MoBY, one of the most successful self-supervised learning algorithms, to the AL pipeline. Thus, we add the downstream task-aware objective function and optimize it jointly with contrastive loss. Further, we derive a data-distribution selection function from labelling the new examples. Finally, we test and study our pipeline robustness and performance for image classification tasks. We successfully achieved state-of-the-art results when compared to recent AL methods. Code available: https://github.com/razvancaramalau/MoBYv2AL
Unify, Align and Refine: Multi-Level Semantic Alignment for Radiology Report Generation
Apr 05, 2023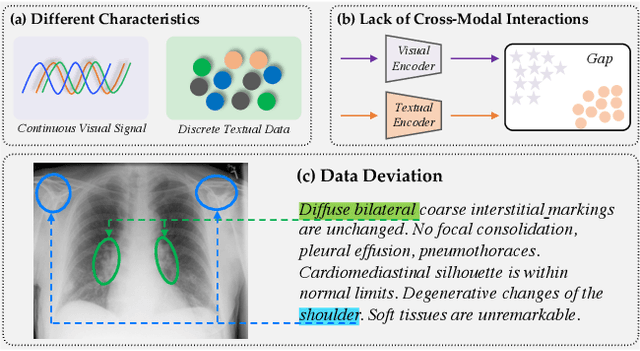
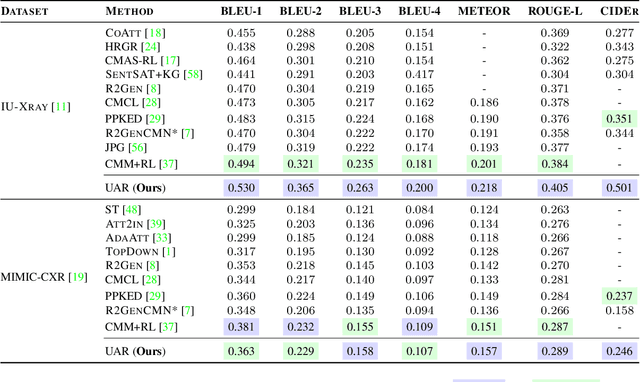
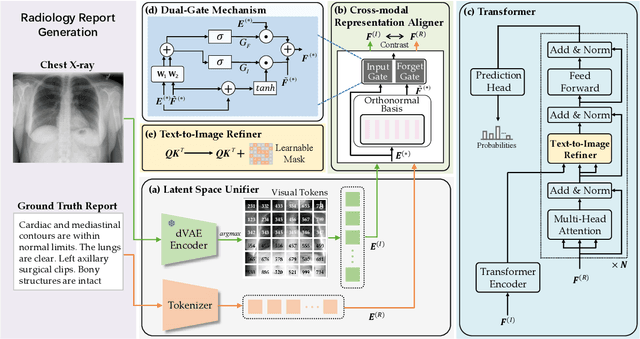
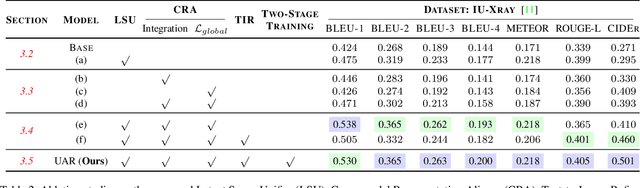
Automatic radiology report generation has attracted enormous research interest due to its practical value in reducing the workload of radiologists. However, simultaneously establishing global correspondences between the image (e.g., Chest X-ray) and its related report and local alignments between image patches and keywords remains challenging. To this end, we propose an Unify, Align and then Refine (UAR) approach to learn multi-level cross-modal alignments and introduce three novel modules: Latent Space Unifier (LSU), Cross-modal Representation Aligner (CRA) and Text-to-Image Refiner (TIR). Specifically, LSU unifies multimodal data into discrete tokens, making it flexible to learn common knowledge among modalities with a shared network. The modality-agnostic CRA learns discriminative features via a set of orthonormal basis and a dual-gate mechanism first and then globally aligns visual and textual representations under a triplet contrastive loss. TIR boosts token-level local alignment via calibrating text-to-image attention with a learnable mask. Additionally, we design a two-stage training procedure to make UAR gradually grasp cross-modal alignments at different levels, which imitates radiologists' workflow: writing sentence by sentence first and then checking word by word. Extensive experiments and analyses on IU-Xray and MIMIC-CXR benchmark datasets demonstrate the superiority of our UAR against varied state-of-the-art methods.
Anything-3D: Towards Single-view Anything Reconstruction in the Wild
Apr 19, 2023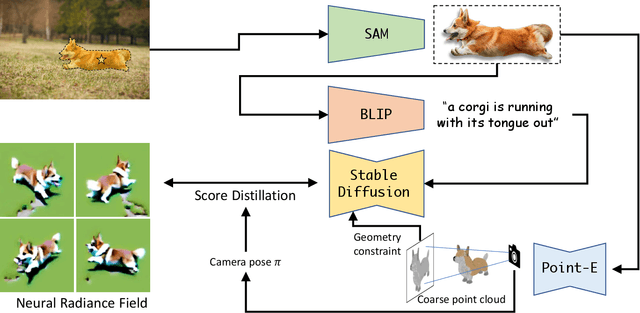


3D reconstruction from a single-RGB image in unconstrained real-world scenarios presents numerous challenges due to the inherent diversity and complexity of objects and environments. In this paper, we introduce Anything-3D, a methodical framework that ingeniously combines a series of visual-language models and the Segment-Anything object segmentation model to elevate objects to 3D, yielding a reliable and versatile system for single-view conditioned 3D reconstruction task. Our approach employs a BLIP model to generate textural descriptions, utilizes the Segment-Anything model for the effective extraction of objects of interest, and leverages a text-to-image diffusion model to lift object into a neural radiance field. Demonstrating its ability to produce accurate and detailed 3D reconstructions for a wide array of objects, \emph{Anything-3D\footnotemark[2]} shows promise in addressing the limitations of existing methodologies. Through comprehensive experiments and evaluations on various datasets, we showcase the merits of our approach, underscoring its potential to contribute meaningfully to the field of 3D reconstruction. Demos and code will be available at \href{https://github.com/Anything-of-anything/Anything-3D}{https://github.com/Anything-of-anything/Anything-3D}.
Learning Semi-supervised Gaussian Mixture Models for Generalized Category Discovery
May 10, 2023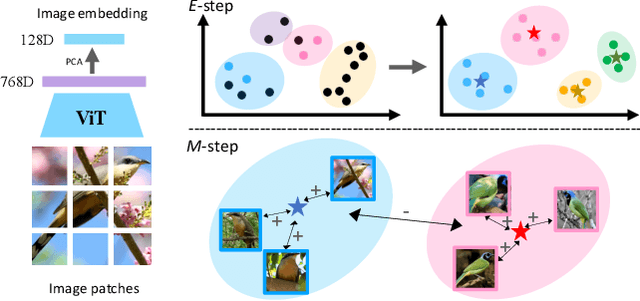
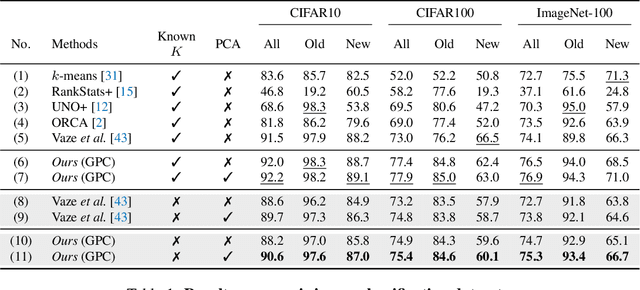

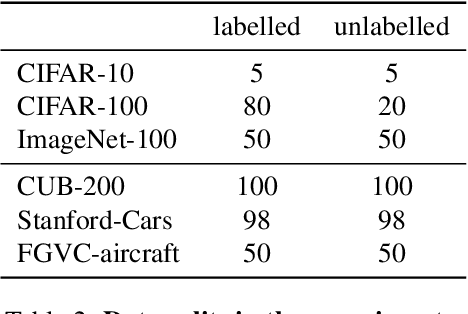
In this paper, we address the problem of generalized category discovery (GCD), \ie, given a set of images where part of them are labelled and the rest are not, the task is to automatically cluster the images in the unlabelled data, leveraging the information from the labelled data, while the unlabelled data contain images from the labelled classes and also new ones. GCD is similar to semi-supervised learning (SSL) but is more realistic and challenging, as SSL assumes all the unlabelled images are from the same classes as the labelled ones. We also do not assume the class number in the unlabelled data is known a-priori, making the GCD problem even harder. To tackle the problem of GCD without knowing the class number, we propose an EM-like framework that alternates between representation learning and class number estimation. We propose a semi-supervised variant of the Gaussian Mixture Model (GMM) with a stochastic splitting and merging mechanism to dynamically determine the prototypes by examining the cluster compactness and separability. With these prototypes, we leverage prototypical contrastive learning for representation learning on the partially labelled data subject to the constraints imposed by the labelled data. Our framework alternates between these two steps until convergence. The cluster assignment for an unlabelled instance can then be retrieved by identifying its nearest prototype. We comprehensively evaluate our framework on both generic image classification datasets and challenging fine-grained object recognition datasets, achieving state-of-the-art performance.