 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Imagen Editor and EditBench: Advancing and Evaluating Text-Guided Image Inpainting
Dec 13, 2022
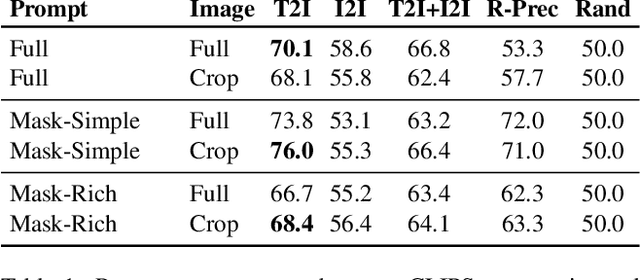
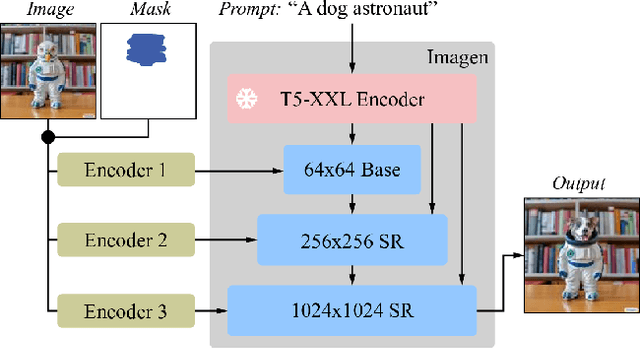
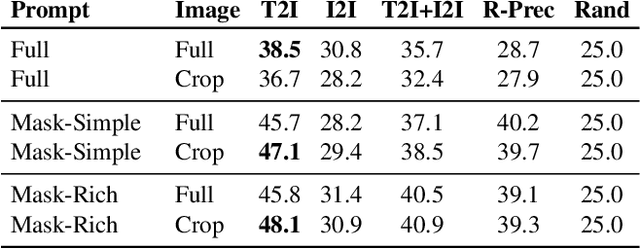

Text-guided image editing can have a transformative impact in supporting creative applications. A key challenge is to generate edits that are faithful to input text prompts, while consistent with input images. We present Imagen Editor, a cascaded diffusion model built, by fine-tuning Imagen on text-guided image inpainting. Imagen Editor's edits are faithful to the text prompts, which is accomplished by using object detectors to propose inpainting masks during training. In addition, Imagen Editor captures fine details in the input image by conditioning the cascaded pipeline on the original high resolution image. To improve qualitative and quantitative evaluation, we introduce EditBench, a systematic benchmark for text-guided image inpainting. EditBench evaluates inpainting edits on natural and generated images exploring objects, attributes, and scenes. Through extensive human evaluation on EditBench, we find that object-masking during training leads to across-the-board improvements in text-image alignment -- such that Imagen Editor is preferred over DALL-E 2 and Stable Diffusion -- and, as a cohort, these models are better at object-rendering than text-rendering, and handle material/color/size attributes better than count/shape attributes.
Hybrid Neural Rendering for Large-Scale Scenes with Motion Blur
Apr 25, 2023
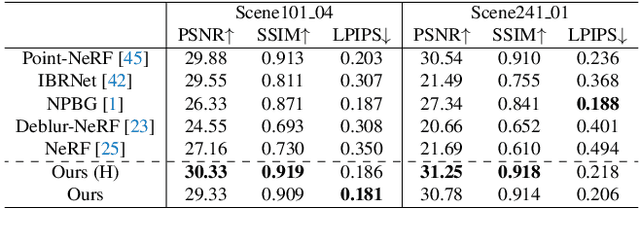

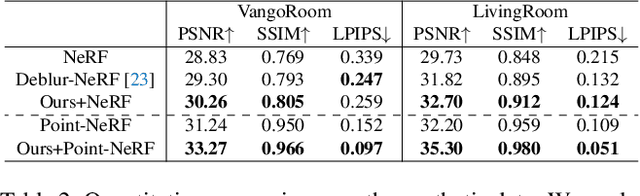
Rendering novel view images is highly desirable for many applications. Despite recent progress, it remains challenging to render high-fidelity and view-consistent novel views of large-scale scenes from in-the-wild images with inevitable artifacts (e.g., motion blur). To this end, we develop a hybrid neural rendering model that makes image-based representation and neural 3D representation join forces to render high-quality, view-consistent images. Besides, images captured in the wild inevitably contain artifacts, such as motion blur, which deteriorates the quality of rendered images. Accordingly, we propose strategies to simulate blur effects on the rendered images to mitigate the negative influence of blurriness images and reduce their importance during training based on precomputed quality-aware weights. Extensive experiments on real and synthetic data demonstrate our model surpasses state-of-the-art point-based methods for novel view synthesis. The code is available at https://daipengwa.github.io/Hybrid-Rendering-ProjectPage.
Underwater object classification combining SAS and transferred optical-to-SAS Imagery
Apr 24, 2023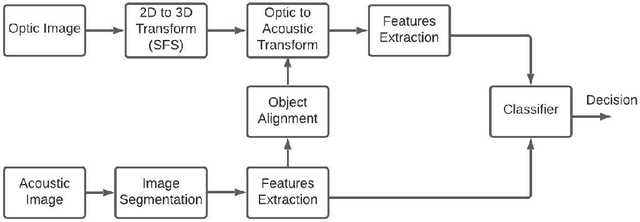
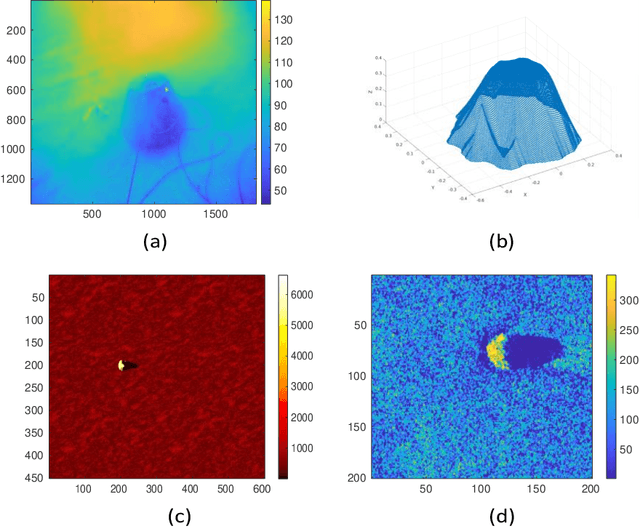
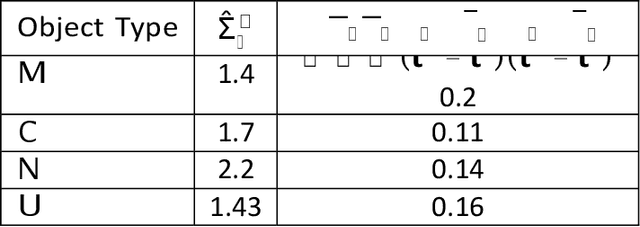
Combining synthetic aperture sonar (SAS) imagery with optical images for underwater object classification has the potential to overcome challenges such as water clarity, the stability of the optical image analysis platform, and strong reflections from the seabed for sonar-based classification. In this work, we propose this type of multi-modal combination to discriminate between man-made targets and objects such as rocks or litter. We offer a novel classification algorithm that overcomes the problem of intensity and object formation differences between the two modalities. To this end, we develop a novel set of geometrical shape descriptors that takes into account the geometrical relation between the objects shadow and highlight. Results from 7,052 pairs of SAS and optical images collected during several sea experiments show improved classification performance compared to the state-of-the-art for better discrimination between different types of underwater objects. For reproducibility, we share our database.
Instruct 3D-to-3D: Text Instruction Guided 3D-to-3D conversion
Mar 28, 2023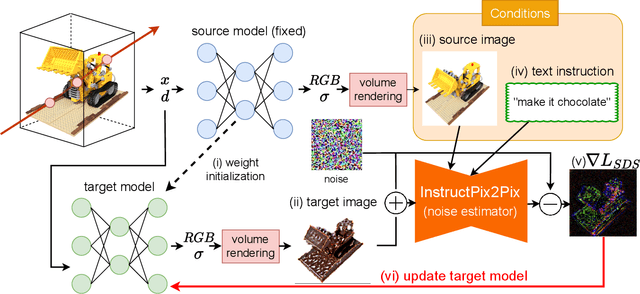
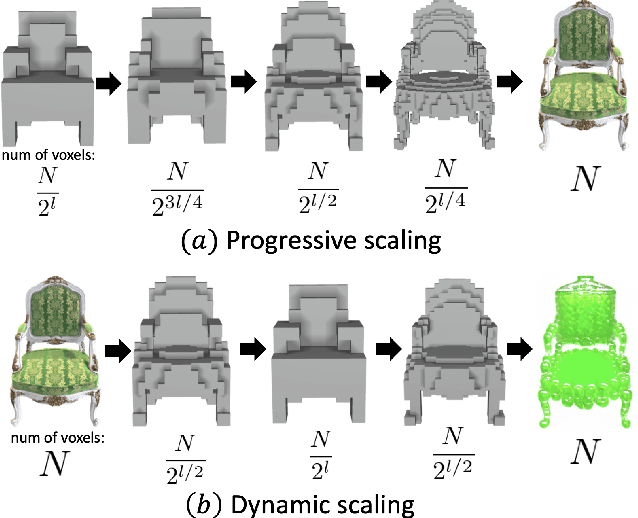

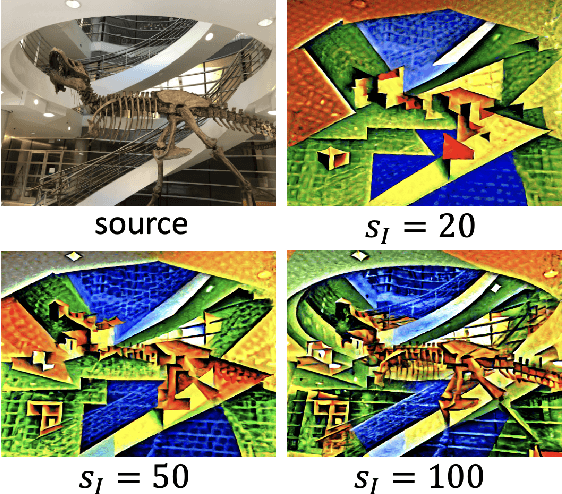
We propose a high-quality 3D-to-3D conversion method, Instruct 3D-to-3D. Our method is designed for a novel task, which is to convert a given 3D scene to another scene according to text instructions. Instruct 3D-to-3D applies pretrained Image-to-Image diffusion models for 3D-to-3D conversion. This enables the likelihood maximization of each viewpoint image and high-quality 3D generation. In addition, our proposed method explicitly inputs the source 3D scene as a condition, which enhances 3D consistency and controllability of how much of the source 3D scene structure is reflected. We also propose dynamic scaling, which allows the intensity of the geometry transformation to be adjusted. We performed quantitative and qualitative evaluations and showed that our proposed method achieves higher quality 3D-to-3D conversions than baseline methods.
NA-SODINN: a deep learning algorithm for exoplanet image detection based on residual noise regimes
Feb 06, 2023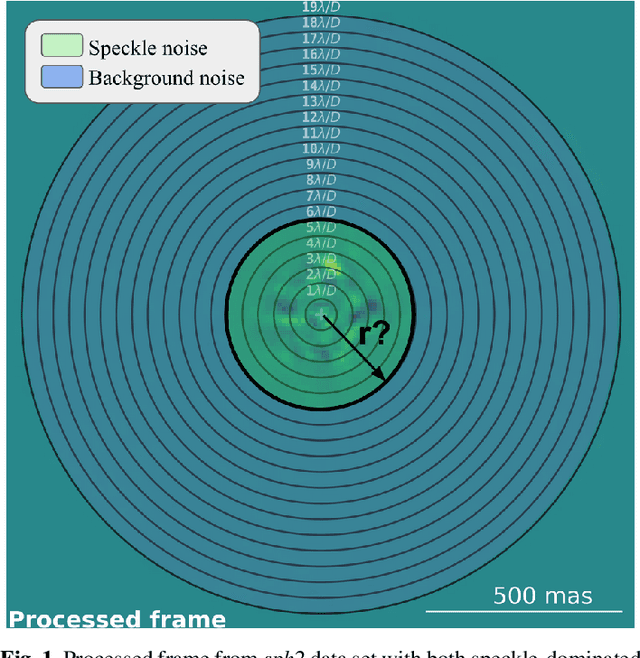
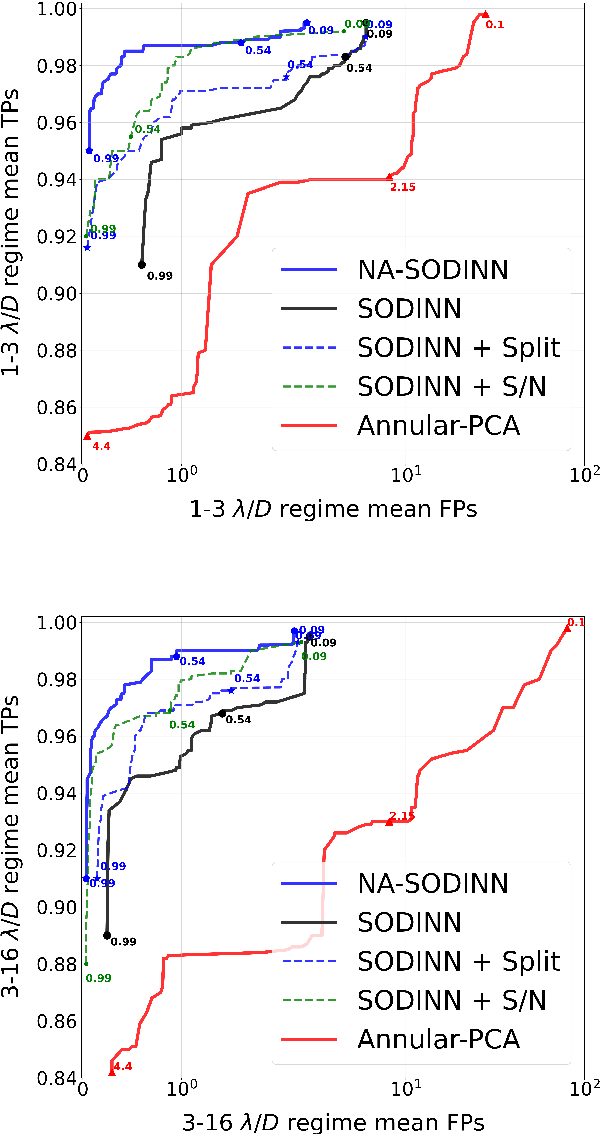
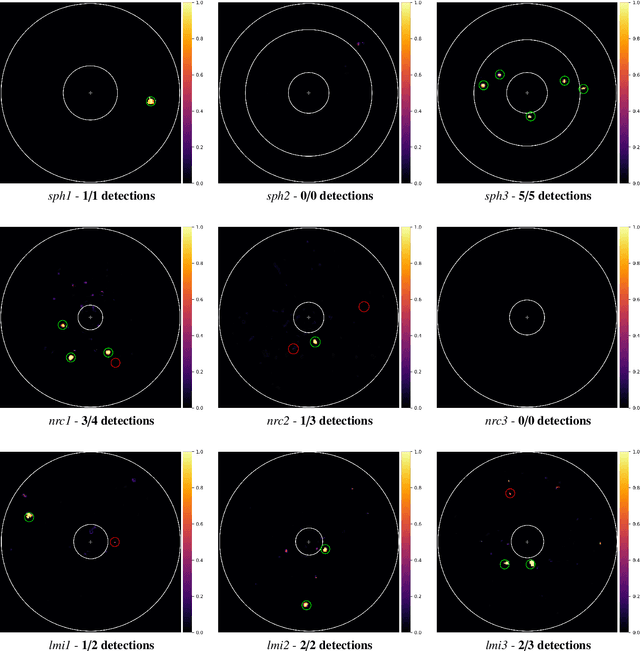
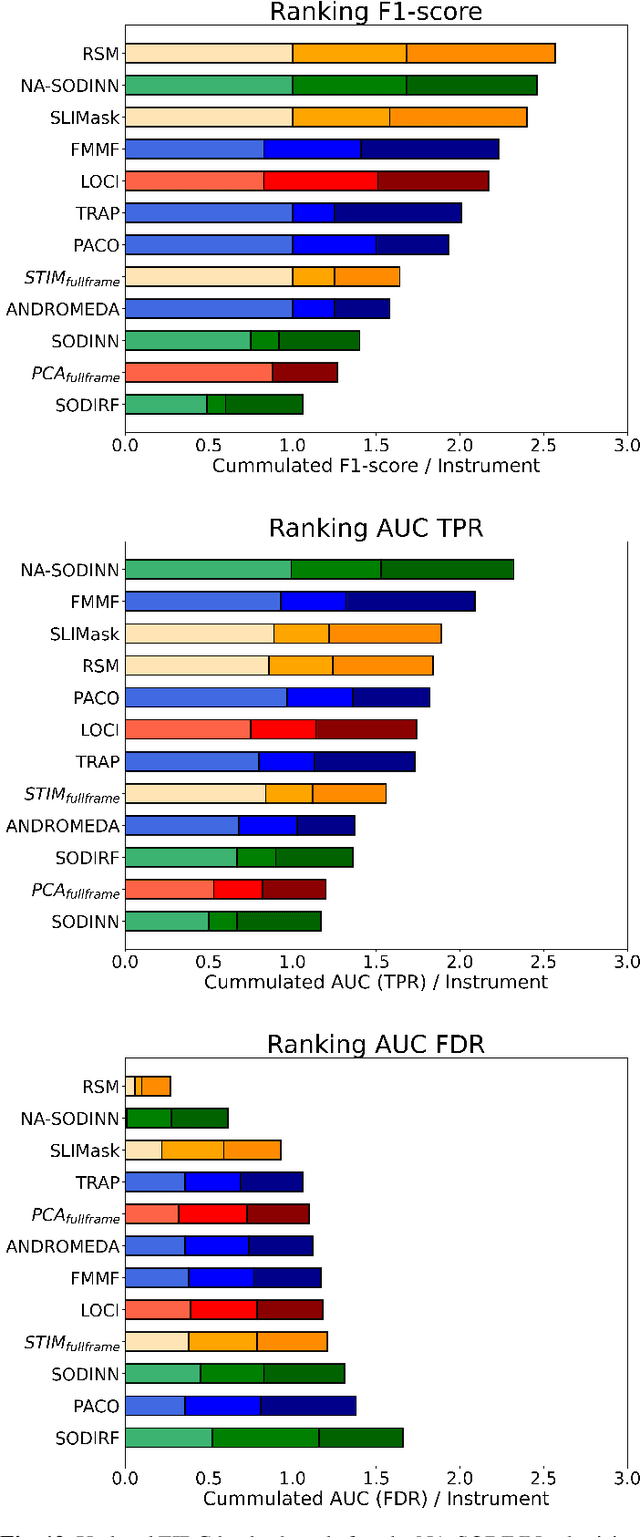
Supervised machine learning was recently introduced in high-contrast imaging (HCI) through the SODINN algorithm, a convolutional neural network designed for exoplanet detection in angular differential imaging (ADI) data sets. The benchmarking of HCI algorithms within the Exoplanet Imaging Data Challenge (EIDC) showed that (i) SODINN can produce a high number of false positives in the final detection maps, and (ii) algorithms processing images in a more local manner perform better. This work aims to improve the SODINN detection performance by introducing new local processing approaches and adapting its learning process accordingly. We propose NA-SODINN, a new deep learning architecture that better captures image noise correlations by training an independent SODINN model per noise regime over the processed frame. The identification of these noise regimes is based on a novel technique, named PCA-pmaps, which allows to estimate the distance from the star in the image from which background noise starts to dominate over residual speckle noise. NA-SODINN is also fed with local discriminators, such as S/N curves, which complement spatio-temporal feature maps when training the model.Our new approach is tested against its predecessor, as well as two SODINN-based hybrid models and a more standard annular-PCA approach, through local ROC analysis of ADI sequences from VLT/SPHERE and Keck/NIRC-2 instruments. Results show that NA-SODINN enhances SODINN in both the sensitivity and specificity, especially in the speckle-dominated noise regime. NA-SODINN is also benchmarked against the complete set of submitted detection algorithms in EIDC, in which we show that its final detection score matches or outperforms the most powerful detection algorithms, reaching a performance similar to that of the Regime Switching Model algorithm.
Learning-Based Conditional Image Coder Using Color Separation
Dec 12, 2022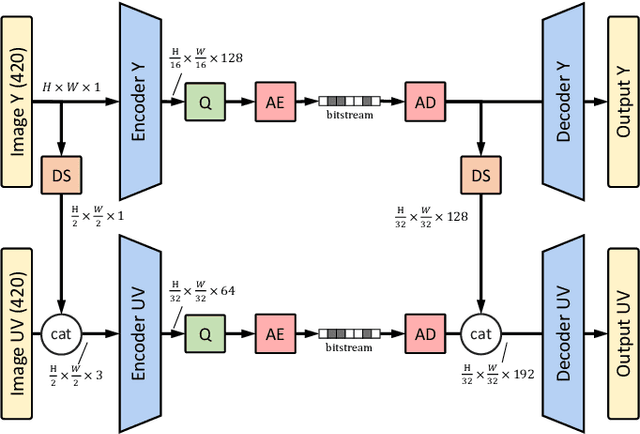

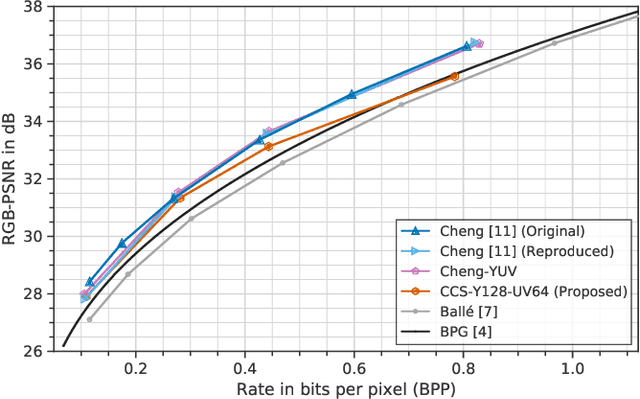
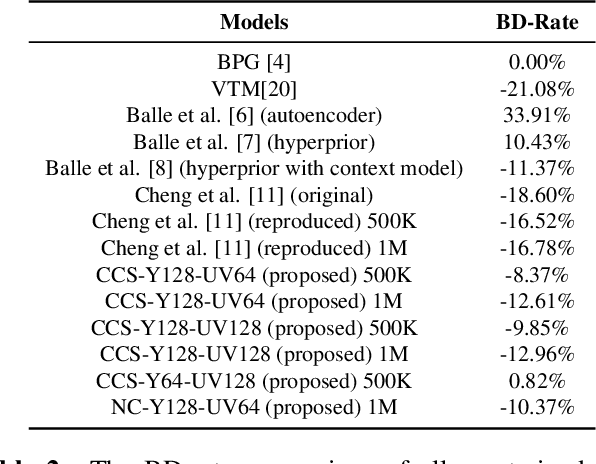
Recently, image compression codecs based on Neural Networks(NN) outperformed the state-of-art classic ones such as BPG, an image format based on HEVC intra. However, the typical NN codec has high complexity, and it has limited options for parallel data processing. In this work, we propose a conditional separation principle that aims to improve parallelization and lower the computational requirements of an NN codec. We present a Conditional Color Separation (CCS) codec which follows this principle. The color components of an image are split into primary and non-primary ones. The processing of each component is done separately, by jointly trained networks. Our approach allows parallel processing of each component, flexibility to select different channel numbers, and an overall complexity reduction. The CCS codec uses over 40% less memory, has 2x faster encoding and 22% faster decoding speed, with only 4% BD-rate loss in RGB PSNR compared to our baseline model over BPG.
A Survey on Few-Shot Class-Incremental Learning
Apr 17, 2023
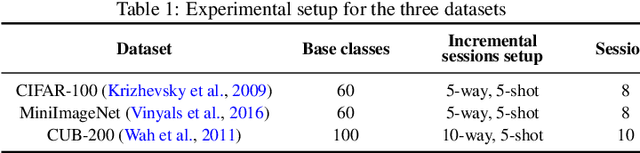
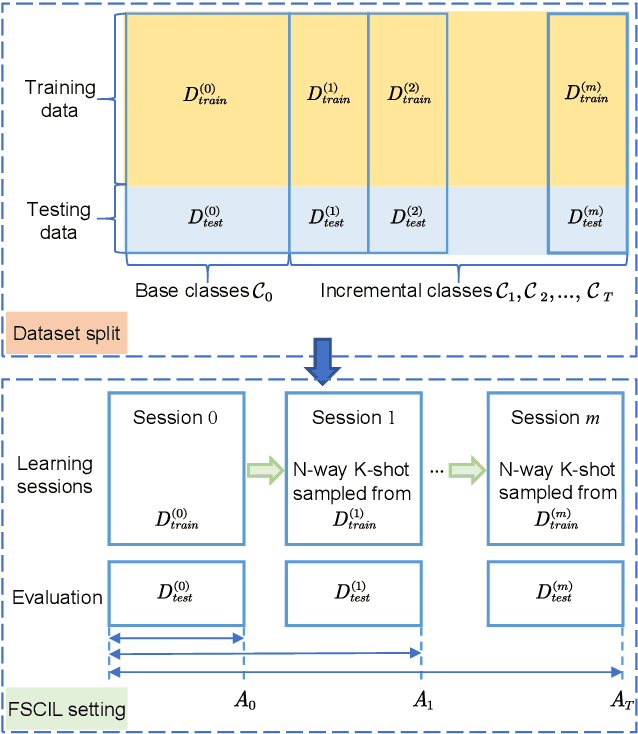
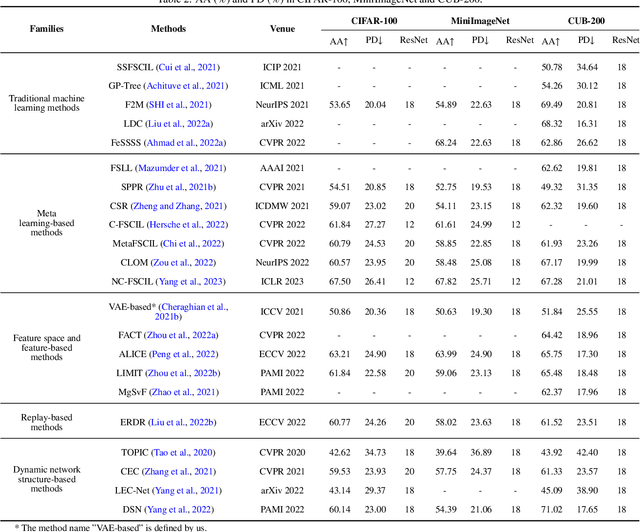
Large deep learning models are impressive, but they struggle when real-time data is not available. Few-shot class-incremental learning (FSCIL) poses a significant challenge for deep neural networks to learn new tasks from just a few labeled samples without forgetting the previously learned ones. This setup easily leads to catastrophic forgetting and overfitting problems, severely affecting model performance. Studying FSCIL helps overcome deep learning model limitations on data volume and acquisition time, while improving practicality and adaptability of machine learning models. This paper provides a comprehensive survey on FSCIL. Unlike previous surveys, we aim to synthesize few-shot learning and incremental learning, focusing on introducing FSCIL from two perspectives, while reviewing over 30 theoretical research studies and more than 20 applied research studies. From the theoretical perspective, we provide a novel categorization approach that divides the field into five subcategories, including traditional machine learning methods, meta-learning based methods, feature and feature space-based methods, replay-based methods, and dynamic network structure-based methods. We also evaluate the performance of recent theoretical research on benchmark datasets of FSCIL. From the application perspective, FSCIL has achieved impressive achievements in various fields of computer vision such as image classification, object detection, and image segmentation, as well as in natural language processing and graph. We summarize the important applications. Finally, we point out potential future research directions, including applications, problem setups, and theory development. Overall, this paper offers a comprehensive analysis of the latest advances in FSCIL from a methodological, performance, and application perspective.
Predicting dynamic, motion-related changes in B0 field in the brain at a 7 T MRI using a subject-specific fine-tuned U-net
Apr 17, 2023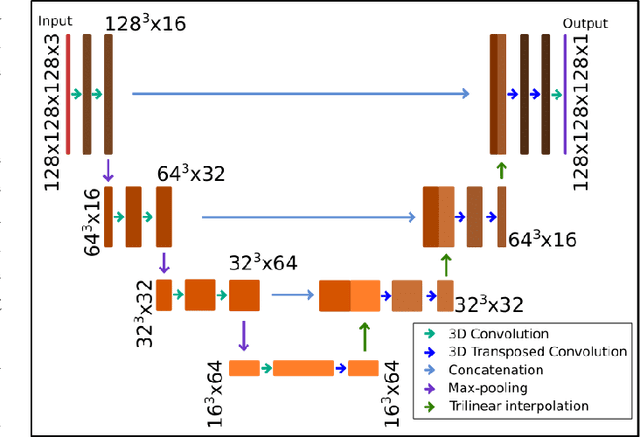
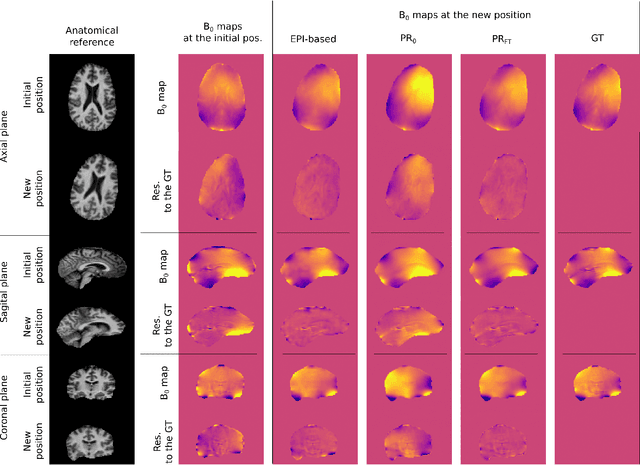
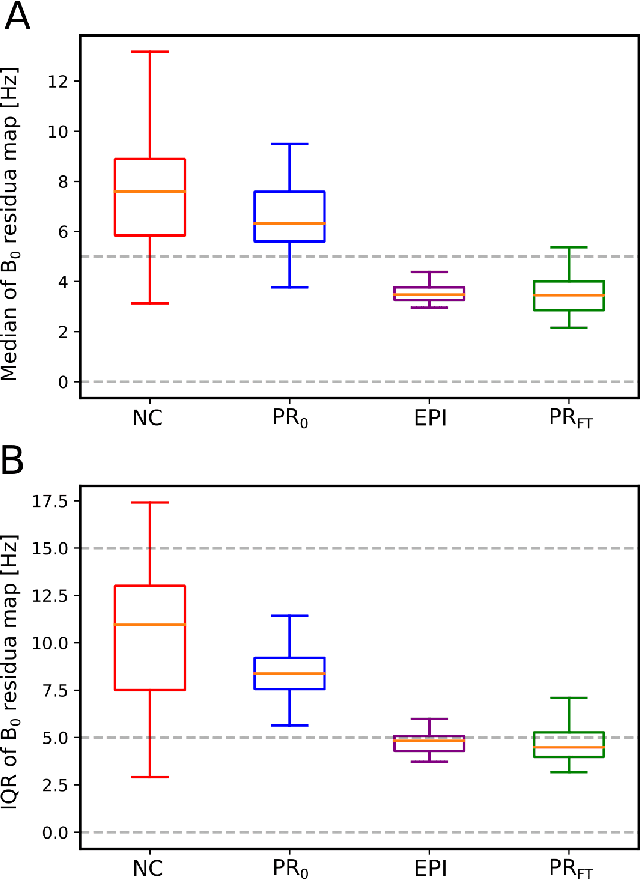
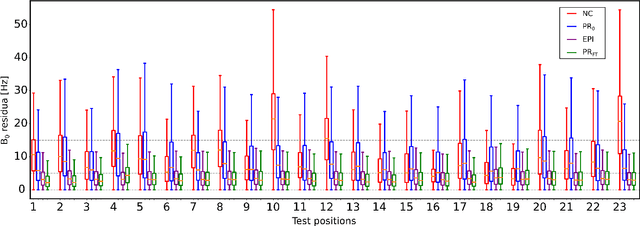
Subject movement during the magnetic resonance examination is inevitable and causes not only image artefacts but also deteriorates the homogeneity of the main magnetic field (B0), which is a prerequisite for high quality data. Thus, characterization of changes to B0, e.g. induced by patient movement, is important for MR applications that are prone to B0 inhomogeneities. We propose a deep learning based method to predict such changes within the brain from the change of the head position to facilitate retrospective or even real-time correction. A 3D U-net was trained on in vivo brain 7T MRI data. The input consisted of B0 maps and anatomical images at an initial position, and anatomical images at a different head position (obtained by applying a rigid-body transformation on the initial anatomical image). The output consisted of B0 maps at the new head positions. We further fine-tuned the network weights to each subject by measuring a limited number of head positions of the given subject, and trained the U-net with these data. Our approach was compared to established dynamic B0 field mapping via interleaved navigators, which suffer from limited spatial resolution and the need for undesirable sequence modifications. Qualitative and quantitative comparison showed similar performance between an interleaved navigator-equivalent method and proposed method. We therefore conclude that it is feasible to predict B0 maps from rigid subject movement and, when combined with external tracking hardware, this information could be used to improve the quality of magnetic resonance acquisitions without the use of navigators.
Open-Vocabulary Point-Cloud Object Detection without 3D Annotation
Apr 03, 2023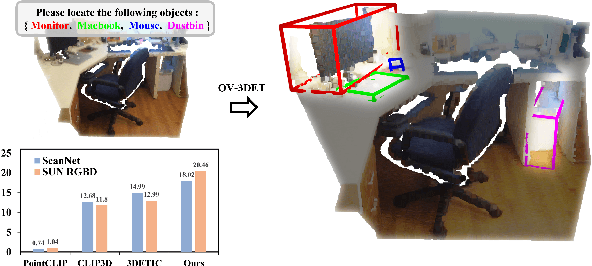
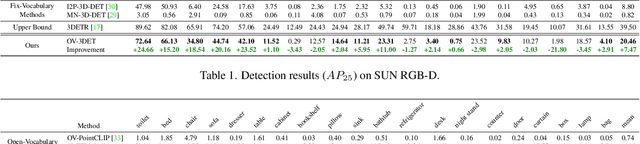
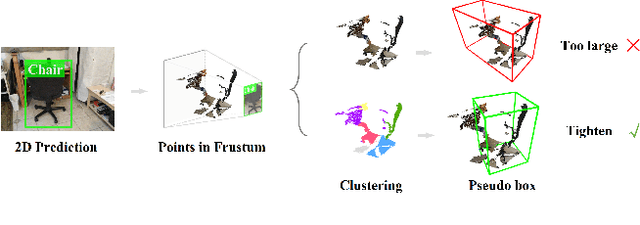

The goal of open-vocabulary detection is to identify novel objects based on arbitrary textual descriptions. In this paper, we address open-vocabulary 3D point-cloud detection by a dividing-and-conquering strategy, which involves: 1) developing a point-cloud detector that can learn a general representation for localizing various objects, and 2) connecting textual and point-cloud representations to enable the detector to classify novel object categories based on text prompting. Specifically, we resort to rich image pre-trained models, by which the point-cloud detector learns localizing objects under the supervision of predicted 2D bounding boxes from 2D pre-trained detectors. Moreover, we propose a novel de-biased triplet cross-modal contrastive learning to connect the modalities of image, point-cloud and text, thereby enabling the point-cloud detector to benefit from vision-language pre-trained models,i.e.,CLIP. The novel use of image and vision-language pre-trained models for point-cloud detectors allows for open-vocabulary 3D object detection without the need for 3D annotations. Experiments demonstrate that the proposed method improves at least 3.03 points and 7.47 points over a wide range of baselines on the ScanNet and SUN RGB-D datasets, respectively. Furthermore, we provide a comprehensive analysis to explain why our approach works.
A Pilot Study of Query-Free Adversarial Attack against Stable Diffusion
Apr 03, 2023



Despite the record-breaking performance in Text-to-Image (T2I) generation by Stable Diffusion, less research attention is paid to its adversarial robustness. In this work, we study the problem of adversarial attack generation for Stable Diffusion and ask if an adversarial text prompt can be obtained even in the absence of end-to-end model queries. We call the resulting problem 'query-free attack generation'. To resolve this problem, we show that the vulnerability of T2I models is rooted in the lack of robustness of text encoders, e.g., the CLIP text encoder used for attacking Stable Diffusion. Based on such insight, we propose both untargeted and targeted query-free attacks, where the former is built on the most influential dimensions in the text embedding space, which we call steerable key dimensions. By leveraging the proposed attacks, we empirically show that only a five-character perturbation to the text prompt is able to cause the significant content shift of synthesized images using Stable Diffusion. Moreover, we show that the proposed target attack can precisely steer the diffusion model to scrub the targeted image content without causing much change in untargeted image content. Our code is available at https://github.com/OPTML-Group/QF-Attack.