 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to "Segment Anything" in Thermal Infrared Images through Knowledge Distillation with a Large Scale Dataset SATIR
Apr 17, 2023
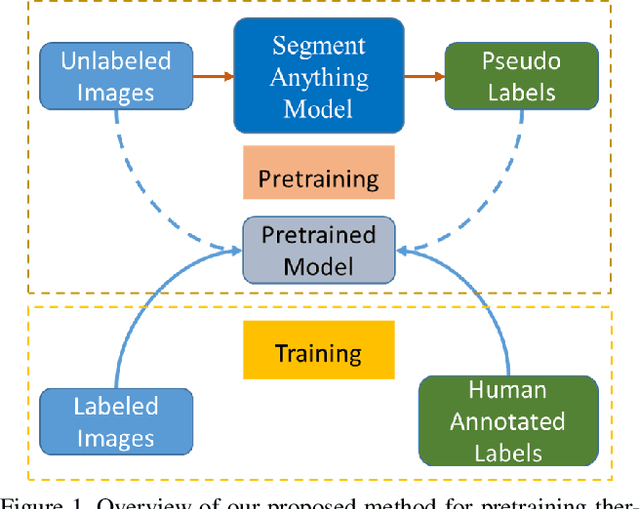

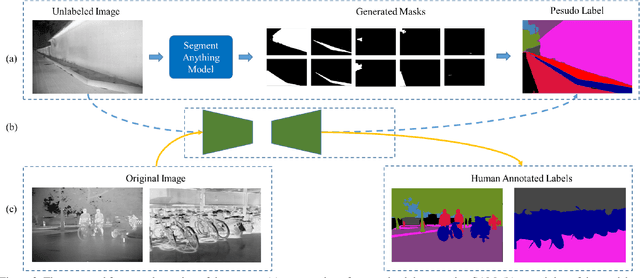
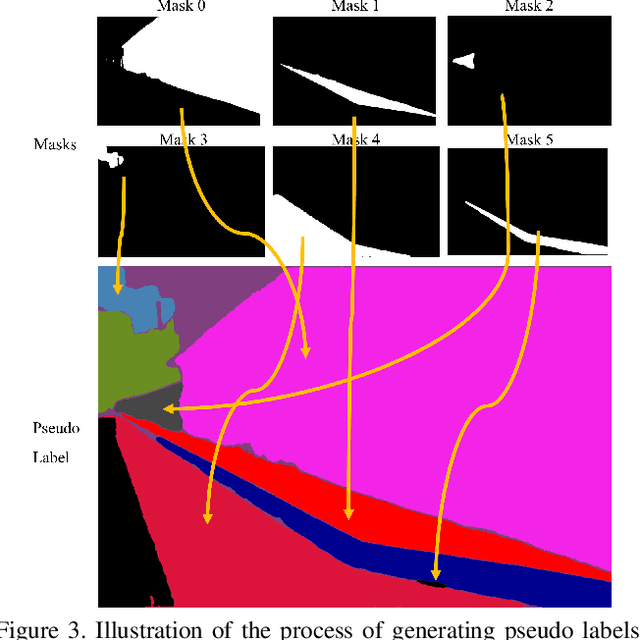
The Segment Anything Model (SAM) is a promptable segmentation model recently introduced by Meta AI that has demonstrated its prowess across various fields beyond just image segmentation. SAM can accurately segment images across diverse fields, and generating various masks. We discovered that this ability of SAM can be leveraged to pretrain models for specific fields. Accordingly, we have proposed a framework that utilizes SAM to generate pseudo labels for pretraining thermal infrared image segmentation tasks. Our proposed framework can effectively improve the accuracy of segmentation results of specific categories beyond the SOTA ImageNet pretrained model. Our framework presents a novel approach to collaborate with models trained with large data like SAM to address problems in special fields. Also, we generated a large scale thermal infrared segmentation dataset used for pretaining, which contains over 100,000 images with pixel-annotation labels. This approach offers an effective solution for working with large models in special fields where label annotation is challenging. Our code is available at https://github.com/chenjzBUAA/SATIR
Synthetic Hard Negative Samples for Contrastive Learning
Apr 17, 2023

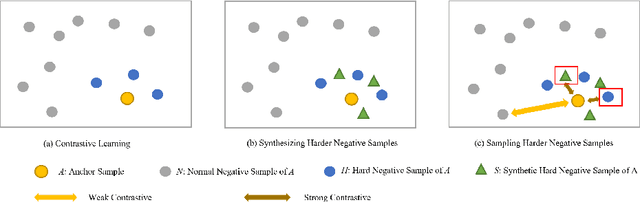
Contrastive learning has emerged as an essential approach for self-supervised learning in visual representation learning. The central objective of contrastive learning is to maximize the similarities between two augmented versions of an image (positive pairs), while minimizing the similarities between different images (negative pairs). Recent studies have demonstrated that harder negative samples, i.e., those that are more difficult to differentiate from the anchor sample, perform a more crucial function in contrastive learning. This paper proposes a novel feature-level method, namely sampling synthetic hard negative samples for contrastive learning (SSCL), to exploit harder negative samples more effectively. Specifically, 1) we generate more and harder negative samples by mixing negative samples, and then sample them by controlling the contrast of anchor sample with the other negative samples; 2) considering the possibility of false negative samples, we further debias the negative samples. Our proposed method improves the classification performance on different image datasets and can be readily integrated into existing methods.
Learning Geometry-aware Representations by Sketching
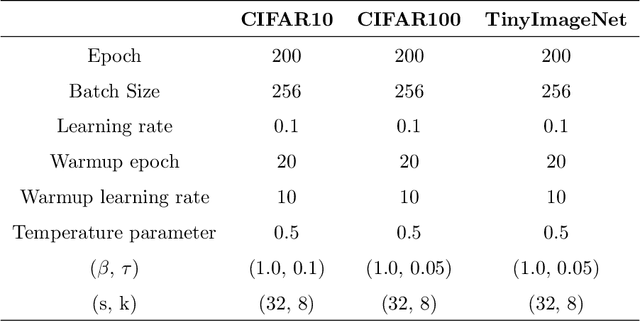
Apr 17, 2023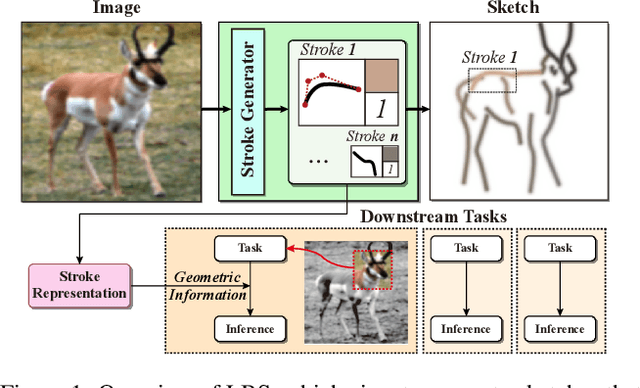
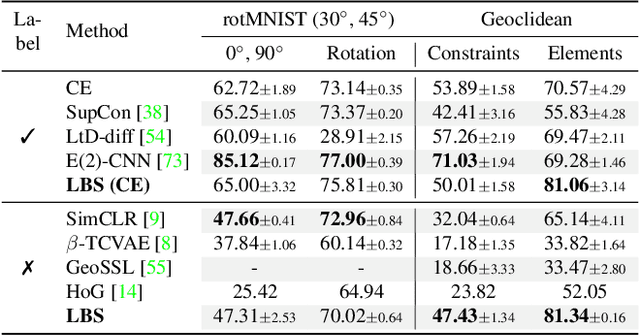
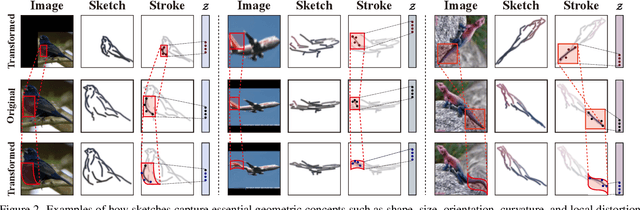
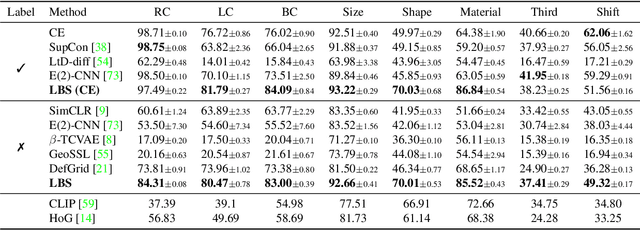
Understanding geometric concepts, such as distance and shape, is essential for understanding the real world and also for many vision tasks. To incorporate such information into a visual representation of a scene, we propose learning to represent the scene by sketching, inspired by human behavior. Our method, coined Learning by Sketching (LBS), learns to convert an image into a set of colored strokes that explicitly incorporate the geometric information of the scene in a single inference step without requiring a sketch dataset. A sketch is then generated from the strokes where CLIP-based perceptual loss maintains a semantic similarity between the sketch and the image. We show theoretically that sketching is equivariant with respect to arbitrary affine transformations and thus provably preserves geometric information. Experimental results show that LBS substantially improves the performance of object attribute classification on the unlabeled CLEVR dataset, domain transfer between CLEVR and STL-10 datasets, and for diverse downstream tasks, confirming that LBS provides rich geometric information.
SSTM: Spatiotemporal Recurrent Transformers for Multi-frame Optical Flow Estimation
Apr 26, 2023

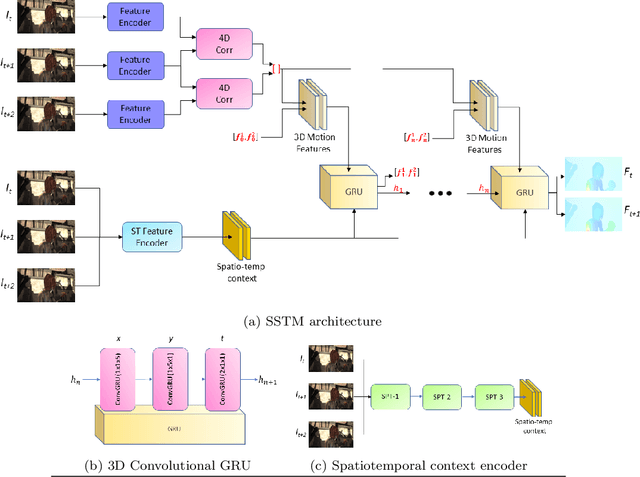
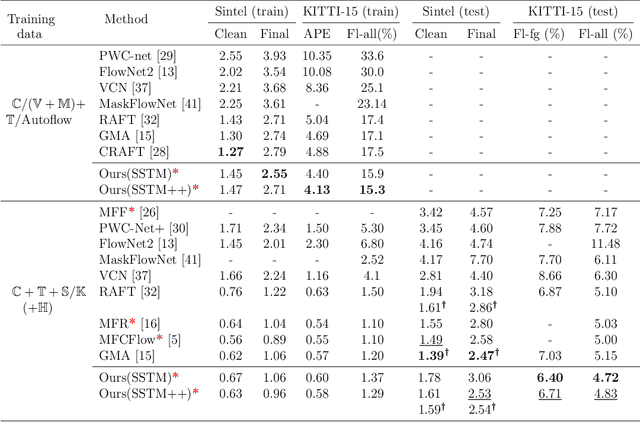
Inaccurate optical flow estimates in and near occluded regions, and out-of-boundary regions are two of the current significant limitations of optical flow estimation algorithms. Recent state-of-the-art optical flow estimation algorithms are two-frame based methods where optical flow is estimated sequentially for each consecutive image pair in a sequence. While this approach gives good flow estimates, it fails to generalize optical flows in occluded regions mainly due to limited local evidence regarding moving elements in a scene. In this work, we propose a learning-based multi-frame optical flow estimation method that estimates two or more consecutive optical flows in parallel from multi-frame image sequences. Our underlying hypothesis is that by understanding temporal scene dynamics from longer sequences with more than two frames, we can characterize pixel-wise dependencies in a larger spatiotemporal domain, generalize complex motion patterns and thereby improve the accuracy of optical flow estimates in occluded regions. We present learning-based spatiotemporal recurrent transformers for multi-frame based optical flow estimation (SSTMs). Our method utilizes 3D Convolutional Gated Recurrent Units (3D-ConvGRUs) and spatiotemporal transformers to learn recurrent space-time motion dynamics and global dependencies in the scene and provide a generalized optical flow estimation. When compared with recent state-of-the-art two-frame and multi-frame methods on real world and synthetic datasets, performance of the SSTMs were significantly higher in occluded and out-of-boundary regions. Among all published state-of-the-art multi-frame methods, SSTM achieved state-of the-art results on the Sintel Final and KITTI2015 benchmark datasets.
Multi-Reference Image Super-Resolution: A Posterior Fusion Approach
Dec 20, 2022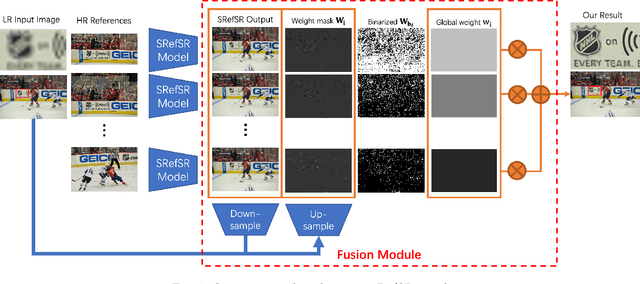

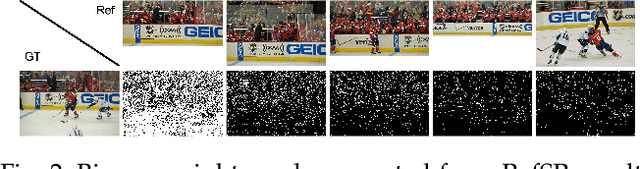
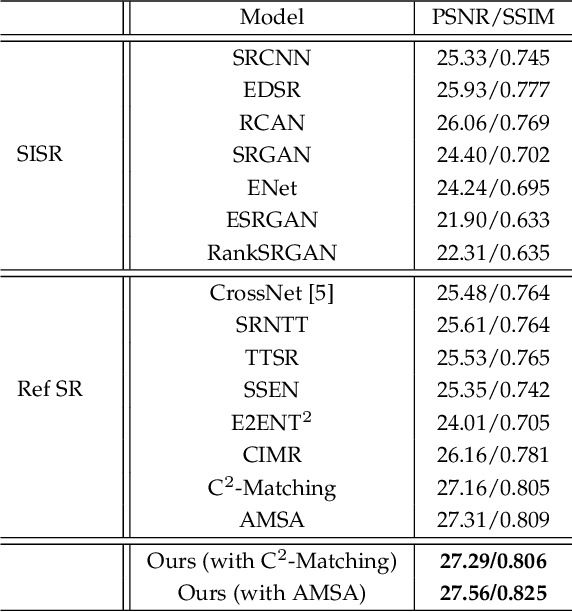
Reference-based Super-resolution (RefSR) approaches have recently been proposed to overcome the ill-posed problem of image super-resolution by providing additional information from a high-resolution image. Multi-reference super-resolution extends this approach by allowing more information to be incorporated. This paper proposes a 2-step-weighting posterior fusion approach to combine the outputs of RefSR models with multiple references. Extensive experiments on the CUFED5 dataset demonstrate that the proposed methods can be applied to various state-of-the-art RefSR models to get a consistent improvement in image quality.
Collection Space Navigator: An Interactive Visualization Interface for Multidimensional Datasets
May 11, 2023
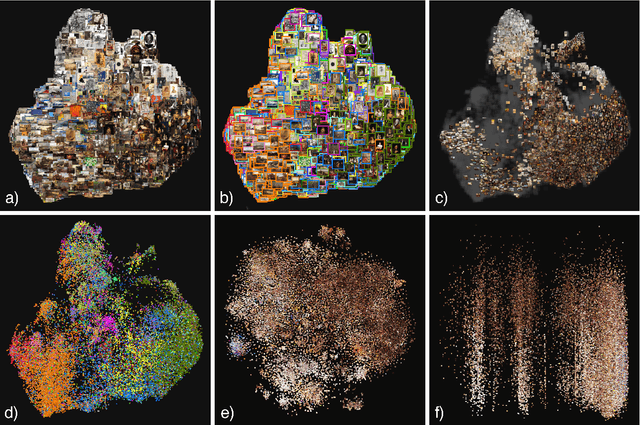
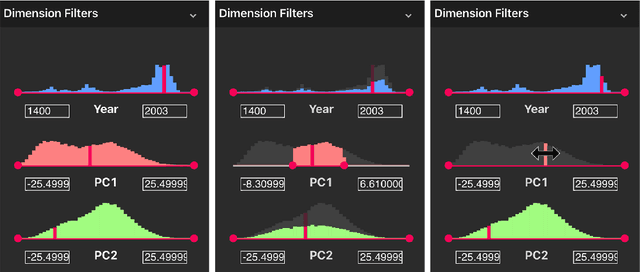
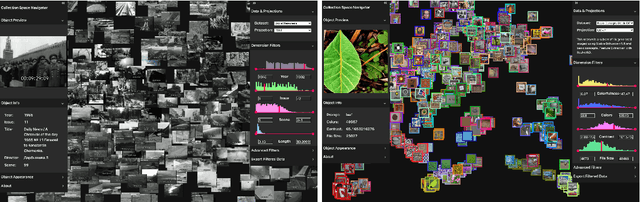
We introduce the Collection Space Navigator (CSN), a browser-based visualization tool to explore, research, and curate large collections of visual digital artifacts that are associated with multidimensional data, such as vector embeddings or tables of metadata. Media objects such as images are often encoded as numerical vectors, for e.g. based on metadata or using machine learning to embed image information. Yet, while such procedures are widespread for a range of applications, it remains a challenge to explore, analyze, and understand the resulting multidimensional spaces in a more comprehensive manner. Dimensionality reduction techniques such as t-SNE or UMAP often serve to project high-dimensional data into low dimensional visualizations, yet require interpretation themselves as the remaining dimensions are typically abstract. Here, the Collection Space Navigator provides a customizable interface that combines two-dimensional projections with a set of configurable multidimensional filters. As a result, the user is able to view and investigate collections, by zooming and scaling, by transforming between projections, by filtering dimensions via range sliders, and advanced text filters. Insights that are gained during the interaction can be fed back into the original data via ad hoc exports of filtered metadata and projections. This paper comes with a functional showcase demo using a large digitized collection of classical Western art. The Collection Space Navigator is open source. Users can reconfigure the interface to fit their own data and research needs, including projections and filter controls. The CSN is ready to serve a broad community.
GlueStick: Robust Image Matching by Sticking Points and Lines Together
Apr 04, 2023
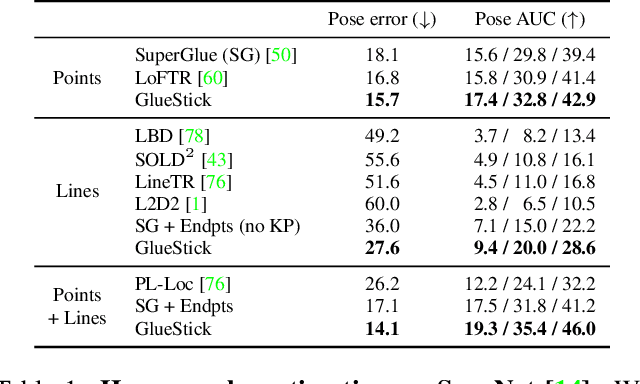
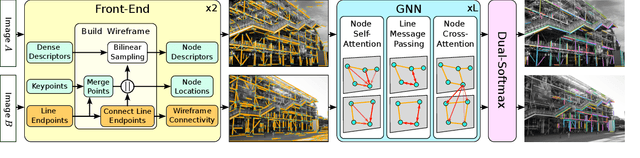
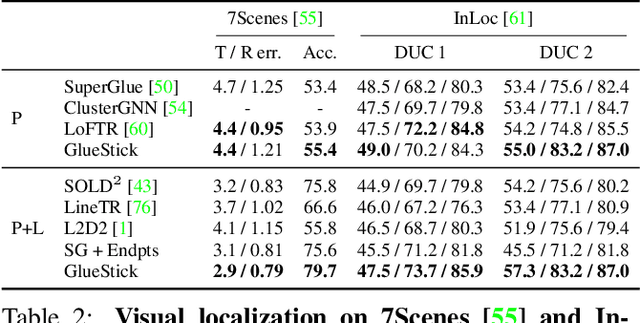
Line segments are powerful features complementary to points. They offer structural cues, robust to drastic viewpoint and illumination changes, and can be present even in texture-less areas. However, describing and matching them is more challenging compared to points due to partial occlusions, lack of texture, or repetitiveness. This paper introduces a new matching paradigm, where points, lines, and their descriptors are unified into a single wireframe structure. We propose GlueStick, a deep matching Graph Neural Network (GNN) that takes two wireframes from different images and leverages the connectivity information between nodes to better glue them together. In addition to the increased efficiency brought by the joint matching, we also demonstrate a large boost of performance when leveraging the complementary nature of these two features in a single architecture. We show that our matching strategy outperforms the state-of-the-art approaches independently matching line segments and points for a wide variety of datasets and tasks. The code is available at https://github.com/cvg/GlueStick.
CSwin2SR: Circular Swin2SR for Compressed Image Super-Resolution
Jan 20, 2023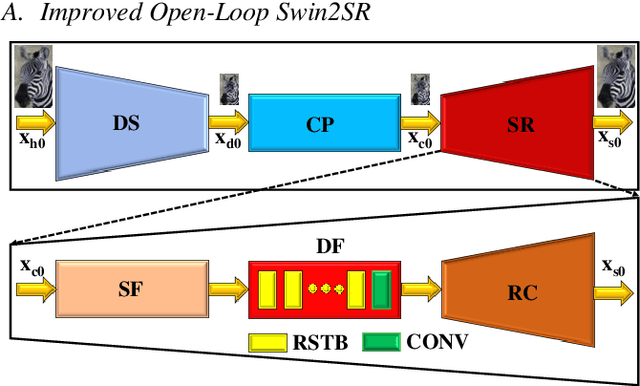
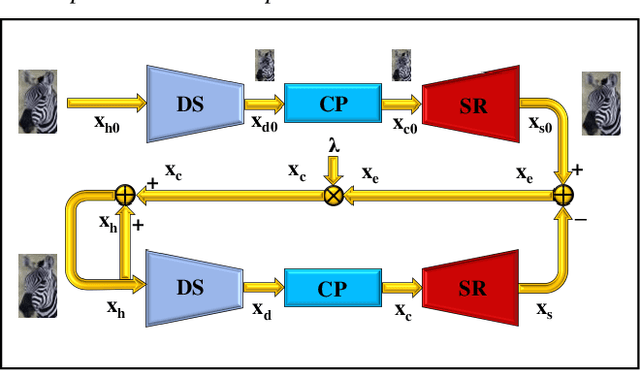


Closed-loop negative feedback mechanism is extensively utilized in automatic control systems and brings about extraordinary dynamic and static performance. In order to further improve the reconstruction capability of current methods of compressed image super-resolution, a circular Swin2SR (CSwin2SR) approach is proposed. The CSwin2SR contains a serial Swin2SR for initial super-resolution reestablishment and circular Swin2SR for enhanced super-resolution reestablishment. Simulated experimental results show that the proposed CSwin2SR dramatically outperforms the classical Swin2SR in the capacity of super-resolution recovery. On DIV2K test and valid datasets, the average increment of PSNR is greater than 1dB and the related average increment of SSIM is greater than 0.006.
Identifying Stochasticity in Time-Series with Autoencoder-Based Content-aware 2D Representation: Application to Black Hole Data
Apr 23, 2023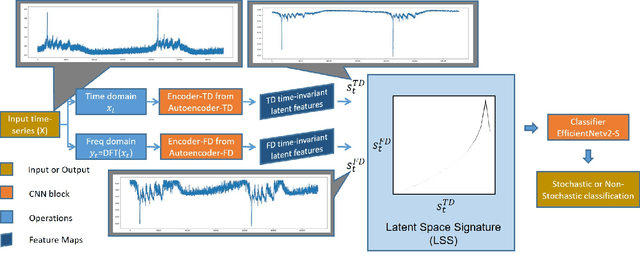
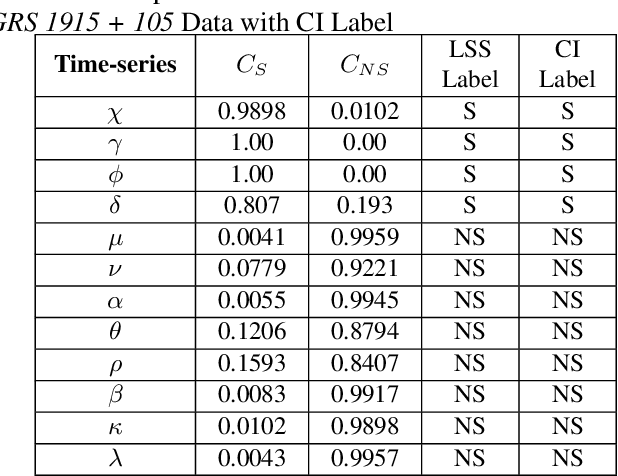
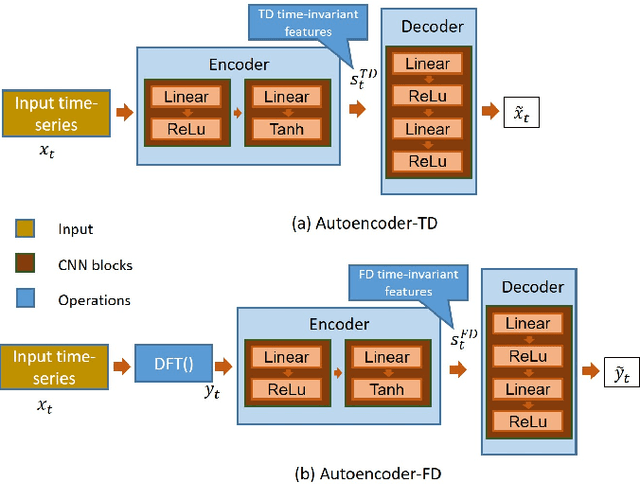
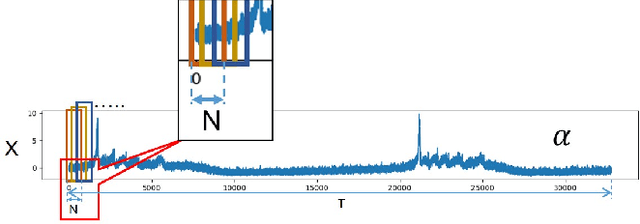
In this work, we report an autoencoder-based 2D representation to classify a time-series as stochastic or non-stochastic, to understand the underlying physical process. Content-aware conversion of 1D time-series to 2D representation, that simultaneously utilizes time- and frequency-domain characteristics, is proposed. An autoencoder is trained with a loss function to learn latent space (using both time- and frequency domains) representation, that is designed to be, time-invariant. Every element of the time-series is represented as a tuple with two components, one each, from latent space representation in time- and frequency-domains, forming a binary image. In this binary image, those tuples that represent the points in the time-series, together form the ``Latent Space Signature" (LSS) of the input time-series. The obtained binary LSS images are fed to a classification network. The EfficientNetv2-S classifier is trained using 421 synthetic time-series, with fair representation from both categories. The proposed methodology is evaluated on publicly available astronomical data which are 12 distinct temporal classes of time-series pertaining to the black hole GRS 1915 + 105, obtained from RXTE satellite. Results obtained using the proposed methodology are compared with existing techniques. Concurrence in labels obtained across the classes, illustrates the efficacy of the proposed 2D representation using the latent space co-ordinates. The proposed methodology also outputs the confidence in the classification label.
Twilight SLAM: A Comparative Study of Low-Light Visual SLAM Pipelines
Apr 27, 2023
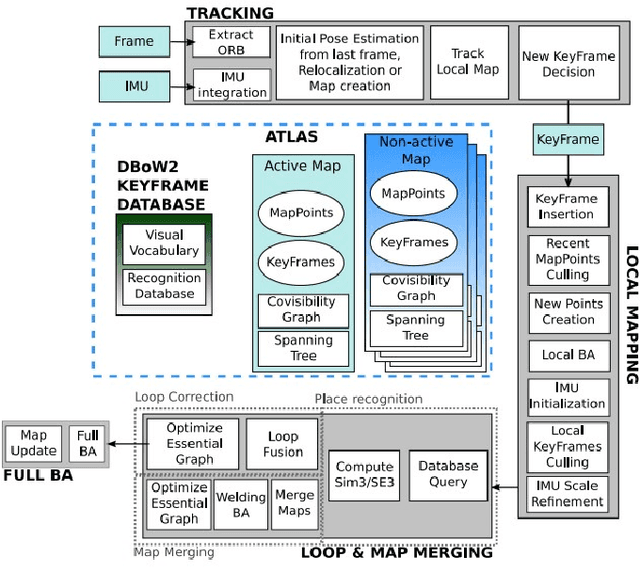
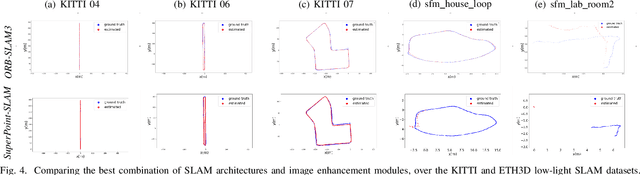
This paper presents a comparative study of low-light visual SLAM pipelines, specifically focusing on determining an efficient combination of the state-of-the-art low-light image enhancement algorithms with standard and contemporary Simultaneous Localization and Mapping (SLAM) frameworks by evaluating their performance in challenging low-light conditions. In this study, we investigate the performance of several different low-light SLAM pipelines for dark and/or poorly-lit datasets as opposed to just partially dim-lit datasets like other works in the literature. Our study takes an experimental approach to qualitatively and quantitatively compare the chosen combinations of modules to enhance the feature-based visual SLAM.