 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Mode Balancing of Generative Models via Diversity Weights
Apr 24, 2023
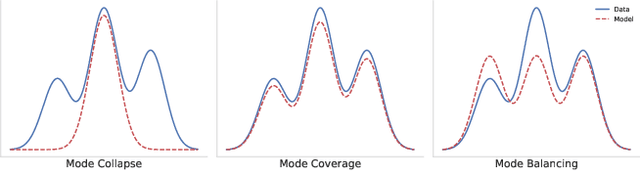
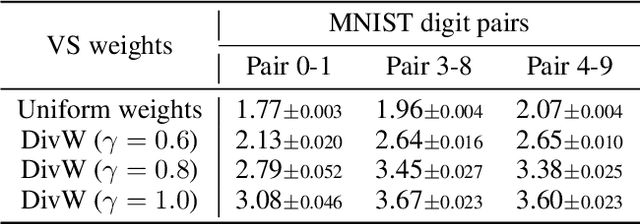


Large data-driven image models are extensively used to support creative and artistic work. Under the currently predominant distribution-fitting paradigm, a dataset is treated as ground truth to be approximated as closely as possible. Yet, many creative applications demand a diverse range of output, and creators often strive to actively diverge from a given data distribution. We argue that an adjustment of modelling objectives, from pure mode coverage towards mode balancing, is necessary to accommodate the goal of higher output diversity. We present diversity weights, a training scheme that increases a model's output diversity by balancing the modes in the training dataset. First experiments in a controlled setting demonstrate the potential of our method. We conclude by contextualising our contribution to diversity within the wider debate on bias, fairness and representation in generative machine learning.
Parameter Efficient Local Implicit Image Function Network for Face Segmentation
Mar 27, 2023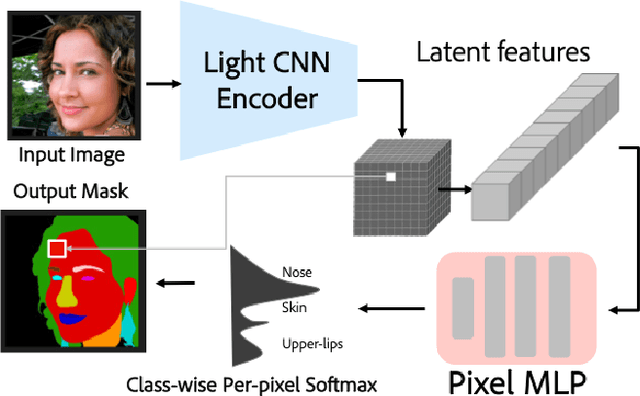
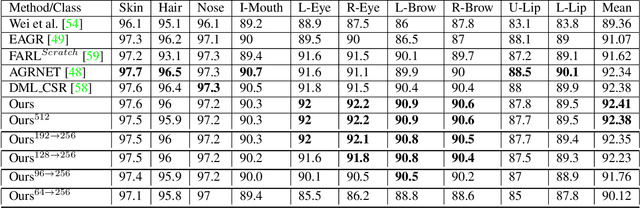

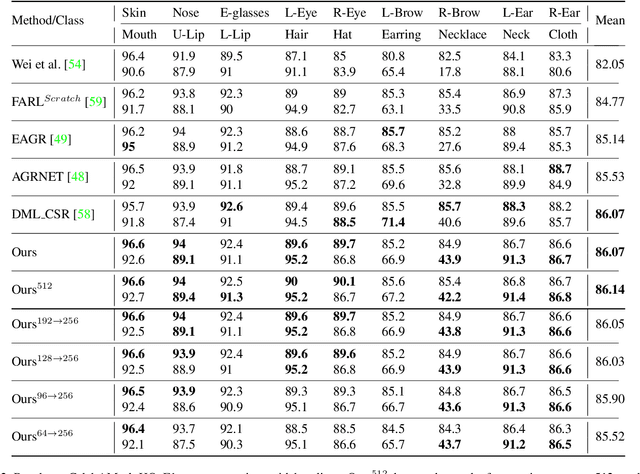
Face parsing is defined as the per-pixel labeling of images containing human faces. The labels are defined to identify key facial regions like eyes, lips, nose, hair, etc. In this work, we make use of the structural consistency of the human face to propose a lightweight face-parsing method using a Local Implicit Function network, FP-LIIF. We propose a simple architecture having a convolutional encoder and a pixel MLP decoder that uses 1/26th number of parameters compared to the state-of-the-art models and yet matches or outperforms state-of-the-art models on multiple datasets, like CelebAMask-HQ and LaPa. We do not use any pretraining, and compared to other works, our network can also generate segmentation at different resolutions without any changes in the input resolution. This work enables the use of facial segmentation on low-compute or low-bandwidth devices because of its higher FPS and smaller model size.
The Infinite Index: Information Retrieval on Generative Text-To-Image Models
Dec 14, 2022
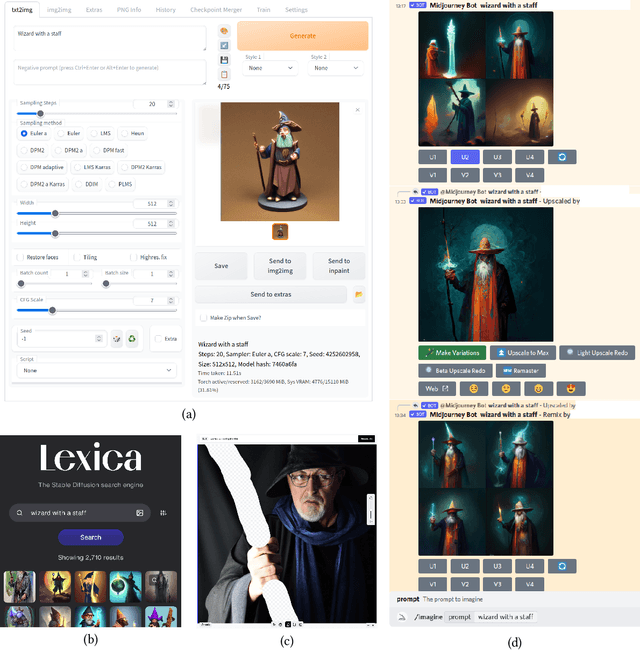
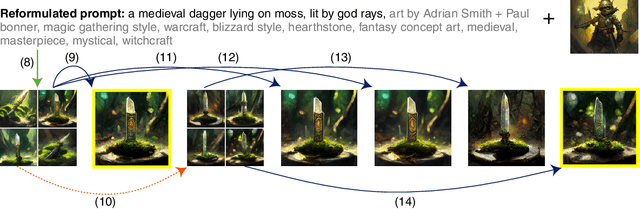
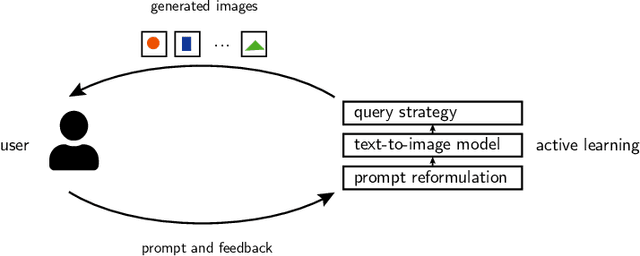
The text-to-image model Stable Diffusion has recently become very popular. Only weeks after its open source release, millions are experimenting with image generation. This is due to its ease of use, since all it takes is a brief description of the desired image to "prompt" the generative model. Rarely do the images generated for a new prompt immediately meet the user's expectations. Usually, an iterative refinement of the prompt ("prompt engineering") is necessary for satisfying images. As a new perspective, we recast image prompt engineering as interactive image retrieval - on an "infinite index". Thereby, a prompt corresponds to a query and prompt engineering to query refinement. Selected image-prompt pairs allow direct relevance feedback, as the model can modify an image for the refined prompt. This is a form of one-sided interactive retrieval, where the initiative is on the user side, whereas the server side remains stateless. In light of an extensive literature review, we develop these parallels in detail and apply the findings to a case study of a creative search task on such a model. We note that the uncertainty in searching an infinite index is virtually never-ending. We also discuss future research opportunities related to retrieval models specialized for generative models and interactive generative image retrieval. The application of IR technology, such as query reformulation and relevance feedback, will contribute to improved workflows when using generative models, while the notion of an infinite index raises new challenges in IR research.
Neural Preset for Color Style Transfer
Mar 24, 2023
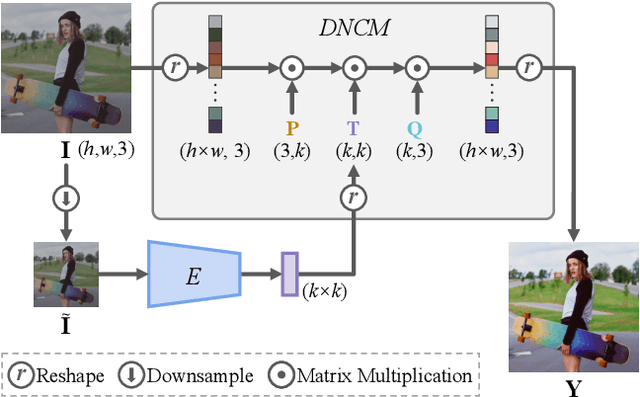
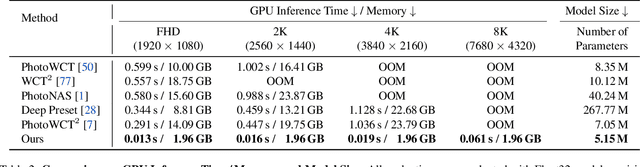
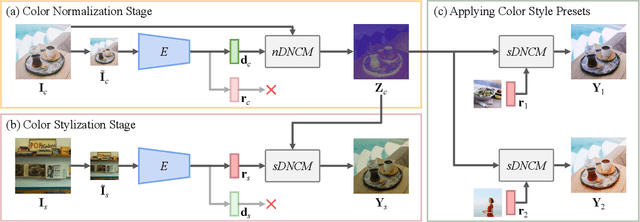
In this paper, we present a Neural Preset technique to address the limitations of existing color style transfer methods, including visual artifacts, vast memory requirement, and slow style switching speed. Our method is based on two core designs. First, we propose Deterministic Neural Color Mapping (DNCM) to consistently operate on each pixel via an image-adaptive color mapping matrix, avoiding artifacts and supporting high-resolution inputs with a small memory footprint. Second, we develop a two-stage pipeline by dividing the task into color normalization and stylization, which allows efficient style switching by extracting color styles as presets and reusing them on normalized input images. Due to the unavailability of pairwise datasets, we describe how to train Neural Preset via a self-supervised strategy. Various advantages of Neural Preset over existing methods are demonstrated through comprehensive evaluations. Notably, Neural Preset enables stable 4K color style transfer in real-time without artifacts. Besides, we show that our trained model can naturally support multiple applications without fine-tuning, including low-light image enhancement, underwater image correction, image dehazing, and image harmonization. Project page with demos: https://zhkkke.github.io/NeuralPreset .
LaCViT: A Label-aware Contrastive Training Framework for Vision Transformers
Mar 31, 2023

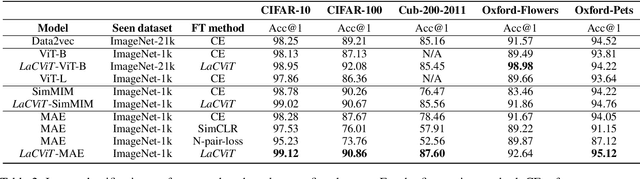
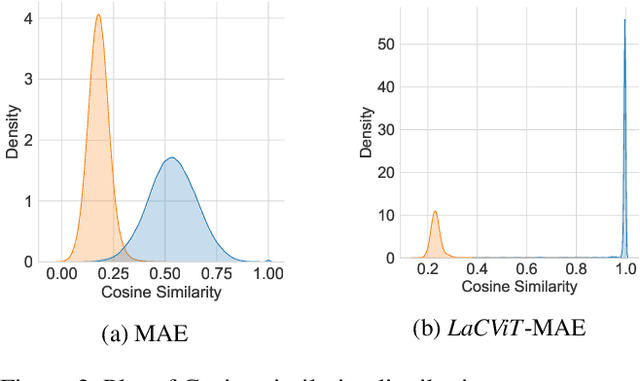
Vision Transformers have been incredibly effective when tackling computer vision tasks due to their ability to model long feature dependencies. By using large-scale training data and various self-supervised signals (e.g., masked random patches), vision transformers provide state-of-the-art performance on several benchmarking datasets, such as ImageNet-1k and CIFAR-10. However, these vision transformers pretrained over general large-scale image corpora could only produce an anisotropic representation space, limiting their generalizability and transferability to the target downstream tasks. In this paper, we propose a simple and effective Label-aware Contrastive Training framework LaCViT, which improves the isotropy of the pretrained representation space for vision transformers, thereby enabling more effective transfer learning amongst a wide range of image classification tasks. Through experimentation over five standard image classification datasets, we demonstrate that LaCViT-trained models outperform the original pretrained baselines by around 9% absolute Accuracy@1, and consistent improvements can be observed when applying LaCViT to our three evaluated vision transformers.
Associating Spatially-Consistent Grouping with Text-supervised Semantic Segmentation
Apr 03, 2023
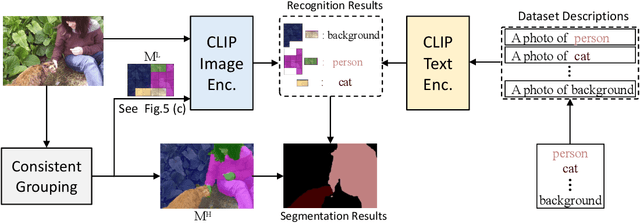
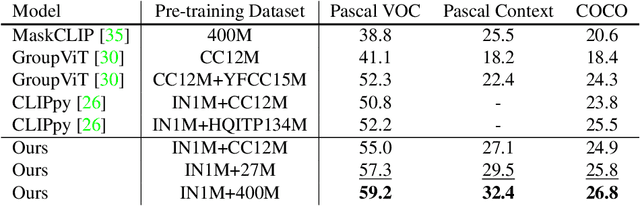
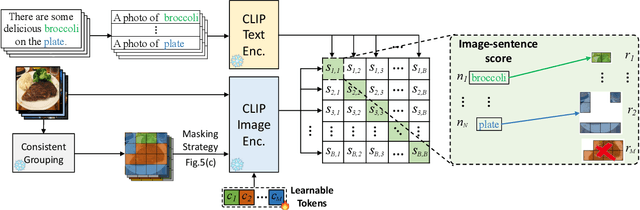
In this work, we investigate performing semantic segmentation solely through the training on image-sentence pairs. Due to the lack of dense annotations, existing text-supervised methods can only learn to group an image into semantic regions via pixel-insensitive feedback. As a result, their grouped results are coarse and often contain small spurious regions, limiting the upper-bound performance of segmentation. On the other hand, we observe that grouped results from self-supervised models are more semantically consistent and break the bottleneck of existing methods. Motivated by this, we introduce associate self-supervised spatially-consistent grouping with text-supervised semantic segmentation. Considering the part-like grouped results, we further adapt a text-supervised model from image-level to region-level recognition with two core designs. First, we encourage fine-grained alignment with a one-way noun-to-region contrastive loss, which reduces the mismatched noun-region pairs. Second, we adopt a contextually aware masking strategy to enable simultaneous recognition of all grouped regions. Coupled with spatially-consistent grouping and region-adapted recognition, our method achieves 59.2% mIoU and 32.4% mIoU on Pascal VOC and Pascal Context benchmarks, significantly surpassing the state-of-the-art methods.
Domain shifts in dermoscopic skin cancer datasets: Evaluation of essential limitations for clinical translation
Apr 18, 2023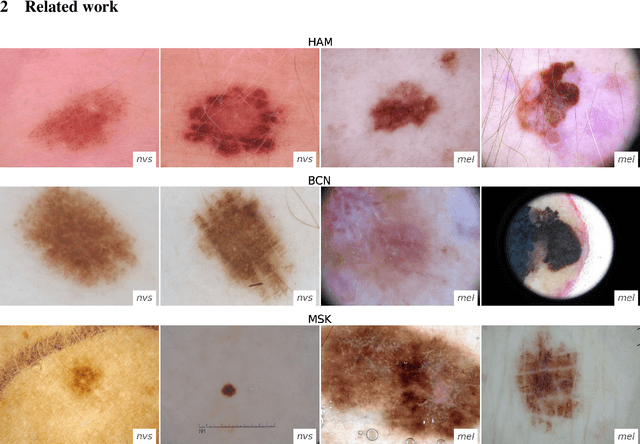
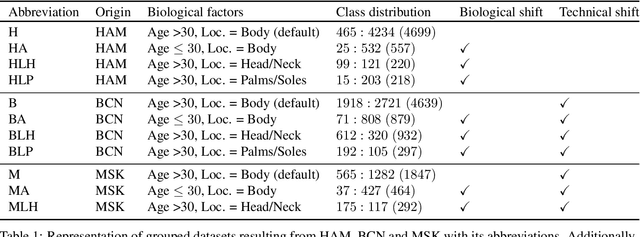
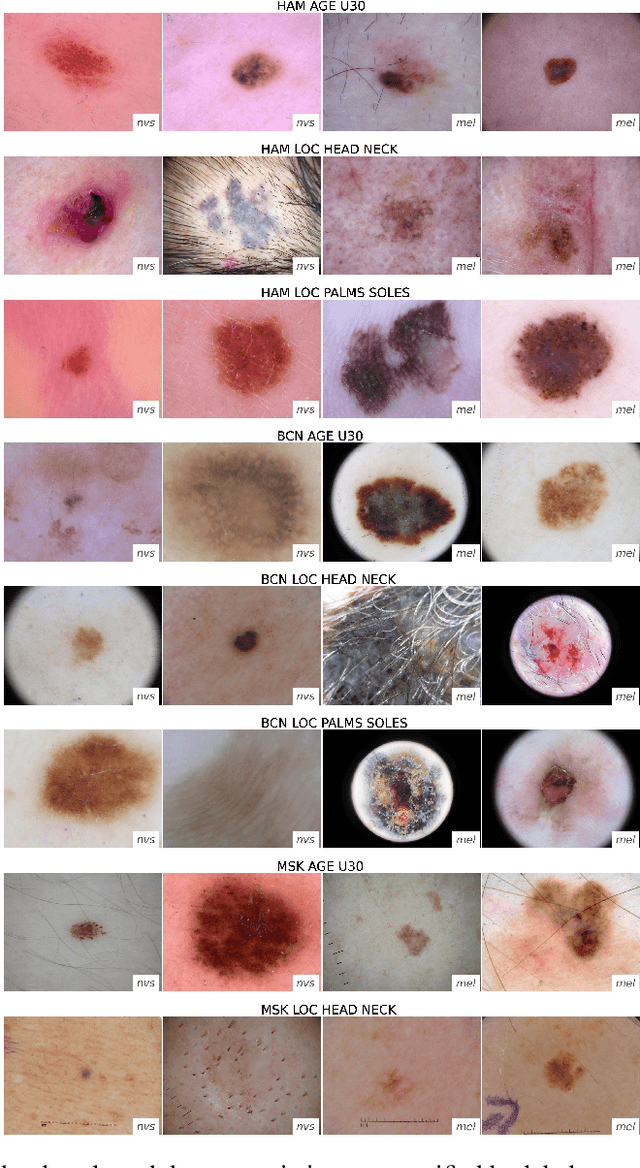
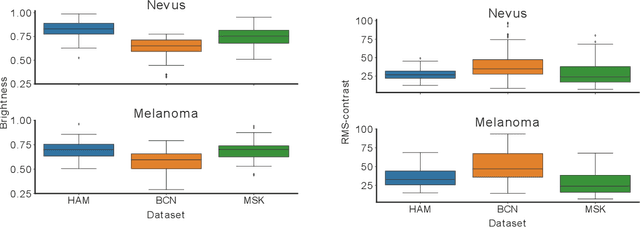
The limited ability of Convolutional Neural Networks to generalize to images from previously unseen domains is a major limitation, in particular, for safety-critical clinical tasks such as dermoscopic skin cancer classification. In order to translate CNN-based applications into the clinic, it is essential that they are able to adapt to domain shifts. Such new conditions can arise through the use of different image acquisition systems or varying lighting conditions. In dermoscopy, shifts can also occur as a change in patient age or occurence of rare lesion localizations (e.g. palms). These are not prominently represented in most training datasets and can therefore lead to a decrease in performance. In order to verify the generalizability of classification models in real world clinical settings it is crucial to have access to data which mimics such domain shifts. To our knowledge no dermoscopic image dataset exists where such domain shifts are properly described and quantified. We therefore grouped publicly available images from ISIC archive based on their metadata (e.g. acquisition location, lesion localization, patient age) to generate meaningful domains. To verify that these domains are in fact distinct, we used multiple quantification measures to estimate the presence and intensity of domain shifts. Additionally, we analyzed the performance on these domains with and without an unsupervised domain adaptation technique. We observed that in most of our grouped domains, domain shifts in fact exist. Based on our results, we believe these datasets to be helpful for testing the generalization capabilities of dermoscopic skin cancer classifiers.
Geometric-aware Pretraining for Vision-centric 3D Object Detection
Apr 07, 2023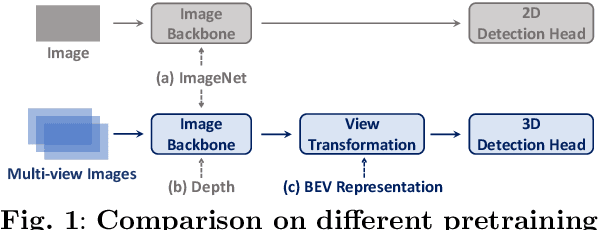
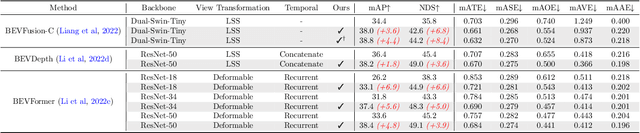
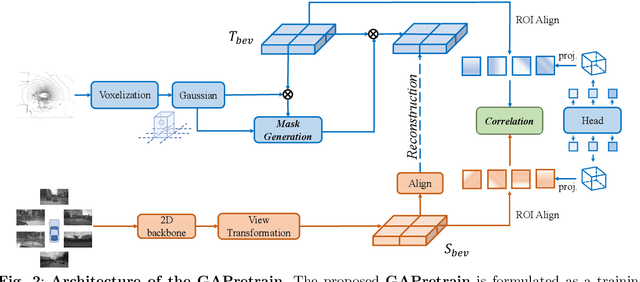
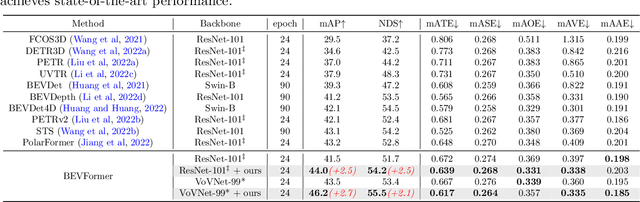
Multi-camera 3D object detection for autonomous driving is a challenging problem that has garnered notable attention from both academia and industry. An obstacle encountered in vision-based techniques involves the precise extraction of geometry-conscious features from RGB images. Recent approaches have utilized geometric-aware image backbones pretrained on depth-relevant tasks to acquire spatial information. However, these approaches overlook the critical aspect of view transformation, resulting in inadequate performance due to the misalignment of spatial knowledge between the image backbone and view transformation. To address this issue, we propose a novel geometric-aware pretraining framework called GAPretrain. Our approach incorporates spatial and structural cues to camera networks by employing the geometric-rich modality as guidance during the pretraining phase. The transference of modal-specific attributes across different modalities is non-trivial, but we bridge this gap by using a unified bird's-eye-view (BEV) representation and structural hints derived from LiDAR point clouds to facilitate the pretraining process. GAPretrain serves as a plug-and-play solution that can be flexibly applied to multiple state-of-the-art detectors. Our experiments demonstrate the effectiveness and generalization ability of the proposed method. We achieve 46.2 mAP and 55.5 NDS on the nuScenes val set using the BEVFormer method, with a gain of 2.7 and 2.1 points, respectively. We also conduct experiments on various image backbones and view transformations to validate the efficacy of our approach. Code will be released at https://github.com/OpenDriveLab/BEVPerception-Survey-Recipe.
RobustSwap: A Simple yet Robust Face Swapping Model against Attribute Leakage
Mar 28, 2023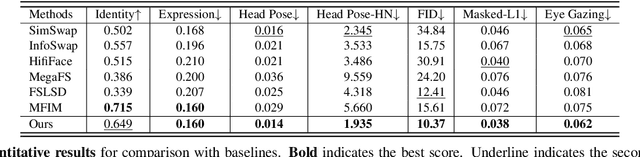

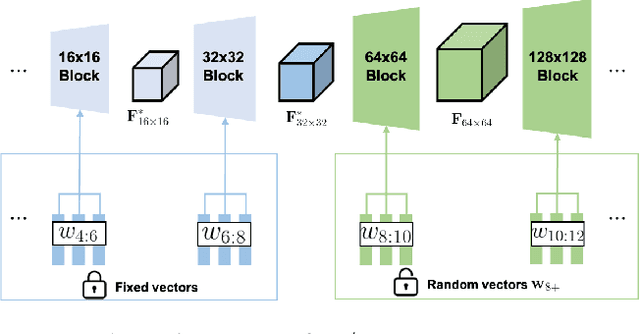
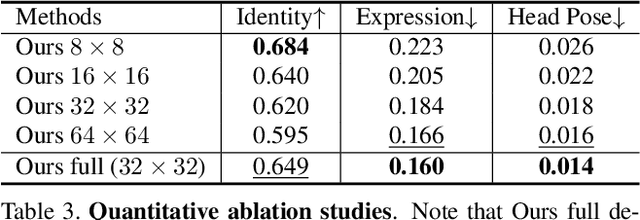
Face swapping aims at injecting a source image's identity (i.e., facial features) into a target image, while strictly preserving the target's attributes, which are irrelevant to identity. However, we observed that previous approaches still suffer from source attribute leakage, where the source image's attributes interfere with the target image's. In this paper, we analyze the latent space of StyleGAN and find the adequate combination of the latents geared for face swapping task. Based on the findings, we develop a simple yet robust face swapping model, RobustSwap, which is resistant to the potential source attribute leakage. Moreover, we exploit the coordination of 3DMM's implicit and explicit information as a guidance to incorporate the structure of the source image and the precise pose of the target image. Despite our method solely utilizing an image dataset without identity labels for training, our model has the capability to generate high-fidelity and temporally consistent videos. Through extensive qualitative and quantitative evaluations, we demonstrate that our method shows significant improvements compared with the previous face swapping models in synthesizing both images and videos. Project page is available at https://robustswap.github.io/
ALIKED: A Lighter Keypoint and Descriptor Extraction Network via Deformable Transformation
Apr 07, 2023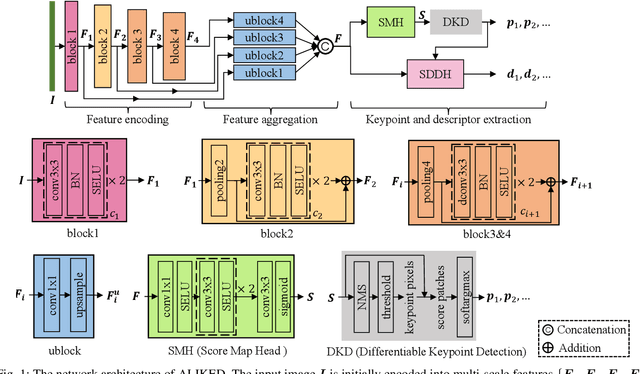
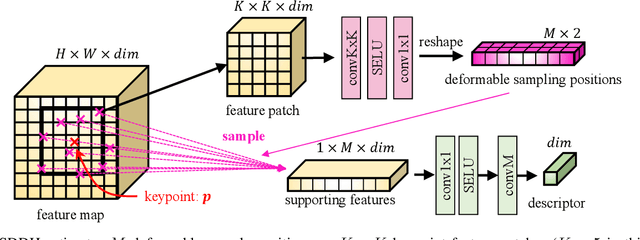
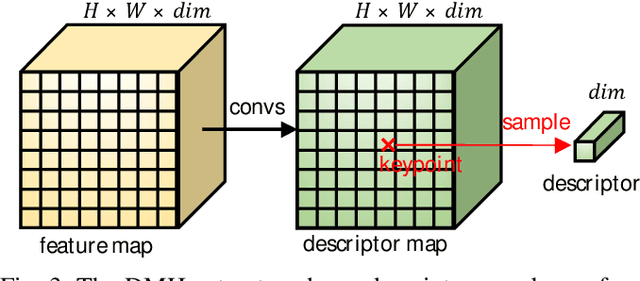

Image keypoints and descriptors play a crucial role in many visual measurement tasks. In recent years, deep neural networks have been widely used to improve the performance of keypoint and descriptor extraction. However, the conventional convolution operations do not provide the geometric invariance required for the descriptor. To address this issue, we propose the Sparse Deformable Descriptor Head (SDDH), which learns the deformable positions of supporting features for each keypoint and constructs deformable descriptors. Furthermore, SDDH extracts descriptors at sparse keypoints instead of a dense descriptor map, which enables efficient extraction of descriptors with strong expressiveness. In addition, we relax the neural reprojection error (NRE) loss from dense to sparse to train the extracted sparse descriptors. Experimental results show that the proposed network is both efficient and powerful in various visual measurement tasks, including image matching, 3D reconstruction, and visual relocalization.