 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pallet Detection from Synthetic Data Using Game Engines
Apr 07, 2023
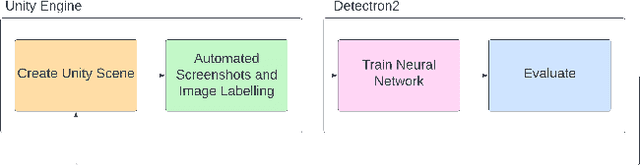
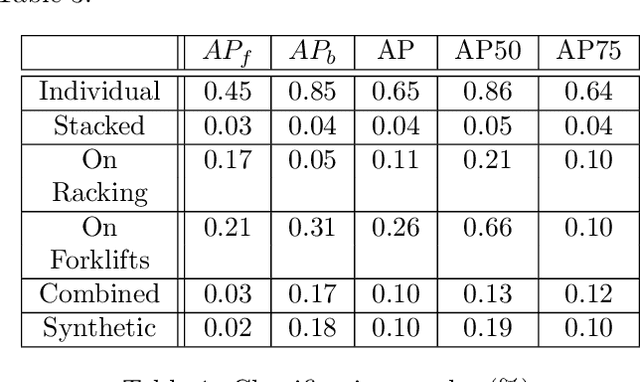

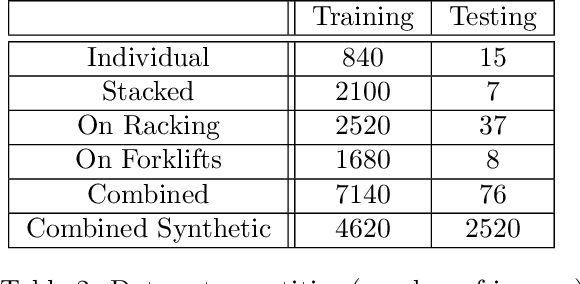
This research sets out to assess the viability of using game engines to generate synthetic training data for machine learning in the context of pallet segmentation. Using synthetic data has been proven in prior research to be a viable means of training neural networks and saves hours of manual labour due to the reduced need for manual image annotation. Machine vision for pallet detection can benefit from synthetic data as the industry increases the development of autonomous warehousing technologies. As per our methodology, we developed a tool capable of automatically generating large amounts of annotated training data from 3D models at pixel-perfect accuracy and a much faster rate than manual approaches. Regarding image segmentation, a Mask R-CNN pipeline was used, which achieved an AP50 of 86% for individual pallets.
* 9 Pages, 10 Figures
Neuromorphic Sensing for Yawn Detection in Driver Drowsiness
May 04, 2023Driver monitoring systems (DMS) are a key component of vehicular safety and essential for the transition from semiautonomous to fully autonomous driving. A key task for DMS is to ascertain the cognitive state of a driver and to determine their level of tiredness. Neuromorphic vision systems, based on event camera technology, provide advanced sensing of facial characteristics, in particular the behavior of a driver's eyes. This research explores the potential to extend neuromorphic sensing techniques to analyze the entire facial region, detecting yawning behaviors that give a complimentary indicator of tiredness. A neuromorphic dataset is constructed from 952 video clips (481 yawns, 471 not-yawns) captured with an RGB color camera, with 37 subjects. A total of 95200 neuromorphic image frames are generated from this video data using a video-to-event converter. From these data 21 subjects were selected to provide a training dataset, 8 subjects were used for validation data, and the remaining 8 subjects were reserved for an "unseen" test dataset. An additional 12300 frames were generated from event simulations of a public dataset to test against other methods. A CNN with self-attention and a recurrent head was designed, trained, and tested with these data. Respective precision and recall scores of 95.9 percent and 94.7 percent were achieved on our test set, and 89.9 percent and 91 percent on the simulated public test set, demonstrating the feasibility to add yawn detection as a sensing component of a neuromorphic DMS.
Object Motion Sensitivity: A Bio-inspired Solution to the Ego-motion Problem for Event-based Cameras
Mar 27, 2023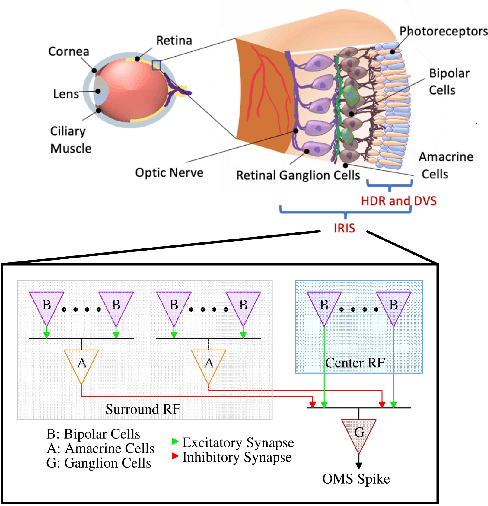
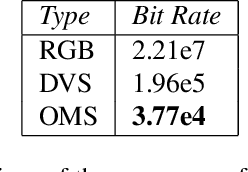
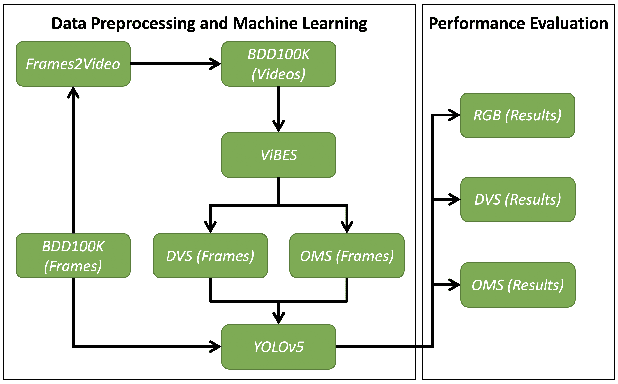
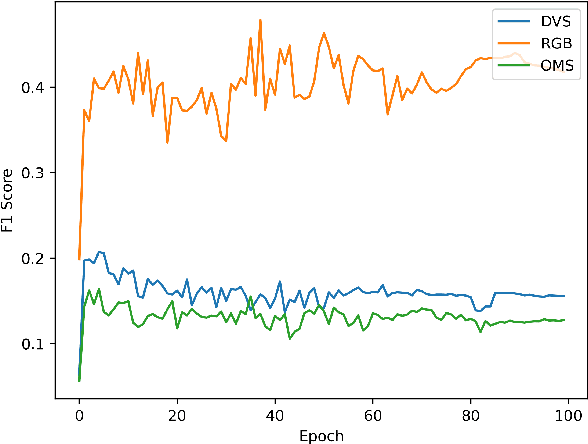
Neuromorphic (event-based) image sensors draw inspiration from the human-retina to create an electronic device that can process visual stimuli in a way that closely resembles its biological counterpart. These sensors process information significantly different than the traditional RGB sensors. Specifically, the sensory information generated by event-based image sensors are orders of magnitude sparser compared to that of RGB sensors. The first generation of neuromorphic image sensors, Dynamic Vision Sensor (DVS), are inspired by the computations confined to the photoreceptors and the first retinal synapse. In this work, we highlight the capability of the second generation of neuromorphic image sensors, Integrated Retinal Functionality in CMOS Image Sensors (IRIS), which aims to mimic full retinal computations from photoreceptors to output of the retina (retinal ganglion cells) for targeted feature-extraction. The feature of choice in this work is Object Motion Sensitivity (OMS) that is processed locally in the IRIS sensor. We study the capability of OMS in solving the ego-motion problem of the event-based cameras. Our results show that OMS can accomplish standard computer vision tasks with similar efficiency to conventional RGB and DVS solutions but offers drastic bandwidth reduction. This cuts the wireless and computing power budgets and opens up vast opportunities in high-speed, robust, energy-efficient, and low-bandwidth real-time decision making.
Where We Are and What We're Looking At: Query Based Worldwide Image Geo-localization Using Hierarchies and Scenes
Mar 07, 2023
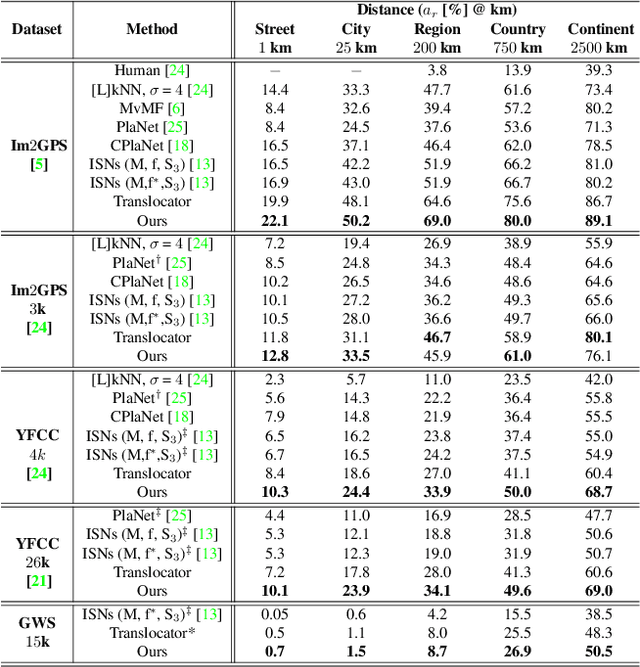

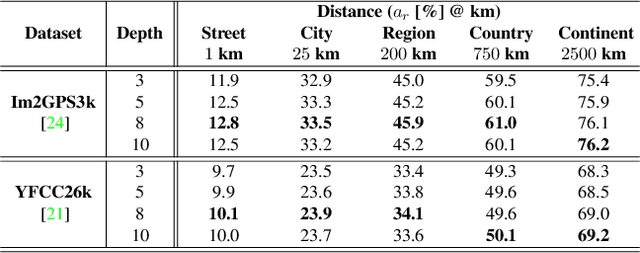
Determining the exact latitude and longitude that a photo was taken is a useful and widely applicable task, yet it remains exceptionally difficult despite the accelerated progress of other computer vision tasks. Most previous approaches have opted to learn a single representation of query images, which are then classified at different levels of geographic granularity. These approaches fail to exploit the different visual cues that give context to different hierarchies, such as the country, state, and city level. To this end, we introduce an end-to-end transformer-based architecture that exploits the relationship between different geographic levels (which we refer to as hierarchies) and the corresponding visual scene information in an image through hierarchical cross-attention. We achieve this by learning a query for each geographic hierarchy and scene type. Furthermore, we learn a separate representation for different environmental scenes, as different scenes in the same location are often defined by completely different visual features. We achieve state of the art street level accuracy on 4 standard geo-localization datasets : Im2GPS, Im2GPS3k, YFCC4k, and YFCC26k, as well as qualitatively demonstrate how our method learns different representations for different visual hierarchies and scenes, which has not been demonstrated in the previous methods. These previous testing datasets mostly consist of iconic landmarks or images taken from social media, which makes them either a memorization task, or biased towards certain places. To address this issue we introduce a much harder testing dataset, Google-World-Streets-15k, comprised of images taken from Google Streetview covering the whole planet and present state of the art results. Our code will be made available in the camera-ready version.
Intriguing properties of synthetic images: from generative adversarial networks to diffusion models
Apr 13, 2023

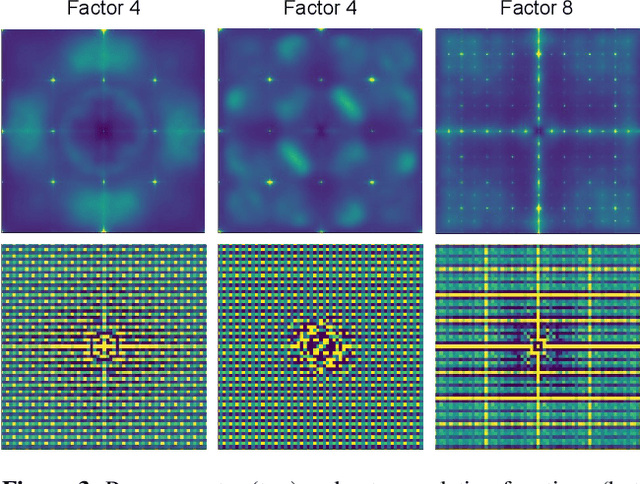
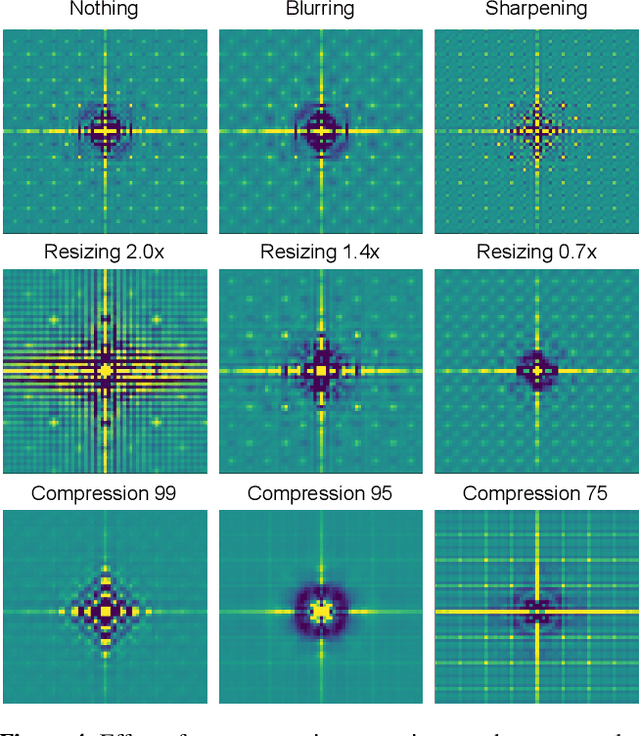
Detecting fake images is becoming a major goal of computer vision. This need is becoming more and more pressing with the continuous improvement of synthesis methods based on Generative Adversarial Networks (GAN), and even more with the appearance of powerful methods based on Diffusion Models (DM). Towards this end, it is important to gain insight into which image features better discriminate fake images from real ones. In this paper we report on our systematic study of a large number of image generators of different families, aimed at discovering the most forensically relevant characteristics of real and generated images. Our experiments provide a number of interesting observations and shed light on some intriguing properties of synthetic images: (1) not only the GAN models but also the DM and VQ-GAN (Vector Quantized Generative Adversarial Networks) models give rise to visible artifacts in the Fourier domain and exhibit anomalous regular patterns in the autocorrelation; (2) when the dataset used to train the model lacks sufficient variety, its biases can be transferred to the generated images; (3) synthetic and real images exhibit significant differences in the mid-high frequency signal content, observable in their radial and angular spectral power distributions.
SC-VAE: Sparse Coding-based Variational Autoencoder
Mar 29, 2023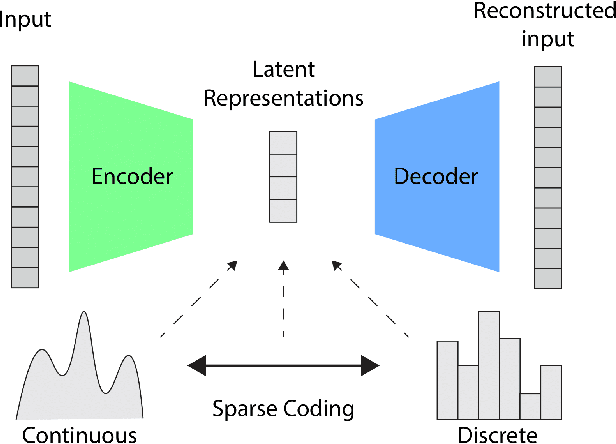
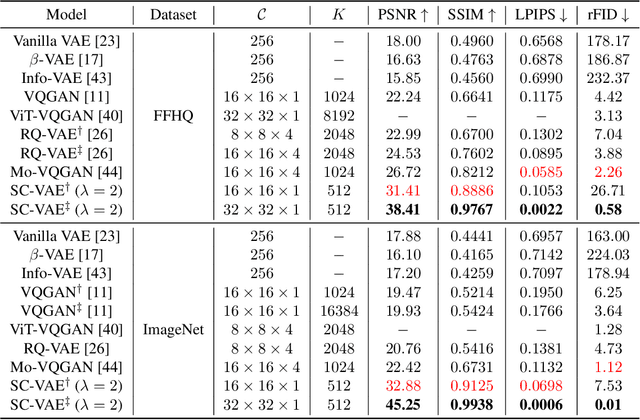
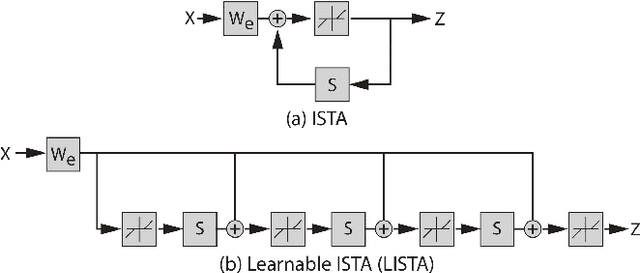
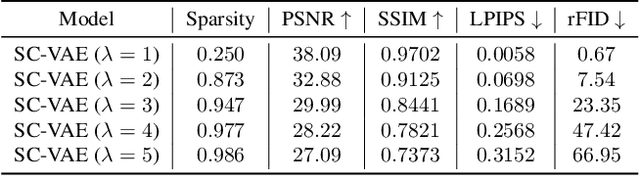
Learning rich data representations from unlabeled data is a key challenge towards applying deep learning algorithms in downstream supervised tasks. Several variants of variational autoencoders have been proposed to learn compact data representaitons by encoding high-dimensional data in a lower dimensional space. Two main classes of VAEs methods may be distinguished depending on the characteristics of the meta-priors that are enforced in the representation learning step. The first class of methods derives a continuous encoding by assuming a static prior distribution in the latent space. The second class of methods learns instead a discrete latent representation using vector quantization (VQ) along with a codebook. However, both classes of methods suffer from certain challenges, which may lead to suboptimal image reconstruction results. The first class of methods suffers from posterior collapse, whereas the second class of methods suffers from codebook collapse. To address these challenges, we introduce a new VAE variant, termed SC-VAE (sparse coding-based VAE), which integrates sparse coding within variational autoencoder framework. Instead of learning a continuous or discrete latent representation, the proposed method learns a sparse data representation that consists of a linear combination of a small number of learned atoms. The sparse coding problem is solved using a learnable version of the iterative shrinkage thresholding algorithm (ISTA). Experiments on two image datasets demonstrate that our model can achieve improved image reconstruction results compared to state-of-the-art methods. Moreover, the use of learned sparse code vectors allows us to perform downstream task like coarse image segmentation through clustering image patches.
DAE-Talker: High Fidelity Speech-Driven Talking Face Generation with Diffusion Autoencoder
Mar 30, 2023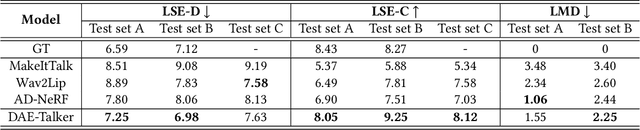
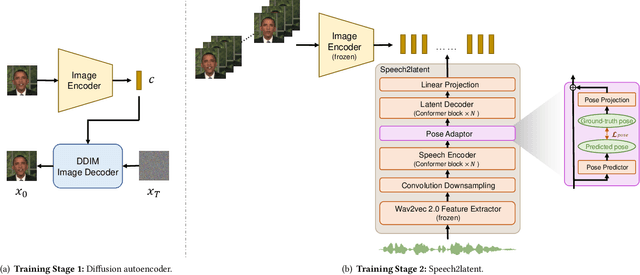

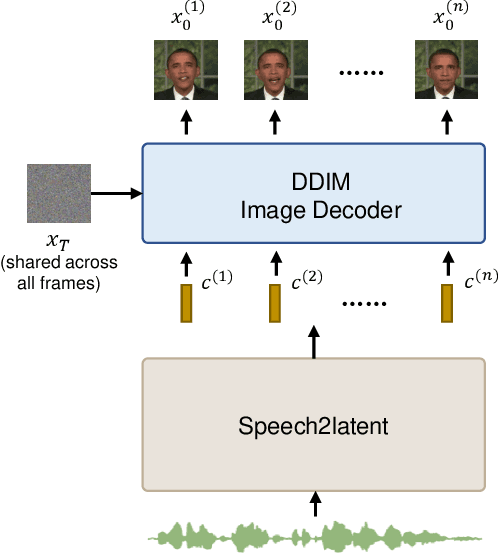
While recent research has made significant progress in speech-driven talking face generation, the quality of the generated video still lags behind that of real recordings. One reason for this is the use of handcrafted intermediate representations like facial landmarks and 3DMM coefficients, which are designed based on human knowledge and are insufficient to precisely describe facial movements. Additionally, these methods require an external pretrained model for extracting these representations, whose performance sets an upper bound on talking face generation. To address these limitations, we propose a novel method called DAE-Talker that leverages data-driven latent representations obtained from a diffusion autoencoder (DAE). DAE contains an image encoder that encodes an image into a latent vector and a DDIM image decoder that reconstructs the image from it. We train our DAE on talking face video frames and then extract their latent representations as the training target for a Conformer-based speech2latent model. This allows DAE-Talker to synthesize full video frames and produce natural head movements that align with the content of speech, rather than relying on a predetermined head pose from a template video. We also introduce pose modelling in speech2latent for pose controllability. Additionally, we propose a novel method for generating continuous video frames with the DDIM image decoder trained on individual frames, eliminating the need for modelling the joint distribution of consecutive frames directly. Our experiments show that DAE-Talker outperforms existing popular methods in lip-sync, video fidelity, and pose naturalness. We also conduct ablation studies to analyze the effectiveness of the proposed techniques and demonstrate the pose controllability of DAE-Talker.
PIAT: Parameter Interpolation based Adversarial Training for Image Classification
Mar 24, 2023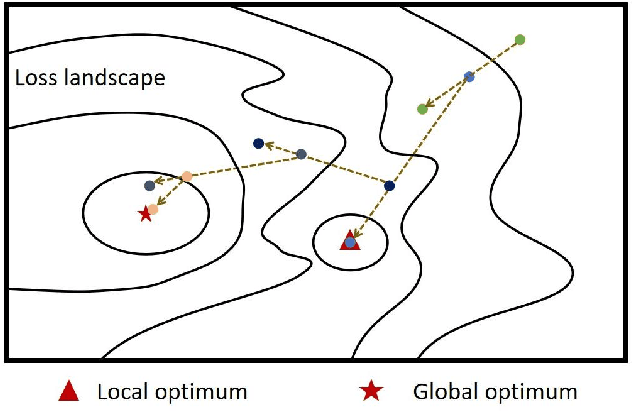
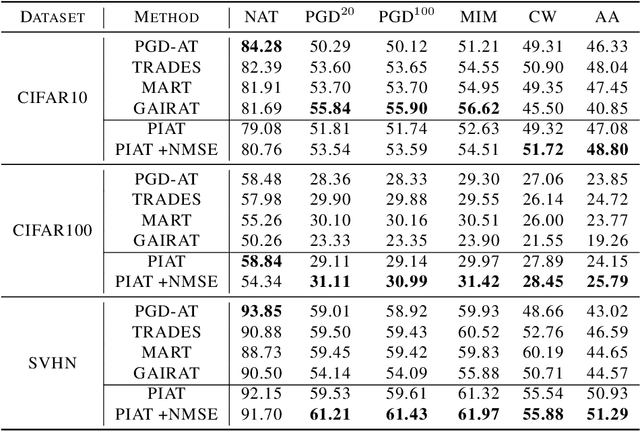
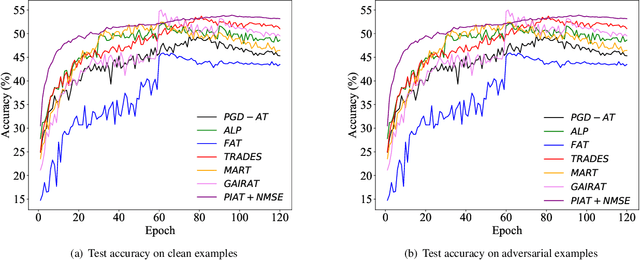
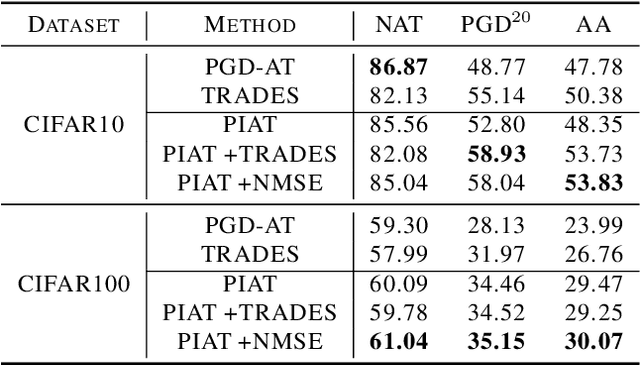
Adversarial training has been demonstrated to be the most effective approach to defend against adversarial attacks. However, existing adversarial training methods show apparent oscillations and overfitting issue in the training process, degrading the defense efficacy. In this work, we propose a novel framework, termed Parameter Interpolation based Adversarial Training (PIAT), that makes full use of the historical information during training. Specifically, at the end of each epoch, PIAT tunes the model parameters as the interpolation of the parameters of the previous and current epochs. Besides, we suggest to use the Normalized Mean Square Error (NMSE) to further improve the robustness by aligning the clean and adversarial examples. Compared with other regularization methods, NMSE focuses more on the relative magnitude of the logits rather than the absolute magnitude. Extensive experiments on several benchmark datasets and various networks show that our method could prominently improve the model robustness and reduce the generalization error. Moreover, our framework is general and could further boost the robust accuracy when combined with other adversarial training methods.
LostPaw: Finding Lost Pets using a Contrastive Learning-based Transformer with Visual Input
Apr 28, 2023Losing pets can be highly distressing for pet owners, and finding a lost pet is often challenging and time-consuming. An artificial intelligence-based application can significantly improve the speed and accuracy of finding lost pets. In order to facilitate such an application, this study introduces a contrastive neural network model capable of accurately distinguishing between images of pets. The model was trained on a large dataset of dog images and evaluated through 3-fold cross-validation. Following 350 epochs of training, the model achieved a test accuracy of 90%. Furthermore, overfitting was avoided, as the test accuracy closely matched the training accuracy. Our findings suggest that contrastive neural network models hold promise as a tool for locating lost pets. This paper provides the foundation for a potential web application that allows users to upload images of their missing pets, receiving notifications when matching images are found in the application's image database. This would enable pet owners to quickly and accurately locate lost pets and reunite them with their families.
QC-StyleGAN -- Quality Controllable Image Generation and Manipulation
Dec 02, 2022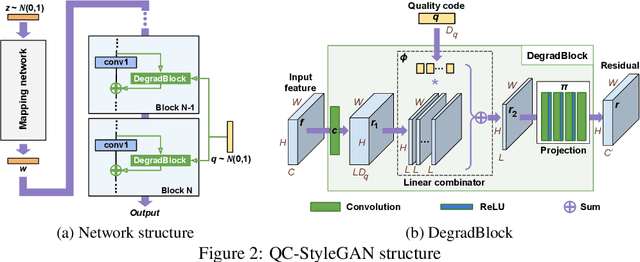
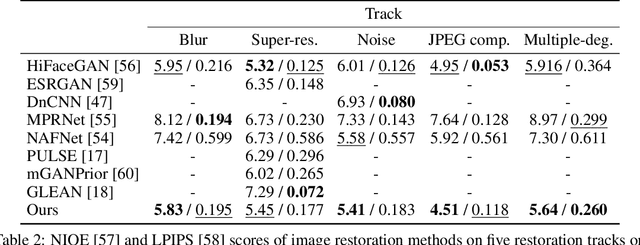


The introduction of high-quality image generation models, particularly the StyleGAN family, provides a powerful tool to synthesize and manipulate images. However, existing models are built upon high-quality (HQ) data as desired outputs, making them unfit for in-the-wild low-quality (LQ) images, which are common inputs for manipulation. In this work, we bridge this gap by proposing a novel GAN structure that allows for generating images with controllable quality. The network can synthesize various image degradation and restore the sharp image via a quality control code. Our proposed QC-StyleGAN can directly edit LQ images without altering their quality by applying GAN inversion and manipulation techniques. It also provides for free an image restoration solution that can handle various degradations, including noise, blur, compression artifacts, and their mixtures. Finally, we demonstrate numerous other applications such as image degradation synthesis, transfer, and interpolation.