 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Interpreting Vision and Language Generative Models with Semantic Visual Priors
May 04, 2023
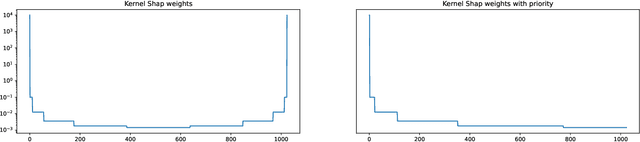

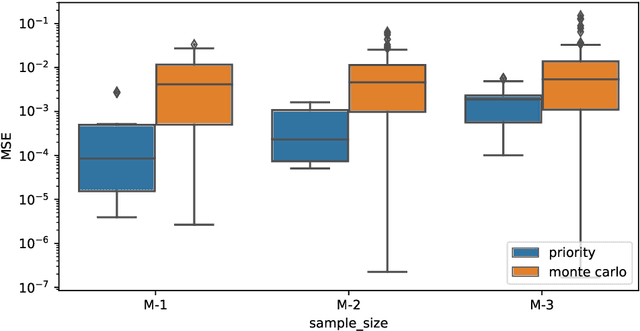
When applied to Image-to-text models, interpretability methods often provide token-by-token explanations namely, they compute a visual explanation for each token of the generated sequence. Those explanations are expensive to compute and unable to comprehensively explain the model's output. Therefore, these models often require some sort of approximation that eventually leads to misleading explanations. We develop a framework based on SHAP, that allows for generating comprehensive, meaningful explanations leveraging the meaning representation of the output sequence as a whole. Moreover, by exploiting semantic priors in the visual backbone, we extract an arbitrary number of features that allows the efficient computation of Shapley values on large-scale models, generating at the same time highly meaningful visual explanations. We demonstrate that our method generates semantically more expressive explanations than traditional methods at a lower compute cost and that it can be generalized over other explainability methods.
The Second Monocular Depth Estimation Challenge
Apr 20, 2023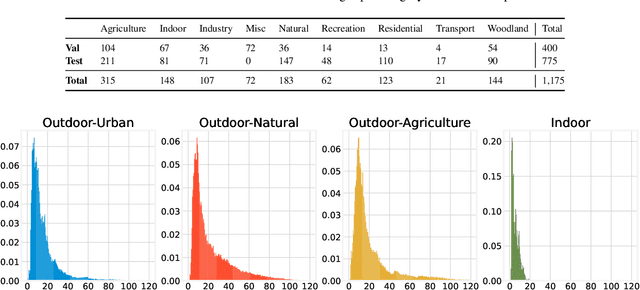
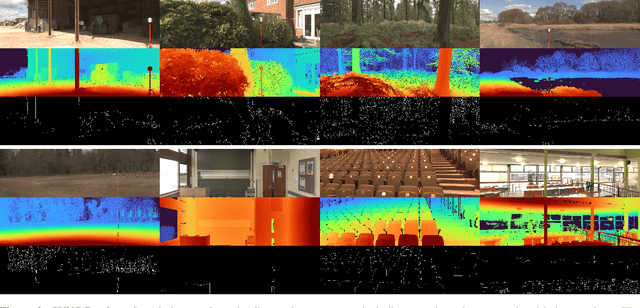
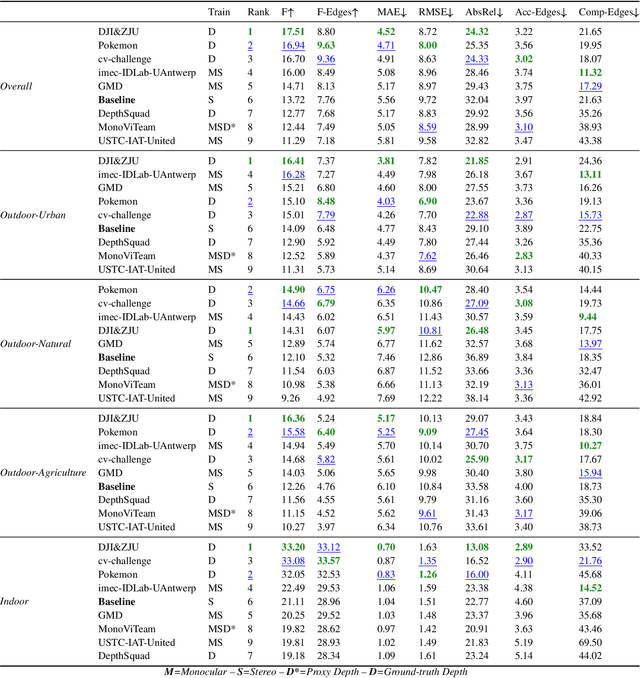
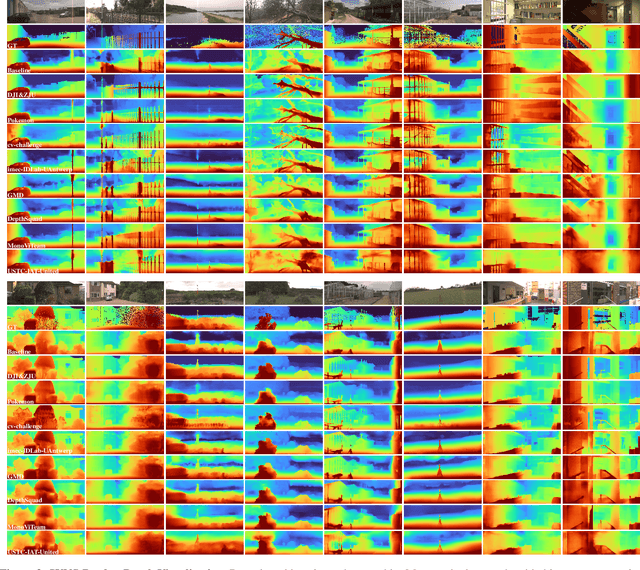
This paper discusses the results for the second edition of the Monocular Depth Estimation Challenge (MDEC). This edition was open to methods using any form of supervision, including fully-supervised, self-supervised, multi-task or proxy depth. The challenge was based around the SYNS-Patches dataset, which features a wide diversity of environments with high-quality dense ground-truth. This includes complex natural environments, e.g. forests or fields, which are greatly underrepresented in current benchmarks. The challenge received eight unique submissions that outperformed the provided SotA baseline on any of the pointcloud- or image-based metrics. The top supervised submission improved relative F-Score by 27.62%, while the top self-supervised improved it by 16.61%. Supervised submissions generally leveraged large collections of datasets to improve data diversity. Self-supervised submissions instead updated the network architecture and pretrained backbones. These results represent a significant progress in the field, while highlighting avenues for future research, such as reducing interpolation artifacts at depth boundaries, improving self-supervised indoor performance and overall natural image accuracy.
FIANCEE: Faster Inference of Adversarial Networks via Conditional Early Exits
Apr 20, 2023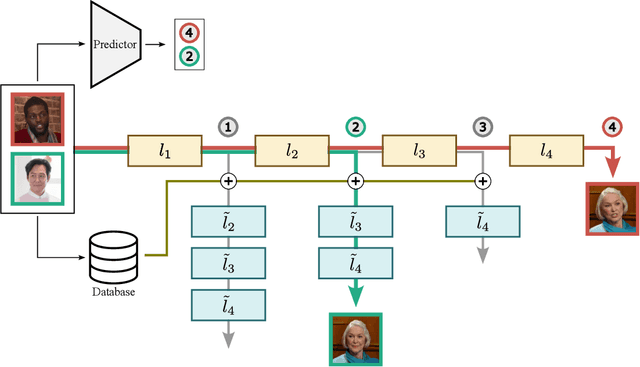
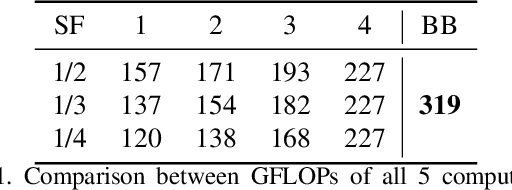
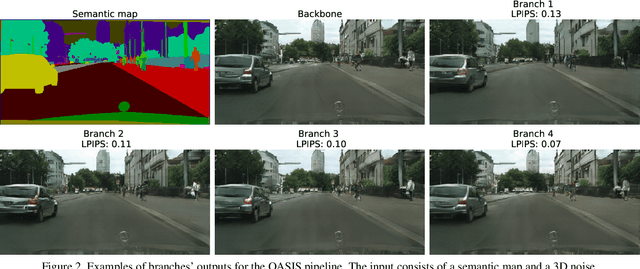
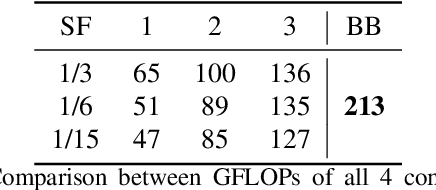
Generative DNNs are a powerful tool for image synthesis, but they are limited by their computational load. On the other hand, given a trained model and a task, e.g. faces generation within a range of characteristics, the output image quality will be unevenly distributed among images with different characteristics. It follows, that we might restrain the models complexity on some instances, maintaining a high quality. We propose a method for diminishing computations by adding so-called early exit branches to the original architecture, and dynamically switching the computational path depending on how difficult it will be to render the output. We apply our method on two different SOTA models performing generative tasks: generation from a semantic map, and cross-reenactment of face expressions; showing it is able to output images with custom lower-quality thresholds. For a threshold of LPIPS <=0.1, we diminish their computations by up to a half. This is especially relevant for real-time applications such as synthesis of faces, when quality loss needs to be contained, but most of the inputs need fewer computations than the complex instances.
Visual DNA: Representing and Comparing Images using Distributions of Neuron Activations
Apr 20, 2023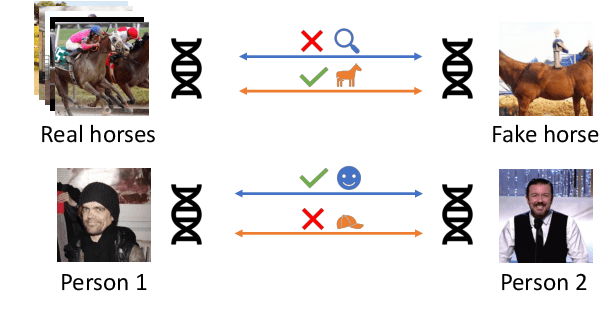

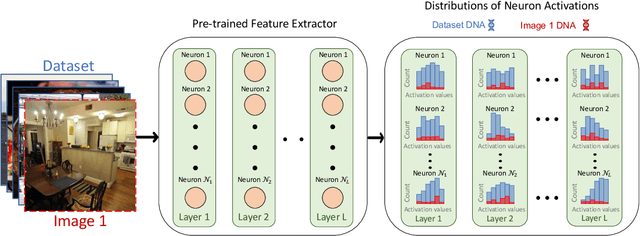
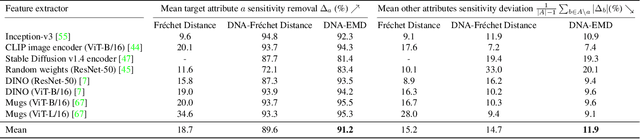
Selecting appropriate datasets is critical in modern computer vision. However, no general-purpose tools exist to evaluate the extent to which two datasets differ. For this, we propose representing images - and by extension datasets - using Distributions of Neuron Activations (DNAs). DNAs fit distributions, such as histograms or Gaussians, to activations of neurons in a pre-trained feature extractor through which we pass the image(s) to represent. This extractor is frozen for all datasets, and we rely on its generally expressive power in feature space. By comparing two DNAs, we can evaluate the extent to which two datasets differ with granular control over the comparison attributes of interest, providing the ability to customise the way distances are measured to suit the requirements of the task at hand. Furthermore, DNAs are compact, representing datasets of any size with less than 15 megabytes. We demonstrate the value of DNAs by evaluating their applicability on several tasks, including conditional dataset comparison, synthetic image evaluation, and transfer learning, and across diverse datasets, ranging from synthetic cat images to celebrity faces and urban driving scenes.
MIPI 2023 Challenge on RGBW Fusion: Methods and Results
Apr 20, 2023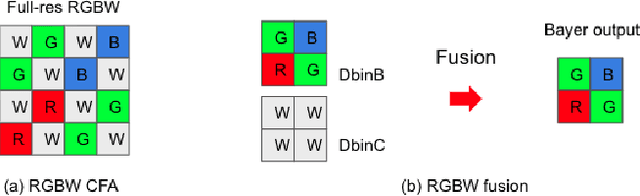


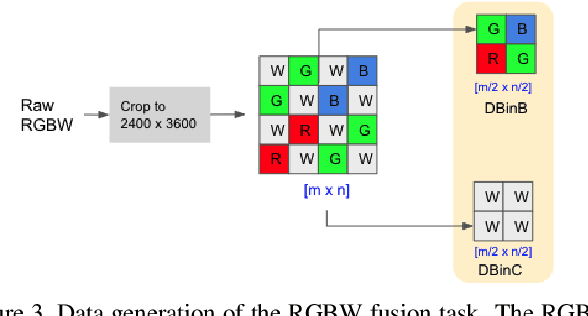
Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for an in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). With the success of the 1st MIPI Workshop@ECCV 2022, we introduce the second MIPI challenge, including four tracks focusing on novel image sensors and imaging algorithms. This paper summarizes and reviews the RGBW Joint Remosaic and Denoise track on MIPI 2023. In total, 81 participants were successfully registered, and 4 teams submitted results in the final testing phase. The final results are evaluated using objective metrics, including PSNR, SSIM, LPIPS, and KLD. A detailed description of the top three models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2023/.
MIPI 2023 Challenge on RGBW Remosaic: Methods and Results
Apr 20, 2023


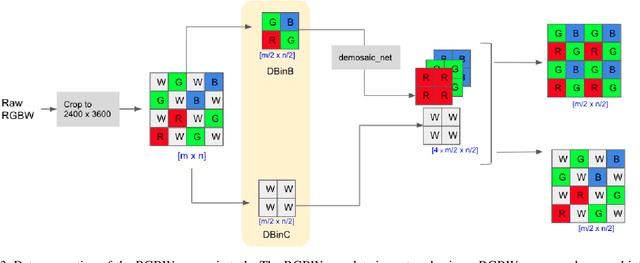
Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for an in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). With the success of the 1st MIPI Workshop@ECCV 2022, we introduce the second MIPI challenge, including four tracks focusing on novel image sensors and imaging algorithms. This paper summarizes and reviews the RGBW Joint Remosaic and Denoise track on MIPI 2023. In total, 81 participants were successfully registered, and 4 teams submitted results in the final testing phase. The final results are evaluated using objective metrics, including PSNR, SSIM, LPIPS, and KLD. A detailed description of the top three models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2023/.
AutoColor: Learned Light Power Control for Multi-Color Holograms
May 02, 2023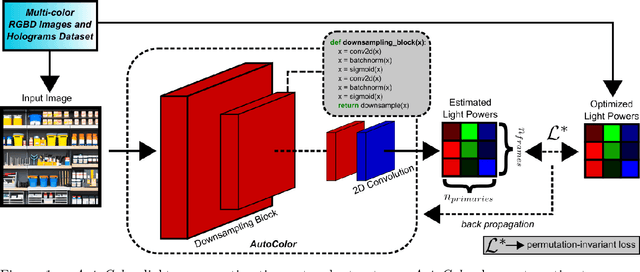

Multi-color holograms rely on simultaneous illumination from multiple light sources. These multi-color holograms could utilize light sources better than conventional single-color holograms and can improve the dynamic range of holographic displays. In this letter, we introduce \projectname, the first learned method for estimating the optimal light source powers required for illuminating multi-color holograms. For this purpose, we establish the first multi-color hologram dataset using synthetic images and their depth information. We generate these synthetic images using a trending pipeline combining generative, large language, and monocular depth estimation models. Finally, we train our learned model using our dataset and experimentally demonstrate that \projectname significantly decreases the number of steps required to optimize multi-color holograms from $>1000$ to $70$ iteration steps without compromising image quality.
Exploring the Protein Sequence Space with Global Generative Models
May 03, 2023Recent advancements in specialized large-scale architectures for training image and language have profoundly impacted the field of computer vision and natural language processing (NLP). Language models, such as the recent ChatGPT and GPT4 have demonstrated exceptional capabilities in processing, translating, and generating human languages. These breakthroughs have also been reflected in protein research, leading to the rapid development of numerous new methods in a short time, with unprecedented performance. Language models, in particular, have seen widespread use in protein research, as they have been utilized to embed proteins, generate novel ones, and predict tertiary structures. In this book chapter, we provide an overview of the use of protein generative models, reviewing 1) language models for the design of novel artificial proteins, 2) works that use non-Transformer architectures, and 3) applications in directed evolution approaches.
Neural Gas Network Image Features and Segmentation for Brain Tumor Detection Using Magnetic Resonance Imaging Data
Jan 28, 2023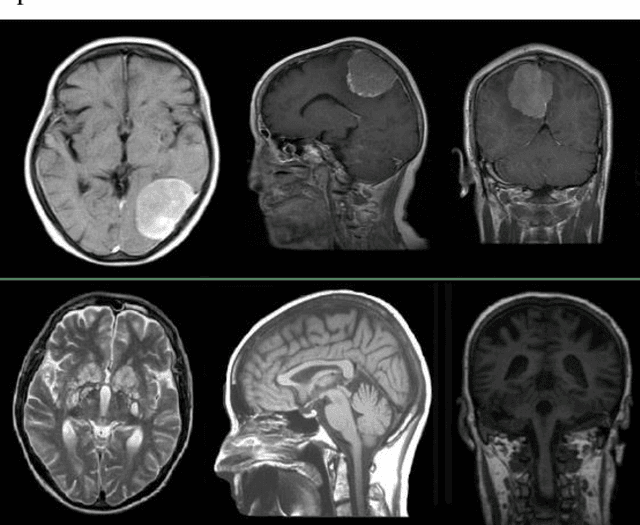
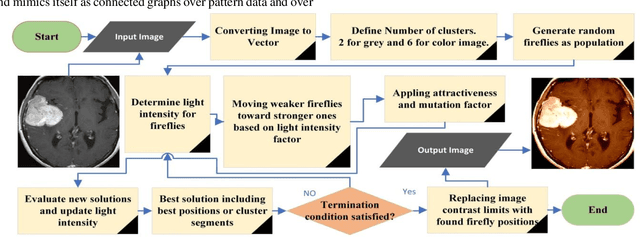
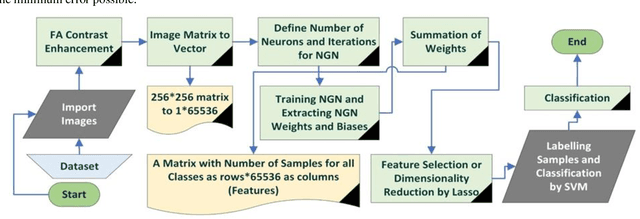
Accurate detection of brain tumors could save lots of lives and increasing the accuracy of this binary classification even as much as a few percent has high importance. Neural Gas Networks (NGN) is a fast, unsupervised algorithm that could be used in data clustering, image pattern recognition, and image segmentation. In this research, we used the metaheuristic Firefly Algorithm (FA) for image contrast enhancement as pre-processing and NGN weights for feature extraction and segmentation of Magnetic Resonance Imaging (MRI) data on two brain tumor datasets from the Kaggle platform. Also, tumor classification is conducted by Support Vector Machine (SVM) classification algorithms and compared with a deep learning technique plus other features in train and test phases. Additionally, NGN tumor segmentation is evaluated by famous performance metrics such as Accuracy, F-measure, Jaccard, and more versus ground truth data and compared with traditional segmentation techniques. The proposed method is fast and precise in both tasks of tumor classification and segmentation compared with other methods. A classification accuracy of 95.14 % and segmentation accuracy of 0.977 is achieved by the proposed method.
Anti-scattering medium computational ghost imaging with modified Hadamard patterns
Apr 15, 2023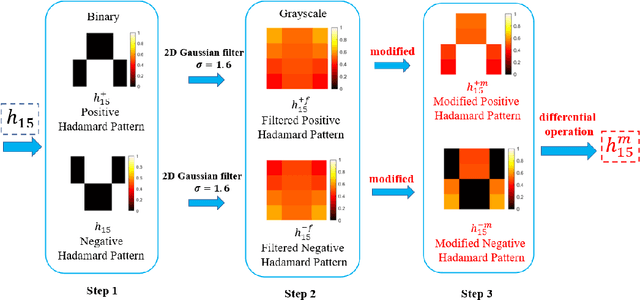
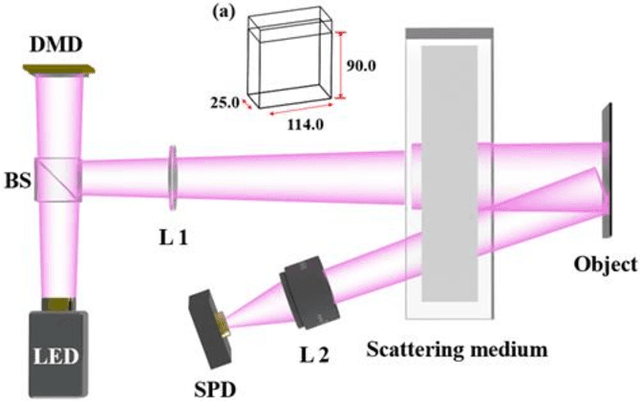
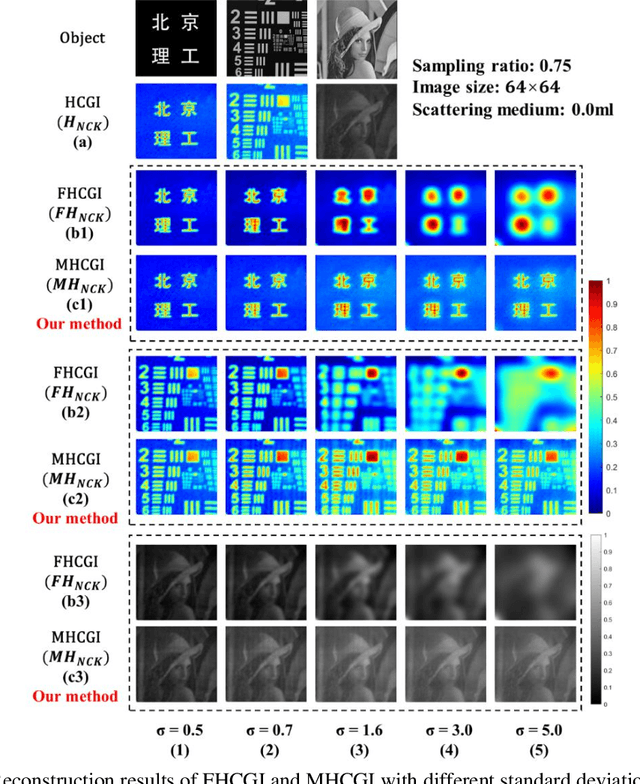
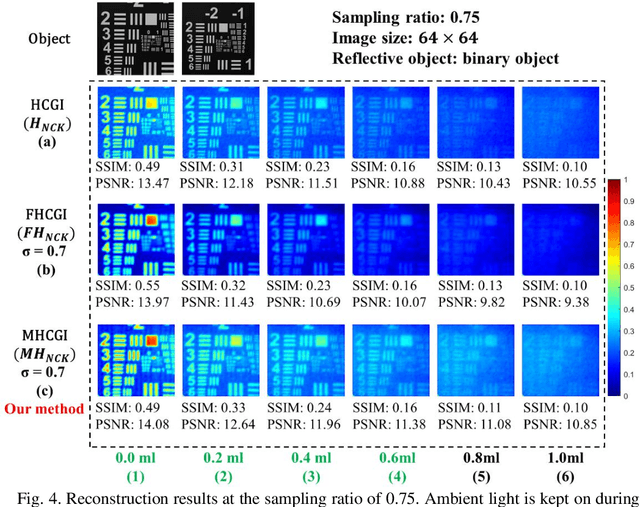
Illumination patterns of computational ghost imaging (CGI) systems suffer from reduced contrast when passing through a scattering medium, which causes the effective information in the reconstruction result to be drowned out by noise. A two-dimensional (2D) Gaussian filter performs linear smoothing operation on the whole image for image denoising. It can be combined with linear reconstruction algorithms of CGI to obtain the noise-reduced results directly, without post-processing. However, it results in blurred image edges while performing denoising and, in addition, a suitable standard deviation is difficult to choose in advance, especially in an unknown scattering environment. In this work, we subtly exploit the characteristics of CGI to solve these two problems very well. A kind of modified Hadamard pattern based on the 2D Gaussian filter and the differential operation features of Hadamard-based CGI is developed. We analyze and demonstrate that using Hadamard patterns for illumination but using our developed modified Hadamard patterns for reconstruction (MHCGI) can enhance the robustness of CGI against turbid scattering medium. Our method not only helps directly obtain noise-reduced results without blurred edges but also requires only an approximate standard deviation, i.e., it can be set in advance. The experimental results on transmitted and reflected targets demonstrate the feasibility of our method. Our method helps to promote the practical application of CGI in the scattering environment.