 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Beta-Rank: A Robust Convolutional Filter Pruning Method For Imbalanced Medical Image Analysis
Apr 15, 2023
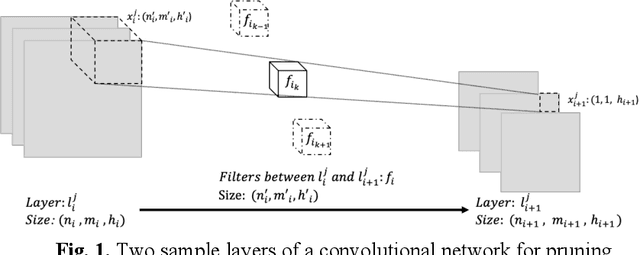
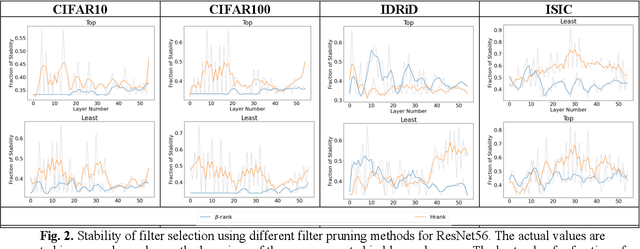
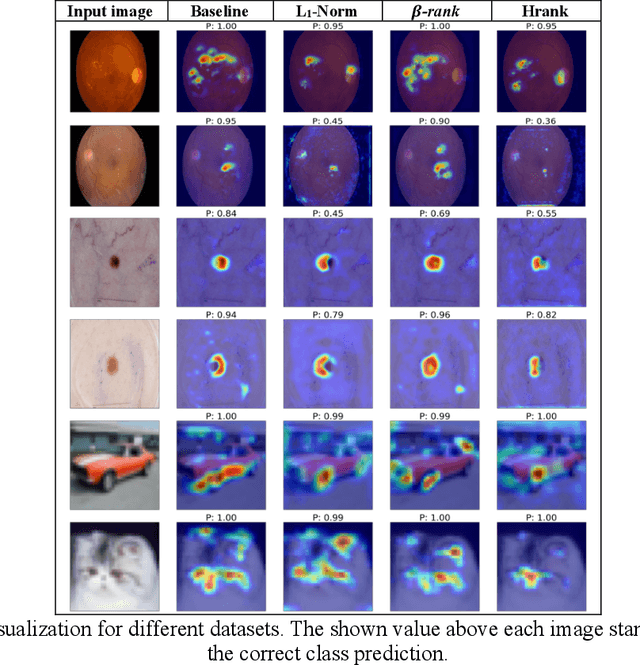
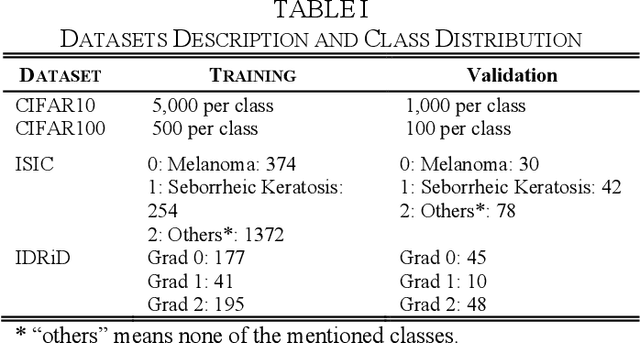
As deep neural networks include a high number of parameters and operations, it can be a challenge to implement these models on devices with limited computational resources. Despite the development of novel pruning methods toward resource-efficient models, it has become evident that these models are not capable of handling "imbalanced" and "limited number of data points". With input and output information, along with the values of the filters, a novel filter pruning method is proposed. Our pruning method considers the fact that all information about the importance of a filter may not be reflected in the value of the filter. Instead, it is reflected in the changes made to the data after the filter is applied to it. In this work, three methods are compared with the same training conditions except for the ranking of each method. We demonstrated that our model performed significantly better than other methods for medical datasets which are inherently imbalanced. When we removed up to 58% of FLOPs for the IDRID dataset and up to 45% for the ISIC dataset, our model was able to yield an equivalent (or even superior) result to the baseline model while other models were unable to achieve similar results. To evaluate FLOP and parameter reduction using our model in real-world settings, we built a smartphone app, where we demonstrated a reduction of up to 79% in memory usage and 72% in prediction time. All codes and parameters for training different models are available at https://github.com/mohofar/Beta-Rank
NeRF-Loc: Visual Localization with Conditional Neural Radiance Field
Apr 17, 2023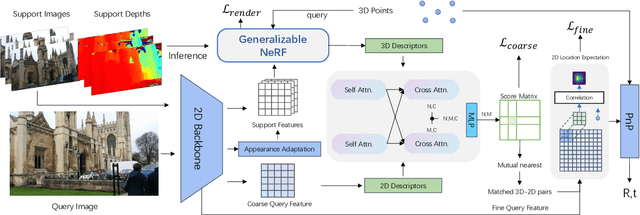



We propose a novel visual re-localization method based on direct matching between the implicit 3D descriptors and the 2D image with transformer. A conditional neural radiance field(NeRF) is chosen as the 3D scene representation in our pipeline, which supports continuous 3D descriptors generation and neural rendering. By unifying the feature matching and the scene coordinate regression to the same framework, our model learns both generalizable knowledge and scene prior respectively during two training stages. Furthermore, to improve the localization robustness when domain gap exists between training and testing phases, we propose an appearance adaptation layer to explicitly align styles between the 3D model and the query image. Experiments show that our method achieves higher localization accuracy than other learning-based approaches on multiple benchmarks. Code is available at \url{https://github.com/JenningsL/nerf-loc}.
2D Forward Looking Sonar Simulation with Ground Echo Modeling
Apr 17, 2023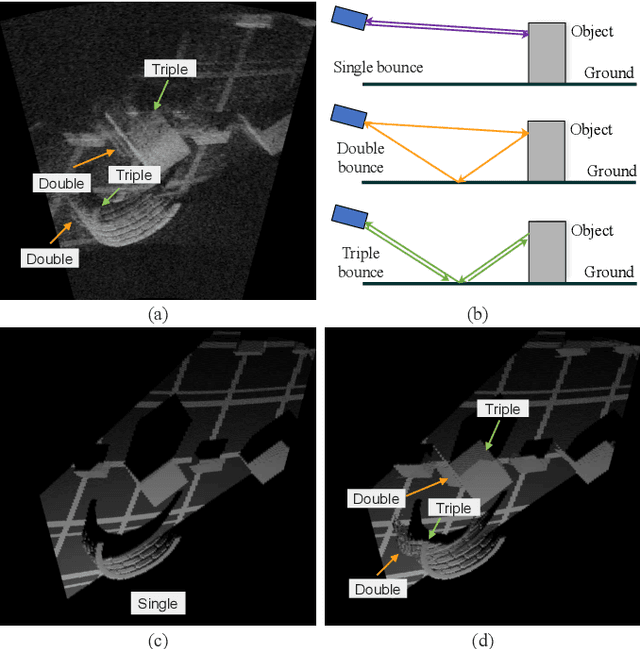

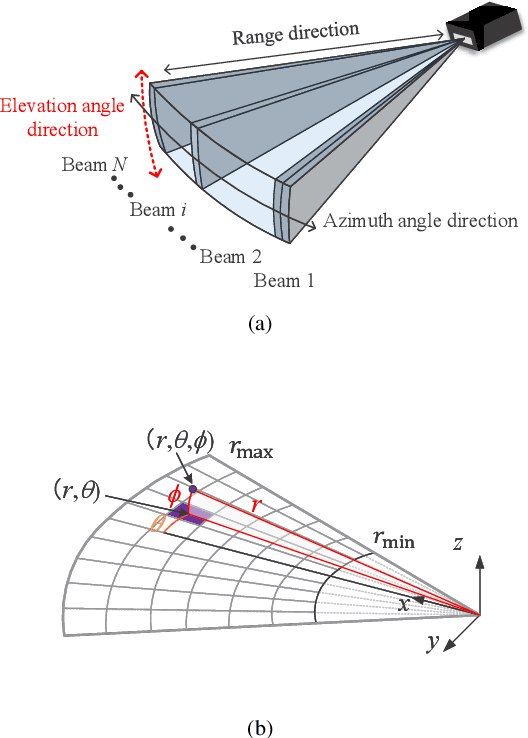
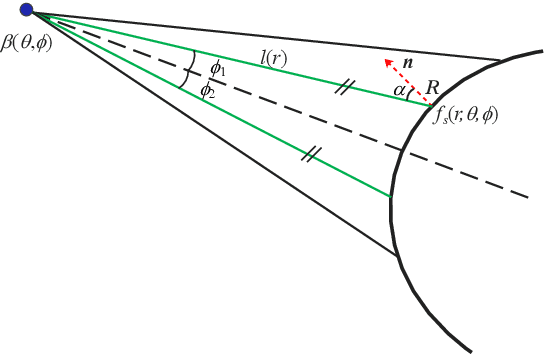
Imaging sonar produces clear images in underwater environments, independent of water turbidity and lighting conditions. The next generation 2D forward looking sonars are compact in size and able to generate high-resolution images which facilitate underwater robotics research. Considering the difficulties and expenses of implementing experiments in underwater environments, tremendous work has been focused on sonar image simulation. However, sonar artifacts like multi-path reflection were not sufficiently discussed, which cannot be ignored in water tank environments. In this paper, we focus on the influence of echoes from the flat ground. We propose a method to simulate the ground echo effect physically in acoustic images. We model the multi-bounce situations using the single-bounce framework for computation efficiency. We compare the real image captured in the water tank with the synthetic images to validate the proposed methods.
A Comprehensive Study on Robustness of Image Classification Models: Benchmarking and Rethinking
Feb 28, 2023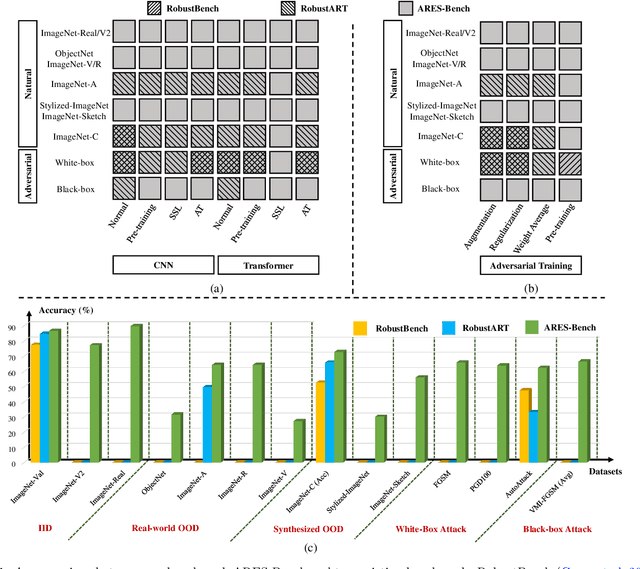

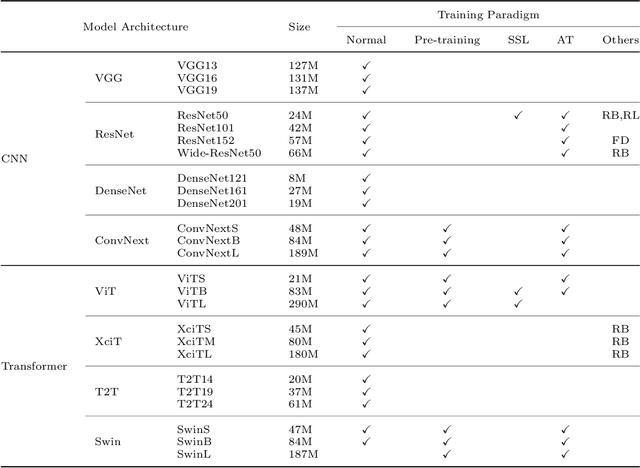
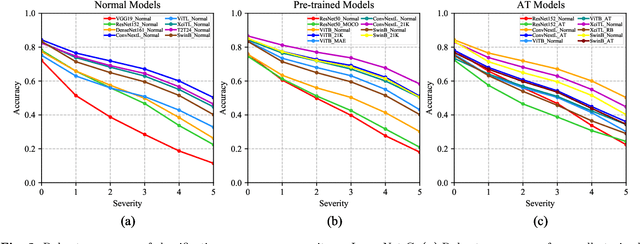
The robustness of deep neural networks is usually lacking under adversarial examples, common corruptions, and distribution shifts, which becomes an important research problem in the development of deep learning. Although new deep learning methods and robustness improvement techniques have been constantly proposed, the robustness evaluations of existing methods are often inadequate due to their rapid development, diverse noise patterns, and simple evaluation metrics. Without thorough robustness evaluations, it is hard to understand the advances in the field and identify the effective methods. In this paper, we establish a comprehensive robustness benchmark called \textbf{ARES-Bench} on the image classification task. In our benchmark, we evaluate the robustness of 55 typical deep learning models on ImageNet with diverse architectures (e.g., CNNs, Transformers) and learning algorithms (e.g., normal supervised training, pre-training, adversarial training) under numerous adversarial attacks and out-of-distribution (OOD) datasets. Using robustness curves as the major evaluation criteria, we conduct large-scale experiments and draw several important findings, including: 1) there is an inherent trade-off between adversarial and natural robustness for the same model architecture; 2) adversarial training effectively improves adversarial robustness, especially when performed on Transformer architectures; 3) pre-training significantly improves natural robustness based on more training data or self-supervised learning. Based on ARES-Bench, we further analyze the training tricks in large-scale adversarial training on ImageNet. By designing the training settings accordingly, we achieve the new state-of-the-art adversarial robustness. We have made the benchmarking results and code platform publicly available.
Relaxed forced choice improves performance of visual quality assessment methods
Apr 29, 2023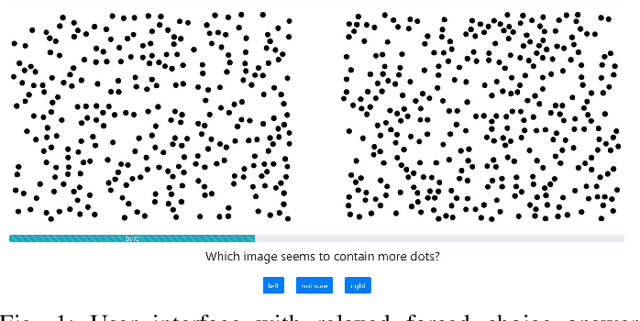
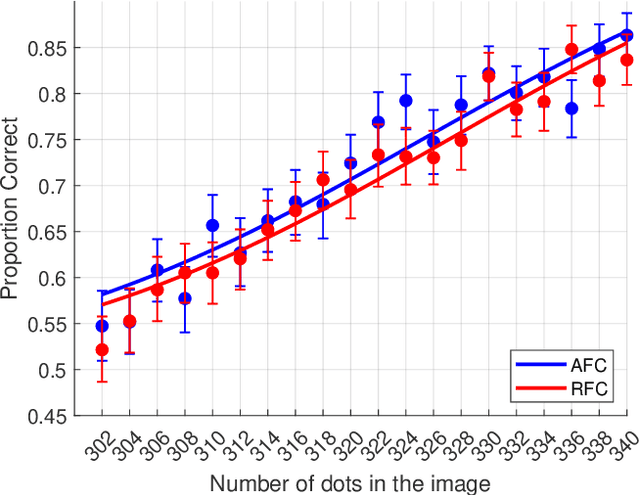
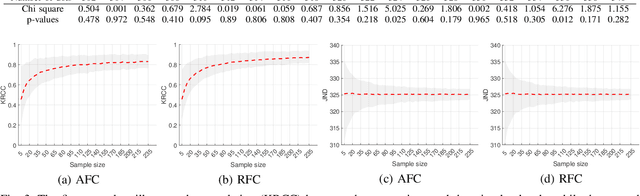
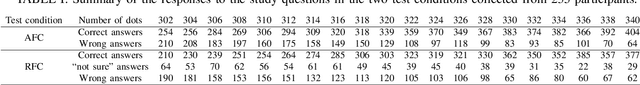
In image quality assessment, a collective visual quality score for an image or video is obtained from the individual ratings of many subjects. One commonly used format for these experiments is the two-alternative forced choice method. Two stimuli with the same content but differing visual quality are presented sequentially or side-by-side. Subjects are asked to select the one of better quality, and when uncertain, they are required to guess. The relaxed alternative forced choice format aims to reduce the cognitive load and the noise in the responses due to the guessing by providing a third response option, namely, ``not sure''. This work presents a large and comprehensive crowdsourcing experiment to compare these two response formats: the one with the ``not sure'' option and the one without it. To provide unambiguous ground truth for quality evaluation, subjects were shown pairs of images with differing numbers of dots and asked each time to choose the one with more dots. Our crowdsourcing study involved 254 participants and was conducted using a within-subject design. Each participant was asked to respond to 40 pair comparisons with and without the ``not sure'' response option and completed a questionnaire to evaluate their cognitive load for each testing condition. The experimental results show that the inclusion of the ``not sure'' response option in the forced choice method reduced mental load and led to models with better data fit and correspondence to ground truth. We also tested for the equivalence of the models and found that they were different. The dataset is available at http://database.mmsp-kn.de/cogvqa-database.html.
Teacher Network Calibration Improves Cross-Quality Knowledge Distillation
Apr 15, 2023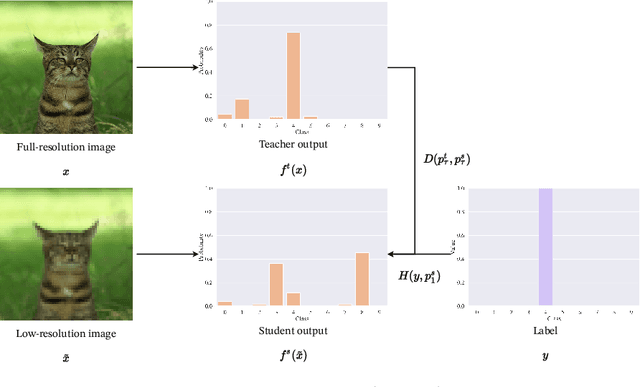
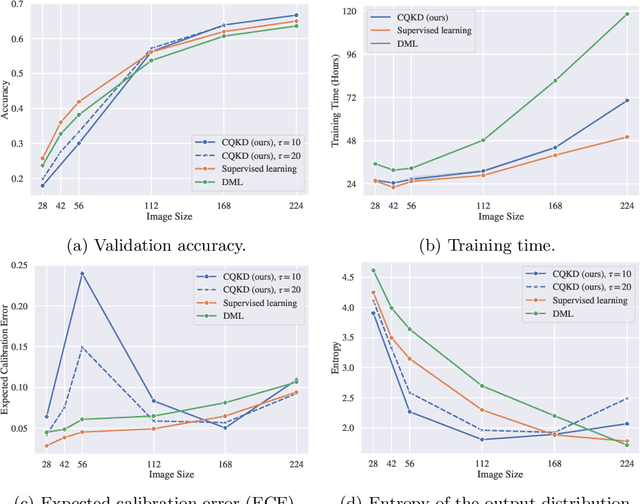
We investigate cross-quality knowledge distillation (CQKD), a knowledge distillation method where knowledge from a teacher network trained with full-resolution images is transferred to a student network that takes as input low-resolution images. As image size is a deciding factor for the computational load of computer vision applications, CQKD notably reduces the requirements by only using the student network at inference time. Our experimental results show that CQKD outperforms supervised learning in large-scale image classification problems. We also highlight the importance of calibrating neural networks: we show that with higher temperature smoothing of the teacher's output distribution, the student distribution exhibits a higher entropy, which leads to both, a lower calibration error and a higher network accuracy.
A Comprehensive Survey on Segment Anything Model for Vision and Beyond
May 14, 2023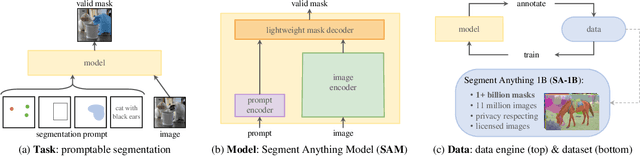
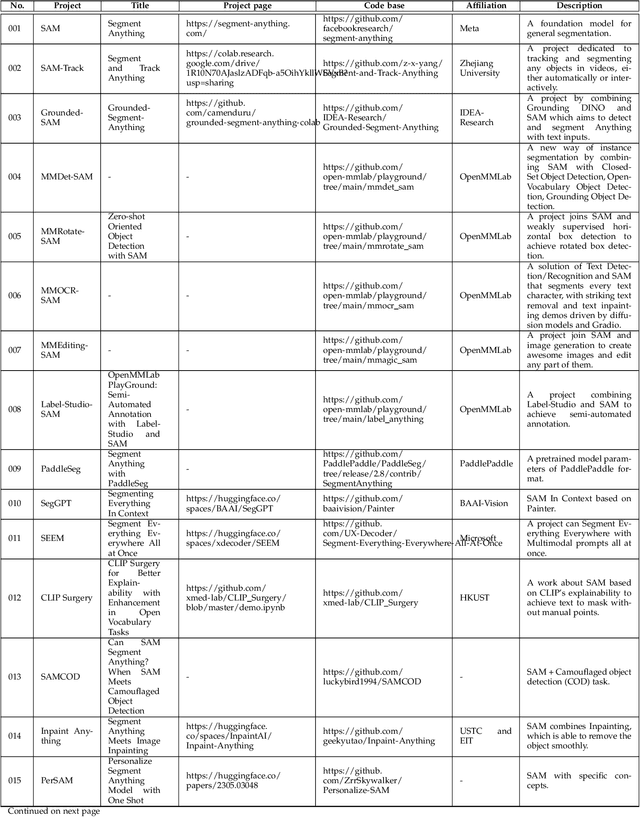

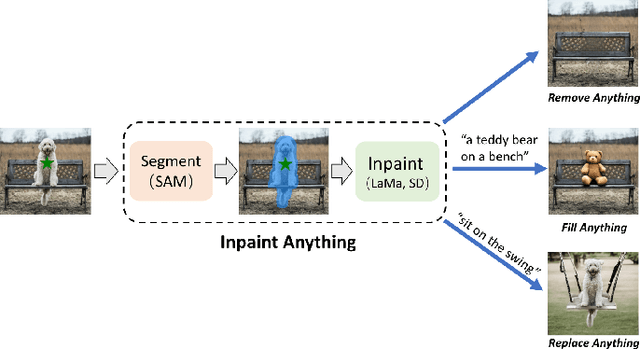
Artificial intelligence (AI) is evolving towards artificial general intelligence, which refers to the ability of an AI system to perform a wide range of tasks and exhibit a level of intelligence similar to that of a human being. This is in contrast to narrow or specialized AI, which is designed to perform specific tasks with a high degree of efficiency. Therefore, it is urgent to design a general class of models, which we term foundation models, trained on broad data that can be adapted to various downstream tasks. The recently proposed segment anything model (SAM) has made significant progress in breaking the boundaries of segmentation, greatly promoting the development of foundation models for computer vision. To fully comprehend SAM, we conduct a survey study. As the first to comprehensively review the progress of segmenting anything task for vision and beyond based on the foundation model of SAM, this work focuses on its applications to various tasks and data types by discussing its historical development, recent progress, and profound impact on broad applications. We first introduce the background and terminology for foundation models including SAM, as well as state-of-the-art methods contemporaneous with SAM that are significant for segmenting anything task. Then, we analyze and summarize the advantages and limitations of SAM across various image processing applications, including software scenes, real-world scenes, and complex scenes. Importantly, some insights are drawn to guide future research to develop more versatile foundation models and improve the architecture of SAM. We also summarize massive other amazing applications of SAM in vision and beyond.
Shape-Net: Room Layout Estimation from Panoramic Images Robust to Occlusion using Knowledge Distillation with 3D Shapes as Additional Inputs
Apr 25, 2023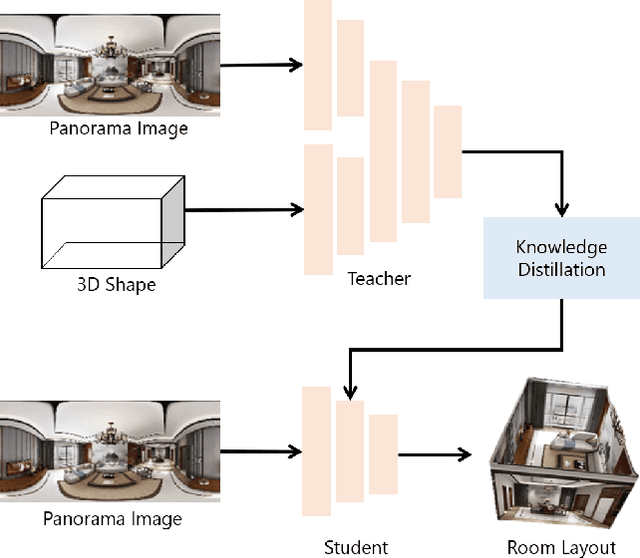

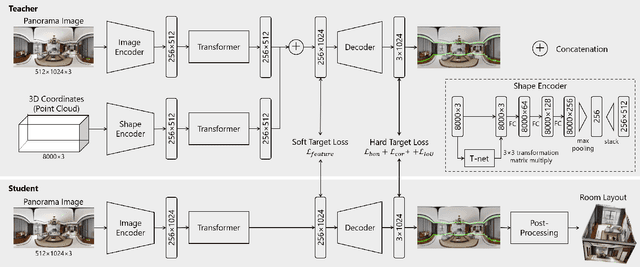

Estimating the layout of a room from a single-shot panoramic image is important in virtual/augmented reality and furniture layout simulation. This involves identifying three-dimensional (3D) geometry, such as the location of corners and boundaries, and performing 3D reconstruction. However, occlusion is a common issue that can negatively impact room layout estimation, and this has not been thoroughly studied to date. It is possible to obtain 3D shape information of rooms as drawings of buildings and coordinates of corners from image datasets, thus we propose providing both 2D panoramic and 3D information to a model to effectively deal with occlusion. However, simply feeding 3D information to a model is not sufficient to utilize the shape information for an occluded area. Therefore, we improve the model by introducing 3D Intersection over Union (IoU) loss to effectively use 3D information. In some cases, drawings are not available or the construction deviates from a drawing. Considering such practical cases, we propose a method for distilling knowledge from a model trained with both images and 3D information to a model that takes only images as input. The proposed model, which is called Shape-Net, achieves state-of-the-art (SOTA) performance on benchmark datasets. We also confirmed its effectiveness in dealing with occlusion through significantly improved accuracy on images with occlusion compared with existing models.
Example-Based Explainable AI and its Application for Remote Sensing Image Classification
Feb 03, 2023
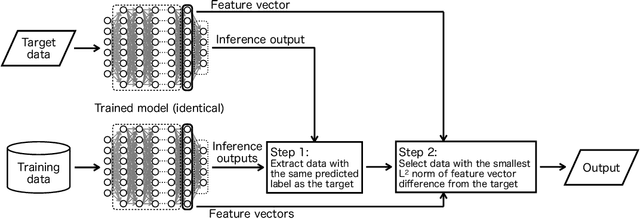


We present a method of explainable artificial intelligence (XAI), "What I Know (WIK)", to provide additional information to verify the reliability of a deep learning model by showing an example of an instance in a training dataset that is similar to the input data to be inferred and demonstrate it in a remote sensing image classification task. One of the expected roles of XAI methods is verifying whether inferences of a trained machine learning model are valid for an application, and it is an important factor that what datasets are used for training the model as well as the model architecture. Our data-centric approach can help determine whether the training dataset is sufficient for each inference by checking the selected example data. If the selected example looks similar to the input data, we can confirm that the model was not trained on a dataset with a feature distribution far from the feature of the input data. With this method, the criteria for selecting an example are not merely data similarity with the input data but also data similarity in the context of the model task. Using a remote sensing image dataset from the Sentinel-2 satellite, the concept was successfully demonstrated with reasonably selected examples. This method can be applied to various machine-learning tasks, including classification and regression.
Maximum Spherical Mean Value (mSMV) Filtering for Whole Brain Quantitative Susceptibility Mapping
Apr 22, 2023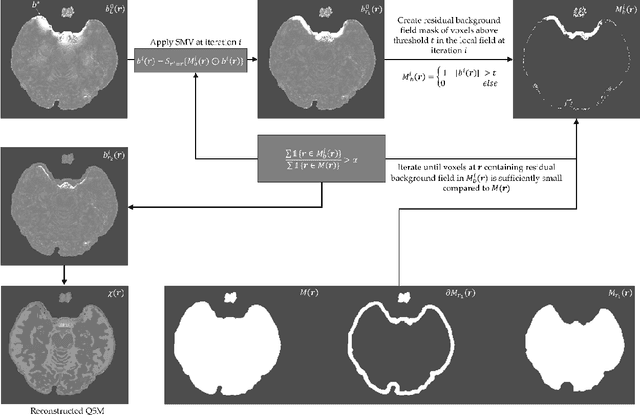
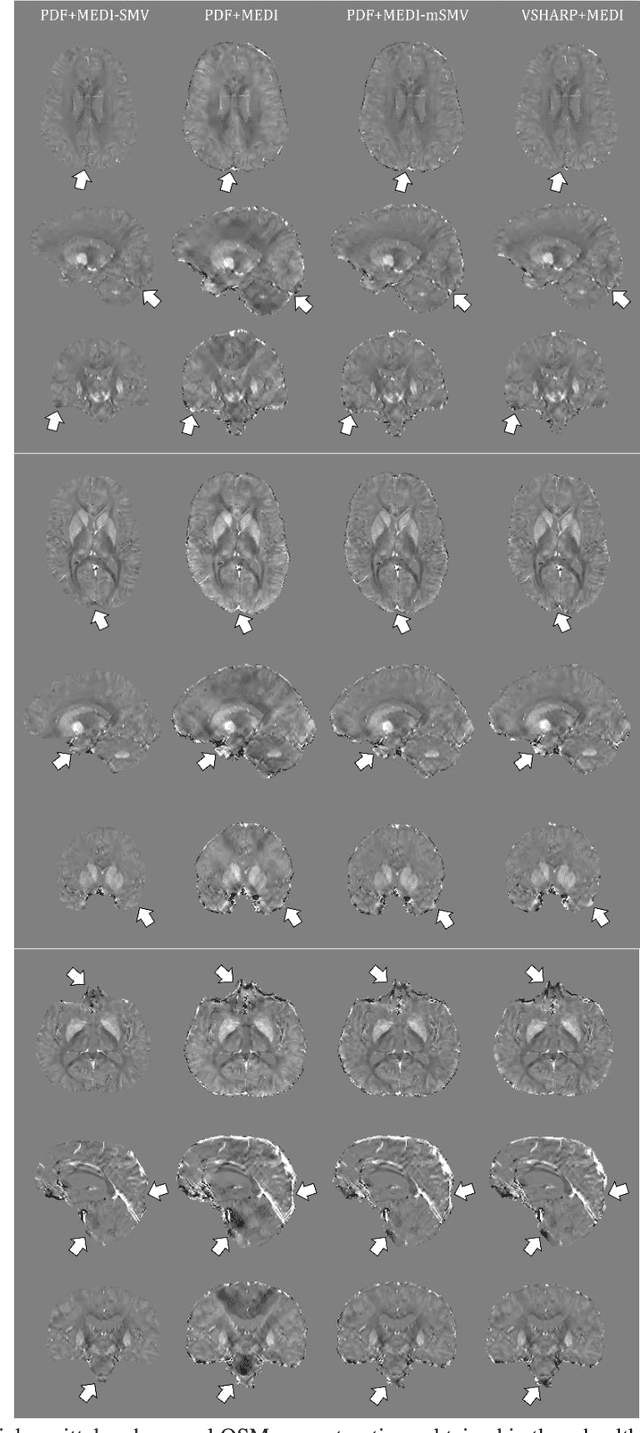
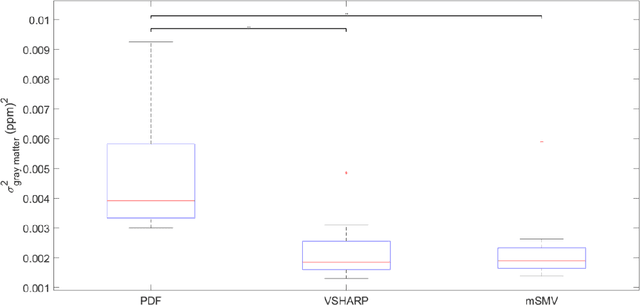
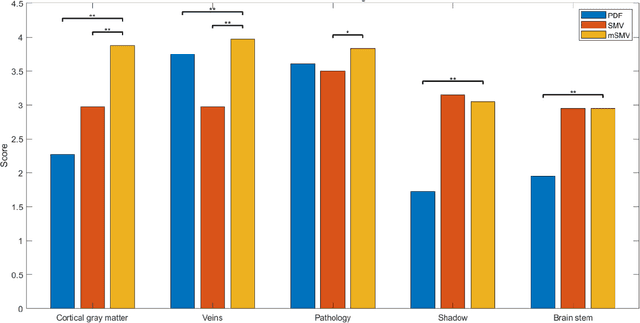
To develop a tissue field filtering algorithm, called maximum Spherical Mean Value (mSMV), for reducing shadow artifacts in quantitative susceptibility mapping (QSM) of the brain without requiring brain tissue erosion. Residual background field is a major source of shadow artifacts in QSM. The mSMV algorithm filters large field values near the border, where the maximum value of the harmonic background field is located. The effectiveness of mSMV for artifact removal was evaluated by comparing with existing QSM algorithms in a simulated numerical brain, 11 healthy volunteers, by assessing image quality in routine clinical patient study $(n=43)$, and by measuring lesion susceptibility values in multiple sclerosis patients $(n=50)$, a total of $n=93$ patients. Numerical simulation showed that mSMV reduces shadow artifacts and improves QSM accuracy. Better shadow reduction, as demonstrated by lower QSM variation in the gray matter and higher QSM image quality score, was also observed in healthy subjects and in patients with hemorrhages, stroke and multiple sclerosis. The mSMV algorithm allows reconstruction of QSMs that are equivalent to those obtained using SMV-filtered dipole inversion without eroding the volume of interest.