 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
EBHI-Seg: A Novel Enteroscope Biopsy Histopathological Haematoxylin and Eosin Image Dataset for Image Segmentation Tasks
Dec 06, 2022
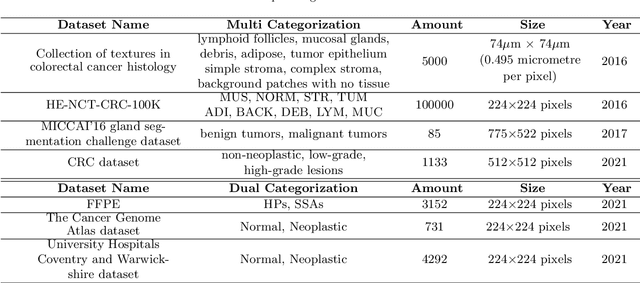
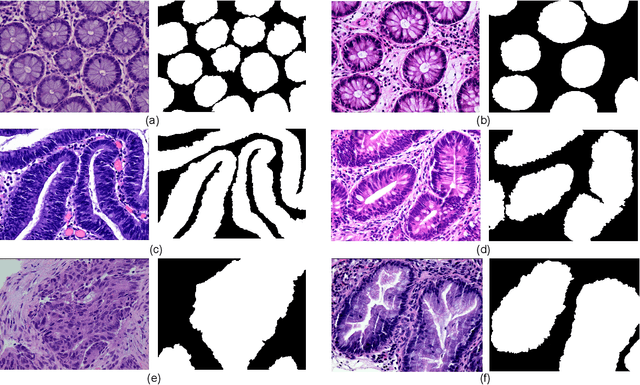
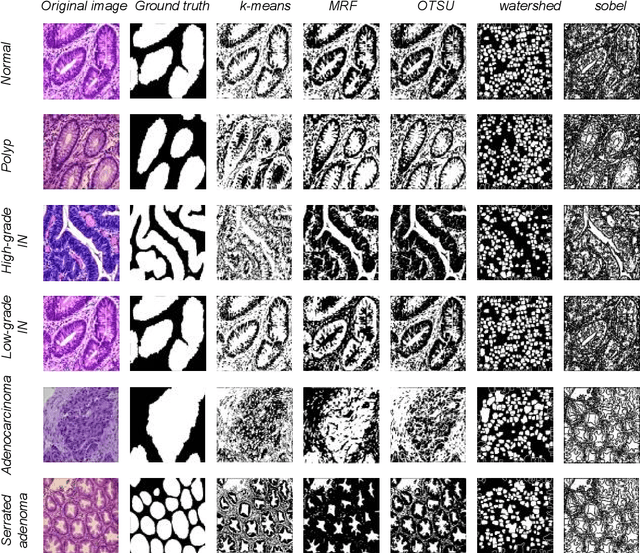
Background and Purpose: Colorectal cancer is a common fatal malignancy, the fourth most common cancer in men, and the third most common cancer in women worldwide. Timely detection of cancer in its early stages is essential for treating the disease. Currently, there is a lack of datasets for histopathological image segmentation of rectal cancer, which often hampers the assessment accuracy when computer technology is used to aid in diagnosis. Methods: This present study provided a new publicly available Enteroscope Biopsy Histopathological Hematoxylin and Eosin Image Dataset for Image Segmentation Tasks (EBHI-Seg). To demonstrate the validity and extensiveness of EBHI-Seg, the experimental results for EBHI-Seg are evaluated using classical machine learning methods and deep learning methods. Results: The experimental results showed that deep learning methods had a better image segmentation performance when utilizing EBHI-Seg. The maximum accuracy of the Dice evaluation metric for the classical machine learning method is 0.948, while the Dice evaluation metric for the deep learning method is 0.965. Conclusion: This publicly available dataset contained 5,170 images of six types of tumor differentiation stages and the corresponding ground truth images. The dataset can provide researchers with new segmentation algorithms for medical diagnosis of colorectal cancer, which can be used in the clinical setting to help doctors and patients.
Cross-Modal Similarity-Based Curriculum Learning for Image Captioning
Dec 14, 2022
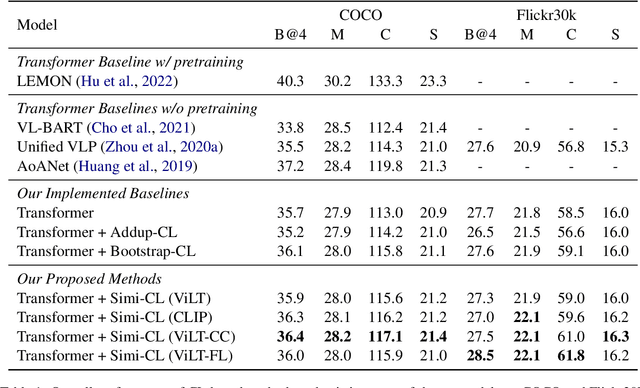
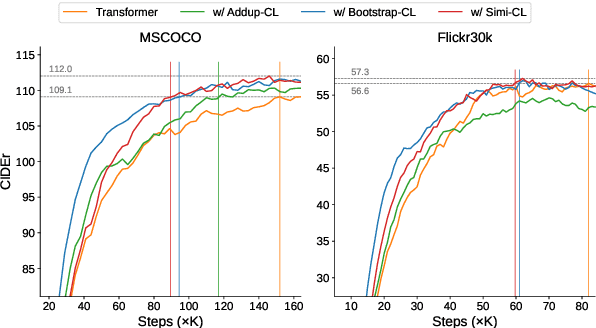
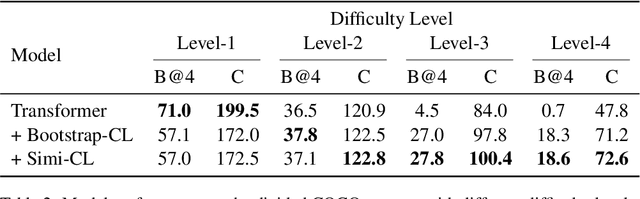
Image captioning models require the high-level generalization ability to describe the contents of various images in words. Most existing approaches treat the image-caption pairs equally in their training without considering the differences in their learning difficulties. Several image captioning approaches introduce curriculum learning methods that present training data with increasing levels of difficulty. However, their difficulty measurements are either based on domain-specific features or prior model training. In this paper, we propose a simple yet efficient difficulty measurement for image captioning using cross-modal similarity calculated by a pretrained vision-language model. Experiments on the COCO and Flickr30k datasets show that our proposed approach achieves superior performance and competitive convergence speed to baselines without requiring heuristics or incurring additional training costs. Moreover, the higher model performance on difficult examples and unseen data also demonstrates the generalization ability.
Approaching Test Time Augmentation in the Context of Uncertainty Calibration for Deep Neural Networks
Apr 11, 2023
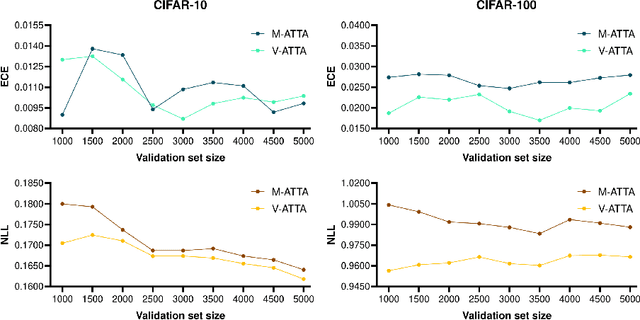
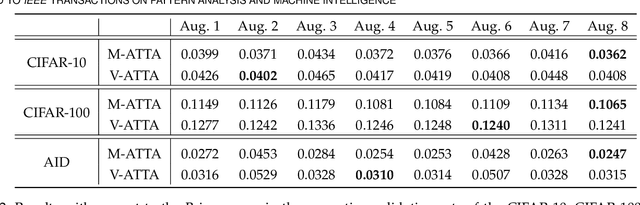
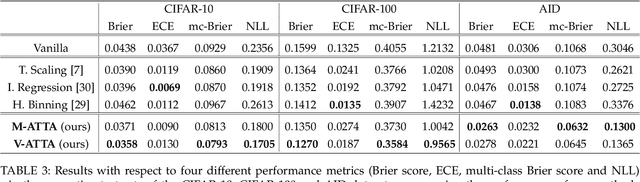
With the rise of Deep Neural Networks, machine learning systems are nowadays ubiquitous in a number of real-world applications, which bears the need for highly reliable models. This requires a thorough look not only at the accuracy of such systems, but also to their predictive uncertainty. Hence, we propose a novel technique (with two different variations, named M-ATTA and V-ATTA) based on test time augmentation, to improve the uncertainty calibration of deep models for image classification. Unlike other test time augmentation approaches, M/V-ATTA improves uncertainty calibration without affecting the model's accuracy, by leveraging an adaptive weighting system. We evaluate the performance of the technique with respect to different metrics of uncertainty calibration. Empirical results, obtained on CIFAR-10, CIFAR-100, as well as on the benchmark Aerial Image Dataset, indicate that the proposed approach outperforms state-of-the-art calibration techniques, while maintaining the baseline classification performance. Code for M/V-ATTA available at: https://github.com/pedrormconde/MV-ATTA.
Synthetic Data for Face Recognition: Current State and Future Prospects
May 01, 2023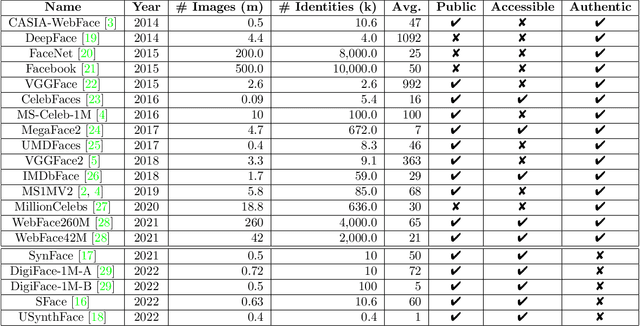
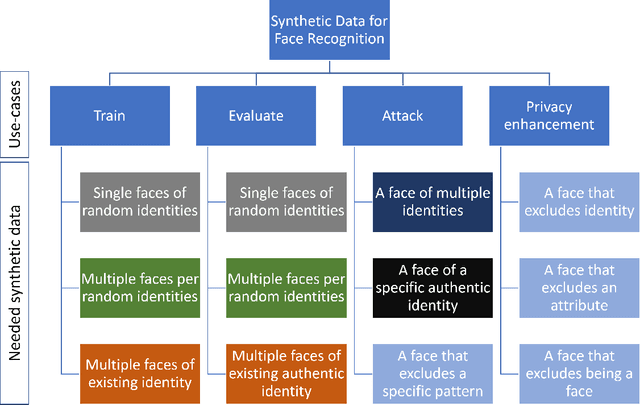
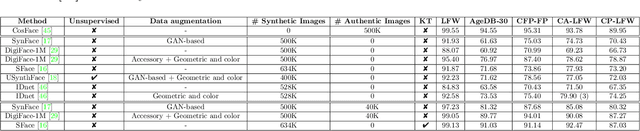

Over the past years, deep learning capabilities and the availability of large-scale training datasets advanced rapidly, leading to breakthroughs in face recognition accuracy. However, these technologies are foreseen to face a major challenge in the next years due to the legal and ethical concerns about using authentic biometric data in AI model training and evaluation along with increasingly utilizing data-hungry state-of-the-art deep learning models. With the recent advances in deep generative models and their success in generating realistic and high-resolution synthetic image data, privacy-friendly synthetic data has been recently proposed as an alternative to privacy-sensitive authentic data to overcome the challenges of using authentic data in face recognition development. This work aims at providing a clear and structured picture of the use-cases taxonomy of synthetic face data in face recognition along with the recent emerging advances of face recognition models developed on the bases of synthetic data. We also discuss the challenges facing the use of synthetic data in face recognition development and several future prospects of synthetic data in the domain of face recognition.
Racial Bias within Face Recognition: A Survey
May 01, 2023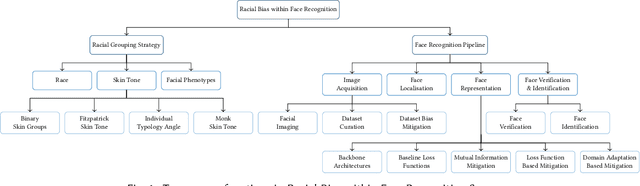
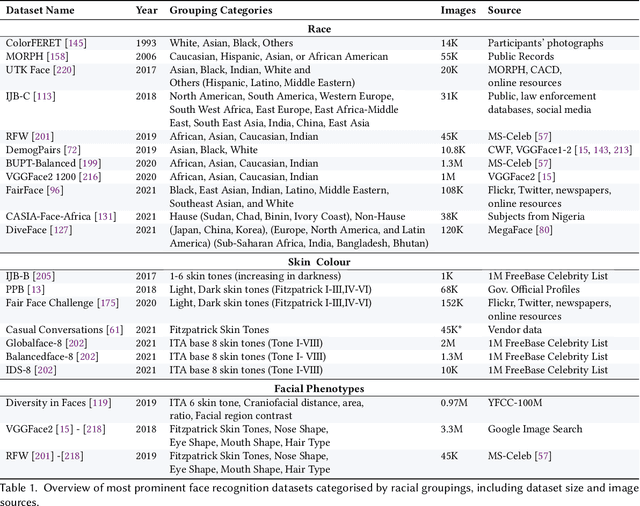

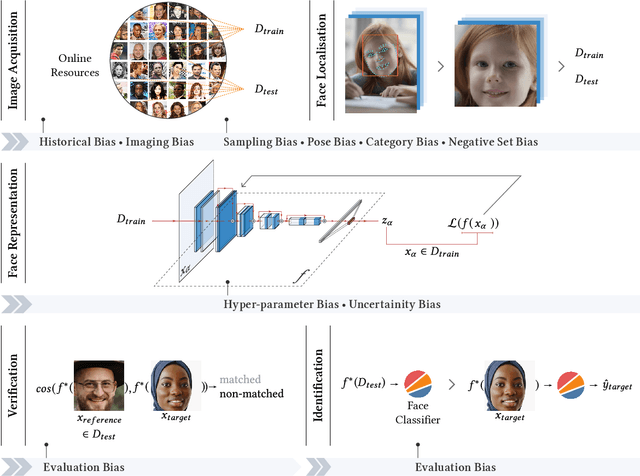
Facial recognition is one of the most academically studied and industrially developed areas within computer vision where we readily find associated applications deployed globally. This widespread adoption has uncovered significant performance variation across subjects of different racial profiles leading to focused research attention on racial bias within face recognition spanning both current causation and future potential solutions. In support, this study provides an extensive taxonomic review of research on racial bias within face recognition exploring every aspect and stage of the face recognition processing pipeline. Firstly, we discuss the problem definition of racial bias, starting with race definition, grouping strategies, and the societal implications of using race or race-related groupings. Secondly, we divide the common face recognition processing pipeline into four stages: image acquisition, face localisation, face representation, face verification and identification, and review the relevant corresponding literature associated with each stage. The overall aim is to provide comprehensive coverage of the racial bias problem with respect to each and every stage of the face recognition processing pipeline whilst also highlighting the potential pitfalls and limitations of contemporary mitigation strategies that need to be considered within future research endeavours or commercial applications alike.
Fully automatic mitral valve 4D shape extraction using probability maps
May 01, 2023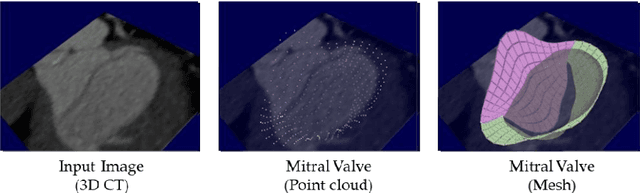
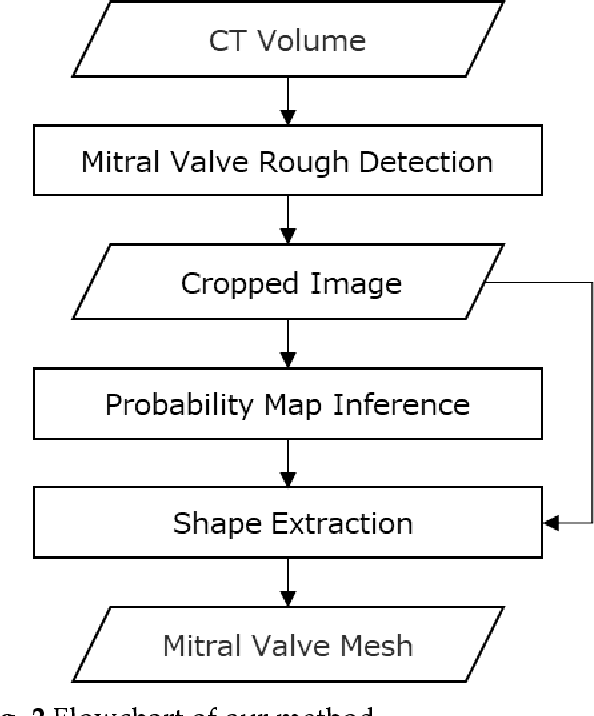
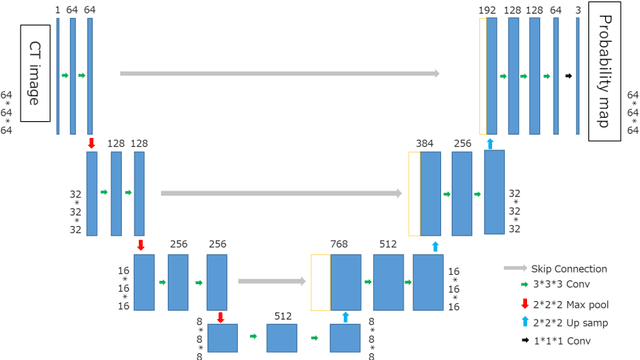
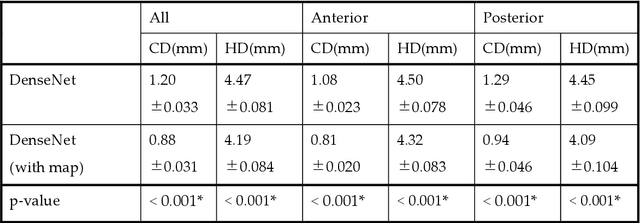
Accurate extraction of mitral valve shape from clinical tomographic images acquired in patients has proven useful for planning surgical and interventional mitral valve treatments. However, manual extraction of the mitral valve shape is laborious, and the existing automatic extraction methods have not been sufficiently accurate. In this paper, we propose a fully automated method of extracting mitral valve shape from computed tomography (CT) images for the all phases of the cardiac cycle. This method extracts the mitral valve shape based on DenseNet using both the original CT image and the existence probability maps of the mitral valve area inferred by U-Net as input. A total of 1585 CT images from 204 patients with various cardiac diseases including mitral regurgitation (MR) were collected and manually annotated for mitral valve region. The proposed method was trained and evaluated by 10-fold cross validation using the collected data and was compared with the method without the existence probability maps. The mean error of shape extraction error in the proposed method is 0.88 mm, which is an improvement of 0.32 mm compared with the method without the existence probability maps.
UniTune: Text-Driven Image Editing by Fine Tuning an Image Generation Model on a Single Image
Oct 20, 2022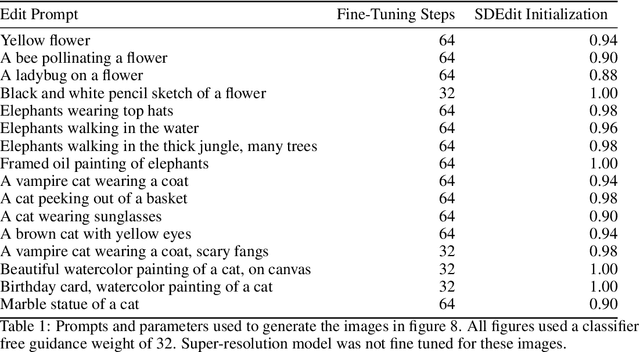
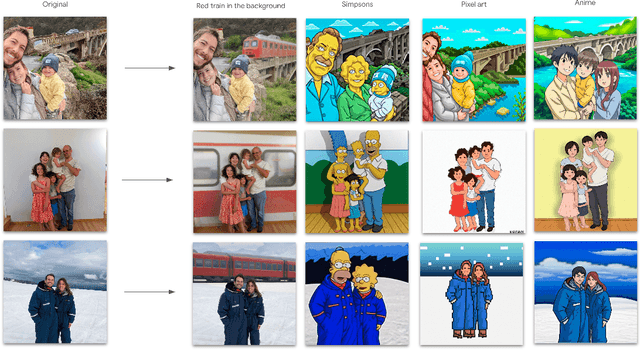


We present UniTune, a simple and novel method for general text-driven image editing. UniTune gets as input an arbitrary image and a textual edit description, and carries out the edit while maintaining high semantic and visual fidelity to the input image. UniTune uses text, an intuitive interface for art-direction, and does not require additional inputs, like masks or sketches. At the core of our method is the observation that with the right choice of parameters, we can fine-tune a large text-to-image diffusion model on a single image, encouraging the model to maintain fidelity to the input image while still allowing expressive manipulations. We used Imagen as our text-to-image model, but we expect UniTune to work with other large-scale models as well. We test our method in a range of different use cases, and demonstrate its wide applicability.
Physics-Informed Optical Kernel Regression Using Complex-valued Neural Fields
Apr 02, 2023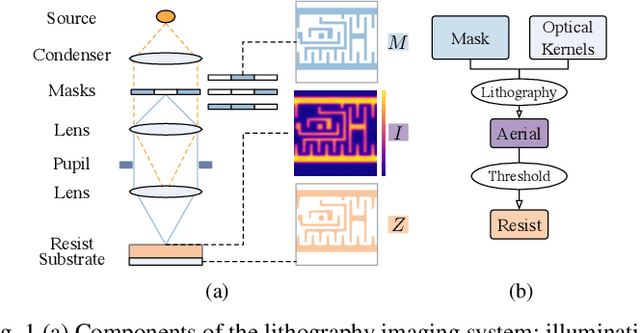
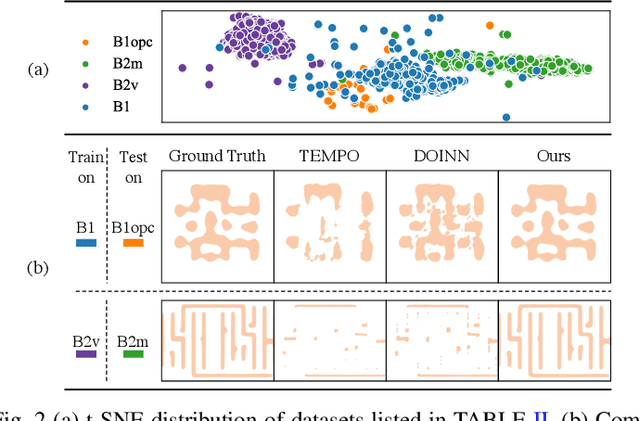
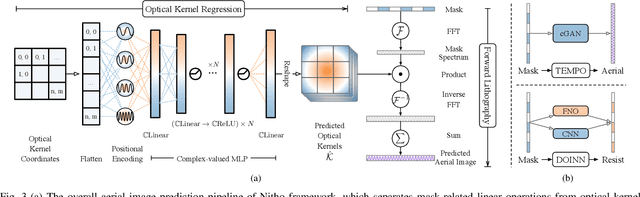
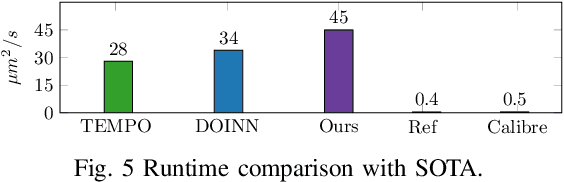
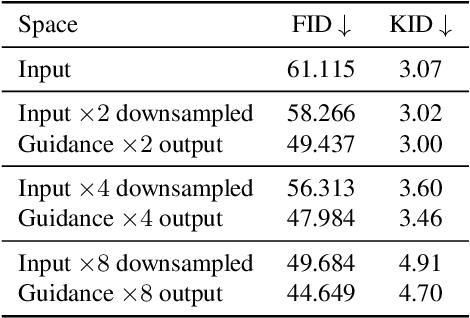
Lithography is fundamental to integrated circuit fabrication, necessitating large computation overhead. The advancement of machine learning (ML)-based lithography models alleviates the trade-offs between manufacturing process expense and capability. However, all previous methods regard the lithography system as an image-to-image black box mapping, utilizing network parameters to learn by rote mappings from massive mask-to-aerial or mask-to-resist image pairs, resulting in poor generalization capability. In this paper, we propose a new ML-based paradigm disassembling the rigorous lithographic model into non-parametric mask operations and learned optical kernels containing determinant source, pupil, and lithography information. By optimizing complex-valued neural fields to perform optical kernel regression from coordinates, our method can accurately restore lithography system using a small-scale training dataset with fewer parameters, demonstrating superior generalization capability as well. Experiments show that our framework can use 31% of parameters while achieving 69$\times$ smaller mean squared error with 1.3$\times$ higher throughput than the state-of-the-art.
Image Deblurring with Domain Generalizable Diffusion Models
Dec 04, 2022
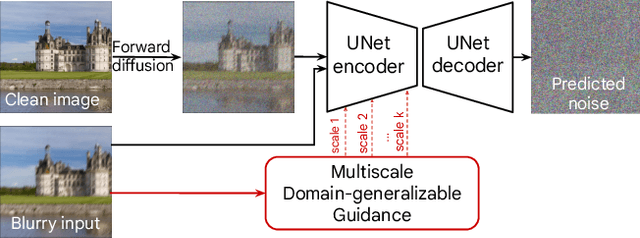
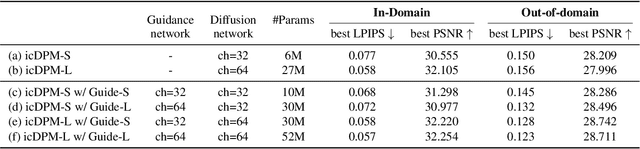
Diffusion Probabilistic Models (DPMs) have recently been employed for image deblurring. DPMs are trained via a stochastic denoising process that maps Gaussian noise to the high-quality image, conditioned on the concatenated blurry input. Despite their high-quality generated samples, image-conditioned Diffusion Probabilistic Models (icDPM) rely on synthetic pairwise training data (in-domain), with potentially unclear robustness towards real-world unseen images (out-of-domain). In this work, we investigate the generalization ability of icDPMs in deblurring, and propose a simple but effective guidance to significantly alleviate artifacts, and improve the out-of-distribution performance. Particularly, we propose to first extract a multiscale domain-generalizable representation from the input image that removes domain-specific information while preserving the underlying image structure. The representation is then added into the feature maps of the conditional diffusion model as an extra guidance that helps improving the generalization. To benchmark, we focus on out-of-distribution performance by applying a single-dataset trained model to three external and diverse test sets. The effectiveness of the proposed formulation is demonstrated by improvements over the standard icDPM, as well as state-of-the-art performance on perceptual quality and competitive distortion metrics compared to existing methods.
A Domain Decomposition-Based CNN-DNN Architecture for Model Parallel Training Applied to Image Recognition Problems
Feb 13, 2023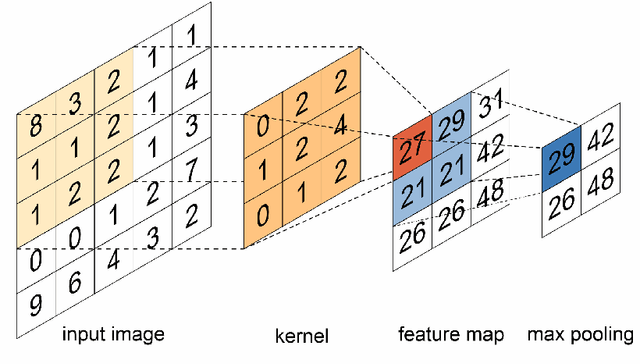
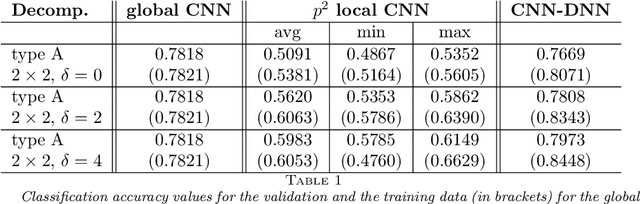
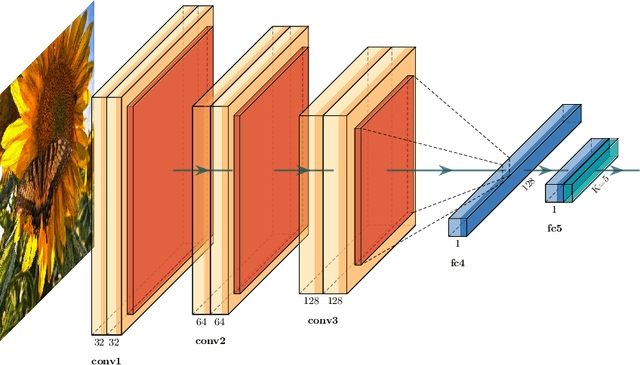
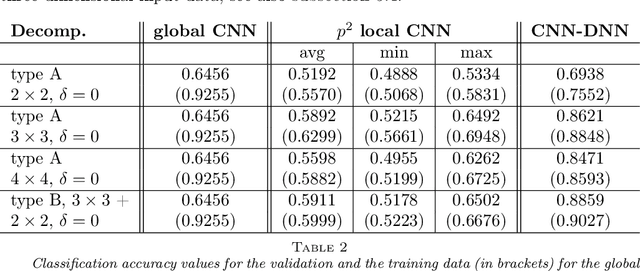
Deep neural networks (DNNs) and, in particular, convolutional neural networks (CNNs) have brought significant advances in a wide range of modern computer application problems. However, the increasing availability of large amounts of datasets as well as the increasing available computational power of modern computers lead to a steady growth in the complexity and size of DNN and CNN models, and thus, to longer training times. Hence, various methods and attempts have been developed to accelerate and parallelize the training of complex network architectures. In this work, a novel CNN-DNN architecture is proposed that naturally supports a model parallel training strategy and that is loosely inspired by two-level domain decomposition methods (DDM). First, local CNN models, that is, subnetworks, are defined that operate on overlapping or nonoverlapping parts of the input data, for example, sub-images. The subnetworks can be trained completely in parallel. Each subnetwork outputs a local decision for the given machine learning problem which is exclusively based on the respective local input data. Subsequently, an additional DNN model is trained which evaluates the local decisions of the local subnetworks and generates a final, global decision. With respect to the analogy to DDM, the DNN can be interpreted as a coarse problem and hence, the new approach can be interpreted as a two-level domain decomposition. In this paper, solely image classification problems using CNNs are considered. Experimental results for different 2D image classification problems are provided as well as a face recognition problem, and a classification problem for 3D computer tomography (CT) scans. The results show that the proposed approach can significantly accelerate the required training time compared to the global model and, additionally, can also help to improve the accuracy of the underlying classification problem.