 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improved Multimodal Fusion for Small Datasets with Auxiliary Supervision
Apr 01, 2023
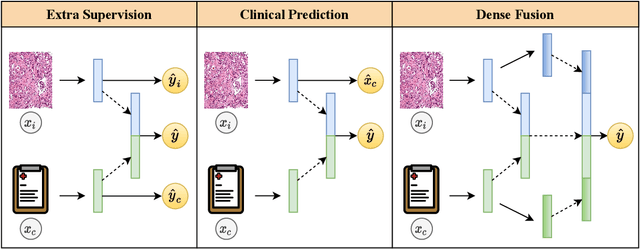
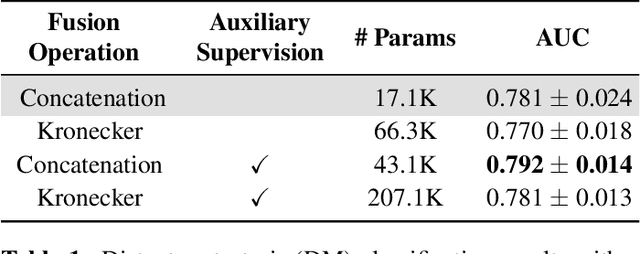
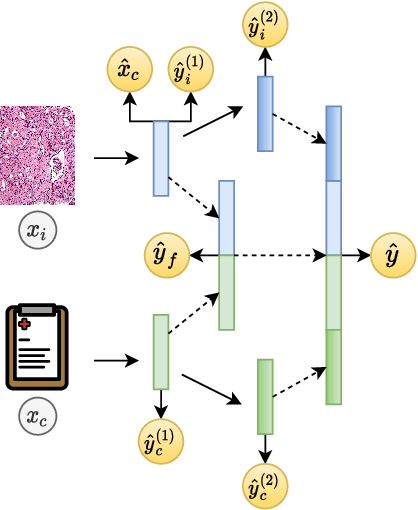
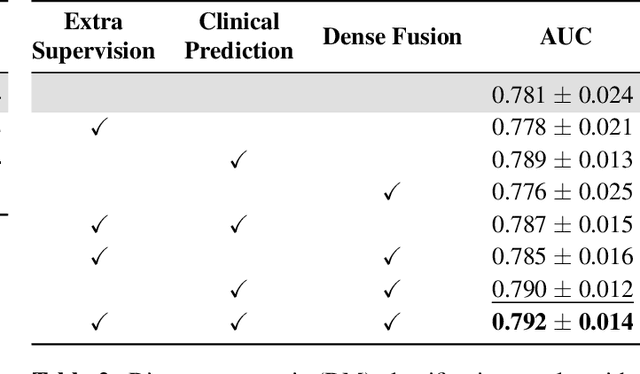
Prostate cancer is one of the leading causes of cancer-related death in men worldwide. Like many cancers, diagnosis involves expert integration of heterogeneous patient information such as imaging, clinical risk factors, and more. For this reason, there have been many recent efforts toward deep multimodal fusion of image and non-image data for clinical decision tasks. Many of these studies propose methods to fuse learned features from each patient modality, providing significant downstream improvements with techniques like cross-modal attention gating, Kronecker product fusion, orthogonality regularization, and more. While these enhanced fusion operations can improve upon feature concatenation, they often come with an extremely high learning capacity, meaning they are likely to overfit when applied even to small or low-dimensional datasets. Rather than designing a highly expressive fusion operation, we propose three simple methods for improved multimodal fusion with small datasets that aid optimization by generating auxiliary sources of supervision during training: extra supervision, clinical prediction, and dense fusion. We validate the proposed approaches on prostate cancer diagnosis from paired histopathology imaging and tabular clinical features. The proposed methods are straightforward to implement and can be applied to any classification task with paired image and non-image data.
Accessible Instruction-Following Agent
May 08, 2023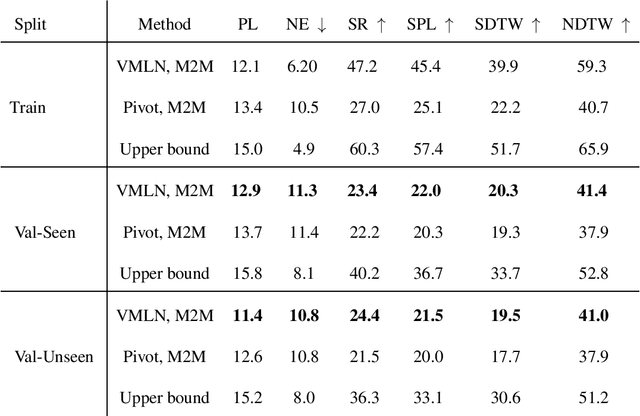
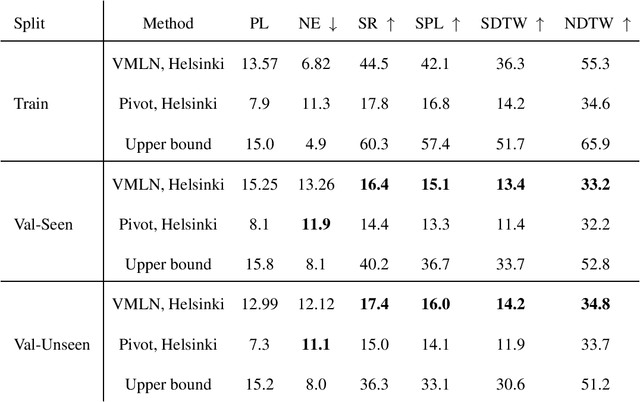
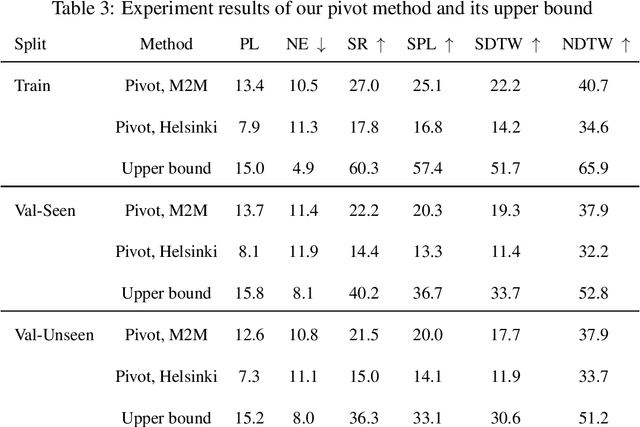
Humans can collaborate and complete tasks based on visual signals and instruction from the environment. Training such a robot is difficult especially due to the understanding of the instruction and the complicated environment. Previous instruction-following agents are biased to English-centric corpus, making it unrealizable to be applied to users that use multiple languages or even low-resource languages. Nevertheless, the instruction-following agents are pre-trained in a mode that assumes the user can observe the environment, which limits its accessibility. In this work, we're trying to generalize the success of instruction-following agents to non-English languages with little corpus resources, and improve its intractability and accessibility. We introduce UVLN (Universal Vision-Language Navigation), a novel machine-translation instructional augmented framework for cross-lingual vision-language navigation, with a novel composition of state-of-the-art large language model (GPT3) with the image caption model (BLIP). We first collect a multilanguage vision-language navigation dataset via machine translation. Then we extend the standard VLN training objectives to a multilingual setting via a cross-lingual language encoder. The alignment between different languages is captured through a shared vision and action context via a cross-modal transformer, which encodes the inputs of language instruction, visual observation, and action decision sequences. To improve the intractability, we connect our agent with the large language model that informs the situation and current state to the user and also explains the action decisions. Experiments over Room Across Room Dataset prove the effectiveness of our approach. And the qualitative results show the promising intractability and accessibility of our instruction-following agent.
Class adaptive threshold and negative class guided noisy annotation robust Facial Expression Recognition
May 03, 2023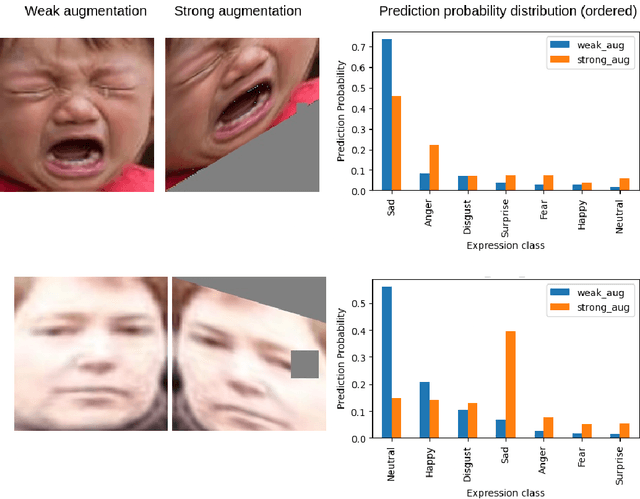

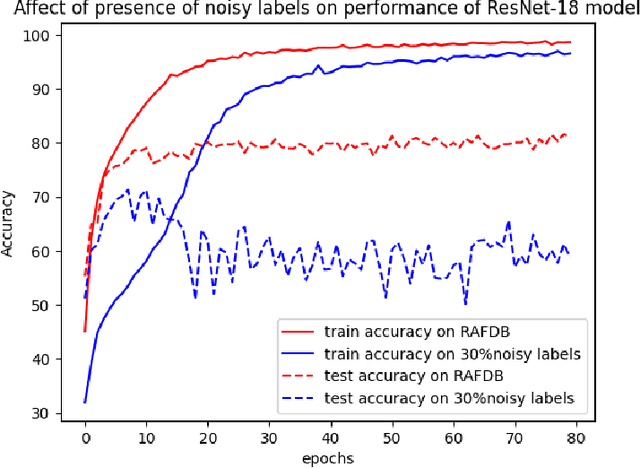

The hindering problem in facial expression recognition (FER) is the presence of inaccurate annotations referred to as noisy annotations in the datasets. These noisy annotations are present in the datasets inherently because the labeling is subjective to the annotator, clarity of the image, etc. Recent works use sample selection methods to solve this noisy annotation problem in FER. In our work, we use a dynamic adaptive threshold to separate confident samples from non-confident ones so that our learning won't be hampered due to non-confident samples. Instead of discarding the non-confident samples, we impose consistency in the negative classes of those non-confident samples to guide the model to learn better in the positive class. Since FER datasets usually come with 7 or 8 classes, we can correctly guess a negative class by 85% probability even by choosing randomly. By learning "which class a sample doesn't belong to", the model can learn "which class it belongs to" in a better manner. We demonstrate proposed framework's effectiveness using quantitative as well as qualitative results. Our method performs better than the baseline by a margin of 4% to 28% on RAFDB and 3.3% to 31.4% on FERPlus for various levels of synthetic noisy labels in the aforementioned datasets.
Efficient CNN-based Super Resolution Algorithms for mmWave Mobile Radar Imaging
May 03, 2023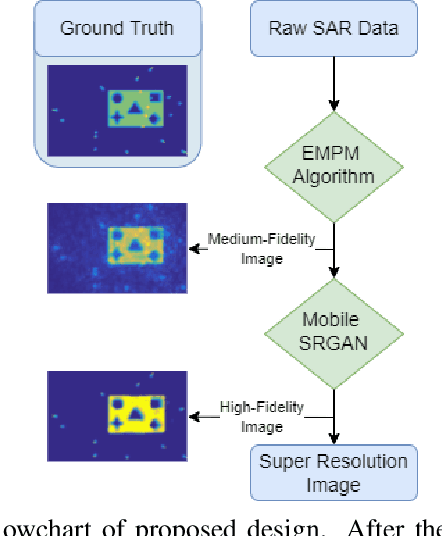

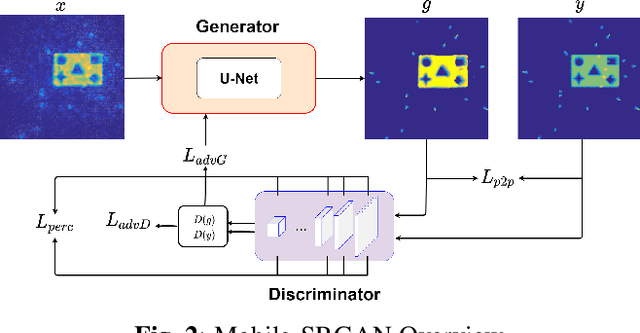
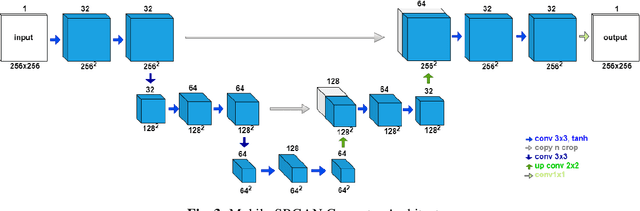
In this paper, we introduce an innovative super resolution approach to emerging modes of near-field synthetic aperture radar (SAR) imaging. Recent research extends convolutional neural network (CNN) architectures from the optical to the electromagnetic domain to achieve super resolution on images generated from radar signaling. Specifically, near-field synthetic aperture radar (SAR) imaging, a method for generating high-resolution images by scanning a radar across space to create a synthetic aperture, is of interest due to its high-fidelity spatial sensing capability, low cost devices, and large application space. Since SAR imaging requires large aperture sizes to achieve high resolution, super-resolution algorithms are valuable for many applications. Freehand smartphone SAR, an emerging sensing modality, requires irregular SAR apertures in the near-field and computation on mobile devices. Achieving efficient high-resolution SAR images from irregularly sampled data collected by freehand motion of a smartphone is a challenging task. In this paper, we propose a novel CNN architecture to achieve SAR image super-resolution for mobile applications by employing state-of-the-art SAR processing and deep learning techniques. The proposed algorithm is verified via simulation and an empirical study. Our algorithm demonstrates high-efficiency and high-resolution radar imaging for near-field scenarios with irregular scanning geometries.
Segment Anything Model (SAM) Enhanced Pseudo Labels for Weakly Supervised Semantic Segmentation
May 09, 2023
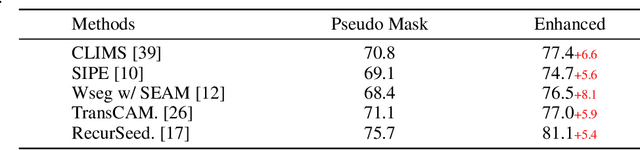

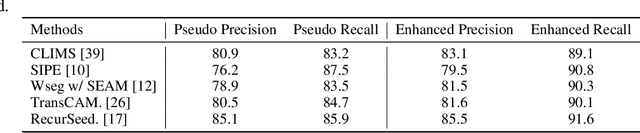
Weakly Supervised Semantic Segmentation (WSSS) with only image-level supervision has garnered increasing attention due to its low annotation cost compared to pixel-level annotation. Most existing methods rely on Class Activation Maps (CAM) to generate pixel-level pseudo labels for supervised training. However, it is well known that CAM often suffers from partial activation -- activating the most discriminative part instead of the entire object area, and false activation -- unnecessarily activating the background around the object. In this study, we introduce a simple yet effective approach to address these limitations by harnessing the recently released Segment Anything Model (SAM) to generate higher-quality pseudo labels with CAM. SAM is a segmentation foundation model that demonstrates strong zero-shot ability in partitioning images into segments but lacks semantic labels for these regions. To circumvent this, we employ pseudo labels for a specific class as the signal to select the most relevant masks and label them to generate the refined pseudo labels for this class. The segments generated by SAM are highly precise, leading to substantial improvements in partial and false activation. Moreover, existing post-processing modules for producing pseudo labels, such as AffinityNet, are often computationally heavy, with a significantly long training time. Surprisingly, we discovered that using the initial CAM with SAM can achieve on-par performance as the post-processed pseudo label generated from these modules with much less computational cost. Our approach is highly versatile and capable of seamless integration into existing WSSS models without modification to base networks or pipelines. Despite its simplicity, our approach improves the mean Intersection over Union (mIoU) of pseudo labels from five state-of-the-art WSSS methods by 6.2\% on average on the PASCAL VOC 2012 dataset.
Exploring the Zero-Shot Capabilities of the Segment Anything Model (SAM) in 2D Medical Imaging: A Comprehensive Evaluation and Practical Guideline
Apr 28, 2023
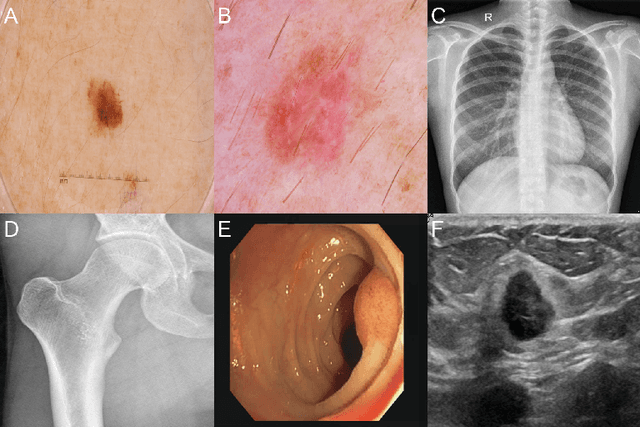
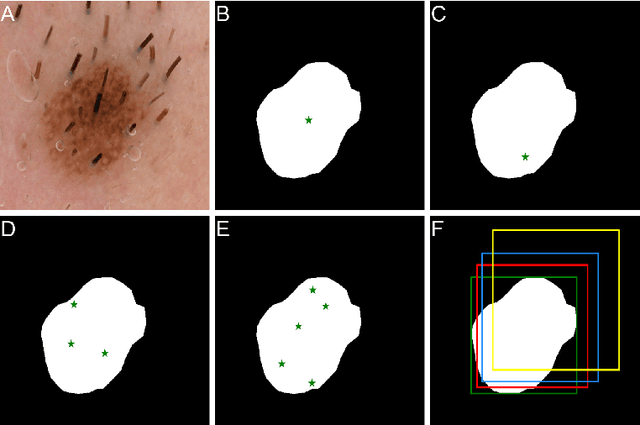
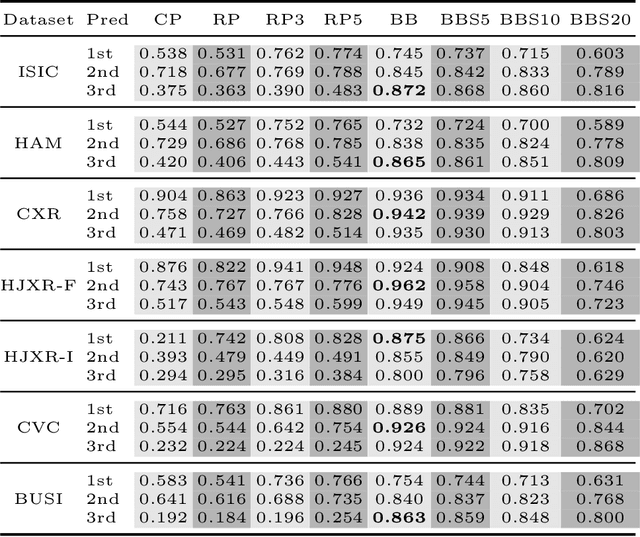
Segmentation in medical imaging plays a crucial role in diagnosing, monitoring, and treating various diseases and conditions. The current landscape of segmentation in the medical domain is dominated by numerous specialized deep learning models fine-tuned for each segmentation task and image modality. Recently, the Segment Anything Model (SAM), a new segmentation model, was introduced. SAM utilizes the ViT neural architecture and leverages a vast training dataset to segment almost any object. However, its generalizability to the medical domain remains unexplored. In this study, we assess the zero-shot capabilities of SAM 2D in medical imaging using eight different prompt strategies across six datasets from four imaging modalities: X-ray, ultrasound, dermatoscopy, and colonoscopy. Our results demonstrate that SAM's zero-shot performance is comparable and, in certain cases, superior to the current state-of-the-art. Based on our findings, we propose a practical guideline that requires minimal interaction and yields robust results in all evaluated contexts.
DD-CISENet: Dual-Domain Cross-Iteration Squeeze and Excitation Network for Accelerated MRI Reconstruction
Apr 28, 2023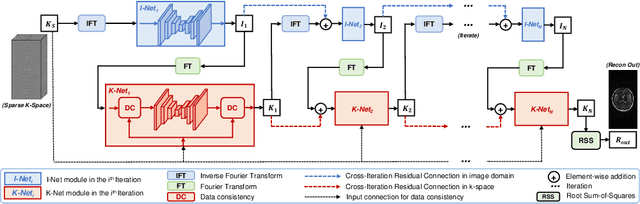
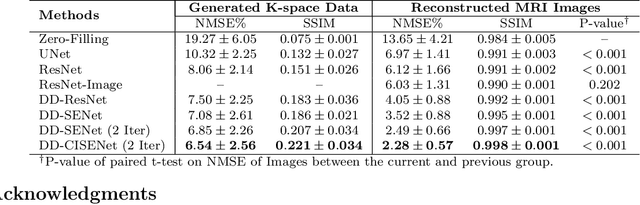
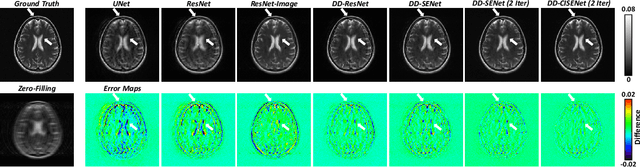
Magnetic resonance imaging (MRI) is widely employed for diagnostic tests in neurology. However, the utility of MRI is largely limited by its long acquisition time. Acquiring fewer k-space data in a sparse manner is a potential solution to reducing the acquisition time, but it can lead to severe aliasing reconstruction artifacts. In this paper, we present a novel Dual-Domain Cross-Iteration Squeeze and Excitation Network (DD-CISENet) for accelerated sparse MRI reconstruction. The information of k-spaces and MRI images can be iteratively fused and maintained using the Cross-Iteration Residual connection (CIR) structures. This study included 720 multi-coil brain MRI cases adopted from the open-source fastMRI Dataset. Results showed that the average reconstruction error by DD-CISENet was 2.28 $\pm$ 0.57%, which outperformed existing deep learning methods including image-domain prediction (6.03 $\pm$ 1.31, p < 0.001), k-space synthesis (6.12 $\pm$ 1.66, p < 0.001), and dual-domain feature fusion approaches (4.05 $\pm$ 0.88, p < 0.001).
Exploring Discrete Diffusion Models for Image Captioning
Dec 09, 2022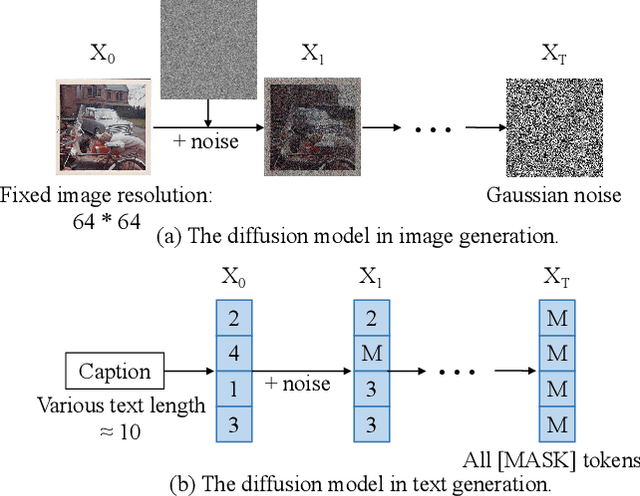

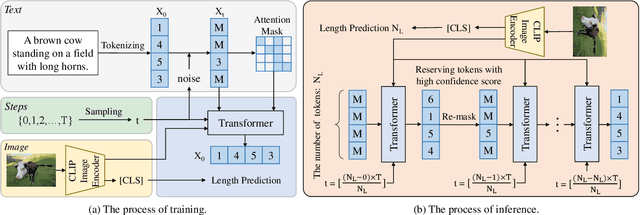
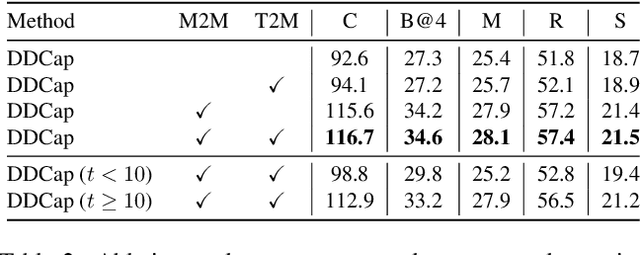
The image captioning task is typically realized by an auto-regressive method that decodes the text tokens one by one. We present a diffusion-based captioning model, dubbed the name DDCap, to allow more decoding flexibility. Unlike image generation, where the output is continuous and redundant with a fixed length, texts in image captions are categorical and short with varied lengths. Therefore, naively applying the discrete diffusion model to text decoding does not work well, as shown in our experiments. To address the performance gap, we propose several key techniques including best-first inference, concentrated attention mask, text length prediction, and image-free training. On COCO without additional caption pre-training, it achieves a CIDEr score of 117.8, which is +5.0 higher than the auto-regressive baseline with the same architecture in the controlled setting. It also performs +26.8 higher CIDEr score than the auto-regressive baseline (230.3 v.s.203.5) on a caption infilling task. With 4M vision-language pre-training images and the base-sized model, we reach a CIDEr score of 125.1 on COCO, which is competitive to the best well-developed auto-regressive frameworks. The code is available at https://github.com/buxiangzhiren/DDCap.
Improving Segmentation of Objects with Varying Sizes in Biomedical Images using Instance-wise and Center-of-Instance Segmentation Loss Function
Apr 13, 2023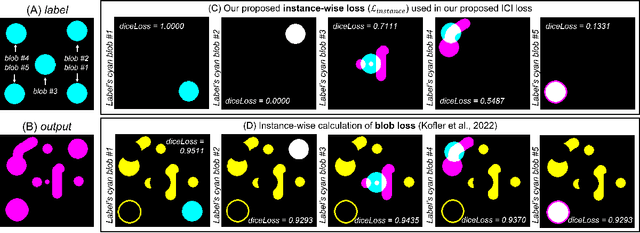
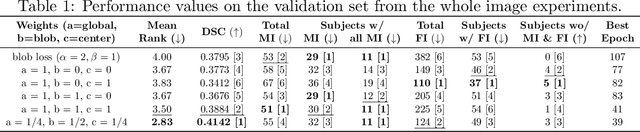
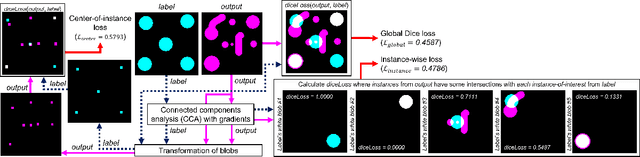
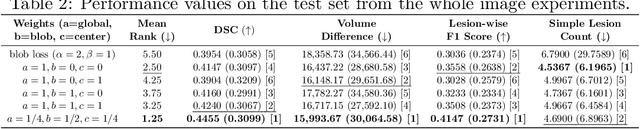
In this paper, we propose a novel two-component loss for biomedical image segmentation tasks called the Instance-wise and Center-of-Instance (ICI) loss, a loss function that addresses the instance imbalance problem commonly encountered when using pixel-wise loss functions such as the Dice loss. The Instance-wise component improves the detection of small instances or ``blobs" in image datasets with both large and small instances. The Center-of-Instance component improves the overall detection accuracy. We compared the ICI loss with two existing losses, the Dice loss and the blob loss, in the task of stroke lesion segmentation using the ATLAS R2.0 challenge dataset from MICCAI 2022. Compared to the other losses, the ICI loss provided a better balanced segmentation, and significantly outperformed the Dice loss with an improvement of $1.7-3.7\%$ and the blob loss by $0.6-5.0\%$ in terms of the Dice similarity coefficient on both validation and test set, suggesting that the ICI loss is a potential solution to the instance imbalance problem.
Incremental Generalized Category Discovery
Apr 27, 2023We explore the problem of Incremental Generalized Category Discovery (IGCD). This is a challenging category incremental learning setting where the goal is to develop models that can correctly categorize images from previously seen categories, in addition to discovering novel ones. Learning is performed over a series of time steps where the model obtains new labeled and unlabeled data, and discards old data, at each iteration. The difficulty of the problem is compounded in our generalized setting as the unlabeled data can contain images from categories that may or may not have been observed before. We present a new method for IGCD which combines non-parametric categorization with efficient image sampling to mitigate catastrophic forgetting. To quantify performance, we propose a new benchmark dataset named iNatIGCD that is motivated by a real-world fine-grained visual categorization task. In our experiments we outperform existing related methods