 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
KBody: Towards general, robust, and aligned monocular whole-body estimation
Apr 25, 2023


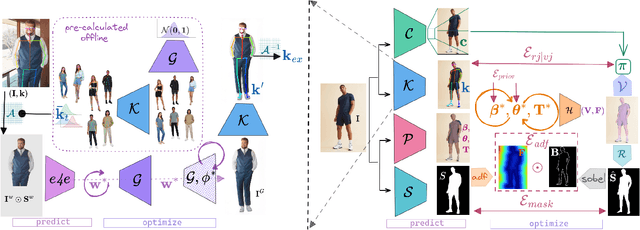
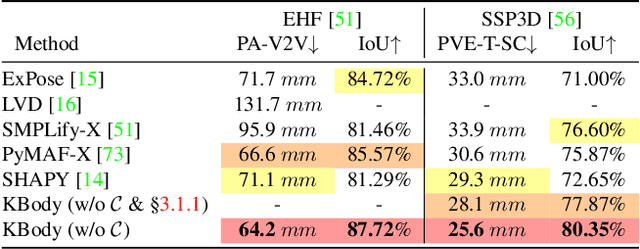
KBody is a method for fitting a low-dimensional body model to an image. It follows a predict-and-optimize approach, relying on data-driven model estimates for the constraints that will be used to solve for the body's parameters. Acknowledging the importance of high quality correspondences, it leverages ``virtual joints" to improve fitting performance, disentangles the optimization between the pose and shape parameters, and integrates asymmetric distance fields to strike a balance in terms of pose and shape capturing capacity, as well as pixel alignment. We also show that generative model inversion offers a strong appearance prior that can be used to complete partial human images and used as a building block for generalized and robust monocular body fitting. Project page: https://klothed.github.io/KBody.
* 11 pages, 6 figures, 58 supplemental figures, project page https://klothed.github.io/KBody , also posted at with high-res images http://graphics.berkeley.edu/papers/Zioulis-KBT-2023-06
Image Super-Resolution using Efficient Striped Window Transformer
Jan 24, 2023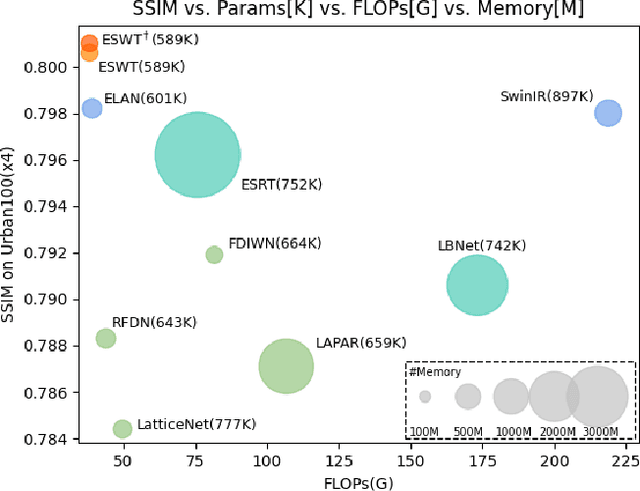
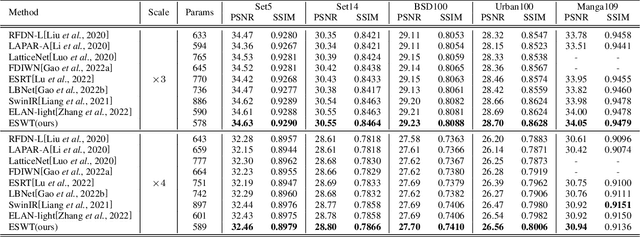
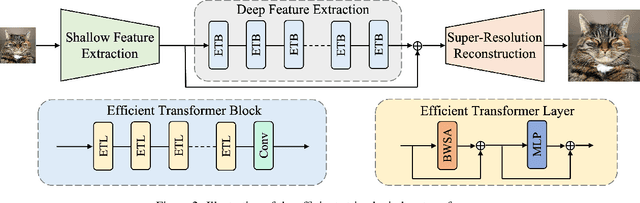
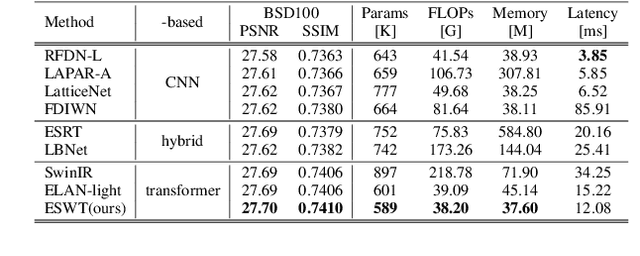
Recently, transformer-based methods have made impressive progress in single-image super-resolu-tion (SR). However, these methods are difficult to apply to lightweight SR (LSR) due to the challenge of balancing model performance and complexity. In this paper, we propose an efficient striped window transformer (ESWT). ESWT consists of efficient transformation layers (ETLs), allowing a clean structure and avoiding redundant operations. Moreover, we designed a striped window mechanism to obtain a more efficient ESWT in modeling long-term dependencies. To further exploit the potential of the transformer, we propose a novel flexible window training strategy. Without any additional cost, this strategy can further improve the performance of ESWT. Extensive experiments show that the proposed method outperforms state-of-the-art transformer-based LSR methods with fewer parameters, faster inference, smaller FLOPs, and less memory consumption, achieving a better trade-off between model performance and complexity.
VA-DepthNet: A Variational Approach to Single Image Depth Prediction
Feb 13, 2023
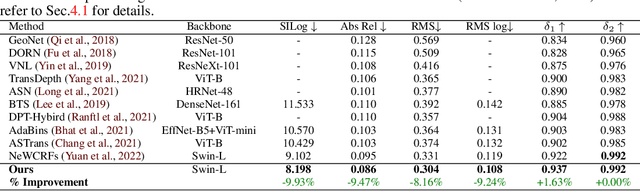
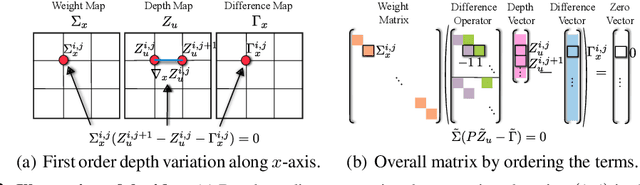

We introduce VA-DepthNet, a simple, effective, and accurate deep neural network approach for the single-image depth prediction (SIDP) problem. The proposed approach advocates using classical first-order variational constraints for this problem. While state-of-the-art deep neural network methods for SIDP learn the scene depth from images in a supervised setting, they often overlook the invaluable invariances and priors in the rigid scene space, such as the regularity of the scene. The paper's main contribution is to reveal the benefit of classical and well-founded variational constraints in the neural network design for the SIDP task. It is shown that imposing first-order variational constraints in the scene space together with popular encoder-decoder-based network architecture design provides excellent results for the supervised SIDP task. The imposed first-order variational constraint makes the network aware of the depth gradient in the scene space, i.e., regularity. The paper demonstrates the usefulness of the proposed approach via extensive evaluation and ablation analysis over several benchmark datasets, such as KITTI, NYU Depth V2, and SUN RGB-D. The VA-DepthNet at test time shows considerable improvements in depth prediction accuracy compared to the prior art and is accurate also at high-frequency regions in the scene space. At the time of writing this paper, our method -- labeled as VA-DepthNet, when tested on the KITTI depth-prediction evaluation set benchmarks, shows state-of-the-art results, and is the top-performing published approach.
Interweaved Graph and Attention Network for 3D Human Pose Estimation
Apr 27, 2023
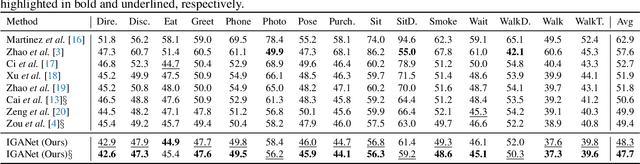
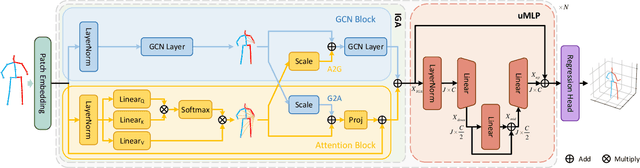

Despite substantial progress in 3D human pose estimation from a single-view image, prior works rarely explore global and local correlations, leading to insufficient learning of human skeleton representations. To address this issue, we propose a novel Interweaved Graph and Attention Network (IGANet) that allows bidirectional communications between graph convolutional networks (GCNs) and attentions. Specifically, we introduce an IGA module, where attentions are provided with local information from GCNs and GCNs are injected with global information from attentions. Additionally, we design a simple yet effective U-shaped multi-layer perceptron (uMLP), which can capture multi-granularity information for body joints. Extensive experiments on two popular benchmark datasets (i.e. Human3.6M and MPI-INF-3DHP) are conducted to evaluate our proposed method.The results show that IGANet achieves state-of-the-art performance on both datasets. Code is available at https://github.com/xiu-cs/IGANet.
Deep-Learning-based Vasculature Extraction for Single-Scan Optical Coherence Tomography Angiography
Apr 20, 2023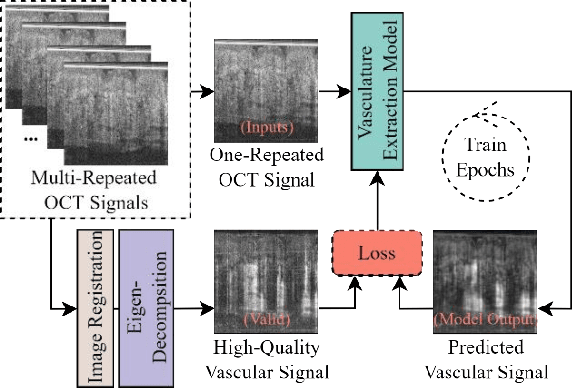
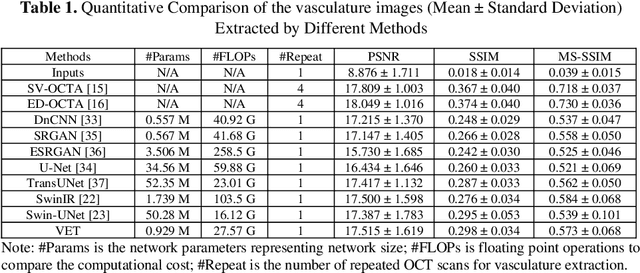
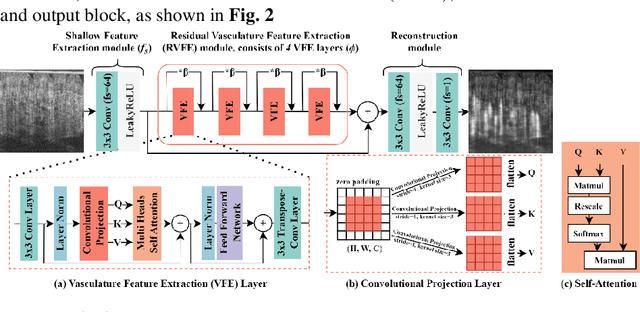
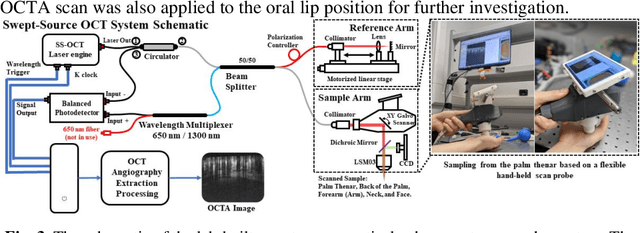
Optical coherence tomography angiography (OCTA) is a non-invasive imaging modality that extends the functionality of OCT by extracting moving red blood cell signals from surrounding static biological tissues. OCTA has emerged as a valuable tool for analyzing skin microvasculature, enabling more accurate diagnosis and treatment monitoring. Most existing OCTA extraction algorithms, such as speckle variance (SV)- and eigen-decomposition (ED)-OCTA, implement a larger number of repeated (NR) OCT scans at the same position to produce high-quality angiography images. However, a higher NR requires a longer data acquisition time, leading to more unpredictable motion artifacts. In this study, we propose a vasculature extraction pipeline that uses only one-repeated OCT scan to generate OCTA images. The pipeline is based on the proposed Vasculature Extraction Transformer (VET), which leverages convolutional projection to better learn the spatial relationships between image patches. In comparison to OCTA images obtained via the SV-OCTA (PSNR: 17.809) and ED-OCTA (PSNR: 18.049) using four-repeated OCT scans, OCTA images extracted by VET exhibit moderate quality (PSNR: 17.515) and higher image contrast while reducing the required data acquisition time from ~8 s to ~2 s. Based on visual observations, the proposed VET outperforms SV and ED algorithms when using neck and face OCTA data in areas that are challenging to scan. This study represents that the VET has the capacity to extract vascularture images from a fast one-repeated OCT scan, facilitating accurate diagnosis for patients.
Exploiting CNNs for Semantic Segmentation with Pascal VOC
May 05, 2023
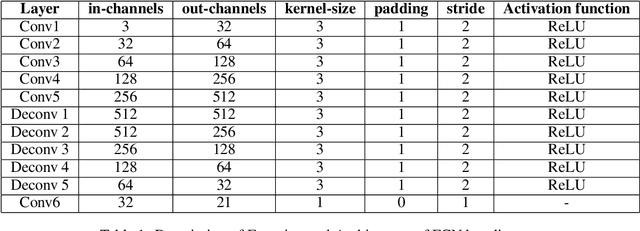
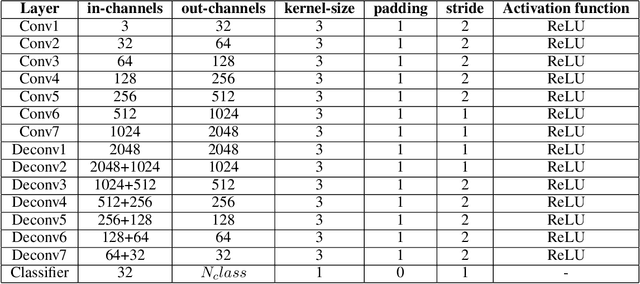
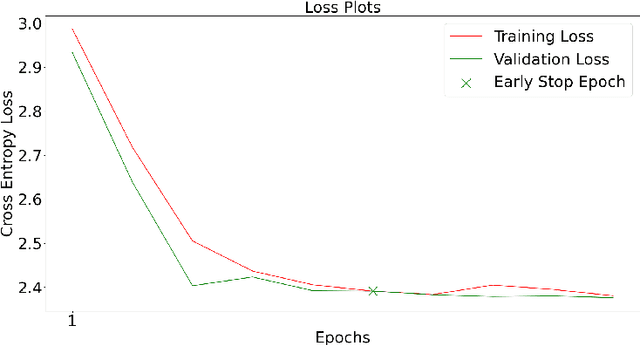
In this paper, we present a comprehensive study on semantic segmentation with the Pascal VOC dataset. Here, we have to label each pixel with a class which in turn segments the entire image based on the objects/entities present. To tackle this, we firstly use a Fully Convolution Network (FCN) baseline which gave 71.31% pixel accuracy and 0.0527 mean IoU. We analyze its performance and working and subsequently address the issues in the baseline with three improvements: a) cosine annealing learning rate scheduler(pixel accuracy: 72.86%, IoU: 0.0529), b) data augmentation(pixel accuracy: 69.88%, IoU: 0.0585) c) class imbalance weights(pixel accuracy: 68.98%, IoU: 0.0596). Apart from these changes in training pipeline, we also explore three different architectures: a) Our proposed model -- Advanced FCN (pixel accuracy: 67.20%, IoU: 0.0602) b) Transfer Learning with ResNet (Best performance) (pixel accuracy: 71.33%, IoU: 0.0926 ) c) U-Net(pixel accuracy: 72.15%, IoU: 0.0649). We observe that the improvements help in greatly improving the performance, as reflected both, in metrics and segmentation maps. Interestingly, we observe that among the improvements, dataset augmentation has the greatest contribution. Also, note that transfer learning model performs the best on the pascal dataset. We analyse the performance of these using loss, accuracy and IoU plots along with segmentation maps, which help us draw valuable insights about the working of the models.
GAANet: Ghost Auto Anchor Network for Detecting Varying Size Drones in Dark
May 05, 2023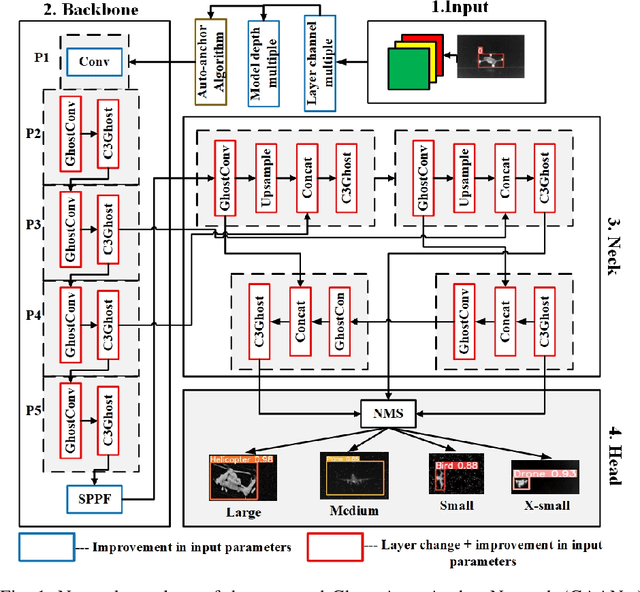

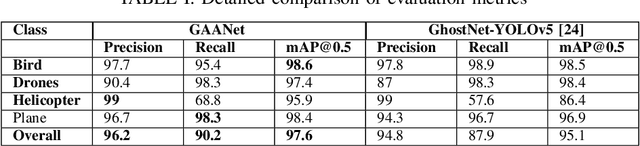
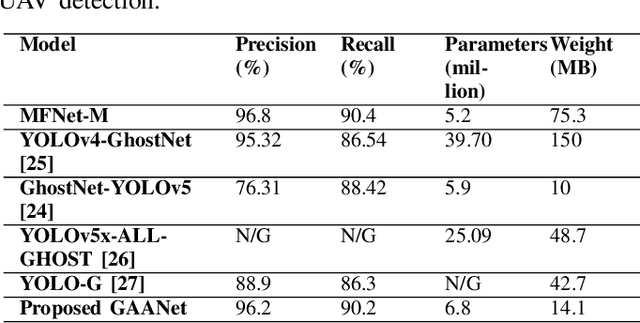
The usage of drones has tremendously increased in different sectors spanning from military to industrial applications. Despite all the benefits they offer, their misuse can lead to mishaps, and tackling them becomes more challenging particularly at night due to their small size and low visibility conditions. To overcome those limitations and improve the detection accuracy at night, we propose an object detector called Ghost Auto Anchor Network (GAANet) for infrared (IR) images. The detector uses a YOLOv5 core to address challenges in object detection for IR images, such as poor accuracy and a high false alarm rate caused by extended altitudes, poor lighting, and low image resolution. To improve performance, we implemented auto anchor calculation, modified the conventional convolution block to ghost-convolution, adjusted the input channel size, and used the AdamW optimizer. To enhance the precision of multiscale tiny object recognition, we also introduced an additional extra-small object feature extractor and detector. Experimental results in a custom IR dataset with multiple classes (birds, drones, planes, and helicopters) demonstrate that GAANet shows improvement compared to state-of-the-art detectors. In comparison to GhostNet-YOLOv5, GAANet has higher overall mean average precision (mAP@50), recall, and precision around 2.5\%, 2.3\%, and 1.4\%, respectively. The dataset and code for this paper are available as open source at https://github.com/ZeeshanKaleem/GhostAutoAnchorNet.
MProtoNet: A Case-Based Interpretable Model for Brain Tumor Classification with 3D Multi-parametric Magnetic Resonance Imaging
Apr 14, 2023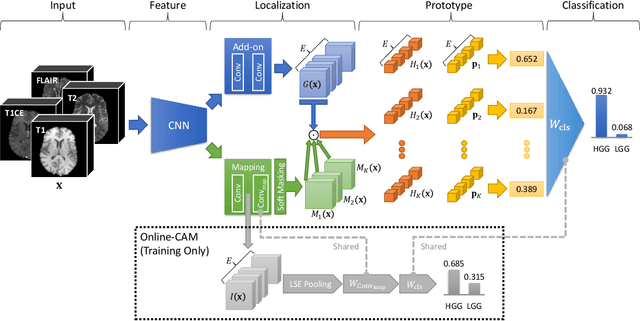
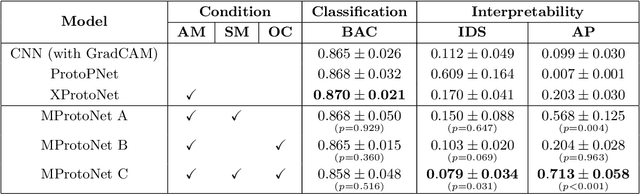
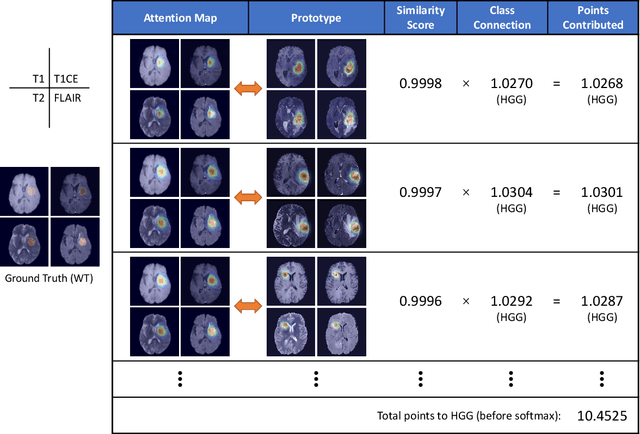
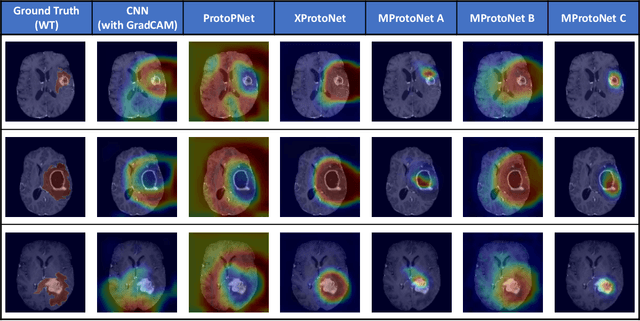
Recent applications of deep convolutional neural networks in medical imaging raise concerns about their interpretability. While most explainable deep learning applications use post hoc methods (such as GradCAM) to generate feature attribution maps, there is a new type of case-based reasoning models, namely ProtoPNet and its variants, which identify prototypes during training and compare input image patches with those prototypes. We propose the first medical prototype network (MProtoNet) to extend ProtoPNet to brain tumor classification with 3D multi-parametric magnetic resonance imaging (mpMRI) data. To address different requirements between 2D natural images and 3D mpMRIs especially in terms of localizing attention regions, a new attention module with soft masking and online-CAM loss is introduced. Soft masking helps sharpen attention maps, while online-CAM loss directly utilizes image-level labels when training the attention module. MProtoNet achieves statistically significant improvements in interpretability metrics of both correctness and localization coherence (with a best activation precision of $0.713\pm0.058$) without human-annotated labels during training, when compared with GradCAM and several ProtoPNet variants. The source code is available at https://github.com/aywi/mprotonet.
KS-GNNExplainer: Global Model Interpretation Through Instance Explanations On Histopathology images
Apr 14, 2023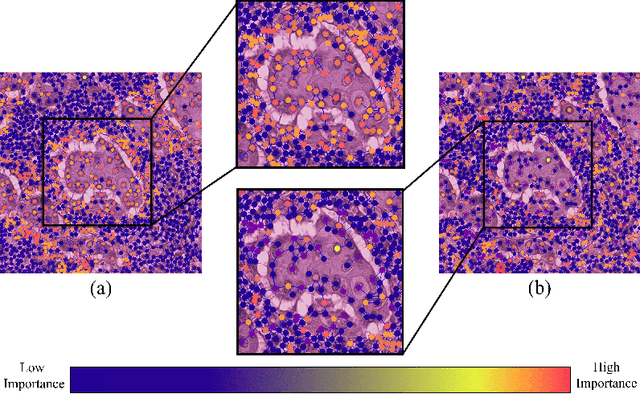

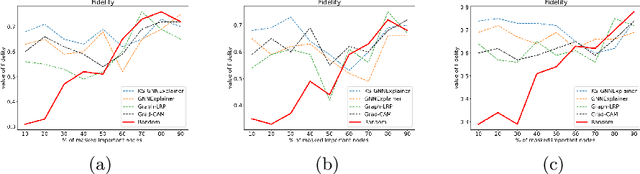
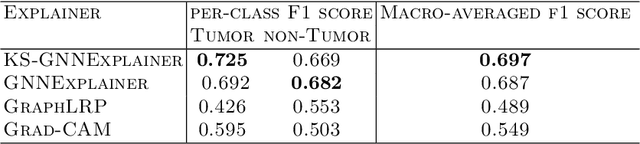
Instance-level graph neural network explainers have proven beneficial for explaining such networks on histopathology images. However, there has been few methods that provide model explanations, which are common patterns among samples within the same class. We envision that graph-based histopathological image analysis can benefit significantly from such explanations. On the other hand, current model-level explainers are based on graph generation methods that are not applicable in this domain because of no corresponding image for their generated graphs in real world. Therefore, such explanations are communicable to the experts. To follow this vision, we developed KS-GNNExplainer, the first instance-level graph neural network explainer that leverages current instance-level approaches in an effective manner to provide more informative and reliable explainable outputs, which are crucial for applied AI in the health domain. Our experiments on various datasets, and based on both quantitative and qualitative measures, demonstrate that the proposed explainer is capable of being a global pattern extractor, which is a fundamental limitation of current instance-level approaches in this domain.
Generalizable Denoising of Microscopy Images using Generative Adversarial Networks and Contrastive Learning
Mar 29, 2023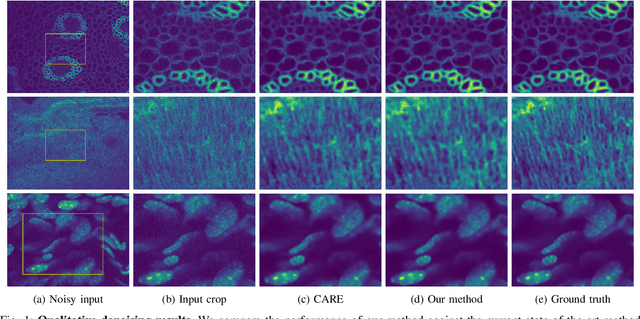



Microscopy images often suffer from high levels of noise, which can hinder further analysis and interpretation. Content-aware image restoration (CARE) methods have been proposed to address this issue, but they often require large amounts of training data and suffer from over-fitting. To overcome these challenges, we propose a novel framework for few-shot microscopy image denoising. Our approach combines a generative adversarial network (GAN) trained via contrastive learning (CL) with two structure preserving loss terms (Structural Similarity Index and Total Variation loss) to further improve the quality of the denoised images using little data. We demonstrate the effectiveness of our method on three well-known microscopy imaging datasets, and show that we can drastically reduce the amount of training data while retaining the quality of the denoising, thus alleviating the burden of acquiring paired data and enabling few-shot learning. The proposed framework can be easily extended to other image restoration tasks and has the potential to significantly advance the field of microscopy image analysis.