 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Visual-Genetic Biometrics for Taxonomic Classification of Rare Species
May 20, 2023
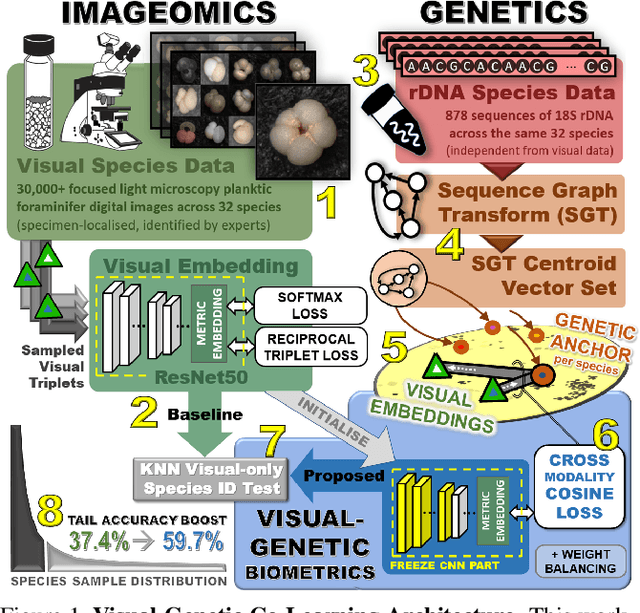
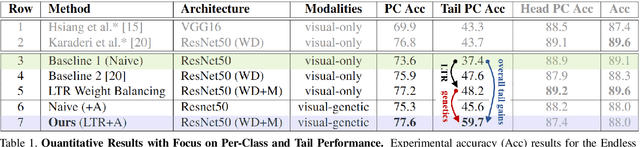
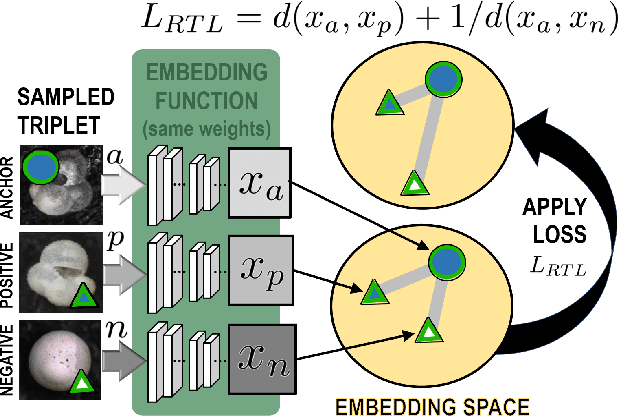
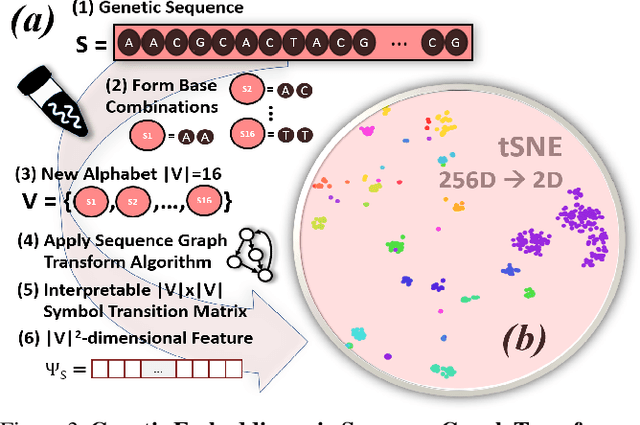
Visual as well as genetic biometrics are routinely employed to identify species and individuals in biological applications. However, no attempts have been made in this domain to computationally enhance visual classification of rare classes with little image data via genetics. In this paper, we thus propose aligned visual-genetic inference spaces with the aim to implicitly encode cross-domain associations for improved performance. We demonstrate for the first time that such alignment can be achieved via deep embedding models and that the approach is directly applicable to boosting long-tailed recognition (LTR) particularly for rare species. We experimentally demonstrate the efficacy of the concept via application to microscopic imagery of 30k+ planktic foraminifer shells across 32 species when used together with independent genetic data samples. Most importantly for practitioners, we show that visual-genetic alignment can significantly benefit visual-only recognition of the rarest species. Technically, we pre-train a visual ResNet50 deep learning model using triplet loss formulations to create an initial embedding space. We re-structure this space based on genetic anchors embedded via a Sequence Graph Transform (SGT) and linked to visual data by cross-domain cosine alignment. We show that an LTR approach improves the state-of-the-art across all benchmarks and that adding our visual-genetic alignment improves per-class and particularly rare tail class benchmarks significantly further. We conclude that visual-genetic alignment can be a highly effective tool for complementing visual biological data containing rare classes. The concept proposed may serve as an important future tool for integrating genetics and imageomics towards a more complete scientific representation of taxonomic spaces and life itself. Code, weights, and data splits are published for full reproducibility.
Image-and-Language Understanding from Pixels Only
Dec 15, 2022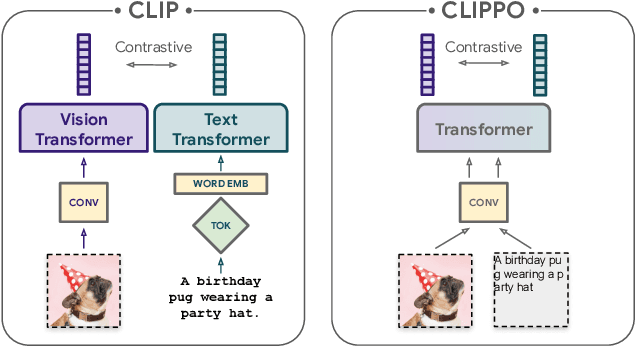
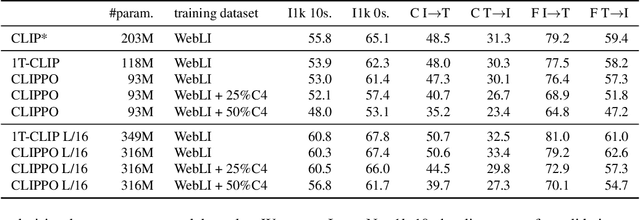
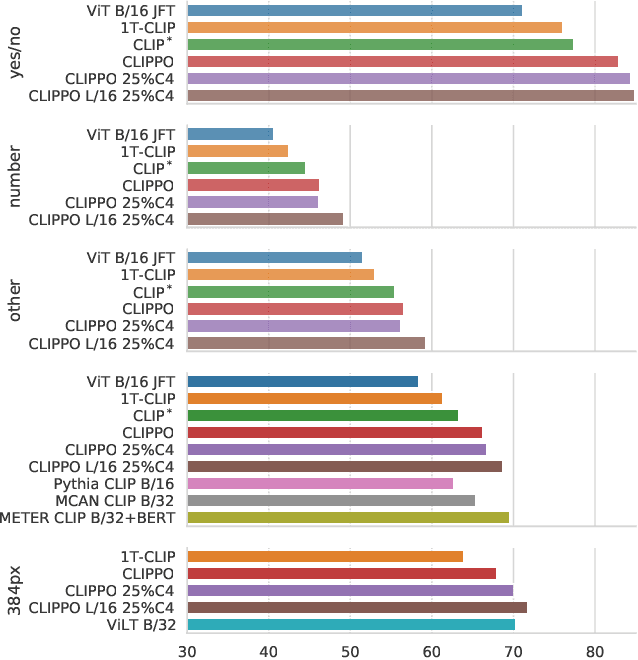
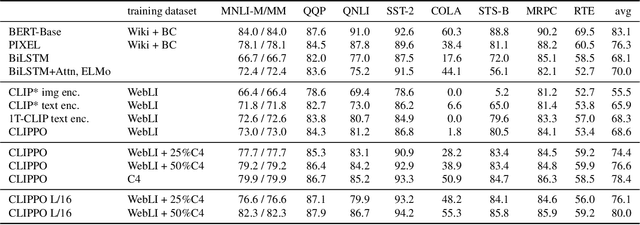
Multimodal models are becoming increasingly effective, in part due to unified components, such as the Transformer architecture. However, multimodal models still often consist of many task- and modality-specific pieces and training procedures. For example, CLIP (Radford et al., 2021) trains independent text and image towers via a contrastive loss. We explore an additional unification: the use of a pure pixel-based model to perform image, text, and multimodal tasks. Our model is trained with contrastive loss alone, so we call it CLIP-Pixels Only (CLIPPO). CLIPPO uses a single encoder that processes both regular images and text rendered as images. CLIPPO performs image-based tasks such as retrieval and zero-shot image classification almost as well as CLIP, with half the number of parameters and no text-specific tower or embedding. When trained jointly via image-text contrastive learning and next-sentence contrastive learning, CLIPPO can perform well on natural language understanding tasks, without any word-level loss (language modelling or masked language modelling), outperforming pixel-based prior work. Surprisingly, CLIPPO can obtain good accuracy in visual question answering, simply by rendering the question and image together. Finally, we exploit the fact that CLIPPO does not require a tokenizer to show that it can achieve strong performance on multilingual multimodal retrieval without
QS-ADN: Quasi-Supervised Artifact Disentanglement Network for Low-Dose CT Image Denoising by Local Similarity Among Unpaired Data
Feb 08, 2023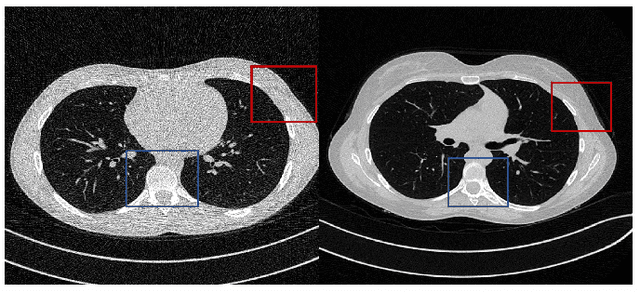
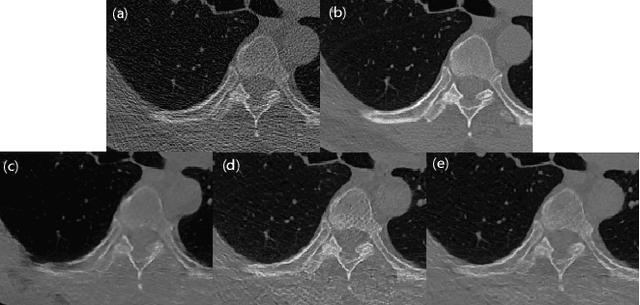
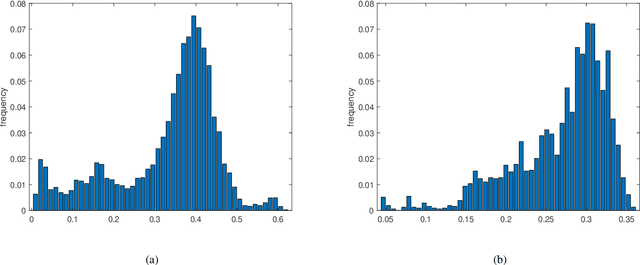
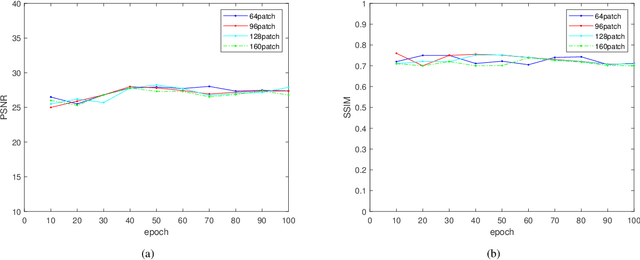
Deep learning has been successfully applied to low-dose CT (LDCT) image denoising for reducing potential radiation risk. However, the widely reported supervised LDCT denoising networks require a training set of paired images, which is expensive to obtain and cannot be perfectly simulated. Unsupervised learning utilizes unpaired data and is highly desirable for LDCT denoising. As an example, an artifact disentanglement network (ADN) relies on unparied images and obviates the need for supervision but the results of artifact reduction are not as good as those through supervised learning.An important observation is that there is often hidden similarity among unpaired data that can be utilized. This paper introduces a new learning mode, called quasi-supervised learning, to empower the ADN for LDCT image denoising.For every LDCT image, the best matched image is first found from an unpaired normal-dose CT (NDCT) dataset. Then, the matched pairs and the corresponding matching degree as prior information are used to construct and train our ADN-type network for LDCT denoising.The proposed method is different from (but compatible with) supervised and semi-supervised learning modes and can be easily implemented by modifying existing networks. The experimental results show that the method is competitive with state-of-the-art methods in terms of noise suppression and contextual fidelity. The code and working dataset are publicly available at https://github.com/ruanyuhui/ADN-QSDL.git.
Are Multimodal Models Robust to Image and Text Perturbations?
Dec 15, 2022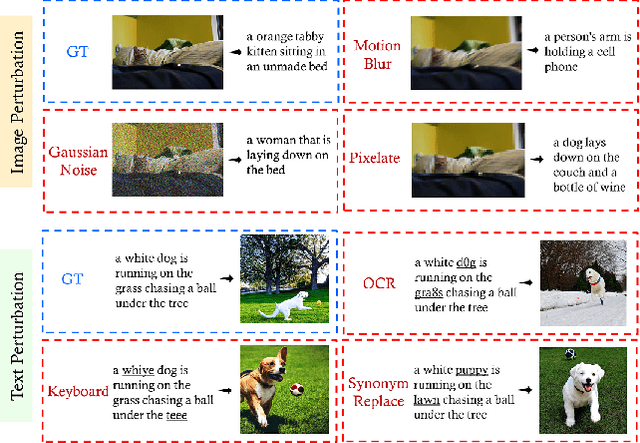
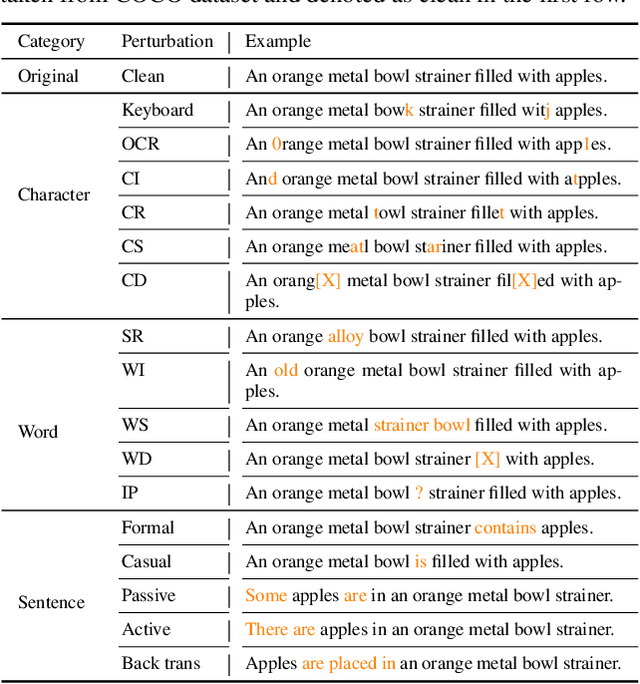


Multimodal image-text models have shown remarkable performance in the past few years. However, evaluating their robustness against distribution shifts is crucial before adopting them in real-world applications. In this paper, we investigate the robustness of 9 popular open-sourced image-text models under common perturbations on five tasks (image-text retrieval, visual reasoning, visual entailment, image captioning, and text-to-image generation). In particular, we propose several new multimodal robustness benchmarks by applying 17 image perturbation and 16 text perturbation techniques on top of existing datasets. We observe that multimodal models are not robust to image and text perturbations, especially to image perturbations. Among the tested perturbation methods, character-level perturbations constitute the most severe distribution shift for text, and zoom blur is the most severe shift for image data. We also introduce two new robustness metrics (MMI and MOR) for proper evaluations of multimodal models. We hope our extensive study sheds light on new directions for the development of robust multimodal models.
AVFace: Towards Detailed Audio-Visual 4D Face Reconstruction
May 11, 2023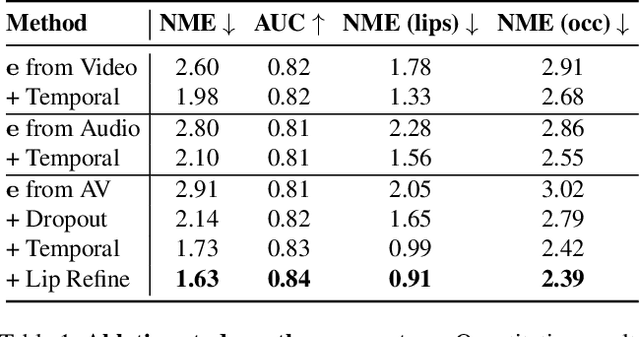
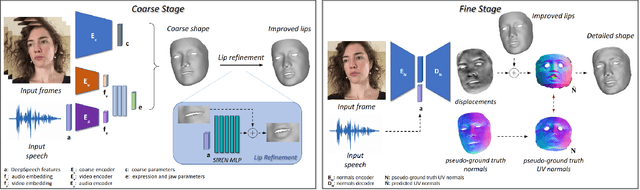
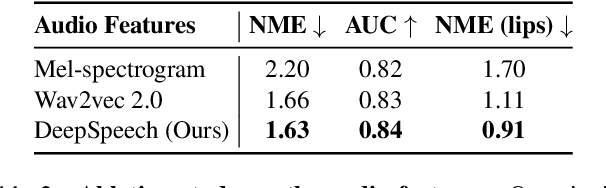

In this work, we present a multimodal solution to the problem of 4D face reconstruction from monocular videos. 3D face reconstruction from 2D images is an under-constrained problem due to the ambiguity of depth. State-of-the-art methods try to solve this problem by leveraging visual information from a single image or video, whereas 3D mesh animation approaches rely more on audio. However, in most cases (e.g. AR/VR applications), videos include both visual and speech information. We propose AVFace that incorporates both modalities and accurately reconstructs the 4D facial and lip motion of any speaker, without requiring any 3D ground truth for training. A coarse stage estimates the per-frame parameters of a 3D morphable model, followed by a lip refinement, and then a fine stage recovers facial geometric details. Due to the temporal audio and video information captured by transformer-based modules, our method is robust in cases when either modality is insufficient (e.g. face occlusions). Extensive qualitative and quantitative evaluation demonstrates the superiority of our method over the current state-of-the-art.
MedViT: A Robust Vision Transformer for Generalized Medical Image Classification
Feb 19, 2023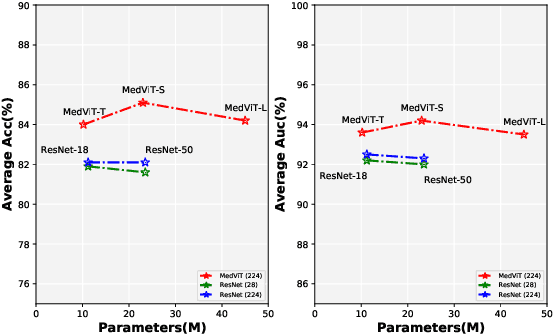
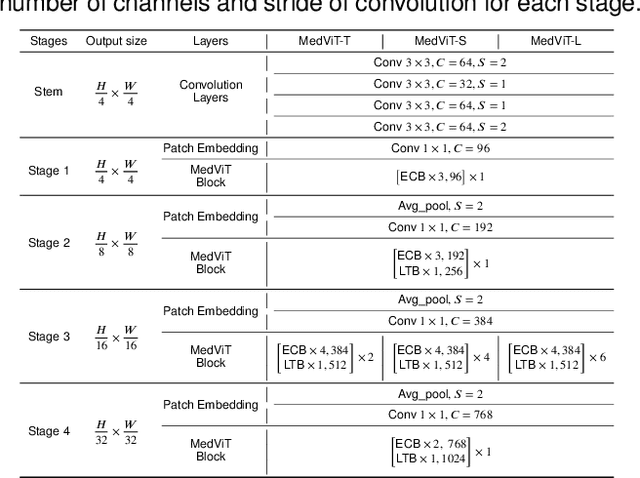
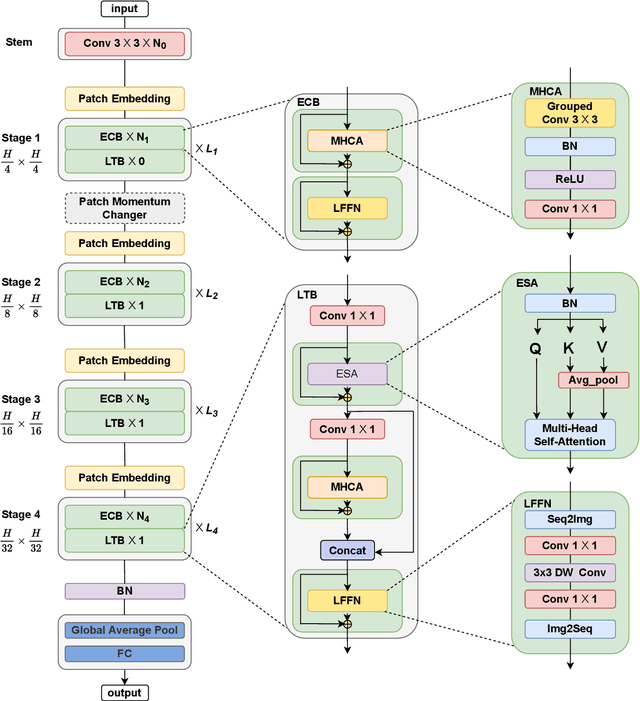
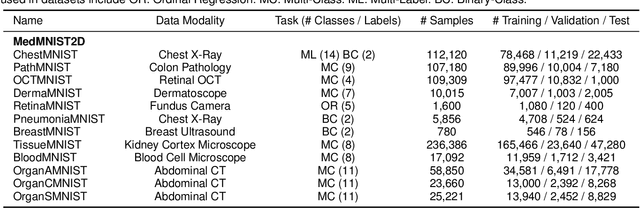
Convolutional Neural Networks (CNNs) have advanced existing medical systems for automatic disease diagnosis. However, there are still concerns about the reliability of deep medical diagnosis systems against the potential threats of adversarial attacks since inaccurate diagnosis could lead to disastrous consequences in the safety realm. In this study, we propose a highly robust yet efficient CNN-Transformer hybrid model which is equipped with the locality of CNNs as well as the global connectivity of vision Transformers. To mitigate the high quadratic complexity of the self-attention mechanism while jointly attending to information in various representation subspaces, we construct our attention mechanism by means of an efficient convolution operation. Moreover, to alleviate the fragility of our Transformer model against adversarial attacks, we attempt to learn smoother decision boundaries. To this end, we augment the shape information of an image in the high-level feature space by permuting the feature mean and variance within mini-batches. With less computational complexity, our proposed hybrid model demonstrates its high robustness and generalization ability compared to the state-of-the-art studies on a large-scale collection of standardized MedMNIST-2D datasets.
Long-Term Photometric Consistent Novel View Synthesis with Diffusion Models
Apr 21, 2023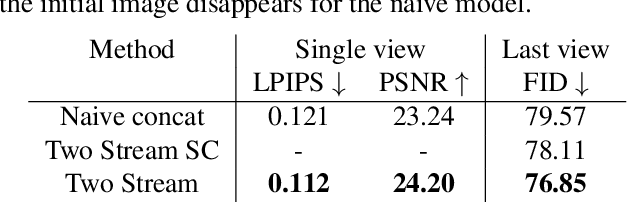
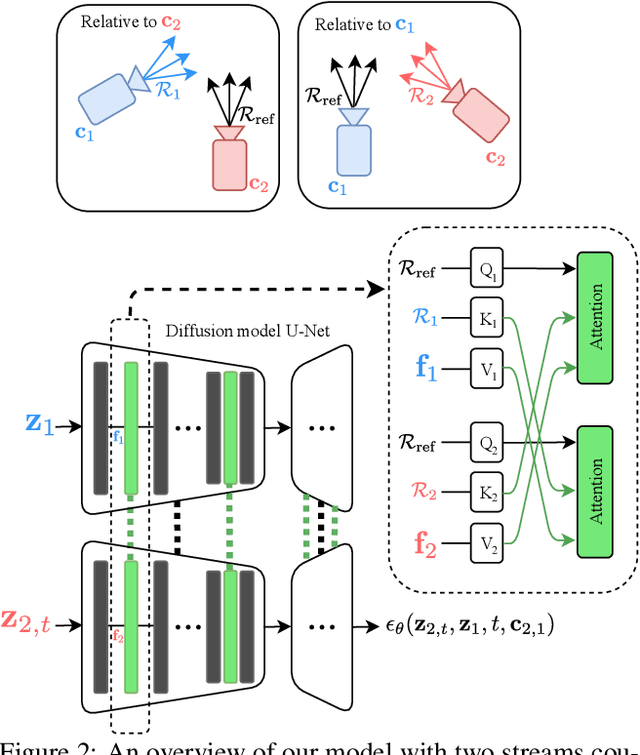
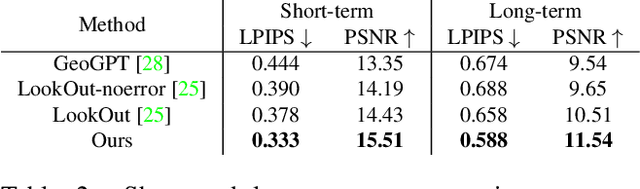
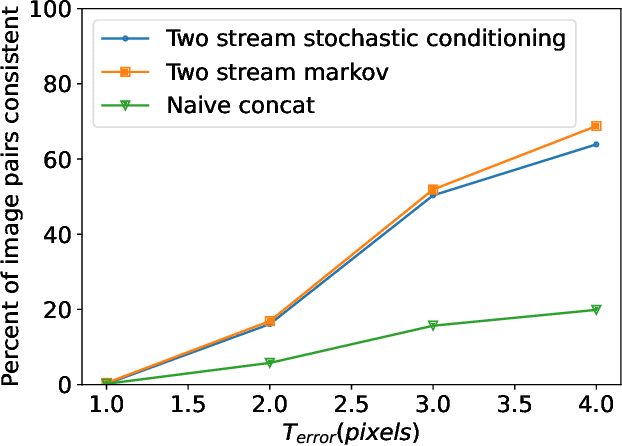
Novel view synthesis from a single input image is a challenging task, where the goal is to generate a new view of a scene from a desired camera pose that may be separated by a large motion. The highly uncertain nature of this synthesis task due to unobserved elements within the scene (i.e., occlusion) and outside the field-of-view makes the use of generative models appealing to capture the variety of possible outputs. In this paper, we propose a novel generative model which is capable of producing a sequence of photorealistic images consistent with a specified camera trajectory, and a single starting image. Our approach is centred on an autoregressive conditional diffusion-based model capable of interpolating visible scene elements, and extrapolating unobserved regions in a view, in a geometrically consistent manner. Conditioning is limited to an image capturing a single camera view and the (relative) pose of the new camera view. To measure the consistency over a sequence of generated views, we introduce a new metric, the thresholded symmetric epipolar distance (TSED), to measure the number of consistent frame pairs in a sequence. While previous methods have been shown to produce high quality images and consistent semantics across pairs of views, we show empirically with our metric that they are often inconsistent with the desired camera poses. In contrast, we demonstrate that our method produces both photorealistic and view-consistent imagery.
CECT: Controllable Ensemble CNN and Transformer for COVID-19 image classification by capturing both local and global image features
Feb 05, 2023
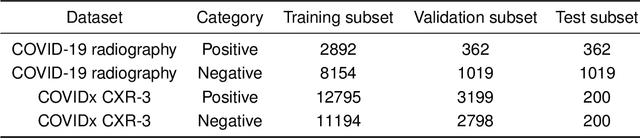
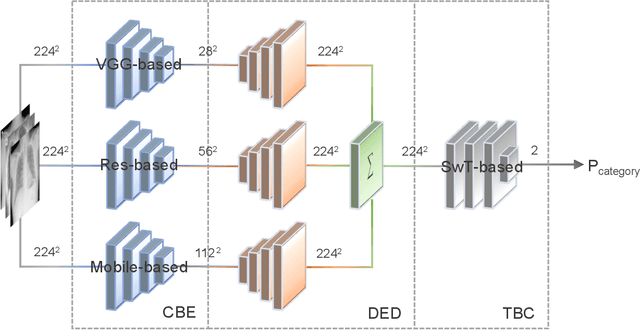
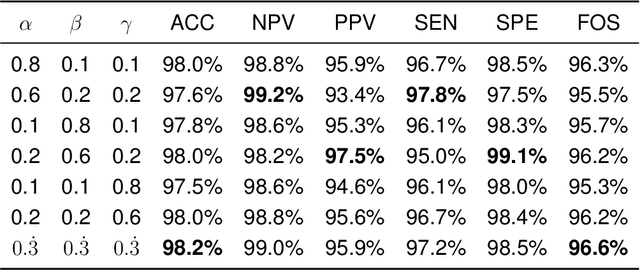
Purpose: Most computer vision models are developed based on either convolutional neural network (CNN) or transformer, while the former (latter) method captures local (global) features. To relieve model performance limitations due to the lack of global (local) features, we develop a novel classification network named CECT by controllable ensemble CNN and transformer. Methods: The proposed CECT is composed of a CNN-based encoder block, a deconvolution-ensemble decoder block, and a transformer-based classification block. Different from conventional CNN- or transformer-based methods, our CECT can capture features at both multi-local and global scales, and the contribution of local features at different scales can be controlled with the proposed ensemble coefficients. Results: We evaluate CECT on two public COVID-19 datasets and it outperforms other state-of-the-art methods on all evaluation metrics. Conclusion: With remarkable feature capture ability, we believe CECT can also be used in other medical image classification scenarios to assist the diagnosis.
What Affects Learned Equivariance in Deep Image Recognition Models?
Apr 07, 2023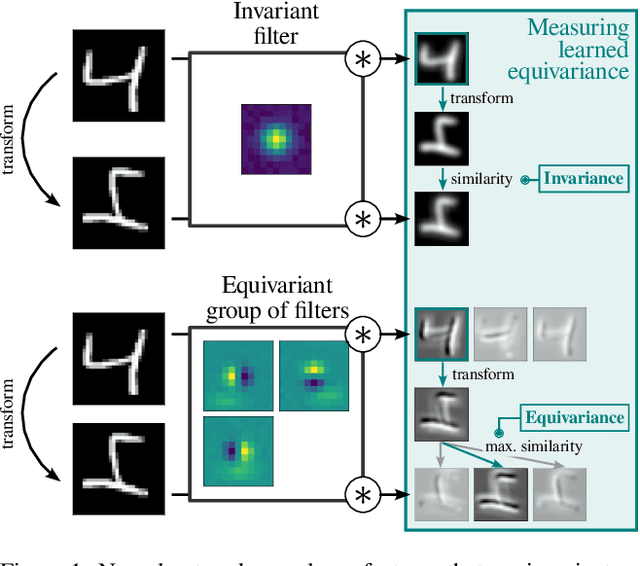
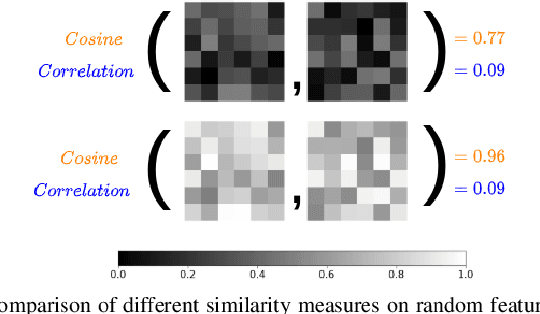
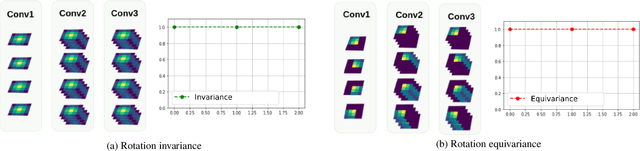
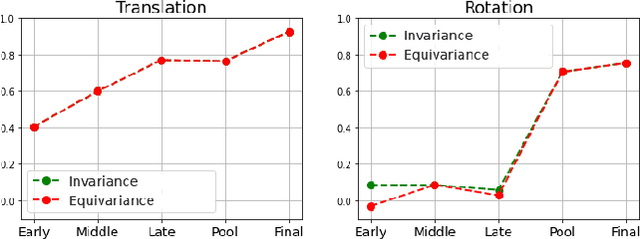
Equivariance w.r.t. geometric transformations in neural networks improves data efficiency, parameter efficiency and robustness to out-of-domain perspective shifts. When equivariance is not designed into a neural network, the network can still learn equivariant functions from the data. We quantify this learned equivariance, by proposing an improved measure for equivariance. We find evidence for a correlation between learned translation equivariance and validation accuracy on ImageNet. We therefore investigate what can increase the learned equivariance in neural networks, and find that data augmentation, reduced model capacity and inductive bias in the form of convolutions induce higher learned equivariance in neural networks.
Bootstrapping Objectness from Videos by Relaxed Common Fate and Visual Grouping
Apr 17, 2023
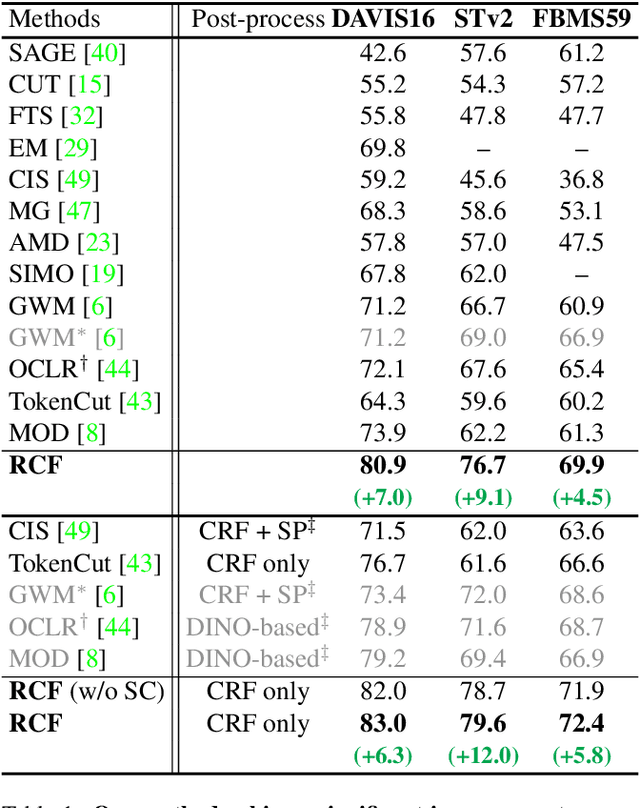

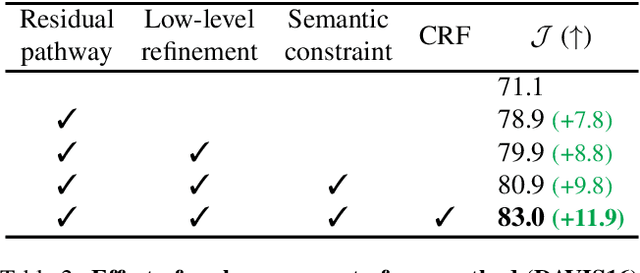
We study learning object segmentation from unlabeled videos. Humans can easily segment moving objects without knowing what they are. The Gestalt law of common fate, i.e., what move at the same speed belong together, has inspired unsupervised object discovery based on motion segmentation. However, common fate is not a reliable indicator of objectness: Parts of an articulated / deformable object may not move at the same speed, whereas shadows / reflections of an object always move with it but are not part of it. Our insight is to bootstrap objectness by first learning image features from relaxed common fate and then refining them based on visual appearance grouping within the image itself and across images statistically. Specifically, we learn an image segmenter first in the loop of approximating optical flow with constant segment flow plus small within-segment residual flow, and then by refining it for more coherent appearance and statistical figure-ground relevance. On unsupervised video object segmentation, using only ResNet and convolutional heads, our model surpasses the state-of-the-art by absolute gains of 7/9/5% on DAVIS16 / STv2 / FBMS59 respectively, demonstrating the effectiveness of our ideas. Our code is publicly available.