 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Acoustic Simulation Framework to Support Indoor Positioning and Data Driven Signal Processing Assessments
May 04, 2023
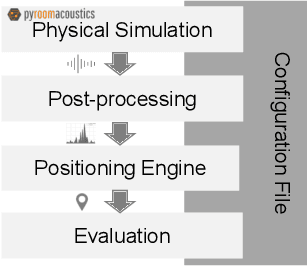
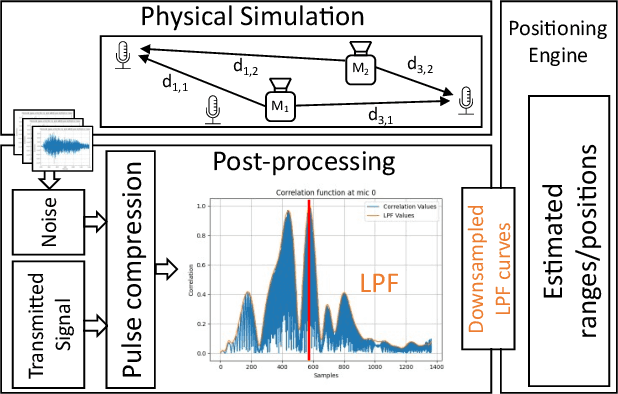
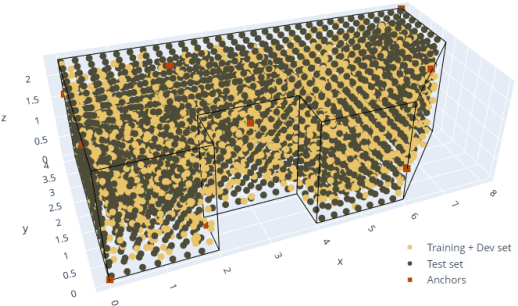
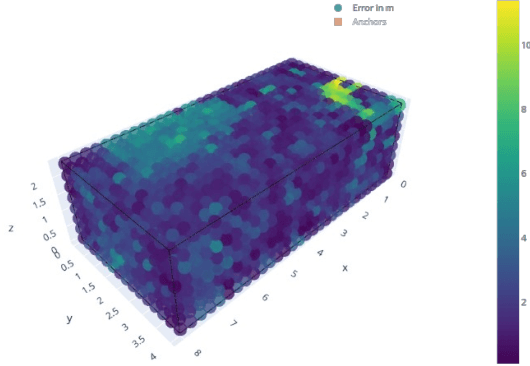
We present an indoor acoustic simulation framework that supports both ultrasonic and audible signaling. The framework opens the opportunity for fast indoor acoustic data generation and positioning development. The improved Pyroomacoustics-based physical model includes both an image-source model (ISM) and ray tracing method to simulate acoustic signaling in geometric spaces that extend typical shoe-box rooms. Moreover, it offers the convenience to facilitate multiple speakers and microphones with different directivity patterns. In addition to temperature and air absorption, the room reverberation is taken into account characterized by the RT60 value or the combination of building materials. Additional noise sources can be added by means of post processing and/or extra speakers. Indoor positioning methods assessed in simulation are compared with real measurements in a testbed, called 'Techtile'. This analysis confirms that the simulation results are close to the measurements and form a realistic representation of the reality. The simulation framework is constructed in a modular way, and parts can be replaced or modified to support different application domains. The code is made available open source.
PATS: Patch Area Transportation with Subdivision for Local Feature Matching
Apr 04, 2023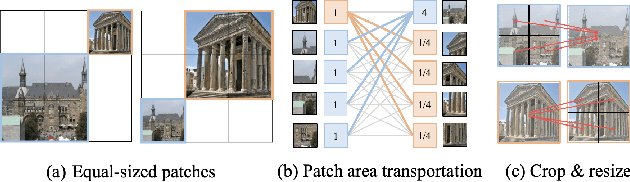

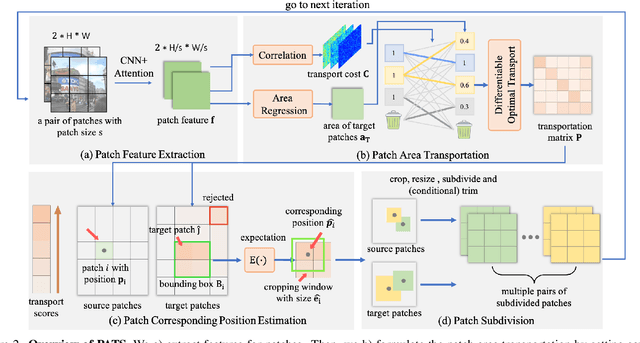
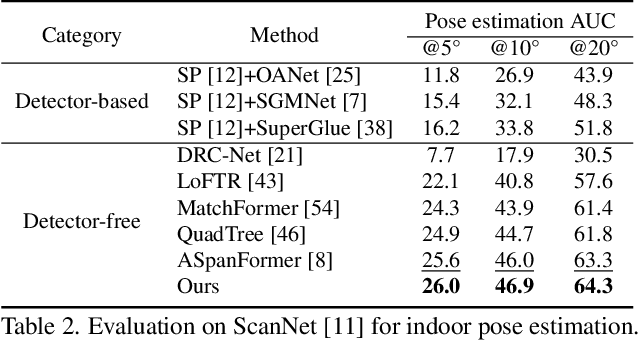
Local feature matching aims at establishing sparse correspondences between a pair of images. Recently, detector-free methods present generally better performance but are not satisfactory in image pairs with large scale differences. In this paper, we propose Patch Area Transportation with Subdivision (PATS) to tackle this issue. Instead of building an expensive image pyramid, we start by splitting the original image pair into equal-sized patches and gradually resizing and subdividing them into smaller patches with the same scale. However, estimating scale differences between these patches is non-trivial since the scale differences are determined by both relative camera poses and scene structures, and thus spatially varying over image pairs. Moreover, it is hard to obtain the ground truth for real scenes. To this end, we propose patch area transportation, which enables learning scale differences in a self-supervised manner. In contrast to bipartite graph matching, which only handles one-to-one matching, our patch area transportation can deal with many-to-many relationships. PATS improves both matching accuracy and coverage, and shows superior performance in downstream tasks, such as relative pose estimation, visual localization, and optical flow estimation. The source code is available at \url{https://zju3dv.github.io/pats/}.
Anything-3D: Towards Single-view Anything Reconstruction in the Wild
Apr 19, 2023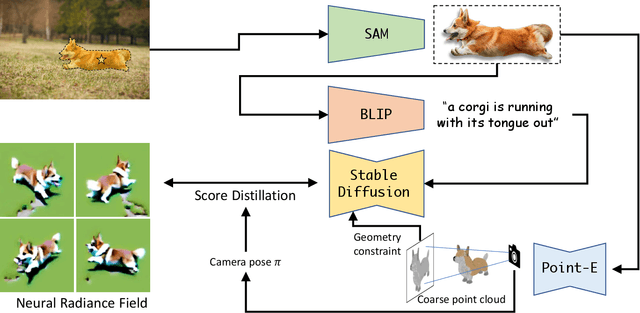


3D reconstruction from a single-RGB image in unconstrained real-world scenarios presents numerous challenges due to the inherent diversity and complexity of objects and environments. In this paper, we introduce Anything-3D, a methodical framework that ingeniously combines a series of visual-language models and the Segment-Anything object segmentation model to elevate objects to 3D, yielding a reliable and versatile system for single-view conditioned 3D reconstruction task. Our approach employs a BLIP model to generate textural descriptions, utilizes the Segment-Anything model for the effective extraction of objects of interest, and leverages a text-to-image diffusion model to lift object into a neural radiance field. Demonstrating its ability to produce accurate and detailed 3D reconstructions for a wide array of objects, \emph{Anything-3D\footnotemark[2]} shows promise in addressing the limitations of existing methodologies. Through comprehensive experiments and evaluations on various datasets, we showcase the merits of our approach, underscoring its potential to contribute meaningfully to the field of 3D reconstruction. Demos and code will be available at \href{https://github.com/Anything-of-anything/Anything-3D}{https://github.com/Anything-of-anything/Anything-3D}.
TIER: Text-Image Entropy Regularization for CLIP-style models
Dec 13, 2022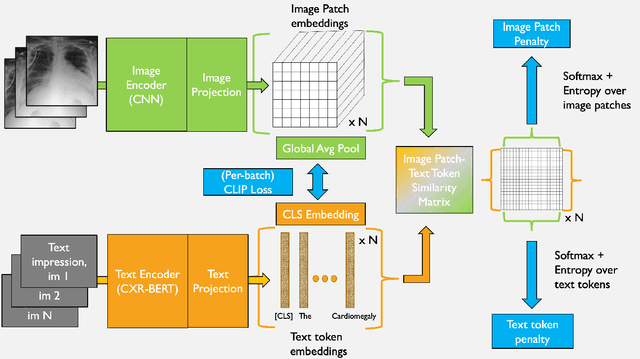
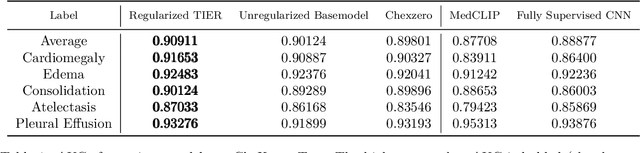

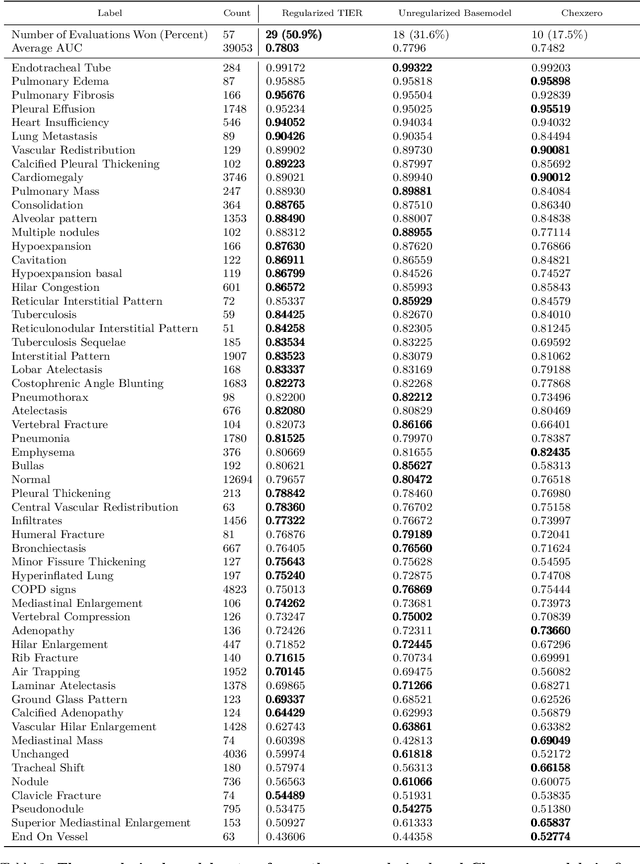
In this paper, we study the effect of a novel regularization scheme on contrastive language-image pre-trained (CLIP) models. Our approach is based on the observation that, in many domains, text tokens should only describe a small number of image regions and, likewise, each image region should correspond to only a few text tokens. In CLIP-style models, this implies that text-token embeddings should have high similarity to only a small number of image-patch embeddings for a given image-text pair. We formalize this observation using a novel regularization scheme that penalizes the entropy of the text-token to image-patch similarity scores. We qualitatively and quantitatively demonstrate that the proposed regularization scheme shrinks the text-token and image-patch similarity scores towards zero, thus achieving the desired effect. We demonstrate the promise of our approach in an important medical context where this underlying hypothesis naturally arises. Using our proposed approach, we achieve state of the art (SOTA) zero-shot performance on all tasks from the CheXpert chest x-ray dataset, outperforming an unregularized version of the model and several recently published self-supervised models.
Oil Spill Segmentation using Deep Encoder-Decoder models
May 02, 2023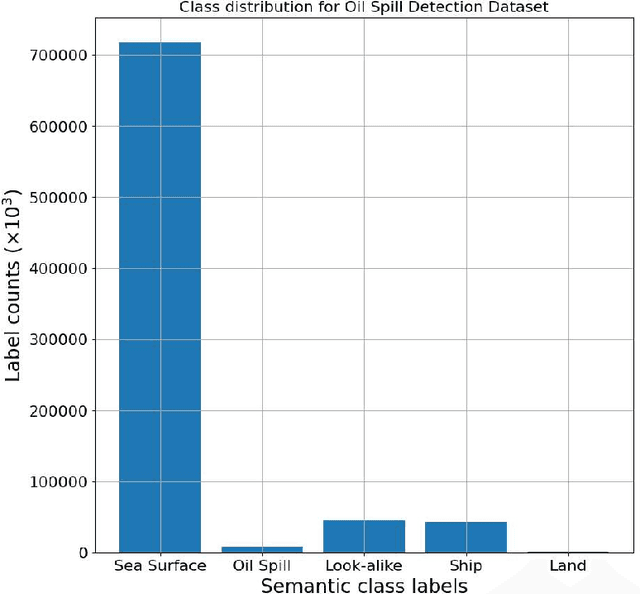
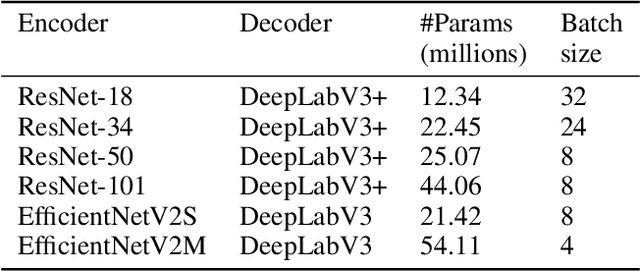

Crude oil is an integral component of the modern world economy. With the growing demand for crude oil due to its widespread applications, accidental oil spills are unavoidable. Even though oil spills are in and themselves difficult to clean up, the first and foremost challenge is to detect spills. In this research, the authors test the feasibility of deep encoder-decoder models that can be trained effectively to detect oil spills. The work compares the results from several segmentation models on high dimensional satellite Synthetic Aperture Radar (SAR) image data. Multiple combinations of models are used in running the experiments. The best-performing model is the one with the ResNet-50 encoder and DeepLabV3+ decoder. It achieves a mean Intersection over Union (IoU) of 64.868% and a class IoU of 61.549% for the "oil spill" class when compared with the current benchmark model, which achieved a mean IoU of 65.05% and a class IoU of 53.38% for the "oil spill" class.
Reconstructing seen images from human brain activity via guided stochastic search
May 02, 2023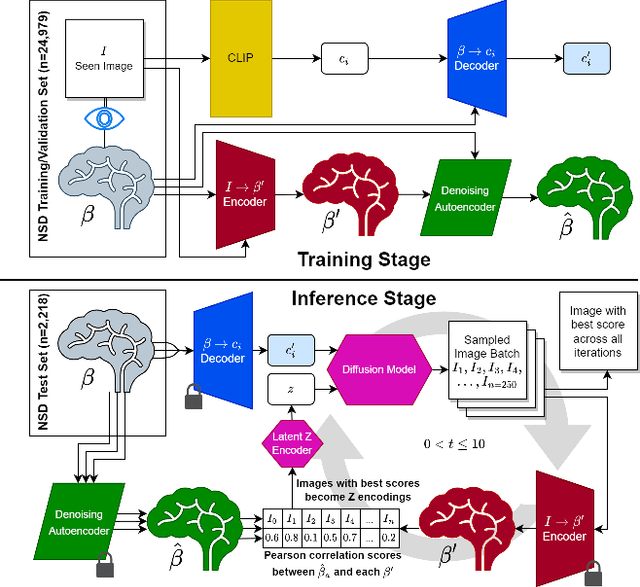
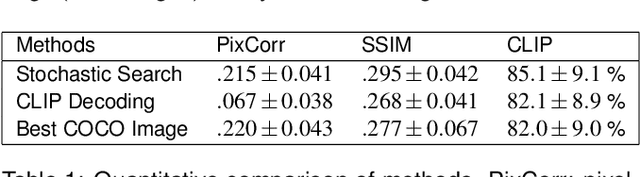


Visual reconstruction algorithms are an interpretive tool that map brain activity to pixels. Past reconstruction algorithms employed brute-force search through a massive library to select candidate images that, when passed through an encoding model, accurately predict brain activity. Here, we use conditional generative diffusion models to extend and improve this search-based strategy. We decode a semantic descriptor from human brain activity (7T fMRI) in voxels across most of visual cortex, then use a diffusion model to sample a small library of images conditioned on this descriptor. We pass each sample through an encoding model, select the images that best predict brain activity, and then use these images to seed another library. We show that this process converges on high-quality reconstructions by refining low-level image details while preserving semantic content across iterations. Interestingly, the time-to-convergence differs systematically across visual cortex, suggesting a succinct new way to measure the diversity of representations across visual brain areas.
Stratified Adversarial Robustness with Rejection
May 02, 2023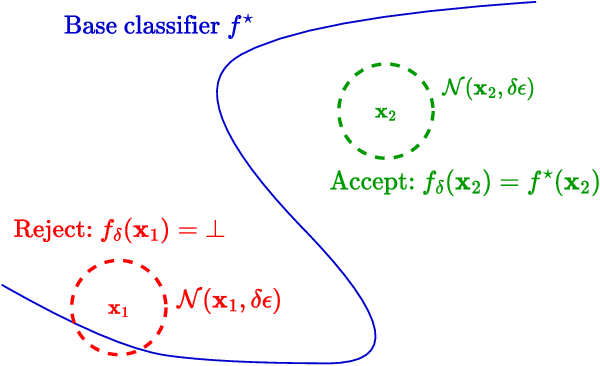
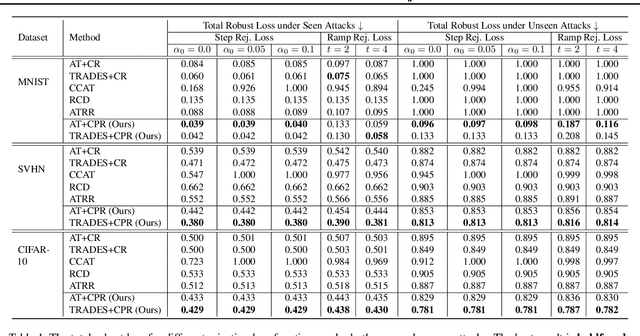
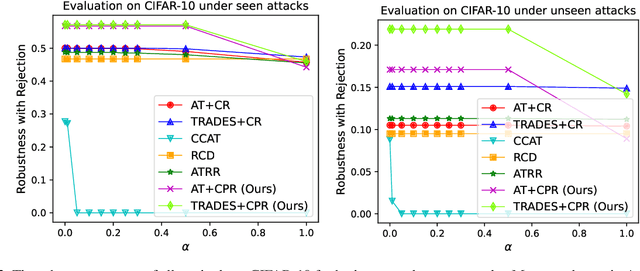
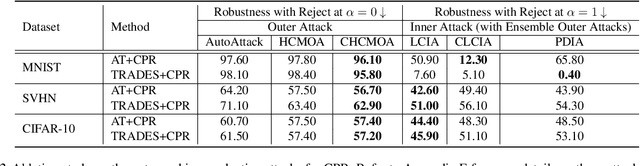
Recently, there is an emerging interest in adversarially training a classifier with a rejection option (also known as a selective classifier) for boosting adversarial robustness. While rejection can incur a cost in many applications, existing studies typically associate zero cost with rejecting perturbed inputs, which can result in the rejection of numerous slightly-perturbed inputs that could be correctly classified. In this work, we study adversarially-robust classification with rejection in the stratified rejection setting, where the rejection cost is modeled by rejection loss functions monotonically non-increasing in the perturbation magnitude. We theoretically analyze the stratified rejection setting and propose a novel defense method -- Adversarial Training with Consistent Prediction-based Rejection (CPR) -- for building a robust selective classifier. Experiments on image datasets demonstrate that the proposed method significantly outperforms existing methods under strong adaptive attacks. For instance, on CIFAR-10, CPR reduces the total robust loss (for different rejection losses) by at least 7.3% under both seen and unseen attacks.
Mask-conditioned latent diffusion for generating gastrointestinal polyp images
Apr 11, 2023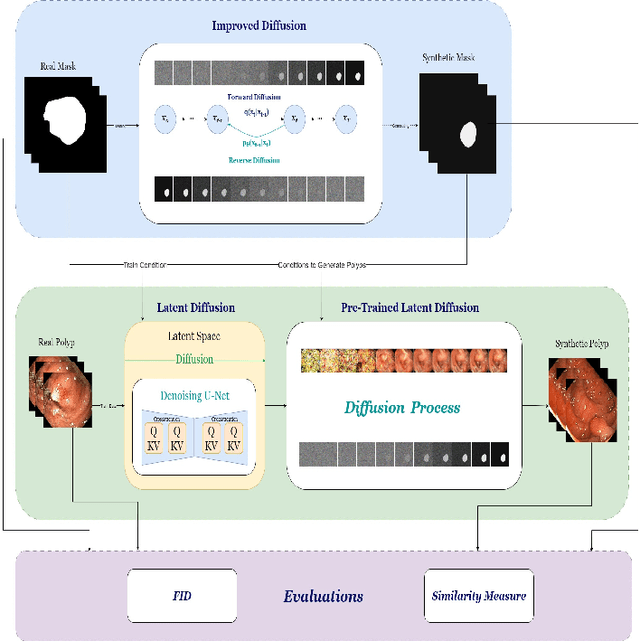
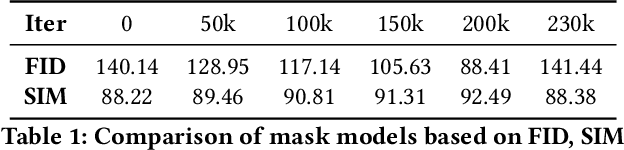


In order to take advantage of AI solutions in endoscopy diagnostics, we must overcome the issue of limited annotations. These limitations are caused by the high privacy concerns in the medical field and the requirement of getting aid from experts for the time-consuming and costly medical data annotation process. In computer vision, image synthesis has made a significant contribution in recent years as a result of the progress of generative adversarial networks (GANs) and diffusion probabilistic models (DPM). Novel DPMs have outperformed GANs in text, image, and video generation tasks. Therefore, this study proposes a conditional DPM framework to generate synthetic GI polyp images conditioned on given generated segmentation masks. Our experimental results show that our system can generate an unlimited number of high-fidelity synthetic polyp images with the corresponding ground truth masks of polyps. To test the usefulness of the generated data, we trained binary image segmentation models to study the effect of using synthetic data. Results show that the best micro-imagewise IOU of 0.7751 was achieved from DeepLabv3+ when the training data consists of both real data and synthetic data. However, the results reflect that achieving good segmentation performance with synthetic data heavily depends on model architectures.
Unify, Align and Refine: Multi-Level Semantic Alignment for Radiology Report Generation
Apr 05, 2023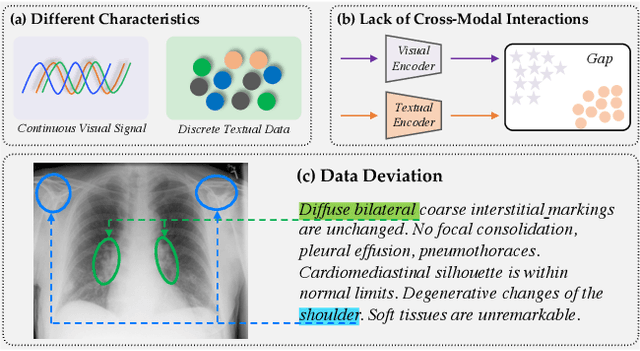
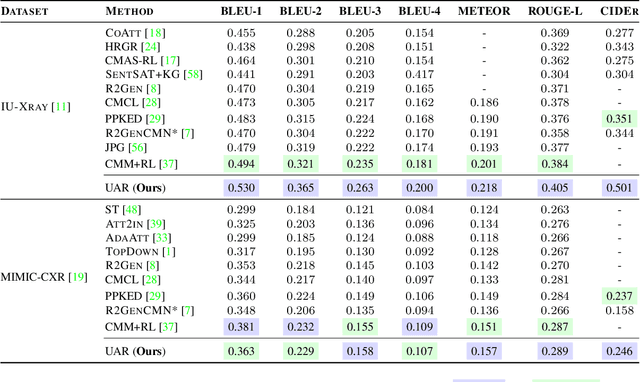
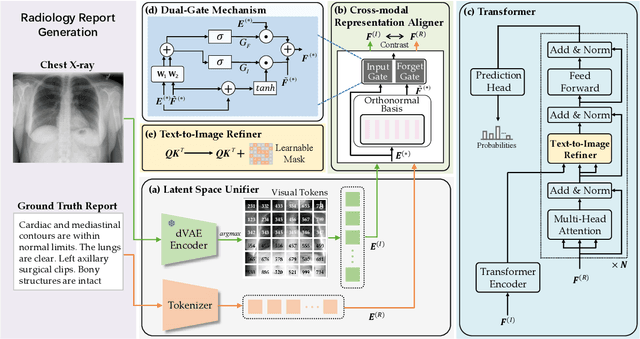
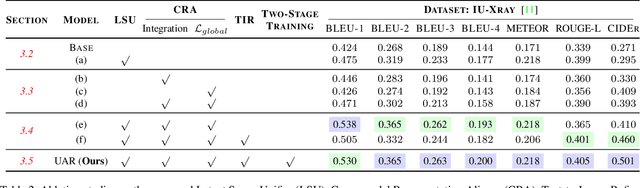
Automatic radiology report generation has attracted enormous research interest due to its practical value in reducing the workload of radiologists. However, simultaneously establishing global correspondences between the image (e.g., Chest X-ray) and its related report and local alignments between image patches and keywords remains challenging. To this end, we propose an Unify, Align and then Refine (UAR) approach to learn multi-level cross-modal alignments and introduce three novel modules: Latent Space Unifier (LSU), Cross-modal Representation Aligner (CRA) and Text-to-Image Refiner (TIR). Specifically, LSU unifies multimodal data into discrete tokens, making it flexible to learn common knowledge among modalities with a shared network. The modality-agnostic CRA learns discriminative features via a set of orthonormal basis and a dual-gate mechanism first and then globally aligns visual and textual representations under a triplet contrastive loss. TIR boosts token-level local alignment via calibrating text-to-image attention with a learnable mask. Additionally, we design a two-stage training procedure to make UAR gradually grasp cross-modal alignments at different levels, which imitates radiologists' workflow: writing sentence by sentence first and then checking word by word. Extensive experiments and analyses on IU-Xray and MIMIC-CXR benchmark datasets demonstrate the superiority of our UAR against varied state-of-the-art methods.
ForamViT-GAN: Exploring New Paradigms in Deep Learning for Micropaleontological Image Analysis
Apr 09, 2023
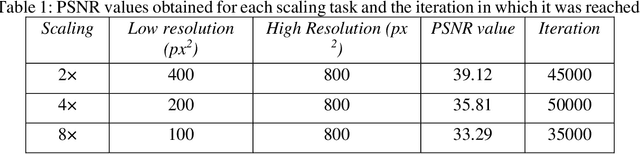
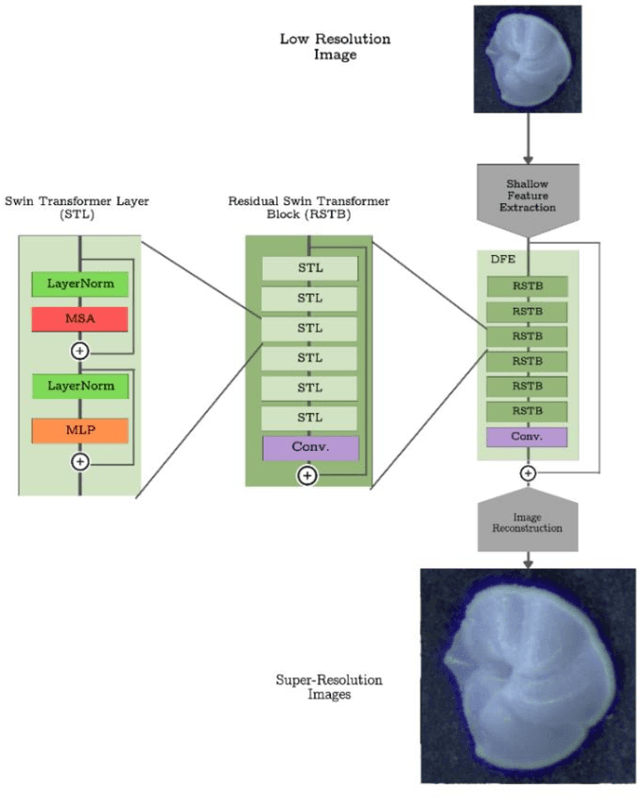
Micropaleontology in geosciences focuses on studying the evolution of microfossils (e.g., foraminifera) through geological records to reconstruct past environmental and climatic conditions. This field heavily relies on visual recognition of microfossil features, making it suitable for computer vision technology, specifically deep convolutional neural networks (CNNs), to automate and optimize microfossil identification and classification. However, the application of deep learning in micropaleontology is hindered by limited availability of high-quality, high-resolution labeled fossil images and the significant manual labeling effort required by experts. To address these challenges, we propose a novel deep learning workflow combining hierarchical vision transformers with style-based generative adversarial network algorithms to efficiently acquire and synthetically generate realistic high-resolution labeled datasets of micropaleontology in large volumes. Our study shows that this workflow can generate high-resolution images with a high signal-to-noise ratio (39.1 dB) and realistic synthetic images with a Frechet inception distance similarity score of 14.88. Additionally, our workflow provides a large volume of self-labeled datasets for model benchmarking and various downstream visual tasks, including fossil classification and segmentation. For the first time, we performed few-shot semantic segmentation of different foraminifera chambers on both generated and synthetic images with high accuracy. This novel meta-learning approach is only possible with the availability of high-resolution, high-volume labeled datasets. Our deep learning-based workflow shows promise in advancing and optimizing micropaleontological research and other visual-dependent geological analyses.