 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ContraCluster: Learning to Classify without Labels by Contrastive Self-Supervision and Prototype-Based Semi-Supervision
Apr 19, 2023

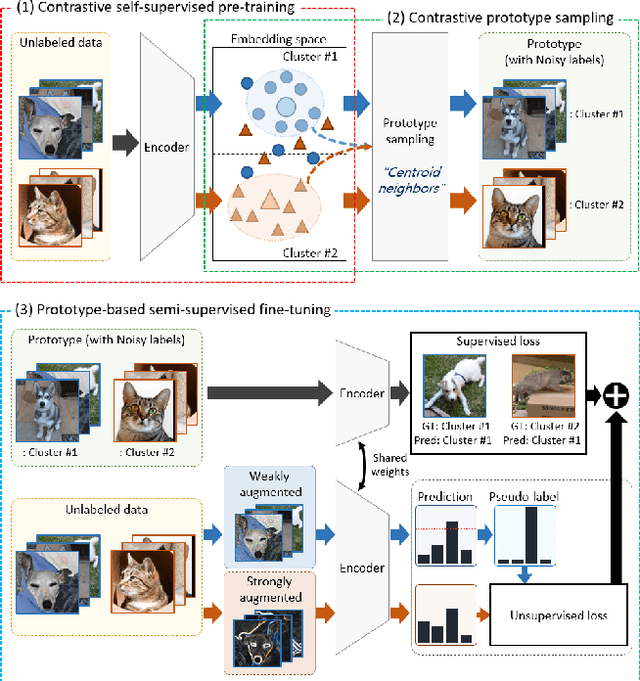
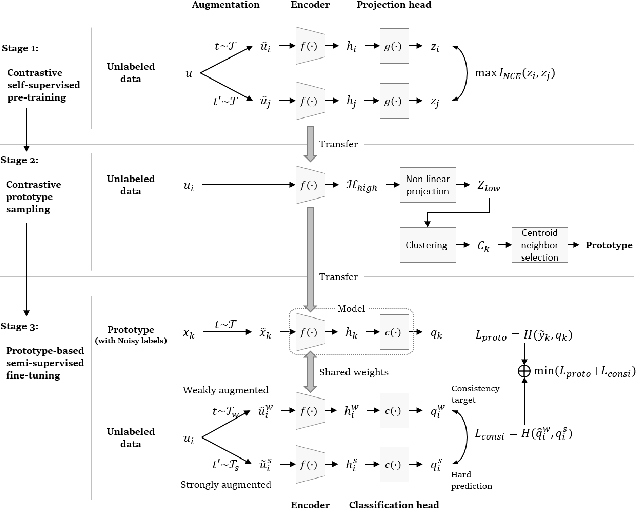
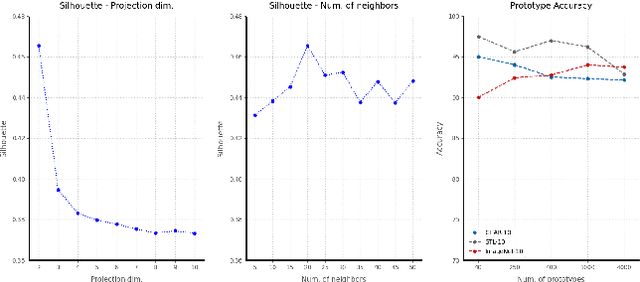
The recent advances in representation learning inspire us to take on the challenging problem of unsupervised image classification tasks in a principled way. We propose ContraCluster, an unsupervised image classification method that combines clustering with the power of contrastive self-supervised learning. ContraCluster consists of three stages: (1) contrastive self-supervised pre-training (CPT), (2) contrastive prototype sampling (CPS), and (3) prototype-based semi-supervised fine-tuning (PB-SFT). CPS can select highly accurate, categorically prototypical images in an embedding space learned by contrastive learning. We use sampled prototypes as noisy labeled data to perform semi-supervised fine-tuning (PB-SFT), leveraging small prototypes and large unlabeled data to further enhance the accuracy. We demonstrate empirically that ContraCluster achieves new state-of-the-art results for standard benchmark datasets including CIFAR-10, STL-10, and ImageNet-10. For example, ContraCluster achieves about 90.8% accuracy for CIFAR-10, which outperforms DAC (52.2%), IIC (61.7%), and SCAN (87.6%) by a large margin. Without any labels, ContraCluster can achieve a 90.8% accuracy that is comparable to 95.8% by the best supervised counterpart.
* Accepted at ICPR 2022
RoSteALS: Robust Steganography using Autoencoder Latent Space
Apr 06, 2023
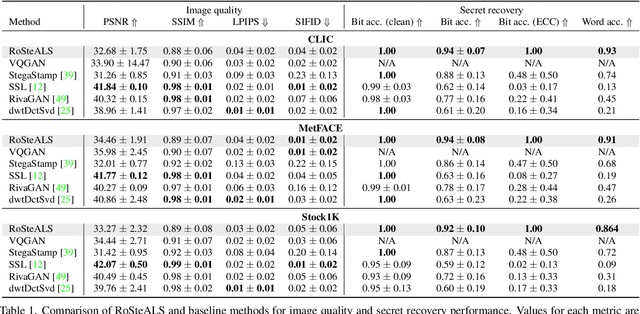
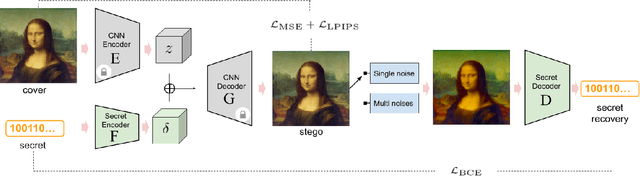

Data hiding such as steganography and invisible watermarking has important applications in copyright protection, privacy-preserved communication and content provenance. Existing works often fall short in either preserving image quality, or robustness against perturbations or are too complex to train. We propose RoSteALS, a practical steganography technique leveraging frozen pretrained autoencoders to free the payload embedding from learning the distribution of cover images. RoSteALS has a light-weight secret encoder of just 300k parameters, is easy to train, has perfect secret recovery performance and comparable image quality on three benchmarks. Additionally, RoSteALS can be adapted for novel cover-less steganography applications in which the cover image can be sampled from noise or conditioned on text prompts via a denoising diffusion process. Our model and code are available at \url{https://github.com/TuBui/RoSteALS}.
CellMix: A General Instance Relationship based Method for Data Augmentation Towards Pathology Image Analysis
Jan 27, 2023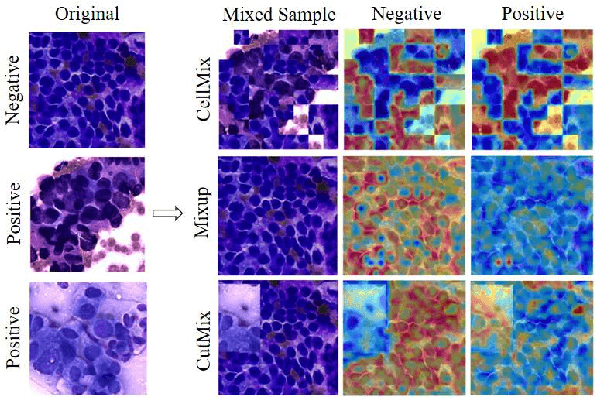
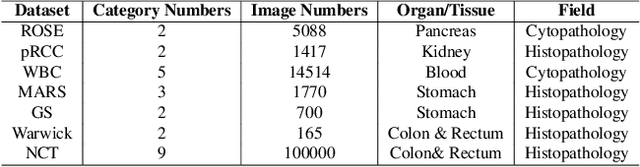
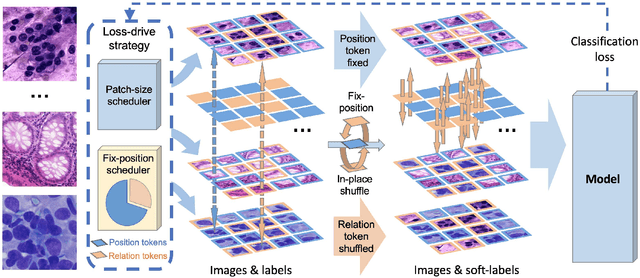
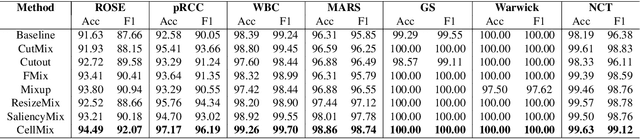
Pathology image analysis crucially relies on the availability and quality of annotated pathological samples, which are very difficult to collect and need lots of human effort. To address this issue, beyond traditional preprocess data augmentation methods, mixing-based approaches are effective and practical. However, previous mixing-based data augmentation methods do not thoroughly explore the essential characteristics of pathology images, including the local specificity, global distribution, and inner/outer-sample instance relationship. To further understand the pathology characteristics and make up effective pseudo samples, we propose the CellMix framework with a novel distribution-based in-place shuffle strategy. We split the images into patches with respect to the granularity of pathology instances and do the shuffle process across the same batch. In this way, we generate new samples while keeping the absolute relationship of pathology instances intact. Furthermore, to deal with the perturbations and distribution-based noise, we devise a loss-drive strategy inspired by curriculum learning during the training process, making the model fit the augmented data adaptively. It is worth mentioning that we are the first to explore data augmentation techniques in the pathology image field. Experiments show SOTA results on 7 different datasets. We conclude that this novel instance relationship-based strategy can shed light on general data augmentation for pathology image analysis. The code is available at https://github.com/sagizty/CellMix.
Uncertainty-Aware Semi-Supervised Learning for Prostate MRI Zonal Segmentation
May 10, 2023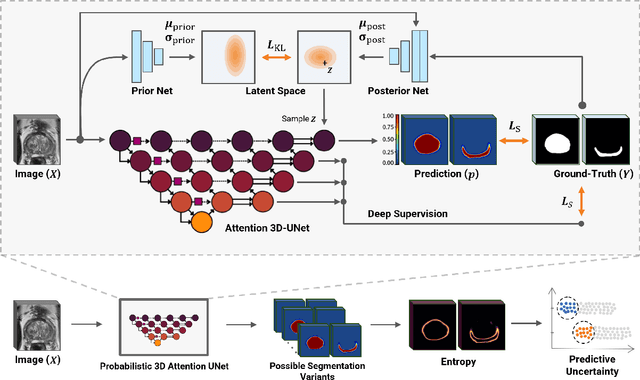
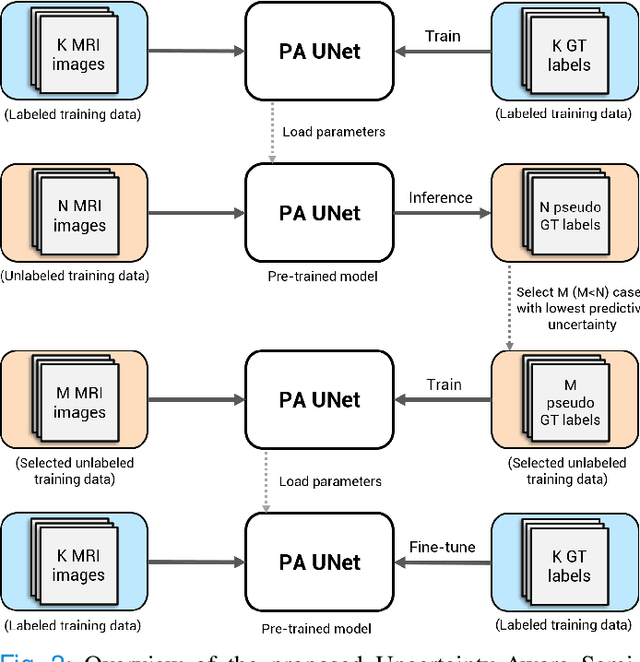
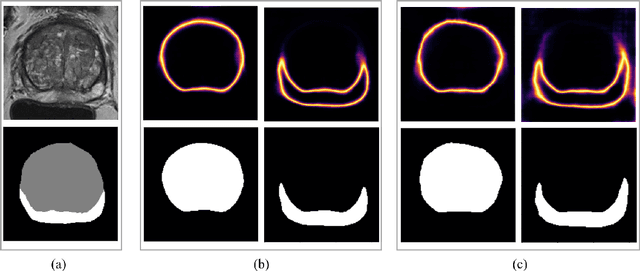
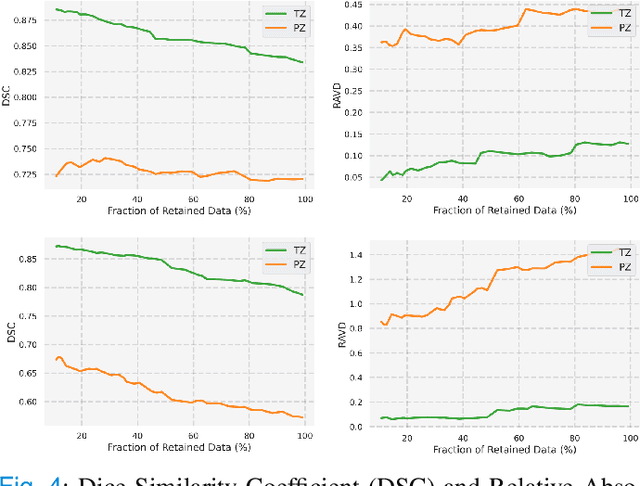
Quality of deep convolutional neural network predictions strongly depends on the size of the training dataset and the quality of the annotations. Creating annotations, especially for 3D medical image segmentation, is time-consuming and requires expert knowledge. We propose a novel semi-supervised learning (SSL) approach that requires only a relatively small number of annotations while being able to use the remaining unlabeled data to improve model performance. Our method uses a pseudo-labeling technique that employs recent deep learning uncertainty estimation models. By using the estimated uncertainty, we were able to rank pseudo-labels and automatically select the best pseudo-annotations generated by the supervised model. We applied this to prostate zonal segmentation in T2-weighted MRI scans. Our proposed model outperformed the semi-supervised model in experiments with the ProstateX dataset and an external test set, by leveraging only a subset of unlabeled data rather than the full collection of 4953 cases, our proposed model demonstrated improved performance. The segmentation dice similarity coefficient in the transition zone and peripheral zone increased from 0.835 and 0.727 to 0.852 and 0.751, respectively, for fully supervised model and the uncertainty-aware semi-supervised learning model (USSL). Our USSL model demonstrates the potential to allow deep learning models to be trained on large datasets without requiring full annotation. Our code is available at https://github.com/DIAGNijmegen/prostateMR-USSL.
Autonomous Stabilization of Retinal Videos for Streamlining Assessment of Spontaneous Venous Pulsations
May 10, 2023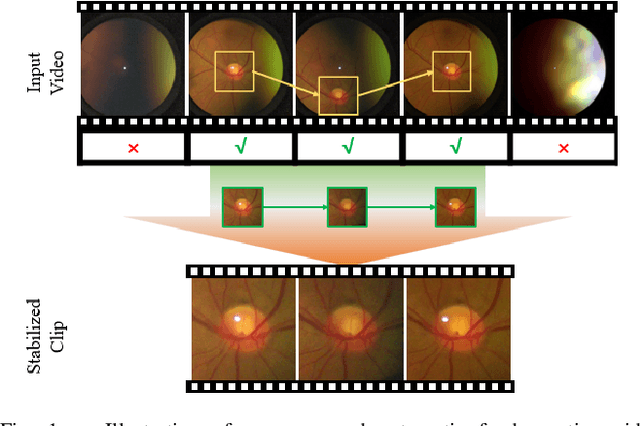
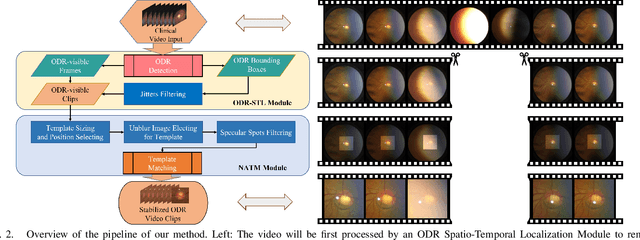
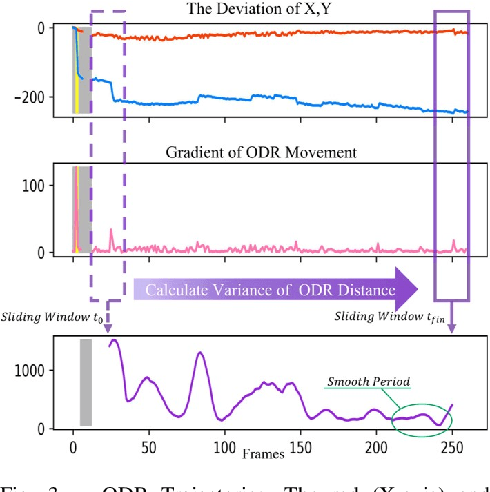
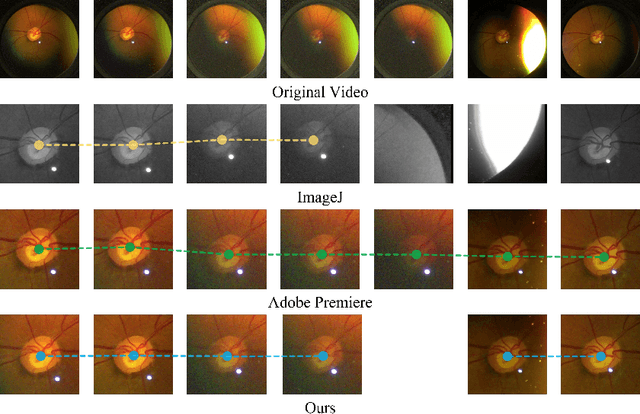
Spontaneous retinal Venous Pulsations (SVP) are rhythmic changes in the caliber of the central retinal vein and are observed in the optic disc region (ODR) of the retina. Its absence is a critical indicator of various ocular or neurological abnormalities. Recent advances in imaging technology have enabled the development of portable smartphone-based devices for observing the retina and assessment of SVPs. However, the quality of smartphone-based retinal videos is often poor due to noise and image jitting, which in return, can severely obstruct the observation of SVPs. In this work, we developed a fully automated retinal video stabilization method that enables the examination of SVPs captured by various mobile devices. Specifically, we first propose an ODR Spatio-Temporal Localization (ODR-STL) module to localize visible ODR and remove noisy and jittering frames. Then, we introduce a Noise-Aware Template Matching (NATM) module to stabilize high-quality video segments at a fixed position in the field of view. After the processing, the SVPs can be easily observed in the stabilized videos, significantly facilitating user observations. Furthermore, our method is cost-effective and has been tested in both subjective and objective evaluations. Both of the evaluations support its effectiveness in facilitating the observation of SVPs. This can improve the timely diagnosis and treatment of associated diseases, making it a valuable tool for eye health professionals.
Regularization of polynomial networks for image recognition
Mar 24, 2023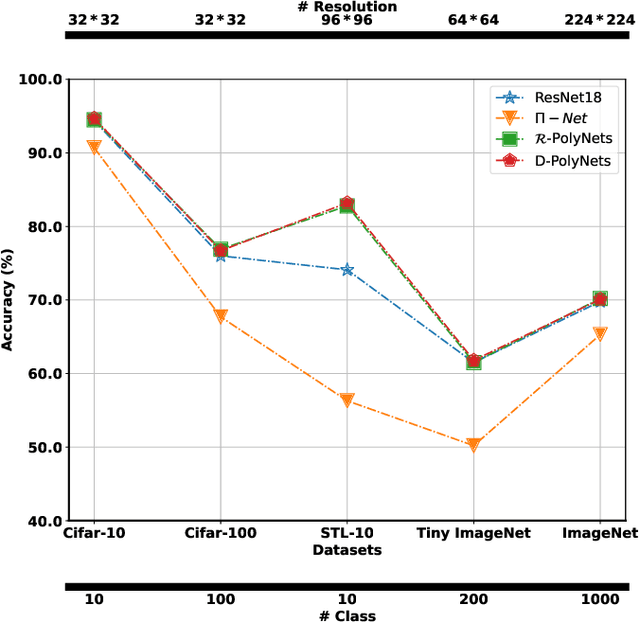
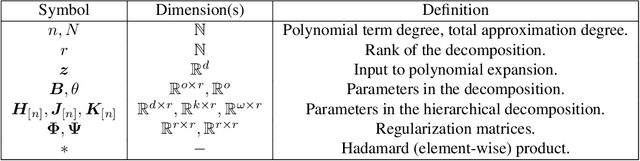
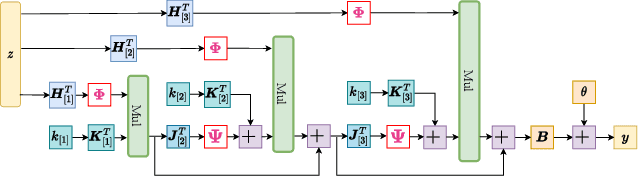
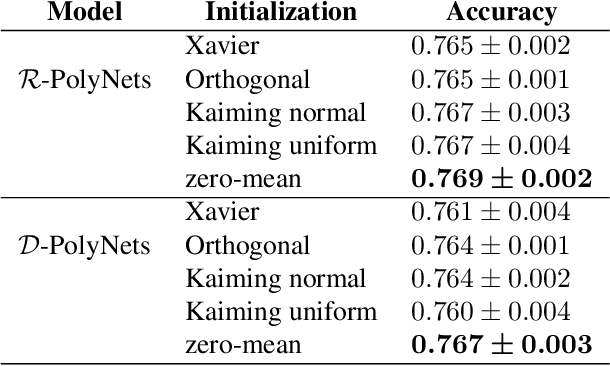
Deep Neural Networks (DNNs) have obtained impressive performance across tasks, however they still remain as black boxes, e.g., hard to theoretically analyze. At the same time, Polynomial Networks (PNs) have emerged as an alternative method with a promising performance and improved interpretability but have yet to reach the performance of the powerful DNN baselines. In this work, we aim to close this performance gap. We introduce a class of PNs, which are able to reach the performance of ResNet across a range of six benchmarks. We demonstrate that strong regularization is critical and conduct an extensive study of the exact regularization schemes required to match performance. To further motivate the regularization schemes, we introduce D-PolyNets that achieve a higher-degree of expansion than previously proposed polynomial networks. D-PolyNets are more parameter-efficient while achieving a similar performance as other polynomial networks. We expect that our new models can lead to an understanding of the role of elementwise activation functions (which are no longer required for training PNs). The source code is available at https://github.com/grigorisg9gr/regularized_polynomials.
TriPINet: Tripartite Progressive Integration Network for Image Manipulation Localization
Dec 25, 2022Image manipulation localization aims at distinguishing forged regions from the whole test image. Although many outstanding prior arts have been proposed for this task, there are still two issues that need to be further studied: 1) how to fuse diverse types of features with forgery clues; 2) how to progressively integrate multistage features for better localization performance. In this paper, we propose a tripartite progressive integration network (TriPINet) for end-to-end image manipulation localization. First, we extract both visual perception information, e.g., RGB input images, and visual imperceptible features, e.g., frequency and noise traces for forensic feature learning. Second, we develop a guided cross-modality dual-attention (gCMDA) module to fuse different types of forged clues. Third, we design a set of progressive integration squeeze-and-excitation (PI-SE) modules to improve localization performance by appropriately incorporating multiscale features in the decoder. Extensive experiments are conducted to compare our method with state-of-the-art image forensics approaches. The proposed TriPINet obtains competitive results on several benchmark datasets.
LiDAR2Map: In Defense of LiDAR-Based Semantic Map Construction Using Online Camera Distillation
Apr 22, 2023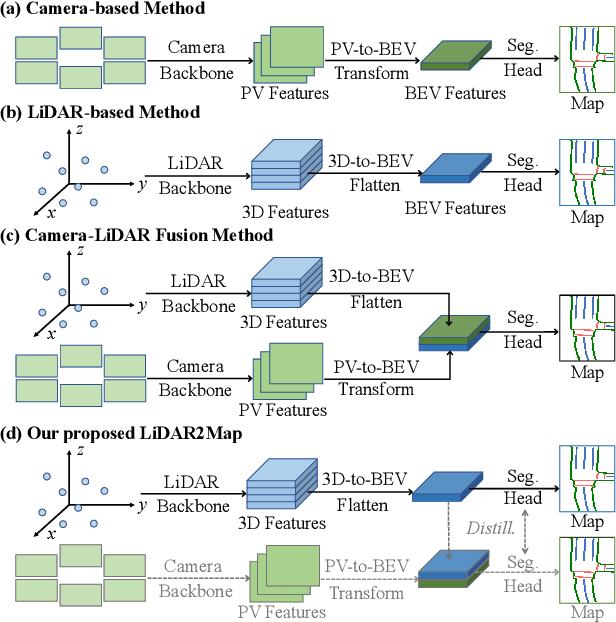
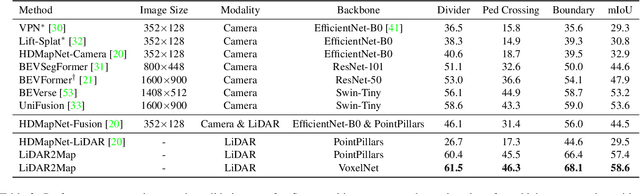
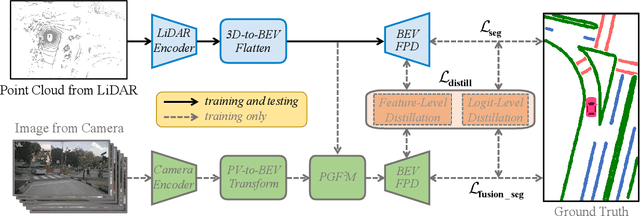
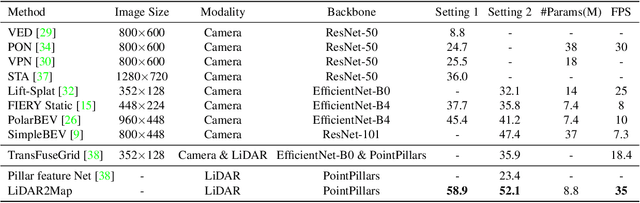
Semantic map construction under bird's-eye view (BEV) plays an essential role in autonomous driving. In contrast to camera image, LiDAR provides the accurate 3D observations to project the captured 3D features onto BEV space inherently. However, the vanilla LiDAR-based BEV feature often contains many indefinite noises, where the spatial features have little texture and semantic cues. In this paper, we propose an effective LiDAR-based method to build semantic map. Specifically, we introduce a BEV pyramid feature decoder that learns the robust multi-scale BEV features for semantic map construction, which greatly boosts the accuracy of the LiDAR-based method. To mitigate the defects caused by lacking semantic cues in LiDAR data, we present an online Camera-to-LiDAR distillation scheme to facilitate the semantic learning from image to point cloud. Our distillation scheme consists of feature-level and logit-level distillation to absorb the semantic information from camera in BEV. The experimental results on challenging nuScenes dataset demonstrate the efficacy of our proposed LiDAR2Map on semantic map construction, which significantly outperforms the previous LiDAR-based methods over 27.9% mIoU and even performs better than the state-of-the-art camera-based approaches. Source code is available at: https://github.com/songw-zju/LiDAR2Map.
PixCUE -- Joint Uncertainty Estimation and Image Reconstruction in MRI using Deep Pixel Classification
Feb 28, 2023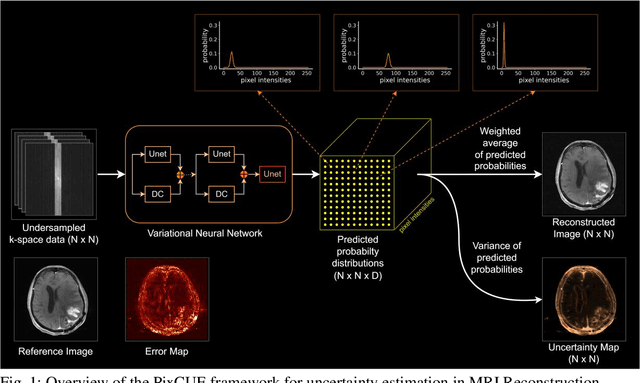
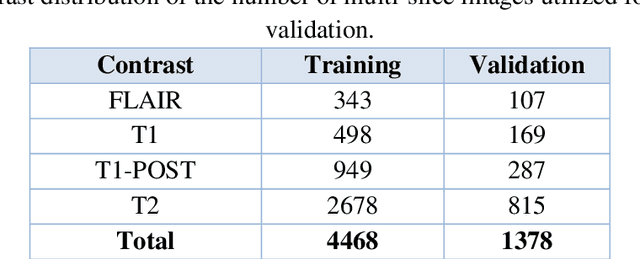
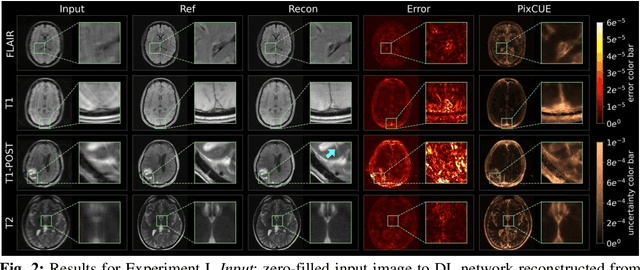
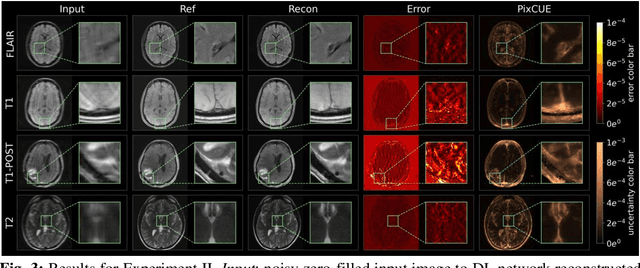
Deep learning (DL) models are capable of successfully exploiting latent representations in MR data and have become state-of-the-art for accelerated MRI reconstruction. However, undersampling the measurements in k-space as well as the over- or under-parameterized and non-transparent nature of DL make these models exposed to uncertainty. Consequently, uncertainty estimation has become a major issue in DL MRI reconstruction. To estimate uncertainty, Monte Carlo (MC) inference techniques have become a common practice where multiple reconstructions are utilized to compute the variance in reconstruction as a measurement of uncertainty. However, these methods demand high computational costs as they require multiple inferences through the DL model. To this end, we introduce a method to estimate uncertainty during MRI reconstruction using a pixel classification framework. The proposed method, PixCUE (stands for Pixel Classification Uncertainty Estimation) produces the reconstructed image along with an uncertainty map during a single forward pass through the DL model. We demonstrate that this approach generates uncertainty maps that highly correlate with the reconstruction errors with respect to various MR imaging sequences and under numerous adversarial conditions. We also show that the estimated uncertainties are correlated to that of the conventional MC method. We further provide an empirical relationship between the uncertainty estimations using PixCUE and well-established reconstruction metrics such as NMSE, PSNR, and SSIM. We conclude that PixCUE is capable of reliably estimating the uncertainty in MRI reconstruction with a minimum additional computational cost.
PMT-IQA: Progressive Multi-task Learning for Blind Image Quality Assessment
Jan 03, 2023
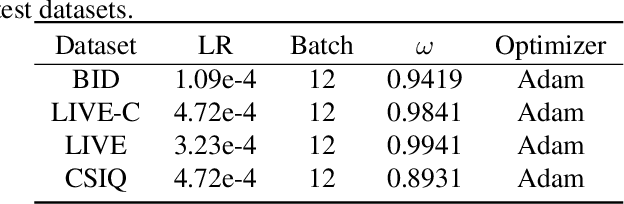
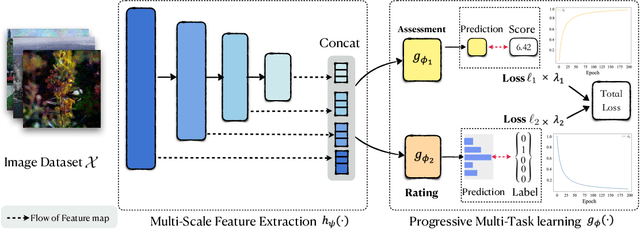
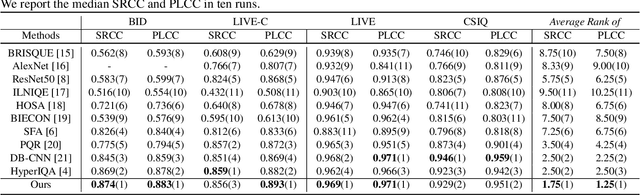
Blind image quality assessment (BIQA) remains challenging due to the diversity of distortion and image content variation, which complicate the distortion patterns crossing different scales and aggravate the difficulty of the regression problem for BIQA. However, existing BIQA methods often fail to consider multi-scale distortion patterns and image content, and little research has been done on learning strategies to make the regression model produce better performance. In this paper, we propose a simple yet effective Progressive Multi-Task Image Quality Assessment (PMT-IQA) model, which contains a multi-scale feature extraction module (MS) and a progressive multi-task learning module (PMT), to help the model learn complex distortion patterns and better optimize the regression issue to align with the law of human learning process from easy to hard. To verify the effectiveness of the proposed PMT-IQA model, we conduct experiments on four widely used public datasets, and the experimental results indicate that the performance of PMT-IQA is superior to the comparison approaches, and both MS and PMT modules improve the model's performance.