 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Gated Multi-Resolution Transfer Network for Burst Restoration and Enhancement
Apr 13, 2023
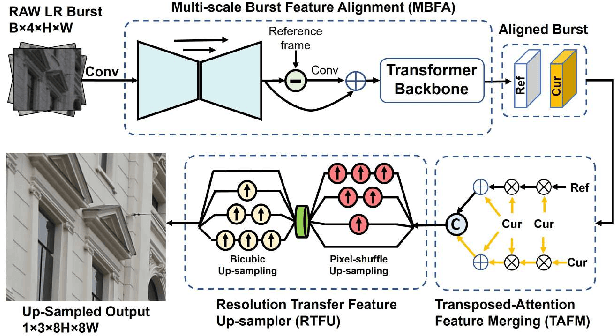
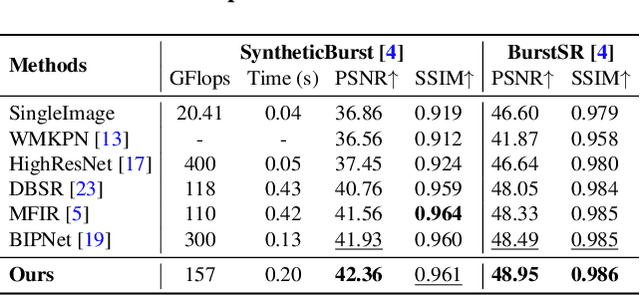
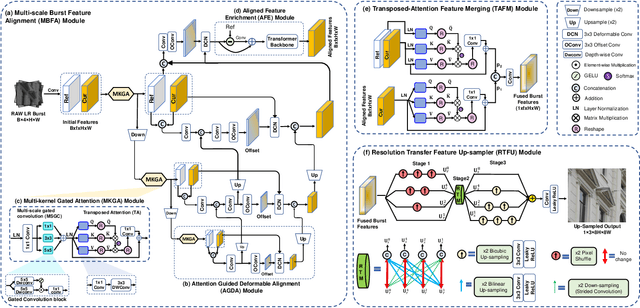
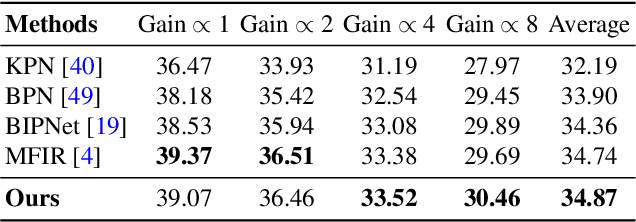
Burst image processing is becoming increasingly popular in recent years. However, it is a challenging task since individual burst images undergo multiple degradations and often have mutual misalignments resulting in ghosting and zipper artifacts. Existing burst restoration methods usually do not consider the mutual correlation and non-local contextual information among burst frames, which tends to limit these approaches in challenging cases. Another key challenge lies in the robust up-sampling of burst frames. The existing up-sampling methods cannot effectively utilize the advantages of single-stage and progressive up-sampling strategies with conventional and/or recent up-samplers at the same time. To address these challenges, we propose a novel Gated Multi-Resolution Transfer Network (GMTNet) to reconstruct a spatially precise high-quality image from a burst of low-quality raw images. GMTNet consists of three modules optimized for burst processing tasks: Multi-scale Burst Feature Alignment (MBFA) for feature denoising and alignment, Transposed-Attention Feature Merging (TAFM) for multi-frame feature aggregation, and Resolution Transfer Feature Up-sampler (RTFU) to up-scale merged features and construct a high-quality output image. Detailed experimental analysis on five datasets validates our approach and sets a state-of-the-art for burst super-resolution, burst denoising, and low-light burst enhancement.
OSRT: Omnidirectional Image Super-Resolution with Distortion-aware Transformer
Feb 07, 2023
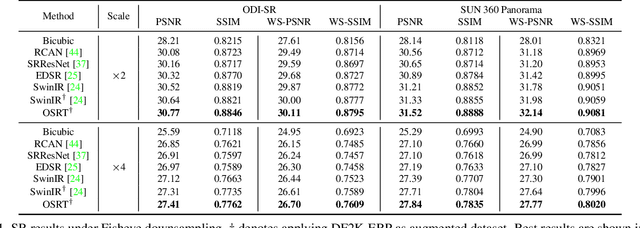
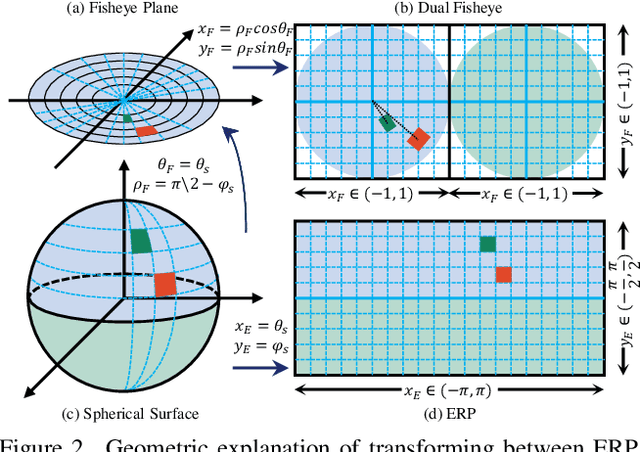
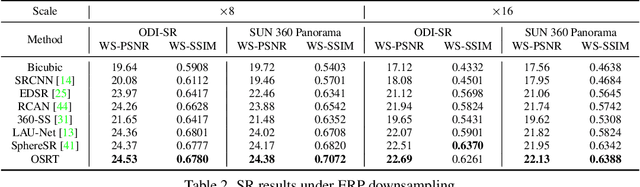
Omnidirectional images (ODIs) have obtained lots of research interest for immersive experiences. Although ODIs require extremely high resolution to capture details of the entire scene, the resolutions of most ODIs are insufficient. Previous methods attempt to solve this issue by image super-resolution (SR) on equirectangular projection (ERP) images. However, they omit geometric properties of ERP in the degradation process, and their models can hardly generalize to real ERP images. In this paper, we propose Fisheye downsampling, which mimics the real-world imaging process and synthesizes more realistic low-resolution samples. Then we design a distortion-aware Transformer (OSRT) to modulate ERP distortions continuously and self-adaptively. Without a cumbersome process, OSRT outperforms previous methods by about 0.2dB on PSNR. Moreover, we propose a convenient data augmentation strategy, which synthesizes pseudo ERP images from plain images. This simple strategy can alleviate the over-fitting problem of large networks and significantly boost the performance of ODISR. Extensive experiments have demonstrated the state-of-the-art performance of our OSRT. Codes and models will be available at https://github.com/Fanghua-Yu/OSRT.
Divided Attention: Unsupervised Multi-Object Discovery with Contextually Separated Slots
Apr 04, 2023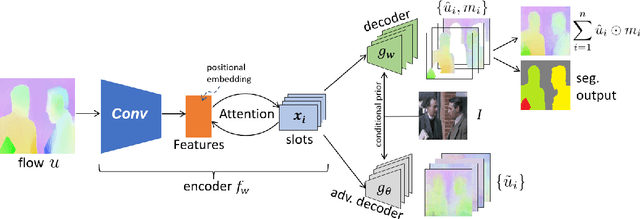
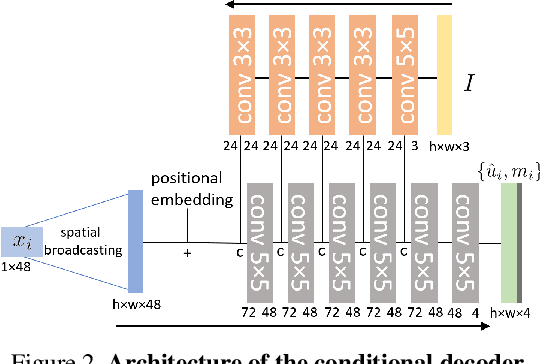
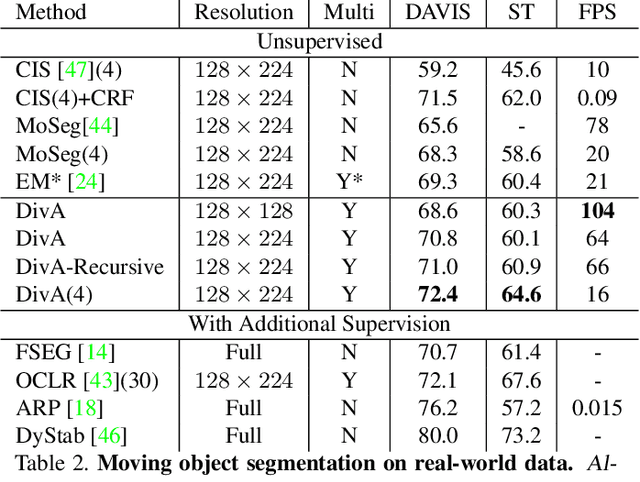

We introduce a method to segment the visual field into independently moving regions, trained with no ground truth or supervision. It consists of an adversarial conditional encoder-decoder architecture based on Slot Attention, modified to use the image as context to decode optical flow without attempting to reconstruct the image itself. In the resulting multi-modal representation, one modality (flow) feeds the encoder to produce separate latent codes (slots), whereas the other modality (image) conditions the decoder to generate the first (flow) from the slots. This design frees the representation from having to encode complex nuisance variability in the image due to, for instance, illumination and reflectance properties of the scene. Since customary autoencoding based on minimizing the reconstruction error does not preclude the entire flow from being encoded into a single slot, we modify the loss to an adversarial criterion based on Contextual Information Separation. The resulting min-max optimization fosters the separation of objects and their assignment to different attention slots, leading to Divided Attention, or DivA. DivA outperforms recent unsupervised multi-object motion segmentation methods while tripling run-time speed up to 104FPS and reducing the performance gap from supervised methods to 12% or less. DivA can handle different numbers of objects and different image sizes at training and test time, is invariant to permutation of object labels, and does not require explicit regularization.
Do humans and machines have the same eyes? Human-machine perceptual differences on image classification
Apr 18, 2023
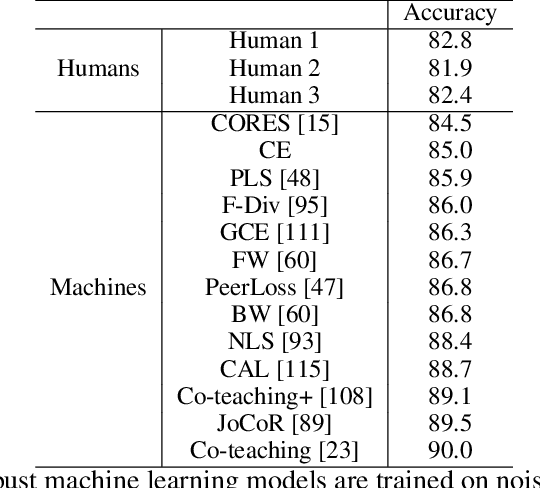
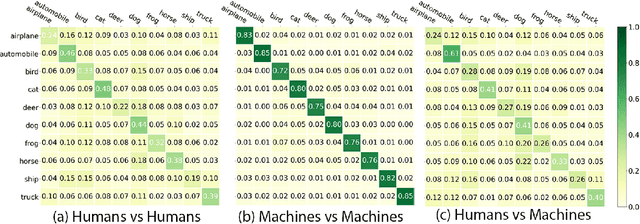
Trained computer vision models are assumed to solve vision tasks by imitating human behavior learned from training labels. Most efforts in recent vision research focus on measuring the model task performance using standardized benchmarks. Limited work has been done to understand the perceptual difference between humans and machines. To fill this gap, our study first quantifies and analyzes the statistical distributions of mistakes from the two sources. We then explore human vs. machine expertise after ranking tasks by difficulty levels. Even when humans and machines have similar overall accuracies, the distribution of answers may vary. Leveraging the perceptual difference between humans and machines, we empirically demonstrate a post-hoc human-machine collaboration that outperforms humans or machines alone.
Collection Space Navigator: An Interactive Visualization Interface for Multidimensional Datasets
May 11, 2023
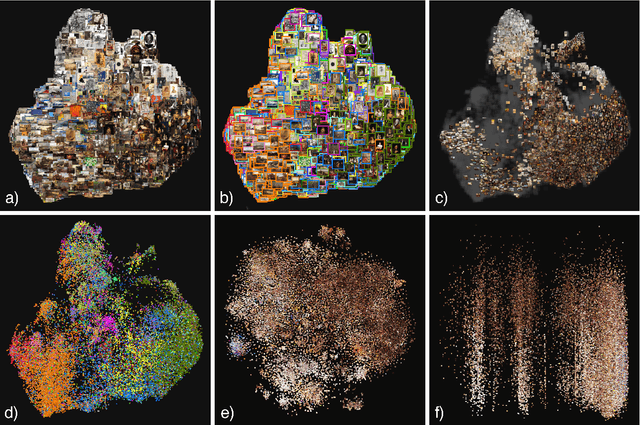
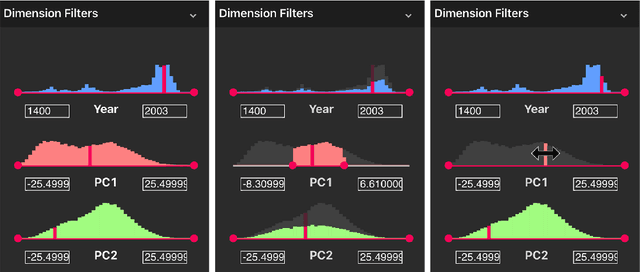
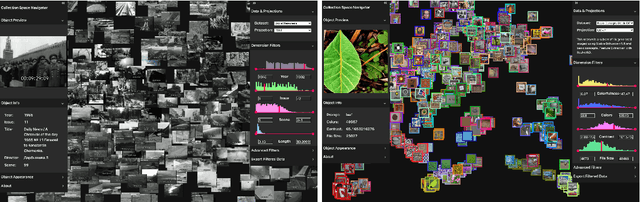
We introduce the Collection Space Navigator (CSN), a browser-based visualization tool to explore, research, and curate large collections of visual digital artifacts that are associated with multidimensional data, such as vector embeddings or tables of metadata. Media objects such as images are often encoded as numerical vectors, for e.g. based on metadata or using machine learning to embed image information. Yet, while such procedures are widespread for a range of applications, it remains a challenge to explore, analyze, and understand the resulting multidimensional spaces in a more comprehensive manner. Dimensionality reduction techniques such as t-SNE or UMAP often serve to project high-dimensional data into low dimensional visualizations, yet require interpretation themselves as the remaining dimensions are typically abstract. Here, the Collection Space Navigator provides a customizable interface that combines two-dimensional projections with a set of configurable multidimensional filters. As a result, the user is able to view and investigate collections, by zooming and scaling, by transforming between projections, by filtering dimensions via range sliders, and advanced text filters. Insights that are gained during the interaction can be fed back into the original data via ad hoc exports of filtered metadata and projections. This paper comes with a functional showcase demo using a large digitized collection of classical Western art. The Collection Space Navigator is open source. Users can reconfigure the interface to fit their own data and research needs, including projections and filter controls. The CSN is ready to serve a broad community.
Analyzing the Domain Shift Immunity of Deep Homography Estimation
Apr 19, 2023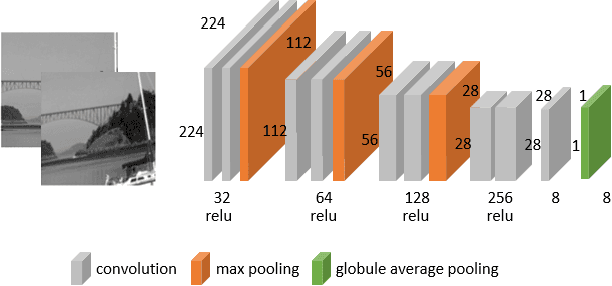



Homography estimation is a basic image-alignment method in many applications. Recently, with the development of convolutional neural networks (CNNs), some learning based approaches have shown great success in this task. However, the performance across different domains has never been researched. Unlike other common tasks (\eg, classification, detection, segmentation), CNN based homography estimation models show a domain shift immunity, which means a model can be trained on one dataset and tested on another without any transfer learning. To explain this unusual performance, we need to determine how CNNs estimate homography. In this study, we first show the domain shift immunity of different deep homography estimation models. We then use a shallow network with a specially designed dataset to analyze the features used for estimation. The results show that networks use low-level texture information to estimate homography. We also design some experiments to compare the performance between different texture densities and image features distorted on some common datasets to demonstrate our findings. Based on these findings, we provide an explanation of the domain shift immunity of deep homography estimation.
ContraCluster: Learning to Classify without Labels by Contrastive Self-Supervision and Prototype-Based Semi-Supervision
Apr 19, 2023
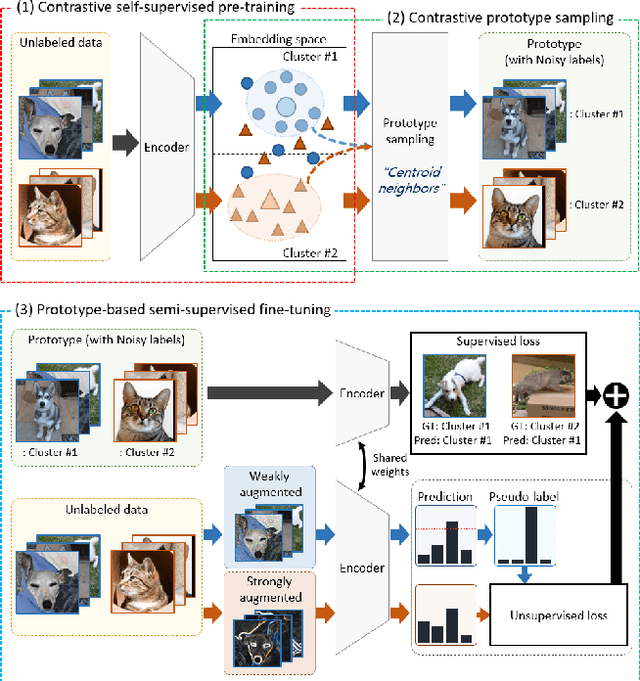
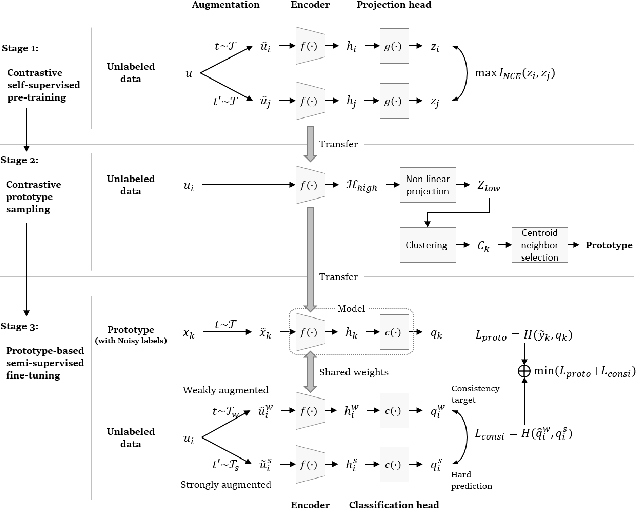
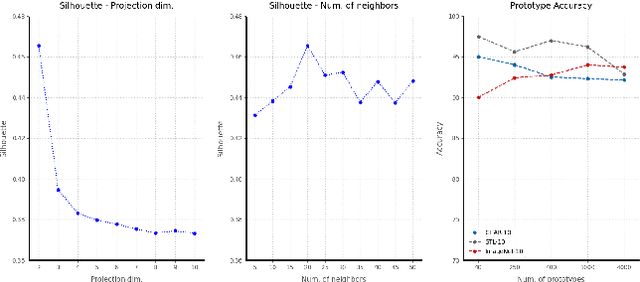
The recent advances in representation learning inspire us to take on the challenging problem of unsupervised image classification tasks in a principled way. We propose ContraCluster, an unsupervised image classification method that combines clustering with the power of contrastive self-supervised learning. ContraCluster consists of three stages: (1) contrastive self-supervised pre-training (CPT), (2) contrastive prototype sampling (CPS), and (3) prototype-based semi-supervised fine-tuning (PB-SFT). CPS can select highly accurate, categorically prototypical images in an embedding space learned by contrastive learning. We use sampled prototypes as noisy labeled data to perform semi-supervised fine-tuning (PB-SFT), leveraging small prototypes and large unlabeled data to further enhance the accuracy. We demonstrate empirically that ContraCluster achieves new state-of-the-art results for standard benchmark datasets including CIFAR-10, STL-10, and ImageNet-10. For example, ContraCluster achieves about 90.8% accuracy for CIFAR-10, which outperforms DAC (52.2%), IIC (61.7%), and SCAN (87.6%) by a large margin. Without any labels, ContraCluster can achieve a 90.8% accuracy that is comparable to 95.8% by the best supervised counterpart.
* Accepted at ICPR 2022
LiDAR2Map: In Defense of LiDAR-Based Semantic Map Construction Using Online Camera Distillation
Apr 22, 2023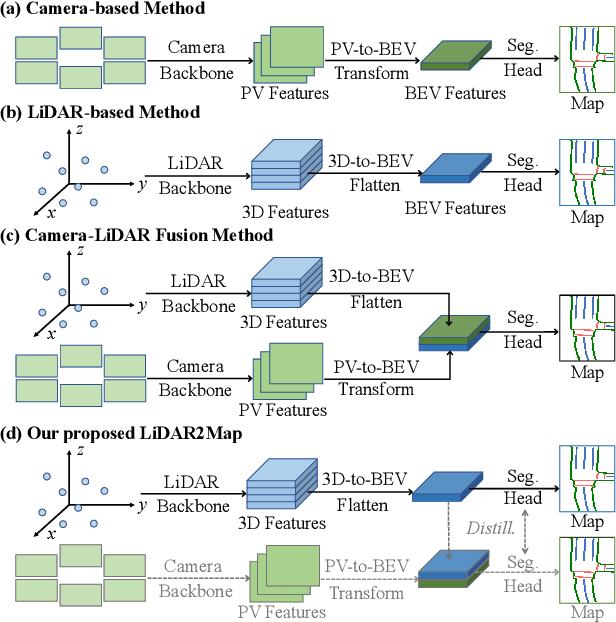
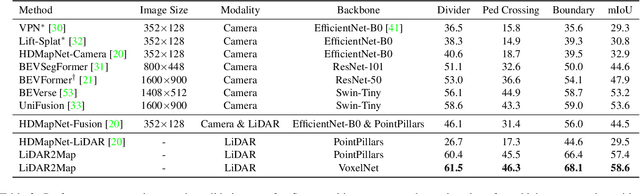
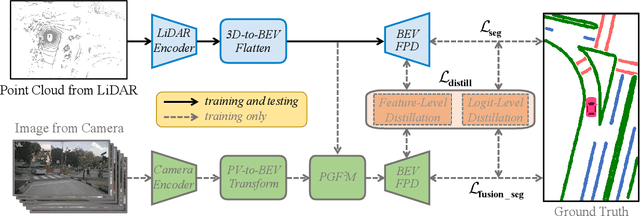
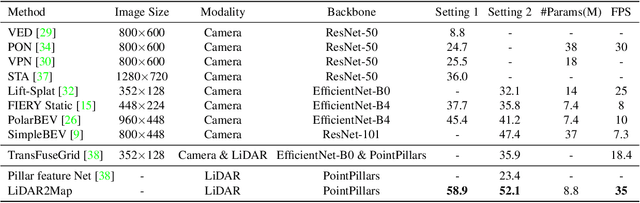
Semantic map construction under bird's-eye view (BEV) plays an essential role in autonomous driving. In contrast to camera image, LiDAR provides the accurate 3D observations to project the captured 3D features onto BEV space inherently. However, the vanilla LiDAR-based BEV feature often contains many indefinite noises, where the spatial features have little texture and semantic cues. In this paper, we propose an effective LiDAR-based method to build semantic map. Specifically, we introduce a BEV pyramid feature decoder that learns the robust multi-scale BEV features for semantic map construction, which greatly boosts the accuracy of the LiDAR-based method. To mitigate the defects caused by lacking semantic cues in LiDAR data, we present an online Camera-to-LiDAR distillation scheme to facilitate the semantic learning from image to point cloud. Our distillation scheme consists of feature-level and logit-level distillation to absorb the semantic information from camera in BEV. The experimental results on challenging nuScenes dataset demonstrate the efficacy of our proposed LiDAR2Map on semantic map construction, which significantly outperforms the previous LiDAR-based methods over 27.9% mIoU and even performs better than the state-of-the-art camera-based approaches. Source code is available at: https://github.com/songw-zju/LiDAR2Map.
SSTM: Spatiotemporal Recurrent Transformers for Multi-frame Optical Flow Estimation
Apr 26, 2023

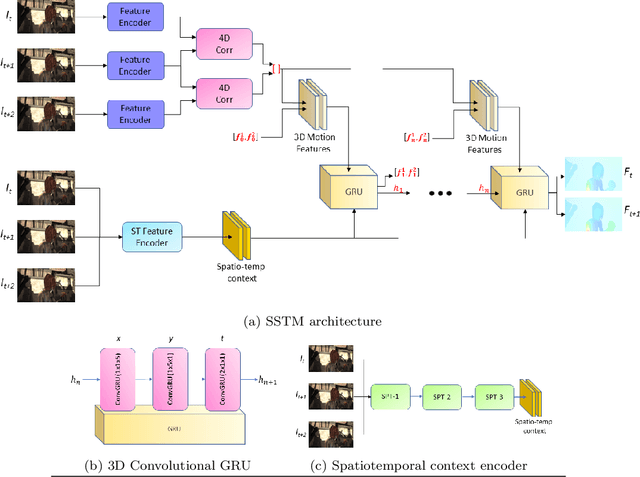
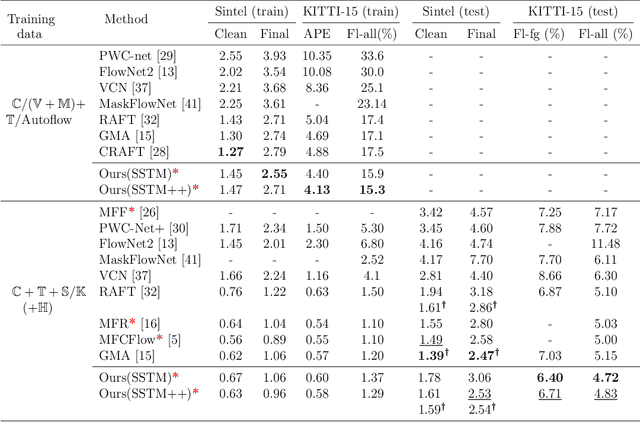
Inaccurate optical flow estimates in and near occluded regions, and out-of-boundary regions are two of the current significant limitations of optical flow estimation algorithms. Recent state-of-the-art optical flow estimation algorithms are two-frame based methods where optical flow is estimated sequentially for each consecutive image pair in a sequence. While this approach gives good flow estimates, it fails to generalize optical flows in occluded regions mainly due to limited local evidence regarding moving elements in a scene. In this work, we propose a learning-based multi-frame optical flow estimation method that estimates two or more consecutive optical flows in parallel from multi-frame image sequences. Our underlying hypothesis is that by understanding temporal scene dynamics from longer sequences with more than two frames, we can characterize pixel-wise dependencies in a larger spatiotemporal domain, generalize complex motion patterns and thereby improve the accuracy of optical flow estimates in occluded regions. We present learning-based spatiotemporal recurrent transformers for multi-frame based optical flow estimation (SSTMs). Our method utilizes 3D Convolutional Gated Recurrent Units (3D-ConvGRUs) and spatiotemporal transformers to learn recurrent space-time motion dynamics and global dependencies in the scene and provide a generalized optical flow estimation. When compared with recent state-of-the-art two-frame and multi-frame methods on real world and synthetic datasets, performance of the SSTMs were significantly higher in occluded and out-of-boundary regions. Among all published state-of-the-art multi-frame methods, SSTM achieved state-of the-art results on the Sintel Final and KITTI2015 benchmark datasets.
Can SAM Boost Video Super-Resolution?
May 12, 2023
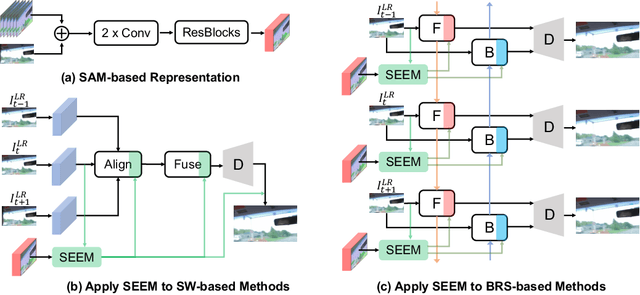

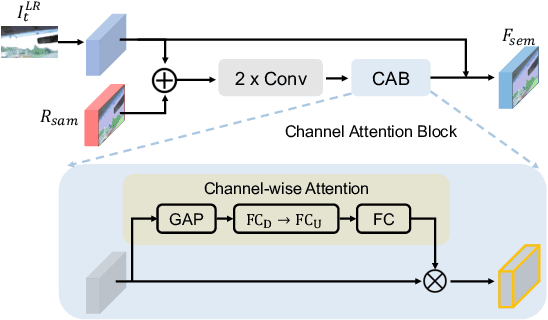
The primary challenge in video super-resolution (VSR) is to handle large motions in the input frames, which makes it difficult to accurately aggregate information from multiple frames. Existing works either adopt deformable convolutions or estimate optical flow as a prior to establish correspondences between frames for the effective alignment and fusion. However, they fail to take into account the valuable semantic information that can greatly enhance it; and flow-based methods heavily rely on the accuracy of a flow estimate model, which may not provide precise flows given two low-resolution frames. In this paper, we investigate a more robust and semantic-aware prior for enhanced VSR by utilizing the Segment Anything Model (SAM), a powerful foundational model that is less susceptible to image degradation. To use the SAM-based prior, we propose a simple yet effective module -- SAM-guidEd refinEment Module (SEEM), which can enhance both alignment and fusion procedures by the utilization of semantic information. This light-weight plug-in module is specifically designed to not only leverage the attention mechanism for the generation of semantic-aware feature but also be easily and seamlessly integrated into existing methods. Concretely, we apply our SEEM to two representative methods, EDVR and BasicVSR, resulting in consistently improved performance with minimal implementation effort, on three widely used VSR datasets: Vimeo-90K, REDS and Vid4. More importantly, we found that the proposed SEEM can advance the existing methods in an efficient tuning manner, providing increased flexibility in adjusting the balance between performance and the number of training parameters. Code will be open-source soon.