 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Restoring Images Captured in Arbitrary Hybrid Adverse Weather Conditions in One Go
May 17, 2023
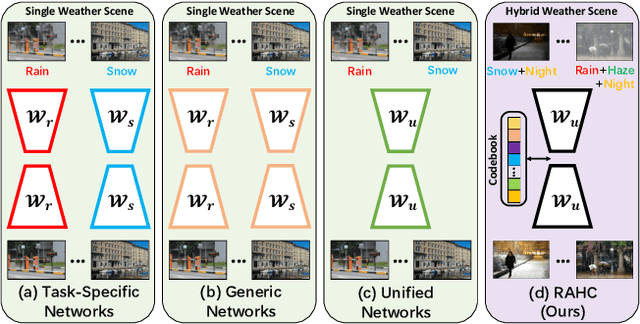
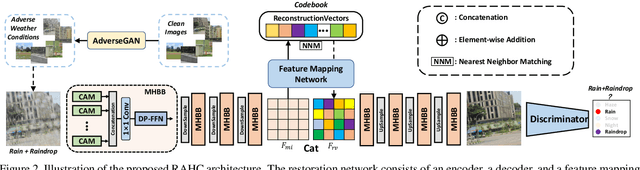
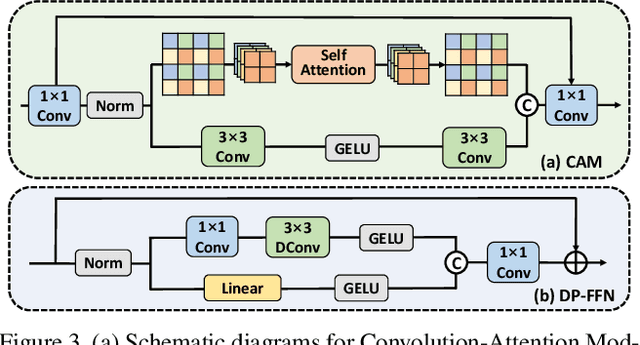
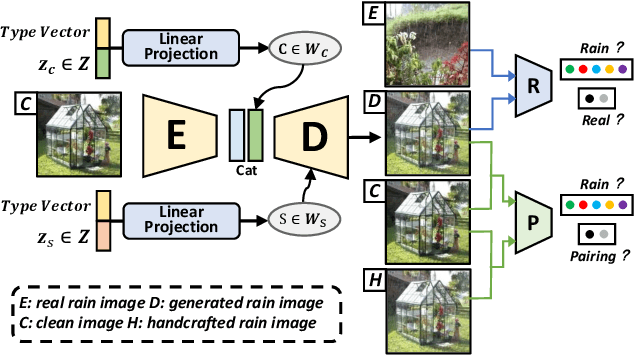
Adverse conditions typically suffer from stochastic hybrid weather degradations (e.g., rainy and hazy night), while existing image restoration algorithms envisage that weather degradations occur independently, thus may fail to handle real-world complicated scenarios. Besides, supervised training is not feasible due to the lack of comprehensive paired dataset to characterize hybrid conditions. To this end, we have advanced the forementioned limitations with two tactics: framework and data. On the one hand, we present a novel unified framework, dubbed RAHC, to Restore Arbitrary Hybrid adverse weather Conditions in one go, which can comfortably cope with hybrid scenarios with insufficient remaining background constituents and restore arbitrary hybrid conditions with a single trained model flexibly. On the other hand, we establish a new dataset, termed HAC, for learning and benchmarking arbitrary Hybrid Adverse Conditions restoration. HAC contains 31 scenarios composed of an arbitrary combination of five common weather, with a total of ~316K adverse-weather/clean pairs. As for fabrication, the training set is automatically generated by a dedicated AdverseGAN with no-frills labor, while the test set is manually modulated by experts for authoritative evaluation. Extensive experiments yield superior results and in particular establish new state-of-the-art results on both HAC and conventional datasets.
State Representation Learning Using an Unbalanced Atlas
May 17, 2023

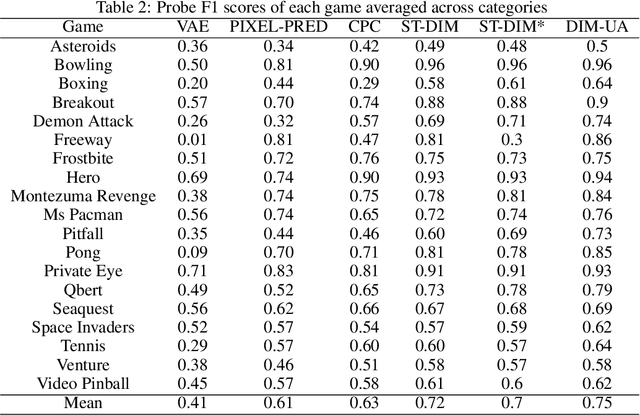
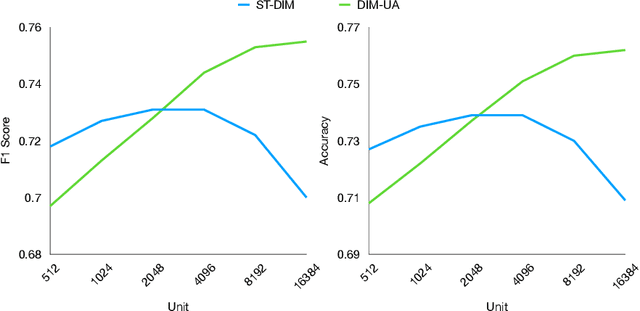
The manifold hypothesis posits that high-dimensional data often lies on a lower-dimensional manifold and that utilizing this manifold as the target space yields more efficient representations. While numerous traditional manifold-based techniques exist for dimensionality reduction, their application in self-supervised learning has witnessed slow progress. The recent MSIMCLR method combines manifold encoding with SimCLR but requires extremely low target encoding dimensions to outperform SimCLR, limiting its applicability. This paper introduces a novel learning paradigm using an unbalanced atlas (UA), capable of surpassing state-of-the-art self-supervised learning approaches. We meticulously investigated and engineered the DeepInfomax with an unbalanced atlas (DIM-UA) method by systematically adapting the Spatiotemporal DeepInfomax (ST-DIM) framework to align with our proposed UA paradigm, employing rigorous scientific methodologies throughout the process. The efficacy of DIM-UA is demonstrated through training and evaluation on the Atari Annotated RAM Interface (AtariARI) benchmark, a modified version of the Atari 2600 framework that produces annotated image samples for representation learning. The UA paradigm improves the existing algorithm significantly when the number of target encoding dimensions grows. For instance, the mean F1 score averaged over categories of DIM-UA is ~75% compared to ~70% of ST-DIM when using 16384 hidden units.
Dynamic Structural Brain Network Construction by Hierarchical Prototype Embedding GCN using T1-MRI
May 17, 2023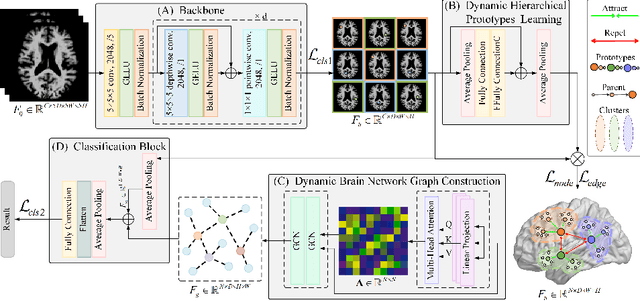
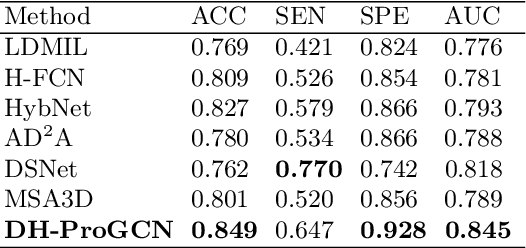
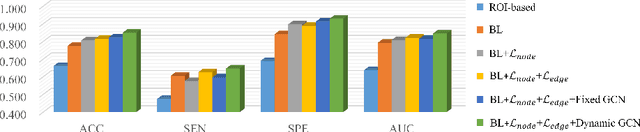
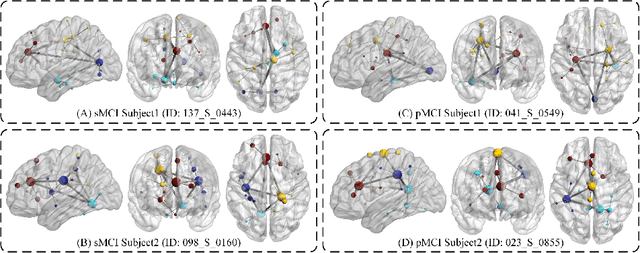
Constructing structural brain networks using T1-weighted magnetic resonance imaging (T1-MRI) presents a significant challenge due to the lack of direct regional connectivity information. Current methods with T1-MRI rely on predefined regions or isolated pretrained location modules to obtain atrophic regions, which neglects individual specificity. Besides, existing methods capture global structural context only on the whole-image-level, which weaken correlation between regions and the hierarchical distribution nature of brain connectivity.We hereby propose a novel dynamic structural brain network construction method based on T1-MRI, which can dynamically localize critical regions and constrain the hierarchical distribution among them for constructing dynamic structural brain network. Specifically, we first cluster spatially-correlated channel and generate several critical brain regions as prototypes. Further, we introduce a contrastive loss function to constrain the prototypes distribution, which embed the hierarchical brain semantic structure into the latent space. Self-attention and GCN are then used to dynamically construct hierarchical correlations of critical regions for brain network and explore the correlation, respectively. Our method is evaluated on ADNI-1 and ADNI-2 databases for mild cognitive impairment (MCI) conversion prediction, and acheive the state-of-the-art (SOTA) performance. Our source code is available at http://github.com/*******.
Using Spatio-Temporal Dual-Stream Network with Self-Supervised Learning for Lung Tumor Classification on Radial Probe Endobronchial Ultrasound Video
May 07, 2023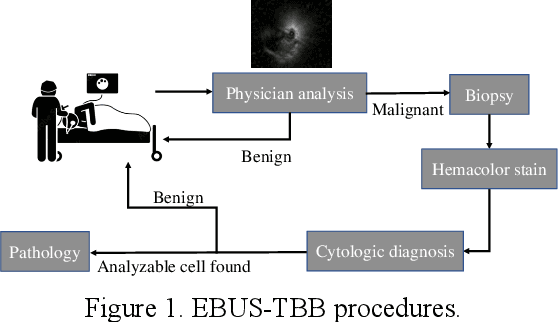
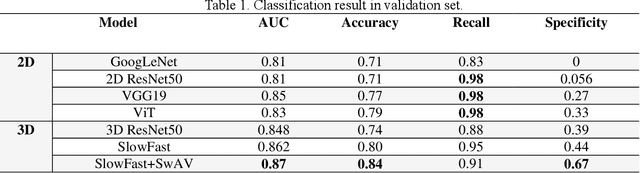
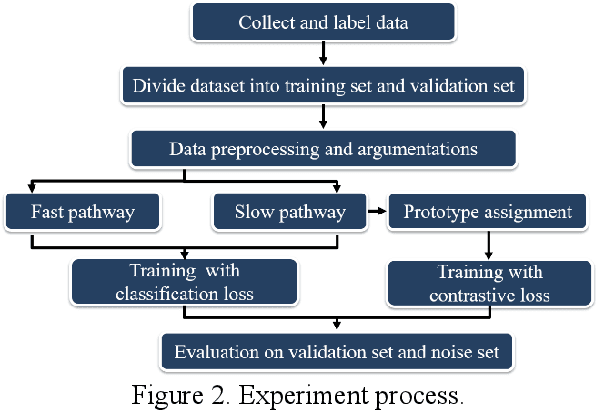
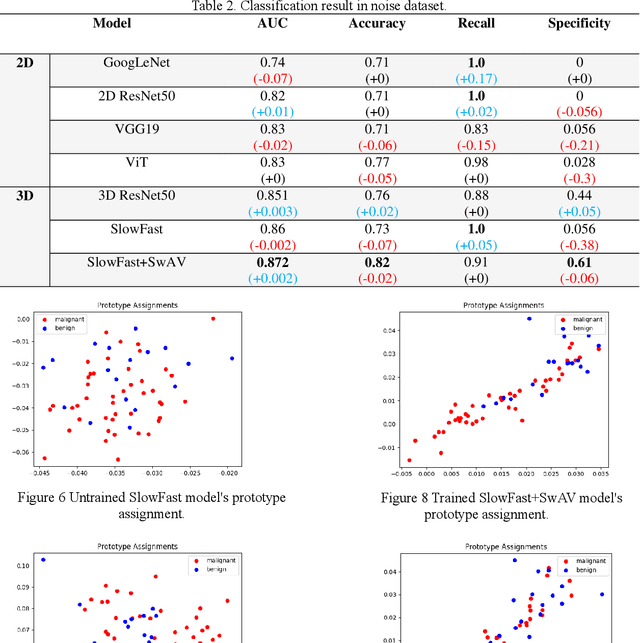
The purpose of this study is to develop a computer-aided diagnosis system for classifying benign and malignant lung lesions, and to assist physicians in real-time analysis of radial probe endobronchial ultrasound (EBUS) videos. During the biopsy process of lung cancer, physicians use real-time ultrasound images to find suitable lesion locations for sampling. However, most of these images are difficult to classify and contain a lot of noise. Previous studies have employed 2D convolutional neural networks to effectively differentiate between benign and malignant lung lesions, but doctors still need to manually select good-quality images, which can result in additional labor costs. In addition, the 2D neural network has no ability to capture the temporal information of the ultrasound video, so it is difficult to obtain the relationship between the features of the continuous images. This study designs an automatic diagnosis system based on a 3D neural network, uses the SlowFast architecture as the backbone to fuse temporal and spatial features, and uses the SwAV method of contrastive learning to enhance the noise robustness of the model. The method we propose includes the following advantages, such as (1) using clinical ultrasound films as model input, thereby reducing the need for high-quality image selection by physicians, (2) high-accuracy classification of benign and malignant lung lesions can assist doctors in clinical diagnosis and reduce the time and risk of surgery, and (3) the capability to classify well even in the presence of significant image noise. The AUC, accuracy, precision, recall and specificity of our proposed method on the validation set reached 0.87, 83.87%, 86.96%, 90.91% and 66.67%, respectively. The results have verified the importance of incorporating temporal information and the effectiveness of using the method of contrastive learning on feature extraction.
Discovering the Effectiveness of Pre-Training in a Large-scale Car-sharing Platform
May 02, 2023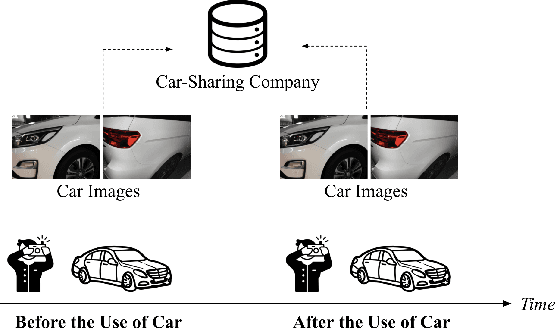

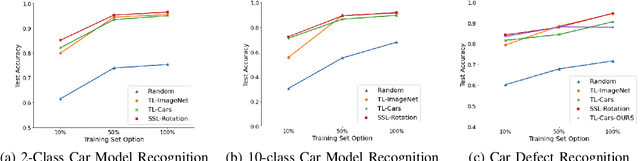
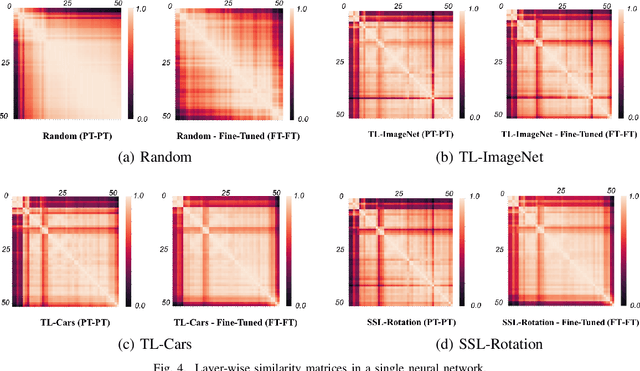
Recent progress of deep learning has empowered various intelligent transportation applications, especially in car-sharing platforms. While the traditional operations of the car-sharing service highly relied on human engagements in fleet management, modern car-sharing platforms let users upload car images before and after their use to inspect the cars without a physical visit. To automate the aforementioned inspection task, prior approaches utilized deep neural networks. They commonly employed pre-training, a de-facto technique to establish an effective model under the limited number of labeled datasets. As candidate practitioners who deal with car images would presumably get suffered from the lack of a labeled dataset, we analyzed a sophisticated analogy into the effectiveness of pre-training is important. However, prior studies primarily shed a little spotlight on the effectiveness of pre-training. Motivated by the aforementioned lack of analysis, our study proposes a series of analyses to unveil the effectiveness of various pre-training methods in image recognition tasks at the car-sharing platform. We set two real-world image recognition tasks in the car-sharing platform in a live service, established them under the many-shot and few-shot problem settings, and scrutinized which pre-training method accomplishes the most effective performance in which setting. Furthermore, we analyzed how does the pre-training and fine-tuning convey different knowledge to the neural networks for a precise understanding.
Augmentation-based Domain Generalization for Semantic Segmentation
Apr 24, 2023
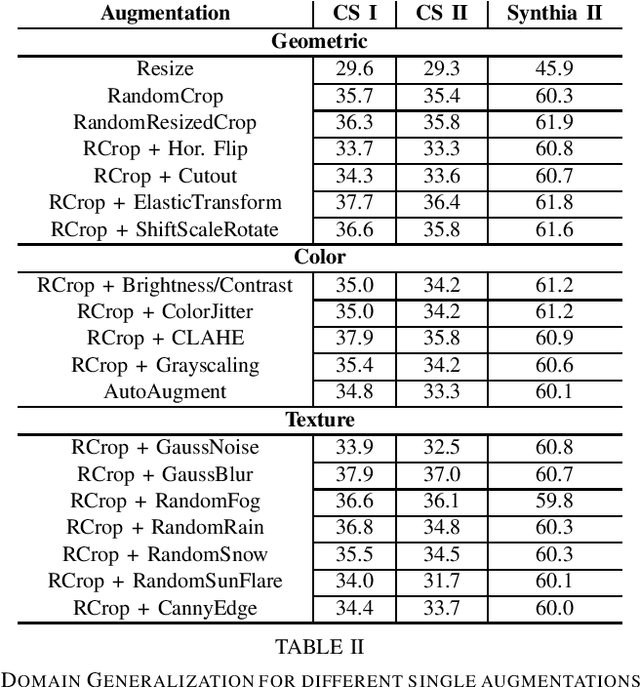
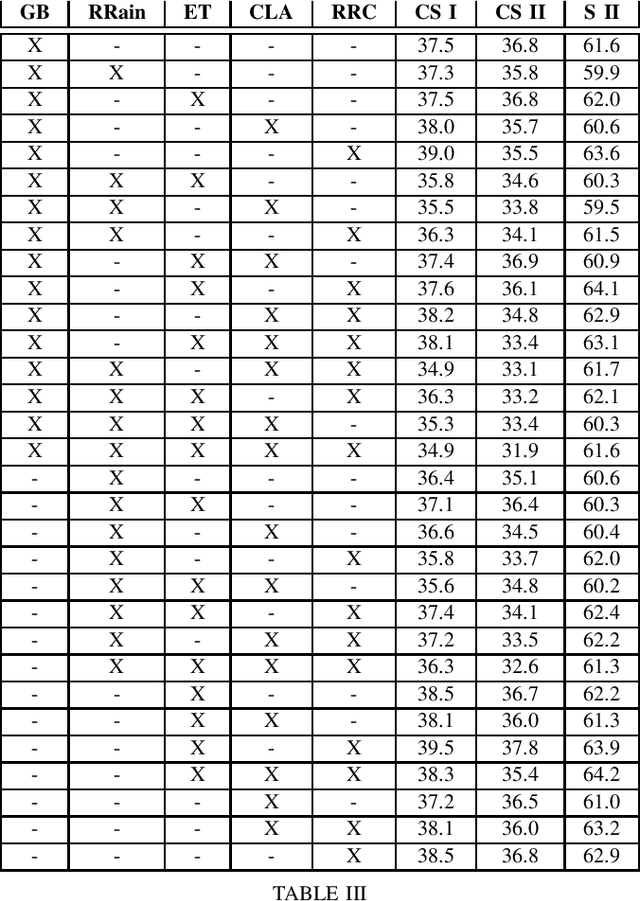
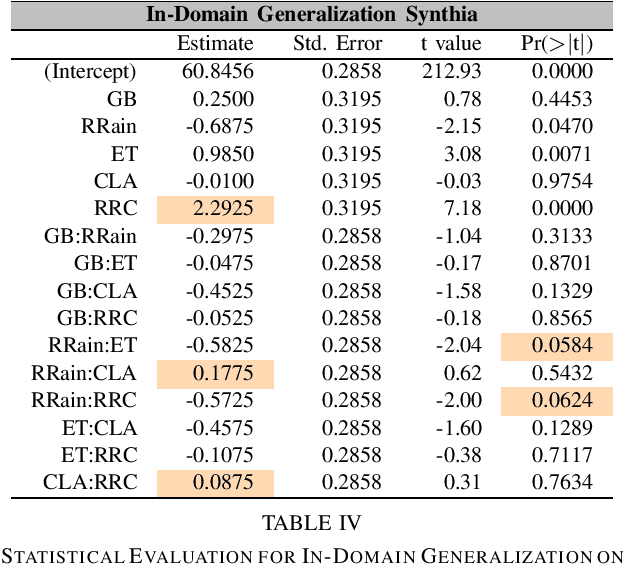
Unsupervised Domain Adaptation (UDA) and domain generalization (DG) are two research areas that aim to tackle the lack of generalization of Deep Neural Networks (DNNs) towards unseen domains. While UDA methods have access to unlabeled target images, domain generalization does not involve any target data and only learns generalized features from a source domain. Image-style randomization or augmentation is a popular approach to improve network generalization without access to the target domain. Complex methods are often proposed that disregard the potential of simple image augmentations for out-of-domain generalization. For this reason, we systematically study the in- and out-of-domain generalization capabilities of simple, rule-based image augmentations like blur, noise, color jitter and many more. Based on a full factorial design of experiment design we provide a systematic statistical evaluation of augmentations and their interactions. Our analysis provides both, expected and unexpected, outcomes. Expected, because our experiments confirm the common scientific standard that combination of multiple different augmentations out-performs single augmentations. Unexpected, because combined augmentations perform competitive to state-of-the-art domain generalization approaches, while being significantly simpler and without training overhead. On the challenging synthetic-to-real domain shift between Synthia and Cityscapes we reach 39.5% mIoU compared to 40.9% mIoU of the best previous work. When additionally employing the recent vision transformer architecture DAFormer we outperform these benchmarks with a performance of 44.2% mIoU
Comments on 'Fast and scalable search of whole-slide images via self-supervised deep learning'
Apr 18, 2023Chen et al. [Chen2022] recently published the article 'Fast and scalable search of whole-slide images via self-supervised deep learning' in Nature Biomedical Engineering. The authors call their method 'self-supervised image search for histology', short SISH. We express our concerns that SISH is an incremental modification of Yottixel, has used MinMax binarization but does not cite the original works, and is based on a misnomer 'self-supervised image search'. As well, we point to several other concerns regarding experiments and comparisons performed by Chen et al.
Measuring Progress in Fine-grained Vision-and-Language Understanding
May 12, 2023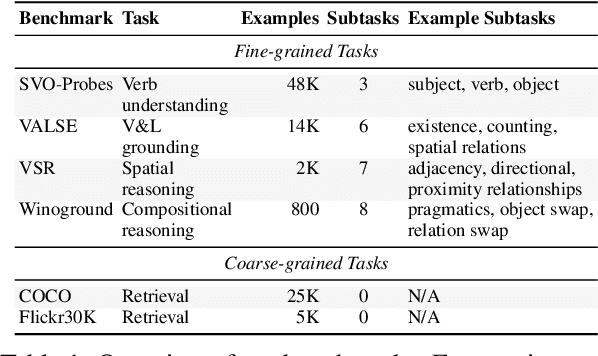
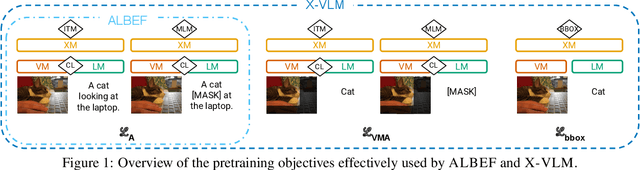

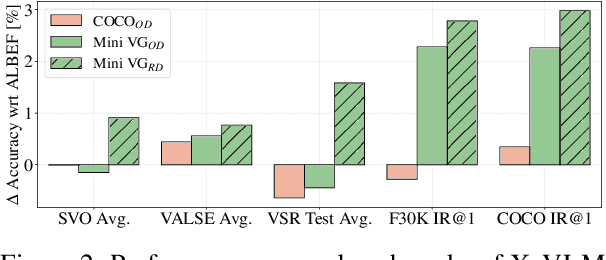
While pretraining on large-scale image-text data from the Web has facilitated rapid progress on many vision-and-language (V&L) tasks, recent work has demonstrated that pretrained models lack "fine-grained" understanding, such as the ability to recognise relationships, verbs, and numbers in images. This has resulted in an increased interest in the community to either develop new benchmarks or models for such capabilities. To better understand and quantify progress in this direction, we investigate four competitive V&L models on four fine-grained benchmarks. Through our analysis, we find that X-VLM (Zeng et al., 2022) consistently outperforms other baselines, and that modelling innovations can impact performance more than scaling Web data, which even degrades performance sometimes. Through a deeper investigation of X-VLM, we highlight the importance of both novel losses and rich data sources for learning fine-grained skills. Finally, we inspect training dynamics, and discover that for some tasks, performance peaks early in training or significantly fluctuates, never converging.
Stratified Adversarial Robustness with Rejection
May 12, 2023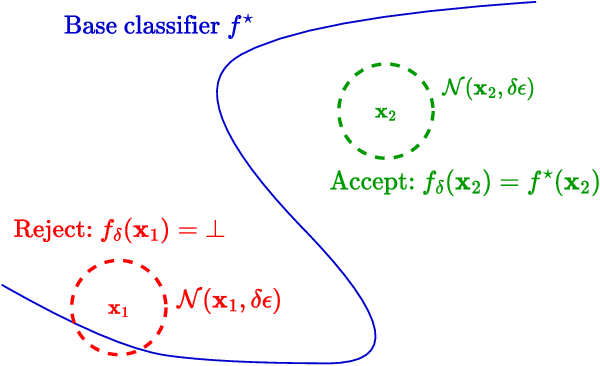
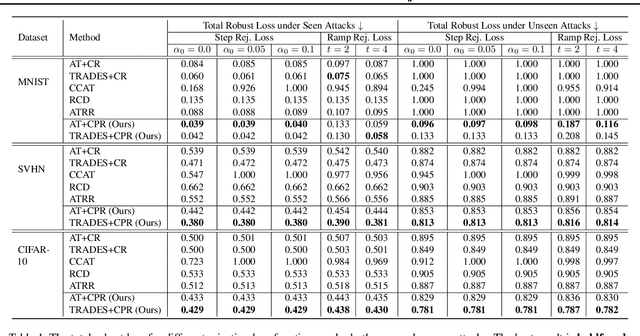
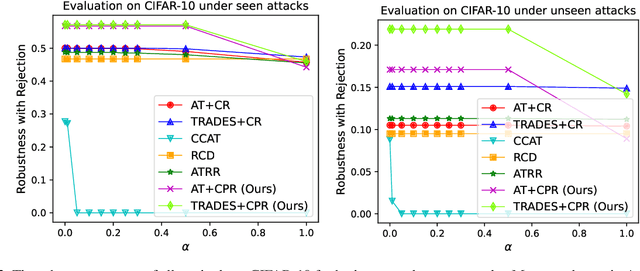
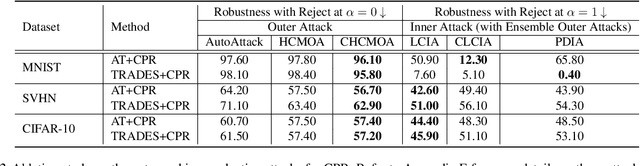
Recently, there is an emerging interest in adversarially training a classifier with a rejection option (also known as a selective classifier) for boosting adversarial robustness. While rejection can incur a cost in many applications, existing studies typically associate zero cost with rejecting perturbed inputs, which can result in the rejection of numerous slightly-perturbed inputs that could be correctly classified. In this work, we study adversarially-robust classification with rejection in the stratified rejection setting, where the rejection cost is modeled by rejection loss functions monotonically non-increasing in the perturbation magnitude. We theoretically analyze the stratified rejection setting and propose a novel defense method -- Adversarial Training with Consistent Prediction-based Rejection (CPR) -- for building a robust selective classifier. Experiments on image datasets demonstrate that the proposed method significantly outperforms existing methods under strong adaptive attacks. For instance, on CIFAR-10, CPR reduces the total robust loss (for different rejection losses) by at least 7.3% under both seen and unseen attacks.
Controllable Image Captioning via Prompting
Dec 04, 2022

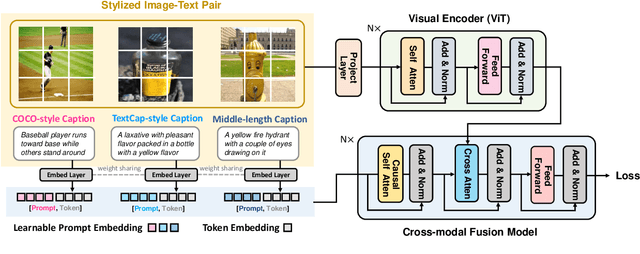
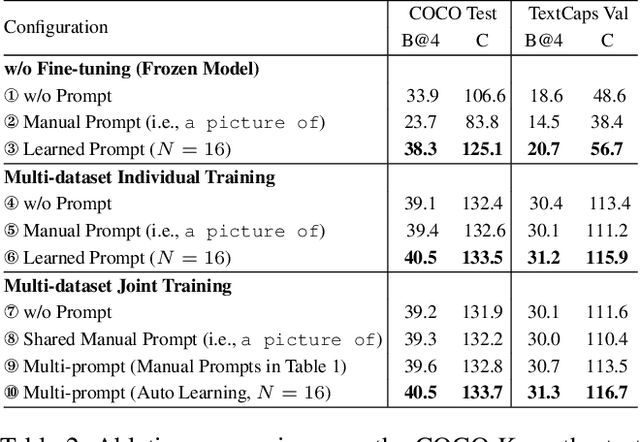
Despite the remarkable progress of image captioning, existing captioners typically lack the controllable capability to generate desired image captions, e.g., describing the image in a rough or detailed manner, in a factual or emotional view, etc. In this paper, we show that a unified model is qualified to perform well in diverse domains and freely switch among multiple styles. Such a controllable capability is achieved by embedding the prompt learning into the image captioning framework. To be specific, we design a set of prompts to fine-tune the pre-trained image captioner. These prompts allow the model to absorb stylized data from different domains for joint training, without performance degradation in each domain. Furthermore, we optimize the prompts with learnable vectors in the continuous word embedding space, avoiding the heuristic prompt engineering and meanwhile exhibiting superior performance. In the inference stage, our model is able to generate desired stylized captions by choosing the corresponding prompts. Extensive experiments verify the controllable capability of the proposed method. Notably, we achieve outstanding performance on two diverse image captioning benchmarks including COCO Karpathy split and TextCaps using a unified model.