 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Discriminative Co-Saliency and Background Mining Transformer for Co-Salient Object Detection
May 06, 2023
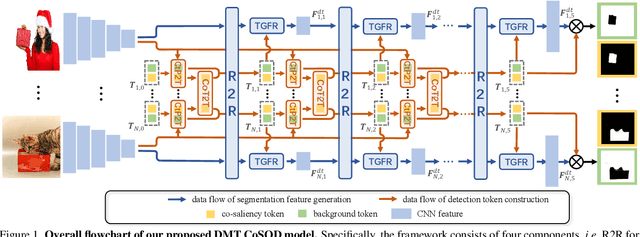
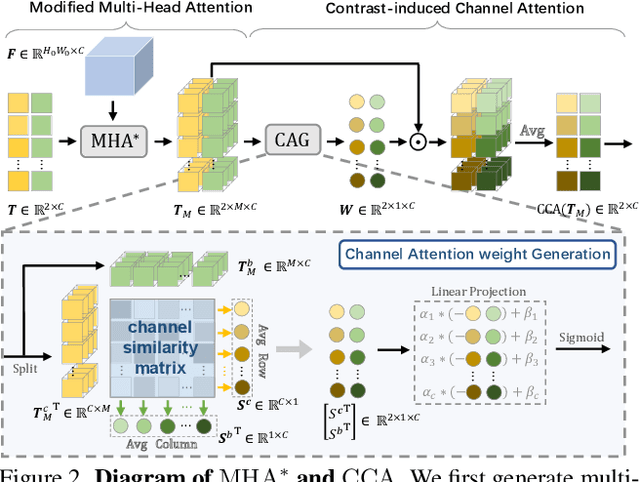
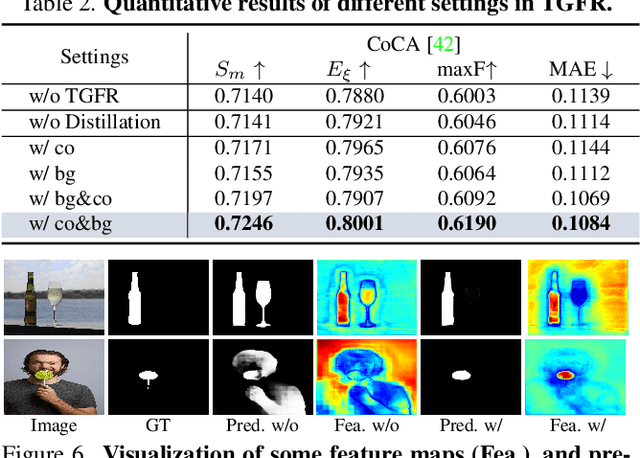
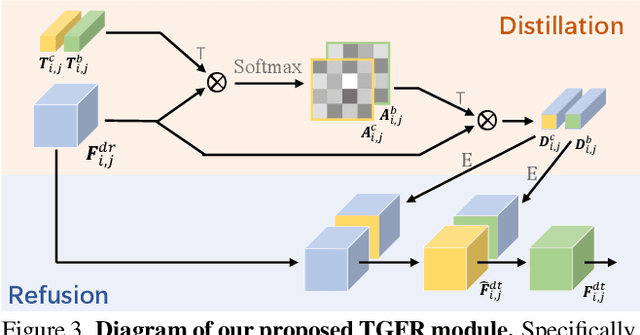
Most previous co-salient object detection works mainly focus on extracting co-salient cues via mining the consistency relations across images while ignoring explicit exploration of background regions. In this paper, we propose a Discriminative co-saliency and background Mining Transformer framework (DMT) based on several economical multi-grained correlation modules to explicitly mine both co-saliency and background information and effectively model their discrimination. Specifically, we first propose a region-to-region correlation module for introducing inter-image relations to pixel-wise segmentation features while maintaining computational efficiency. Then, we use two types of pre-defined tokens to mine co-saliency and background information via our proposed contrast-induced pixel-to-token correlation and co-saliency token-to-token correlation modules. We also design a token-guided feature refinement module to enhance the discriminability of the segmentation features under the guidance of the learned tokens. We perform iterative mutual promotion for the segmentation feature extraction and token construction. Experimental results on three benchmark datasets demonstrate the effectiveness of our proposed method. The source code is available at: https://github.com/dragonlee258079/DMT.
Improved Techniques for Maximum Likelihood Estimation for Diffusion ODEs
May 06, 2023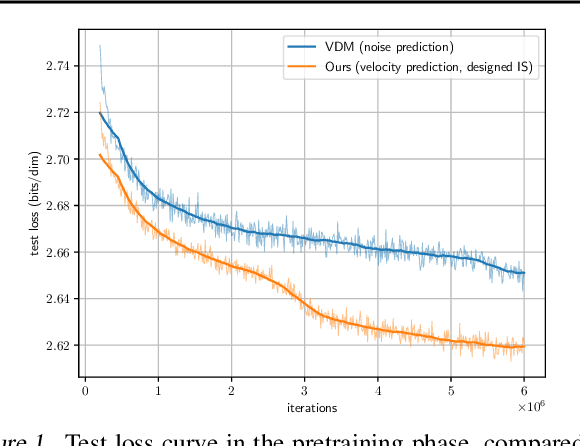

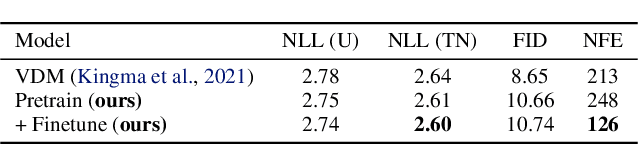
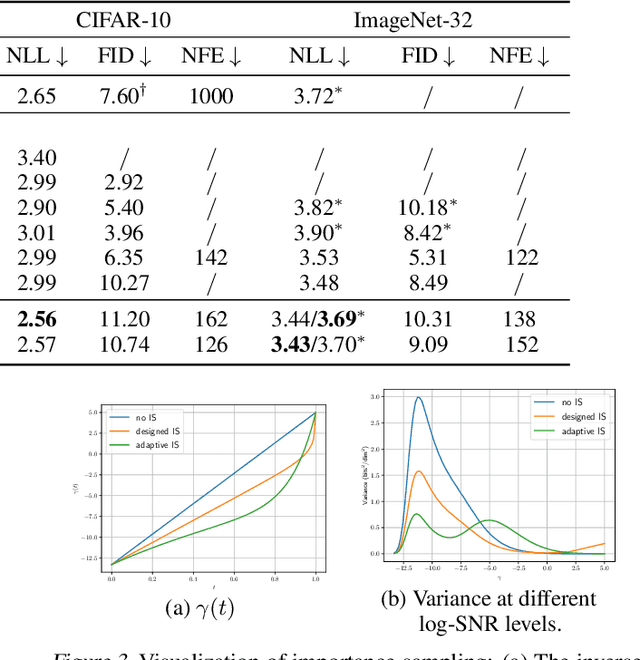
Diffusion models have exhibited excellent performance in various domains. The probability flow ordinary differential equation (ODE) of diffusion models (i.e., diffusion ODEs) is a particular case of continuous normalizing flows (CNFs), which enables deterministic inference and exact likelihood evaluation. However, the likelihood estimation results by diffusion ODEs are still far from those of the state-of-the-art likelihood-based generative models. In this work, we propose several improved techniques for maximum likelihood estimation for diffusion ODEs, including both training and evaluation perspectives. For training, we propose velocity parameterization and explore variance reduction techniques for faster convergence. We also derive an error-bounded high-order flow matching objective for finetuning, which improves the ODE likelihood and smooths its trajectory. For evaluation, we propose a novel training-free truncated-normal dequantization to fill the training-evaluation gap commonly existing in diffusion ODEs. Building upon these techniques, we achieve state-of-the-art likelihood estimation results on image datasets (2.56 on CIFAR-10, 3.43 on ImageNet-32) without variational dequantization or data augmentation.
Multimodal-driven Talking Face Generation via a Unified Diffusion-based Generator
May 09, 2023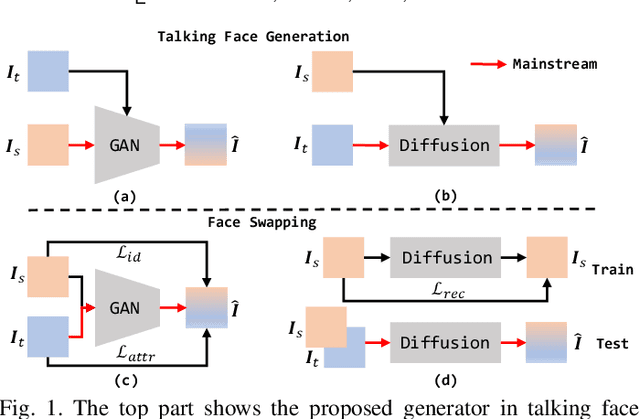
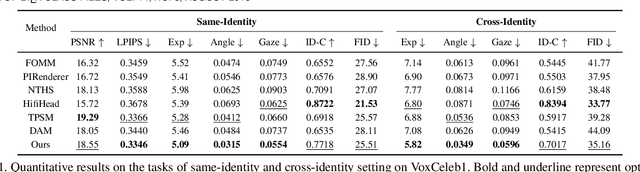
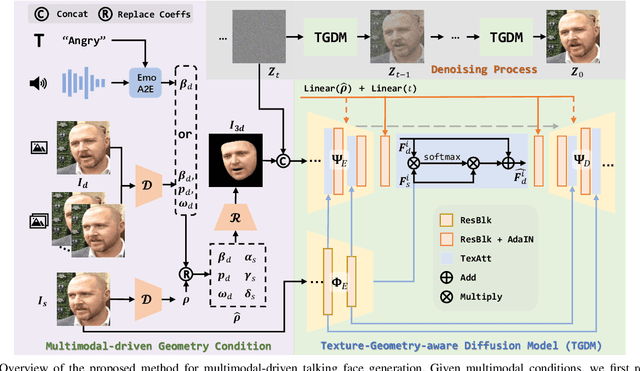
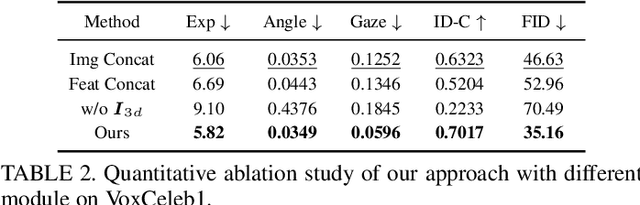
Multimodal-driven talking face generation refers to animating a portrait with the given pose, expression, and gaze transferred from the driving image and video, or estimated from the text and audio. However, existing methods ignore the potential of text modal, and their generators mainly follow the source-oriented feature rearrange paradigm coupled with unstable GAN frameworks. In this work, we first represent the emotion in the text prompt, which could inherit rich semantics from the CLIP, allowing flexible and generalized emotion control. We further reorganize these tasks as the target-oriented texture transfer and adopt the Diffusion Models. More specifically, given a textured face as the source and the rendered face projected from the desired 3DMM coefficients as the target, our proposed Texture-Geometry-aware Diffusion Model decomposes the complex transfer problem into multi-conditional denoising process, where a Texture Attention-based module accurately models the correspondences between appearance and geometry cues contained in source and target conditions, and incorporate extra implicit information for high-fidelity talking face generation. Additionally, TGDM can be gracefully tailored for face swapping. We derive a novel paradigm free of unstable seesaw-style optimization, resulting in simple, stable, and effective training and inference schemes. Extensive experiments demonstrate the superiority of our method.
Neuralizer: General Neuroimage Analysis without Re-Training
May 09, 2023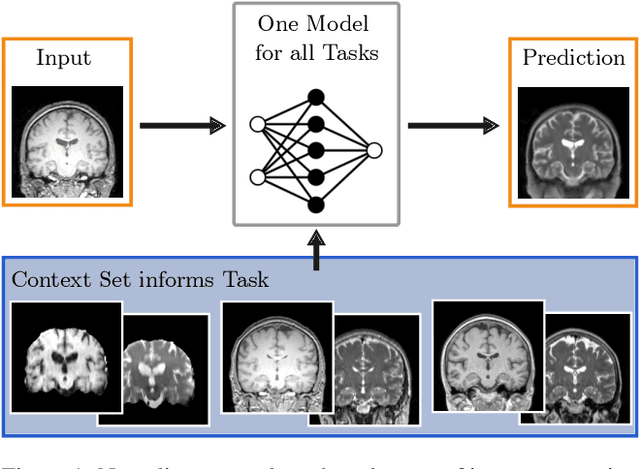
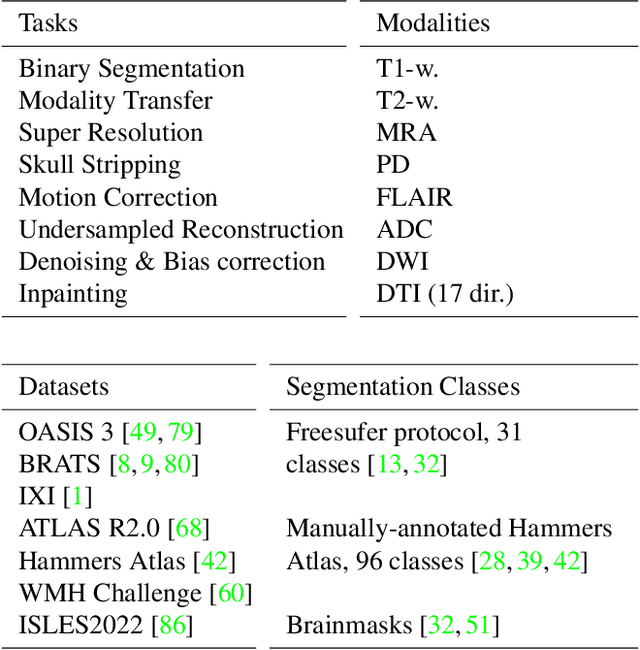
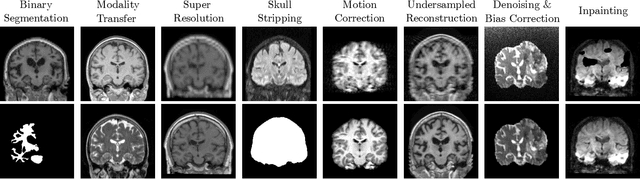

Neuroimage processing tasks like segmentation, reconstruction, and registration are central to the study of neuroscience. Robust deep learning strategies and architectures used to solve these tasks are often similar. Yet, when presented with a new task or a dataset with different visual characteristics, practitioners most often need to train a new model, or fine-tune an existing one. This is a time-consuming process that poses a substantial barrier for the thousands of neuroscientists and clinical researchers who often lack the resources or machine-learning expertise to train deep learning models. In practice, this leads to a lack of adoption of deep learning, and neuroscience tools being dominated by classical frameworks. We introduce Neuralizer, a single model that generalizes to previously unseen neuroimaging tasks and modalities without the need for re-training or fine-tuning. Tasks do not have to be known a priori, and generalization happens in a single forward pass during inference. The model can solve processing tasks across multiple image modalities, acquisition methods, and datasets, and generalize to tasks and modalities it has not been trained on. Our experiments on coronal slices show that when few annotated subjects are available, our multi-task network outperforms task-specific baselines without training on the task.
TPS++: Attention-Enhanced Thin-Plate Spline for Scene Text Recognition
May 09, 2023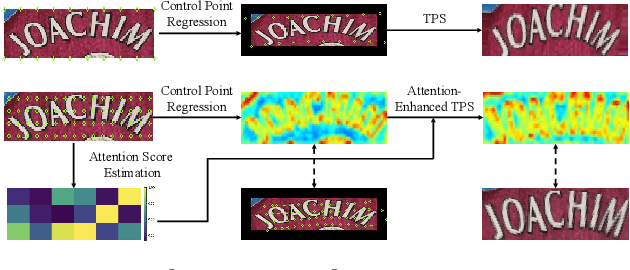

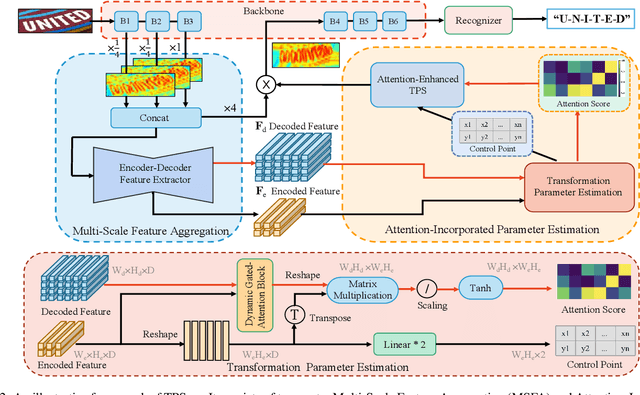
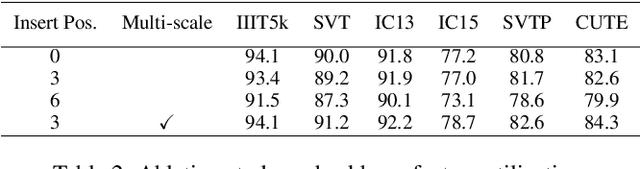
Text irregularities pose significant challenges to scene text recognizers. Thin-Plate Spline (TPS)-based rectification is widely regarded as an effective means to deal with them. Currently, the calculation of TPS transformation parameters purely depends on the quality of regressed text borders. It ignores the text content and often leads to unsatisfactory rectified results for severely distorted text. In this work, we introduce TPS++, an attention-enhanced TPS transformation that incorporates the attention mechanism to text rectification for the first time. TPS++ formulates the parameter calculation as a joint process of foreground control point regression and content-based attention score estimation, which is computed by a dedicated designed gated-attention block. TPS++ builds a more flexible content-aware rectifier, generating a natural text correction that is easier to read by the subsequent recognizer. Moreover, TPS++ shares the feature backbone with the recognizer in part and implements the rectification at feature-level rather than image-level, incurring only a small overhead in terms of parameters and inference time. Experiments on public benchmarks show that TPS++ consistently improves the recognition and achieves state-of-the-art accuracy. Meanwhile, it generalizes well on different backbones and recognizers. Code is at https://github.com/simplify23/TPS_PP.
Fashion CUT: Unsupervised domain adaptation for visual pattern classification in clothes using synthetic data and pseudo-labels
May 09, 2023Accurate product information is critical for e-commerce stores to allow customers to browse, filter, and search for products. Product data quality is affected by missing or incorrect information resulting in poor customer experience. While machine learning can be used to correct inaccurate or missing information, achieving high performance on fashion image classification tasks requires large amounts of annotated data, but it is expensive to generate due to labeling costs. One solution can be to generate synthetic data which requires no manual labeling. However, training a model with a dataset of solely synthetic images can lead to poor generalization when performing inference on real-world data because of the domain shift. We introduce a new unsupervised domain adaptation technique that converts images from the synthetic domain into the real-world domain. Our approach combines a generative neural network and a classifier that are jointly trained to produce realistic images while preserving the synthetic label information. We found that using real-world pseudo-labels during training helps the classifier to generalize in the real-world domain, reducing the synthetic bias. We successfully train a visual pattern classification model in the fashion domain without real-world annotations. Experiments show that our method outperforms other unsupervised domain adaptation algorithms.
Weakly Supervised Image Segmentation Beyond Tight Bounding Box Annotations
Jan 28, 2023



Weakly supervised image segmentation approaches in the literature usually achieve high segmentation performance using tight bounding box supervision and decrease the performance greatly when supervised by loose bounding boxes. However, compared with loose bounding box, it is much more difficult to acquire tight bounding box due to its strict requirements on the precise locations of the four sides of the box. To resolve this issue, this study investigates whether it is possible to maintain good segmentation performance when loose bounding boxes are used as supervision. For this purpose, this work extends our previous parallel transformation based multiple instance learning (MIL) for tight bounding box supervision by integrating an MIL strategy based on polar transformation to assist image segmentation. The proposed polar transformation based MIL formulation works for both tight and loose bounding boxes, in which a positive bag is defined as pixels in a polar line of a bounding box with one endpoint located inside the object enclosed by the box and the other endpoint located at one of the four sides of the box. Moreover, a weighted smooth maximum approximation is introduced to incorporate the observation that pixels closer to the origin of the polar transformation are more likely to belong to the object in the box. The proposed approach was evaluated on two public datasets using dice coefficient when bounding boxes at different precision levels were considered in the experiments. The results demonstrate that the proposed approach achieves state-of-the-art performance for bounding boxes at all precision levels and is robust to mild and moderate errors in the loose bounding box annotations. The codes are available at \url{https://github.com/wangjuan313/wsis-beyond-tightBB}.
Towards Vision Transformer Unrolling Fixed-Point Algorithm: a Case Study on Image Restoration
Jan 29, 2023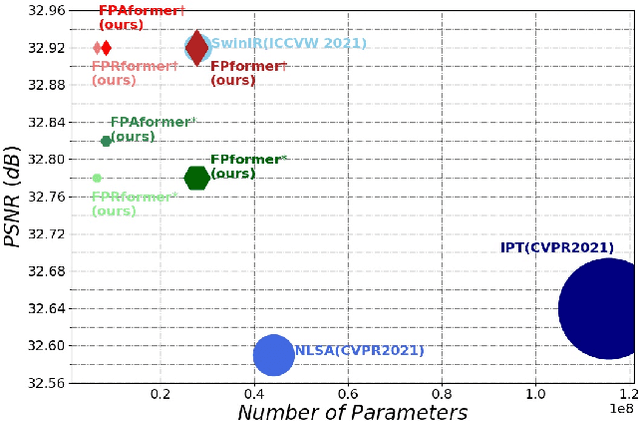



The great success of Deep Neural Networks (DNNs) has inspired the algorithmic development of DNN-based Fixed-Point (DNN-FP) for computer vision tasks. DNN-FP methods, trained by Back-Propagation Through Time or computing the inaccurate inversion of the Jacobian, suffer from inferior representation ability. Motivated by the representation power of the Transformer, we propose a framework to unroll the FP and approximate each unrolled process via Transformer blocks, called FPformer. To reduce the high consumption of memory and computation, we come up with FPRformer by sharing parameters between the successive blocks. We further design a module to adapt Anderson acceleration to FPRformer to enlarge the unrolled iterations and improve the performance, called FPAformer. In order to fully exploit the capability of the Transformer, we apply the proposed model to image restoration, using self-supervised pre-training and supervised fine-tuning. 161 tasks from 4 categories of image restoration problems are used in the pre-training phase. Hereafter, the pre-trained FPformer, FPRformer, and FPAformer are further fine-tuned for the comparison scenarios. Using self-supervised pre-training and supervised fine-tuning, the proposed FPformer, FPRformer, and FPAformer achieve competitive performance with state-of-the-art image restoration methods and better training efficiency. FPAformer employs only 29.82% parameters used in SwinIR models, and provides superior performance after fine-tuning. To train these comparison models, it takes only 26.9% time used for training SwinIR models. It provides a promising way to introduce the Transformer in low-level vision tasks.
A Real Balanced Dataset For Understanding Bias? Factors That Impact Accuracy, Not Numbers of Identities and Images
Apr 17, 2023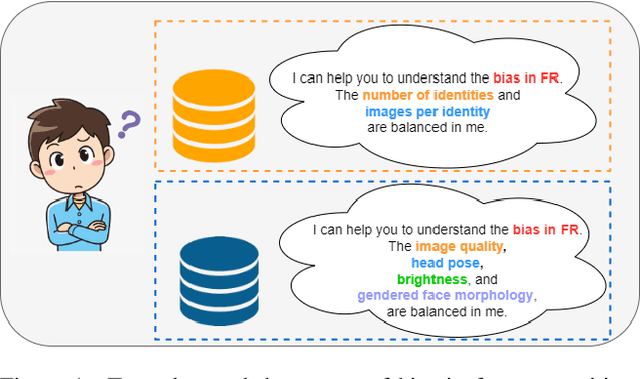
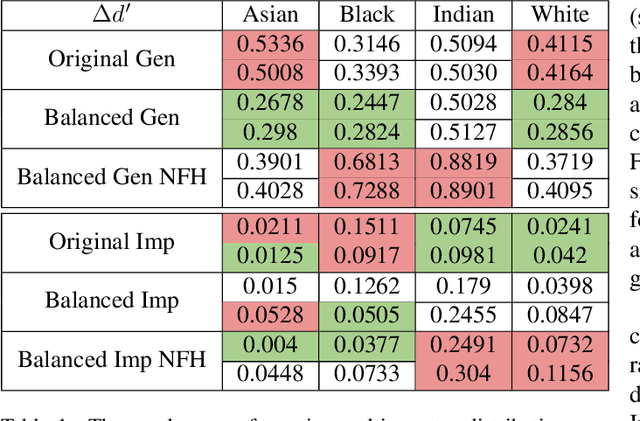
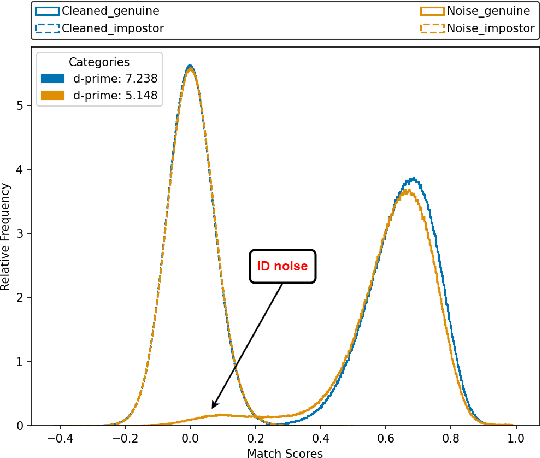
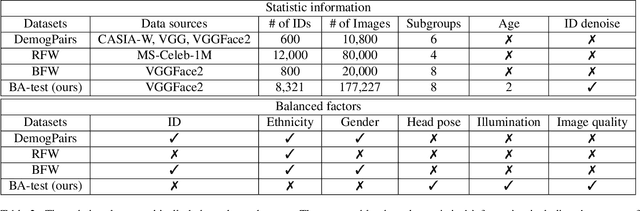
The issue of disparities in face recognition accuracy across demographic groups has attracted increasing attention in recent years. Various face image datasets have been proposed as 'fair' or 'balanced' to assess the accuracy of face recognition algorithms across demographics. While these datasets often balance the number of identities and images across demographic groups. It is important to note that the number of identities and images in an evaluation dataset are not the driving factors for 1-to-1 face matching accuracy. Moreover, balancing the number of identities and images does not ensure balance in other factors known to impact accuracy, such as head pose, brightness, and image quality. We demonstrate these issues using several recently proposed datasets. To enhance the capacity for less biased evaluations, we propose a bias-aware toolkit that facilitates the creation of cross-demographic evaluation datasets balanced on factors mentioned in this paper.
MMViT: Multiscale Multiview Vision Transformers
Apr 28, 2023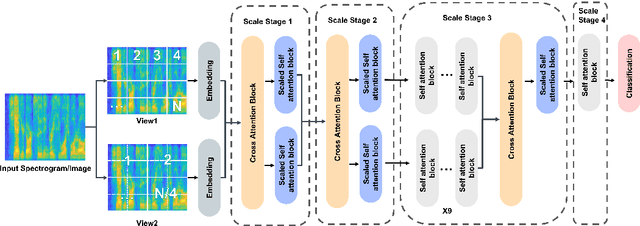
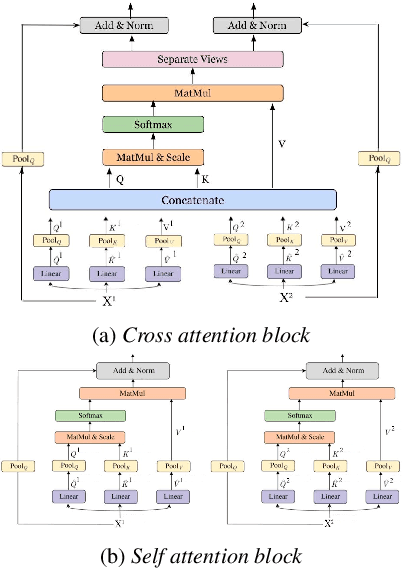
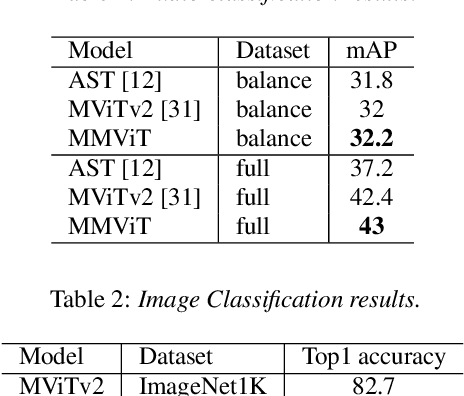
We present Multiscale Multiview Vision Transformers (MMViT), which introduces multiscale feature maps and multiview encodings to transformer models. Our model encodes different views of the input signal and builds several channel-resolution feature stages to process the multiple views of the input at different resolutions in parallel. At each scale stage, we use a cross-attention block to fuse information across different views. This enables the MMViT model to acquire complex high-dimensional representations of the input at different resolutions. The proposed model can serve as a backbone model in multiple domains. We demonstrate the effectiveness of MMViT on audio and image classification tasks, achieving state-of-the-art results.