 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bayesian Optimization Meets Self-Distillation
Apr 25, 2023
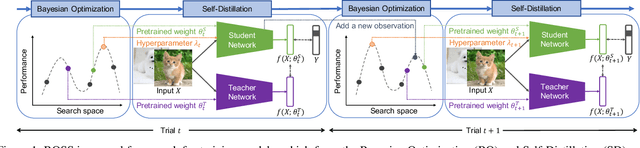

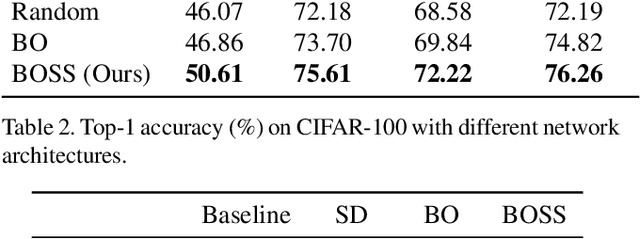
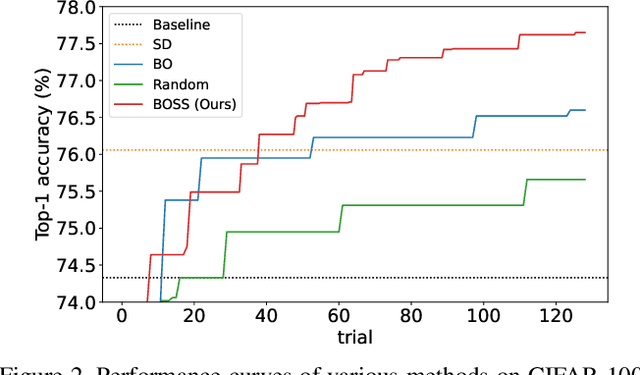
Bayesian optimization (BO) has contributed greatly to improving model performance by suggesting promising hyperparameter configurations iteratively based on observations from multiple training trials. However, only partial knowledge (i.e., the measured performances of trained models and their hyperparameter configurations) from previous trials is transferred. On the other hand, Self-Distillation (SD) only transfers partial knowledge learned by the task model itself. To fully leverage the various knowledge gained from all training trials, we propose the BOSS framework, which combines BO and SD. BOSS suggests promising hyperparameter configurations through BO and carefully selects pre-trained models from previous trials for SD, which are otherwise abandoned in the conventional BO process. BOSS achieves significantly better performance than both BO and SD in a wide range of tasks including general image classification, learning with noisy labels, semi-supervised learning, and medical image analysis tasks.
Graph based Label Enhancement for Multi-instance Multi-label learning
Apr 21, 2023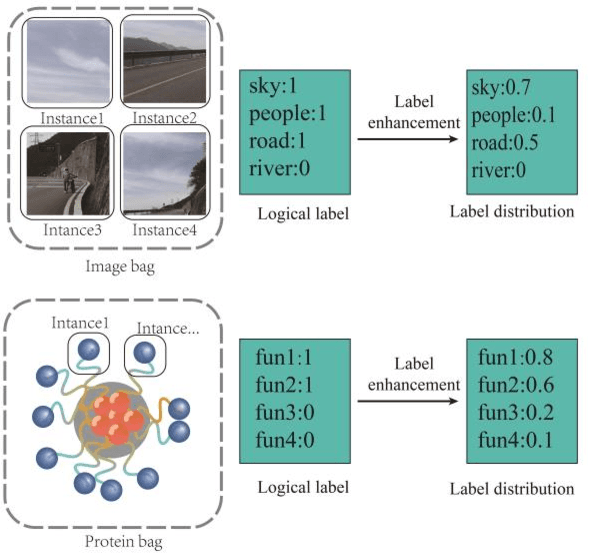
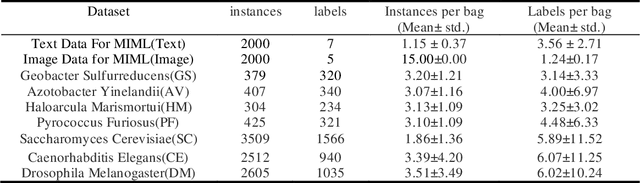
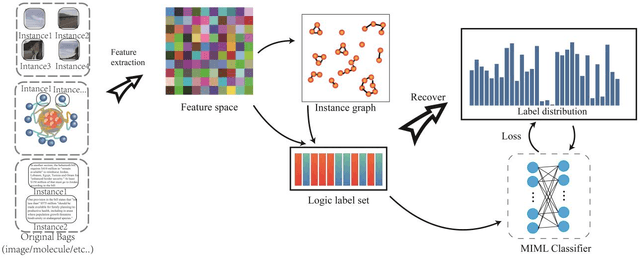
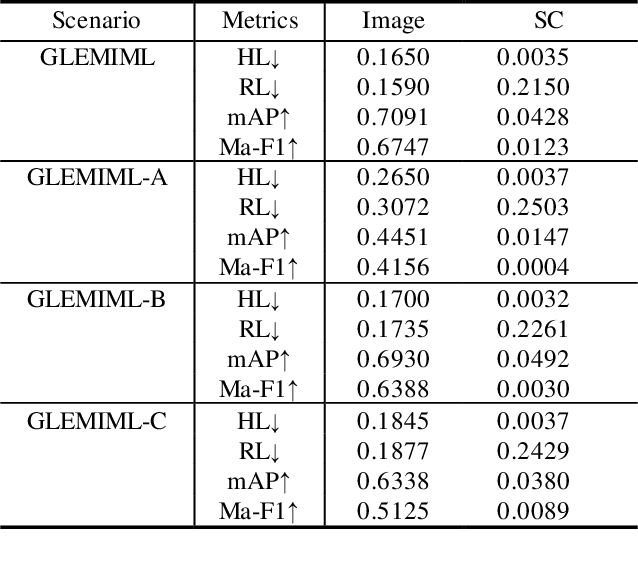
Multi-instance multi-label (MIML) learning is widely applicated in numerous domains, such as the image classification where one image contains multiple instances correlated with multiple logic labels simultaneously. The related labels in existing MIML are all assumed as logical labels with equal significance. However, in practical applications in MIML, significance of each label for multiple instances per bag (such as an image) is significant different. Ignoring labeling significance will greatly lose the semantic information of the object, so that MIML is not applicable in complex scenes with a poor learning performance. To this end, this paper proposed a novel MIML framework based on graph label enhancement, namely GLEMIML, to improve the classification performance of MIML by leveraging label significance. GLEMIML first recognizes the correlations among instances by establishing the graph and then migrates the implicit information mined from the feature space to the label space via nonlinear mapping, thus recovering the label significance. Finally, GLEMIML is trained on the enhanced data through matching and interaction mechanisms. GLEMIML (AvgRank: 1.44) can effectively improve the performance of MIML by mining the label distribution mechanism and show better results than the SOTA method (AvgRank: 2.92) on multiple benchmark datasets.
ReMark: Receptive Field based Spatial WaterMark Embedding Optimization using Deep Network
May 11, 2023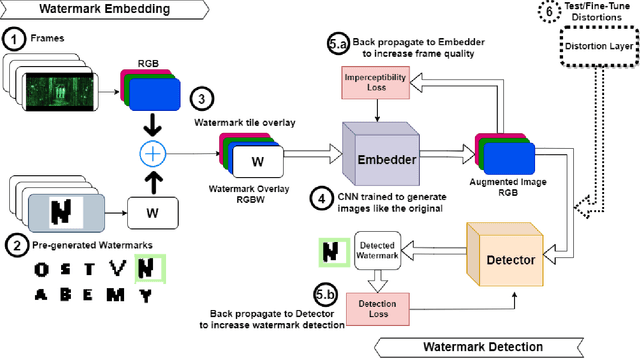
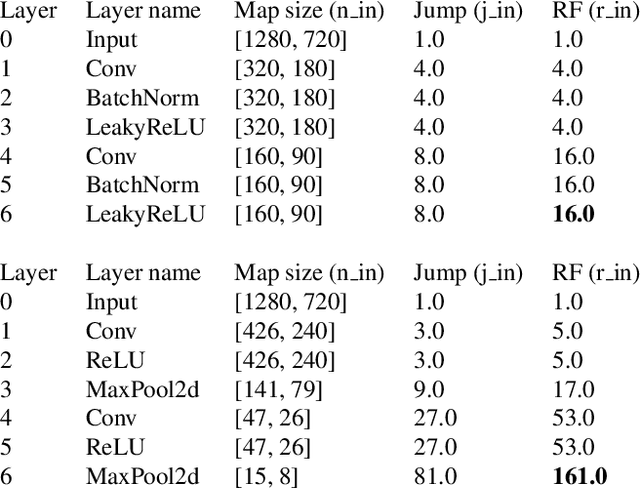
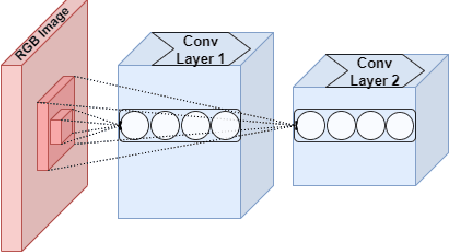
Watermarking is one of the most important copyright protection tools for digital media. The most challenging type of watermarking is the imperceptible one, which embeds identifying information in the data while retaining the latter's original quality. To fulfill its purpose, watermarks need to withstand various distortions whose goal is to damage their integrity. In this study, we investigate a novel deep learning-based architecture for embedding imperceptible watermarks. The key insight guiding our architecture design is the need to correlate the dimensions of our watermarks with the sizes of receptive fields (RF) of modules of our architecture. This adaptation makes our watermarks more robust, while also enabling us to generate them in a way that better maintains image quality. Extensive evaluations on a wide variety of distortions show that the proposed method is robust against most common distortions on watermarks including collusive distortion.
Radious: Unveiling the Enigma of Dental Radiology with BEIT Adaptor and Mask2Former in Semantic Segmentation
May 10, 2023
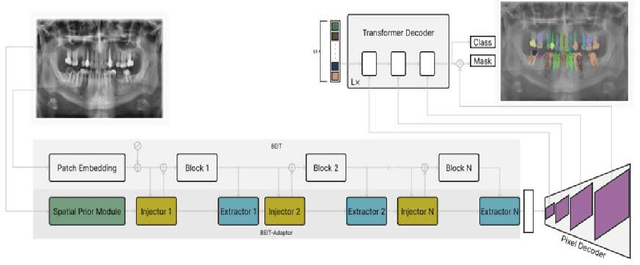
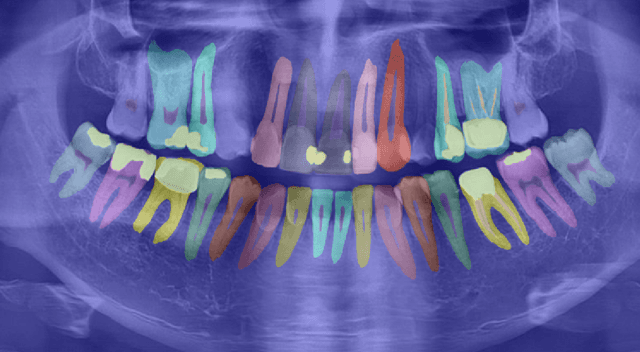
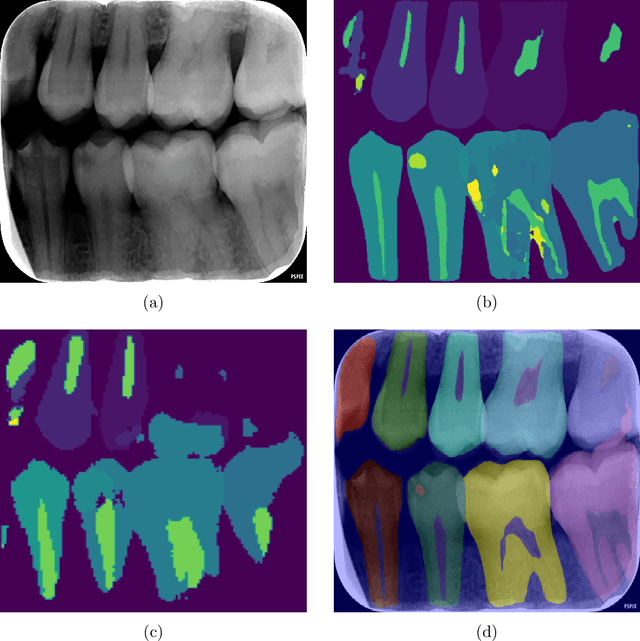
X-ray images are the first steps for diagnosing and further treating dental problems. So, early diagnosis prevents the development and increase of oral and dental diseases. In this paper, we developed a semantic segmentation algorithm based on BEIT adaptor and Mask2Former to detect and identify teeth, roots, and multiple dental diseases and abnormalities such as pulp chamber, restoration, endodontics, crown, decay, pin, composite, bridge, pulpitis, orthodontics, radicular cyst, periapical cyst, cyst, implant, and bone graft material in panoramic, periapical, and bitewing X-ray images. We compared the result of our algorithm to two state-of-the-art algorithms in image segmentation named: Deeplabv3 and Segformer on our own data set. We discovered that Radious outperformed those algorithms by increasing the mIoU scores by 9% and 33% in Deeplabv3+ and Segformer, respectively.
MVP-SEG: Multi-View Prompt Learning for Open-Vocabulary Semantic Segmentation
Apr 14, 2023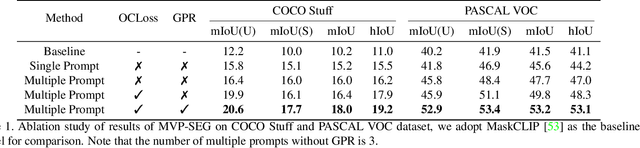
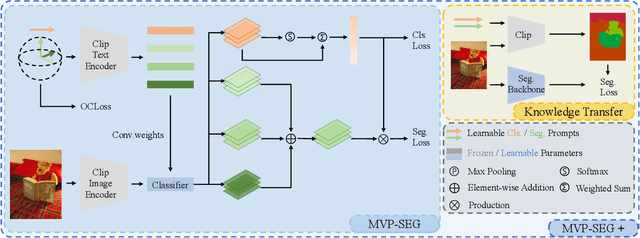
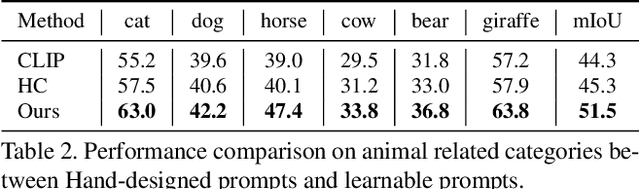
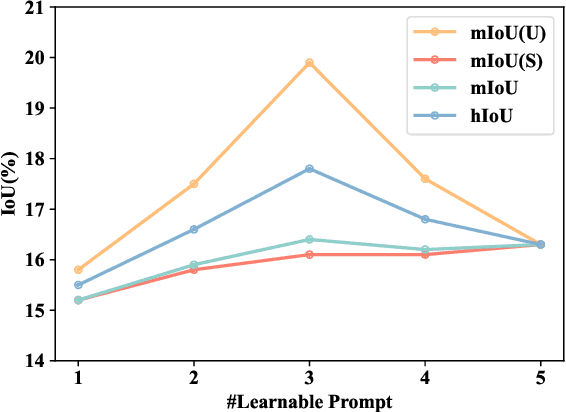
CLIP (Contrastive Language-Image Pretraining) is well-developed for open-vocabulary zero-shot image-level recognition, while its applications in pixel-level tasks are less investigated, where most efforts directly adopt CLIP features without deliberative adaptations. In this work, we first demonstrate the necessity of image-pixel CLIP feature adaption, then provide Multi-View Prompt learning (MVP-SEG) as an effective solution to achieve image-pixel adaptation and to solve open-vocabulary semantic segmentation. Concretely, MVP-SEG deliberately learns multiple prompts trained by our Orthogonal Constraint Loss (OCLoss), by which each prompt is supervised to exploit CLIP feature on different object parts, and collaborative segmentation masks generated by all prompts promote better segmentation. Moreover, MVP-SEG introduces Global Prompt Refining (GPR) to further eliminate class-wise segmentation noise. Experiments show that the multi-view prompts learned from seen categories have strong generalization to unseen categories, and MVP-SEG+ which combines the knowledge transfer stage significantly outperforms previous methods on several benchmarks. Moreover, qualitative results justify that MVP-SEG does lead to better focus on different local parts.
Content-Adaptive Downsampling in Convolutional Neural Networks
May 16, 2023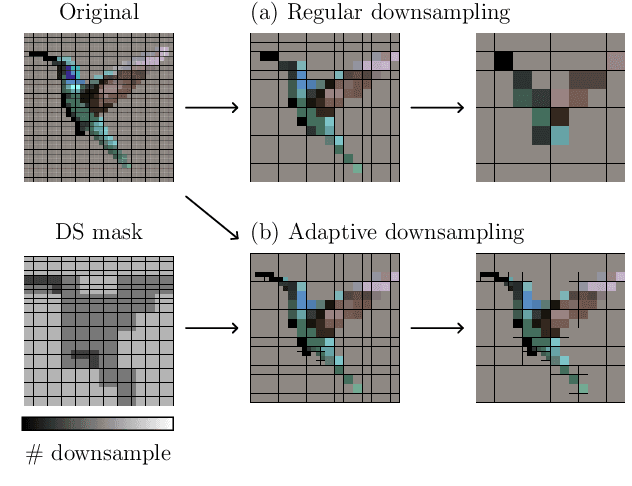
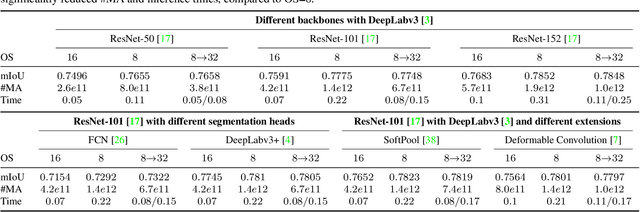
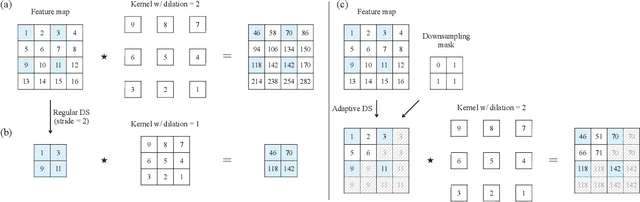
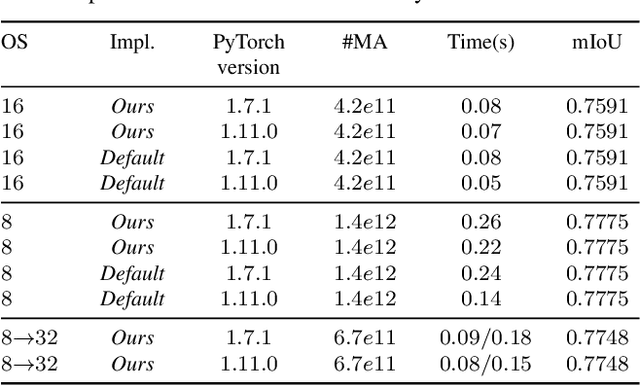
Many convolutional neural networks (CNNs) rely on progressive downsampling of their feature maps to increase the network's receptive field and decrease computational cost. However, this comes at the price of losing granularity in the feature maps, limiting the ability to correctly understand images or recover fine detail in dense prediction tasks. To address this, common practice is to replace the last few downsampling operations in a CNN with dilated convolutions, allowing to retain the feature map resolution without reducing the receptive field, albeit increasing the computational cost. This allows to trade off predictive performance against cost, depending on the output feature resolution. By either regularly downsampling or not downsampling the entire feature map, existing work implicitly treats all regions of the input image and subsequent feature maps as equally important, which generally does not hold. We propose an adaptive downsampling scheme that generalizes the above idea by allowing to process informative regions at a higher resolution than less informative ones. In a variety of experiments, we demonstrate the versatility of our adaptive downsampling strategy and empirically show that it improves the cost-accuracy trade-off of various established CNNs.
Consensus and Subjectivity of Skin Tone Annotation for ML Fairness
May 16, 2023

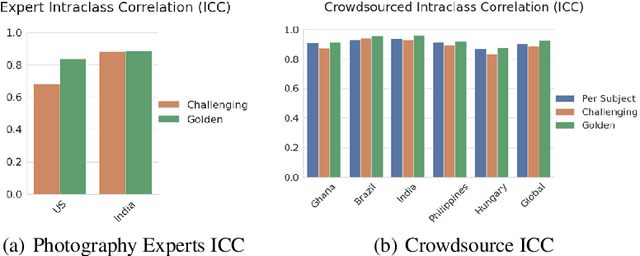
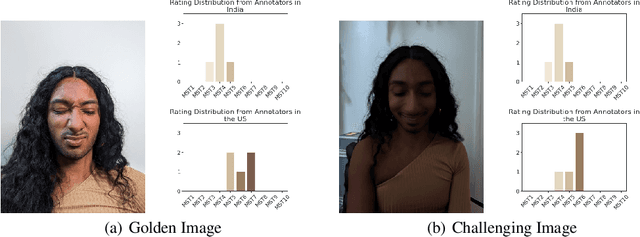
Recent advances in computer vision fairness have relied on datasets augmented with perceived attribute signals (e.g. gender presentation, skin tone, and age) and benchmarks enabled by these datasets. Typically labels for these tasks come from human annotators. However, annotating attribute signals, especially skin tone, is a difficult and subjective task. Perceived skin tone is affected by technical factors, like lighting conditions, and social factors that shape an annotator's lived experience. This paper examines the subjectivity of skin tone annotation through a series of annotation experiments using the Monk Skin Tone (MST) scale, a small pool of professional photographers, and a much larger pool of trained crowdsourced annotators. Our study shows that annotators can reliably annotate skin tone in a way that aligns with an expert in the MST scale, even under challenging environmental conditions. We also find evidence that annotators from different geographic regions rely on different mental models of MST categories resulting in annotations that systematically vary across regions. Given this, we advise practitioners to use a diverse set of annotators and a higher replication count for each image when annotating skin tone for fairness research.
3DFill:Reference-guided Image Inpainting by Self-supervised 3D Image Alignment
Nov 09, 2022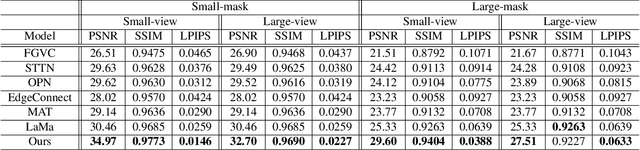
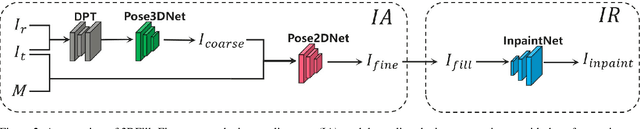
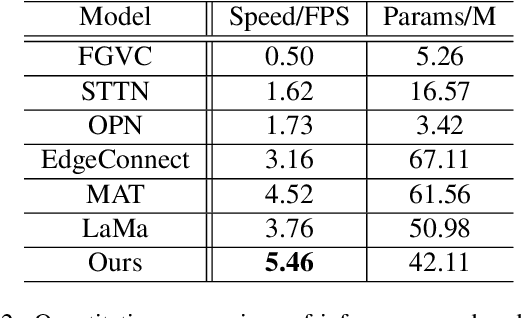
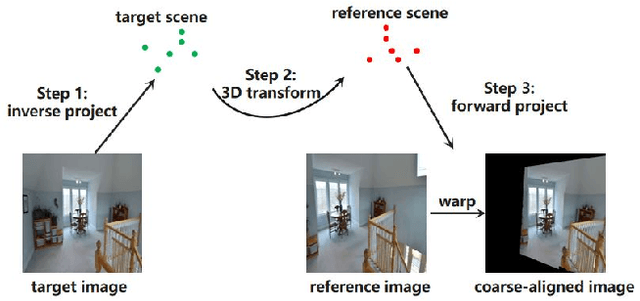
Most existing image inpainting algorithms are based on a single view, struggling with large holes or the holes containing complicated scenes. Some reference-guided algorithms fill the hole by referring to another viewpoint image and use 2D image alignment. Due to the camera imaging process, simple 2D transformation is difficult to achieve a satisfactory result. In this paper, we propose 3DFill, a simple and efficient method for reference-guided image inpainting. Given a target image with arbitrary hole regions and a reference image from another viewpoint, the 3DFill first aligns the two images by a two-stage method: 3D projection + 2D transformation, which has better results than 2D image alignment. The 3D projection is an overall alignment between images and the 2D transformation is a local alignment focused on the hole region. The entire process of image alignment is self-supervised. We then fill the hole in the target image with the contents of the aligned image. Finally, we use a conditional generation network to refine the filled image to obtain the inpainting result. 3DFill achieves state-of-the-art performance on image inpainting across a variety of wide view shifts and has a faster inference speed than other inpainting models.
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
Apr 27, 2023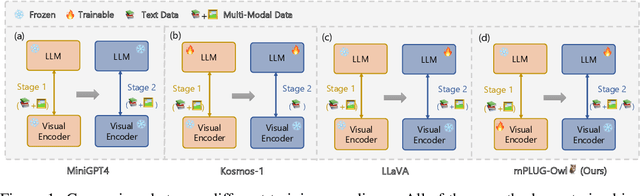

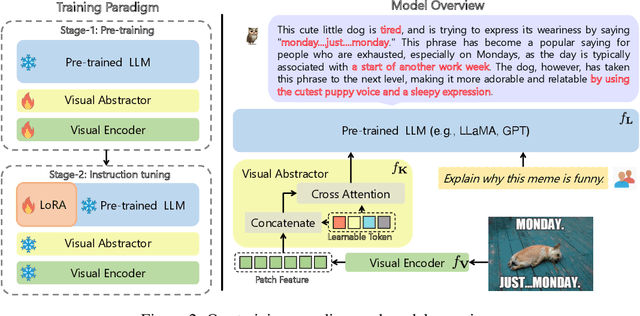
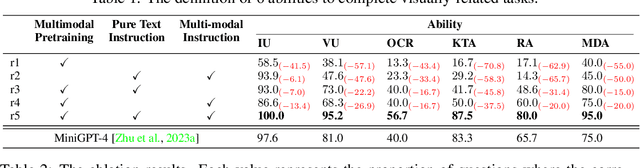
Large language models (LLMs) have demonstrated impressive zero-shot abilities on a variety of open-ended tasks, while recent research has also explored the use of LLMs for multi-modal generation. In this study, we introduce mPLUG-Owl, a novel training paradigm that equips LLMs with multi-modal abilities through modularized learning of foundation LLM, a visual knowledge module, and a visual abstractor module. This approach can support multiple modalities and facilitate diverse unimodal and multimodal abilities through modality collaboration. The training paradigm of mPLUG-Owl involves a two-stage method for aligning image and text, which learns visual knowledge with the assistance of LLM while maintaining and even improving the generation abilities of LLM. In the first stage, the visual knowledge module and abstractor module are trained with a frozen LLM module to align the image and text. In the second stage, language-only and multi-modal supervised datasets are used to jointly fine-tune a low-rank adaption (LoRA) module on LLM and the abstractor module by freezing the visual knowledge module. We carefully build a visually-related instruction evaluation set OwlEval. Experimental results show that our model outperforms existing multi-modal models, demonstrating mPLUG-Owl's impressive instruction and visual understanding ability, multi-turn conversation ability, and knowledge reasoning ability. Besides, we observe some unexpected and exciting abilities such as multi-image correlation and scene text understanding, which makes it possible to leverage it for harder real scenarios, such as vision-only document comprehension. Our code, pre-trained model, instruction-tuned models, and evaluation set are available at https://github.com/X-PLUG/mPLUG-Owl. The online demo is available at https://www.modelscope.cn/studios/damo/mPLUG-Owl.
DeepFEL: Deep Fastfood Ensemble Learning for Histopathology Image Analysis
Jan 23, 2023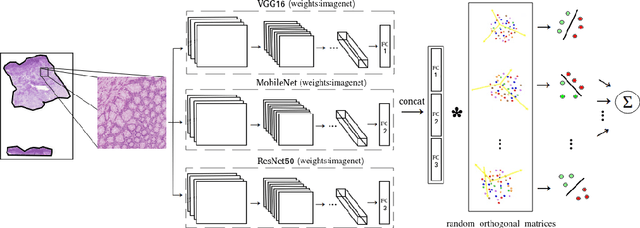
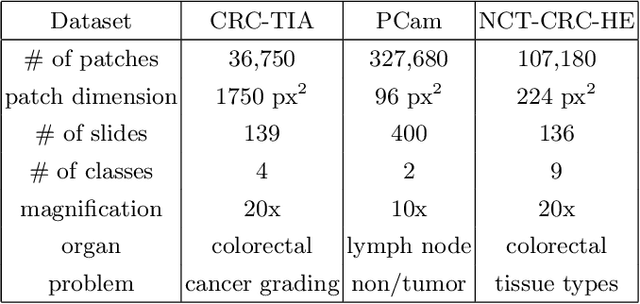
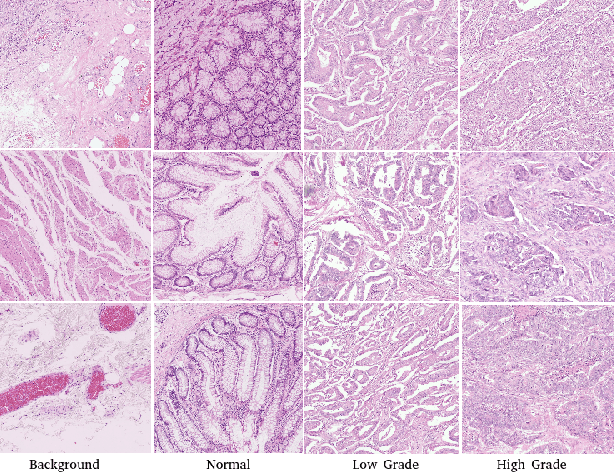
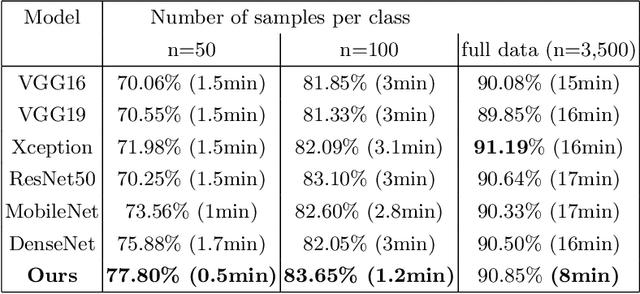
Computational pathology tasks have some unique characterises such as multi-gigapixel images, tedious and frequently uncertain annotations, and unavailability of large number of cases [13]. To address some of these issues, we present Deep Fastfood Ensembles - a simple, fast and yet effective method for combining deep features pooled from popular CNN models pre-trained on totally different source domains (e.g., natural image objects) and projected onto diverse dimensions using random projections, the so-called Fastfood [11]. The final ensemble output is obtained by a consensus of simple individual classifiers, each of which is trained on a different collection of random basis vectors. This offers extremely fast and yet effective solution, especially when training times and domain labels are of the essence. We demonstrate the effectiveness of the proposed deep fastfood ensemble learning as compared to the state-of-the-art methods for three different tasks in histopathology image analysis.